目錄
TCP 協議
TCP 協議段格式
可靠傳輸
幾個?TCP 協議中的機制
1. 確認應答
2. 超時重傳
完!
TCP 協議
TCP 全稱為 “傳輸控制協議”(Transmission Control Protocol),要對數據的傳輸進行一個詳細的控制。
TCP 協議段格式
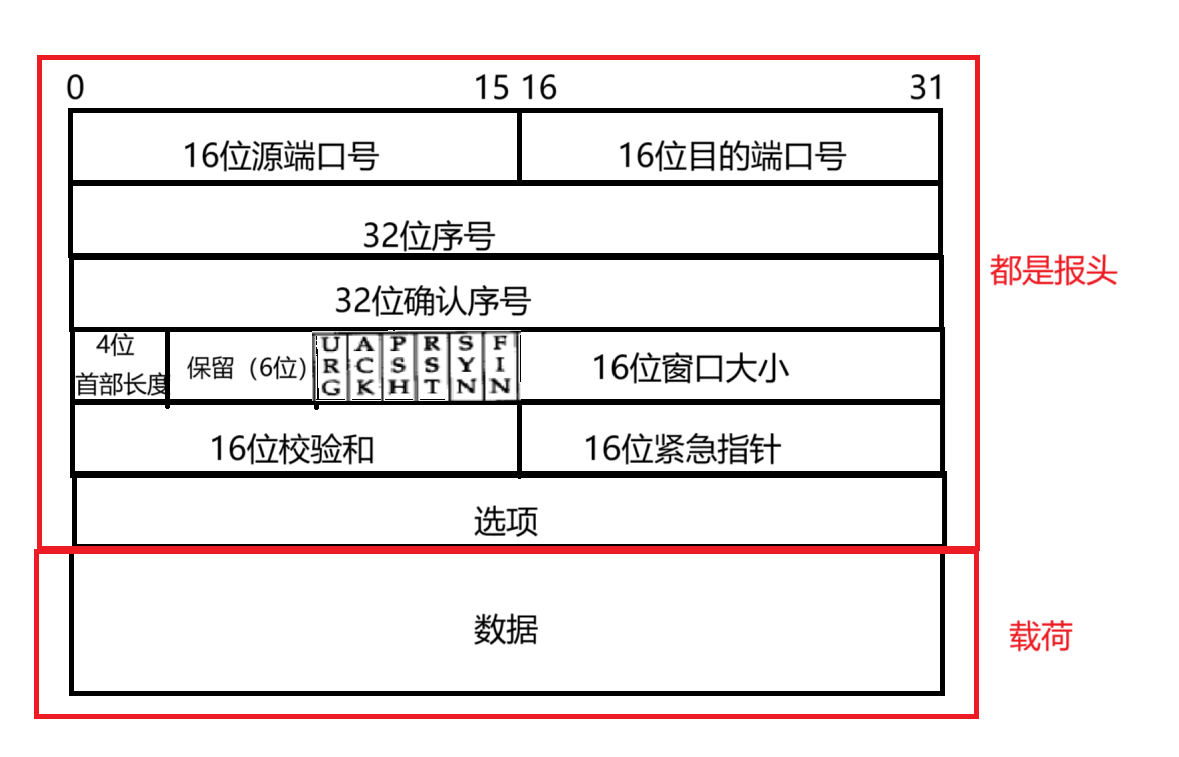
TCP 的報頭對比于 UDP 的報頭,就復雜很多了~~~
源端口號,目的端口號:和 UDP 還是一樣的,表示數據是從那個進程來,到那個進程去。
32 位序號和 32 位確認序號,后面再詳談
4 位首部長度:首部長度也就是報頭長度(header),不像?UDP 協議(報頭固定是 8 個字節),TCP 報頭中的前 20 個字節是固定長度的。后面這里包含了“選項(optional)”部分,選項部分可以有,也可以沒有,可以有一個,也可以有多個。總的來說,表示了該 TCP 頭部有多少個 32 位 bit(有多少個 4 字節),4 位首部長度,則說明 TCP 頭部最大長度是 15(1111) * 4 = 60
保留位(reserved):在 UDP 協議中,長度受到 2 個字節的限制,想要進行擴展,發現無法擴展,一旦改變了報頭長度,就會使得發送的 UDP 數據報和其他機器不兼容,無法通信。TCP 就提前做好了防備,設定報頭的時候,提前準備了幾個保留位(雖然不用,但先占個位置),后面一旦需要了,就把這些保留位給使用起來。
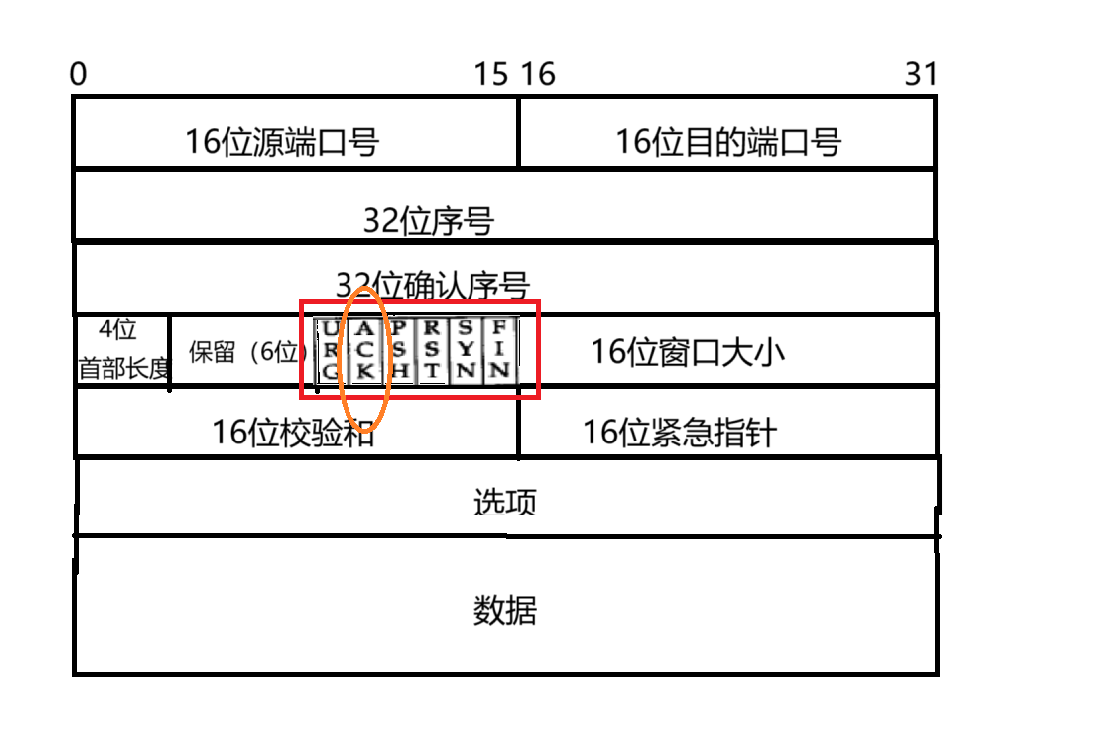
URG,ACK,PSH,PST,SYN,FIN:6 位標志位,是 TCP 協議中非常核心的部分,后面會詳細展開
16 位窗口大小:后面再詳談
16 位校驗和:類似于 UDP 的校驗和一樣。會把報頭和數據載荷放在一起進行校驗和。
16 位緊急指針:可以表示那部分數據是緊急數據。
TCP 內部的機制有非常多,上述報頭的字段都是針對 TCP 中的各個機制的屬性支撐,我們要詳細了解 TCP 中的其他機制,才能更加深刻的認識到報頭的含義。
可靠傳輸
前面我們提到 TCP 的特點:有連接,可靠傳輸,面向字節流,全雙工。其中,TCP 中最核心,最重要的就是解決“可靠傳輸”的問題。
網絡通信的過程是及其復雜的,無法確保發送方發出去的數據,100% 能夠到達接收方。此處所提到的可靠性,只能“退而求其次”,只要盡可能的去進行發送,發送方能夠知道對方是否收到,就認為是“可靠傳輸”了。
幾個?TCP 協議中的機制
1. 確認應答
用來確保可靠性最核心的機制,稱為“確認應答”。
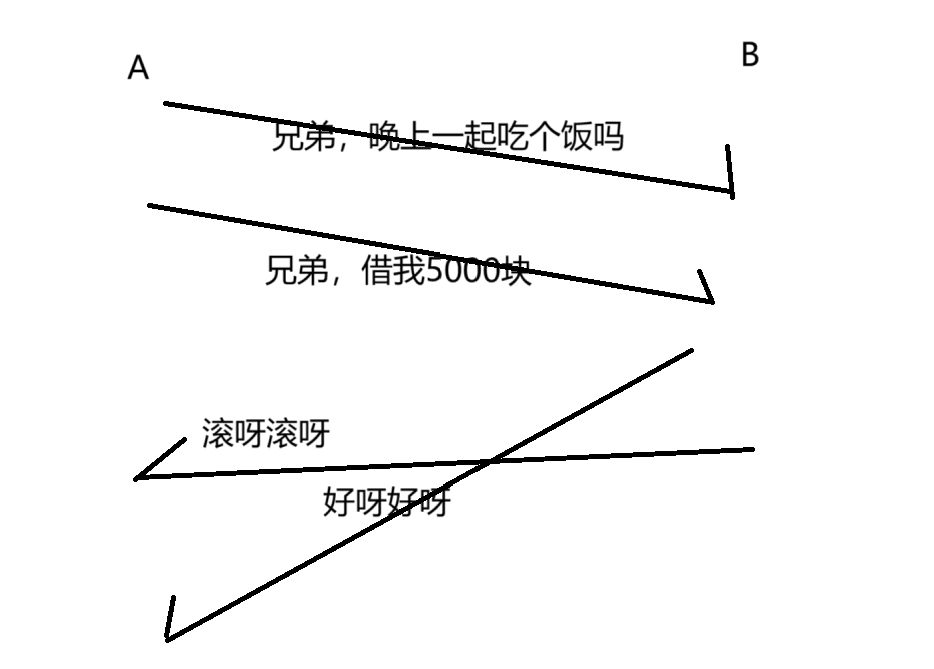
舉個栗子:A 和 B 進行交互~
A 向 B 發出消息說:“兄弟,晚上有事情嗎,一起吃個飯”,B 回復:“好呀好呀”
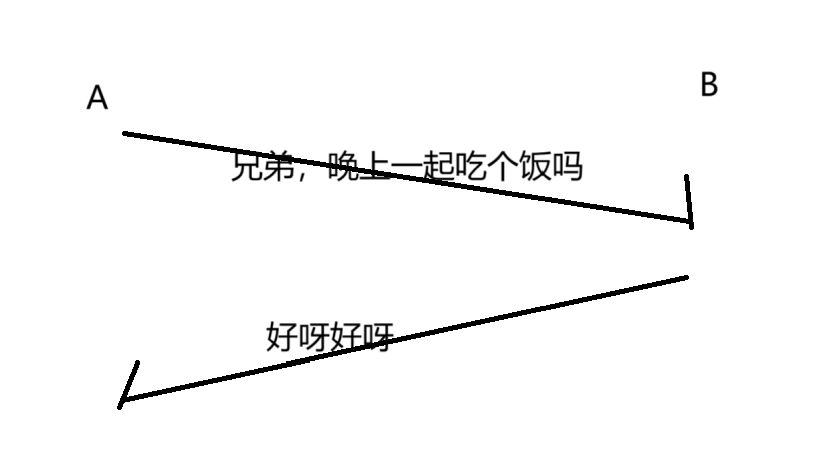
但是當 A 再說出下面這句“借我5000塊”,B 看到之后,心想,果然沒按好心,會回復”滾呀滾呀“。
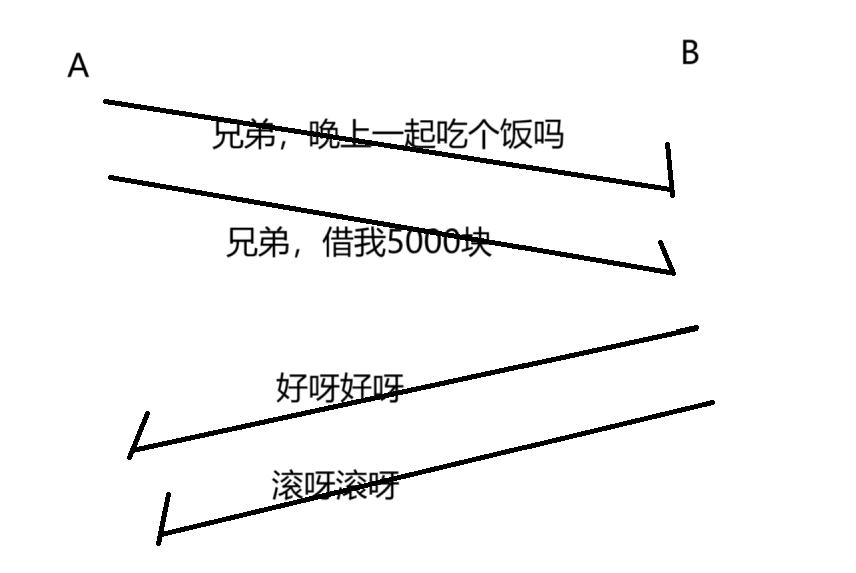
但是上面情況的時序,有些過于理想化了,實際上,網絡傳輸過程中,經常會出現”后發先至”的情況。
網絡通信中,為什么會出現“后發先至”的情況呢???
當一個數據報從發送方到接收方,其數據報會經歷許多交換機 / 路由器,其傳輸過程中走的路徑可能不一樣,第一個數據包,可能走路線一,第二個數據包,走路線二...
有可能路線二暢通,路線一發生阻塞了,這就會導致,數據包二雖然后發,但是會先到達接收方。
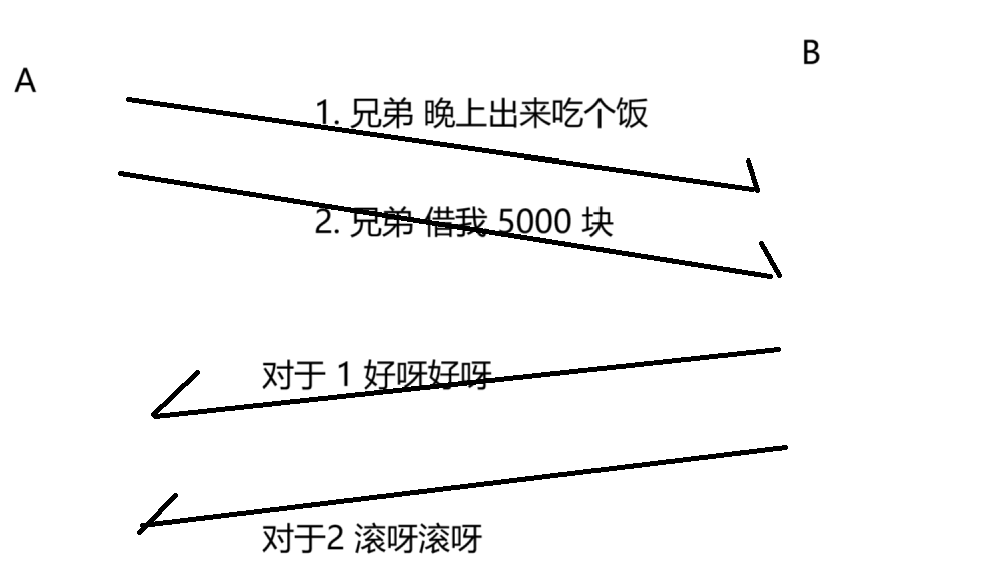
我們上述的對話就可能變成這樣:
如果出現后發先至的情況,再去理解這里的含義,就會出現問題了!!!
為了解決上述的問題,就引入了序號和確認序號,對數據進行編號,應答報文里面,就告訴發送發,我這次應答的是那個數據!
當然,我們上述的情況是一個簡化版本的模型,真實的 TCP 協議的情況是更加復雜的。
TCP 是面向字節流的,以字節為單位進行傳輸的,沒有“一條 兩條”的概念。
實際上,TCP 的序號和確認序號都是以字節來進行編號的。
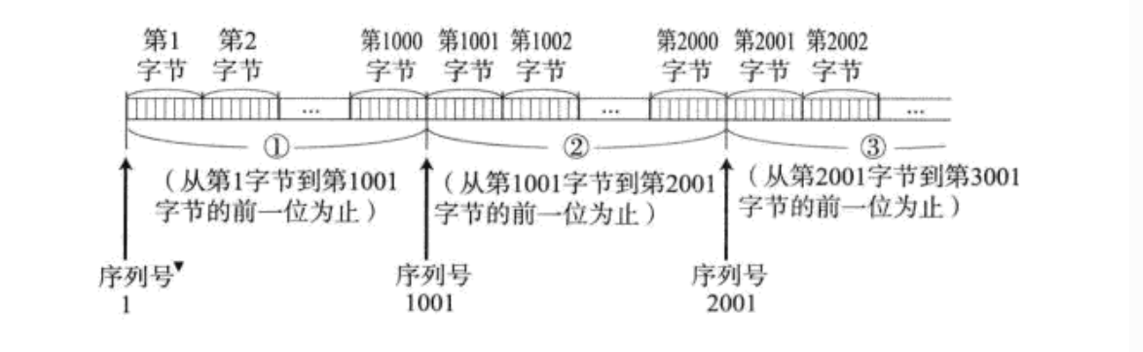 這就呼應到我們前面 TCP 協議中報頭的 32 位序號了,在 TCP 的報頭中的序號,只能存一個。
這就呼應到我們前面 TCP 協議中報頭的 32 位序號了,在 TCP 的報頭中的序號,只能存一個。
比如說有如下數據報:
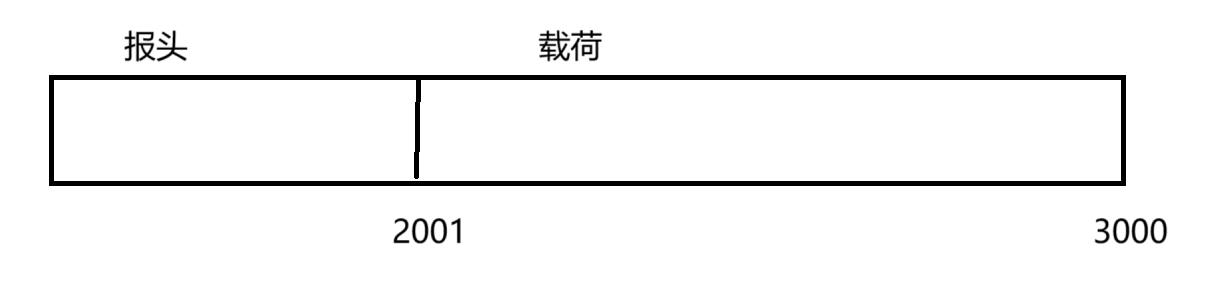
即假設載荷有 1000 個字節,1000 個序號,由于序號是連續的,只需要在報頭中保存第一個字節的序號 - 2001 即可,后續字節的序號都是很容易計算得到的~
而應答報文中的確認序號,是按照發送過去的最后一個字節的序號再加 1 來進行設定的~
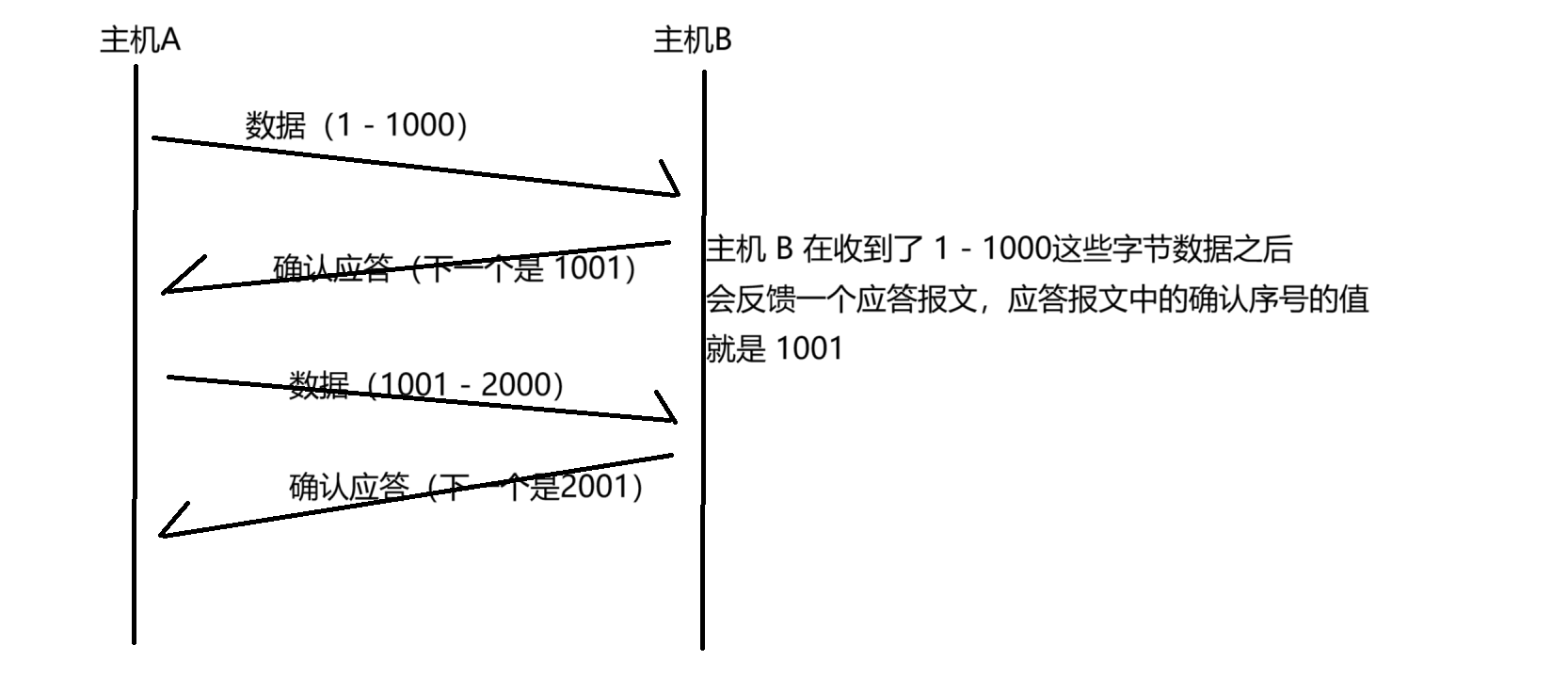
確認應答 1001 的含義,有兩種或理解方式:
? ? ? ? 1. 數據小于 1001 的數據,都已經收到了
? ? ? ? 2. 發送方接下來要給我(接收方)發 1001 開始的數據了
TCP 的確認應答是確保 TCP可靠性的最核心的機制!!!
(錯誤的說法:TCP 之所以能夠保證可靠性,是因為“進行了“三次握手”)
在確認應答中,通過應答報文來反饋給發送方,表示當前的數據正確收到了。應答報文,也叫做 ACK(acknowledge)?報文。這個 ACK 是不是有些熟悉呢???就是我們剛剛在報頭結構中的 6 位標記位中的一位~~~平時的普通報文,ACK 這位是 0,如果當前報文是應答報文,則此時這個報文的 ACK 位置就是 1。
2. 超時重傳
超時重傳這個機制,是對確認應答的補充。
如果一切順利,通過應答報文,接收方就可以告訴發送方,當前數據是不是成功收到了,但是,網絡上可能存在“丟包”的情況。如果數據包丟了,沒有到達對端,對方自然也就沒有 ACK 報文了。
這個情況下,就需要超時重傳了!
TCP 可靠性就是在對抗丟包,期望做到,在丟包情況客觀存在的時候,也能夠盡可能的把包傳過去!
大概流程如下:
發送方發了個數據過去之后,要等一段時間。在等待的這段時間中,收到了接收方發來的 ACK(數據報在網絡上傳輸也是需要時間的)如果等了好久,ACK 還沒有等到,此時發送方就會人數數據的傳輸出現丟包情況了,當認為丟包之后,就會把剛才的數據包再傳一次(重傳),等待的過程有一個時間上的閾值(上限),就是超時。
上面的流程中,是認為沒收到 ACK 就是丟包,其實這樣說是有些問題的。
丟包,不一定就是發的數據丟了,還有可能是,ACK 丟了。數據丟了,還是 ACK 丟了,在發送方的角度來看,咦,都是一樣的呀,就是收不到接收方的 ACK
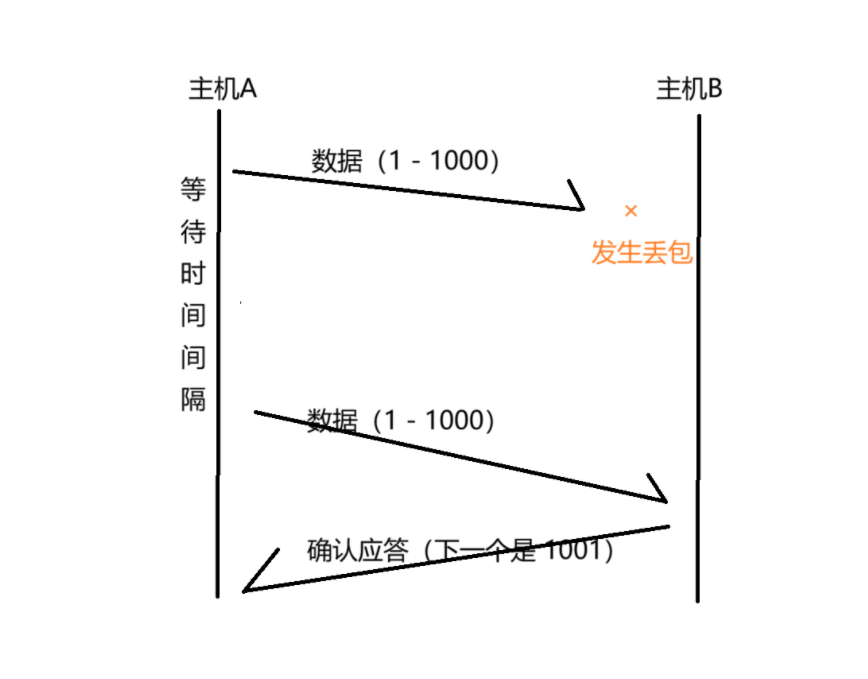
當我們是上面這種情況下,接收方本身就沒收到數據,此時進行重傳是理所應當的,沒有任何問題~~~
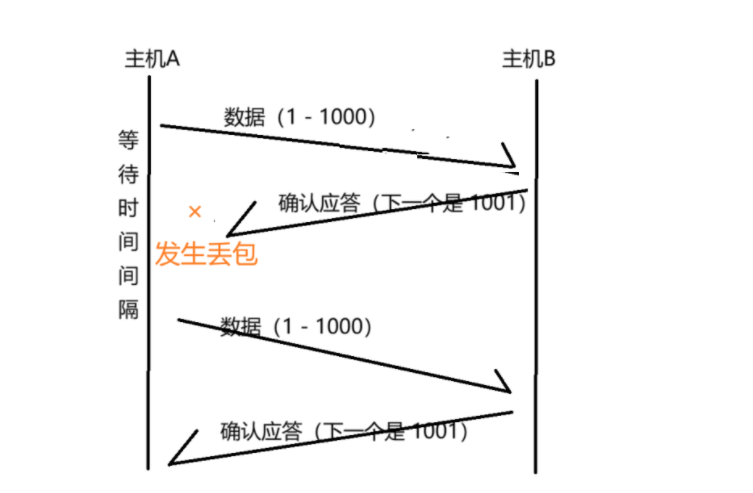
但如果是上圖這種情況呢???數據已經被 B 收到了,再傳輸一次,同一份數據,B 就會收到兩次,試想一下,如果發送的請求是扣款請求呢???(扣兩次款???用戶一定會猛噴!!!)
其實不然~~~
TCP socket 在內核中,存在一個接收緩沖區(一塊內存空間),發送方發來的數據,是要先放到接收緩沖區中的,然后應用程序調用 read / scanner.next 才能讀取到數據,這里的讀操作,其實是讀取接收緩沖區中的數據。

當數據到達接收緩沖區的時候,接收方首先會判定一下,看當前緩沖區中,是否已經有這個數據了(也會判定,這個數據曾經是否在緩沖區中存在過),如果已經存在或者存在過,就直接把重發發來的數據就丟棄了~~就能確保應用程序,在調用 read / scanner.next 的時候,不會出現重復數據~~~
那接收方是如何判定這個數據是否是“重復數據”呢???
核心的判定依據,還是我們剛剛提到過的 -- 數據的序號!!!
1. 數據還在緩沖區里面,還沒有被 read 走,此時,我們就要拿著新收到的數據的序號,和緩沖區中的數據的序號對一下,看看有沒有一樣的,有一樣的,就是重復了,就可以把新收到的數據丟棄了。
2. 數據已經被應用程序給 read 走了,此時新來的數據的序號就無法直接在接收緩沖區中查到了。
但是!!!應用程序在讀取數據的時候,是會按照序號的先后順序,連續進行讀取的!!!
先讀 1 - 1000, 1001 - 2000, 2001?- 3000。
一定是先讀序號小的數據,然后再讀序號大的數據(可以把接收緩沖區理解為帶有優先級的阻塞隊列)。此時 socket API 中就可以記錄上次讀的最后一個字節的序號是多少。
比如上次讀的最后一個字節的序號是 3000,新收到一個數據包的序號是 1001,則這個 1001 一定是之前已經讀過的了~這個時候,同樣可以把這個新的數據包判定為“重復的包”直接丟棄掉~~~
上面談到的 ACK,重傳,保證順序,自動取寵,其實都是 TCP 已經內置好了的,我們使用 TCP 的 API 的時候,outputStream.write()? 只需要簡單的調用這一行代碼,上述功能都自動生效了~~~
(UDP 的不可靠,我們就需要好好考慮一下上面的問題了~~~)
補充:
超時是會重傳,但是重傳過程中,也是有一定策略的。
1. 重傳次數是有上限的,重傳到一定的程序,還沒有收到 ACK,就會嘗試重置連接,如果充值也失敗,發送方就會直接放棄連接。
2. 重傳的超時時間閾值也不是固定不變的,會隨著重傳次數的增加而增大。(換句話講,就是重傳的頻率會越來越低)(因為:如果經歷過了重傳之后,還出現了丟包情況,那大概率是網絡出現了比較嚴重的問題了,再怎么重傳,也是白費勁,不如省點力氣~~~)
舉個栗子:
假設:一次網絡通信過程中,丟包的概率是 10%(這已經是一個非常夸張的數字了!!!)
包能順利到達的概率是 90%,那我們重傳了一次,卻又發生丟包,即兩次傳輸數據都丟包的概率是 10% * 10% = 1% ==》換個角度看,兩次傳輸包至少有一次能到達的概率是 99%,隨著重傳的次數增加,包到達接收方的概率也會大大增加,如果我們連續重傳了三四次仍然還是發生丟包,只能說明,此時的丟包率是非常非常非常大了,意味著此時的網絡已經出現了非常非常嚴重的故障了!!!再重傳也意義不大了~~~









)



)



以管理員權限啟動(UAC))

