?1. 定義與核心思想
強化學習(Reinforcement Learning, RL)是一種通過智能體(Agent)與環境(Environment)的持續交互來學習最優決策策略的機器學習范式。其核心特征為:
- ??試錯學習??:智能體初始策略隨機("開局是智障"),通過大量交互獲得經驗數據("裝備全靠打")
- ??獎勵驅動??:環境對每個動作給出獎勵信號(Reward),智能體目標為最大化長期累積獎勵
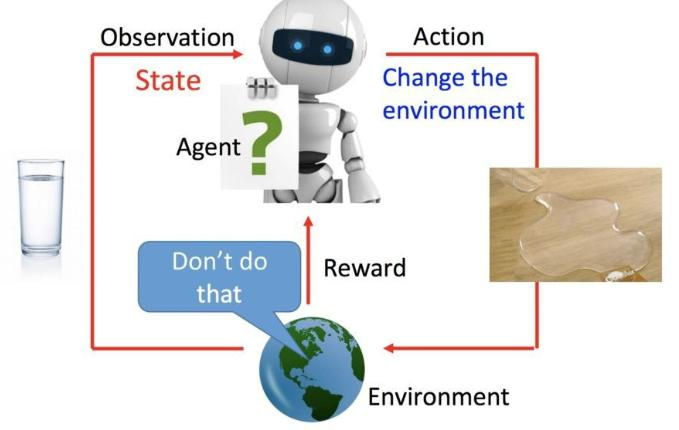
2. 馬爾可夫決策過程(MDP)
RL問題可形式化為五元組:
其中:
:狀態空間(如飛船位置、速度)
:動作空間(離散:{左,右,開火};連續:力度∈[0,1])
:狀態轉移概率
:即時獎勵函數
:折扣因子
3. 獎勵機制與目標函數
智能體追求??最大化期望折扣累積獎勵??:
對于飛船著陸問題:
- 最終獎勵:成功著陸+100,墜毀-100
- 過程獎勵:燃料消耗-0.1,姿態偏離-0.5
4. 策略與價值函數
??策略表示狀態到動作的概率分布,??狀態值函數??評估策略優劣:
??動作值函數??(Q函數)定義為:
5. 策略優化方法
5.1 基于值函數的方法(如Q-Learning)
通過貝爾曼最優方程更新Q值:
5.2 策略梯度方法(如REINFORCE)
直接優化參數化策略,梯度計算為:
6. 深度強化學習實現
使用神經網絡近似策略或價值函數(如DQN):
輸入:輸出:動作概率分布/最優動作
訓練目標為最小化時序差分誤差:
7. 應用領域
| 領域 | 狀態空間 | 動作空間 | 獎勵設計 |
|---|---|---|---|
| 機器人控制 | 關節角度、力反饋 | 力矩調整 | 姿態穩定性獎勵 |
| 游戲AI | 屏幕像素 | 手柄按鍵組合 | 得分增減機制 |
| 金融交易 | 市場行情 | 買入/賣出量 | 投資回報率 |
8. 核心挑戰
- ??探索與利用的平衡??:ε-greedy、UCB等方法
- ??稀疏獎勵問題??:基于好奇心(Curiosity)的探索
- ??高維連續動作空間??:確定性策略梯度(DDPG)






)
部署筆記)







)

:使用4個文件實現MVC框架)

)