目錄
1、函數
1.1、語法格式
1.2、函數返回值
1.3、變量作用域
1.4、執行過程
1.5、鏈式調用
1.6、嵌套調用
1.7、函數遞歸
1.8、參數默認值
?1.9、關鍵字參數
2、列表
2.1、創建列表
2.2、下標訪問
2.3、切片操作
2.4、遍歷列表元素
2.5、新增元素
2.6、查找元素
2.7、刪除元素
2.8、連接列表
3、元組
4、字典
4.1、創建字典
4.2、查找key
4.3、新增和修改元素
4.4、刪除元素
4.5、遍歷字典元素
4.6、合法的key類型
1、函數
編程中的函數和數學中的函數有一定的相似之處。編程中的函數,是一段可以被重復使用的代碼片段。例如:
# 1. 求 1 - 100 的和
sum = 0
for i in range(1, 101):sum += i
print(sum)
# 2. 求 300 - 400 的和
sum = 0
for i in range(300, 401):sum += i
print(sum)
# 3. 求 1 - 1000 的和
sum = 0
for i in range(1, 1001):sum += i
print(sum)可以發現,這幾組代碼基本是相似的,只有一點點差異,可以把重復代碼提取出來,做成一個函數
1.1、語法格式
定義函數:
def 函數名(形參列表):函數體return 返回值調用函數:
函數名(實參列表)函數定義并不會執行函數體內容, 必須要調用才會執行。調用幾次就會執行幾次。函數必須先定義,再使用。Python要求函數定義必須寫在前面,函數調用寫在后面。例如:
# 定義函數
def calcSum(beg, end):sum = 0for i in range(beg, end + 1):sum += iprint(sum)
# 調用函數
calcSum(1, 100)
calcSum(300, 400)
calcSum(1, 1000)一個函數可以有一個形參, 也可以有多個形參, 也可以沒有形參。一個函數的形參有幾個, 那么傳遞實參的時候也得傳幾個。保證個數要匹配。
和 C++ / Java 不同,Python 是動態類型的編程語言,函數的形參不必指定參數類型。換句話說, 一個函數可以支持多種不同類型的參數。例如:
def test(a):print(a)
test(10)
test('hello')
test(True)結果為:
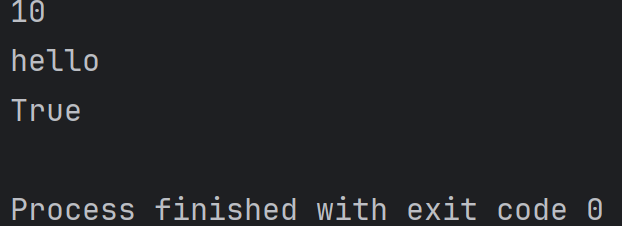
1.2、函數返回值
函數的參數可以視為是函數的 "輸入", 則函數的返回值, 就可以視為是函數的 "輸出" 。
例如:我們可以將之前的加法函數寫為
def calcSum(beg, end):sum = 0for i in range(beg, end + 1):sum += ireturn sum
result = calcSum(1, 100)
print(result)這個代碼與之前的代碼的區別就在于,前者直接在函數內部進行了打印,后者則使用return語句把結果返回給函數調用者,再由調用者負責打印。
我們一般傾向于第二種寫法,因為實際開發中我們的一個通常的編程原則是 "邏輯和用戶交互分離"。?而第一種寫法的函數中,既包含了計算邏輯,又包含了和用戶交互(打印到控制臺上),這種寫法是不太好的,如果后續我們需要的是把計算結果保存到文件中,或者通過網絡發送,或者展示到圖形化界面里,那么第一種寫法的函數,就難以勝任了。而第二種寫法則專注于做計算邏輯,不負責和用戶交互,那么就很容易把這個邏輯與其他代碼搭配,來實現不同的效果。簡單來說就是:一個函數只做一件事。
一個函數是可以一次返回多個返回值的,使用,來分割多個返回值。例如:
def getPoint():x = 10y = 20return x, y
a, b = getPoint()
print(a,b)如果只想關注其中的部分返回值,可以使用 _ 來忽略不想要的返回值。例如:
def getPoint():x = 10y = 20return x, y
_, b = getPoint()
print(b)注:Python中的一個函數可以返回多個返回值,這一點和C++與JAVA不同。?
1.3、變量作用域
觀察以下代碼:
def getPoint():x = 10y = 20return x, y
x, y = getPoint()
print(x,y)在這個代碼中, 函數內部存在 x, y, 函數外部也有 x, y。但是這兩組 x, y 不是相同的變量, 而只是恰好有一樣的名字。
在函數 getPoint() 內部定義的 x, y 只是在函數內部生效。一旦出了函數的范圍, 這兩個變量就不再生效了。例如:像下面這樣寫就會報錯
def getPoint():x = 10y = 20return x, y
getPoint()
print(x, y)在不同的作用域中, 允許存在同名的變量,例如:
x = 20
def test():x = 10print(f'函數內部 x = {x}')
test()
print(f'函數外部 x = {x}')?雖然名字相同,實際上是不同的變量。結果為:

注意:在函數內部的變量,也稱為 "局部變量" 。不在任何函數內部的變量,也稱為 "全局變量"。
全局變量是在整個程序中都有效的,局部變量只是在函數內部有效。
如果函數內部嘗試訪問的變量在局部不存在,就會嘗試去全局作用域中查找。例如:
x = 20
def test():print(f'x = {x}')
test()如果是想在函數內部,修改全局變量的值,需要使用 global 關鍵字聲明。例如:
x = 20
def test():global xx = 10print(f'函數內部 x = {x}')
test()
print(f'函數外部 x = {x}')如果此處沒有 global ,則函數內部的 x = 10 就會被視為是創建一個局部變量 x,這樣就和全局變量 x 不相關了。
if / while / for 等語句塊不會影響到變量作用域。換而言之,在 if / while / for 中定義的變量,在語句外面也可以正常使用。例如:
for i in range(1, 10):print(f'函數內部 i = {i}')
print(f'函數外部 i = {i}')1.4、執行過程
調用函數才會執行函數體代碼。不調用則不會執行。函數體執行結束(或者遇到 return 語句)。則回到函數調用位置,繼續往下執行。例如:
def test():print("執行函數內部代碼")print("執行函數內部代碼")print("執行函數內部代碼")
print("1111")
test()
print("2222")
test()
print("3333")上面的代碼的執行過程還可以使用 PyCharm 自帶的調試器來觀察:
1、點擊行號右側的空白, 可以在代碼中插入斷點。
2、右鍵,Debug,可以按照調試模式執行代碼,每次執行到斷點,程序都會暫停下來。
3、使用 Step Into (F7) 功能可以逐行執行代碼。
1.5、鏈式調用
把一個函數的返回值,作為另一個函數的參數,這種操作稱為鏈式調用。鏈式調用中,先執行里面的函數,再執行外面的函數。例如:
# 判定是否是奇數
def isOdd(num):if num % 2 == 0:return Falseelse:return True
print(isOdd(10))1.6、嵌套調用
函數內部還可以調用其他的函數,這個動作稱為 "嵌套調用"。一個函數里面可以嵌套調用任意多個函數。例如:
def test():print("執行函數內部代碼")print("執行函數內部代碼")print("執行函數內部代碼")test 函數內部調用了 print 函數,這里就屬于嵌套調用。
函數嵌套的過程是非常靈活的,例如:
def a():print("函數 a")
def b():print("函數 b")a()
def c():print("函數 c")b()
def d():print("函數 d")c()
d()如果把代碼稍微調整,打印結果則可能發生很大變化,例如:
def a():print("函數 a")
def b():a()print("函數 b")
def c():b()print("函數 c")
def d():c()print("函數 d")
d()函數之間的調用關系,在 Python 中會使用一個特定的數據結構來表示,稱為函數調用棧。每次函數調用,都會在調用棧里新增一個元素,稱為棧幀。可以通過 PyCharm 調試器看到函數調用棧和棧幀。在調試狀態下,PyCharm 左下角一般就會顯示出函數調用棧。例如:
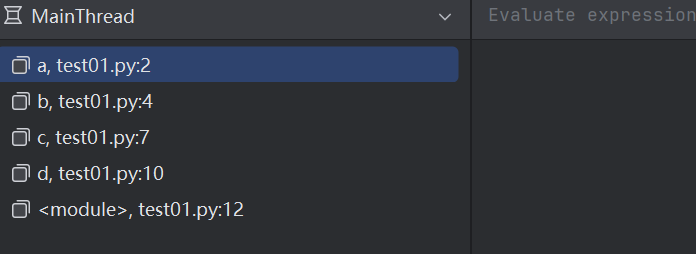
每個函數的局部變量,都包含在自己的棧幀中。調用函數則生成對應的棧幀,函數結束,則對應的棧幀消滅,里面的局部變量也就沒了。例如:
def a():num1 = 10print("函數 a")
def b():num2 = 20a()print("函數 b")
def c():num3 = 30b()print("函數 c")
def d():num4 = 40c()print("函數 d")
d()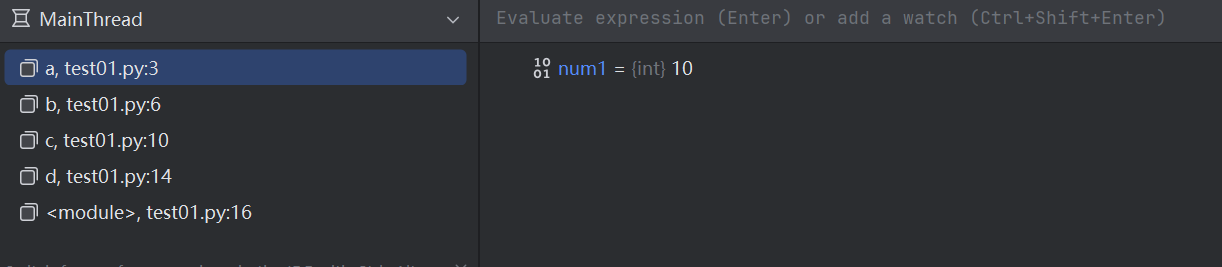
選擇不同的棧幀,就可以看到各自棧幀中的局部變量。
1.7、函數遞歸
遞歸是嵌套調用中的一種特殊情況,即一個函數嵌套調用自己。例如:遞歸計算 5!
def factor(n):if n == 1:return 1return n * factor(n - 1)
result = factor(5)
print(result)上述代碼中,就屬于典型的遞歸操作。在 factor 函數內部,又調用了 factor 自身。
注意:遞歸代碼務必要保證存在遞歸結束條件,比如 if n == 1 就是結束條件,當 n 為 1 的時候, 遞歸就結束了。每次遞歸的時候,要保證函數的實參是逐漸逼近結束條件的。
如果上述條件不能滿足,就會出現 "無限遞歸" 。這是一種典型的代碼錯誤。例如:
def factor(n):return n * factor(n - 1)
result = factor(5)
print(result)結果為:

如前面所描述, 函數調用時會在函數調用棧中記錄每一層函數調用的信息,但是函數調用棧的空間不是無限大的,如果調用層數太多, 就會超出棧的最大范圍, 導致出現問題。
遞歸的優點:遞歸類似于 "數學歸納法" ,明確初始條件和遞推公式,就可以解決一系列的問題,遞歸代碼往往代碼量非常少。
遞歸的缺點:遞歸代碼往往難以理解,很容易超出掌控范圍。遞歸代碼容易出現棧溢出的情況。遞歸代碼往往可以轉換成等價的循環代碼。并且通常來說循環版本的代碼執行效率要略高于遞歸版 本。
1.8、參數默認值
Python 中的函數, 可以給形參指定默認值,帶有默認值的參數, 可以在調用的時候不傳參。例如:
def add(x, y, debug=False):if debug:print(f'調試信息: x={x}, y={y}')return x + y
print(add(10, 20))
print(add(10, 20, True))此處 debug=False 即為參數默認值。當我們不指定第三個參數的時候,默認debug 的取值即為 False。
帶有默認值的參數需要放到沒有默認值的參數的后面。如果不這樣做就會報錯,例如:
def add(x, debug=False, y):if debug:print(f'調試信息: x={x}, y={y}')return x + y
print(add(10, 20))結果為:

如果有多個帶有默認參數的形參,也是要放在后面的。?
?1.9、關鍵字參數
在調用函數的時候,需要給函數指定實參。一般默認情況下是按照形參的順序,來依次傳遞實參的
但是我們也可以通過關鍵字參數, 來調整這里的傳參順序, 顯式指定當前實參傳遞給哪個形參。
例如:
def test(x, y):print(f'x = {x}')print(f'y = {y}')
test(x=10, y=20)
test(y=100, x=200)形如上述 test(x=10, y=20) 這樣的操作,即為關鍵字參數。
使用關鍵字參數能非常明顯的告訴讀代碼的人參數要傳遞給誰。另外這種寫法可以無視形參和實參的順序。
2、列表
編程中, 經常需要使用變量, 來保存或表示數據。如果代碼中需要表示的數據個數比較少, 我們直接創建多個變量即可。但是有的時候, 代碼中需要表示的數據特別多, 甚至也不知道要表示多少個數據。這個時候, 就需要用到列表。
元組和列表相比, 是非常相似的, 只是列表中放哪些元素可以修改調整, 元組中放的元素是創建元組的時候就設定好的, 不能修改調整。
2.1、創建列表
創建列表主要有兩種方式。alist = [ ] 和alist = list() ,其中[ ] 表示一個空的列表。例如:
alist = [ ] #使用列表字面值來創建列表
blist = list() #使用list()函數來創建列表
print(type(alist))
print(type(blist))注:列表的類型為list。?
如果需要往里面設置初始值,可以直接寫在 [ ] 當中。可以直接使用 print 來打印 list 中的元素內容
alist = [1, 2, 3, 4]
print(alist)列表中存放的元素允許是不同的類型,這一點和 C++ Java 差別較大。例如:
alist = [1, 'hello', True]
print(alist)注:列表內還可以放列表類型的元素。?
注:因為 list 本身是 Python 中的內建函數, 不宜再使用 list 作為變量名, 因此命名為alist。
2.2、下標訪問
可以通過下標訪問操作符 [ ] 來獲取到列表中的任意元素。我們把 [ ] 中填寫的數字, 稱為下標或者索引。例如:
alist = [1, 2, 3, 4]
print(alist[2])注意:下標是從 0 開始計數的, 因此下標為 2 , 則對應著 3 這個元素。
通過下標不光能讀取元素內容, 還能修改元素的值,如果下標超出列表的有效范圍, 會拋出異常。
alist = [1, 2, 3, 4]
print(alist[100])結果為:
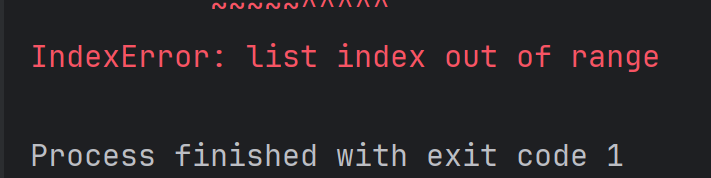
因為下標是從 0 開始的, 因此下標的有效范圍是 [0, 列表長度 - 1]。使用 len函數可以獲取列表的元素個數。例如:
alist = [1, 2, 3, 4]
print(len(alist))下標可以取負數,表示 "倒數第幾個元素"。
alist = [1, 2, 3, 4]
print(alist[3])
print(alist[-1])alist[-1] 相當于alist[len(alist) - 1]。
2.3、切片操作
通過下標操作是一次取出里面第一個元素。通過切片, 則是一次取出一組連續的元素, 相當于得到一個子列表。列表的切片操作是一個比較高效的操作,進行切片時,只是取出原有列表的一部分,并不涉及到數據的拷貝。
1、使用 [ : ] 的方式進行切片操作。例如:
alist = [1, 2, 3, 4]
print(alist[1:3])結果為:
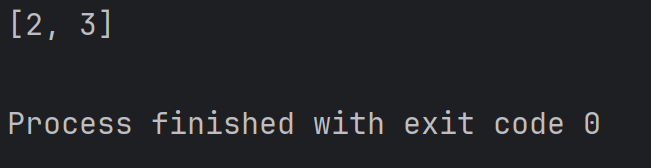
其中,alist[1:3] 中的 1:3 表示的是 [1, 3) 這樣的由下標構成的前閉后開區間。也就是從下標為 1 的元素開始(2), 到下標為 3 的元素結束(4), 但是不包含下標為 3 的元素。
2、切片操作中可以省略前后邊界。例如:
alist = [1, 2, 3, 4]
print(alist[1:])
print(alist[:-1])
print(alist[:]) 結果為:
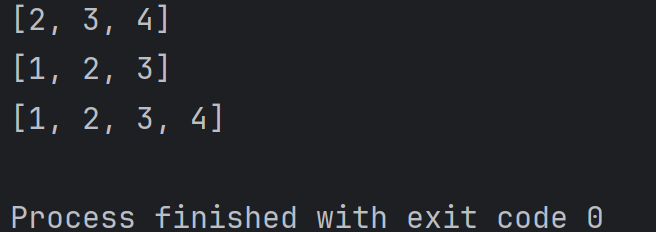
3、切片操作還可以指定 "步長" , 也就是 "每訪問一個元素后, 下標自增幾步"。例如:
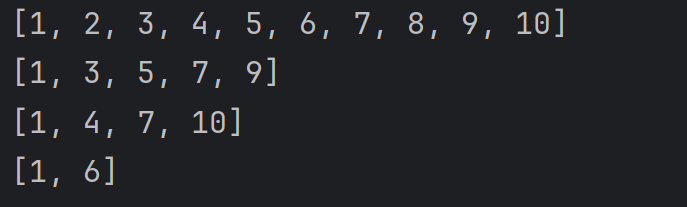
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::1])
print(alist[::2])
print(alist[::3])
print(alist[::5])結果為:
4、切片操作指定的步長還可以是負數, 此時是從后往前進行取元素。表示 "每訪問一個元素之后, 下標自減幾步"。例如:
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::-1])
print(alist[::-2])
print(alist[::-3])
print(alist[::-5])結果為:

注:如果切片中填寫的數字越界了, 不會出現異常,只會盡可能的把滿足條件的元素給獲取到。例如:
alist = [1, 2, 3, 4]
print(alist[100:200])結果為:
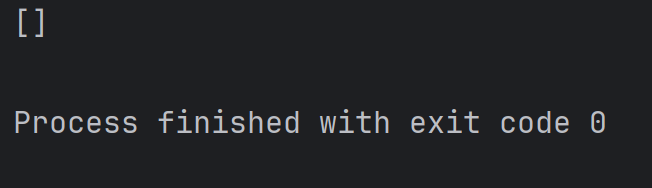
2.4、遍歷列表元素
"遍歷" 指的是把元素一個一個的取出來。
1、最簡單的辦法就是使用 for 循環,例如:
alist = [1, 2, 3, 4]
for elem in alist:print(elem)也可以使用 for 按照范圍生成下標, 按下標訪問,例如:
alist = [1, 2, 3, 4]
for i in range(0, len(alist)):print(alist[i])2、還可以使用 while 循環,手動控制下標的變化,例如:
alist = [1, 2, 3, 4]
i = 0
while i < len(alist):print(alist[i])i += 12.5、新增元素
使用 append 方法, 向列表末尾插入一個元素(尾插)。例如:
alist = [1, 2, 3, 4]
alist.append('hello')
print(alist)使用 insert 方法, 向任意位置插入一個元素,insert 第一個參數表示要插入元素的下標。例如:
alist = [1, 2, 3, 4]
alist.insert(1, 'hello')
print(alist)另外,如果插入的下標越界的話,不會出現異常,而是把要插入的元素進行尾插,例如:
alist = [1, 2, 3, 4]
alist.insert(100, 'hello')
print(alist)注:方法其實就是函數,只不過函數是獨立存在的,而方法往往要依附于某個 "對象"。像上述代碼 alist.append , append 就是依附于 alist,而不是作為一個獨立的函數,相當于是 "針對 alist 這個列表, 進行尾插操作"。type,print,input等都是獨立的函數,不用搭配其他的東西就能使用。
2.6、查找元素
使用 in 操作符, 判定元素是否在列表中存在,返回值是布爾類型,例如:
alist = [1, 2, 3, 4]
print(2 in alist)
print(10 in alist)
print(2 not in alist) #邏輯取反,結果為False使用 index 方法, 查找列表中的元素,返回值是一個整數,這個整數也就是查找到的元素的下標,如果元素不存在, 則會拋出異常,例如:
alist = [1, 2, 3, 4]
print(alist.index(2))
print(alist.index(10)) #會發生異常2.7、刪除元素
使用 pop 方法刪除最末尾元素,例如:
alist = [1, 2, 3, 4]
alist.pop()
print(alist)pop 也能按照下標來刪除元素,例如:
alist = [1, 2, 3, 4]
alist.pop(2)
print(alist)使用 remove 方法, 按照元素值刪除元素。例如:
alist = [1, 2, 3, 4]
alist.remove(2)
print(alist)2.8、連接列表
使用 + 能夠把兩個列表拼接在一起。此處的 + 結果會生成一個新的列表,而不會影響到舊列表的內容。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
print(alist + blist)使用 extend 方法, 相當于把一個列表拼接到另一個列表的后面。a.extend(b) , 是把 b 中的內容拼接到 a 的末尾,不會修改 b, 但是會修改 a。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
alist.extend(blist)
print(alist)
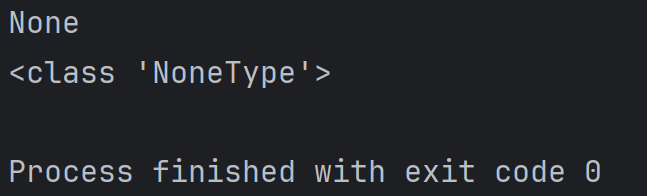
print(blist)注意:None在Python中是一個特殊的變量值,表示啥都沒有。拿一個變量接收沒有返回值的方法的返回值,這個變量的結果就為None,類型為Nonetype。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
a=alist.extend(blist)
print(a)
print(type(a))結果為:
3、元組
元組的功能和列表相比, 基本是一致的,元組使用 ( ) 來表示。元組的類型為tuple,例如:
atuple = ( )
atuple = tuple()元組不能修改里面的元素, 列表則可以修改里面的元素。
因此,像讀操作,比如訪問下標,切片,遍歷,in,index,+ 等,元組也是一樣支持的。但是,像寫操作,比如修改元素,新增元素,刪除元素,extend 等,元組則不能支持。
另外, 元組在 Python 中很多時候是默認的集合類型。例如, 當一個函數返回多個值的時候。
def getPoint():return 10, 20
result = getPoint()
print(type(result))結果為:
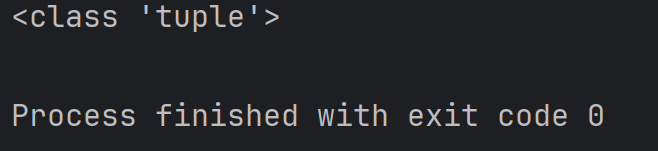
此處的 result 的類型,其實就是元組。
問題來了, 既然已經有了列表, 為啥還需要有元組?
元組相比于列表來說, 優勢有兩方面:
1、比如有一個列表, 現在需要調用一個函數進行一些處理,但是你有不是特別確認這個函數是否會修改你列表的數據,那么這時候傳一個元組就安全很多。
2、我們馬上要說的字典, 是一個鍵值對結構,要求字典的鍵必須是 "可hash對象" (字典本質上也 是一個hash表),而一個可hash對象的前提就是不可變,因此元組可以作為字典的鍵, 但是列表不行。
4、字典
字典是一種存儲鍵值對的結構。把鍵(key)和值(value) 進行一個一對一的映射,這就是鍵值對,然后就可以根據鍵,快速找到值。
4.1、創建字典
創建一個空的字典,使用 { } 表示字典,字典的類型為dict,例如:
a = { }
b = dict()
print(type(a))
print(type(b))也可以在創建的同時指定初始值,鍵值對之間使用,分割,鍵和值之間使用 : 分割。冒號后面推薦加一個空格。例如:
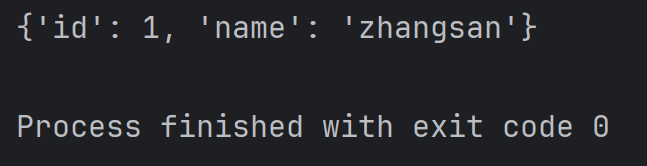
student = { 'id': 1, 'name': 'zhangsan' }
print(student)結果為:
注意:字典的key是不能重復的。
為了代碼更規范美觀, 在創建字典的時候往往會把多個鍵值對, 分成多行來書寫。例如:
student = {'id': 1,'name': 'zhangsan'
}最后一個鍵值對,后面可以寫,也可以不寫,例如:
student = {'id': 1,'name': 'zhangsan',
}4.2、查找key
使用 in 可以判定 key 是否在字典中存在,返回布爾值,但是不能使用in判斷value是否在字典中。例如:
student = {'id': 1,'name': 'zhangsan'
}
print('id' in student)
print('score' in student)使用 [ ] 通過類似于取下標的方式,獲取到元素的值,只不過此處的 "下標" 是 key。(可能是整數, 也可能是字符串等其他類型)。
student = {'id': 1,'name': 'zhangsan',
}
print(student['id'])
print(student['name'])如果 key 在字典中不存在,則會拋出異常。例如:
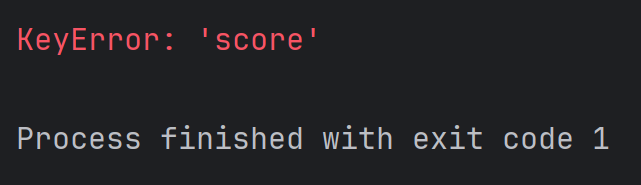
student = {'id': 1,'name': 'zhangsan',
}
print(student['score'])結果為:
4.3、新增和修改元素
使用 [ ] 可以根據 key 來新增/修改 value。
如果 key 不存在, 對取下標操作賦值, 即為新增鍵值對,例如:
student = {'id': 1,'name': 'zhangsan',
}
student['score'] = 90
print(student)如果 key 已經存在, 對取下標操作賦值, 即為修改鍵值對的值。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
student['score'] = 90
print(student)4.4、刪除元素
使用 pop 方法根據 key 刪除對應的鍵值對。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
student.pop('score')
print(student)4.5、遍歷字典元素
直接使用 for 循環能夠獲取到字典中的所有的 key, 進一步的就可以取出每個值了。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
for key in student:print(key, student[key])?注:在C++和JAVA中,哈希表里面的鍵值對的存儲是無序的,Python中做了特殊處理,能夠保證遍歷出來的順序,就是和插入的順序一致的。Python中的字典不是一個單純的哈希表。
使用 keys 方法可以獲取到字典中的所有的 key,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.keys())結果為:
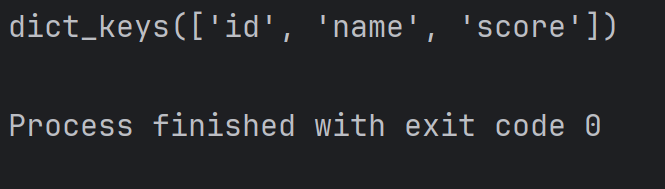
注:此處 dict_keys 是一個特殊的類型,專門用來表示字典的所有 key,這是一個自定義類型,返回的結果看起來像列表,又不完全是,但使用的時候也可以把他當作一個列表來使用。
使用 values 方法可以獲取到字典中的所有 value,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.values())結果為:
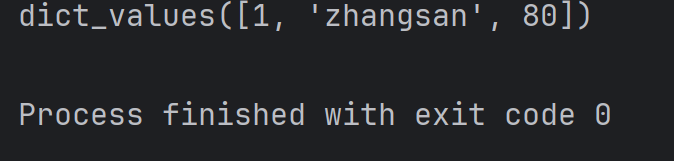
注:此處 dict_values 也是一個特殊的類型, 和 dict_keys 類似。
使用 items 方法可以獲取到字典中所有的鍵值對。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.items())結果為:

注:此處 dict_items 也是一個特殊的類型,首先是一個列表一樣的結構,里面每個元素又是一個元組,元組里面包含了鍵和值。
我們還可以這樣遍歷字典元素,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
for key,value in student.items():print(key,value)4.6、合法的key類型
不是所有的類型都可以作為字典的 key。字典本質上是一個 哈希表,哈希表的 key 要求是 "可哈希的",也就是可以計算出一個哈希值。
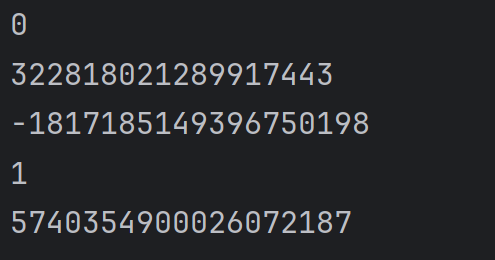
可以使用 hash 函數計算某個對象的哈希值。但凡能夠計算出哈希值的類型,都可以作為字典的 key。例如:
print(hash(0))
print(hash(3.14))
print(hash('hello'))
print(hash(True))
print(hash(()))結果為:
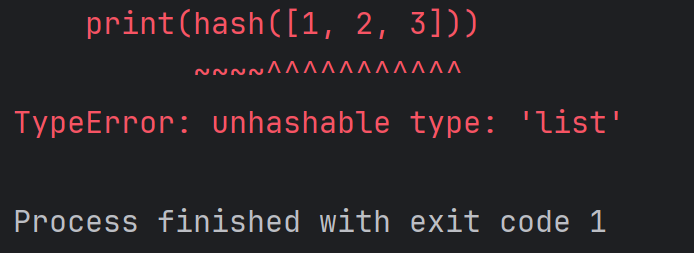
注意:列表無法計算哈希值,字典也無法計算哈希值,例如:
print(hash([1, 2, 3]))結果為:
再比如:
print(hash({ 'id': 1 }))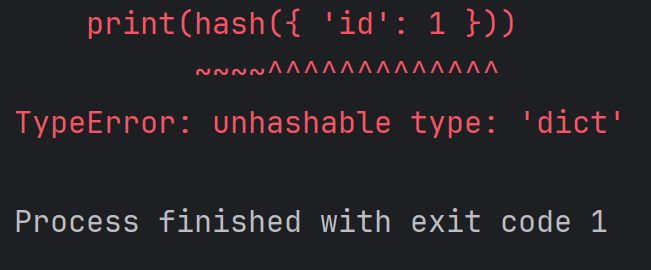
注:不可變的對象,一般就是可哈希的;可變的對象一般就是不可哈希的。
)


![LeetCode[232]用棧實現隊列](http://pic.xiahunao.cn/LeetCode[232]用棧實現隊列)



)











