在人工智能領域,生成模型的發展一直是研究熱點。從最早的自編碼器到如今的多模態擴散模型,這一技術路線不斷突破,為創意內容生成、數據增強和表示學習等領域帶來革命性變化。本文將詳細介紹幾種關鍵生成模型的技術原理和演進路徑,展示從單模態到多模態的技術發展歷程。
生成模型簡介
1. GAN(生成對抗網絡,2014年6月)
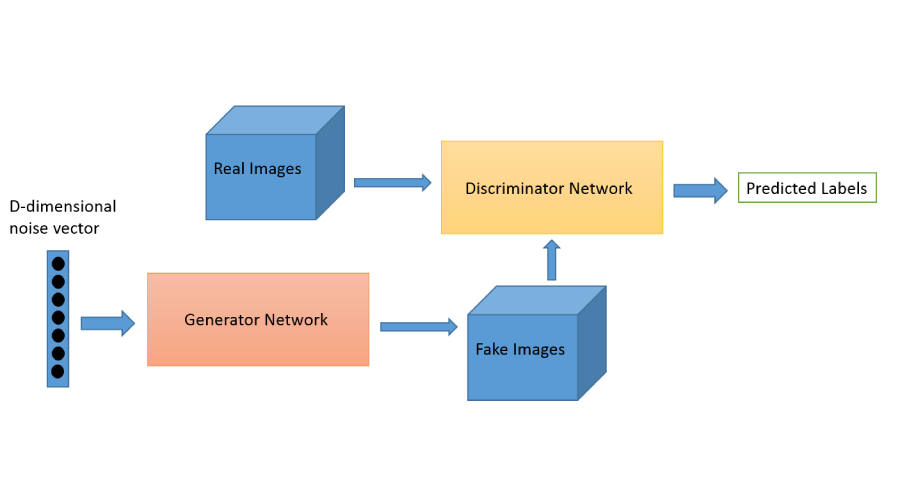
背景
由Ian Goodfellow等人提出,旨在通過對抗訓練生成逼真數據。其核心思想是通過生成器與判別器的博弈,使生成器逐漸逼近真實數據分布。
原理
- 生成器(Generator):將隨機噪聲 z z z映射到數據空間,生成樣本 G ( z ) G(z) G(z)。
- 判別器(Discriminator):判斷輸入樣本是否來自真實數據分布,輸出概率 D ( x ) D(x) D(x)。
- 對抗目標:生成器最大化判別器的判斷錯誤,判別器最小化分類誤差:
min ? G max ? D E x ~ p d a t a ( x ) [ log ? D ( x ) ] + E z ~ p z ( z ) [ log ? ( 1 ? D ( G ( z ) ) ) ] \min_G \max_D \mathbb{E}_{x\sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z\sim p_z(z)}[\log(1 - D(G(z)))] Gmin?Dmax?Ex~pdata?(x)?[logD(x)]+Ez~pz?(z)?[log(1?D(G(z)))]
網絡結構
- 生成器:多層全連接或卷積網絡,輸出與真實數據相同維度的樣本。
- 判別器:類似分類器,通常為全連接或卷積網絡,輸出二分類概率。
優缺點
- 優點:
- 生成樣本質量高,支持多樣化生成(如高分辨率圖像)。
- 支持條件生成(如CGAN)。
- 缺點:
- 訓練不穩定(模式崩潰、梯度消失)。
- 難以評估收斂性,需平衡生成器與判別器的訓練速度。
應用場景
- 圖像生成(如DeepFakes)、風格遷移(如CycleGAN)、超分辨率重建。
2. AE(自編碼器,1986年)
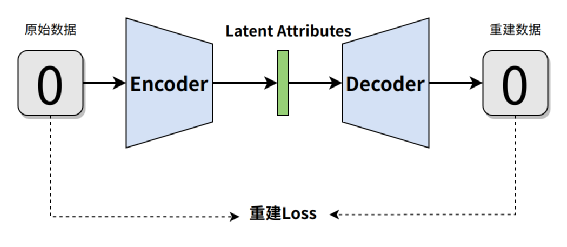
背景
經典無監督學習模型,由編碼器和解碼器組成,目標是學習數據的緊湊表示并重構原始數據。
原理
- 編碼器:將輸入 x x x壓縮為低維潛在向量 z = E ( x ) z = E(x) z=E(x)。
- 解碼器:從 z z z重構 x ′ x' x′,最小化重構誤差:
L = ∣ ∣ x ? D ( E ( x ) ) ∣ ∣ 2 \mathcal{L} = ||x - D(E(x))||^2 L=∣∣x?D(E(x))∣∣2
網絡結構
- 編碼器:全連接或卷積層,逐步降低維度。
- 解碼器:反卷積或全連接層,恢復原始數據維度。
優缺點
- 優點:
- 簡單高效,適合降維和去噪。
- 可用于特征提取(如圖像壓縮)。
- 缺點:
- 潛在空間無明確結構,生成樣本模糊。
- 不支持直接采樣生成新樣本。
應用場景
- 數據壓縮(如圖像壓縮)、特征提取、去噪(如圖像修復)。
3. VAE(變分自編碼器,2013年12月)
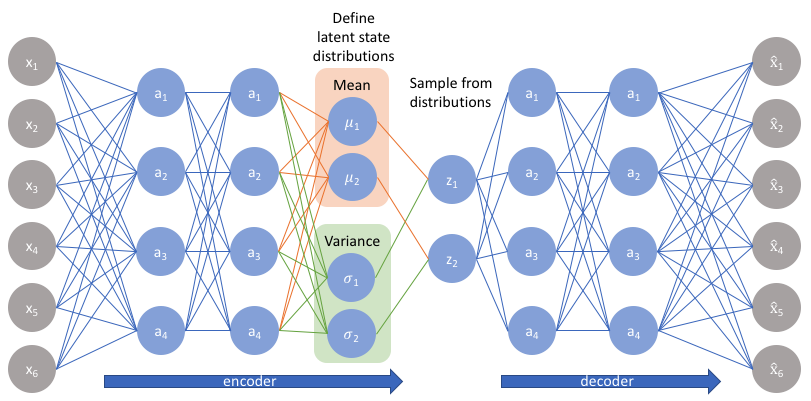
背景
基于貝葉斯概率框架,通過變分推斷學習潛在變量分布,解決AE的潛在空間不連續問題。
原理
- 編碼器:輸出潛在變量分布參數 μ , σ \mu, \sigma μ,σ,即 q ? ( z ∣ x ) q_\phi(z|x) q??(z∣x)。
- 解碼器:從 z ~ N ( μ , σ 2 ) z \sim \mathcal{N}(\mu, \sigma^2) z~N(μ,σ2)生成樣本。
- 損失函數:重構損失(Reconstruction Loss) + KL散度(正則化):
L = E q ? ( z ∣ x ) [ log ? p θ ( x ∣ z ) ] ? KL ( q ? ( z ∣ x ) ∣ ∣ p ( z ) ) \mathcal{L} = \mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)] - \text{KL}(q_\phi(z|x) || p(z)) L=Eq??(z∣x)?[logpθ?(x∣z)]?KL(q??(z∣x)∣∣p(z))
網絡結構
- 編碼器:輸出均值和方差的兩個向量。
- 重參數化技巧: z = μ + ? ? σ z = \mu + \epsilon \cdot \sigma z=μ+??σ, ? ~ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ?~N(0,I)。
優缺點
- 優點:
- 潛在空間連續且結構化,支持插值和采樣。
- 可解釋性強,適合生成多樣化樣本。
- 缺點:
- 生成樣本模糊(KL散度懲罰過強)。
- 重構質量可能下降(如圖像邊緣模糊)。
應用場景
- 圖像生成、語義嵌入、數據增強(如生成相似但不同的樣本)。
4. VQ-VAE(矢量量化變分自編碼器,2017年12月)
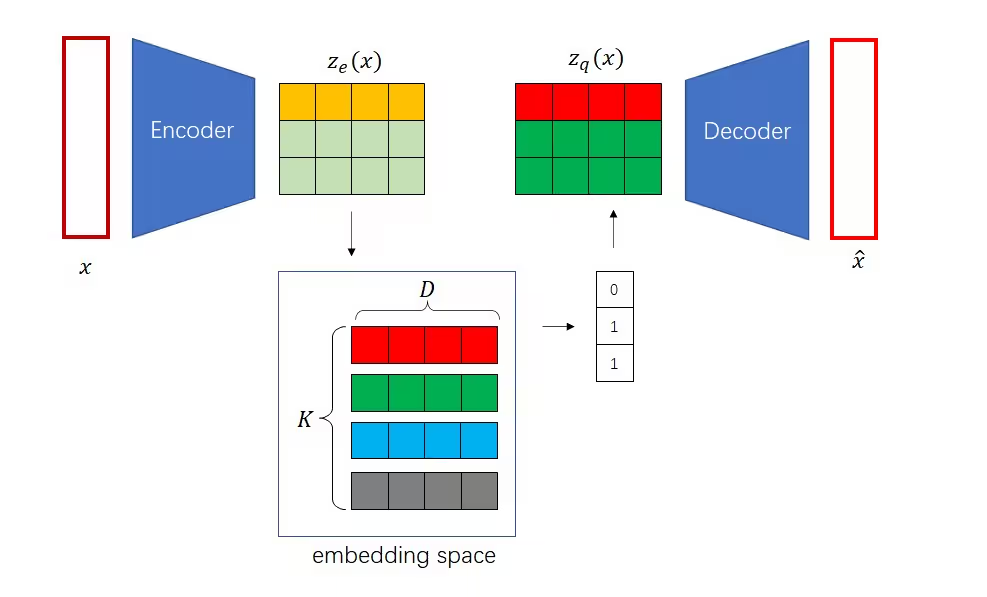
背景
為解決VAE生成模糊問題,引入離散潛在空間,結合自編碼器與矢量量化技術。
原理
- 編碼器:輸出連續潛在向量。
- 矢量量化層:將連續向量映射到最近鄰離散碼本向量 e k e_k ek?。
- 解碼器:從離散向量重構數據。
- 損失函數:重構損失 + 矢量量化誤差(編碼器與碼本的差異)。
網絡結構
- 碼本:預先定義的離散向量集合。
- 離散化步驟: z q = arg ? min ? e k ∣ ∣ z e ? e k ∣ ∣ 2 z_q = \arg\min_{e_k} ||z_e - e_k||^2 zq?=argminek??∣∣ze??ek?∣∣2。
優缺點
- 優點:
- 生成樣本清晰,避免后驗坍塌。
- 離散空間支持高效檢索(如文本生成)。
- 缺點:
- 離散化可能降低潛在空間的連續性。
- 訓練復雜度增加(需優化碼本)。
應用場景
- 圖像生成(如DALL·E)、音頻合成(如語音編碼)、文本生成(如離散化語言模型)。
5. Diffusion Model(擴散模型,2015年3月)

背景
受物理擴散過程啟發,通過逐步添加噪聲再逆向去噪生成數據。
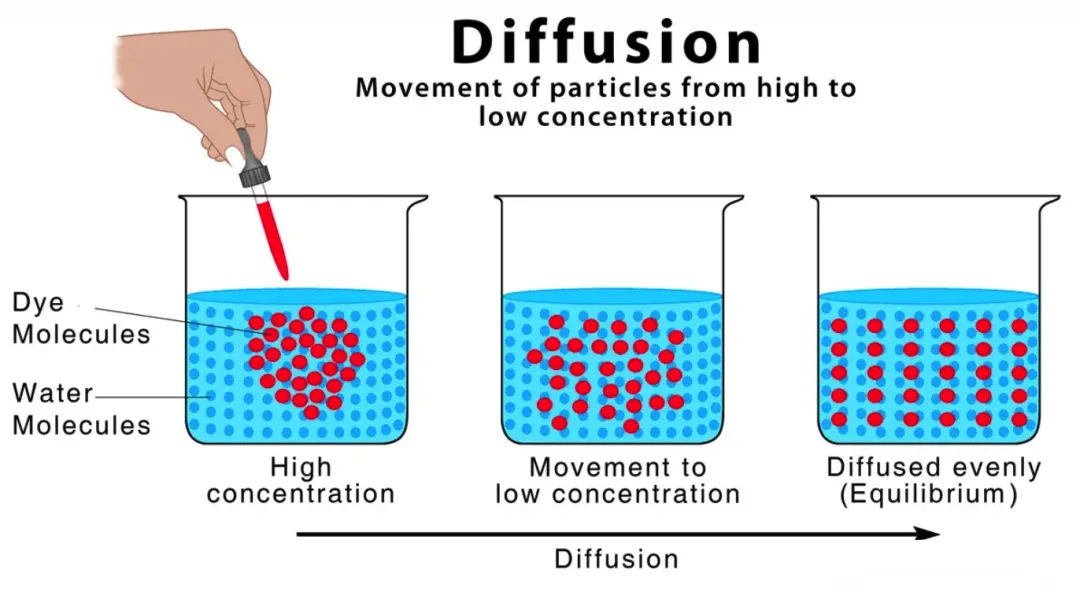
原理
- 正向擴散過程:
x t = 1 ? β t x t ? 1 + β t ? t ? 1 , ? t ? 1 ~ N ( 0 , I ) x_t = \sqrt{1-\beta_t}x_{t-1} + \sqrt{\beta_t}\epsilon_{t-1}, \quad \epsilon_{t-1} \sim \mathcal{N}(0,I) xt?=1?βt??xt?1?+βt???t?1?,?t?1?~N(0,I)
其中, β t \beta_t βt?為噪聲調度參數,逐步將數據 x 0 x_0 x0?變為噪聲 x T x_T xT?。 - 逆向生成過程:
學習模型 p θ ( x t ? 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ?(xt?1?∣xt?)從噪聲恢復數據。
數學基礎
- 正向過程:馬爾可夫鏈,每一步添加高斯噪聲。
- 逆向過程:通過深度網絡預測噪聲 ? t \epsilon_t ?t?,逐步去噪:
x t ? 1 = 1 α t ( x t ? 1 ? α t ? θ ( x t , t ) ) x_{t-1} = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \sqrt{1-\alpha_t}\epsilon_\theta(x_t,t)\right) xt?1?=αt??1?(xt??1?αt???θ?(xt?,t))
其中, α t = 1 ? β t \alpha_t = 1-\beta_t αt?=1?βt?。
網絡結構
- 去噪網絡:通常為U-Net,預測當前步的噪聲 ? t \epsilon_t ?t?。
- 時間嵌入:擴散步數 t t t作為輸入,指導去噪。
優缺點
- 優點:
- 生成質量高,支持條件生成(如文本到圖像)。
- 理論基礎扎實,避免模式崩潰。
- 缺點:
- 訓練與推理速度慢(需多步迭代,如1000步)。
- 計算資源需求高(內存和顯存占用大)。
應用場景
- 高分辨率圖像生成(如Stable Diffusion)、超分辨率、圖像修復。
6. DDPM(去噪擴散概率模型,2020年6月)
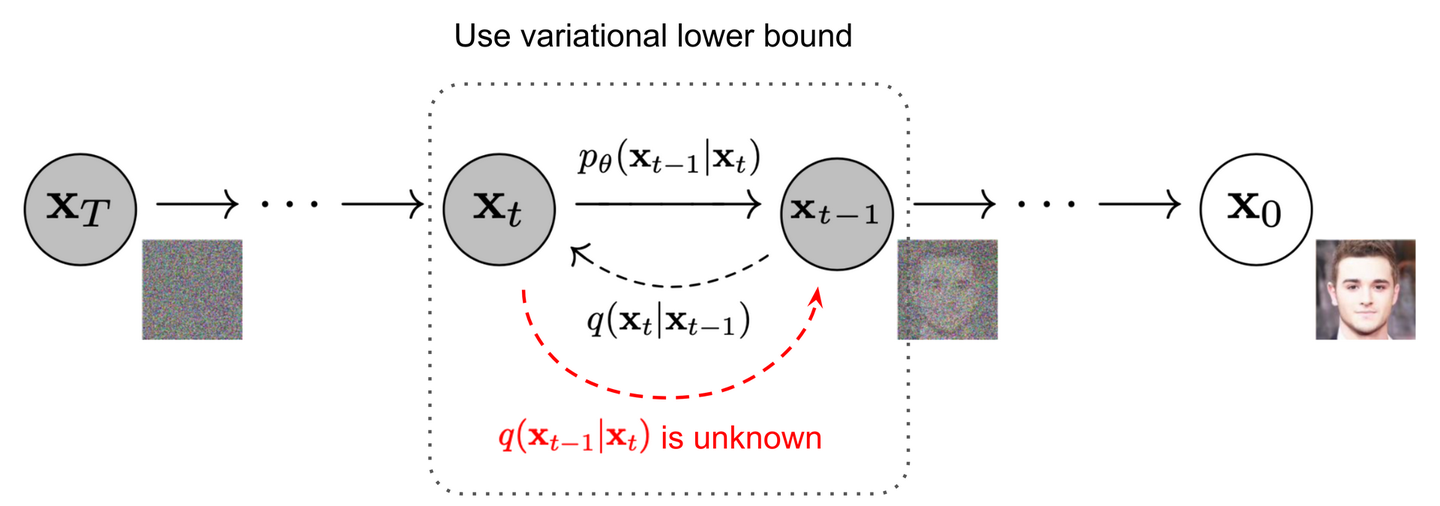
背景
Diffusion Model的里程碑實現,通過馬爾可夫鏈和噪聲調度參數優化訓練。
原理
- 噪聲預測:模型直接預測添加的噪聲 ? t \epsilon_t ?t?:
? θ ( x t , t ) ≈ ? \epsilon_\theta(x_t, t) \approx \epsilon ?θ?(xt?,t)≈? - 去噪公式:
x t ? 1 = 1 α t ( x t ? 1 ? α t ? θ ( x t , t ) ) x_{t-1} = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \sqrt{1-\alpha_t}\epsilon_\theta(x_t,t)\right) xt?1?=αt??1?(xt??1?αt???θ?(xt?,t))
網絡結構
- U-Net:編碼器-解碼器結構,處理多尺度特征。
- 時間嵌入:擴散步數 t t t經正弦嵌入后輸入網絡。
優缺點
- 優點:
- 理論嚴謹,支持靈活調度噪聲參數。
- 生成質量接近真實數據分布。
- 缺點:
- 采樣步驟多(通常需1000步),計算成本高。
- 需要大量訓練數據。
應用場景
- 圖像生成(如DDPM的變體)、文本到圖像(如DALLE-2)、視頻生成。
7. Diffusion Models Beat GANs(2021年5月)
背景
通過改進擴散模型架構(如引入注意力機制),在ImageNet等數據集上超越GAN的生成質量與多樣性。
關鍵改進
- 層次化擴散過程:分階段處理不同尺度特征。
- 條件生成:結合文本或標簽條件,增強可控性。
- 注意力機制:增強跨區域特征關聯(如Transformer模塊)。
原理
- 多尺度擴散:在不同分辨率下執行擴散過程,提升細節質量。
- 混合模型:結合擴散模型與GAN的判別器進行聯合訓練。
優缺點
- 優點:
- 生成多樣性與保真度并存,無模式崩潰。
- 支持復雜條件生成(如文本描述生成圖像)。
- 缺點:
- 計算資源需求高,訓練復雜度大。
- 需要大量標注數據。
應用場景
- 高質量圖像生成、風格遷移、藝術創作。
8. DALLE-2(2022年4月)
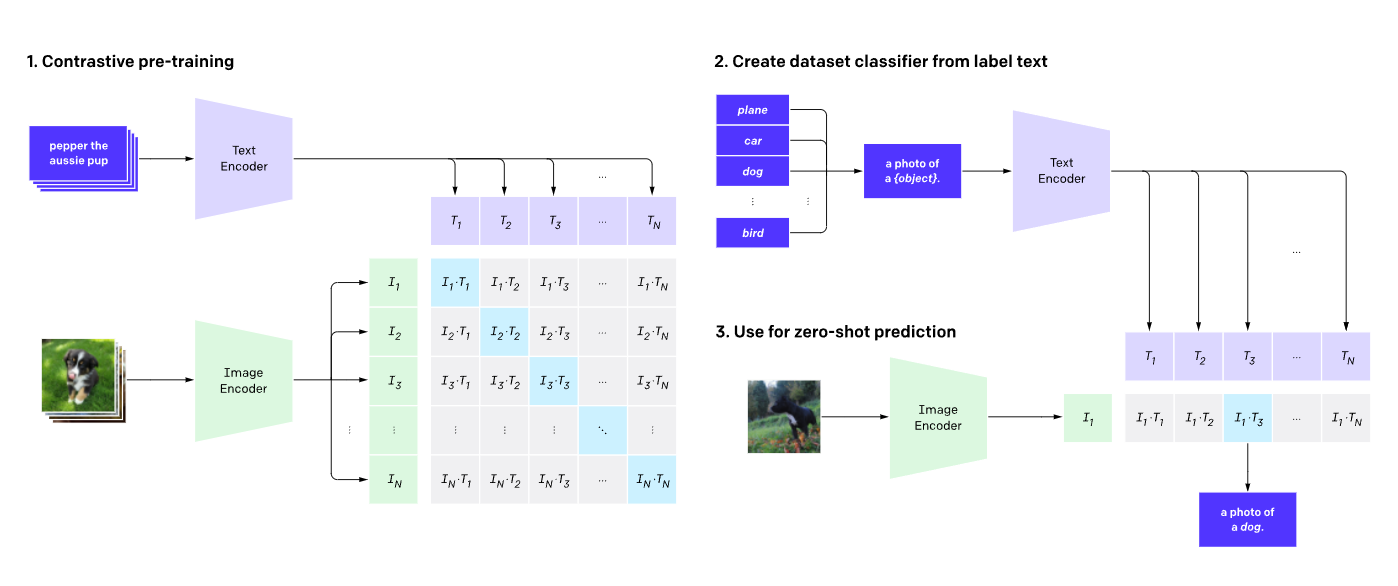
背景
結合文本到圖像生成與擴散模型,通過CLIP對齊文本與視覺特征。
原理
- 文本編碼器:將文本映射為CLIP的嵌入向量。
- 擴散解碼器:在潛在空間(如VQ-VAE的碼本)中執行擴散,逐步去噪生成圖像。
網絡結構
- 文本編碼器:基于Transformer的編碼器,輸出文本嵌入。
- 擴散模型:在潛在空間中執行,使用U-Net預測噪聲。
- CLIP對齊:通過對比學習對齊文本和圖像的嵌入空間。
優缺點
- 優點:
- 文本-圖像對齊度高,支持復雜描述(如“一只戴帽子的熊貓在跳舞”)。
- 生成多樣性與質量平衡。
- 缺點:
- 依賴預訓練CLIP模型,計算成本高。
- 需要大量文本-圖像配對數據。
應用場景
- 文本生成圖像(如MidJourney)、藝術創作、內容生成(如廣告設計)。
9. Latent Diffusion Model(潛在擴散模型,2022年7月)
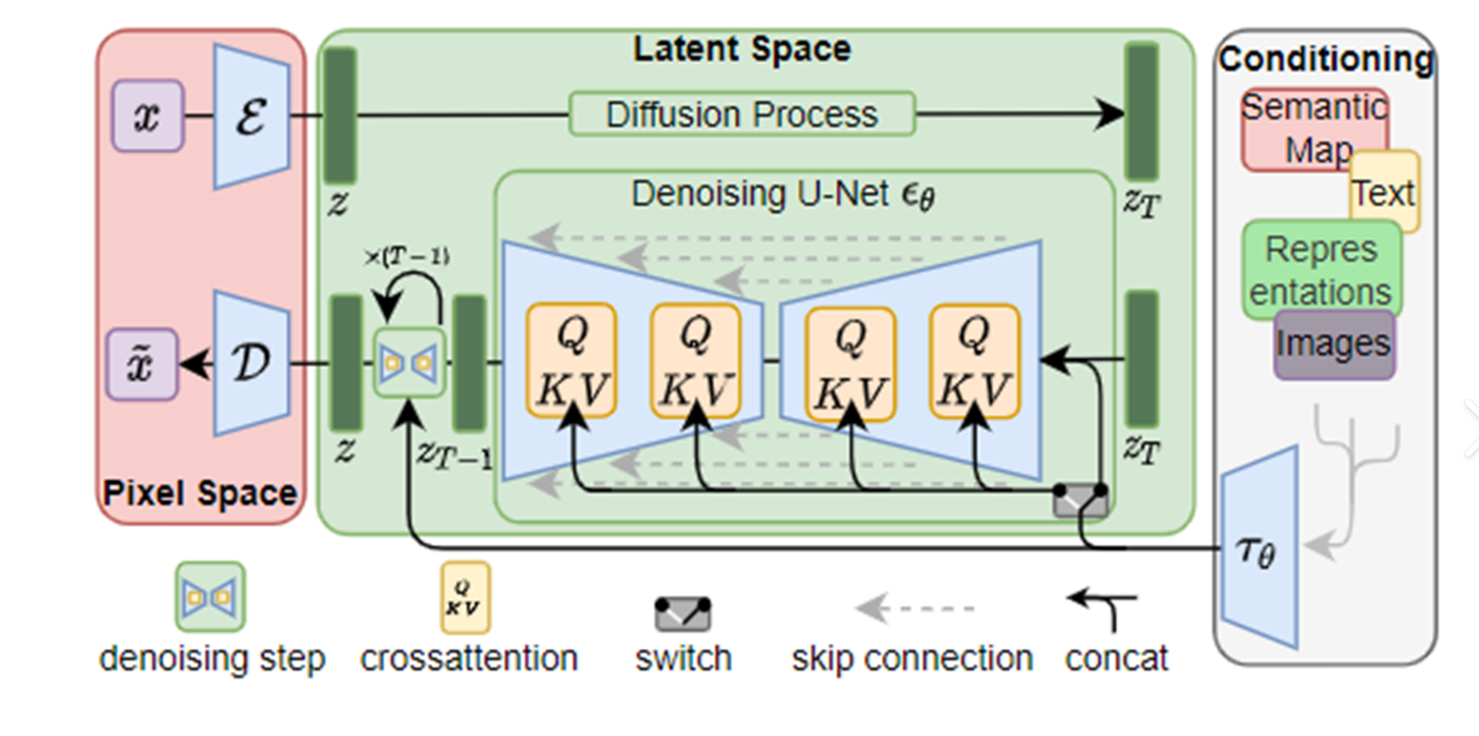
背景
在潛在空間(如VQ-VAE的離散碼本)中執行擴散過程,大幅減少計算量。
原理
- 潛在空間擴散:在低維潛在空間(如 z ∈ R d z \in \mathbb{R}^d z∈Rd)中進行擴散,而非像素空間。
- 解碼器:將潛在空間的生成結果映射回像素空間。
網絡結構
- 編碼器-解碼器:如VQ-VAE或AutoEncoder,將圖像壓縮到潛在空間。
- 擴散過程:在潛在空間中執行,使用U-Net預測噪聲。
優缺點
- 優點:
- 推理速度加快(維度降低,如從 256 × 256 256 \times 256 256×256像素到 32 × 32 32 \times 32 32×32潛在碼本)。
- 生成質量與原始模型相當。
- 缺點:
- 依賴潛在空間編碼器的質量。
- 需要額外訓練編碼器-解碼器。
應用場景
- 高效圖像生成(如Stable Diffusion)、編輯工具(如圖像修復)。
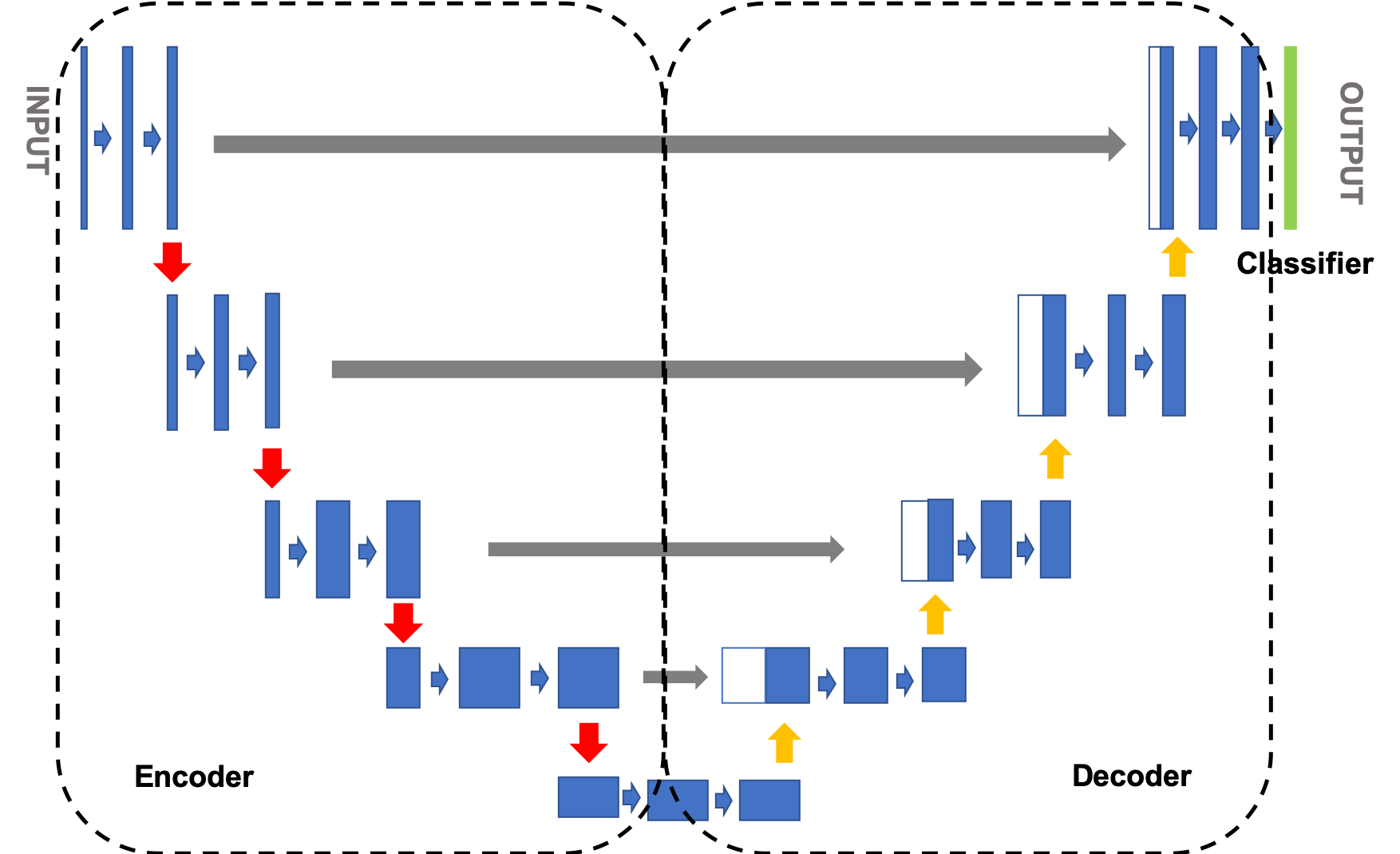
10. UNet(2015年)
背景
由Olaf Ronneberger提出,最初用于醫學圖像分割,現廣泛用于擴散模型的去噪網絡。
原理
- 編碼器(收縮路徑):卷積層提取特征,池化降低分辨率。
- 解碼器(擴張路徑):反卷積恢復分辨率,跳躍連接融合多尺度特征。
網絡結構
- 跳躍連接:編碼器層與解碼器對應層的特征拼接。
- 時間嵌入:擴散模型中需輸入當前步數 t t t,通過正弦嵌入擴展維度。
- 注意力機制:部分改進版UNet(如U-Net++)引入注意力模塊。
優缺點
- 優點:
- 多尺度特征融合,適配復雜任務(如醫學圖像的細節重建)。
- 模塊化設計,易于擴展。
- 缺點:
- 參數量較大,計算成本高。
- 需要大量標注數據訓練。
應用場景
- 醫學圖像分割(如腫瘤檢測)、擴散模型去噪(如DDPM、Stable Diffusion)、語義分割。
11. DDIM(去噪擴散隱式模型,2020年10月)
背景
由Jonathan Ho等人提出的擴散模型改進版本,通過設計非馬爾可夫鏈加速采樣過程,顯著提高擴散模型的推理效率。
原理
- 隱式采樣:打破馬爾可夫鏈約束,允許直接從 x t x_t xt?到 x t ? s x_{t-s} xt?s?的跳躍:
x t ? s = α t ? s ( x t ? 1 ? α t ? θ ( x t , t ) α t ) + 1 ? α t ? s ? θ ( x t , t ) x_{t-s} = \sqrt{\alpha_{t-s}}\left(\frac{x_t - \sqrt{1-\alpha_t}\epsilon_\theta(x_t,t)}{\sqrt{\alpha_t}}\right) + \sqrt{1-\alpha_{t-s}}\epsilon_\theta(x_t,t) xt?s?=αt?s??(αt??xt??1?αt???θ?(xt?,t)?)+1?αt?s???θ?(xt?,t) - 確定性推理:可選擇確定性路徑(無隨機性),實現可控生成:
x t ? 1 = α t ? 1 ( x t ? 1 ? α t ? θ ( x t , t ) α t ) + 1 ? α t ? 1 ? θ ( x t , t ) x_{t-1} = \sqrt{\alpha_{t-1}}\left(\frac{x_t - \sqrt{1-\alpha_t}\epsilon_\theta(x_t,t)}{\sqrt{\alpha_t}}\right) + \sqrt{1-\alpha_{t-1}}\epsilon_\theta(x_t,t) xt?1?=αt?1??(αt??xt??1?αt???θ?(xt?,t)?)+1?αt?1???θ?(xt?,t)
網絡結構
- 與DDPM相同,使用U-Net預測噪聲。
- 通過調度采樣步數,如從1000步減少到10-50步。
優缺點
- 優點:
- 大幅提高采樣速度(可達10-100倍)。
- 支持確定性采樣,便于插值和編輯。
- 缺點:
- 質量略低于完整步數的DDPM。
- 參數調整復雜,需平衡速度與質量。
應用場景
- 實時圖像生成、交互式編輯工具、快速原型設計。
12. Transformer-based Generative Models(基于Transformer的生成模型,2021年后)
背景
將Transformer架構應用于生成模型,如VQGAN+CLIP、Imagen等,結合自注意力機制的長距離依賴建模優勢。
原理
- 自回歸生成:類似GPT模型,逐元素生成序列。
- 擴散Transformer:將擴散模型的U-Net替換為Transformer架構。
- 雙向注意力:通過交叉注意力機制融合文本與圖像特征。
網絡結構
- Vision Transformer (ViT):將圖像分割為patch處理。
- 交叉注意力層:融合文本特征指導圖像生成。
- 位置編碼:維持序列的空間信息。
優缺點
- 優點:
- 長距離依賴建模能力強,適合復雜場景。
- 與大語言模型架構一致,便于多模態融合。
- 缺點:
- 計算復雜度高,尤其是自注意力機制( O ( n 2 ) O(n^2) O(n2))。
- 需要大量訓練數據和計算資源。
應用場景
- 高質量圖像生成(如Parti、Imagen)、視頻生成(如Make-A-Video)、多模態生成。
13. ControlNet(2023年2月)
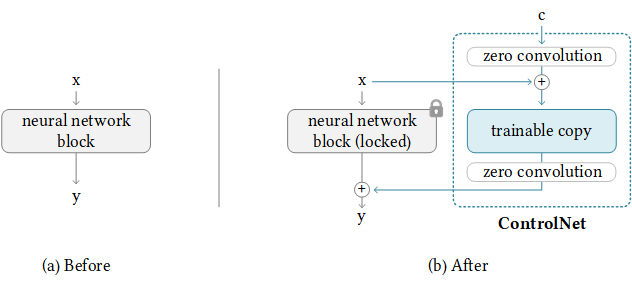
背景
由Lvmin Zhang等人提出的條件控制框架,為擴散模型增加精確的空間控制能力,實現結構化生成。
原理
- 零卷積:使用參數初始化為零的卷積層,逐步學習條件控制信號。
- 條件分支:額外的神經網絡分支處理控制信號(如邊緣、姿勢等)。
- 特征融合:在U-Net的各層級融合條件特征。
網絡結構
- 主干網絡:預訓練的穩定擴散模型(freeze)。
- 控制分支:與主干網絡相同結構,但專注于條件信號處理。
- 特征適配器:將條件特征映射到主干網絡相容的空間。
優缺點
- 優點:
- 精確的空間控制,支持多種條件(線稿、姿勢、深度等)。
- 保留原始模型生成能力,僅增強控制層面。
- 缺點:
- 需要特定條件數據訓練。
- 額外內存占用,增加計算負擔。
應用場景
- 精確圖像編輯(如姿勢引導)、草圖轉圖像、風格遷移與保持結構。
總結對比表
| 模型 | 核心思想 | 優勢與局限 | 典型應用 |
|---|---|---|---|
| GAN | 對抗訓練 | 高質量生成,但訓練不穩定 | 圖像生成、風格遷移 |
| AE/VAE/VQ-VAE | 潛在空間建模 | 結構化表示,但生成模糊 | 數據壓縮、圖像修復 |
| Diffusion Model | 逐步去噪生成 | 高保真,但速度慢 | 文本到圖像、超分辨率 |
| DALLE-2 | 文本-圖像對齊 | 復雜描述生成,依賴CLIP | 文本生成圖像 |
| Latent Diffusion | 潛在空間加速 | 高效生成,依賴編碼器質量 | 快速圖像生成工具 |
| UNet | 多尺度特征融合 | 細節保留,計算成本高 | 醫學分割、擴散模型核心 |
| DDIM | 非馬爾可夫鏈加速 | 采樣快,但質量略低 | 實時生成、快速原型設計 |
| Transformer | 自注意力機制 | 多模態建模強,但計算復雜 | 高質量圖像生成、視頻生成 |
| ControlNet | 條件控制 | 精確控制,但需要額外資源 | 姿勢引導、草圖轉圖像 |
未來方向
- 效率優化:如隱式擴散模型(DDIM)加速采樣,或結合神經渲染技術。
- 多模態融合:結合文本、音頻等生成復雜內容(如DALLE-2的擴展)。
- 可控生成:通過條件輸入(如文本、屬性)精細控制生成結果。


數據ETL)





+SQLite實現(Web)校園助手)
)


項目分享)





)
