一、簡介
深度學習是機器學習領域新興且關鍵的研究方向。機器學習重點在于讓計算機從數據中挖掘規律以預測未知,而深度學習借助構建多層神經網絡,自動學習數據的復雜特征,從而實現更精準的模式識別,在圖像、語音等眾多領域廣泛應用。
二、神經網絡基礎結構介紹
1、神經元工作機制
神經元模擬人類大腦神經元,接收多個帶權重的輸入信號,將其加權求和并加上偏置值,再通過激活函數(如 sigmoid 函數)處理,把輸出映射到 0 - 1 之間,為神經網絡引入非線性因素,使其能夠處理復雜的非線性關系。
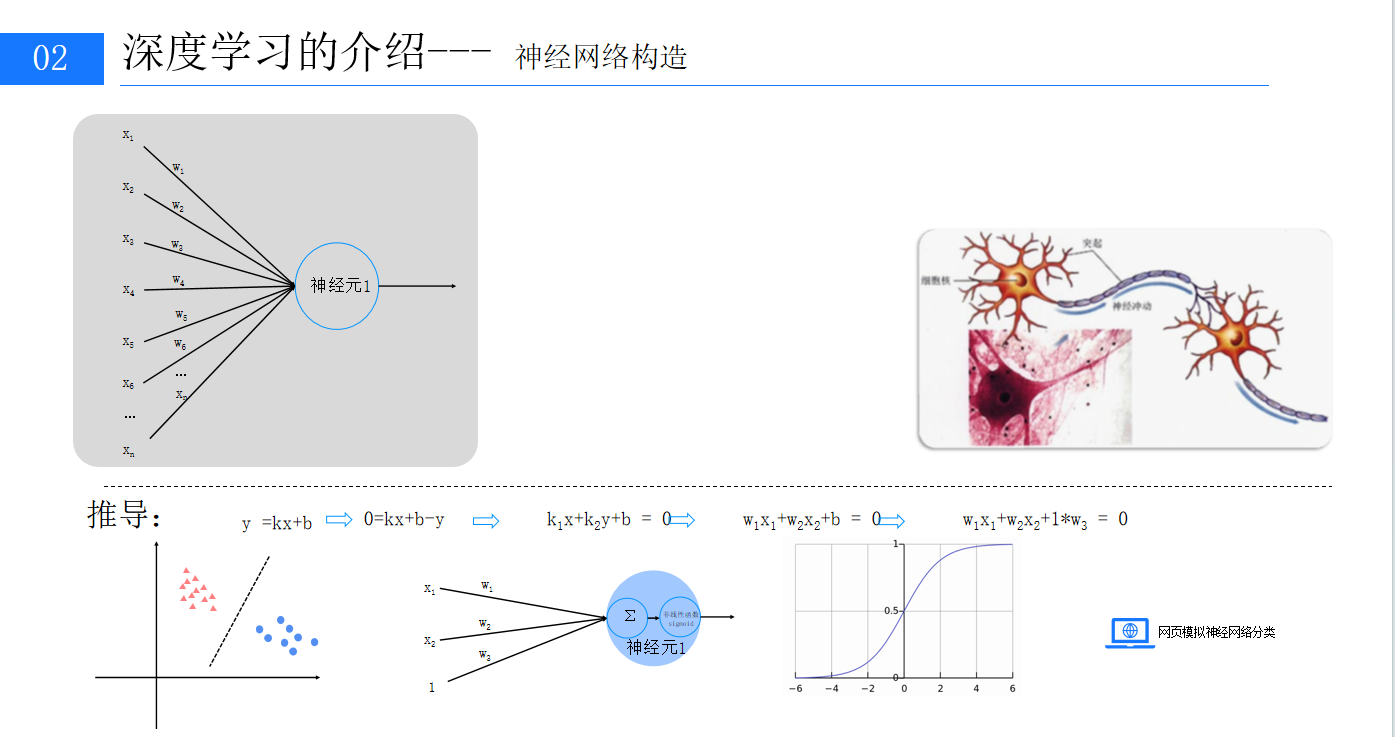
2、感知器的原理?
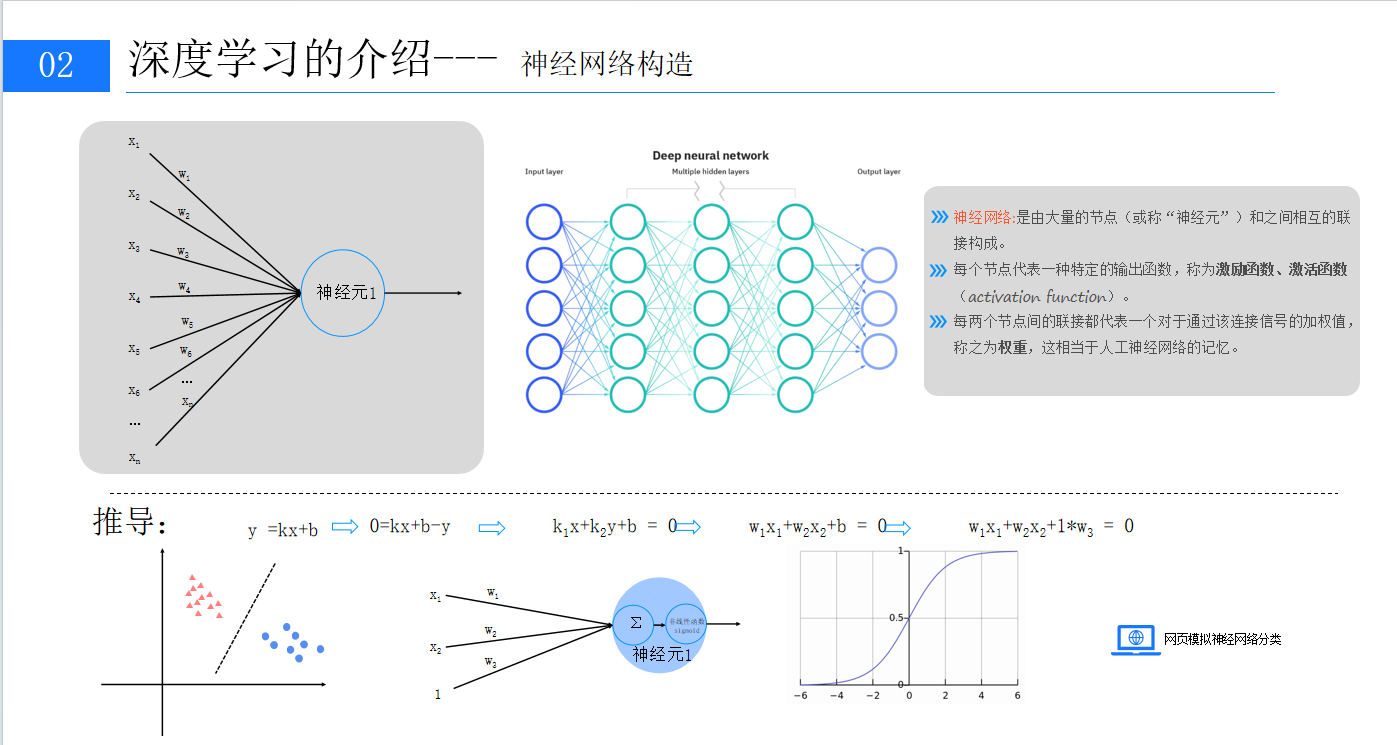
 ?
?
由兩層神經元構成的感知器,能用矩陣乘法表示輸出公式g(W?x)=z?。它可對數據進行線性分類,但僅適用于線性可分數據,面對復雜非線性問題時表現不佳。
3、多層感知器
多層感知器在輸入層和輸出層間添加了隱含層,能學習到數據的非線性特征,實現復雜數據的分類和預測。設計時,輸入層節點數與數據特征維度匹配,輸出層節點數與預測目標維度一致,中間層節點數目前依靠經驗設定,通過試驗不同值對比模型預測效果來確定最優數量。
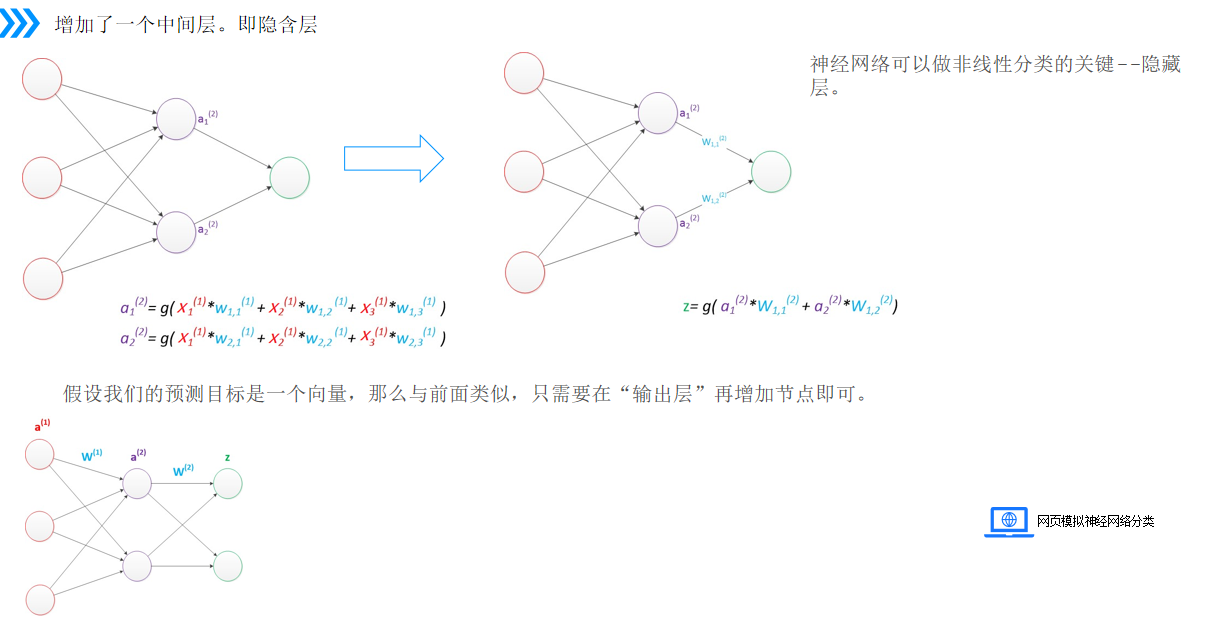 ?
?
?4、偏置神經元
偏置神經元是神經網絡中存儲值恒為 1 的特殊單元,除輸出層外每層都存在。它雖不接收外部輸入,但為神經網絡增加了靈活性,助力模型更好地擬合數據,學習復雜函數關系。
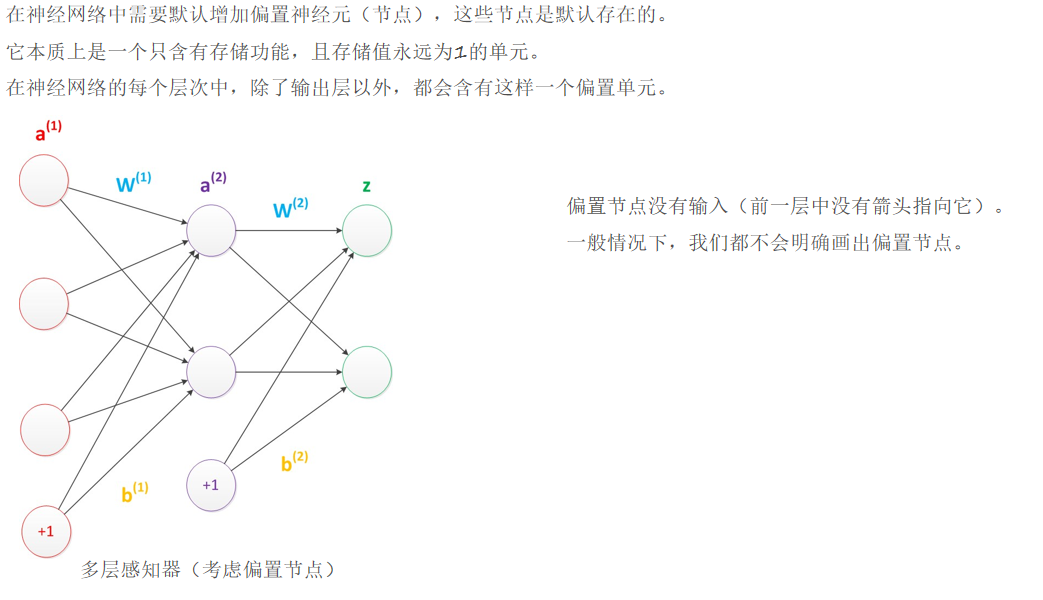
三、神經網絡構造過程
1、輸入輸出層的確定

2、損失函數
損失函數用于衡量模型預測值與真實值的誤差,常見類型包括 0 - 1 損失函數、均方差損失、平均絕對差損失、交叉熵損失、合頁損失等。多分類問題中常用交叉熵損失,以圖像分類為例,模型預測各類別概率,通過處理概率計算損失值,預測越準確,損失值越小。
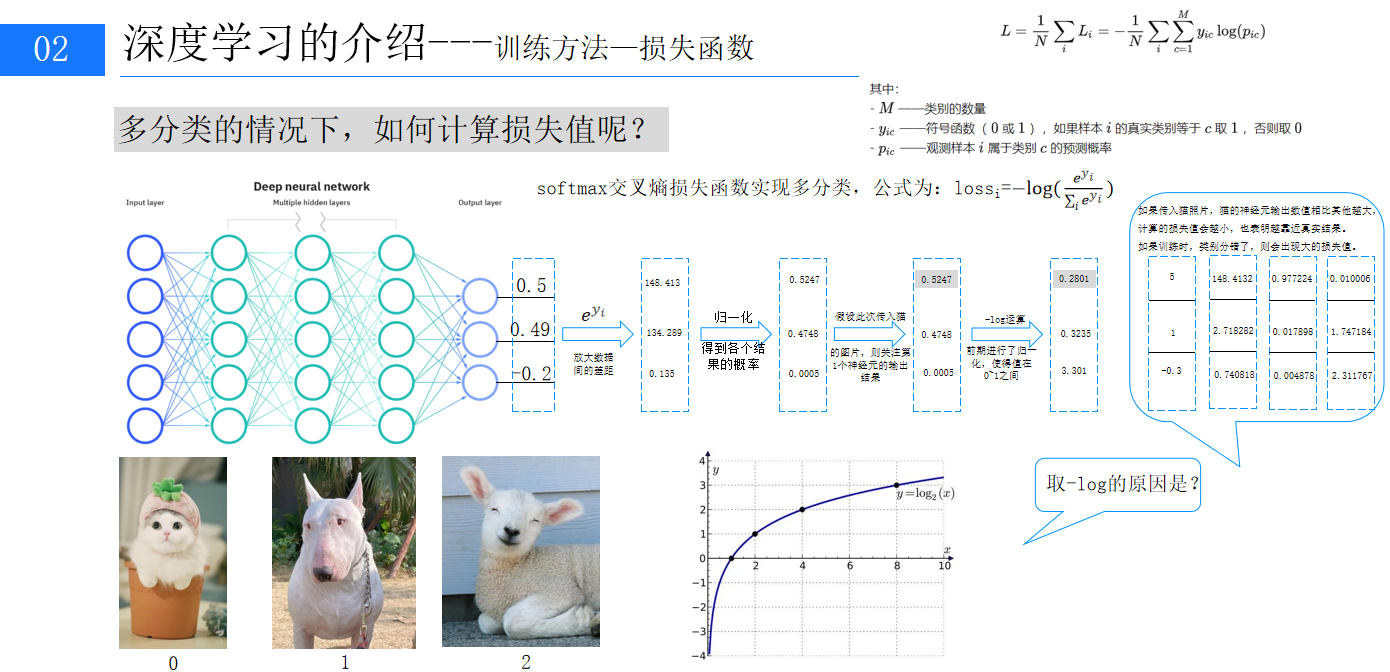
3 、正則化懲罰
為防止模型過擬合,引入正則化懲罰,常見的有 L1 和 L2 正則化。它們通過約束權重參數,懲罰過大的權重值,使模型更具泛化能力,避免過度依賴訓練數據中的噪聲和細節。

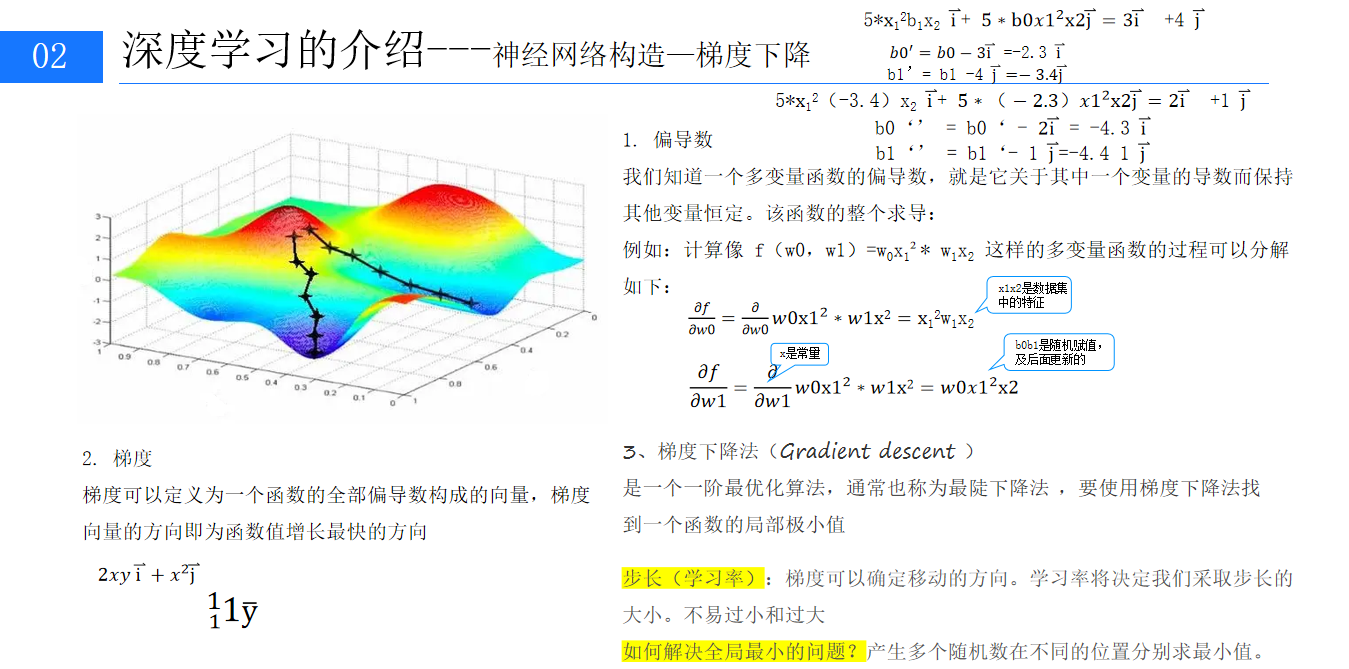
4、梯度下降法的原理與應用
梯度下降法是深度學習常用的優化算法,用于調整模型參數使損失函數最小化。基于偏導數和梯度概念,偏導數表示函數關于某變量的變化率,梯度是所有偏導數組成的向量,指向函數值增長最快的方向。梯度下降法沿梯度反方向更新參數,學習率決定每次更新的步長,其大小影響模型訓練效果,過大易跳過最優解,過小則訓練速度緩慢。
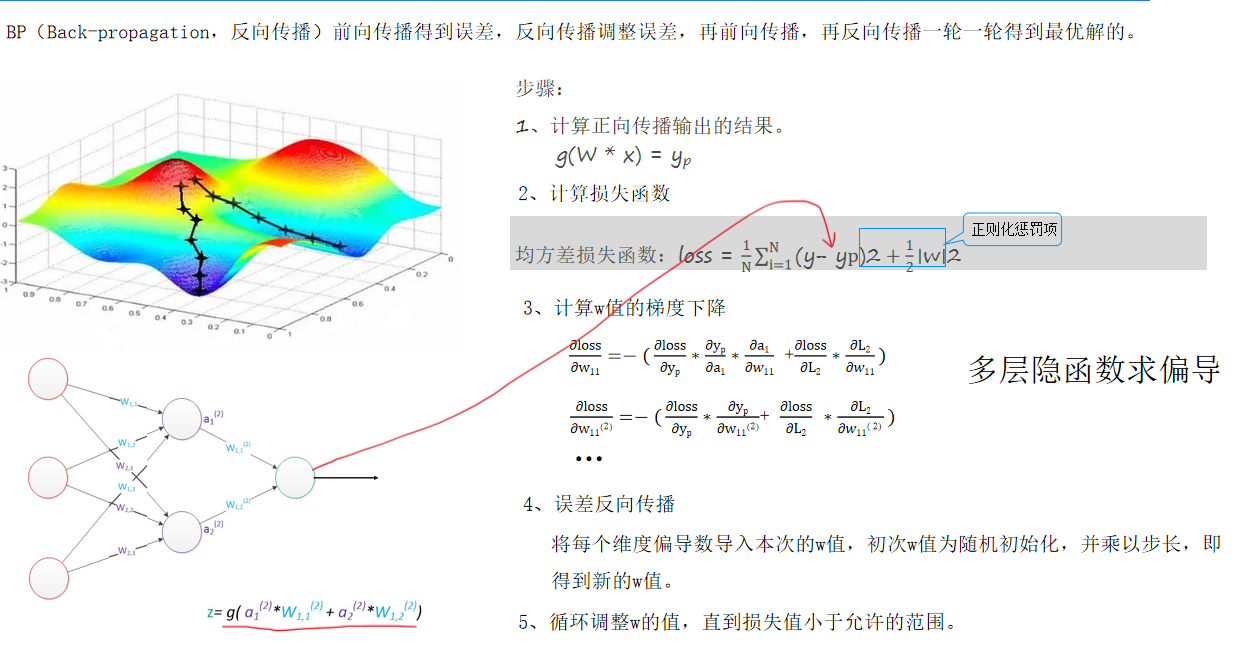
5、BP 神經網絡
BP 神經網絡結合梯度下降法,訓練過程包括正向傳播和反向傳播。正向傳播時,輸入數據經各層計算得出預測結果,進而計算損失函數;反向傳播時,將損失函數關于權重的梯度從輸出層反向傳播到輸入層,更新各層權重參數。不斷重復這兩個過程,優化模型參數,降低損失值,提升模型預測能力。
四、總結
深度學習是機器學習的重要分支,通過構建多層神經網絡自動學習數據特征。神經網絡由神經元構成,從簡單的感知器到多層感知器,逐步突破線性局限,偏置神經元為網絡帶來靈活性。訓練時,損失函數衡量誤差,正則化防止過擬合,梯度下降法結合 BP 神經網絡不斷調整參數,使模型在預測任務中表現更佳,廣泛應用于圖像、語音等多領域。?下篇文章將會帶領大家來實現神經網絡的搭建,歡迎大家的關注!
?








)





)




