一、#和##
1、#運算符
這里的#是一個運算符,整個運算符會將宏的參數轉換為字符串字面量,它僅可以出現在帶參數的宏的替換列表中,我們可以將其理解為字符串化。
我們先看下面的一段代碼:
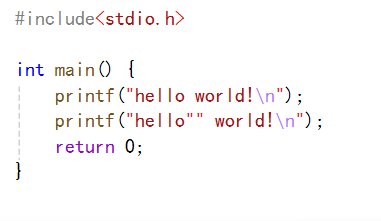
第二個printf中是由兩個字符串組成的,這樣寫法的輸出和第一個寫法輸出是否會有不同呢?
運行結果:
?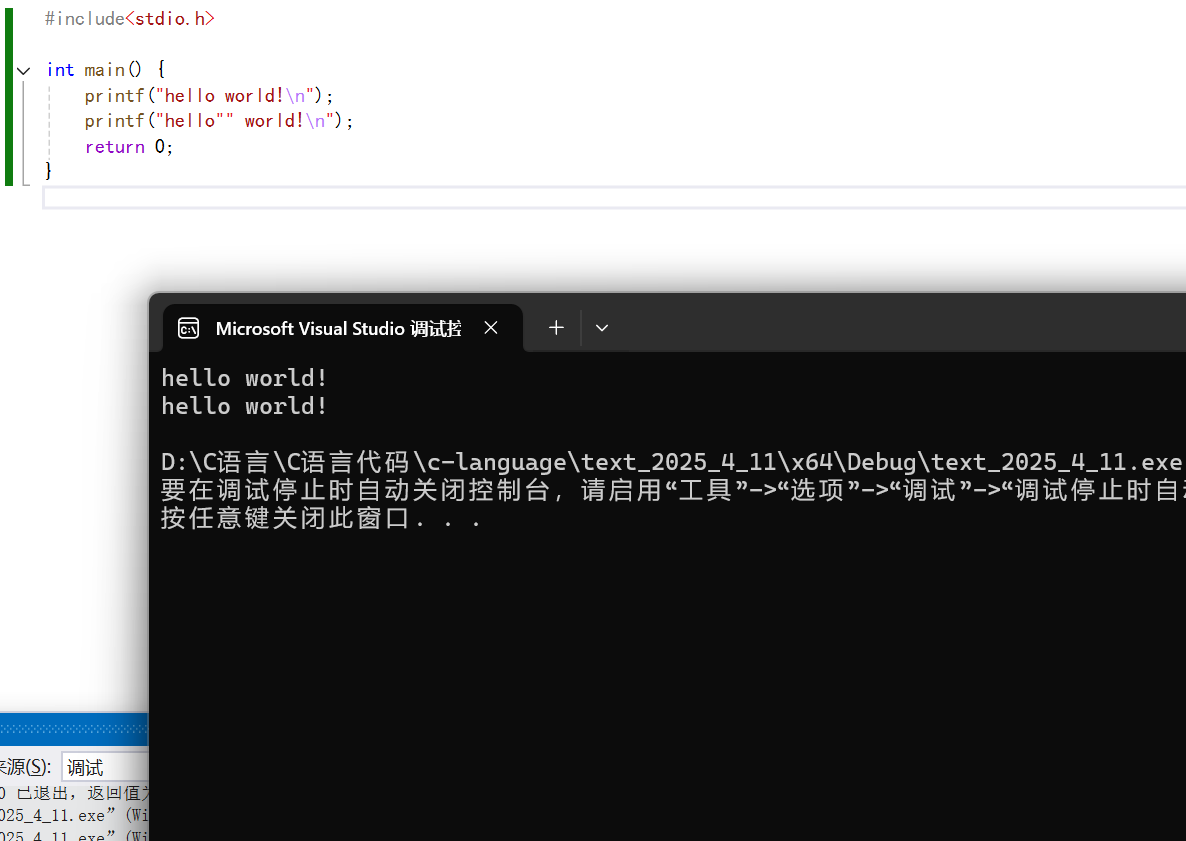
可以看到,這兩個挨在一塊的字符串會被合并起來輸出。?
下面我們通過一個例子來弄清楚# 符號到底是怎么個事:
我們現在想在屏幕上打印the value of a is 20?。那么我們可以如下面一樣操作:
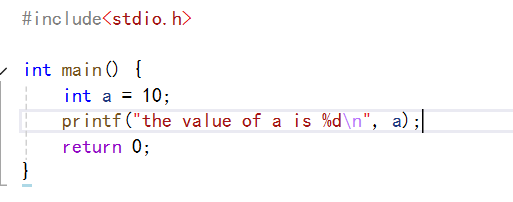
但是當我們需要對其他幾個變量也打印這樣的信息呢?那么是不是要重復的寫這么一長串的代碼,有沒有什么辦法可以將其簡化?
此時我們可以通過宏來解決這個問題,在上面的字符串中,不同的變量發生變化的有三個地方:
一個就是of后面的,這個地方是要填入的是變量名,然后是占位符,然后就是參數了。
參數是比較好解決的,主要是變量名和占位符,這是因為這兩個都是字符串,所以我們在使用宏替換的時候,是不會將其替換的,此時是不是就沒辦法了呢?
對于占位符的替換,我們可以用上面那個代碼的情況,兩個字符串是可以合并的。
還有就是對于變量名,其就需要使用到我們的#運算符了,我們上面提到了其可以將我們后面的內容字符串化。
代碼如下:
?????
我們看看其運行結果:
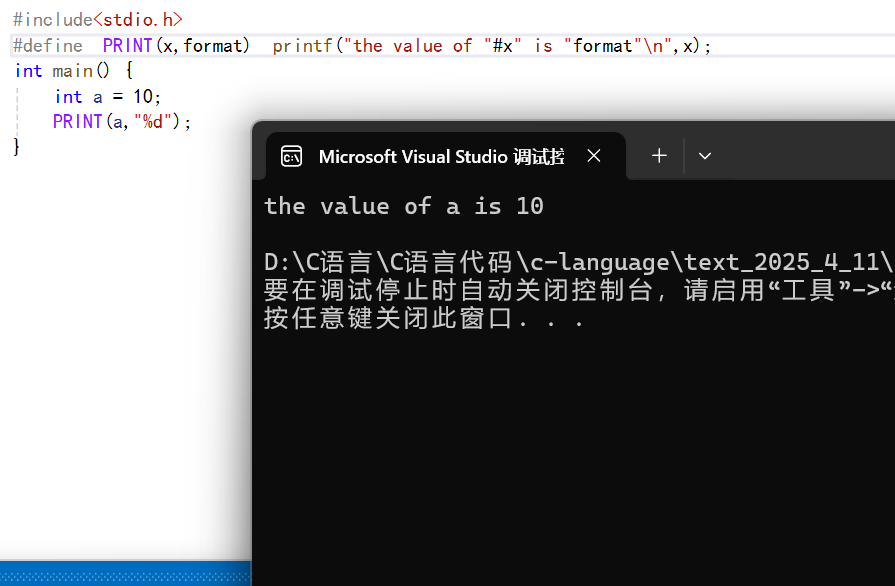
可以看到其完美的實現了我們需要的功能。?
2、##運算符
##運算符又是一個完全陌生的符號,其作用是將其兩邊的符號合成一個符號,其運算宏定義從分離的文本片段創建標識符。##被稱為記號粘合運算符。
比如我們現在有一個變量class115,那么我們可以通過粘合class和115來得到它
如下:
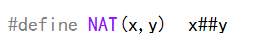
我們將其合并后,那么其此時就可以表示我們的變量了,那么我們使用printf將其打印出來,看看是不是10。
如下:
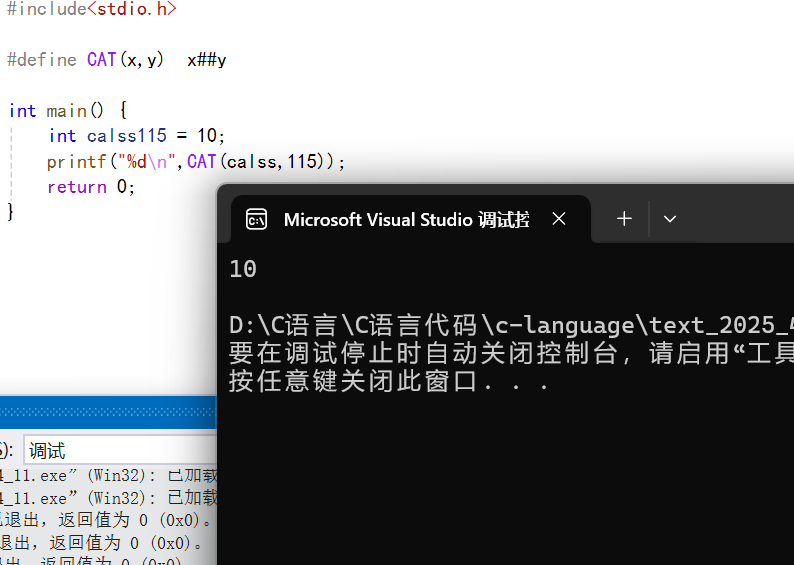
可以看到其可以順利得到我們的這個變量名字。
下面我們再通過一個例子理解這個運算符:
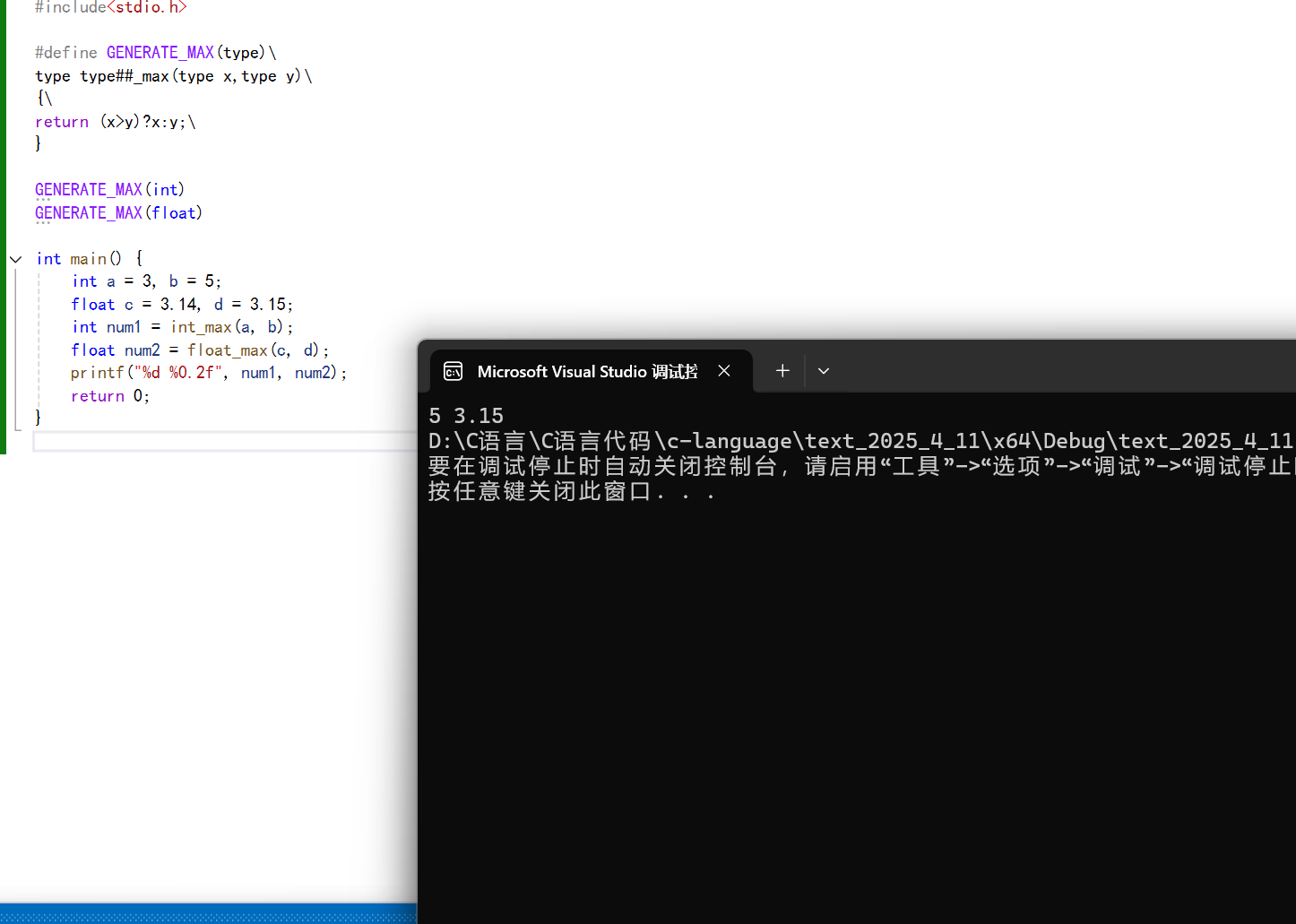
我們前面使用函數寫過一個比較兩個數的大小,當我們比較的兩個數是整數的時候,那我們就需要寫一個整型數據求最大值的函數,當要求浮點數的時候,就需要寫一個浮點數使用的函數,但是我們可以知道的是,這兩個函數除了返回值類型,和參數的數據類型不一樣罷了,其他的都是一樣的。
如下:
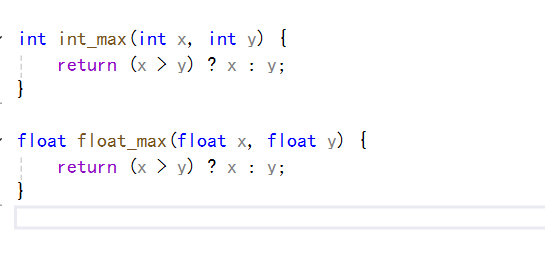
下面我們通過宏來定義:
這個宏要實現的功能就是根據我們傳入的數據類型,然后生成對應的求最大值的函數。
那么主要是解決對于數據類型如何與函數名相連了,那么剛剛好可以使用##進行粘合。
這些函數的名字的共同點如:數據類型_max。
如下:

上面就是我們創建的對于不同的數據類型都可以使用的求最大值的宏,我們根據用戶傳入的type來確定函數的名字和函數的返回值類型,然后\是一個換行符號。
這里我們使用了##運算符將type與_max連接起來,可以讓用戶傳入的type可以完美的替換。
那么我們就可以通過這個宏來創建需要使用到的求最大值的函數:
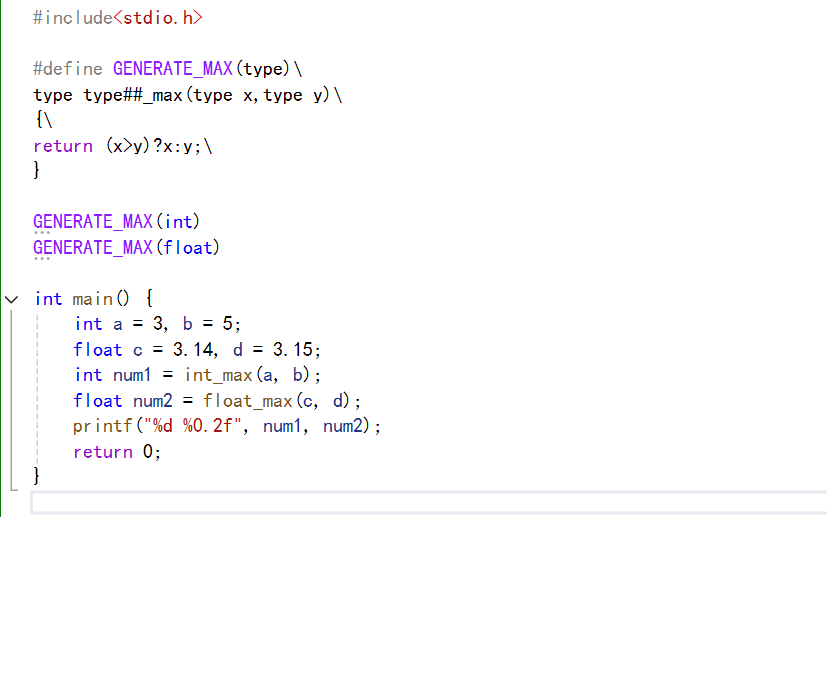
運行結果:
二、預處理指令#under?
#under指令的作用是移除一個#define的定義,其語法如下:
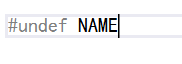
其中NAME就是我們要移除的#define定義的名字了,當我們需要使用這個名字重新定義一個宏的時候,那么我們就需要使用#under將其原來的定義移除,然后才可以使用這個名字進行定義一個新的宏。
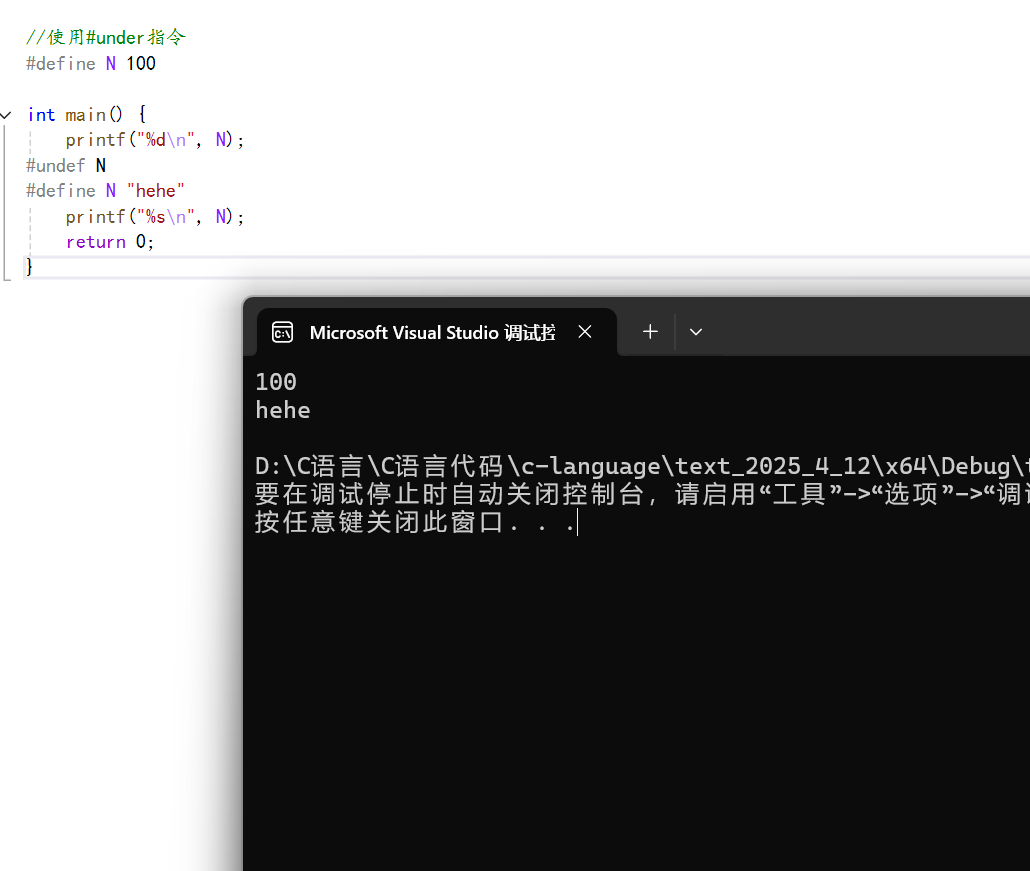
如下:

上面我們首先使用#define將N定義為100,然后將其在屏幕上打印,然后我們使用#undef先將其原來的定義移除,然后再將N重新定義為hehe字符串,然后將其在屏幕上打印。
 ?
?
三、條件編譯?
條件編譯,類似于我們的選擇語句,不過這個過程是在預處理階段進行的,它會根據我們的條件來決定是否對某些語句進行編譯。
1、單分支條件翻譯
單分支條件編譯就是說我們只有一條分支需要進行判斷。
其語法如下:
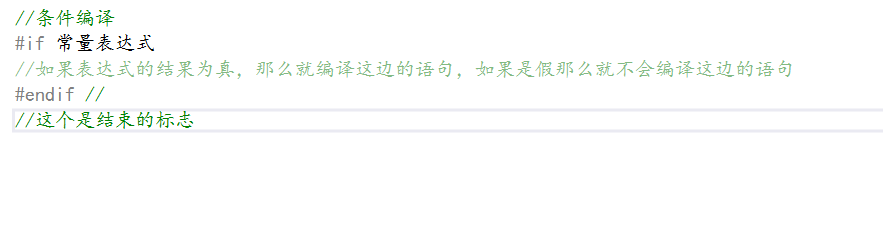 ?可以發現其和if語句類似,也是有個條件表達式決定其里面的內容編譯不編譯,不過其比if語句多了一個結束的標志。
?可以發現其和if語句類似,也是有個條件表達式決定其里面的內容編譯不編譯,不過其比if語句多了一個結束的標志。
不過條件表達式其要求的是常量表達式,下面我們使用其看看效果:
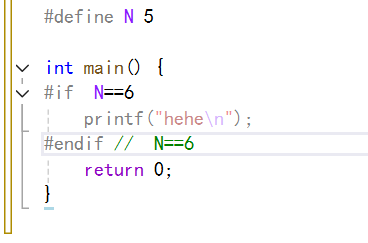
那么這個代碼就啥都不會打印。因為常量表達式的值是為假的。
那么為什么后面只能為常量表達式呢?這是因為在這個階段是預處理階段,在這個階段,變量還不存在,那么也就不能使用變量了,只能使用常量
2、多分支條件編譯?
多分支編譯和單分支編譯的原理大致相同,不過其就是多了幾個選擇這樣。
其語法如下:
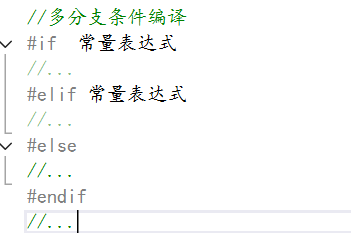
這個就是我們的多分支條件編譯的語法,其用法和if -else的差不多,就是在第一個#if要是不滿足,那么就看#elif的條件是否滿足,要是滿足則運行其代碼,要是不滿足,要是這兩個都不滿足,那么就會運行#else的內容,然后就結束。
如下:
 ?
?
上面的代碼其是滿足#elif的條件,那么我們看看其是否可以將hehe打印在屏幕上。
運行結果:
 ?
?
下面我們試試當前面兩個的都不滿足,其是否會運行#else的內容:
 ?
?
運行結果:
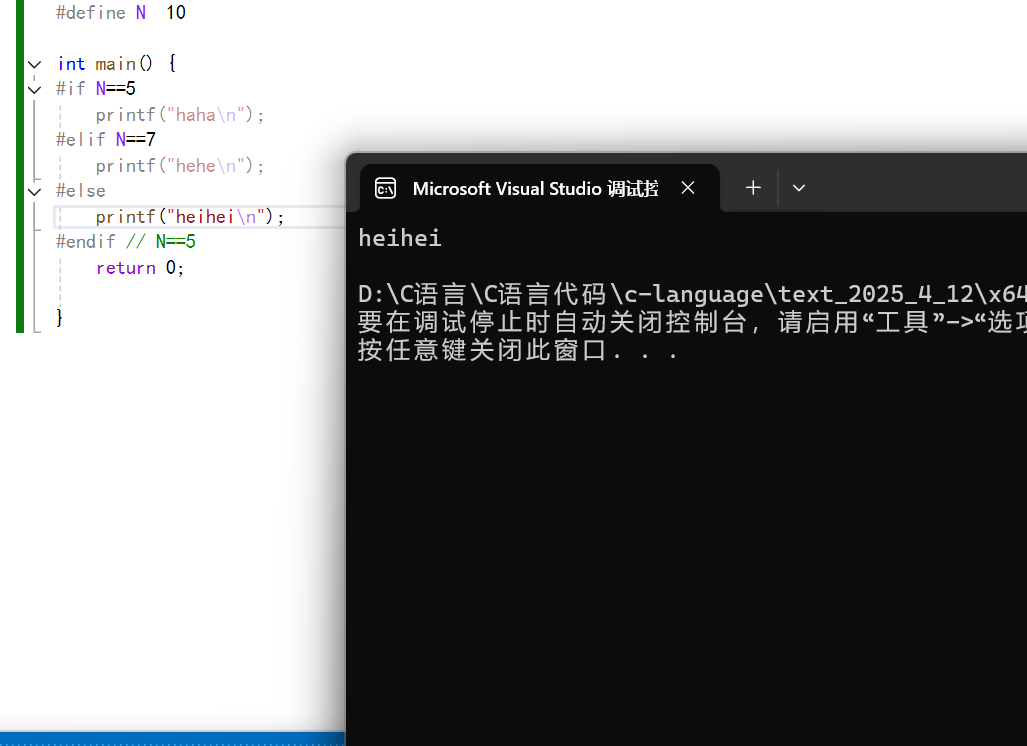 ?可以看到確實是如此。
?可以看到確實是如此。
那么細心的同學就會發現了,在我們的多分支條件編譯中,會被編譯的代碼會比不被進行編譯的代碼顏色更深。
3、判斷符號是否被定義
在編譯一個程序的時候,如果我們要將一條語句,編譯或者放棄編譯,那么我們可以使用條件編譯,比如調試性的代碼,我們在調試完后,將其刪去又會很浪費,但是保留又會很難看,影響我們代碼的可讀性,那么我們就可以使用條件編譯,在編譯的時候不編譯這些調試性代碼。
例如我們在開頭使用了#define定義一個符號,如果我們沒有注釋或者刪除這個符號,那么我們是可以編譯里面的調試性代碼的,反之就不可以編譯。但是這個是不會影響代碼的正常運行的。
我們先學習如何進行判斷一個符號是否被定義:
1、使用#if? define進行判斷其語法如下:
![]()
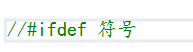
2、使用#ifdef進行判斷:
? ?  ?
?
使用#ifdef的話,要判斷的符號就不需要使用括號了。
下面我們使用其判讀符號是否被定義:
我們首先定義一個GEBUG的符號,然后在main函數中創建一個變量a,然后我們使用#ifdef判斷這個GEBUG符號是否被定義,要是被定義了就將這個變量打印出來。
如下:
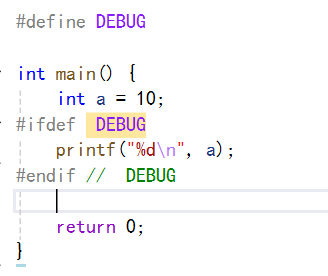 ?
?
運行結果:
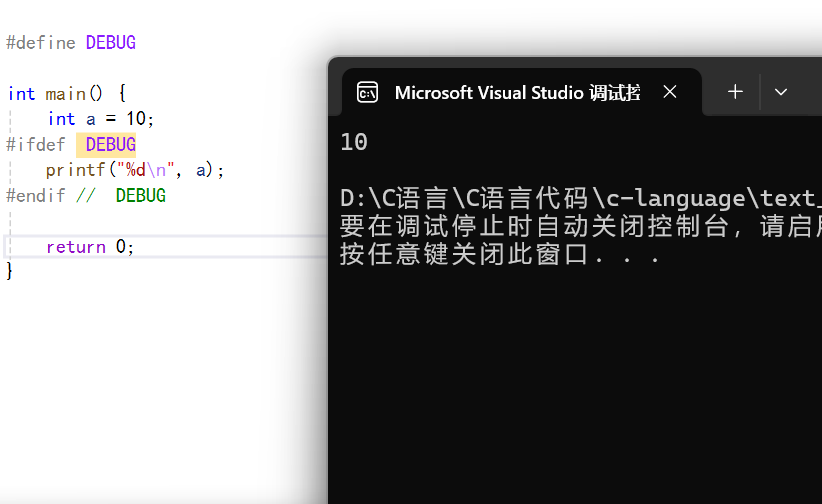 ?
?
我們注釋掉它的定義后,那么就不會打印這個變量了:
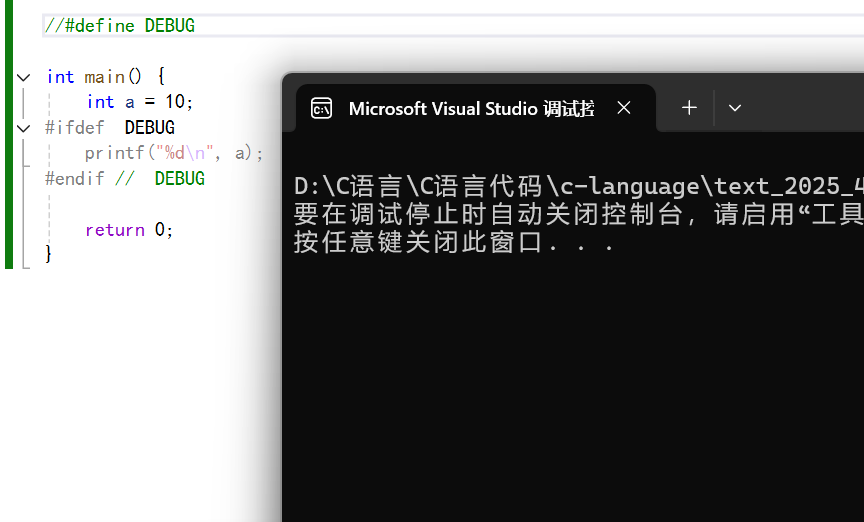 ?
?
4、判斷符號是否沒有被定義?
其和上面的判斷符號是否被定義差不多:
1、使用#if !defined:這個就是我們上面使用到的#if defined的前面加上一個非符號。
2、使用#ifndef:這個就是在上面的#ifdef加上一個n,表示no實際上就是表示否定。
四、頭文件的包含
頭文件的包含我們一直都有在使用,其本質上是拷貝,當我們包含一個頭文件后,會直接將頭文件的內容拷貝過來,下面我們具體學習一下頭文件的包含。
1、庫頭文件的包含
庫頭文件里面包含了C語言的庫函數和一些其他功能,我們只需要包含庫的頭文件就可以直接使用。
我們包含頭文件的語法就是:
#include<頭文件>
2、本地頭文件的包含
本地頭文件就是我們自己寫的頭文件,這種我們自己實現的頭文件的話,我們包含其的語法如下:
#include "頭文件"
3、如何避免重復包含頭文件
我們在包含頭文件中,我們可能會造成嵌套的包含,也就是可能會多次包含同一個頭文件,那么這就會造成代碼的冗余。
那么我們有沒有什么辦法解決這個問題呢?
我們可以使用條件編譯指令:
就是使用#ifndef或者使用#if? !defined這兩個指令。
因為頭文件其是就是簡單的拷貝,那么我們可以在頭文件中的開頭寫下面的代碼:

或者使用預處理指令#pragma
這種方法比上面的還簡答,我們可以在當前程序下創建一個頭文件,我們可以發現頭文件中自動包含了一條語句。
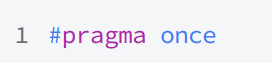 ?
?
這樣也可以達到我們想要的效果。
五、C語言完結?
感想各位大佬們的閱讀、點贊、收藏和評論,后面我們就會對數據結構的學習。









)









