本文重點
從數據集的類型來看,數據集可以分為有界數據和無界數據兩種,從處理方式來看,有批處理和流處理兩種。一般而言有界數據常常使用批處理方式,無界數據往往使用流處理方式。
有界數據和無界數據
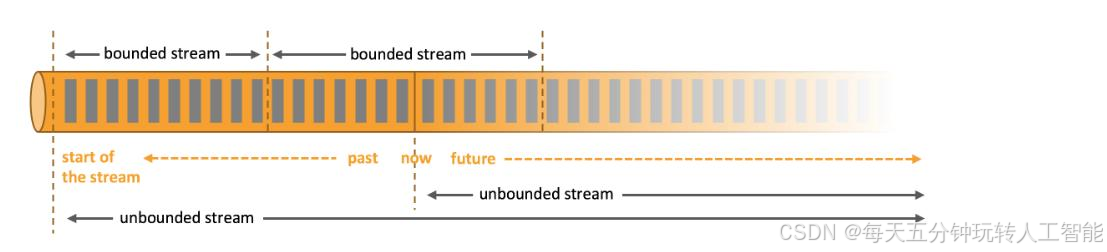
有界數據有一個明確的開始和結束。在執行任何計算之前,可以通過獲取所有數據來處理有界流。處理有界流不需要有序攝取,因為有界數據集總是可以排序的。有界流的處理也稱為批處理。
無界數據有開始但是沒有結束。無界數據流必須被連續處理,即事件在被接收后必須被迅速處理。不可能等待所有輸入數據到達,因為輸入是無限的,并且不會在任何時間點完成。處理無限數據通常需要以特定的順序接收事件,例如事件發生的順序,以便能夠推斷結果的完整性,這往往也是處理無界數據困難的地方,因為事件的接收順序和事件的發生順序往往是不一致的。
有界數據集和無界數據集只是一個相對的概念,主要根據時間的范圍而定,可以認為一段時間內的無界數據集其實就是有界數據集,同時有界數據也可以通過一些方法轉換為無界數據。例如一臺插座設備上報一年的電量數據,其本質上應該是有界的數據集,可是當我們把它一條一條按照產生的順序發送到流式系統,通過流式系統對數據進行處理,在這種情況下可以認為數據是相對無界的。對于無界數據也可以拆分成有界數據進行處理,例如一臺設備不停的上報電量數據,如果按照年或月進行切割,此時我們就可以將數據看成是有界的。
從以上分析我們可以得出結論:有界數據和無界數據其實是可以相互轉換的。有了這樣的理論基礎,對于不同的數據類型,業界也提出了不同的能夠統一數據處理的計算框架。比如Apache Spark框架和Apache Flink框架。
?比如Spark通過批處理模式來統一處理有界和無界的數據集,對于無界數據是將數據按照批次切分成微批 (有界數據集)來進行處理。Flink 通過流處理模式來統一處理不同類型的數據集。將有界數據也按照無界數據進行處理,最終將批處理和流處理統一在一套流式引擎中,而需要部署兩套。
批處理和流處理
在大數據領域批處理和流式處理常常被認為是兩種不同的任務。
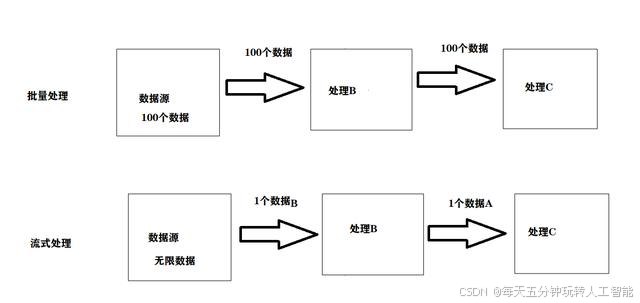
批處理是有界數據流處理的范例。在這種模式下,你可以選擇在計算結果輸出之前輸入整個數據集,這也就意味著你可以對整個數據集的數據進行排序、統計或匯總計算后再輸出結果。假設數據處理產線有多個處理操作,批處理需要將所有數據處理完成之后才會進入下一個操作。如圖所示,這100條數據經過處理A處理之后,才會將處理結果輸入到下一個處理B,如果A沒有處理完畢,那么B就只能等待。
流處理正相反,其涉及無界數據流。至少理論上來說,它的數據輸入永遠不會結束,因此程序必須持續不斷地對到達的數據進行處理。如圖所示,數據A經過處理B處理完畢之后,就可以放到下一環節被處理C處理,此時新的數據數據B不會閑下來,又處理新來的數據B了,也就是說處理B和處理C可以同時加工不同的數據,處理完就把數據往下扔,然后接著處理上一環節的數據。
注意:并不是說無界數據就一定要流式處理,也不一定有界數據就一定批式處理。我們前面說過了有界數據和無界數據其實是可以相互轉換的,如果我們想要批量處理我們就將其轉變為有界數據,如果我們想要流式處理我們就將其轉變為無界數據就好了。
應用場景
1. 批處理的應用場景
批處理通常用于處理大量的歷史數據,例如,企業的銷售數據、財務數據等。批處理可以幫助企業進行數據分析、數據挖掘、預測分析等工作,從而幫助企業做出更好的決策。
2. 流處理的應用場景
流處理通常用于處理實時數據,例如,股票行情、網絡流量、傳感器數據等。流處理可以幫助企業進行實時監控、實時預警、實時決策等工作,從而幫助企業更好地應對突發事件和變化。
)
)



)
詳解)


:PyTorch 中的 `expand` 與 `repeat`:詳解廣播機制與復制行為(附詳細示例))




 和 useSelector()使用以及詳細案例)

計算輸入矩陣 src 中每個元素的平方根函數sqrt())


