前言
25年3.26日,這是一個值得紀念的日子,這一天,我司「七月在線」的定位正式升級為了:具身智能的場景落地與定制開發商 ,后續則從定制開發 逐步過渡到 標準產品化
比如25年q2起,在定制開發之外,我司正式推出第一類具身產品(后續更多產品 詳見七月官網):復現各個前沿具身模型的軟硬全套的標準化產品,相當于已幫組裝好的硬件,和對應復現好的程序,包括且不限于ALOHA/RDT/umi/dexcap/idp3/π0,如此軟硬一體標準化的產品,省去復現過程中的
- 各種硬件組裝問題
- 各種算法問題
- 各種工程問題
真正做到:一旦拿來,開箱即用
我司具身落地中,過去半年用π0居多,其次idp3和其他模型,?也是目前國內具身落地經驗最豐富的團隊之一了
- 其中有不少工作便涉及到對具身模型的微調——恍如18-20年期間 大家各種微調語言模型
再之后隨著GPT3、GPT3.5、GPT4這類語言模型底層能力的飛速提升,使得針對語言模型的微調呈逐年下降趨勢 - 但在具身方向,未來一兩年,微調具身模型都是主流方向之一
當然了,隨著具身模型底層能力的越來越強、泛化性越來越好,也早晚會走到如今語言模型這般 微調偏少的地步
且我(們)始終保持對具身最前沿技術的溝通,這不,25年2月底,斯坦福的三位研究者
- Moo Jin Kim
OpenVLA的一作 - Chelsea Finn
ALOHA團隊的指導老師,也是RT-2、OpenVLA、π0的作者之一,是我過去一兩年下來讀的機器人論文中出現頻率最高的一個人了 - Percy Liang
OpenVLA的作者之一
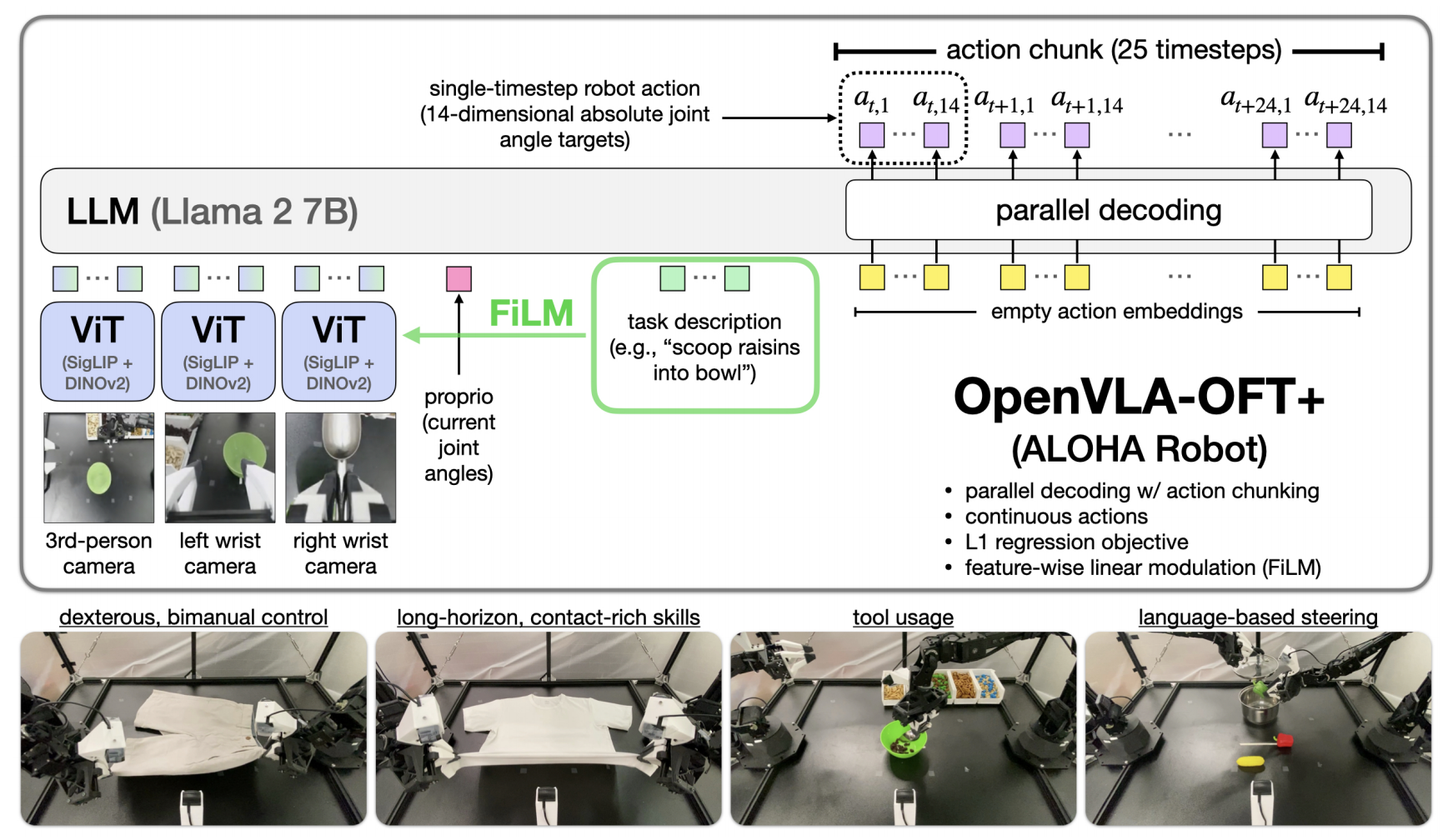
提出OpenVLA-OFT「paper地址《Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success》、項目地址、GitHub地址」,在他們的角度上,揭示微調VLA的三大關鍵設計:并行解碼、動作分塊、連續動作表示以及L1回歸目標
注意,我在解讀的過程中,不一定會嚴格按照「論文整體的順序及部分內容的原文順序」展開,而是會為方便普通讀者更好理解、更好認知的邏輯展開,包括部分小標題的編寫
第一部分?OpenVLA-OFT
1.1?OpenVLA-OFT的提出背景與相關工作
1.1.1?OpenVLA-OFT的提出背景
???Kim等人[22]提出了OpenVLA(一種代表性的自回歸VLA模型),其通過LoRA進行參數高效的微調。然而,OpenVLA的自回歸動作生成在高頻控制中仍然過于緩慢——只能做到3-5 Hz 沒法做到高頻的25-50+ Hz,并且LoRA和自回歸VLAs的全微調在雙手操作任務中往往表現不佳[51,26,3]
OpenVLA結合了
- 一個融合的視覺主干(包括SigLIP [52]和DINOv2 [34]視覺變換器)
- 一個Llama-2 7B語言模型[49]
- 以及一個帶有GELU激活[11]的三層MLP投影器,用于將視覺特征投影到語言嵌入空間中
流程上,OpenVLA處理單張第三人稱圖像和語言指令(例如,“將茄子放入鍋中”)。融合的視覺編碼器從每個ViT中提取256個patch嵌入,沿隱藏維度將它們拼接,并將其投影到語言嵌入空間。這些投影的特征與語言嵌入沿序列維度拼接,然后由Llama-2解碼器處理,以輸出一個7維的機器人動作,表示末端執行器姿態的增量,由一串離散動作標記表示
更多細節,詳見此文《一文通透OpenVLA及其源碼剖析——基于Prismatic VLM(SigLIP、DinoV2、Llama 2)及離散化動作預測》

盡管最近的方法通過更好的動作tokenization方案[2,36]提高了效率,實現了2到13倍的加速,但動作塊之間的顯著延遲「例如,最近的FAST方法[36]為750毫秒」仍然限制了在高頻雙手機器人上的實時部署
對此,三位作者使用OpenVLA作為基礎模型,將VLA適配到新型機器人和任務中的關鍵設計決策
他們考察了三個關鍵設計選擇并揭示了一些關鍵見解:
- 對于動作解碼方案——自回歸與并行生成
通過動作分塊的并行解碼不僅提高了推理效率,還改善了下游任務的成功率,同時增強了模型輸入輸出規范的靈活性 - 對于動作表示——離散與連續
與離散表示相比,連續動作表示進一步提高了模型質量 - 對于學習目標——下一個token預測、L1回歸與擴散
使用L1回歸目標對VLA進行微調時,在性能上與基于擴散的微調相當,同時提供了更快的訓練收斂速度和推理速度
基于以上見解,他們引入了OpenVLA-OFT:一種優化微調(OFT)方案的具體實現,該方案結合了并行解碼和動作分塊、連續動作表示以及L1回歸目標,以在保持算法簡單性的同時提高推理效率、任務性能和模型輸入輸出靈活性
具體而言,在架構層面上,相比OpenVLA,OpenVLA-OFT 引入了以下關鍵變化:
- 動作塊與解碼上(詳見下文1.2.1節)
將因果注意力替換為雙向注意力以實現并行解碼
且輸出K個動作的塊——比如K可以設置為14,而不是單時間步的動作 - 輸出變化上,即動作表示上(詳見下文1.2.2節)
用一個四層的多層感知機(ReLU激活)替代語言模型解碼器的輸出層,用于生成連續動作(而非離散動作)
比如,
,
..,總計25輪
至于學習目標上——即怎么生成動作呢?下文1.2.3節會介紹,三位作者實現了L1回歸、與條件去噪擴散conditional denoising diffusion - 輸入變化上?(詳見下文1.3.1節)
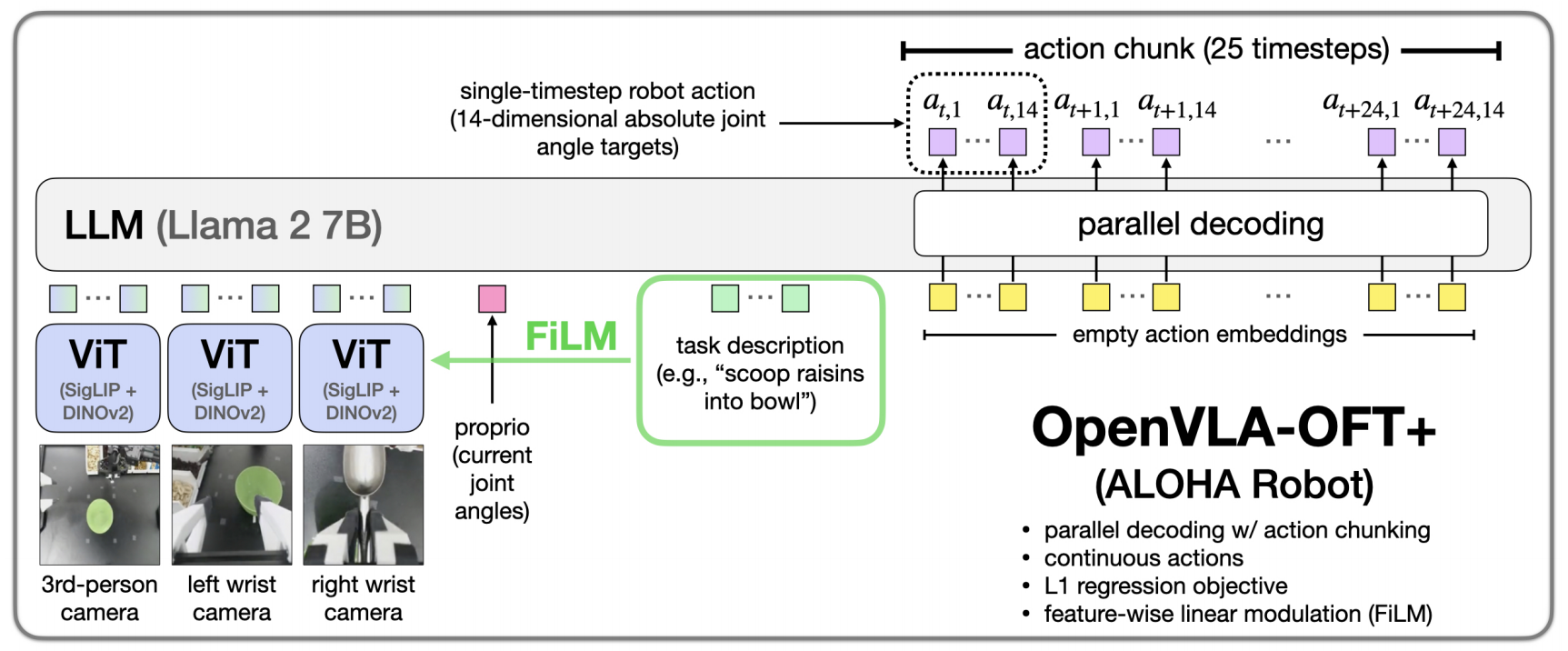
通過共享的 SigLIP-DINOv2 主干網絡處理多個輸入圖像(例如第三人稱圖像,加上腕部攝像機圖像)
下文《1.3 微調三大關鍵設計之外的:額外輸入輸出、FiLM》會再次提到——一個帶有GELU激活函數的三層MLP投影到語言模型嵌入空間
且通過帶有 GELU 激活的兩層MLP將機器人本體狀態投影到語言嵌入空間
下文《1.3 微調三大關鍵設計之外的:額外輸入輸出、FiLM》會再次提到——即低維的機器人狀態同樣通過一個帶有GELU激活函數的兩層MLP投影到語言嵌入空間 - 可選的FiLM,下文1.3.2節詳述
(適用于 OpenVLA-OFT+)添加了 FiLM [35] 模塊,該模塊使用任務語言嵌入的平均值來調制 SigLIP和 DINOv2 視覺變換器中的視覺特征(詳見附錄C)
最終,他們號稱在標準化的LIBERO模擬基準測試和真實雙手ALOHA機器人上的靈巧任務中進行了實驗
- 在LIBERO中
一方面,準確率高
OpenVLA-OFT通過在四個任務套件中達到97.1%的平均成功率,建立了新的技術標準,超越了微調的OpenVLA策略[22](76.5%),和π0策略[3](94.2%)
二方面,動作生成速度快
同時在動作生成中實現了26倍的速度提升(使用8步動作分塊),換言之,如果使用14步動作分塊,則可以實現14/8 × 26 = 45.5,也意味著更高的吞吐量 - 對于真實的ALOHA任務[53],通過FiLM[35]增強了他們的方案以增強語言基礎能力
1.1.2 相關工作:OpenVLA無法高頻、π0_FAST(推理慢/吞吐慢)、擴散VLA(訓練慢)
第一,以往的研究更關注什么呢?他們更關注模型開發
- 利用語言和視覺基礎模型來增強機器人能力,將其用作預訓練的視覺表示,從而加速機器人策略學習 [29-Vip,32-R3m,30-Liv,19-Language-driven representation learning for robotic,31]
在機器人任務中進行物體定位 [9,45]
以及用于高層次的規劃和推理
[1-SayCan,17,42-Progprompt,16-Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,43-Llmplanner: Few-shot grounded planning for embodied agents with large language models,18-Voxposer,6-Manipulate-anything] - 最近,研究人員探索了微調視覺-語言模型(VLMs)以直接預測低級別機器人控制動作,生成“視覺-語言-動作”模型(VLAs)
[4-RT-2,33-Open x-embodiment,23-Vision-language foundation models as effective robot imitators,22-Openvla,7-An interactive agent foundation model,15-An embodied generalist agent in 3d world,8-Introducing rfm-1: Giving robots human-like reasoning capabilities,50-Lingo-2,55-3dvla,51-Tinyvla,3-π0,2-Minivla]
這些模型展示了對分布外測試條件和未見語義概念的有效泛化能力
而OpenVLA-OFT的三位作者則專注于開發微調此類模型的流程,并通過從實證分析中獲得的見解來驗證每個設計決策的合理性
第二,相比OpenVLA,OpenVLA-OFT優勢是什么呢
- 據論文稱,盡管微調對于現實世界中的VLA部署至關重要,但關于有效微調策略的經驗分析仍然有限
Kim等人[22]研究了各種參數更新策略,并通過他們的研究發現,LoRA微調能夠有效適應單臂機器人在低控制頻率(<10Hz)下的操作,但OpenVLA的分析并未擴展到雙臂機器人在高控制頻率(25-50+ Hz)下的更復雜控制場景 - 而本次的研究,OpenVLA-OFT通過探索VLA適應設計決策,以實現快速推理和在具有25 Hz控制器的真實雙臂操控器上可靠的任務執行——這是第二點意義
第三,相比π0_FAST(推理慢),OpenVLA-OFT意義在于什么呢
- 盡管π0_FAST通過新的動作tokenization化方案改進了VLA 的效率,使用矢量量化或基于離散余弦變換的壓縮方法,以比簡單的逐維分箱——如RT-2 [4] 和OpenVLA [22] 中使用的,更少的token表示動作塊(動作序列)
- 盡管這些方法為自回歸VLA——π0_FAST 實現了2 到13× 的加速,但三位作者探索了超越自回歸建模的設計決策,而自回歸建模本質上受到迭代生成的限制
說白了,正因為OpenVLA和π0_FAST都屬于自回歸的VLA,所以他倆都無法實現很高頻的控制(比如50hz以上),也就都存在推理慢、吞吐慢、高延遲的問題
最終OpenVLA-OFT的并行解碼方法,與動作分塊結合時,實現了
? 顯著更高的加速:26× 到43× 的吞吐量
第四,與基于擴散的VLA(訓練慢)相比
盡管這些基于擴散的VLA通過同時生成多時間步的動作塊實現了比自回歸VLA更高的動作吞吐量,但它們因為訓練速度較慢以及推理時需要多次去噪或整合步驟,從而引入了計算上的權衡「they introduce compu-tational trade-offs through slower training and multiple denois-ing or integration steps at inference time」
- 此外,這些擴散VLA在架構、學習算法、視覺語言融合方法以及輸入輸出規范方面差異很大——哪些設計元素對性能影響最大仍不清楚
- 通過受控實驗,三位作者表明,使用更簡單的L1回歸目標微調的策略可以在任務性能上匹配更復雜的方法,同時顯著提高推理效率
1.2 微調VLA的三大關鍵設計:動作分塊下的并行解碼、連續動作表示、L1回歸
在涉及到微調VLA的三個關鍵設計決策之前,有三點 需要先特別說明下
首先,三位作者使用 OpenVLA [22] 作為他們代表性的基礎 VLA
- 如上文介紹過的,這是一種通過在 Open X-Embodiment 數據集 [33] 的 100 萬個episodes上對Prismatic VLM [20] 進行微調而創建的 7B 參數操控策略
- OpenVLA的原始訓練公式使用 7 個離散機器人動作token的自回歸預測,每個時間步有
它采用與語言模型類似的「交叉熵損失的下一個token預測」作為其學習目標
其次,先前的研究表明,動作分塊——即預測并執行一系列未來動作而無需中間重新規劃,在許多操作任務中提高了策略的成功率[53-ALOHA ACT, 5-Diffusion policy, 27-Bidirectional decoding]
- 然而,OpenVLA 的自回歸生成方案使得動作分塊變得不切實際,因為即使生成單個時間步的動作,在NVIDIA A100 GPU 上也需要0.33秒
- 對于塊大小為
個時間步和動作維度為D 的情況,OpenVLA 需要進行
次順序解碼器前向傳遞,而無需分塊時僅需
次
這種
最后,現有的方法使用基礎模型的自回歸訓練策略微調VLA時面臨兩個主要限制:
- 推理速度較慢(3-5 Hz),不適合高頻控制
- 以及在雙手操作器上的任務執行可靠性不足 [51-Tinyvla,26-Rdt-1b,3-π0]
為了解決這些挑戰,三位作者研究了VLA微調的三個關鍵設計組件:
- 動作生成策略(圖2,左):

比較了需要逐個token順序處理的自回歸生成,與同時生成所有動作并支持高效動作分塊的并行解碼 - 動作表示(圖2,右):
對通過基于 softmax 的token預測處理的離散動作(對歸一化動作進行 256 個分箱的離散化)與由多層感知機(MLP)動作頭直接生成的連續動作進行了比較
- 學習目標(圖2,右側)
比較了通過
L1回歸(L1 Regression)是一種回歸分析方法,它通過最小化預測值與真實值之間的絕對誤差(L1范數)來擬合模型
L1回歸的目標是最小化以下損失函數:
他們使用OpenVLA [22]作為基礎模型,并通過LoRA微調[14]對其進行適配,這是因為的訓練數據集相對較小(500個示例,相比于預訓練的1百萬個示例)
1.2.1 支持動作分塊的并行解碼
OpenVLA 最初采用自回歸生成離散動作token,并通過下一個token預測進行優化。三位作者實施了不同的微調設計決策,同時保持原始預訓練不變
第一,與需要按順序token預測的自回歸生成不同
- 并行解碼使模型能夠在一次前向傳遞中將輸入嵌入映射到預測的輸出序列「parallel decoding enables the model to map input embeddingsto the predicted output sequence in a single forward pass」
- 為此,三位作者修改了模型,使其接收空的動作嵌入作為輸入,并用雙向注意力替換因果注意力掩碼,從而使解碼器能夠同時預測所有動作
這將動作生成從D 次順序傳遞減少到一次傳遞,其中D 是動作的維度「This reduces action generation from D sequential passes to asingle pass, where D is the action dimensionality」
此外,并行解碼可以自然地擴展到動作分塊
- 為了預測多個未來時間步的動作,只需在解碼器的輸入中插入額外的空動作嵌入,這些嵌入隨后會被映射到未來的一組動作
- 對于分塊大小為 K 的情況,模型在一次前向傳遞中預測
個動作,吞吐量增加
雖然從理論上講,并行解碼可能不如自回歸方法那樣具有表現力,但三位作者的實驗表明,在各種任務中均未出現性能下降
在原始OpenVLA 自回歸訓練方案中,模型接收真實標簽動作token(向右偏移一個位置)作為輸入(這種設置稱為教師強制)
- 因果注意力掩碼確保模型僅關注當前和先前的token。在測試時,每個預測token會作為輸入反饋用于下一個預測
- 對于并行解碼,三位作者將此輸入替換為空的動作嵌入,這些嵌入僅在位置編碼值上有所不同「類似于[53-ALOHA ACT]」
且他們還使用了雙向注意力掩碼(而非因果掩碼),使模型在預測動作塊中的每個元素時可以非因果性地利用所有中間特征
1.2.2?連續動作表示
OpenVLA 最初使用離散動作token,其中每個動作維度被歸一化到[?1, +1] 并均勻離散化為256 個區間
- 雖然這種方法很方便,因為它不需要對底層VLM進行架構修改,但離散化過程可能會犧牲細粒度的動作細節
換言之,對于離散動作表示,增加用于離散化的分箱數量可以提高精度,但會降低單個token在訓練數據中的出現頻率,此舉會損害泛化能力 - 對此,三位作者研究了連續動作表示
1.2.3 提取「L1回歸和條件去噪擴散」的學習目標
連續動作表示之外,三位作者并從突出的模仿學習方法中提取了兩個學習目標
- L1 回歸,該動作頭直接將解碼器最后一層隱藏狀態映射到連續動作值
模型被訓練為最小化預測動作與真實動作之間的平均 L1 差異
同時保持并行解碼的效率優勢并可能提高動作精度 - 其次,受 Chi 等人[5] 的啟發,他們實現了條件去噪擴散(conditional denoising diffusion)建模
在訓練過程中,模型學習預測在前向擴散期間添加到動作樣本中的噪聲
在推理過程中,策略通過反向擴散逐漸去噪噪聲動作樣本以生成真實動作
雖然這種方法提供了可能更具表現力的動作建模,但它在推理期間需要多次前向傳遞(在三位作者的實現中為 50 次擴散步驟),即使使用并行解碼也會影響部署延遲
得益于使用連續動作表示,VLA可以直接建模動作分布而無需有損離散化。三位作者的連續表示實現中,使用以下規范
- L1回歸:MLP動作頭由4層帶有ReLU激活的層組成,將最終的Llama-2解碼器層隱藏狀態直接映射到連續動作
- 擴散:使用DDIM [44] 采樣器,具有50個擴散時間步,且遵循 [5,54] 的平方余弦β調度,此外,基于4層噪聲預測器,采用與L1回歸頭相同的MLP架構
1.3 微調三大關鍵設計之外的:額外的輸入及針對輸入的FiLM處理
1.3.1 額外的模型輸入:多視角圖像和機器人狀態
雖然原始 OpenVLA 處理單個攝像頭視圖,但一些機器人設置包括多個視角和額外的機器人狀態信息
故三位作者實現了一個靈活的輸入處理管道:
- 對于攝像頭圖像,三位作者使用 OpenVLA 的雙視覺編碼器提取每個視圖的 256 個patch嵌入,這些嵌入通過共享投影網絡被投影到語言嵌入空間
即將每個輸入圖像通過OpenVLA融合視覺編碼器處理,生成256個patch嵌入,這些嵌入通過一個帶有GELU激活函數的三層MLP投影到語言模型嵌入空間 - 對于低維機器人狀態輸入(例如關節角度和夾持器狀態),三位作者使用單獨的投影網絡將這些映射到與攝像頭圖像相同的嵌入空間——從而作為另一個輸入嵌入
即低維的機器人狀態同樣通過一個帶有GELU激活函數的兩層MLP投影到語言嵌入空間
所有輸入嵌入——視覺特征、機器人狀態和語言token——在傳遞給解碼器之前沿序列維度進行連接。這種統一的潛在表示使模型能夠在生成動作時關注所有可用信息
且結合并行解碼和動作分塊,這種架構可以高效處理豐富的多模態輸入,同時生成多時間步的動作
1.3.2(可選) 使用 FiLM 增強 OpenVLA-OFT 的語言基礎能力(使模型更加關注語言輸入)
當在 ALOHA 機器人設置中部署時,包含來自腕部安裝攝像頭的多個視角,三位作者觀察到由于視覺輸入中的偽相關性,策略可能難以跟隨語言
- 在訓練過程中,策略可能會在預測動作時學習依賴這些偽相關性,而不是正確關注語言指令,導致在測試時無法很好地遵循用戶的命令
- 此外,語言輸入可能僅在任務的特定時刻是關鍵的——例如,在“將X 舀入碗中”任務中,抓住勺子后決定舀取哪種成分,如第 VI 節所述
因此,如果沒有特殊技術,訓練模型適當地關注語言輸入可能特別具有挑戰性
為了增強語言跟隨能力
- 三位作者采用了特征線性調制FiLM[35],它將語言嵌入注入到視覺表示中,以使模型更加關注語言輸入
we employ feature-wise linear modulation (FiLM) [35], which infuses languageembeddings into the visual representations so that the modelpays more attention to the language inputs. - 怎么實現呢?三位作者計算任務描述中的語言嵌入
?的平均值,并將其投影以獲得縮放和偏移向量
?和
,這些向量通過仿射變換調制視覺特征F
We compute the average of the language embeddings x from the task description and project it to obtain scaling and shifting vectors γ and β. These vectors modulate the visual features F through an affine transformation
一個關鍵的實現細節是選擇什么去ViT中調制(對應的視覺)” 特征”。盡管人們可能自然地考慮將單個patch 嵌入作為需要調制的特征,但三位作者發現這種方法會導致較差的語言跟隨能力
相反,借鑒FiLM 在卷積網絡中的操作方式,其中調制通過縮放和偏移整個特征圖來空間無關地進行,他們將 和
的每個元素應用于所有視覺patch 嵌入中的對應隱藏單元,從而使
和
影響所有patch 嵌入「we apply each element of γ and β to the corresponding hidden unit across all visual patch embeddings so that γ and β influence all patch embeddings」
- 具體來說,這使得γ 和β 成為
維向量「別忘了,這兩個向量怎么來的——任務描述中的語言嵌入
- 三位作者在每個ViT塊的自注意力層之后和前饋層之前應用 FiLM,每個塊都有單獨的投影器
具體如下圖所示,在OpenVLA的融合視覺主干中,將FiLM[35]集成到SigLIP[52]和DINOv2[34] ViT中
通過在每個transformer塊中進行縮放和偏移操作,平均任務描述嵌入對視覺特征進行調制,從而增強語言與視覺的集成。這一修改顯著提高了ALOHA任務中的語言跟隨能力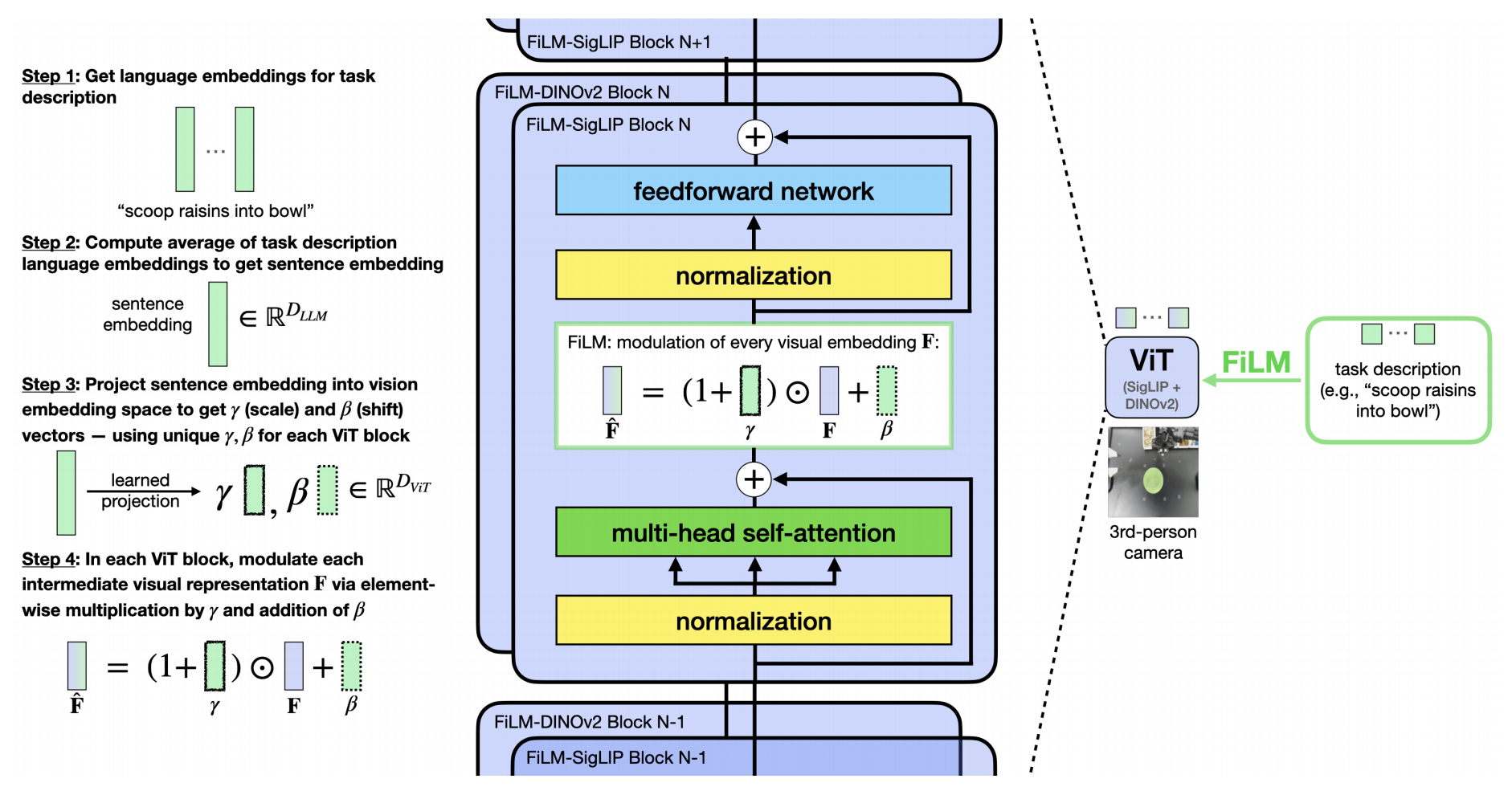
且三位作者遵循Perez 等人[35] 的做法,他們將F 乘以(1 + γ) 而不是γ,因為在初始化時γ 和β接近于零。這有助于在微調開始時保留視覺編碼器的原始激活,最小化對預訓練表示的擾動
實現細節上
- 將語言嵌入投影為 γ 和 β 的函數 f(x) 和h(x) 被實現為簡單的仿射變換。為每個transformer學習了單獨的投影器,以允許塊特定的調制模式。這種設計使模型能夠在視覺特征處理的不同層次學習不同的調制模式
- 可能有人最初會考慮獨立調制每個patch嵌入,而不是像第 IV-C 節討論的那樣調制每個嵌入的每個隱藏維度
然而,他們的空間無關調制方法更接近 FiLM 在卷積網絡中的操作,其中調制在空間維度上全局應用,因為特征圖的整個部分由 γ 和 β 的單個元素進行縮放和偏移
這種設計選擇更好地保留了 FiLM 的優勢,并顯著改善了策略的語言理解能力。且發現,一種獨立調制每個patch嵌入的替代形式導致了較弱的語言理解能力最后,他們僅在第 VI 節討論的 ALOHA 實驗中使用 FiLM,在這些實驗中,多個攝像機視角導致視覺輸入中存在更多的虛假相關性
1.4 對VLA微調設計決策的評估
根據原論文,下面將通過旨在回答三個關鍵問題的控制實驗,評估他們提出的 VLA 適配設計決策的效果
- 每個設計決策如何影響微調策略在下游任務上的成功率
- 每個設計決策如何影響模型推理效率(動作生成吞吐量和延遲)
- 替代的微調形式如何影響模型輸入輸出規范的靈活性
1.4.1?LIBERO 實驗設置:4個任務套件,每個套件10個任務
在 LIBERO 模擬基準 [25] 上進行評估,該基準包含一個 Franka Emika Panda 機械臂模擬,演示數據包括相機圖像、機器人狀態、任務注釋和末端執行器位姿變化的動作
他們使用四個任務套件——LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和LIBERO-Long,每個套件提供 10 個任務的 500 個專家演示,用于評估策略在不同空間布局、物體、目標
根據Kim 等人[22] 的方法,他們篩選出不成功的示范,并通過LoRA [14] 獨立地對每個任務集微調OpenVLA
- 針對非擴散方法訓練50 ?150 K 次梯度步
對于擴散方法(收斂較慢)訓練100 ?250 K 次梯度步
并使用跨8 個A100/H100 GPU 的64-128 的批量大小 - 每隔50K 步測試一次檢查點,并報告每次運行的最佳性能。除非另有說明,策略接收一張第三人稱圖像和語言指令作為輸入
- 對于使用動作分塊的方法,將塊大小設置為K = 8,以匹配Diffusion Policy 基線[5],并在重新規劃前執行完整的塊,這一設置被發現可以同時提高速度和性能。超參數的詳細信息見附錄D
1.4.2?LIBERO任務性能比較
為了實現令人滿意的部署,機器人策略必須展示出可靠的任務執行能力
三位作者首先評估不同的VLA微調設計決策如何影響LIBERO基準測試中的成功率。根據效率分析顯示,并行解碼PD和動作分塊AC對于高頻控制(25-50+ Hz)是必要的,特別是對于具有雙倍動作維度的雙臂機器人
因此,他們評估了同時使用這兩種技術的OpenVLA策略,并比較了使用離散動作、帶L1回歸的連續動作以及帶擴散的連續動作的變體
下表表I的結果顯示「1?對比了包括從預訓練基礎模型 (Octo, DiT Policy, Seer,π0) 微調的策略,從頭訓練的模型 (Diffusion Policy, Seer (scratch), MDT),以及使用不同微調設計決策的 OpenVLA 變體:并行解碼 (PD)、動作分塊 (AC,塊大小 K=8 步長)、以及帶有 L1 回歸的連續動作 (Cont-L1) 或擴散 (Cont-Diffusion)。2 本研究中的 OpenVLA 結果是對每個任務套件 (10 個任務 × 50 個實驗) 平均 500 次試驗的結果。最終,帶有額外輸入的完整 OpenVLA-OFT 方法實現了 97.1% 的平均成功率,達到了最先進的水平。基線結果來自原始論文,除了 Diffusion Policy、Octo 和原始 OpenVLA 策略的結果由 Kim 等人[22] 報告。加粗和下劃線的值分別表示最佳和次優性能」
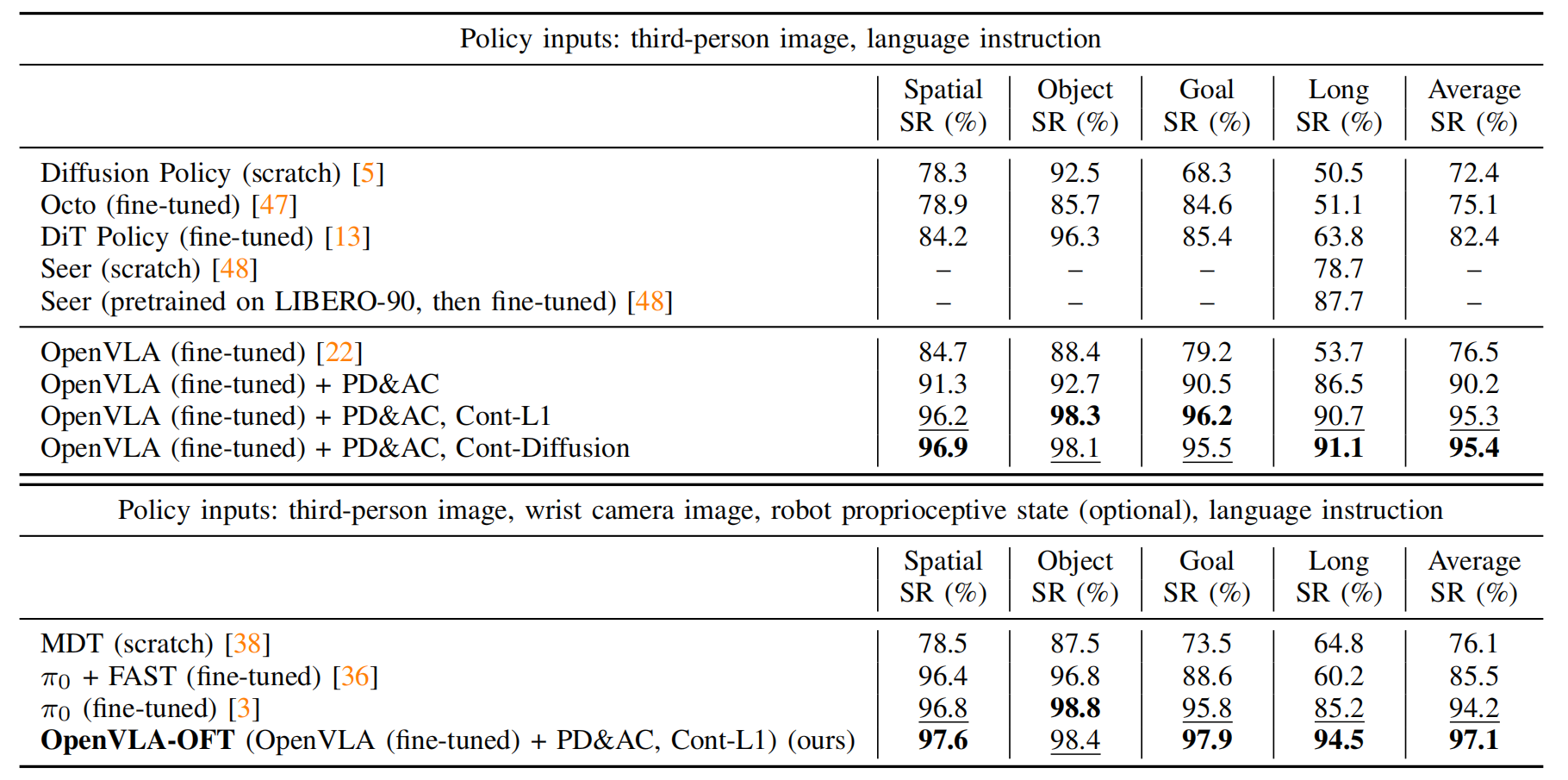
- 并行解碼和動作分塊不僅提高了吞吐量,還顯著提升了性能,使得自回歸OpenVLA策略的平均成功率絕對提高了14%。這一改進在LIBERO-Long中尤為顯著,這表明動作分塊有助于捕獲時間依賴性[27]并減少復合錯誤[39],最終導致更平滑和更可靠的任務執行
- 此外,談發現使用連續動作變體相較于離散動作變體,成功率進一步提高了 5%(絕對值),這可能是由于動作預測的精度更高所致
- L1回歸和擴散變體表現相當,這表明高容量的OpenVLA模型即使使用簡單的L1回歸也能有效建模多任務動作分布
1.4.3?LIBERO 推理效率比較
高效的推理對于在高頻控制機器人上部署 VLAs 至關重要。故原論文中評估了并行解碼(PD)、動作分塊(AC)和連續動作表示如何影響模型推理速度
- 他們通過在 NVIDIA A100 GPU 上對每種模型變體進行 100 次查詢來測量平均延遲(生成一個機器人動作或動作塊所需的時間)和吞吐量(每秒生成的總動作數)
- 每次查詢處理一個 224 x 224 像素的圖像和一個示例 LIBERO 語言指令(“拾起alphabet soup并將其放入籃子中”)
下表表II 中的結果表明「1 針對對 7 維動作的動作生成吞吐量和延遲,平均在 NVIDIA A100 GPU 上的 100 次查詢中得出結果。每次查詢處理一個 224 × 224 像素的圖像和一個 LIBERO 任務指令(“拾起字母湯并將其放入籃子”)。2 比較了使用并行解碼(PD)、動作分塊(K=8 個時間步長)以及使用 L1 回歸或擴散目標的連續動作的 OpenVLA 變體。最后一行添加了腕部攝像頭圖像和機器人狀態輸入。加粗和下劃線的值分別表示最佳和次優性能」

- 通過將策略中解碼器部分的 7 次順序前向傳遞替換為單次傳遞,并行解碼將延遲降低了 4 倍,并將吞吐量提高了 4 倍
Results in Table II show that parallel decoding reduces latency and increases throughput by 4× by replacing 7 se-quential forward passes through the decoder portion of the policy with a single pass - 添加動作分塊(K = 8)會使延遲增加 17%,這是由于解碼器中的注意力序列變長所致,但當與并行解碼結合使用時,它能顯著提高吞吐量,比基準 OpenVLA 快 26 倍
- 帶有 L1 回歸的連續動作變體在效率方面幾乎沒有差異,因為額外的 MLP 動作頭僅增加了極少量的計算量
擴散變體需要50個去噪步驟,因此延遲增加了3倍。然而,通過并行解碼和分塊,它的吞吐量仍然比基線OpenVLA高出2倍
這意味著盡管動作塊之間的暫停時間更長,擴散變體仍然比原始自回歸變體更快地完成機器人操作周期
1.4.4?模型輸入輸出的靈活性
并行解碼使得OpenVLA能夠以最小的延遲增加生成動作塊,從而提高模型輸出的靈活性。且并行解碼和動作塊的顯著加速為處理額外的模型輸入也創造了余地
接下來,通過對OpenVLA進行微調,添加機器人本體狀態等額外輸入來證明這一點
機器人腕部安裝的相機圖像,這使得傳遞到語言模型解碼器的視覺patch嵌入數量翻倍,從256增加到512
- 盡管輸入序列長度大幅增加,微調后的OpenVLA策略仍然保持高吞吐量(71.4 Hz)和低延遲(0.112秒),如表II所示
- 通過在LIBERO基準上使用額外的輸入評估這些策略,顯示出所有任務套件的平均成功率進一步提高(表I)
- 值得注意的是,改進的經過微調的OpenVLA策略甚至超過了最佳微調的π0策略[3,36]——這些策略得益于具有更大規模預訓練和更復雜學習目標(流匹配[24])的基礎模型——以及多模態擴散變換器(MDT)[38]
- 即使使用比最近的VLA更少數據預訓練的簡單基礎模型,他們發現他們的替代VLA適應設計決策使得微調的OpenVLA策略能夠在LIBERO基準上建立新的技術水平
第二部分 將OpenVLA適配于現實世界的ALOHA機器人
雖然上面第一部分的實驗結果表明OpenVLA-OFT在模擬中的有效性,但在現實世界中成功部署在與預訓練階段所見機器人平臺有顯著差異的機器人上,對于展示廣泛的適用性至關重要
- 因此,三位作者還評估了他們優化后的微調方法在ALOHA機器人環境[53]中的效果,這是一種實際的雙手操作平臺,以高控制頻率運行
- 他們在新穎的靈巧操作任務上進行了評估,這些任務在OpenVLA的預訓練階段(僅涉及單臂機器人數據)中從未遇到過
- 先前的研究[51-Tinyvla,26-Rdt-1b,3-π0]表明,使用自回歸VLA[22-Openvla]進行原始LoRA微調對于此類任務是不切實際的,因為其吞吐量(單臂機器人為3-5 Hz,雙臂任務甚至更低)遠低于實時部署所需的25-50Hz
因此,他們在實驗中排除了這一基線,并將其與稍后討論的更有效方法進行比較
在論文的該部分中,三位作者介紹了增強版本的VLA微調方案(OFT+),該方案額外包括特征線性調制(FiLM)以增強語言基礎
最終,他們將通過此增強微調方案實例化的OpenVLA策略記為OpenVLA-OFT+
2.1?ALOHA 實驗設置
2.1.1?ALOHA與OpenVLA硬件設置的不同
ALOHA 平臺由兩個 ViperX 300 S 機械臂、三個相機視角(一個俯視視角和兩個安裝在手腕上的視角)以及機器人狀態輸入(14 維關節角度)組成。其運行頻率為 25 Hz(從原始的 50 Hz 降低,以實現更快的訓練,同時仍保持平滑的機器人控制),動作表示目標絕對關節角度
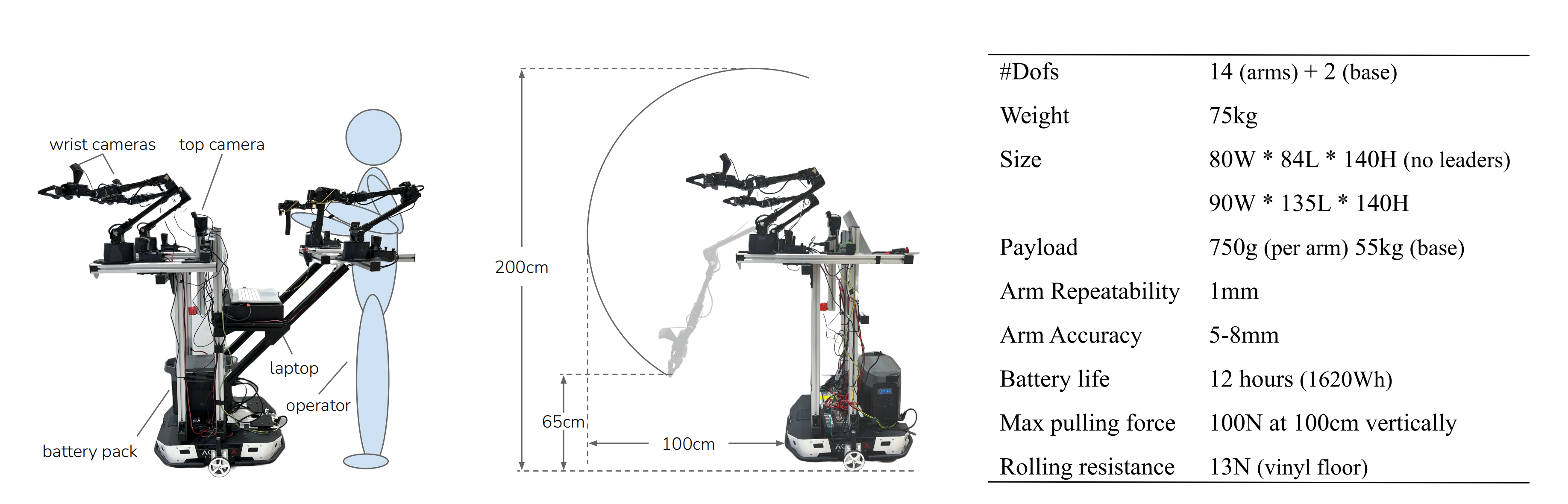
此設置與 OpenVLA 的預訓練顯著不同,后者僅包括單臂機器人數據、來自第三人稱相機的單一視角、無機器人狀態輸入、低頻率控制(3-10 Hz),以及相對末端執行器的姿態動作。 這種分布的變化給該模型的適應性帶來了挑戰
2.1.2?4個代表性任務:折疊短褲、折疊T恤、將X舀入碗中、將X放入鍋中
他們設計了四個代表性任務,用于測試可變形物體操作、長時間技能、工具使用和基于語言的控制:
- “折疊短褲”:在桌子上使用連續的雙手折疊動作折疊白色短褲
訓練:20次示范(19次訓練 一次驗證)
事件長度:1000步長(40s)
評估:10次試驗
初始狀態:下圖圖9
- “折疊T恤”:通過多次同步的雙手折疊動作折疊白色T恤,測試接觸豐富的長時間操作
訓練:30次演示(29次訓練,1次驗證)
情節長度:1250步,50s
評估:10次試驗 - “將X舀入碗中”:用左臂將碗移至桌子中央,用右臂使用金屬勺舀取指定的原料(“葡萄干”、“杏仁和綠色M&M巧克力”或“椒鹽脆餅”)
訓練:45次演示(每種原料15次,42個用于訓練,3個用于驗證)
情節步長:900,36s
評估:12次試驗(每種原料4次) - “將X放入鍋中”:用左臂打開鍋蓋,用右臂放置指定物品(“青椒”、“紅椒”或“黃玉米”),然后關閉鍋蓋
訓練:300次演示(每個物體100次,總計285次訓練,15次驗證)
評估:24次試驗(12次分布內,12次分布外)
這個相對較大的演示數量并不是為了達到令人滿意的性能所必需的。這僅僅反映了這項工作的早期調查階段,在該階段三位作者遇到了在學習的策略中進行語言對接的困難,并最初假設增加演示數量可能會提高語言跟隨能力。然而,單純擴展訓練集不足以實現令人滿意的語言對接,三位作者發現需要額外的技術來實現更可靠的語言對接,比如FiLM。盡管如此,他們仍然決定使用包含300個演示的完整數據集進行微調
為了完成上述任務,他們使用OFT+ 對OpenVLA 在每個任務上獨立進行微調,進行50 ?150 K 次梯度步驟(總批量大小為32,使用8 個A100/H100-80GB GPU),動作塊大小為K = 25
且在推理時,在重新查詢模型以獲取下一個塊之前,先執行完整的動作塊
2.2 各個方法的PK:OpenVLA-OFT+/RDT/π0/ACT/diffusion policy
ALOHA 任務對OpenVLA 作為基礎模型提出了顯著的適應性挑戰,因為在控制頻率、動作空間和輸入模態方面,它與OpenVLA的預訓練平臺存在顯著差異
2.2.1 與VLA 模型RDT-1B?和π0 之間的對比PK
基于此,三位作者將OpenVLA-OFT+ 與最近的VLA 模型RDT-1B [26] 和π0 [3]進行比較,這些模型在雙手操作數據上進行了預訓練,并可能在這些下游任務中表現得更好
且三位作者按照原作者推薦的微調方法對這些模型進行評估,這些方法作為重要的比較基準
- RDT-1B微調的超參數見表 VIII
RDT-1B 的作者建議訓練 150K 次梯度步長,但由于三位作者的微調數據集比 RDT-1B 的微調數據集小得多,三位作者觀察到訓練在顯著較少的步長內就收斂了
因此,他們發現沒有必要訓練如此長的時間
事實上,在“將 X舀入碗中”這一任務上,較早的 18K 步長檢查點(73.3% 成功率)優于較晚的 40K 步長檢查點(70.0%)——我們在 ALOHA 實驗中報告的是前者 - π0 的訓練細節見表 IX
三位作者使用完整微調(其代碼庫中的默認選項)并訓練至收斂
2.2.2 與ACT和Diffusion Policy的對比PK
此外,為了提供與計算效率較高的替代方法的比較,三位作者評估了兩個流行的模仿學習基線:ACT[53] 和Diffusion Policy [5],它們在每項任務上從零開始訓練
為了在這些基線方法中啟用語言跟隨,三位作者使用了跟隨語言的實現
- 對于ACT,三位作者修改了EfficientNet-B0[46-Efficientnet: Rethinking model scaling for convolutional neural networks]
且通過FiLM [35-Film: Visual reasoning with a general conditioning layer,41-Yell at your robot: Improving on-the-fly from language corrections,詳見此文《YAY Robot——斯坦福和UC伯克利開源的:人類直接口頭喊話從而實時糾正機器人行為(含FiLM詳解)》]處理CLIP [37]語言嵌入
下表表 VII 列出了從頭開始為每個任務訓練的 ACT [53] 的超參數
當然了,他們僅將此FiLM-EfficientNet實現用于與語言相關的任務,即
最后,ACT 的作者建議訓練至少 5K 個周期,而三位作者將每個任務的訓練擴展到 10K-70K 個周期以提高性能 - 對于Diffusion Policy,三位作者使用了DROID數據集[21-Droid: A large-scale in-the-wild robot manipulation dataset]的實現,該實現將動作去噪條件設定為基于DistilBERT [40]的語言嵌入,并修改以支持雙手控制和多圖像輸入
下表表 VII 中列出了超參數
2.3?ALOHA任務性能結果
三位作者評估了所有方法——ACT、Diffusion Policy、RDT-1B、π0和OpenVLA-OFT+——在他們4個ALOHA任務上的表現
為了提供精細的評估,三位作者使用了一個預定的評分標準,該標準為部分任務完成分配分數(詳見附錄F)
圖4展示了綜合性能分數「OpenVLA-OFT+通過并行解碼、動作分塊、連續動作、L1回歸以及用于語言基礎的FiLM [35]增強了基礎模型。微調的VLA模型始終優于從頭開始的方法,其中OpenVLA-OFT+達到了最高的平均性能」
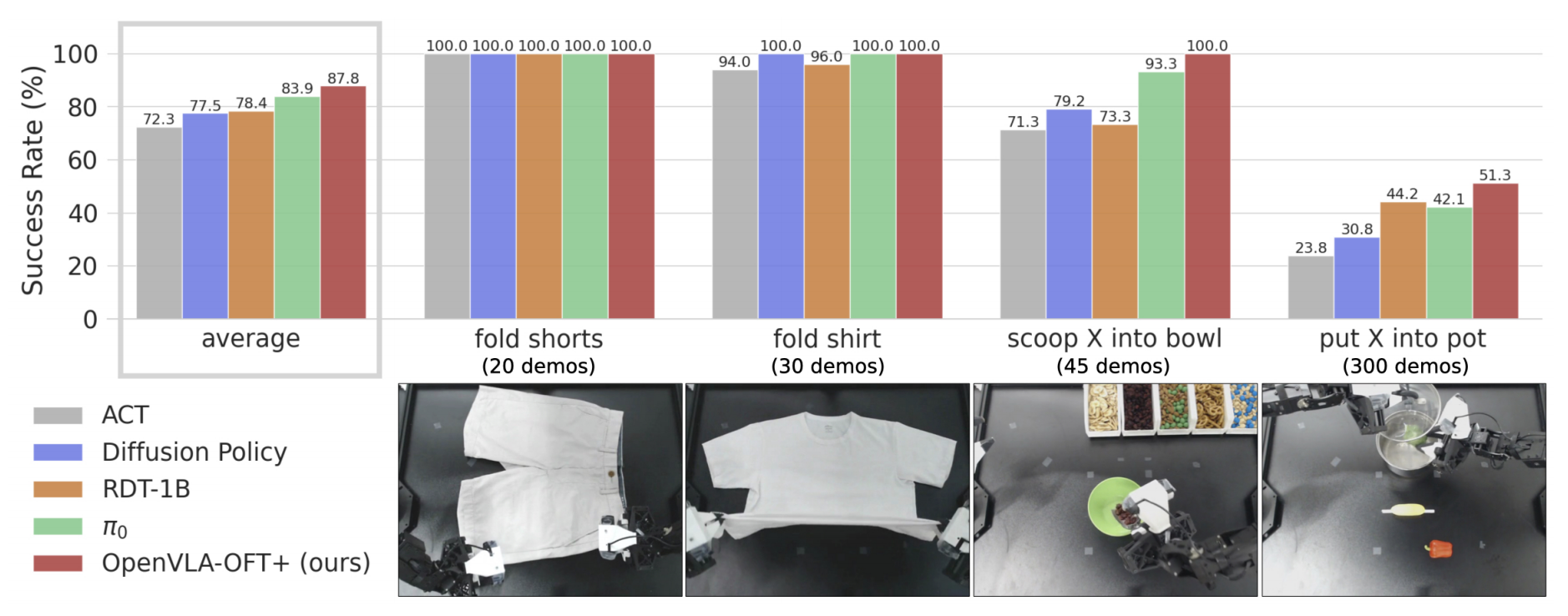
2.3.1 非VLA基線的性能
從頭開始訓練的基線方法表現出不同程度的成功
- ACT雖然能夠完成基本任務,但其產生的動作不夠精確,總體表現最低
- 擴散策略展示了更強的能力,在折衣服和舀取任務中與RDT-1B的可靠性相匹配或超過。然而,它在“將X放入鍋中”任務中表現不佳,該任務具有更大的訓練數據集,這表明相比基于VLA的方法,其可擴展性有限
2.3.2 微調的VLA的性能
微調的VLA策略在任務執行和語言跟隨方面通常優于從頭開始的基線,與之前的研究結果一致[26-Rdt-1b,3]
在VLA中,三位作者觀察到不同的特點:
- RDT-1B通過其“交替條件注入”方案[26-Rdt-1b]實現了良好的語言跟隨,但顯示出在處理閉環反饋方面的局限性
如圖7 所示,它經常無法糾正” 將X 舀入碗中” 任務中的錯誤——例如,在錯過實際碗后繼續將材料倒入一個想象中的碗中,這表明其對本體感受狀態的依賴超過了視覺反饋
- 另一方面,π0 展現了更穩健的執行能力,動作更流暢,對反饋的反應更靈敏,經常能夠從初始失敗中成功恢復(如圖7 所示)
盡管其語言理解能力稍微落后于RDT-1B,π0 實現了更好的整體任務完成能力,使其成為最強的基線模型
- 最后,OpenVLA-OFT+ 在任務執行和語言理解兩方面都達到了最高性能(有關成功任務展開的示例,請參見圖6)
當然,值得注意的是,因為基礎OpenVLA 模型僅在單臂數據上進行了預訓練,而RDT-1B 和π0 分別在大量雙臂數據集上進行了預訓練(6 K 個任務和8 K 小時的雙臂數據)
這表明,微調技術可能比預訓練數據的覆蓋范圍對下游性能更為關鍵
2.3.3?FiLM的消融研究
三位作者通過消融并評估其對他們OpenVLA-OFT+方法中策略語言跟隨能力的重要性來進行研究,這些策略在最后兩個任務中需要良好的語言基礎才能成功執行
如圖5所示——專門跟蹤了語言依賴任務的語言跟隨能力「微調的 VLA 比從頭訓練的策略更頻繁地遵循用戶的命令。OpenVLA-OFT+ 展示了最強的語言基礎,然而移除 FiLM [35] 將成功率降低到隨機水平」,在這兩個任務中,OpenVLA-OFT+語言跟隨能力下降到33%——相當于隨機選擇正確的指令
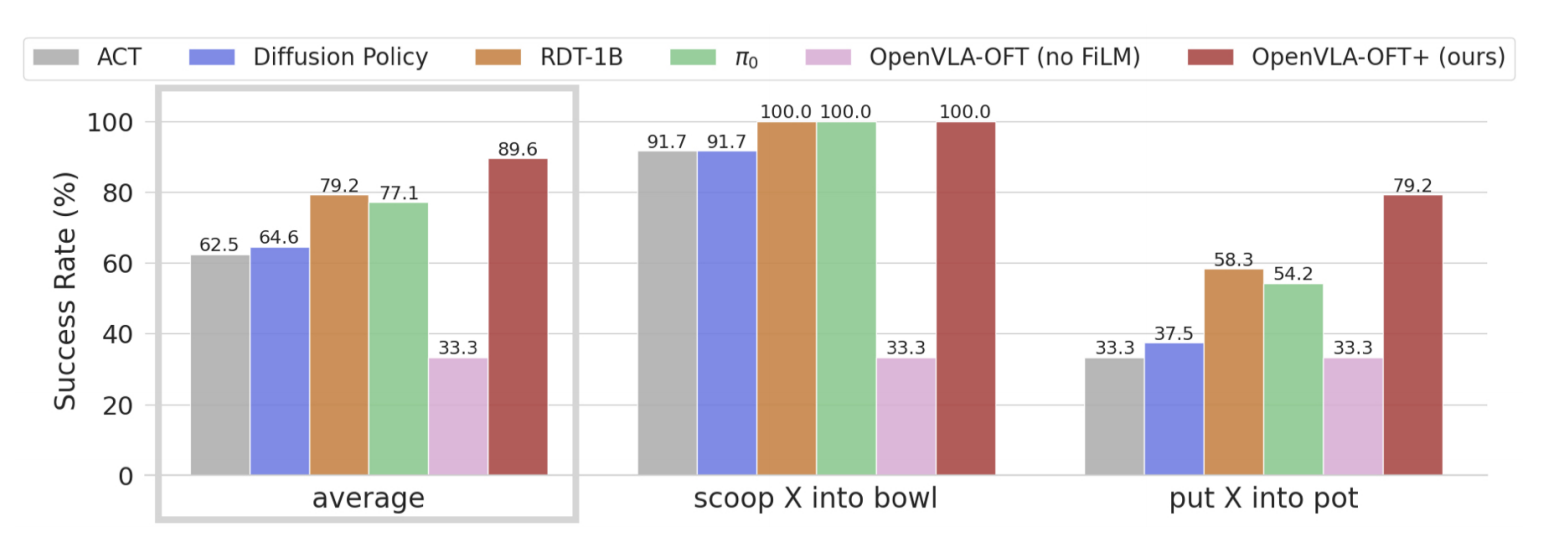
這表明 FiLM 對于防止模型過度擬合于虛假視覺特征以及確保對語言輸入的恰當關注至關重要
2.4?ALOHA 推理效率比較
三位作者通過測量每100個查詢的動作生成吞吐量和延遲來評估推理效率
他們在表III中報告了結果「1?吞吐量和延遲測量基于在NVIDIA A100 GPU上進行的100次查詢的平均值。每次查詢處理三張224 × 224像素的圖像、14維機器人狀態和一個任務命令(“將葡萄干舀入碗中”)。2 所有方法使用動作塊大小K=25,除了DiffusionPolicy(K=24,因為需要是4的倍數)和原始的OpenVLA(K=1,無塊化)。RDT-1B預測64個動作,但為了公平比較,他們只執行前25個動作。所有實現都使用PyTorch,除了π0(使用JAX)。加粗和下劃線的值表示最佳和次優性能」
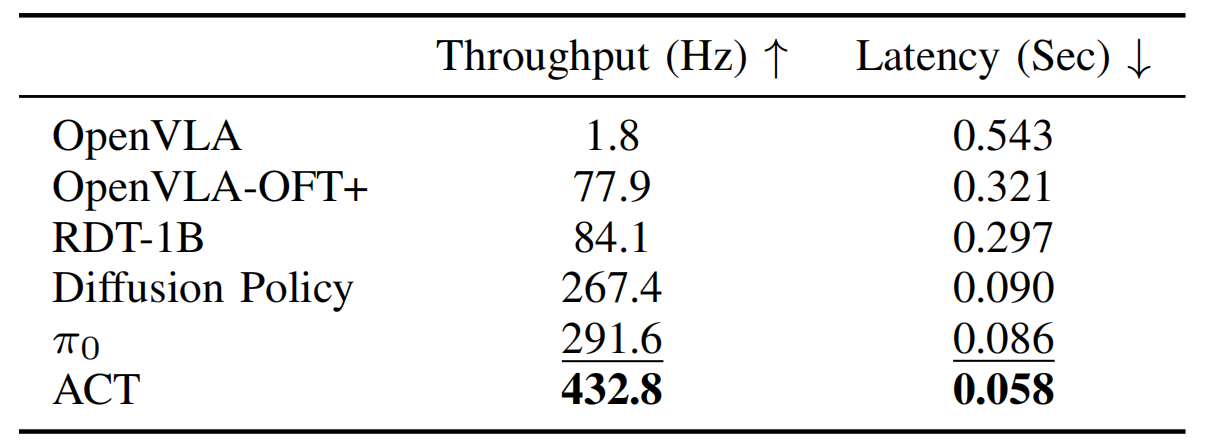
- 即使加入了額外的手腕攝像頭輸入,原始的OpenVLA公式表現出較低的效率,吞吐量為1.8 Hz,延遲為0.543秒
- 相比之下,OpenVLA-OFT+實現了77.9 Hz的吞吐量,盡管與之前LIBERO實驗中的策略相比,其延遲較高,因為它需要處理兩個額外的輸入圖像
其他方法展示了更高的吞吐量由于其較小的架構:ACT(84M參數)、DiffusionPolicy(157M)、RDT-1B(1.2B)和π0(3.3B)——而OpenVLA擁有7.5B參數
- ACT通過結合基于L1回歸的單次動作生成(類似于OpenVLA-OFT+)及其緊湊架構,實現了最高速度
- 此外,盡管其規模更大,π0仍然由于其優化的JAX實現(所有其他方法均以PyTorch實現),在速度方面同時超過了RDT-1B和Diffusion Policy
- 值得注意的是,OpenVLA-OFT+ 的吞吐量(77.9 Hz)接近RDT-1B的(84.1 Hz),盡管其大小是后者的7倍,因為它通過單次前向傳遞生成動作,而不像RDT-1B那樣需要多個去噪步驟
2.5 總結與不足
最后,引用原論文的闡述總結一下
- 對VLA微調設計決策的研究揭示了不同組件如何影響推理效率、任務性能、模型輸入輸出的靈活性以及語言跟隨能力
這些見解形成了他們的優化微調(OFT)方案,該方案通過并行解碼、動作分塊、連續動作、L1回歸和(可選的)FiLM語言條件化,實現了VLA在新機器人和任務上的有效適應 - OFT的成功在OpenVLA上尤其值得注意:盡管在預訓練期間沒有接觸過雙手機器人或多視圖圖像輸入,使用OFT微調的OpenVLA能夠適應此類配置,并能匹配甚至超越遇到過雙手操控器和多輸入圖像的更近期的基于擴散的VLA(π0和RDT-1B)
這表明,一個設計良好的微調方案對最終性能可以有顯著影響,且現有的VLA可以在不從頭開始大量重新訓練的情況下成功適應新的機器人系統 - 三位作者的研究結果表明,基于簡單L1回歸的方法結合高容量模型(如OpenVLA)在適應新型機器人和任務方面非常有效
與基于擴散的方法相比,這種方法具有實際優勢:更簡單的算法可以加快訓練收斂和推理速度,同時保持較強的性能,這使其特別適合于實際的機器人應用
盡管OFT方法在將VLA適配到新型機器人和任務方面表現出潛力,但仍存在一些重要問題需要解決
- 處理多模態演示
三位作者的實驗使用了針對每個任務具有統一策略的聚焦演示數據集。雖然 L1 回歸可能通過鼓勵策略學習演示動作中的中位數模式來幫助平滑訓練演示中的噪聲,但它可能難以準確地對存在多個有效動作的相同輸入的真正多模態動作分布進行建模,這在生成替代動作序列對任務完成有益的情況下可能不是理想的選擇
相反,基于擴散的方法可能更好地捕捉這種多模態性,但存在過度擬合訓練數據中次優模式的風險(有關這些細微差別的討論和視頻演示,請訪問該項目的網站)。了解 OFT 在多模態演示中的有效性是未來工作的一個重要方向 - 預訓練與微調
三位作者的研究特別關注為下游任務微調視覺語言模型。OFT 的優勢是否能有效地延伸到預訓練,或者對于大規模訓練是否需要更強大的算法如擴散模型,這需要進一步的研究 - 不一致的語言對齊
三位作者的 ALOHA 實驗表明,沒有 FiLM 的 OpenVLA 在語言對齊方面表現不佳,盡管在 LIBERO 模擬基準實驗中并未出現此類問題。造成這種差異的原因——無論是由于預訓練中缺乏雙手數據還是其他因素——仍不清楚,需要進一步研究
// 待更

)







)
)

)


零基礎入門系列第二篇:項目創建和初始化)


)
)