解決的問題
Multi-Head Latent Attention,MLA——解決的問題:KV cache帶來的計算效率低和內存需求大以及上下文長度擴展問題。
MLA原理
MLA原理:其核心思想是將鍵(Key)和值(Value)矩陣壓縮到一個低維的"潛在"空間中,從而顯著減少KV緩存的內存占用。與傳統MHA相比,MLA不直接存儲完整的鍵值矩陣,而是存儲一個維度更小的壓縮向量。在需要進行注意力計算時,再通過解壓縮重構出所需的鍵和值(減少了權重矩陣要學習的參數量)。這種壓縮-解壓縮機制使得模型可以在顯著減少內存占用的同時,保持甚至提升性能。DeepSeek-V2的技術報告顯示,MLA使KV緩存減少了93.3%,訓練成本節省了42.5%,生成吞吐量提高了5.76倍。在8個H800 GPU上實際部署時,實現了超過50,000令牌每秒的生成速度,這一數據充分證明了MLA的高效性。
步驟
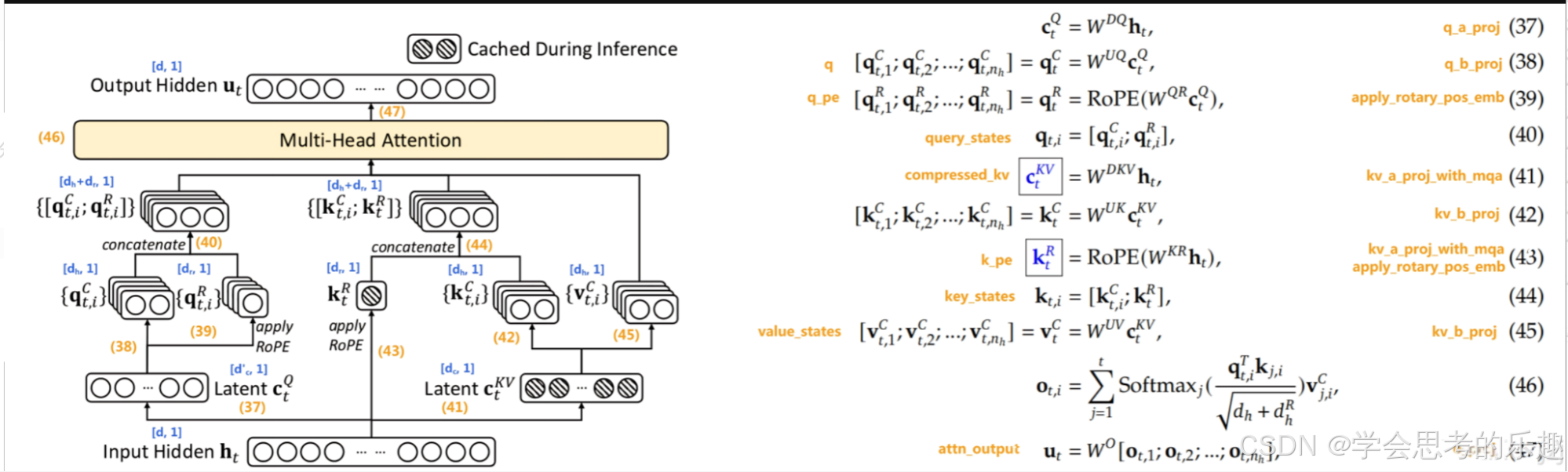
首先壓縮Q即公式(37)。
從5120先降維再升維,好處是相比直接使用大小為 [5120, 24576] 的矩陣# [5120, 1536] * [1536, 24576] 這樣的低秩分解在存儲空間和計算量上都大幅度降低維降到1536維?。也就是(37)-(40)模型所要學習的矩陣。
# 對隱藏狀態進行線性投影和歸一化,生成查詢張量q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states))) # 調整查詢張量的形狀q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)

?解壓縮C并拆分,即(38)、(39)和(40)
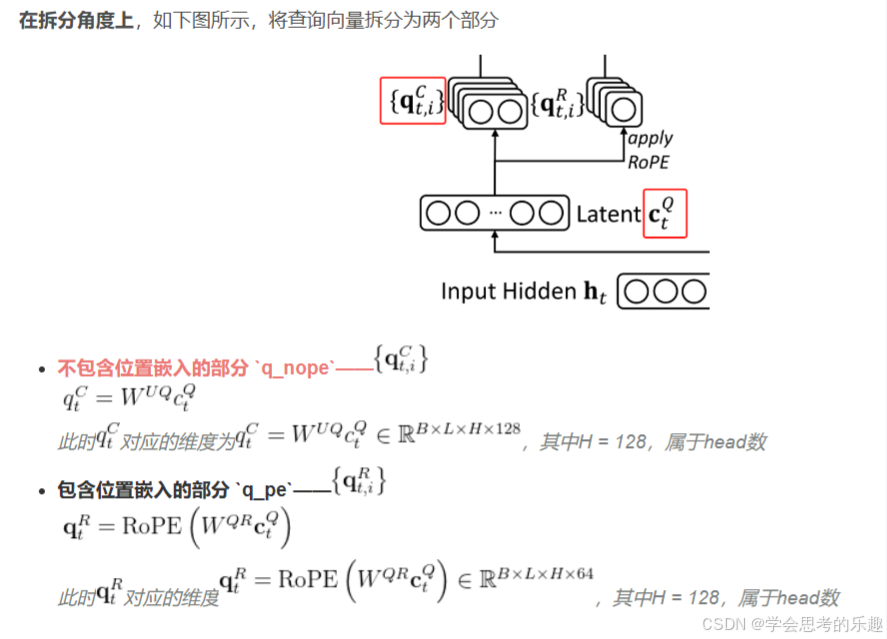

q_nope, q_pe = torch.split(# 將查詢張量拆分為不包含位置嵌入的部分和包含位置嵌入的部分q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1 )
?對KV張量的降維、分裂K、拆分KV且升維
具體的代碼涉及公式(41) kv_a_proj_with_mqa 和 公式(42)kv_b_proj 兩個參數矩陣。?

升維之后計算注意力?
?給q_pe, k_pe給加上rope且合并,然后做標準注意力計算。
這一部分也涉及一個權重矩陣:?o_proj,大小 [num_heads * v_head_dim, hidden_size] = [128*128, 5120]

?將查詢和鍵張量 `q_pe` 和 `k_pe` 進行旋轉
# 計算旋轉位置嵌入的余弦和正弦值cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) # 應用旋轉位置嵌入q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
?接著,方法創建新的查詢狀態張量 `query_states` ,然后將旋轉后的部分和不包含位置嵌入的部分合并便可得到最終的Q向量
# 創建新的查詢狀態張量query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)# 將不包含位置嵌入的部分賦值給查詢狀態張量query_states[:, :, :, : self.qk_nope_head_dim] = q_nope# 將包含位置嵌入的部分賦值給查詢狀態張量query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
?K相似操作。
關于矩陣吸收十倍提速


這里不用展開計算的意思我理解為就是不需要再單獨升維計算,UK矩陣被吸收后直接與降維壓縮的K相乘即可。?這樣減少了中間變量的存儲,提高了計算效率。
# 以下和原本實現相同bsz, q_len, _ = hidden_states_q.size()q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states_q)))q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)kv_seq_len = compressed_kv.size(1)compressed_kv, k_pe = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)k_pe = k_pe.view(bsz, 1, kv_seq_len, self.qk_rope_head_dim)# 從 kv_b_proj 中分離的 W^{UK} 和 W^{UV} 兩部分,他們要分別在不同的地方吸收kv_b_proj = self.kv_b_proj.weight.view(self.num_heads, -1, self.kv_lora_rank)q_absorb = kv_b_proj[:, :self.qk_nope_head_dim,:]#W^{UK}out_absorb = kv_b_proj[:, self.qk_nope_head_dim:, :]#W^{UV}cos, sin = self.rotary_emb(q_pe)q_pe = apply_rotary_pos_emb(q_pe, cos, sin, q_position_ids)# !!! 關鍵點,W^{UK} 即 q_absorb 被 q_nope(W^{UQ}) 吸收q_nope = torch.einsum('hdc,bhqd->bhqc', q_absorb, q_nope) # 吸收后 attn_weights 直接基于 compressed_kv 計算不用展開。attn_weights = torch.matmul(q_pe, k_pe.transpose(2, 3)) + torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv)attn_weights *= self.softmax_scale?![]()
#原始順序
v_t = einsum('hdc,blc->blhd', W_UV, c_t_KV) # (1)
o = einsum('bqhl,blhd->bqhd', attn_weights, v_t) # (2)
u = einsum('hdD,bhqd->bhD', W_o, o) # (3)# 將上述三式合并,得到總的計算過程
u = einsum('hdc,blc,bqhl,hdD->bhD', W_UV, c_t_KV, attn_weights, W_o)
#改變順序
# 利用結合律改變計算順序
o_ = einsum('bhql,blc->bhqc', attn_weights, c_t_KV) # (4)#將注意力權重attn_weights與壓縮的鍵-值矩陣c_t_KV相乘,直接得到一個更緊湊的中間結果o_。
o = einsum('bhqc,hdc->bhqd', o_, W_UV) # (5)#將中間結果o_與權重矩陣W_UV相乘,得到o
u = einsum('hdD,bhqd->bqD', W_o, o) # (6)#將權重矩陣W_o與o相乘,得到最終輸出u總結
MLA不直接存儲完整的鍵值矩陣,而是存儲一個維度更小的壓縮向量。在需要進行注意力計算時,再通過解壓縮重構出所需的鍵和值
1.減少了權重矩陣要學習的參數量。2.通過矩陣吸收減少了中間需要解壓后的K和V的矩陣,減少了中間存儲數據量提高了計算效率。
與其他注意力機制的比較
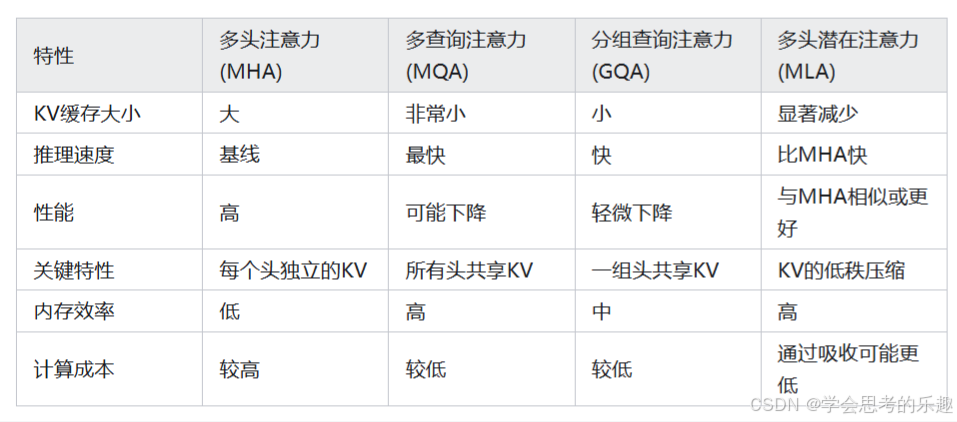
參考說明
[1]????????[深度剖析Deepseek 多頭潛在注意力(MLA) - 知乎
[2]MLA實現及其推理上的十倍提速——逐行解讀DeepSeek V2中多頭潛在注意力MLA的源碼(圖、公式、代碼逐一對應)_mla加速 csdn-CSDN博客
[3]DeepSeek-V2 高性能推理 (1):通過矩陣吸收十倍提速 MLA 算子 - 知乎





)
跨阻放大器簡單仿真)












