
文章目錄
Spark運行架構與MapReduce區別
一、Spark運行架構
二、Spark與MapReduce區別
Spark運行架構與MapReduce區別
一、Spark運行架構
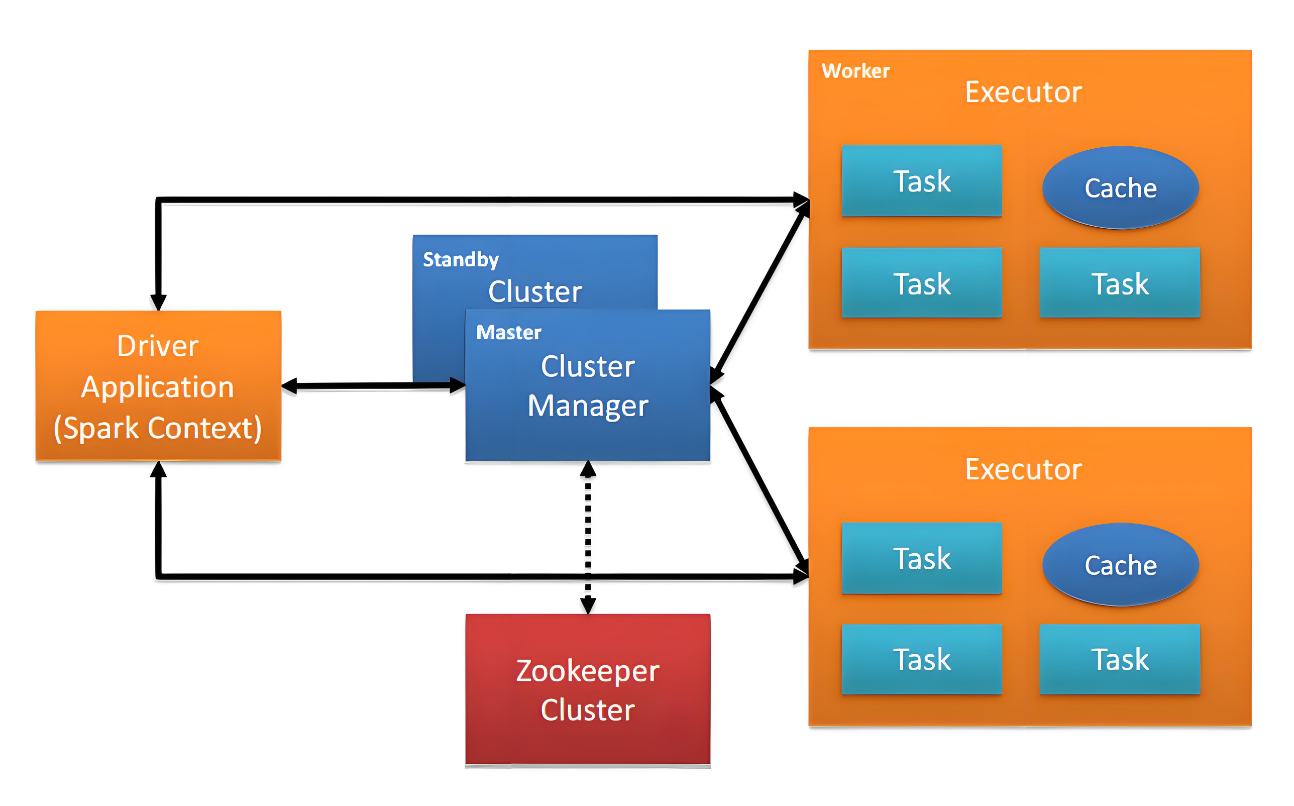
- Master:Spark集群中資源管理主節點,負責管理Worker節點。
- Worker:Spark集群中資源管理的從節點,負責任務的運行。
- Application:Spark用戶運行程序,包含Driver端和在各個Worker運行的Executor端。
- Driver:用來連接Worker的程序,Driver可以將Task發送到Worker節點處理這些數據。每個Spark Application都有獨立的Driver,Driver負責任務(Tasks)的分發和結果回收。如果task的計算結果非常大就不要回收了,可能會造成oom。
- Executor:Worker節點上運行的進程,負責執行Task,將數據存儲在內存或者磁盤中,并將結果返回給Driver。每個Application都有各自獨立的一批Executors。
- Task:被發送到某個Executor上的工作單元。
二、Spark與MapReduce區別
Apache Spark 和 Hadoop MapReduce 都是用于大規模數據處理的分布式計算框架,但它們在架構設計、數據處理方式和應用場景等方面存在顯著差異。以下是兩者的主要區別:
1) 數據處理方式
MapReduce:采用基于磁盤的處理方式,每個任務的中間結果需要寫入磁盤,然后再讀取進行下一步處理。這種方式增加了磁盤 I/O 操作,導致處理速度較慢。
Spark:利用內存進行數據處理,將中間結果存儲在內存中,減少了磁盤讀寫操作,從而顯著提高了處理速度。特別是在需要多次迭代計算的場景下,Spark 的性能優勢更加明顯。
2) 編程模型
MapReduce:提供了相對低級的編程接口,主要包含 Map 和 Reduce 兩個操作,開發者需要編寫較多的代碼來實現復雜的數據處理邏輯。
Spark:提供了更高級的編程接口,如 RDD(彈性分布式數據集)和 DataFrame,支持豐富的操作算子,使得開發者可以以更簡潔的方式編寫復雜的處理邏輯。此外,Spark支持SQL處理批/流數據。
3) 任務調度
MapReduce:采用多進程模型,每個Task任務作為一個獨立的JVM進程運行。
Spark:采用多線程模型,在同一個進程中管理多個Task任務,資源調度更為高效。
4) 資源申請
MapReduce:采用細粒度資源調度,每個 MapReduce Job 運行前申請資源,Job運行完釋放資源。如果一個Application中有多個 MapReduce Job,每個Job獨立申請和釋放資源。
Spark:采用粗粒度資源調度。Application運行前,為所有的Spark Job申請資源,所有Job執行完成后,統一釋放資源。
5) 數據處理能力
MapReduce:主要用于批處理任務,不適合實時數據處理。
Spark:適用于批量/實時數據處理。通過 SparkStreaming 和 StructuredStreaming 模塊,支持實時數據流處理。
6) 容錯機制
MapReduce:通過將中間結果寫入磁盤,實現任務失敗后的重試和恢復。
Spark:采用 RDD 的血統(lineage)機制,記錄數據集的生成過程。當節點發生故障時,Spark 可以根據血統信息重新計算丟失的數據分區,實現高效的容錯。
- 📢博客主頁:https://lansonli.blog.csdn.net
- 📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
- 📢本文由 Lansonli 原創,首發于 CSDN博客🙉
- 📢停下休息的時候不要忘了別人還在奔跑,希望大家抓緊時間學習,全力奔赴更美好的生活??





)



)








核心技術解析)
)