Spring-IOC部分
1.SpringBean的配置詳解(Bean標簽)
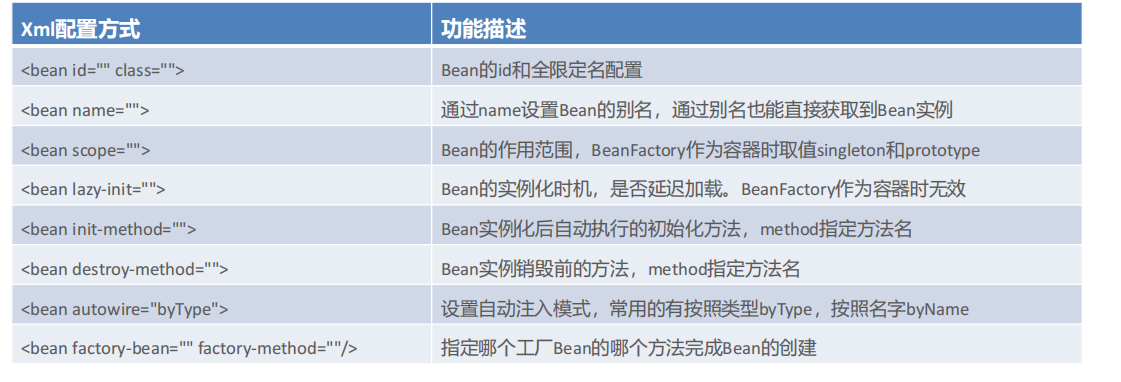
(1)scope
默認情況下,單純的Spring環境Bean的作用范圍有兩個:Singleton和Prototype
singleton:單例,默認值,Spring容器創建的時候,就會進行Bean的實例化,并存儲到容器內部的單例池中,每次getBean時都是從單例池中獲取相同的Bean實例;
prototype:原型,Spring容器初始化時不會創建Bean實例,當調用getBean時才會實例化Bean,每次getBean都會創建一個新的Bean實例。生成的Bean不會存在單例池中
(2)lazy-init
當lazy-init設置為true時為延遲加載,也就是當Spring容器創建的時候,不會立即創建Bean實例,等待用到時在創建Bean實例并存儲到單例池中去,后續在使用該Bean直接從單例池獲取即可,本質上該Bean還是單例的
(3)init-method
可以在Bean中創建一個成員方法init,在Bean被實例化之后執行,或者實現InitializingBean 接口重寫afterPropertiesSet方法
(4)Bean實例化配置
1.構造方式實例化:底層通過構造方法對Bean進行實例化
-
無參構造
-
有參構造
<bean id="userDao" class="com.itheima.dao.impl.UserDaoImpl"><constructor-arg name="name" value="haohao"/> </bean>
2.工廠方式實例化:底層通過調用自定義的工廠方法對Bean進行實例化
-
靜態工廠方法實例化Bean
靜態工廠方法實例化Bean,其實就是定義一個工廠類,提供一個靜態方法用于生產Bean實例,在將該工廠類及其靜態方法配置給Spring即可
//工廠類 public class UserDaoFactoryBean {//非靜態工廠方法public static UserDao getUserDao(String name){//可以在此編寫一些其他邏輯代碼return new UserDaoImpl();} }<bean id="userDao" class="com.itheima.factory.UserDaoFactoryBean" factory-method="getUserDao"><constructor-arg name="name" value="haohao"/> </bean>- 靜態工廠方法是一個普通的靜態方法,它負責創建并返回一個對象實例。
- 靜態工廠方法本身不會被 Spring 容器管理,因為它是一個靜態方法,不屬于任何 Spring Bean。
-
實例工廠方法實例化Bean
<!-- 配置實例工廠Bean --> <bean id="userDaoFactoryBean2" class="com.itheima.factory.UserDaoFactoryBean2"/> <!-- 配置實例工廠Bean的哪個方法作為工廠方法 --> <bean id="userDao" factory-bean="userDaoFactoryBean2" factory-method="getUserDao"><constructor-arg name="name" value="haohao"/> </bean> -
實現FactoryBean規范延遲實例化Bean
public interface FactoryBean<T> {String OBJECT_TYPE_ATTRIBUTE = “factoryBeanObjectType”;T getObject() throws Exception; //獲得實例對象方法Class<?> getObjectType(); //獲得實例對象類型方法default boolean isSingleton() {return true;} }public class UserDaoFactoryBean3 implements FactoryBean<UserDao> {public UserDao getObject() throws Exception {return new UserDaoImpl();}public Class<?> getObjectType() {return UserDao.class;} }<bean id="userDao" class="com.itheima.factory.UserDaoFactoryBean3"/>Spring容器創建時,FactoryBean被實例化了,并存儲到了單例池singletonObjects中,但是getObject() 方法尚未被執行,UserDaoImpl也沒被實例化,當首次用到UserDaoImpl時,才調用getObject() ,此工廠方式產生的Bean實例不會存儲到單例池singletonObjects中,會存儲到 factoryBeanObjectCache 緩存池中,并且后期每次使用到userDao都從該緩存池中返回的是同一個userDao實例。
(5)Bean的依賴注入配置
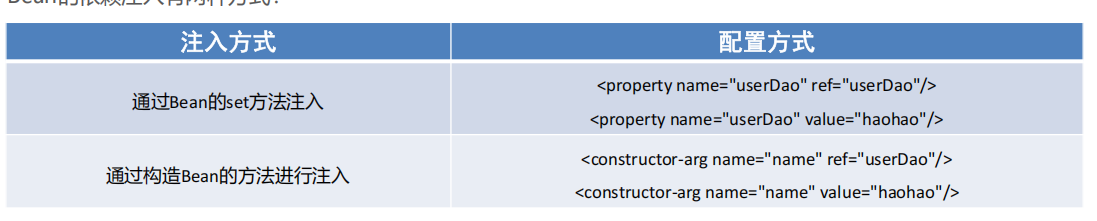
構造器方法注入就和使用有參構造器實例化Bean的方式一樣
自動裝配
如果被注入的屬性類型是Bean引用的話,那么可以在 標簽中使用 autowire 屬性去配置自動注入方式,屬性值有兩個:
byName:通過屬性名自動裝配,即去匹配 setXxx 與 id=“xxx”(name=“xxx”)是否一致;
byType:通過Bean的類型從容器中匹配,匹配出多個相同Bean類型時,報錯。
<bean id="userService" class="com.itheima.service.impl.UserServiceImpl" autowire="byType">
基于注解的依賴注入
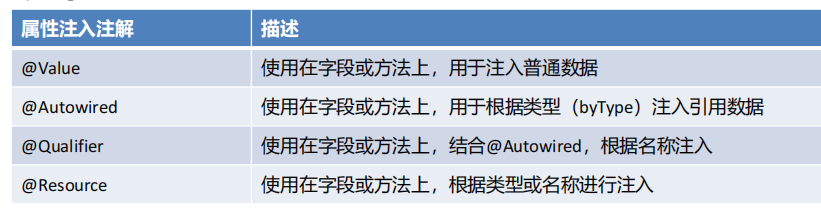
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.username}")
public void setUsername(String username){
System.out.println(username);
}//使用在屬性上直接注入
@Autowired
private UserDao userDao;
//使用在方法上直接注入
@Autowired
public void setUserDao(UserDao userDao){
System.out.println(userDao);
}@Autowired
@Qualifier("userDao2")
private UserDao userDao;//@Resource注解既可以根據類型注入,也可以根據名稱注入,無參就是根據類型注入,有參數就是根據名稱注入 是javax包下
@Resource
private UserDao userDao;
@Resource(name = "userDao2")
public void setUserDao(UserDao userDao){
System.out.println(userDao);
}
(6)Spring其他的配置標簽
Spring 的 xml 標簽大體上分為兩類,一種是默認標簽,一種是自定義標簽
-
默認標簽:就是不用額外導入其他命名空間約束的標簽,例如 標簽.
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> </beans>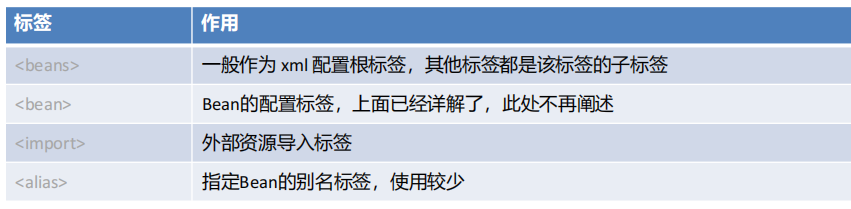
-
自定義標簽:就是需要額外引入其他命名空間約束,并通過前綴引用的標簽,例如 context:property-placeholder/ 標簽
在使用注解開發中,使用@Component注解代替標簽,其他標簽就可以定義一個配置類來替代原有的xml配置文件
@Configuration注解標識的類為配置類,替代原有xml配置文件,該注解第一個作用是標識該類是一個配置類,第二個作用是具備@Component作用
@ComponentScan 組件掃描配置,替代原有xml文件中的<context:component-scan base-package=“”/>
@PropertySource 注解用于加載外部properties資源配置,替代原有xml中的<context:property placeholder location=“”/>配置
@Import 用于加載其他配置類,替代原有xml中的配置
(7)基于注解配置
除了使用xml進行配置,還可以使用注解配置,在Bean類上使用注解@Component注解,value屬性指定當前Bean實例的beanName,也可以省略不寫,不寫的情況下為當前類名首字母小寫。
需要在xml文件中進行配置
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/xmlSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"><!-- 告知Spring框架去itheima包及其子包下去掃描使用了注解的類 --><context:component-scan base-package="com.itheima"/>
</beans>
//獲取方式:applicationContext.getBean("userDao");
@Component("userDao")
public class UserDaoImpl implements UserDao {
}
//獲取方式:applicationContext.getBean("userDaoImpl");
@Component
public class UserDaoImpl implements UserDao {
}
xml配置和注解的對應
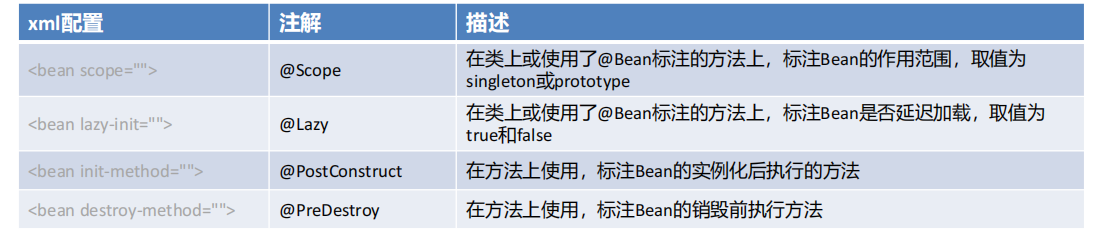
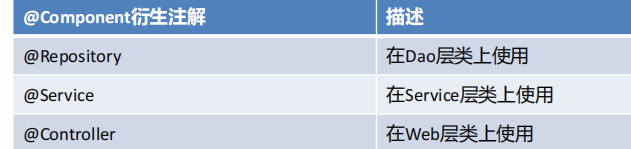
為了每層Bean標識的注解語義化更加明確,@Component又衍生出如下三個注解
(8)Spring配置其他注解
@Primary注解用于標注相同類型的Bean優先被使用權,@Primary 是Spring3.0引入的,與@Component和@Bean一起使用,標注該Bean的優先級更高,則在通過類型獲取Bean或通過@Autowired根據類型進行注入時,會選用優先級更高的
注解 @Profile 標注在類或方法上,標注當前產生的Bean從屬于哪個環境,只有激活了當前環境,被標注的Bean才能被注冊到Spring容器里,不指定環境的Bean,任何環境下都能注冊到Spring容器里
2.Spring的get方法

3.Spring配置非自定義Bean(第三方提供的Bean)
配置非自定義的Bean需要考慮如下兩個問題:
- 被配置的Bean的實例化方式是什么?無參構造、有參構造、靜態工廠方式還是實例工廠方式;
- 被配置的Bean是否需要注入必要屬性。
以MyBatis為例
原始代碼
//加載mybatis核心配置文件,使用Spring靜態工廠方式
InputStream in = Resources.getResourceAsStream(“mybatis-conifg.xml”);
//創建SqlSessionFactoryBuilder對象,使用Spring無參構造方式
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//調用SqlSessionFactoryBuilder的build方法,使用Spring實例工廠方式
SqlSessionFactory sqlSessionFactory = builder.build(in);
用xml配置
<!--靜態工廠方式產生Bean實例-->
<bean id=“inputStream” class=“org.apache.ibatis.io.Resources” factory-method=“getResourceAsStream”><constructor-arg name=“resource” value=“mybatis-config.xml/>
</bean>
<!--無參構造方式產生Bean實例-->
<bean id="sqlSessionFactoryBuilder" class="org.apache.ibatis.session.SqlSessionFactoryBuilder"/>
<!--實例工廠方式產生Bean實例-->
<bean id="sqlSessionFactory" factory-bean="sqlSessionFactoryBuilder" factory-method="build"><constructor-arg name="inputStream" ref="inputStream"/>
</bean>
用注解配置
//將方法返回值Bean實例以@Bean注解指定的名稱存儲到Spring容器中
@Bean("dataSource")
public DataSource dataSource(){DruidDataSource dataSource = new DruidDataSource();dataSource.setDriverClassName("com.mysql.jdbc.Driver");dataSource.setUrl("jdbc:mysql://localhost:3306/mybatis");dataSource.setUsername("root");dataSource.setPassword("root");return dataSource;
}
工廠方法所在類必須要被Spring管理
如果需要注入參數的話,@Autowired可以省略
@Bean
@Autowired //根據類型匹配參數
public Object objectDemo01(UserDao userDao){System.out.println(userDao);return new Object();
}
@Bean
public Object objectDemo02(@Qualifier("userDao") UserDao userDao,
@Value("${jdbc.username}") String username){System.out.println(userDao);System.out.println(username);return new Object();
}
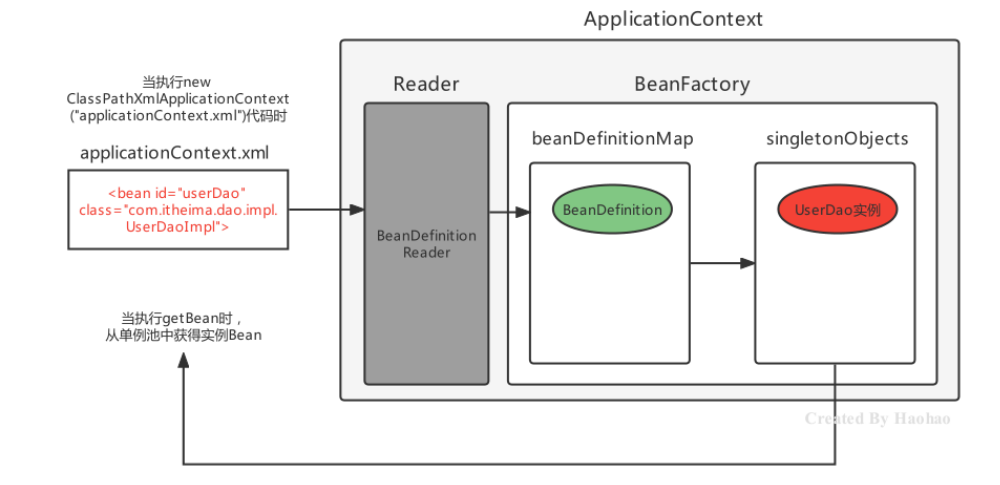
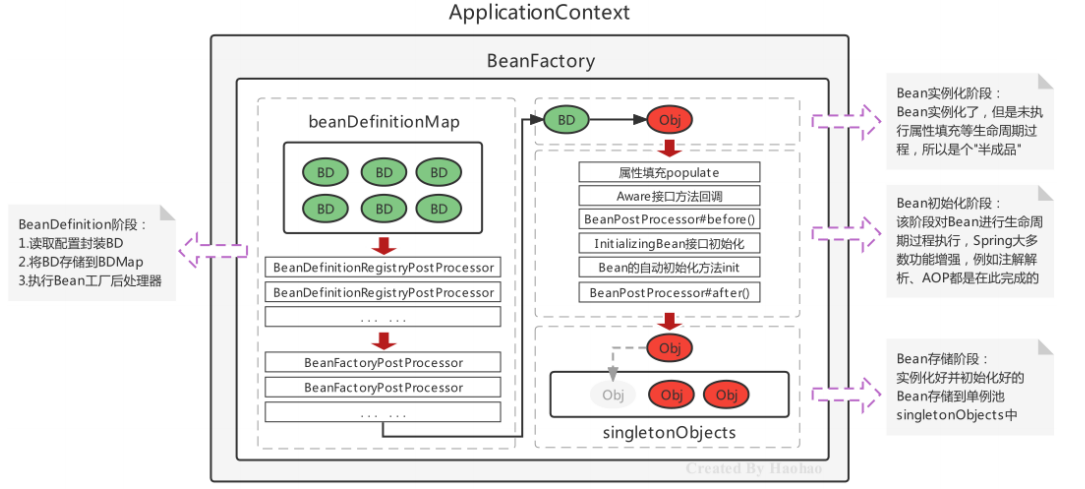
4.Bean實例化的基本流程
Spring容器在進行初始化時,會將xml配置的的信息封裝成一個BeanDefinition對象,所有的BeanDefinition存儲到一個名為beanDefinitionMap的Map集合中去,Spring框架在對該Map進行遍歷,使用反射創建Bean實例對象,創建好的Bean對象存儲在一個名為singletonObjects的Map集合中,當調用getBean方法時則最終從該Map集合中取出Bean實例對象返回。
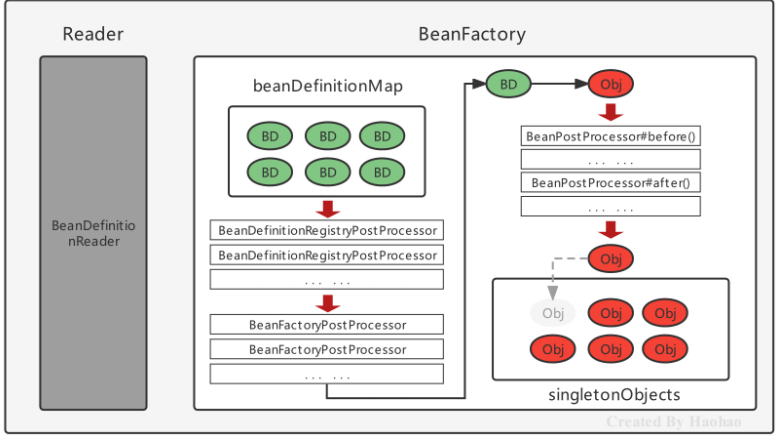
5.Spring的后處理器
Spring的后處理器是Spring對外開發的重要擴展點,允許我們介入到Bean的整個實例化流程中來,以達到動態注冊BeanDefinition,動態修改BeanDefinition,以及動態修改Bean的作用。Spring主要有兩種后處理器:
-
BeanFactoryPostProcessor:Bean工廠后處理器,在BeanDefinitionMap填充完畢,Bean實例化之前執行;
BeanFactoryPostProcessor是一個接口規范,實現了該接口的類只要交由Spring容器(xml文件中用bean配置)管理的話,那么Spring就會回調該接口的方法,用于對BeanDefinition注冊和修改的功能。
public interface BeanFactoryPostProcessor {void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory); }可以動態修改BeanDefinition(修改class,修改初始化方法,是否懶加載)
Spring 提供了一個BeanFactoryPostProcessor的子接口BeanDefinitionRegistryPostProcessor專門用于注冊BeanDefinition操作
public class MyBeanFactoryPostProcessor2 implements BeanDefinitionRegistryPostProcessor {@Overridepublic void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {}@Overridepublic void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanDefinitionRegistry) throws BeansException {BeanDefinition beanDefinition = new RootBeanDefinition();beanDefinition.setBeanClassName("com.itheima.dao.UserDaoImpl2");beanDefinitionRegistry.registerBeanDefinition("userDao2",beanDefinition);} }這個對象本身也會交給spring容器管理,進入到單例池中
-
BeanPostProcessor:Bean后處理器,一般在Bean實例化之后,填充到單例池singletonObjects之前執行。
Bean被實例化后,到最終緩存到名為singletonObjects單例池之前,中間會經過Bean的初始化過程,例如:屬性的填充、初始方法init的執行等,其中有一個對外進行擴展的點BeanPostProcessor,我們稱為Bean后處理
public interface BeanPostProcessor {@Nullable//在屬性注入完畢,init初始化方法執行之前被回調default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {return bean;}@Nullable//在初始化方法執行之后,被添加到單例池singletonObjects之前被回調default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {return bean;} }這個對象本身也會交給spring容器管理,進入到單例池中

6.Spring的生命周期
Spring Bean的生命周期是從 Bean 實例化之后,即通過反射創建出對象之后,到Bean成為一個完整對象,最終存儲到單例池中,這個過程被稱為Spring Bean的生命周期。Spring Bean的生命周期大體上分為三個階段:
- Bean的實例化階段:Spring框架會取出BeanDefinition的信息進行判斷當前Bean的范圍是否是singleton的,是否不是延遲加載的,是否不是FactoryBean等,最終將一個普通的singleton的Bean通過反射進行實例化;
- Bean的初始化階段:Bean創建之后還僅僅是個"半成品",還需要對Bean實例的屬性進行填充、執行一些Aware接口方法、執行BeanPostProcessor方法、執行InitializingBean接口的初始化方法、執行自定義初始化init方法等。該階段是Spring最具技術含量和復雜度的階段,Aop增強功能,后面要學習的Spring的注解功能等、spring高頻面試題Bean的循環引用問題都是在這個階段體現的;
- Bean的完成階段:經過初始化階段,Bean就成為了一個完整的Spring Bean,被存儲到單例池singletonObjects中去了,即完成了Spring Bean的整個生命周期。
初始化階段主要設計以下幾個過程:
- Bean實例的屬性填充
- Aware接口屬性注入
- BeanPostProcessor的before()方法回調
- InitializingBean接口的初始化方法回調
- 自定義初始化方法init回調
- BeanPostProcessor的after()方法回調
(1)Bean的實例屬性填充
Spring在進行屬性注入時,會分為如下幾種情況:
-
注入普通屬性,String、int或存儲基本類型的集合時,直接通過set方法的反射設置進去;
-
注入單向對象引用屬性時,從容器中getBean獲取后通過set方法反射設置進去,如果容器中沒有,則先創建被注入對象Bean實例(完成整個生命周期)后,在進行注入操作;
-
注入雙向對象引用屬性時,就比較復雜了,涉及了循環引用(循環依賴)問題,下面會詳細闡述解決方案

三級緩存
public class DefaultSingletonBeanRegistry ... {//1、最終存儲單例Bean成品的容器,即實例化和初始化都完成的Bean,稱之為"一級緩存"Map<String, Object> singletonObjects = new ConcurrentHashMap(256);//2、早期Bean單例池,緩存半成品對象,且當前對象已經被其他對象引用了,稱之為"二級緩存"Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16);//3、單例Bean的工廠池,緩存半成品對象,對象未被引用,使用時在通過工廠創建Bean,稱之為"三級緩存"Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
}
UserService和UserDao循環依賴的過程結合上述三級緩存描述一下
- UserService 實例化對象,但尚未初始化,將UserService存儲到三級緩存;
- UserService 屬性注入,需要UserDao,從緩存中獲取,沒有UserDao;
- UserDao實例化對象,但尚未初始化,將UserDao存儲到到三級緩存;
- UserDao屬性注入,需要UserService,從三級緩存獲取UserService,UserService從三級緩存移入二級緩存;
- UserDao執行其他生命周期過程,最終成為一個完成Bean,存儲到一級緩存,刪除二三級緩存;
- UserService 注入UserDao;
- UserService執行其他生命周期過程,最終成為一個完成Bean,存儲到一級緩存,刪除二三級緩存。
(2)Aware接口
Aware接口是一種框架輔助屬性注入的一種思想,其他框架中也可以看到類似的接口。框架具備高度封裝性,我們接觸到的一般都是業務代碼,一個底層功能API不能輕易的獲取到,但是這不意味著永遠用不到這些對象,如果用到了,就可以使用框架提供的類似Aware的接口,讓框架給我們注入該對象。

7.整合第三方框架(如何使用第三方功能)
(1)使用默認命名空間 beans
Spring整合MyBatis的步驟如下:
原始代碼
public static void main(String[] args) throws IOException {// 加載 MyBatis 配置文件String resource = "com/example/config/mybatis-config.xml";Reader reader = Resources.getResourceAsReader(resource);// 構建 SqlSessionFactorySqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);// 打開 SqlSessiontry (SqlSession session = sqlSessionFactory.openSession()) {// 獲取 MapperUserMapper userMapper = session.getMapper(UserMapper.class);// 查詢用戶User user = userMapper.selectUserById(1);System.out.println("User: " + user.getUsername() + ", Password: " + user.getPassword());// 插入用戶User newUser = new User();newUser.setUsername("newuser");newUser.setPassword("newpassword");userMapper.insertUser(newUser);session.commit(); // 提交事務}}
-
導入MyBatis整合Spring的相關坐標;
-
編寫Mapper和Mapper.xml;
-
配置SqlSessionFactoryBean和MapperScannerConfigurer;
<!--配置數據源--> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"><property name="url" value="jdbc:mysql://localhost:3306/mybatis"></property><property name="username" value="root"></property><property name="password" value="root"></property> </bean> <!--配置SqlSessionFactoryBean--> <bean class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="dataSource"></property> </bean> <!--配置Mapper包掃描--> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="com.itheima.dao"></property> </bean> -
編寫測試代碼
原理(對照原始代碼看)
-
SqlSessionFactoryBean:實現了FactoryBean規范,用于提供SqlSessionFactory;用于創建SqlSession
-
MapperScannerConfigurer:實現了BeanDefinitionRegistryPostProcessor接口,完成注冊,用于掃描指定包下的mapper注冊到BeanDefinitionMap中;
-
MapperFactoryBean:實現了FactoryBean規范,它的getObject方法就是this.getSqlSession().getMapper(this.mapperInterface);
-
ClassPathMapperScanner:在mapper(接口,無法實例化成一個對象)注冊到BeanDefinitionMap后,動態修改BeanDefinitionMap,對于每一個mapper的class修改成MapperFactoryBean
definition.setAutowireMode(2) 修改了自動注入狀態(根據類型),所以MapperFactoryBean中的setSqlSessionFactory會自動注入進去。
使用注解整合
@Configuration
@ComponentScan("com.itheima")
@MapperScan("com.itheima.mapper")
public class ApplicationContextConfig {@Beanpublic DataSource dataSource(){DruidDataSource dataSource = new DruidDataSource();//省略部分代碼return dataSource;}@Beanpublic SqlSessionFactoryBean sqlSessionFactoryBean(DataSource dataSource){SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(dataSource);return sqlSessionFactoryBean;
}}
@MapperScan不是Spring提供的注解,是MyBatis為了整合Spring,在整合包org.mybatis.spring.annotation中提供的注解。這個注解上有一個元注解,@Import({MapperScannerRegistrar.class}),當@MapperScan被掃描加載時,會解析@Import注解,從而加載指定的類,此處就是加載了MapperScannerRegistrar。
MapperScannerRegistrar實現了ImportBeanDefinitionRegistrar接口,Spring會自動調用registerBeanDefinitions方法,該方法中又注冊MapperScannerConfigurer類,而MapperScannerConfigurer類作用是掃描Mapper,向容器中注冊Mapper對應的MapperFactoryBean
@Import注解
@Import可以導入如下三種類:
-
普通的配置類
-
實現ImportSelector接口的類
重寫String[] selectImports(AnnotationMetadata annotationMetadata)方法,//返回要進行注冊的Bean的全限定名數組
-
實現ImportBeanDefinitionRegistrar接口的類
重寫registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry),手動注冊BeanDefinition
(2)使用第三方命名空間(如何生效的)
需求:加載外部properties文件,將鍵值對存儲在Spring容器中
jdbc.url=jdbc:mysql://localhost:3306/mybatis
jdbc.username=root
jdbc.password=root
引入context命名空間,在使用context命名空間的標簽,使用SpEL表達式在xml或注解中根據key獲得value
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:context="http://www.springframework.org/schema/context"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"><context:property-placeholder location="classpath:jdbc.properties" /><bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"><property name="url" value="${jdbc.url}"></property><property name="username" value="${jdbc.username}"></property><property name="password" value="${jdbc.password}"></property></bean>
<beans>
-
將自定義標簽的約束 與 物理約束文件與網絡約束名稱的約束 以鍵值對形式存儲到一個spring.schemas文件里,該文件存儲在類加載路徑的 META-INF里,Spring會自動加載到;
http\://www.springframework.org/schema/context/spring-context.xsd=org/springframework/context/config/spring-context.xsd在xsd文件中就定義了命令空間下有哪些子標簽
-
將自定義命名空間的名稱 與 自定義命名空間的處理器映射關系 以鍵值對形式存在到一個叫spring.handlers文件里,該文件存儲在類加載路徑的 META-INF里,Spring會自動加載到;
http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler -
在ContextNamespaceHandler中,會為命名空間中的每一個標簽都注冊一個解析器
public class ContextNamespaceHandler extends NamespaceHandlerSupport {public ContextNamespaceHandler() {}public void init() {this.registerBeanDefinitionParser("property-placeholder", new PropertyPlaceholderBeanDefinitionParser());this.registerBeanDefinitionParser("property-override", new PropertyOverrideBeanDefinitionParser());this.registerBeanDefinitionParser("annotation-config", new AnnotationConfigBeanDefinitionParser());this.registerBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());this.registerBeanDefinitionParser("load-time-weaver", new LoadTimeWeaverBeanDefinitionParser());this.registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());this.registerBeanDefinitionParser("mbean-export", new MBeanExportBeanDefinitionParser());this.registerBeanDefinitionParser("mbean-server", new MBeanServerBeanDefinitionParser());} }根據標簽,找到對應的解析器進行解析
8.Spring注解的解析原理
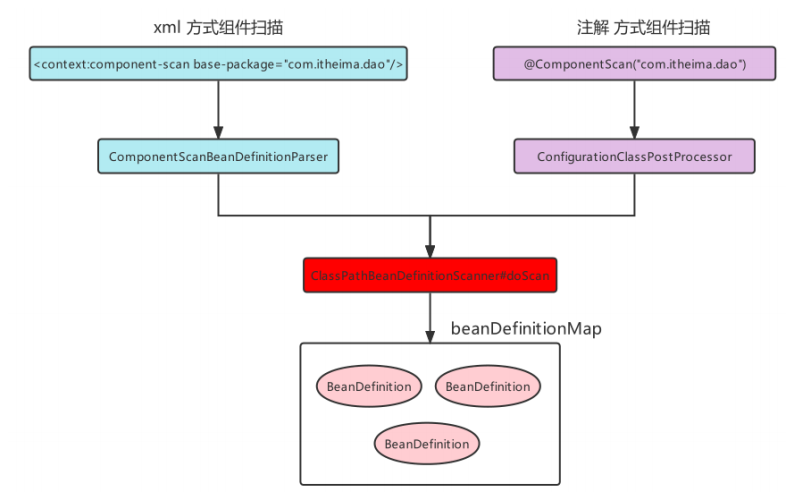
(1)xml配置組件掃描
<context:component-scan base-package="com.itheima"/>
component-scan是一個context命名空間下的自定義標簽,所以要找到對應的命名空間處理器NamespaceHandler 和 解析器.
將ComponentScanBeanDefinitionParser進行了注冊
(2)配置類配置組件掃描
@Configuration
@ComponentScan("com.itheima")
public class AppConfig {
}
使用AnnotationConfigApplicationContext容器在進行創建時,內部調用了如下代碼,該工具注冊了幾個Bean后處理器






027 OSPF外部路由計算)

電壓比較器)

)








