
本教程的知識點為:爬蟲概要 爬蟲基礎 爬蟲概述 知識點: 1. 爬蟲的概念 requests模塊 requests模塊 知識點: 1. requests模塊介紹 1.1 requests模塊的作用: 數據提取概要 數據提取概述 知識點 1. 響應內容的分類 知識點:了解 響應內容的分類 Selenium概要 selenium的介紹 知識點: 1. selenium運行效果展示 1.1 chrome瀏覽器的運行效果 Selenium概要 selenium的其它使用方法 知識點: 1. selenium標簽頁的切換 知識點:掌握 selenium控制標簽頁的切換 反爬與反反爬 常見的反爬手段和解決思路 學習目標 1 服務器反爬的原因 2 服務器常反什么樣的爬蟲 反爬與反反爬 驗證碼處理 學習目標 1.圖片驗證碼 2.圖片識別引擎 反爬與反反爬 JS的解析 學習目標: 1 確定js的位置 1.1 觀察按鈕的綁定js事件 Mongodb數據庫 介紹 內容 mongodb文檔 mongodb的簡單使用 Mongodb數據庫 介紹 內容 mongodb文檔 mongodb的聚合操作 Mongodb數據庫 介紹 內容 mongodb文檔 mongodb和python交互 scrapy爬蟲框架 介紹 內容 scrapy官方文檔 scrapy的入門使用 scrapy爬蟲框架 介紹 內容 scrapy官方文檔 scrapy管道的使用 scrapy爬蟲框架 介紹 內容 scrapy官方文檔 scrapy中間件的使用 scrapy爬蟲框架 介紹 內容 scrapy官方文檔 scrapy_redis原理分析并實現斷點續爬以及分布式爬蟲 scrapy爬蟲框架 介紹 內容 scrapy官方文檔 scrapy的日志信息與配置 利用appium抓取app中的信息 介紹 內容 appium環境安裝 學習目標
完整筆記資料代碼:https://gitee.com/yinuo112/Backend/tree/master/爬蟲/爬蟲開發從0到1全知識教程/note.md
感興趣的小伙伴可以自取哦~
全套教程部分目錄:


部分文件圖片:
scrapy爬蟲框架
介紹
我們知道常用的流程web框架有django、flask,那么接下來,我們會來學習一個全世界范圍最流行的爬蟲框架scrapy
內容
- scrapy的概念作用和工作流程
- scrapy的入門使用
- scrapy構造并發送請求
- scrapy模擬登陸
- scrapy管道的使用
- scrapy中間件的使用
- scrapy_redis概念作用和流程
- scrapy_redis原理分析并實現斷點續爬以及分布式爬蟲
- scrapy_splash組件的使用
- scrapy的日志信息與配置
- scrapyd部署scrapy項目
scrapy官方文檔
[
scrapy中間件的使用
學習目標:
- 應用 scrapy中使用間件使用隨機UA的方法
- 應用 scrapy中使用ip的的方法
- 應用 scrapy與selenium配合使用
1. scrapy中間件的分類和作用
1.1 scrapy中間件的分類
根據scrapy運行流程中所在位置不同分為:
- 下載中間件
- 爬蟲中間件
1.2 scrapy中間的作用:預處理request和response對象
- 對header以及cookie進行更換和處理
- 使用ip等
- 對請求進行定制化操作,
但在scrapy默認的情況下 兩種中間件都在middlewares.py一個文件中
爬蟲中間件使用方法和下載中間件相同,且功能重復,通常使用下載中間件
2. 下載中間件的使用方法:
接下來我們對騰訊招聘爬蟲進行修改完善,通過下載中間件來學習如何使用中間件 編寫一個Downloader Middlewares和我們編寫一個pipeline一樣,定義一個類,然后在setting中開啟
Downloader Middlewares默認的方法:
-
process_request(self, request, spider):
-
當每個request通過下載中間件時,該方法被調用。
- 返回None值:沒有return也是返回None,該request對象傳遞給下載器,或通過引擎傳遞給其他權重低的process_request方法
- 返回Response對象:不再請求,把response返回給引擎
-
返回Request對象:把request對象通過引擎交給調度器,此時將不通過其他權重低的process_request方法
-
process_response(self, request, response, spider):
-
當下載器完成http請求,傳遞響應給引擎的時候調用
- 返回Resposne:通過引擎交給爬蟲處理或交給權重更低的其他下載中間件的process_response方法
-
返回Request對象:通過引擎交給調取器繼續請求,此時將不通過其他權重低的process_request方法
-
在settings.py中配置開啟中間件,權重值越小越優先執行
3. 定義實現隨機User-Agent的下載中間件
3.1 在middlewares.py中完善代碼
import random
from Tencent.settings import USER_AGENTS_LIST # 注意導入路徑,請忽視pycharm的錯誤提示class UserAgentMiddleware(object):def process_request(self, request, spider):user_agent = random.choice(USER_AGENTS_LIST)request.headers['User-Agent'] = user_agent# 不寫returnclass CheckUA:def process_response(self,request,response,spider):print(request.headers['User-Agent'])return response # 不能少!
3.2 在settings中設置開啟自定義的下載中間件,設置方法同管道
DOWNLOADER_MIDDLEWARES = {'Tencent.middlewares.UserAgentMiddleware': 543, # 543是權重值'Tencent.middlewares.CheckUA': 600, # 先執行543權重的中間件,再執行600的中間件
}
3.3 在settings中添加UA的列表
USER_AGENTS_LIST = ["Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
運行爬蟲觀察現象
4. ip的使用
4.1 思路分析
- 添加的位置:request.meta中增加
proxy字段 - 獲取一個ip,賦值給
request.meta['proxy'] - 池中隨機選擇ip
- ip的webapi發送請求獲取一個ip
4.2 具體實現
免費ip:
class ProxyMiddleware(object):def process_request(self,request,spider):# proxies可以在settings.py中,也可以來源于ip的webapi# proxy = random.choice(proxies) # 免費的會失效,報 111 connection refused 信息!重找一個ip再試proxy = ' request.meta['proxy'] = proxyreturn None # 可以不寫return
收費ip:
# 人民幣玩家的代碼(使用abuyun提供的ip)import base64# 隧道驗證信息 這個是在那個網站上申請的proxyServer = ' # 收費的ip服務器地址,這里是abuyun
proxyUser = 用戶名
proxyPass = 密碼
proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass)class ProxyMiddleware(object):def process_request(self, request, spider):# 設置request.meta["proxy"] = proxyServer# 設置認證request.headers["Proxy-Authorization"] = proxyAuth
4.3 檢測ip是否可用
在使用了ip的情況下可以在下載中間件的process_response()方法中處理ip的使用情況,如果該ip不能使用可以替換其他ip
class ProxyMiddleware(object):......def process_response(self, request, response, spider):if response.status != '200':request.dont_filter = True # 重新發送的請求對象能夠再次進入隊列return requst
在settings.py中開啟該中間件
5. 在中間件中使用selenium
以github登陸為例
5.1 完成爬蟲代碼
import scrapyclass Login4Spider(scrapy.Spider):name = 'login4'allowed_domains = ['github.com']start_urls = [' # 直接對驗證的url發送請求def parse(self, response):with open('check.html', 'w') as f:f.write(response.body.decode())
5.2 在middlewares.py中使用selenium
import time
from selenium import webdriverdef getCookies():# 使用selenium模擬登陸,獲取并返回cookieusername = input('輸入github賬號:')password = input('輸入github密碼:')options = webdriver.ChromeOptions()options.add_argument('--headless')options.add_argument('--disable-gpu')driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver',chrome_options=options)driver.get('time.sleep(1)driver.find_element_by_xpath('//*[@id="login_field"]').send_keys(username)time.sleep(1)driver.find_element_by_xpath('//*[@id="password"]').send_keys(password)time.sleep(1)driver.find_element_by_xpath('//*[@id="login"]/form/div[3]/input[3]').click()time.sleep(2)cookies_dict = {cookie['name']: cookie['value'] for cookie in driver.get_cookies()}driver.quit()return cookies_dictclass LoginDownloaderMiddleware(object):def process_request(self, request, spider):cookies_dict = getCookies()print(cookies_dict)request.cookies = cookies_dict # 對請求對象的cookies屬性進行替換
配置文件中設置開啟該中間件后,運行爬蟲可以在日志信息中看到selenium相關內容
小結
中間件的使用:
-
完善中間件代碼:
-
process_request(self, request, spider):
- 當每個request通過下載中間件時,該方法被調用。
- 返回None值:沒有return也是返回None,該request對象傳遞給下載器,或通過引擎傳遞給其他權重低的process_request方法
- 返回Response對象:不再請求,把response返回給引擎
- 返回Request對象:把request對象通過引擎交給調度器,此時將不通過其他權重低的process_request方法
-
process_response(self, request, response, spider):
- 當下載器完成http請求,傳遞響應給引擎的時候調用
- 返回Resposne:通過引擎交給爬蟲處理或交給權重更低的其他下載中間件的process_response方法
- 返回Request對象:通過引擎交給調取器繼續請求,此時將不通過其他權重低的process_request方法
-
需要在settings.py中開啟中間件 DOWNLOADER_MIDDLEWARES = { 'myspider.middlewares.UserAgentMiddleware': 543, }
scrapy_redis概念作用和流程
學習目標
- 了解 分布式的概念及特點
- 了解 scarpy_redis的概念
- 了解 scrapy_redis的作用
- 了解 scrapy_redis的工作流程
在前面scrapy框架中我們已經能夠使用框架實現爬蟲爬取網站數據,如果當前網站的數據比較龐大, 我們就需要使用分布式來更快的爬取數據
1. 分布式是什么
簡單的說 分布式就是不同的節點(服務器,ip不同)共同完成一個任務
2. scrapy_redis的概念
scrapy_redis是scrapy框架的基于redis的分布式組件
3. scrapy_redis的作用
Scrapy_redis在scrapy的基礎上實現了更多,更強大的功能,具體體現在:
通過持久化請求隊列和請求的指紋集合來實現:
- 斷點續爬
- 分布式快速抓取
4. scrapy_redis的工作流程
4.1 回顧scrapy的流程
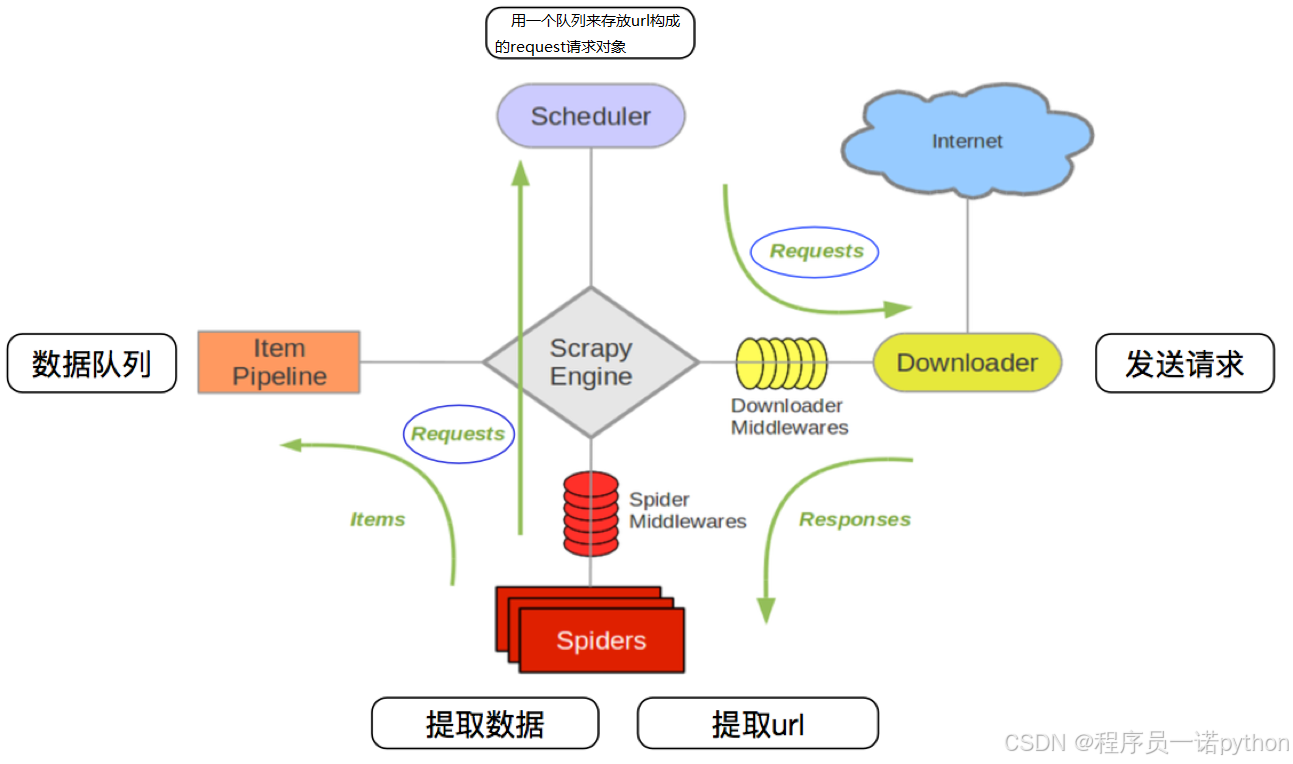
思考:那么,在這個基礎上,如果需要實現分布式,即多臺服務器同時完成一個爬蟲,需要怎么做呢?
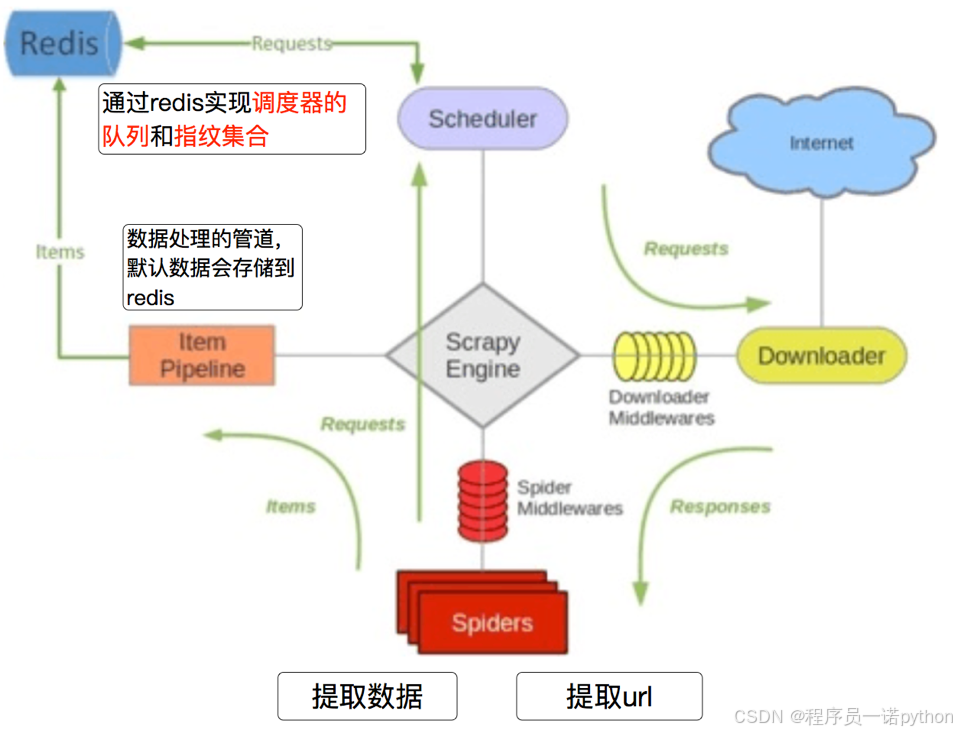
4.2 scrapy_redis的流程
-
在scrapy_redis中,所有的待抓取的request對象和去重的request對象指紋都存在所有的服務器公用的redis中
-
所有的服務器中的scrapy進程公用同一個redis中的request對象的隊列
-
所有的request對象存入redis前,都會通過該redis中的request指紋集合進行判斷,之前是否已經存入過
-
在默認情況下所有的數據會保存在redis中
具體流程如下:
小結
scarpy_redis的分布式工作原理
- 在scrapy_redis中,所有的待抓取的對象和去重的指紋都存在公用的redis中
- 所有的服務器公用同一redis中的請求對象的隊列
- 所有的request對象存入redis前,都會通過請求對象的指紋進行判斷,之前是否已經存入過



027 OSPF外部路由計算)

電壓比較器)

)










(附腳本))
