一、系統級性能分析工具perf原理????????
1. perf 的基本概念
內核集成:perf 直接集成在 Linux 內核源碼中,能夠深度訪問硬件和操作系統層面的性能數據,具有低開銷、高精度的特點。
事件采樣原理:通過定期采樣系統事件(如 CPU 周期、指令執行、緩存訪問等),統計熱點代碼和資源消耗,幫助定位性能瓶頸。
2. 系統級性能優化的兩個階段
(1) 性能剖析(Performance Profiling, PP)
目標:識別系統的瓶頸,如 CPU 利用率過高、內存泄漏、I/O 延遲等。
方法:通過 perf 收集硬件事件(如 CPU 周期)、軟件事件(如上下文切換)和追蹤點(TracePoint)數據,生成性能報告。
輸出:確定程序中耗時最多的函數(熱點代碼)、資源爭用情況等。
(2) 代碼優化
目標:基于剖析結果,針對性優化代碼或調整系統配置。
常見手段:
優化算法復雜度;
減少鎖競爭或使用無鎖數據結構;
改善緩存局部性;
調整內存分配策略等。
3. perf 的核心技術支撐
perf 依賴以下三類技術收集性能數據:
(1) PMU(Performance Monitoring Unit)
硬件支持:PMU 是 CPU 內置的硬件單元,用于監控處理器級事件。
監控事件:
CPU 周期(cycles)、指令數(instructions);
緩存命中/失效(cache-misses, cache-references);
分支預測失敗(branch-misses)等。
優勢:直接訪問硬件計數器,精度高、開銷極低。
(2) TracePoint
內核靜態探針:TracePoint 是 Linux 內核中預定義的靜態跟蹤點,用于記錄特定事件的發生。
監控事件:
系統調用(syscalls)、調度事件(sched_switch);
文件 I/O(ext4 文件系統操作)、網絡包處理等。
優勢:提供細粒度的內核行為追蹤,適用于分析系統調用和內核態性能問題。
(3) 內核計數器
軟件統計:內核通過計數器記錄系統事件的發生次數。
監控事件:
上下文切換(context-switches)、缺頁異常(page-faults);
進程創建(process-fork)等。
優勢:適用于統計類性能分析,如系統負載分布。
4. perf 的典型使用場景
(1) CPU 瓶頸分析
命令示例:
perf record -g -e cycles ./my_program # 記錄程序的 CPU 周期事件 perf report # 生成熱點函數報告輸出:顯示消耗最多 CPU 周期的函數及其調用棧。
(2) 緩存效率分析
命令示例:
perf stat -e cache-references,cache-misses ./my_program輸出:統計緩存命中率,幫助優化內存訪問模式。
(3) 內核行為追蹤
命令示例:
perf trace -e syscalls:sys_enter_openat # 追蹤文件打開操作輸出:記錄所有?
openat?系統調用的參數和頻率。
5. perf 的優勢與對比
優勢:
低開銷:基于事件采樣而非全量記錄,對系統影響小;
多功能性:支持硬件事件、內核事件、用戶態程序分析;
深度集成:直接利用內核基礎設施,無需額外插樁。
對比其他工具:
gprof:僅支持用戶態函數耗時統計,無內核級支持;
Valgrind:功能強大但開銷極高,適合內存調試而非性能分析。
?
二、安裝性能分析工具perf與perf list命令
1.安裝性能分析工具perf
sudo apt-get update
sudo apt-get install linux-tools-generic linux-cloud-tools-generic? ? ? ? 我這里已經安裝過了:

????????執行perf命令如下,證明已經成功安裝perf性能分析工具了。

? ? ? ? ?查看當前perf所支持的性能事件列表如下(有軟件也有硬件的):

?除此之外還有常用的命令如下:
perf list:查看當前系統支持的性能事件perf bench:針對系統性能進行摸底perf test:針對系統進行健全性能測試perf stat:對全局性能進行統計perf top:針對實時查看當前系統進程函數占用率情況perf probe:自定義動態事件
【perf list sw】

命令作用
perf list sw?用于列出系統中?軟件模擬的性能事件。其中:
perf list?基礎功能是展示系統預定義的性能事件;sw?是過濾條件,用于篩選出類型為?[Software event](軟件事件)的條目,這些事件由內核通過軟件層面統計生成,而非硬件計數器直接采集。輸出含義
輸出結果為符合條件的性能事件列表,格式為?
?事件名稱 [事件類型],具體含義:
- 事件名稱:
- 如?
alignment-faults(內存對齊錯誤次數)、context-switches OR cs(上下文切換次數,OR?表示別名)、cpu-clock(CPU 活動時間)等,是性能分析的具體觀測對象,反映系統軟件層面的行為(如進程調度、內存管理等)。- 事件類型:
[Software event]:表示該事件由內核通過軟件模擬統計(例如上下文切換、內存頁錯誤等,無需硬件計數器支持);- 圖中少量?
[Tool event]?屬于輸出異常(正常?sw?過濾應僅含?Software event),可能是系統版本或工具特性導致,[Tool event]?與?perf?工具自身功能相關(如時間統計),一般不歸類于常規軟件事件。
?【perf list cache】

命令作用
perf list cache?用于列出系統中與?緩存(Cache)相關的預定義性能事件,這些事件可用于分析 CPU 緩存(如一級數據緩存、指令緩存、TLB 等)的訪問、命中 / 缺失情況,幫助定位緩存相關的性能瓶頸。輸出含義
輸出內容為緩存相關的性能事件列表,格式為?事件名稱,具體解釋:
?
- 事件分類:
- 以?
cpu:?開頭,表明這些事件與 CPU 緩存相關,基于硬件計數器統計。- 常見事件示例:
L1-dcache-loads OR cpu/L1-dcache-loads/:
- 表示 CPU 一級數據緩存(L1 Data Cache)的加載次數,用于統計從 L1 數據緩存中讀取數據的操作數量。
L1-dcache-load-misses OR cpu/L1-dcache-load-misses/:
- 表示 CPU 一級數據緩存加載缺失次數,即讀取數據時在 L1 數據緩存中未命中,需從更高層級緩存或內存獲取的次數。
L1-icache-loads OR cpu/L1-icache-loads/:
- 表示 CPU 一級指令緩存(L1 Instruction Cache)的加載次數,統計從 L1 指令緩存中讀取指令的操作數量。
dTLB-loads OR cpu/dTLB-loads/:
- 表示數據轉換查找緩沖(Data Translation Lookaside Buffer, dTLB)的加載次數,用于統計數據地址轉換時 TLB 的訪問情況。
branch-loads OR cpu/branch-loads/:
- 表示分支指令緩存的加載次數,統計分支指令相關的緩存訪問操作。
這些事件可通過?
perf stat -e 事件名?等命令結合具體工具(如?perf stat?perf record),深入分析程序運行時的緩存使用效率。
?
三、使用perf采集數據信息/perf stat|top
1.perf stat全局性能統計如下:

命令作用
perf stat ls?用于運行?ls?命令(列出當前目錄文件),同時收集并展示該命令執行過程中的性能計數器統計信息,幫助分析程序對 CPU、內存等資源的使用情況。輸出內容詳解
1. 命令執行結果
FlameGraph grpc linux-5.6.18 linux-5.6.18.tar.gz mosquitto-2.0.15 snap tmp work workflow zvfs這是?
ls?命令的正常輸出,顯示當前目錄下的文件和文件夾。2. 性能計數器統計(
Performance counter stats for 'ls')
1.66 msec task-clock:
- 含義:任務(即?
ls?命令)占用的 CPU 時間,單位為毫秒。- 關聯計算:
CPUs utilized = task-clock / time elapsed,用于計算 CPU 利用率(本例中通過后續?0.583 CPUs utilized?體現)。2 context-switches:
- 含義:
ls?執行過程中發生的上下文切換次數,反映進程在運行中被調度器暫停 / 恢復的頻率。0 cpu-migrations:
- 含義:CPU 遷移次數,即進程在不同 CPU 核心間遷移的次數(本例未發生遷移)。
103 page-faults:
- 含義:缺頁異常次數,即訪問的內存頁面不在物理內存中,需從磁盤加載的次數。
3,073,664 cycles:
- 含義:CPU 消耗的周期數,反映指令執行的硬件耗時(結合?
1.856 GHz?可輔助分析頻率影響)。0 stalled-cycles-frontend:
- 含義:前端停滯周期數,指 CPU 指令獲取或解碼階段的停滯情況(本例無停滯)。
0 instructions:
- 含義:執行的指令數量。
0.00 insn per cycle?表示每周期執行指令數為 0(可能因統計范圍或事件未完全計數導致)。0 branches:
- 含義:分支指令數量,統計程序中條件跳轉等分支操作的次數。
0 branch-misses:
- 含義:分支預測錯誤次數,若分支指令預測錯誤,會導致流水線刷新,影響性能(本例未統計到,提示?
<not counted>)。3. 時間統計
0.002841599 seconds time elapsed:
- 含義:從命令開始到結束的總耗時(墻鐘時間)。
0.001439000 seconds user:
- 含義:
ls?在用戶態執行的時間。0.001439000 seconds sys:
- 含義:
ls?在內核態(系統調用)執行的時間。4. 統計提示
Some events weren't counted. Try disabling the NMI watchdog...
- 含義:部分事件(如?
branch-misses)未成功計數,提示通過關閉 NMI 看門狗(修改?/proc/sys/kernel/nmi_watchdog)嘗試解決統計問題。
?2.perf top指定性能事件,消耗最多的函數或指令
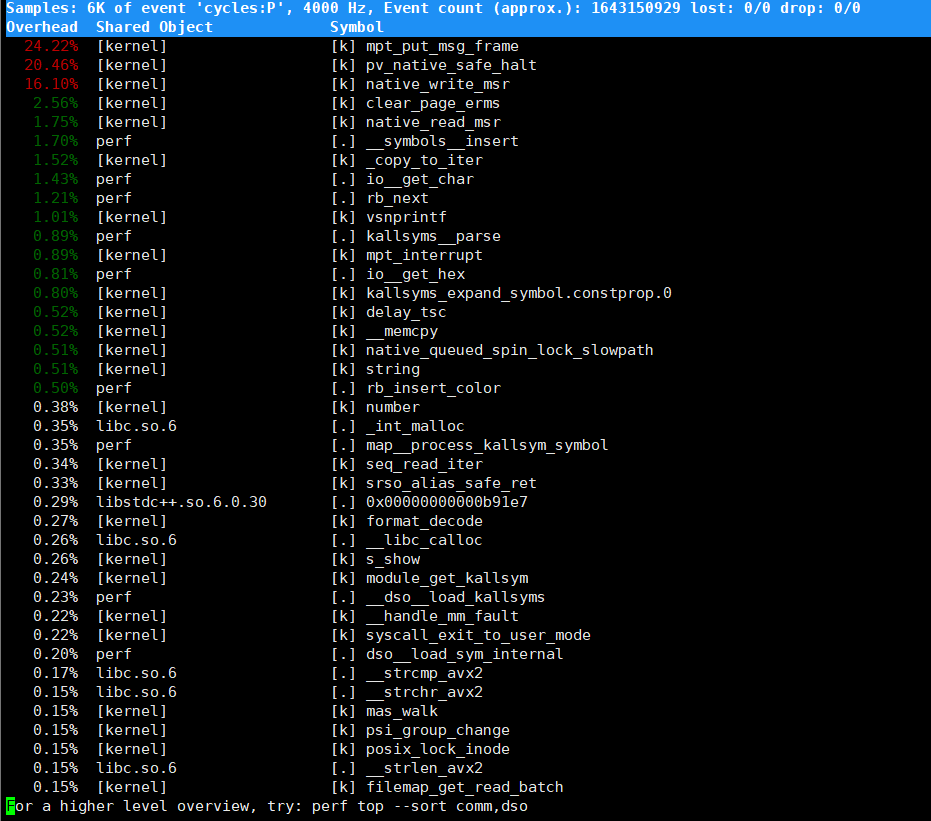
perf top?命令作用
perf top?是 Linux 性能分析工具?perf?的子命令,主要用于實時分析系統中各函數在特定性能事件(如 CPU 周期、緩存命中 / 缺失等)上的 “熱度”。它通過采樣統計,快速定位消耗資源最多的函數(包括應用程序函數、內核函數、動態鏈接庫函數等),幫助開發者或運維人員識別系統性能瓶頸,例如哪些內核函數占用過多 CPU 周期、哪些應用函數存在效率問題等。
結合輸出的詳細分析(以圖中內容為例)
輸出表格包含四列,每列含義及對應圖中內容分析如下:
1.?第一列:符號引發的性能事件比例
- 含義:表示該函數在性能事件(默認是 CPU 周期)中占用的比例,反映函數對性能事件的 “貢獻度”,比例越高,說明該函數越消耗資源。
- 圖中示例:
24.22%:表示?mpt_put_msg_frame?函數占用了約 24.22% 的 CPU 周期,是當前采樣中最 “熱” 的函數。20.46%:pv_native_safe_halt?函數占用 20.46% 的 CPU 周期,也是主要的資源消耗點。2.?第二列:符號所在的 BSO(Binary/Symbol Object)
- 含義:標識函數所屬的二進制對象,可能是內核、動態鏈接庫、應用程序或內核模塊等。
- 圖中示例:
[kernel]:表示函數屬于內核(如?mpt_put_msg_frame?pv_native_safe_halt?等)。perf:表示函數屬于?perf?工具本身(如?io_get_char?rb_next?等)。libc.so.6:表示函數屬于 C 標準庫(如?_int_malloc?_libc_calloc?等)。3.?第三列:BSO 的類型
- 含義:
[k]:表示符號屬于內核空間(內核代碼或內核模塊)。[.]:表示符號屬于用戶空間的 ELF 文件(如應用程序、動態鏈接庫)。- 圖中示例:
[k]:如?mpt_put_msg_frame?pv_native_safe_halt?等內核函數。[.]:如?io_get_char(屬于?perf?工具的用戶態函數)。4.?第四列:符號名稱或地址
- 含義:
- 若能解析為函數名,直接顯示函數名(如?
mpt_put_msg_frame?_int_malloc);- 若無法解析(如匿名函數、代碼地址),則顯示地址(如?
0x00000000000b91e7)。- 圖中示例:
mpt_put_msg_frame:內核中可解析的函數名。0x00000000000b91e7:無法解析為函數名,僅顯示地址的符號。
總結
????????通過?
perf top?的輸出,可快速定位系統中資源消耗最大的函數。例如圖中內核函數?mpt_put_msg_frame?和?pv_native_safe_halt?占據較高比例,若系統存在 CPU 利用率過高的問題,就可優先分析這些函數的邏輯是否存在優化空間。?
?3.perf record
????????perf record 精確到函數級別(混合顯示匯編語言和代碼),就是我們運行此工具命令之后,將其數據保存到 perf.data 中,我們也可以通過 perf report 進行分析。? ?
perf record 工具命令常用選項:
????????-e-->record 指定 PMU 事件(--filter event 事件過濾器)
????????-a--> 獲取所有 CPU 事件
????????-p--> 獲取指定 PID 進程的事件
????????-o--> 指定獲取保存數據的文件名稱
????????-g--> 能夠使函數調用圖功能
????????-C--> 獲取指定 CPU 事件
【具體案例】
testfork.c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>int main() {int i;for (i = 0; i < 5; i++) {pid_t pid = fork();if (pid == 0) { // 子進程int j;for (j = 0; j < 100000; j++) {int x = j * j; // 模擬計算}return 0;} else if (pid > 0) { // 父進程wait(NULL); // 等待子進程結束} else {perror("fork");return 1;}}return 0;
}編譯采集:

?接著執行命令 perf report --call-graph none

?
四、采集perf數據信息生成火焰圖
- 火焰圖(flame graph)是性能分析的利器,通過它可以快速定位性能瓶頸點。
- perf 命令(performance 的縮寫)是 Linux 系統原生提供的性能分析工具,會返回 CPU 正在執行的函數名以及調用棧(stack)。
使用步驟
1.下載FlameGraph包
curl -O http://example.com/FlameGraph.zip 
2.生成perf.unfold文件
????????perf script -i perf.data &> perf.unfold

? ? ? ? 如果中間出現權限問題
Permission denied?,可以使用chmod u+x 增加執行權限。
3.生成perf.folded文件
????????./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded?

下面這兩行命令和上面兩行命令功能相同,也可以生成需要的perf.folded
perf script > perf.script
./FlameGraph/stackcollapse-perf.pl perf.script > perf.folded? ?
4.生成perf.svg文件
?????????./FlameGraph/flamegraph.pl perf.folded > perf.svg?

5.打開火焰圖

?
https://github.com/0voice






 詳細分析)
萬字長文解析:deepResearch如何用更長的思考時間換取更高質量的回復?各家產品對比深度詳解)










)
