論文題目:Retrieval-Augmented Generation for AI-Generated Content: A Survey
論文地址:https://arxiv.org/abs/2402.19473
bib引用:
@misc{zhao2024retrievalaugmentedgenerationaigeneratedcontent,title={Retrieval-Augmented Generation for AI-Generated Content: A Survey}, author={Penghao Zhao and Hailin Zhang and Qinhan Yu and Zhengren Wang and Yunteng Geng and Fangcheng Fu and Ling Yang and Wentao Zhang and Jie Jiang and Bin Cui},year={2024},eprint={2402.19473},archivePrefix={arXiv},primaryClass={cs.CV},url={https://arxiv.org/abs/2402.19473},
}
InShort
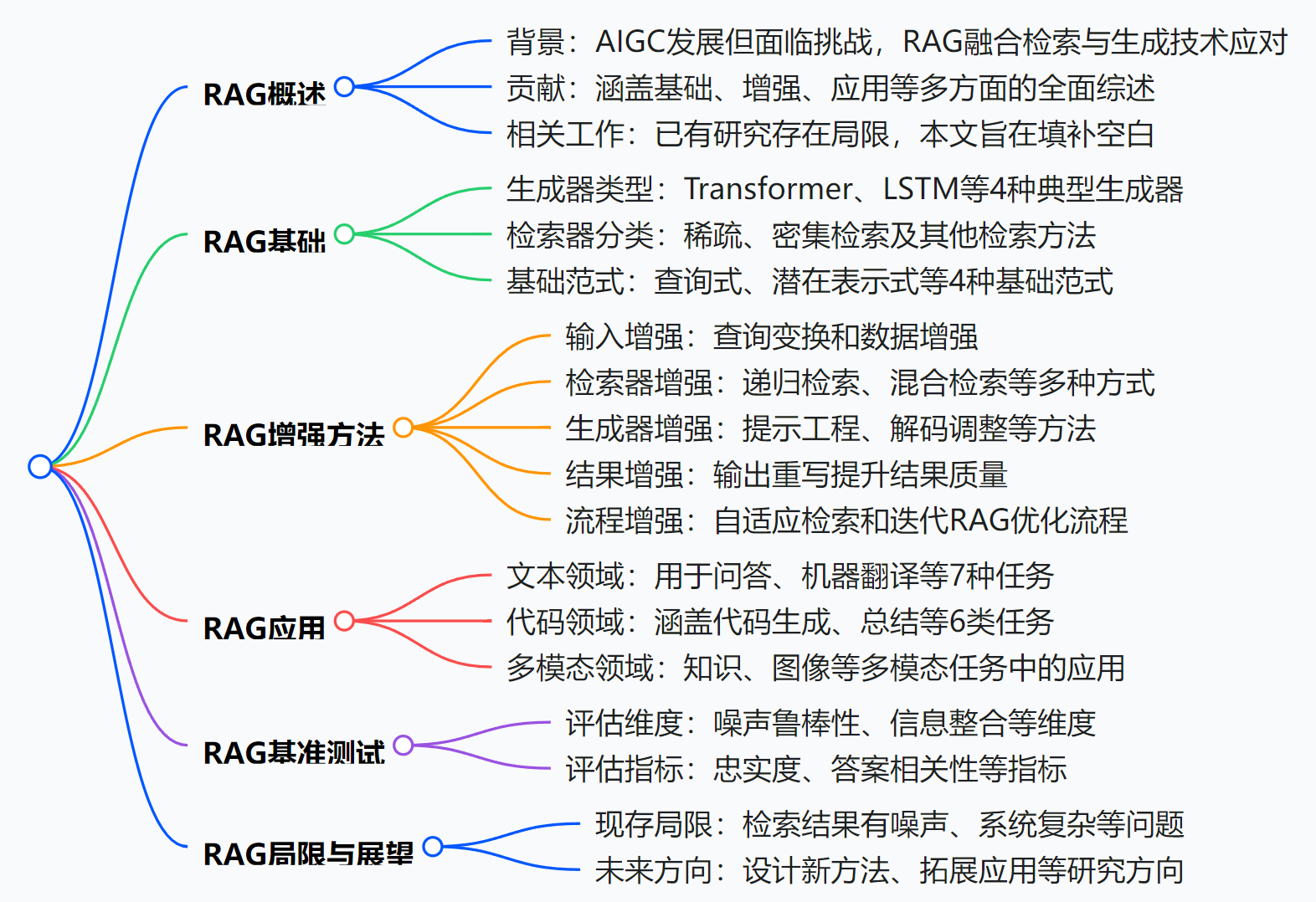
本文對RAG進行了全面綜述,涵蓋其基礎、增強方法、應用、基準測試、局限與未來方向。
- RAG概述
- 背景:AIGC借助模型算法創新、基礎模型擴展和優質數據實現發展,但面臨知識更新、長尾數據處理等問題。RAG通過引入檢索過程,利用可檢索知識作為非參數化記憶,解決這些問題,其應用已拓展到多種模態。
- 貢獻:系統梳理RAG基礎范式,探究增強方法,展示其在多模態和任務中的應用,討論局限并提出未來方向,為研究和實踐提供參考。
- 相關工作:已有相關研究存在局限,本文旨在提供全面系統的RAG綜述,涵蓋基礎、增強和應用等方面。
- RAG基礎
- 生成器:常用生成器包括Transformer模型、LSTM、擴散模型和GAN,不同模型適用于不同生成場景。
- 檢索器:檢索方法分為稀疏檢索、密集檢索和其他方法。稀疏檢索基于詞項匹配,密集檢索使用密集嵌入向量,其他方法如基于編輯距離、知識圖搜索和命名實體識別等。
- 基礎范式:分為查詢式RAG(如REALM、SELF - RAG)、潛在表示式RAG(如FiD、RETRO)、基于logit的RAG(如kNN - LM、TRIME)和推測式RAG(如REST、GPTCache),每種范式在不同模態和任務中各有應用。
- RAG增強方法
- 輸入增強:通過查詢變換(如Query2doc、HyDE)和數據增強(如Make - An - Audio、LESS)提升檢索效果。
- 檢索器增強:采用遞歸檢索(如ReACT、RATP)、塊優化(如LlamaIndex、RAPTOR)、檢索器微調(如REPLUG、APICoder)、混合檢索(如RAP - Gen、BlendedRAG)、重排序(如Re2G、AceCoder)和檢索變換(如FILCO、FiD - Light)等方法。
- 生成器增強:運用提示工程(如LLMLingua、ReMoDiffuse)、解碼調整(如InferFix、SYNCHROMESH)和生成器微調(如RETRO、APICoder)提升生成質量。
- 結果增強:通過輸出重寫(如SARGAM、Ring)改進生成結果,使其更符合下游任務需求。
- 流程增強:包括自適應檢索(如FLARE、Self - RAG)和迭代RAG(如RepoCoder、ITER - RETGEN),優化RAG整體流程。
- RAG應用
- 文本領域:在問答、事實驗證、常識推理、人機對話、神經機器翻譯、事件提取和文本摘要等任務中廣泛應用,如FiD、REALM用于問答,CONCRETE用于事實驗證。
- 代碼領域:涵蓋代碼生成、總結、補全、自動程序修復、文本到SQL和代碼語義解析等任務,不同任務采用不同的RAG范式和方法,如SKCODER用于代碼生成,Re2Com用于代碼總結。
- 多模態領域:在知識、圖像、視頻、音頻、3D和科學等領域均有應用,如在知識領域用于知識庫問答和知識增強開放域問答;在圖像領域用于圖像生成和圖像字幕;在視頻領域用于視頻字幕和視頻問答對話等。
- RAG基準測試:多個基準測試從不同維度評估RAG系統,如噪聲魯棒性、負樣本拒絕、信息整合、反事實魯棒性、忠實度、答案相關性和上下文相關性等。
- RAG局限與展望
- 現存局限:存在檢索結果有噪聲、額外開銷大、檢索器與生成器存在差距、系統復雜度增加和上下文過長等問題。
- 未來方向:包括設計新的增強方法、構建靈活的RAG管道、拓展應用領域、實現高效部署和處理、整合長尾和實時知識以及與其他技術結合等。
| 評估維度 | 評估指標 | 評估基準測試示例 |
|---|---|---|
| 噪聲魯棒性 | 測試LLMs能否從噪聲文檔中提取必要信息 | Chen等人提出的RAG基準測試 |
| 負樣本拒絕 | 評估LLMs在檢索內容不足時能否拒絕響應 | Chen等人提出的RAG基準測試 |
| 信息整合 | 檢查LLMs能否整合多個檢索內容獲取知識并響應 | Chen等人提出的RAG基準測試 |
| 反事實魯棒性 | 判斷LLMs能否識別檢索內容中的反事實錯誤 | Chen等人提出的RAG基準測試 |
| 忠實度 | 基于檢索內容評估事實準確性 | RAGAS、ARES、TruLens |
| 答案相關性 | 確定結果是否回答了查詢 | RAGAS、ARES、TruLens |
| 上下文相關性 | 評估檢索內容的相關性和簡潔性 | RAGAS、ARES、TruLens |
關鍵問題
- RAG的基礎范式有哪些,它們是如何增強生成過程的?
- RAG的基礎范式有查詢式RAG、潛在表示式RAG、基于logit的RAG和推測式RAG。查詢式RAG將檢索信息與用戶查詢整合作為生成器輸入;潛在表示式RAG把檢索對象作為潛在表示融入生成模型;基于logit的RAG在解碼過程中通過logits整合檢索信息;推測式RAG利用檢索替代部分生成過程以節省資源和加速響應。這些范式從不同角度增強生成過程,提升生成內容的質量和效率。
- RAG在不同模態中的應用有何特點?
- 在文本模態中,廣泛應用于多種自然語言處理任務,通過檢索相關文本信息輔助生成;代碼模態結合檢索和生成技術,提升代碼相關任務的性能;知識模態利用結構化知識(如知識圖譜和表格)進行檢索增強;圖像模態借助檢索提高圖像生成和描述的質量;視頻模態用于視頻字幕生成和視頻問答對話等,增強對視頻內容的理解和描述;音頻模態在音頻生成和字幕任務中發揮作用;3D模態應用于3D資產生成;科學領域用于藥物發現、生物醫學信息增強和數學應用等。不同模態根據自身特點和需求,采用不同的RAG方法和技術,以實現更好的效果。
- RAG目前面臨哪些挑戰,未來有哪些發展方向?
- RAG目前面臨檢索結果有噪聲、額外開銷大、檢索器與生成器存在差距、系統復雜度增加和上下文過長等挑戰。未來發展方向包括設計新的增強方法,以更好地發揮RAG的潛力;構建靈活的RAG管道,適應復雜任務;拓展應用領域,設計領域特定的RAG技術;實現高效部署和處理,降低檢索開銷和系統復雜度;整合長尾和實時知識,使RAG能夠處理動態信息;與其他技術結合,如微調、強化學習等,進一步提升AIGC的效果 。









)



![[Mac]利用Hexo+Github Pages搭建個人博客](http://pic.xiahunao.cn/[Mac]利用Hexo+Github Pages搭建個人博客)
)




