《動手學深度學習》-4.4-筆記
驗證數據集:通常是從訓練集中劃分出來的一部分數據,不要和訓練數據混在一起,評估模型好壞的數據集
測試數據集:只用一次的數據集
k-折交叉驗證(k-Fold Cross-Validation)是一種統計方法,用于評估和比較機器學習模型的性能。它通過將數據集分成k個子集(或“折”)來實現,每個子集都作為一次測試集,而剩余的k-1個子集則作為訓練集。這個過程會重復k次,每次選擇不同的子集作為測試集,最終將k次測試結果的平均值作為模型的性能評估。常用k=5/10,在沒有足夠多數據使用時。
總結:
訓練數據集:訓練模型參數
驗證數據集:選擇模型超參數
非大型數據集上通常使用k-折交叉驗證
欠擬合(Underfitting)
欠擬合是指模型對訓練數據的擬合程度不夠,無法捕捉到數據中的規律和模式。換句話說,模型過于簡單,無法很好地描述數據的特征。
過擬合(Overfitting)
過擬合是指模型對訓練數據擬合得過于完美,以至于模型在訓練數據上表現很好,但在新的、未見過的數據上表現很差。換句話說,模型過度學習了訓練數據中的噪聲和細節,而無法泛化到新的數據。
模型容量的定義
表示容量:模型的最大擬合能力,即通過調節參數,模型能夠表示的函數族
-
模型參數數量:參數越多,模型容量通常越高。
-
模型結構復雜度:例如,神經網絡的層數和每層的神經元數量。
-
數據復雜度:數據的復雜度(如樣本數量、特征數量)也會影響模型容量的選擇
模型容量與過擬合、欠擬合的關系
-
容量不足:模型無法很好地擬合訓練數據,導致欠擬合。
-
容量過高:模型可能會過度擬合訓練數據中的噪聲,導致過擬合
總結;
模型容量需要匹配數據復雜度,否則可能過擬合或欠擬合
統計機器學習提供數學工具來衡量模型復雜度?
代碼部分:
?
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l引入需要的庫
max_degree = 20 # 多項式的最大階數
n_train, n_test = 100, 100 # 訓練和測試數據集大小
true_w = np.zeros(max_degree) # 分配大量的空間
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])features = np.random.normal(size=(n_train + n_test, 1))#隨機生成200個樣本點(服從標準正態分布的x值)。
np.random.shuffle(features)#打亂樣本順序。
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的維度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)#加上噪音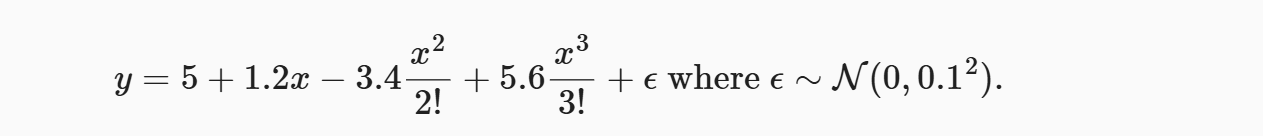

分析:
生成一個多項式回歸的訓練/測試數據集。也就是說,我們在模擬一個“隱藏函數”,然后加一點噪聲,生成一些數據,來用于模型訓練。
多項式階數:我們打算生成最多20階的多項式數據(比如 1, x, x2, ..., x1?)。
true_w = np.zeros(max_degree) # 創建一個長度為20的權重數組,初始值全是0
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])這一步設置了我們想要“模擬”的真實多項式模型的參數。它實際上模擬了一個三階多項式:
y = 5 + 1.2x - 3.4x2 + 5.6x3
其余的高階項(x? ~ x1?)的系數為0。
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
這一步是關鍵!構造一個 多項式特征矩陣。
假設 features = [[x1], [x2], ..., [x200]],
我們把它轉化為:
[[1, x1, x12, x13, ..., x1^19],
?[1, x2, x22, x23, ..., x2^19],
?...
]
for i in range(max_degree):poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!這一步是做多項式特征的縮放處理,用的是數學中的Gamma函數。
舉例:
-
gamma(1) = 0! = 1 -
gamma(2) = 1! = 1 -
gamma(3) = 2! = 2 -
gamma(4) = 3! = 6...
所以這是在做歸一化的處理,讓高階項不會變得太大
labels = np.dot(poly_features, true_w)這一步是最核心的:根據我們設定的權重 true_w 計算標簽 y 值。
可以理解為:
對每一行的多項式特征向量和權重向量做內積(點乘),
也就是:

-
所以最終的標簽是:
真實標簽 + 小范圍擾動
# NumPy ndarray轉換為tensor
true_w, features, poly_features, labels = [torch.tensor(x, dtype=torch.float32) for x in [true_w, features, poly_features, labels]]
#這句用列表推導式,把之前的 NumPy 數組全部 轉換成 PyTorch 的 tensor(張量)格式,這樣就可以用 PyTorch 來訓練模型啦!
features[:2], poly_features[:2, :], labels[:2]#這個不是賦值語句,而是查看前兩個樣本的輸入特征、多項式特征和標簽的值,已經把 NumPy 的數組轉成了 PyTorch 的張量
def evaluate_loss(net, data_iter, loss): #@save"""評估給定數據集上模型的損失"""metric = d2l.Accumulator(2) # 損失的總和,樣本數量for X, y in data_iter:out = net(X)#前向傳播 + 計算損失 讓模型對輸入 X 做預測,得到輸出 outy = y.reshape(out.shape)l = loss(out, y)#計算預測結果和真實值之間的損失metric.add(l.sum(), l.numel())#計算預測結果和真實值之間的損失return metric[0] / metric[1]#計算預測結果和真實值之間的損失評估模型在某個數據集(data_iter)上的平均損失。
分析:
-
net: 模型(PyTorch 中定義的神經網絡) -
data_iter: 數據迭代器(通常是訓練集或測試集的DataLoader) -
loss: 損失函數(比如nn.MSELoss())
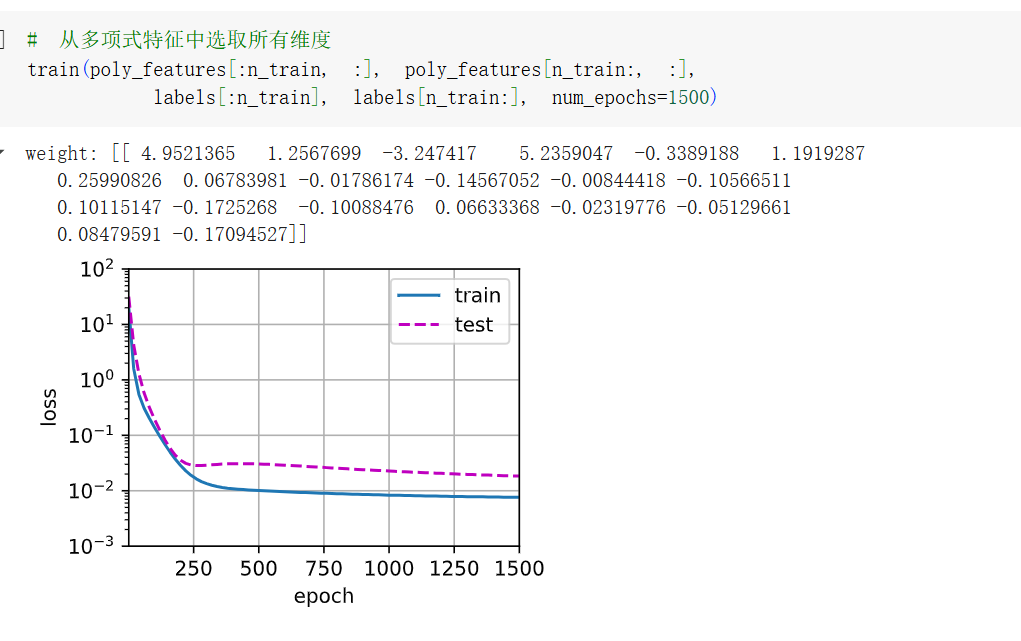
def train(train_features, test_features, train_labels, test_labels,num_epochs=400):#定義了一個訓練函數loss = nn.MSELoss(reduction='none')#均方誤差損失函數(MSE),但不求平均,保留每個樣本的損失值。input_shape = train_features.shape[-1]# 不設置偏置,因為我們已經在多項式中實現了它net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))batch_size = min(10, train_labels.shape[0])train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),batch_size)#把訓練和測試數據打包成 DataLoader,方便模型一批一批訓練test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),batch_size, is_train=False)trainer = torch.optim.SGD(net.parameters(), lr=0.01)#使用隨機梯度下降(SGD)優化模型參數,學習率為 0.01animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',xlim=[1, num_epochs], ylim=[1e-3, 1e2],legend=['train', 'test'])#用 D2L 里的 Animator 動態繪圖類,記錄訓練過程的 loss 曲線for epoch in range(num_epochs):#訓練一個 epoch,用的是 D2L 中封裝好的 train_epoch_ch3(每輪完整訓練一遍所有 batch)d2l.train_epoch_ch3(net, train_iter, loss, trainer)if epoch == 0 or (epoch + 1) % 20 == 0:#每隔20輪(或第1輪),就評估一下訓練集和測試集上的平均損失,然后加到圖上animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),evaluate_loss(net, test_iter, loss)))print('weight:', net[0].weight.data.numpy()) #打印最終訓練得到的權重PyTorch + 多項式特征訓練一個線性模型,并可視化訓練過程的
-
用線性模型擬合你設計的多項式數據(多階特征)
-
使用 MSELoss + SGD 訓練
-
可視化訓練和測試集上的損失變化
-
打印最終訓練好的模型參數,看看學得準不準
按書中的報錯然后,你調用了 l.backward() 來反向傳播,但這個 l 是一個 不需要梯度 的張量(requires_grad=False),所以無法反向傳播!
還是之前的做法:
loss = nn.MSELoss(reduction='none')返回的是一個 每個樣本的損失 的張量,而不是所有樣本損失的平均或總和。看看 train_epoch_ch3 的定義),它里面可能是直接用了 l = loss(y_hat, y),然后 l.backward()。
修改后
![]()
正常:
欠擬合
如果用不同復雜度的模型來擬合這個函數,表現會怎樣?
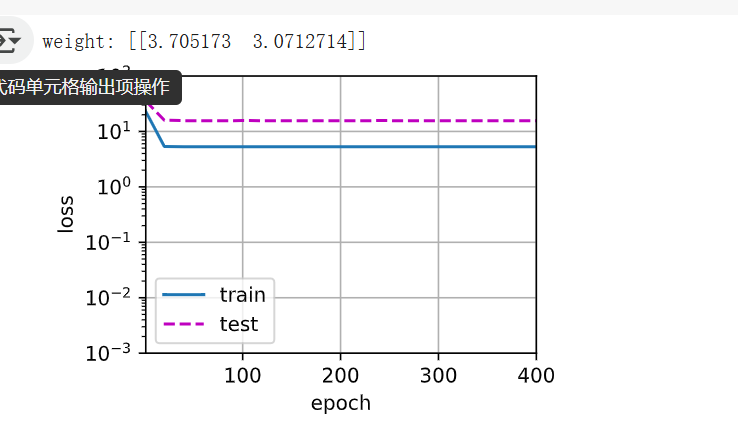
# 只用 1 和 x 兩項(線性模型)
train(poly_features[:n_train, :2], poly_features[n_train:, :2],labels[:n_train], labels[n_train:])
這意味著你在訓練一個線性模型:
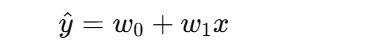
這個模型完全忽略了二階項 x2 和三階項 x3,所以它根本學不出原來的復雜模式。
結果就是:
-
訓練損失很高
-
測試損失也高
-
模型欠擬合:學得太簡單,跟不上真實的非線性函數
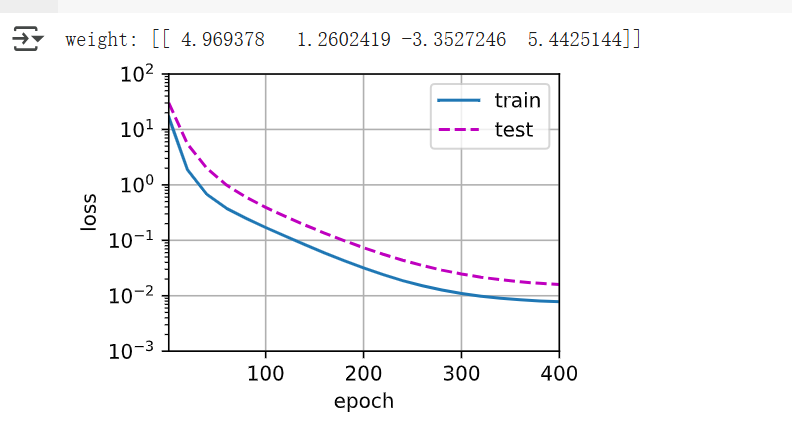
# 使用與真實模型相同的特征階數
train(poly_features[:n_train, :4], poly_features[n_train:, :4],labels[:n_train], labels[n_train:])
?這次你用了前4項:
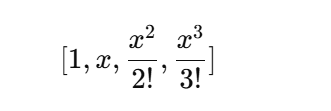
注意:你訓練的時候也會擬合這幾個特征,也就是:

而我們真實函數 y = 5 + 1.2x - 3.4x^2 + 5.6x^3,剛好就是3階多項式
-
訓練損失下降得更快
-
最終損失更低
-
模型可以很好地擬合數據,不欠擬合也不過擬合
 ?
?
poly_features[:, :] 表示使用 所有20階的多項式特征,也就是: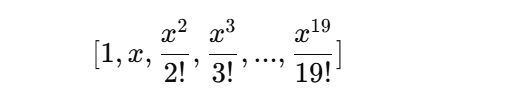
-
訓練了一個 20維輸入的線性模型
-
訓練次數設為 1500 輪(比前面更多)
-
但現在用一個 包含20階的模型 去擬合這些數據,雖然原函數只有3階,后面17個高階項都是“多余的”。
-
訓練集表現很好(損失很低),但在測試集上 泛化能力變差



)
)








)


)


