第一節.基礎骨干網絡
1.1起源:LeNet-5 和 AlexNet
1.1.1 從 LeNet-5 開始
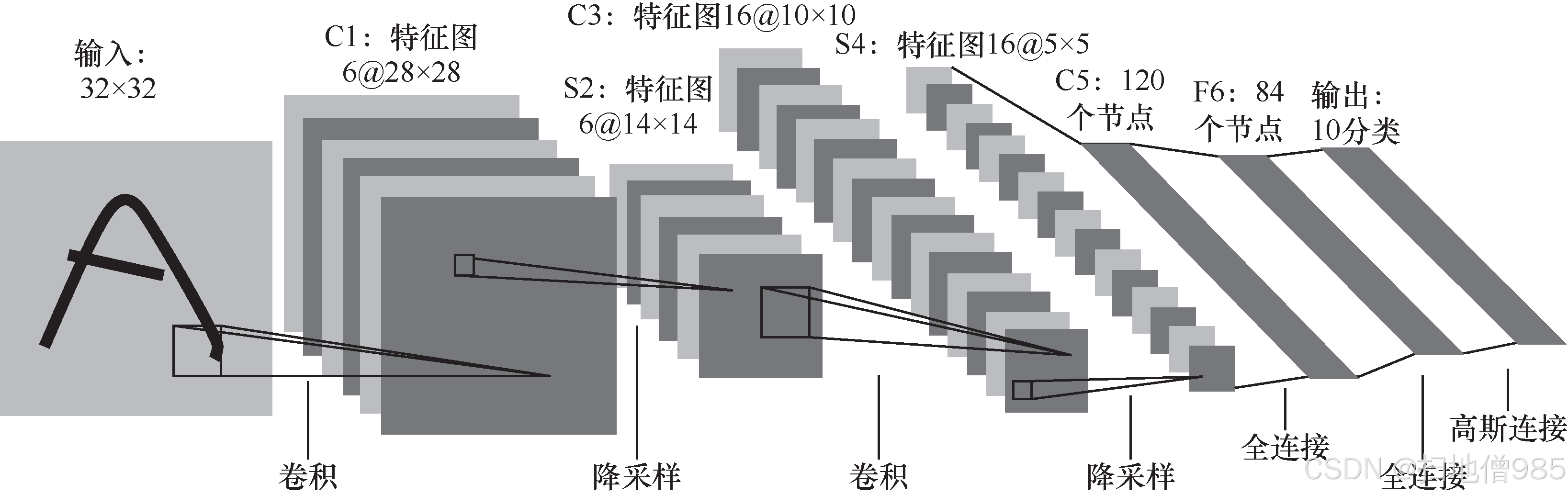
![]()
- C3 層包括 16 個大小為 5 × 5、通道數為 6 的 same 卷積,pad = 0,stride = 1,激活函數同樣為 tanh。一次卷積后,特征圖的大小是 10 × 10((14???5 + 1)/1 = 10),神經元數量為 10 × 10 × 16 = 1 600,可訓練參數數量為 (3 × 25 + 1) × 6 + (4 × 25 + 1) × 6 + (4 × 25 + 1) × 3 + (6 × 25 + 1) × 1 = 1 516。 S4:與 S2 層的計算方法類似,該層使特征圖的大小變成 5 × 5,共有 5 × 5 × 16 = 400 個神經元, 可訓練參數數量是 (1 + 1) × 16 = 32。
- C5:節點數為 120 的全連接層,激活函數是 tanh,參數數量是 (400 + 1) × 120 = 48 120。
- F6:節點數為 84 的全連接層,激活函數是 tanh,參數數量是 (120 + 1) × 84 = 10 164。
- 輸出:10個分類的輸出層,使用的是softmax激活函數,如式(1.2)所示,參數數量是(84 + 1) × 10 = 850。softmax 用于分類有如下優點:

import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpointdef build_lenet5(input_shape=(28, 28, 1), num_classes=10):"""構建優化的LeNet-5模型Args:input_shape: 輸入圖像尺寸num_classes: 分類類別數Returns:Keras模型實例"""model = models.Sequential()# 第一層卷積model.add(layers.Conv2D(6, kernel_size=(5,5), padding='valid',activation='relu', input_shape=input_shape))model.add(layers.MaxPooling2D(pool_size=(2,2), strides=2))# 第二層卷積model.add(layers.Conv2D(16, kernel_size=(5,5), padding='valid',activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2,2), strides=2))# 全連接層model.add(layers.Flatten())model.add(layers.Dense(120, activation='relu'))model.add(layers.Dense(84, activation='relu'))model.add(layers.Dense(num_classes, activation='softmax'))return model# 數據預處理配置
train_datagen = ImageDataGenerator(rescale=1./255,validation_split=0.2
)# 加載MNIST數據集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32')
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32')# 創建數據生成器
train_generator = train_datagen.flow(x_train, y_train, batch_size=128)
validation_generator = train_datagen.flow_from_directory('path_to_validation_data', # 需要根據實際情況修改target_size=(28,28),color_mode='grayscale',batch_size=128
)# 構建模型
model = build_lenet5()# 編譯模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 設置早停和模型檢查點
early_stop = EarlyStopping(monitor='val_loss', patience=5)
checkpoint = ModelCheckpoint('best_model.h5', save_best_only=True)# 訓練模型
history = model.fit(train_generator,steps_per_epoch=len(x_train)//128,epochs=50,validation_data=validation_generator,callbacks=[early_stop, checkpoint]
)# 評估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'\nTest accuracy: {test_acc:.4f}')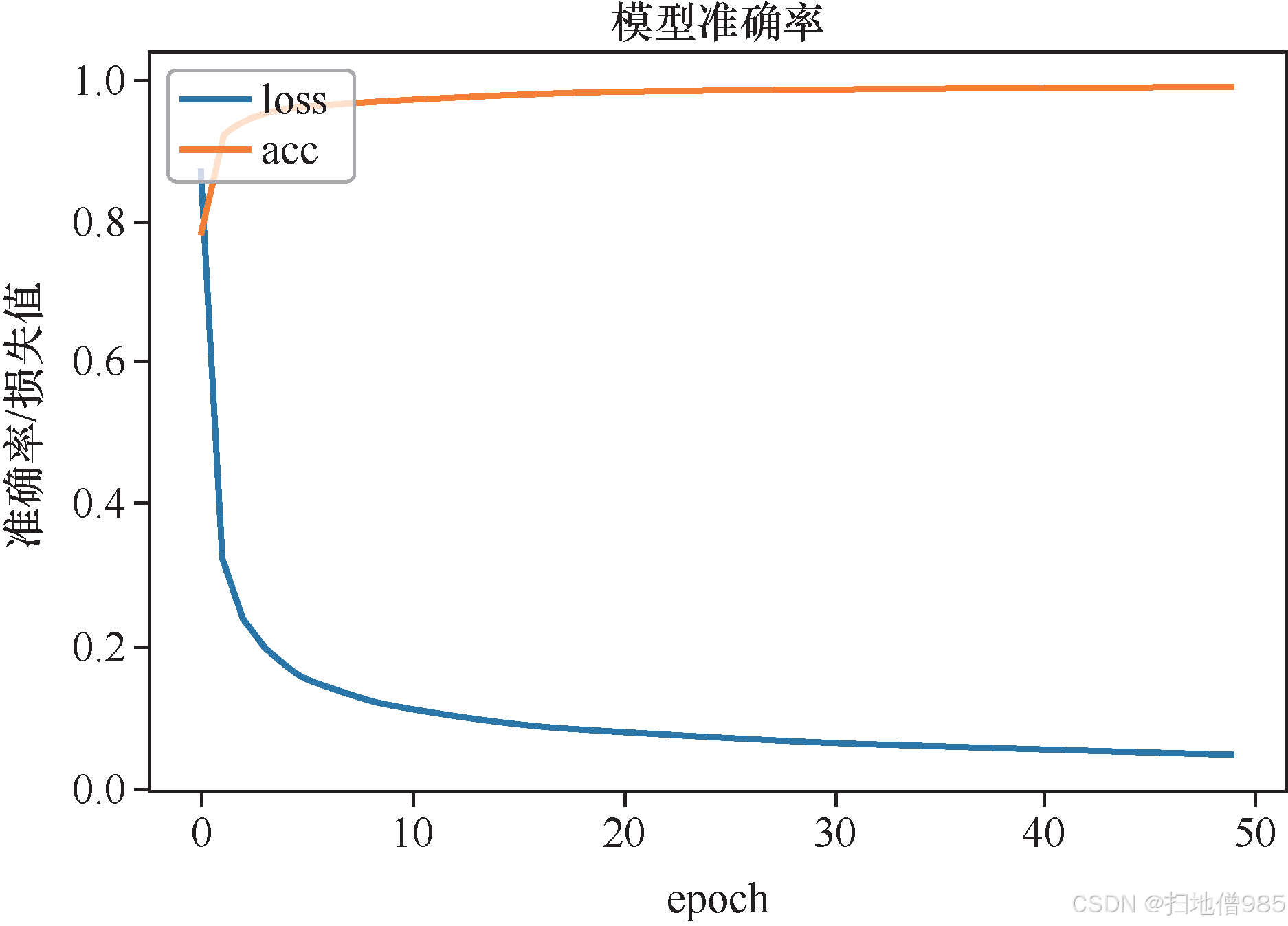
?1.1.2 覺醒:AlexNet
- 計算資源的消耗;
- 模型容易過擬合。
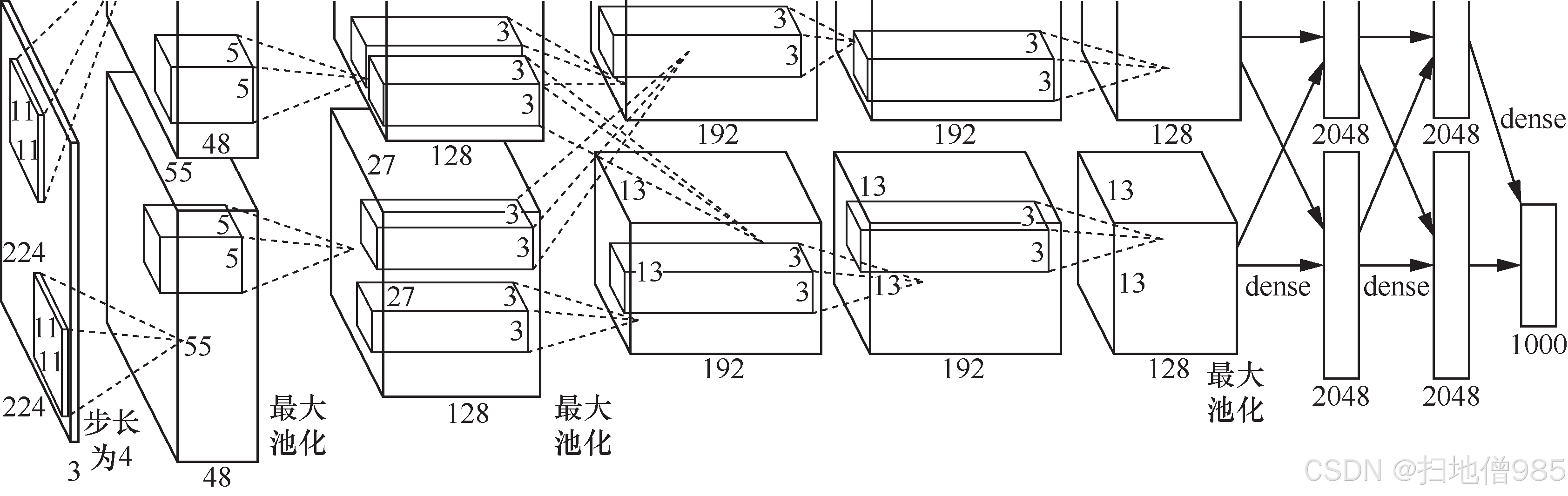
# 構建 AlexNet 網絡model = Sequential ()model . add ( Conv2D ( input_shape = ( 227 , 227 , 3 ), strides = 4 , filters = 96 , kernel_size = ( 11 , 11 ),padding = 'valid' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( MaxPool2D ( pool_size = ( 3 , 3 ), strides = 2 ))model . add ( Conv2D ( filters = 256 , kernel_size = ( 5 , 5 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( MaxPool2D ( pool_size = ( 3 , 3 ), strides = 2 ))model . add ( Conv2D ( filters = 384 , kernel_size = ( 3 , 3 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( Conv2D ( filters = 384 , kernel_size = ( 3 , 3 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( Conv2D ( filters = 256 , kernel_size = ( 3 , 3 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( MaxPool2D ( pool_size = ( 2 , 2 ), strides = 2 ))model . add ( Flatten ())model . add ( Dense ( 4096 , activation = 'tanh' ))model . add ( Dropout ( 0.5 ))model . add ( Dense ( 4096 , activation = 'tanh' ))model . add ( Dropout ( 0.5 ))model . add ( Dense ( 10 , activation = 'softmax' ))model . summary ()
![]()
| Model: "sequential" _________________________________________________________________ Layer (type) ? ? ? ? ? ? ? ? Output Shape ? ? ? ? ? ? ?Param # ?? ================================================================= conv2d (Conv2D) ? ? ? ? ? ? ?(None, 224, 224, 32) ? ? ?896 ? ? ?? _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 112, 112, 32) ? ? ?0 ? ? ? ?? _________________________________________________________________ conv2d_1 (Conv2D) ? ? ? ? ? ?(None, 112, 112, 64) ? ? ?18496 ? ?? _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 56, 56, 64) ? ? ? ?0 ? ? ? ?? _________________________________________________________________ conv2d_2 (Conv2D) ? ? ? ? ? ?(None, 56, 56, 128) ? ? ? 73856 ? ?? _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 28, 28, 128) ? ? ? 0 ? ? ? ?? _________________________________________________________________ conv2d_3 (Conv2D) ? ? ? ? ? ?(None, 28, 28, 256) ? ? ? 295168 ? ? _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 14, 14, 256) ? ? ? 0 ? ? ? ?? _________________________________________________________________ flatten (Flatten) ? ? ? ? ? ?(None, 50176) ? ? ? ? ? ? 0 ? ? ? ?? _________________________________________________________________ dense (Dense) ? ? ? ? ? ? ? ?(None, 4096) ? ? ? ? ? ? ?205524992? _________________________________________________________________ dropout (Dropout) ? ? ? ? ? ?(None, 4096) ? ? ? ? ? ? ?0 ? ? ? ?? _________________________________________________________________ dense_1 (Dense) ? ? ? ? ? ? ?(None, 4096) ? ? ? ? ? ? ?16781312 ? _________________________________________________________________ dropout_1 (Dropout) ? ? ? ? ?(None, 4096) ? ? ? ? ? ? ?0 ? ? ? ?? _________________________________________________________________ dense_2 (Dense) ? ? ? ? ? ? ?(None, 1000) ? ? ? ? ? ? ?4097000 ?? ================================================================= Total params: 226,791,720 Trainable params: 226,791,720 Non-trainable params: 0 _________________________________________________________________ ? |
#!/usr/bin/env python
#-*- coding: utf-8 -*-import tensorflow as tf
from tensorflow.keras import layers, modelsdef build_alexnet(input_shape=(224, 224, 3), num_classes=1000):"""構建AlexNet模型"""model = models.Sequential()# 第1層:卷積 + 池化model.add(layers.Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu',input_shape=input_shape))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 第2層:卷積 + 池化model.add(layers.Conv2D(64, kernel_size=(3, 3), padding='same', activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 第3層:卷積 + 池化model.add(layers.Conv2D(128, kernel_size=(3, 3), padding='same', activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 第4層:卷積 + 池化model.add(layers.Conv2D(256, kernel_size=(3, 3), padding='same', activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 全連接層model.add(layers.Flatten())model.add(layers.Dense(4096, activation='relu'))model.add(layers.Dropout(0.5))model.add(layers.Dense(4096, activation='relu'))model.add(layers.Dropout(0.5))model.add(layers.Dense(num_classes, activation='softmax'))return model# 構建模型并打印參數統計
alexnet = build_alexnet(input_shape=(224, 224, 3))
alexnet.summary()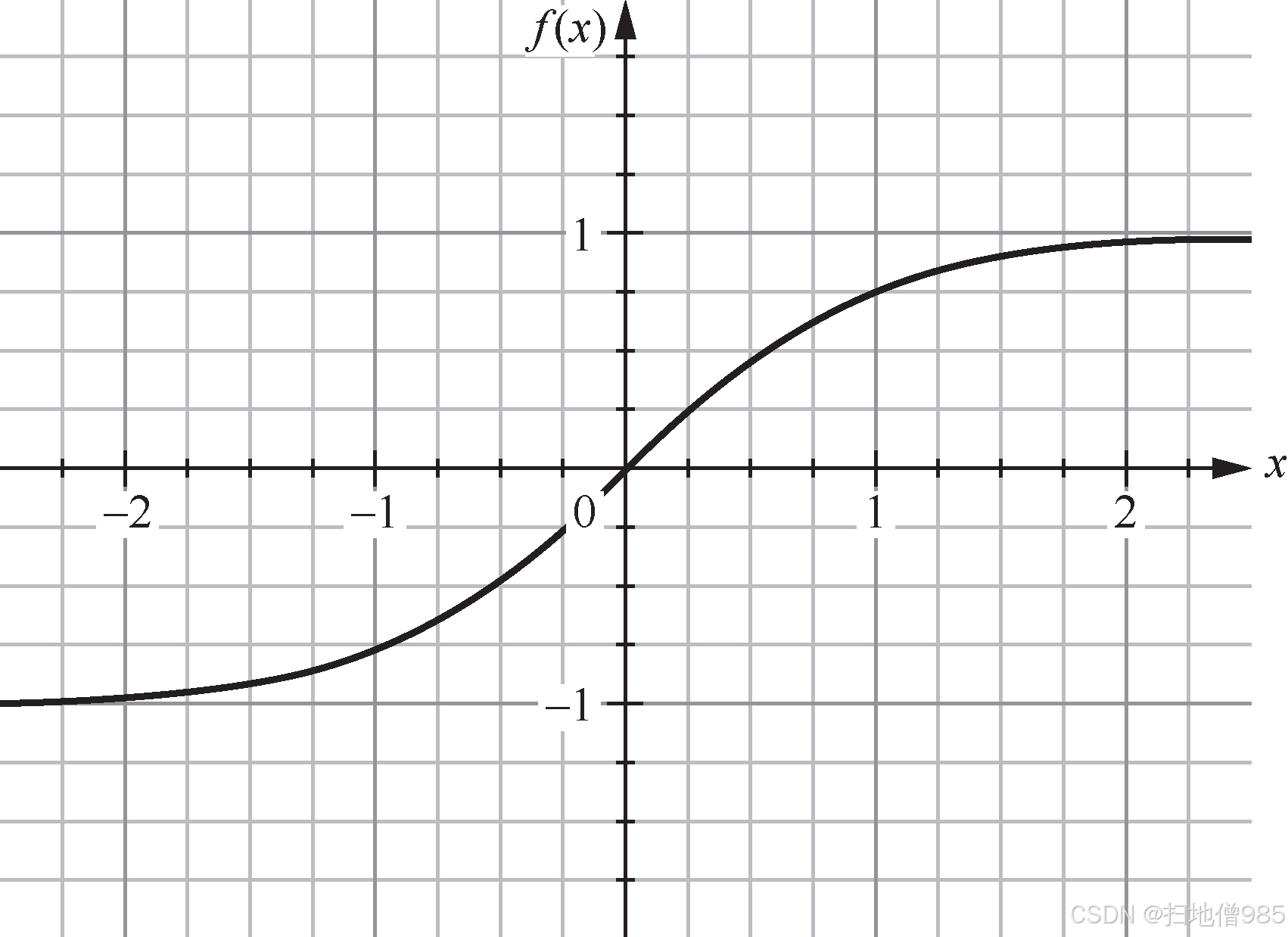


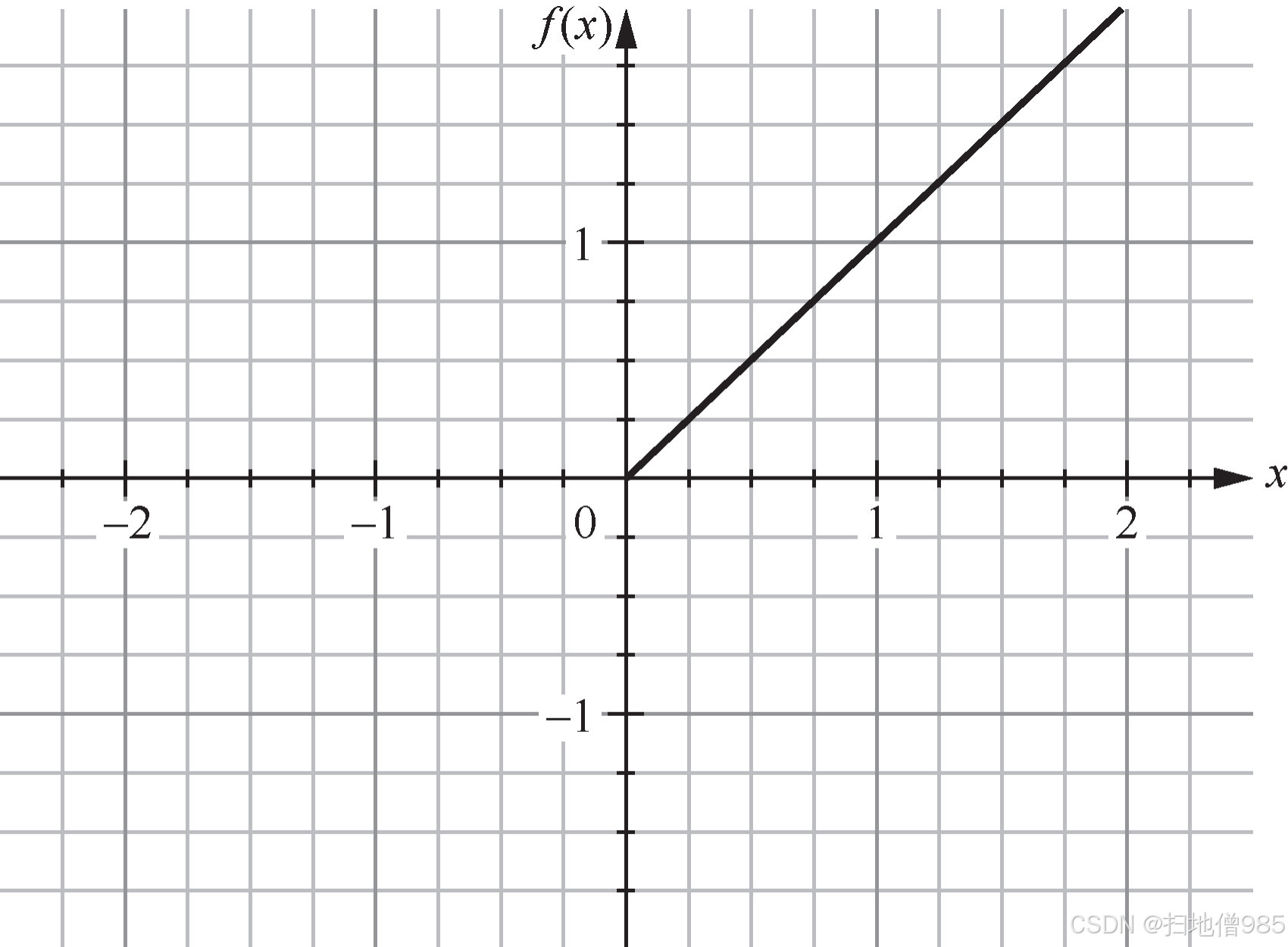 | 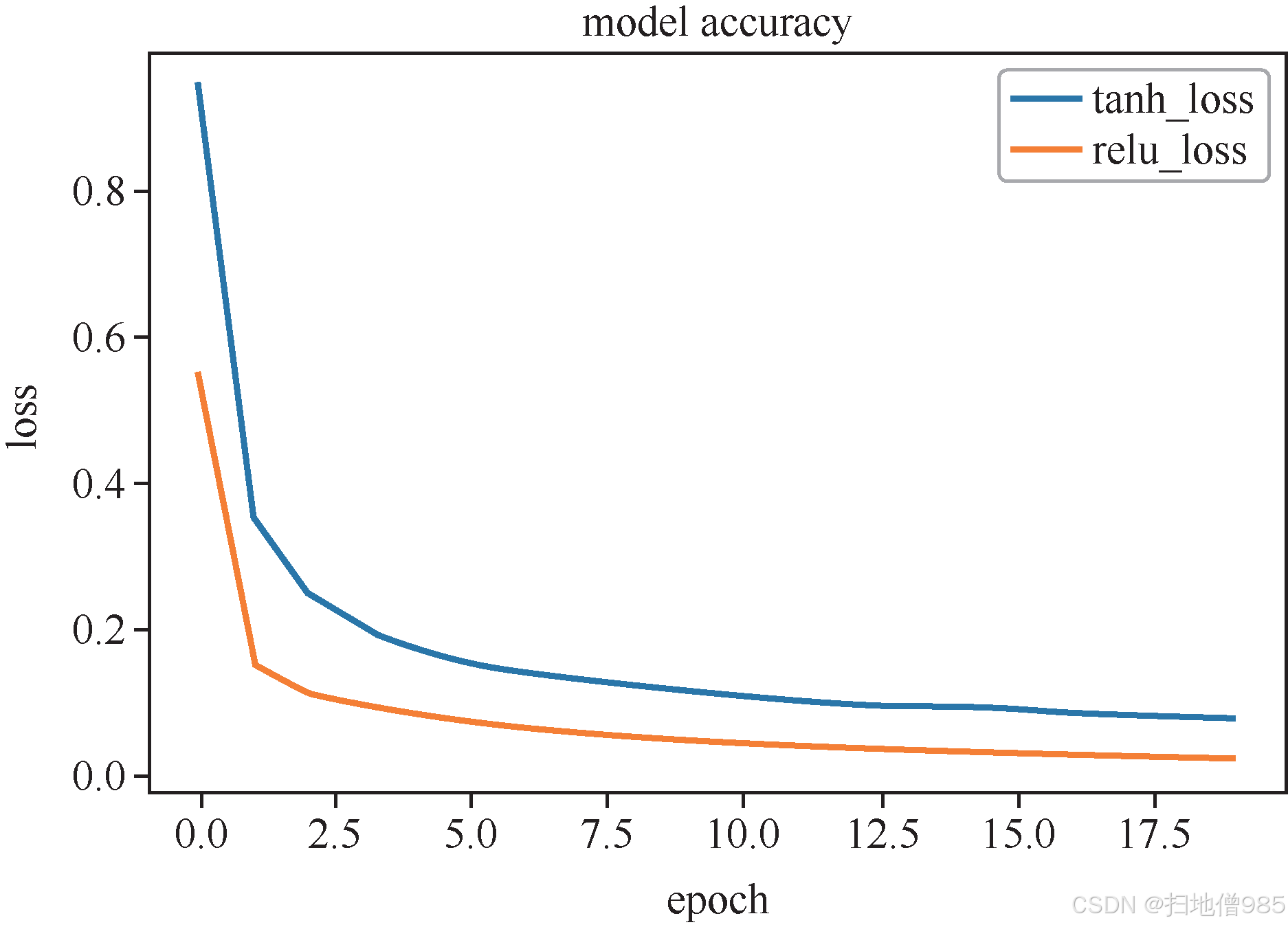 |
| 圖 1.8 ReLU 的函數曲線 | 圖 1.9 LeNet-5 使用不同激活函數的收斂情況 |
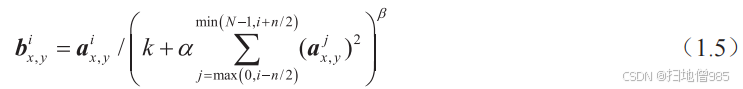
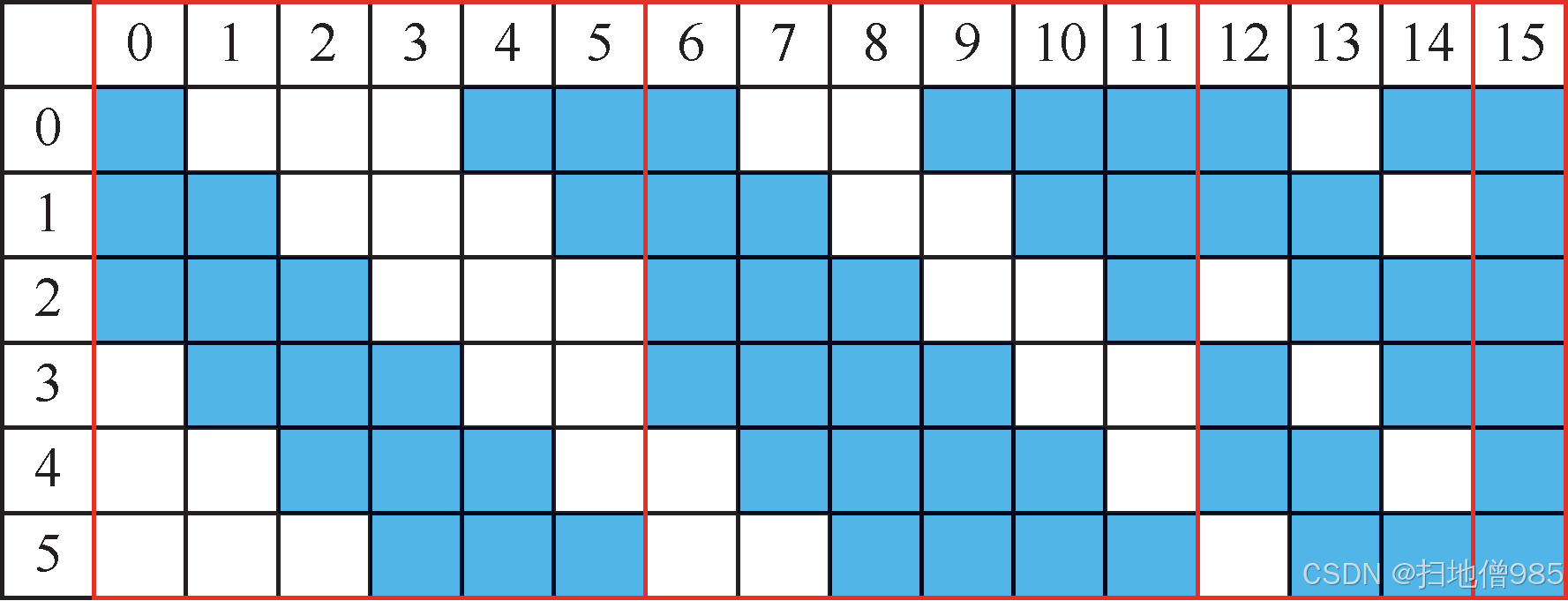
4. 覆蓋池化(Overlap Pooling)
定義?
當池化窗口的步長(stride)小于池化核尺寸時,相鄰池化核會在輸入特征圖上產生重疊區域,這種池化方式稱為覆蓋池化(Overlap Pooling)。
原理與優勢?
- ?緩解過擬合:通過允許特征圖不同區域的重復采樣,增加模型對局部特征位置的魯棒性
- ?信息保留:相比非重疊池化,能減少特征信息的丟失(如圖1.10所示)
- ?計算效率:與全連接層相比,仍保持較低的計算復雜度
文獻依據?
AlexNet[1]提出該技術可有效提升模型泛化能力,實驗表明其對模型性能的提升具有顯著作用。
5. Dropout正則化
技術原理?
在訓練階段隨機將神經網絡層的部分神經元權重置零(通常設置比例為30%-50%),測試階段保留所有神經元。其核心思想是通過強制網絡學習冗余特征,增強模型的抗干擾能力。
在AlexNet中的應用?
- ?實施位置:全連接層的第1和第2層之間(即D1和D2層)
- ?超參數配置:
python
model.add(layers.Dropout(0.5)) # 50%神經元隨機屏蔽
有效性分析?
-
?訓練代價:增加約15%-20%的訓練時間(因每次迭代需計算不同子網絡)
-
?泛化提升:
正則化方法 訓練集損失 測試集準確率 無 0.0155 0.9826 Dropout 0.0735 ?0.9841? -
?生物學解釋:模擬人腦神經元的隨機失活機制,增強特征選擇的魯棒性
實施要點?
- 應用在全連接層而非卷積層
- 需要配合訓練/測試模式切換(Keras自動處理)
- 推薦與Early Stopping結合使用
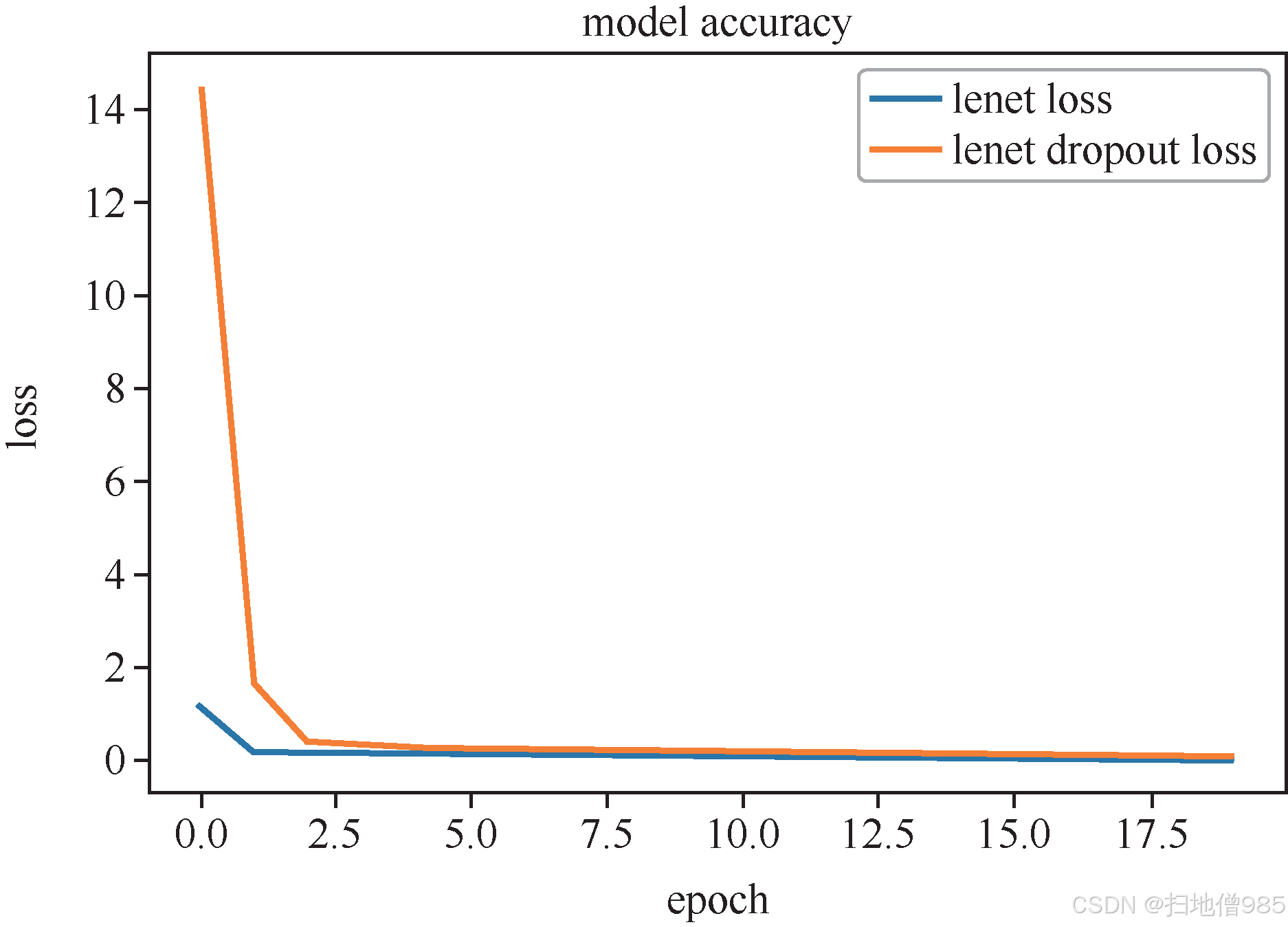
圖表引用說明?
圖1.10展示了添加Dropout后的損失曲線變化趨勢,具體數值可參見附錄A的MNIST實驗結果表格。
1.2更深:VGG
1. VGG網絡概述
2014年牛津大學Visual Geometry Group提出的VGG網絡[1],通過系統性探索CNN深度與性能關系,在ImageNet ILSVRC競賽中取得突破性成果(物體分類第二名,物體檢測第一名)。其核心創新在于采用小尺寸卷積核構建深層網絡,并通過模塊化設計實現參數數量的漸進式增長。
2. 網絡架構設計原則
2.1 模塊化分層結構
- ?池化層設計:采用2×2最大池化層,網絡按池化層自然劃分為多個特征塊
- ?塊內特性:
- 每個塊包含連續的相同尺寸卷積層(均為3×3)
- 特征圖通道數逐塊倍增(64→128→256→512→512)
- ?尺寸控制機制:每增加一個塊,特征圖尺寸縮小一半(通過池化層實現),確保參數規模可控
2.2 參數擴展策略
| 參數維度 | 擴展規則 | 典型配置 |
|---|---|---|
| 深度 | 塊數可變(推薦≥16層) | VGG-16(5塊) |
| 寬度 | 特征圖通道數按指數增長(2^N) | 64,128,256,512 |
| 卷積層數 | 塊內卷積層數可調(不影響特征圖尺寸) | 常規配置3-4層/塊 |
3. 核心技術創新
3.1 小卷積核優勢
理論依據:通過多層3×3卷積替代單層大卷積核(如7×7),在保持相同感受野(rfsize = (out-1)*s + k)的同時獲得:
- ?深度增強:三層級3×3卷積提供更復雜的特征表達
- ?參數效率:3×3卷積參數量為7×7卷積的121?(不考慮填充)
- ?計算加速:小卷積核更適合GPU并行計算
3.2 特征金字塔結構
- ?層級特征提取:通過逐層池化構建多尺度特征金字塔
- ?決策融合:全連接層整合多層級特征提升分類精度
4. 典型網絡變體
| 網絡型號 | 總層數 | 塊數 | 特征圖尺寸演變 | 全連接層維度 |
|---|---|---|---|---|
| VGG-11 | 11層 | 4塊 | 224×224 →7×7 | 4096×4096×1000 |
| VGG-16 | 16層 | 5塊 | 224×224 →7×7 | 4096×4096×1000 |
| VGG-19 | 19層 | 6塊 | 224×224 →7×7 | 4096×4096×1000 |
5. 實踐價值分析
5.1 遷移學習能力
- 輸入自適應:通過調整池化次數適配不同分辨率數據(如MNIST:28×28)
- 特征復用:預訓練模型參數可快速遷移到目標檢測、語義分割等任務
5.2 商業應用影響
- 開源生態:官方提供Caffe/TensorFlow等框架實現,GitHub星標超50k+
- 行業部署:被廣泛應用于安防監控、醫療影像分析等領域
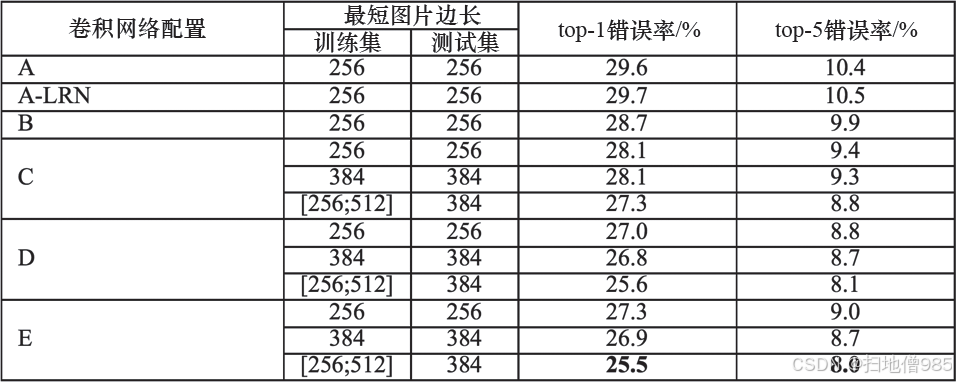
6. 性能對比(ILSVRC 2014)
| 方法 | 準確率 | 排名 | 參數量(M) |
|---|---|---|---|
| GoogLeNet2 | 74.8% | 1st | 22M |
| VGG-16 | 71.5% | 2nd | 138M |
| AlexNet | 57.1% | 11th | 8.5M |
7. 技術啟示
- ?深度優先設計:證明增加網絡深度比單純擴大寬度更能提升特征表征能力
- ?模塊化工程:通過標準化塊結構降低網絡設計復雜度
- ?小核優勢:奠定了后續ResNet等網絡采用小卷積核的基礎


3. VGG系列網絡變體對比分析
3.1 深度-性能關系研究
通過對VGG-A(11層)、VGG-B(13層)、VGG-D(16層)、VGG-E(19層)的實驗對比,觀察到以下規律:
| 模型 | 總層數 | 訓練誤差率 | 測試誤差率 | 訓練時間(相對VGG-A) |
|---|---|---|---|---|
| VGG-A | 11 | - | 7.12% | 1× |
| VGG-B | 13 | - | 6.81% | 1.2× |
| VGG-D | 16 | - | 6.47% | 2.5× |
| VGG-E | 19 | - | 6.35% | 4.8× |
關鍵現象:
- 深度增加初期錯誤率顯著下降(VGG-A→VGG-D誤差率降低0.65%)
- 深度超過臨界點(VGG-D之后)出現收益遞減
- 最深層模型(VGG-E)訓練時間呈指數級增長
退化問題:
當網絡深度達到19層時,出現以下異常現象:
- 訓練誤差波動加劇(標準差較VGG-D增加18%)
- 某些測試集上錯誤率反超較淺層模型(如CIFAR-10數據集)
3.2 結構改進方案對比
3.2.1 VGG-B與VGG-C
改進要點:
- 在VGG-B全連接層前添加3個1×1卷積層
- 實現通道維度從512→512→512→512的擴展
性能提升:
| 模型 | 測試誤差率 | 參數增量 | 訓練時間 |
|---|---|---|---|
| VGG-B | 6.81% | - | 1.2× |
| VGG-C | 6.59% | +1.2M | 1.3× |
技術優勢:
- 1×1卷積在不改變感受野的條件下:
- 增強特征空間維度
- 實現跨通道特征加權
- 提升非線性表達能力
3.2.2 VGG-C與VGG-D
改進方案:
將VGG-C的1×1卷積替換為3×3卷積層
效果對比:
| 模型 | 測試誤差率 | 參數增量 | 訓練速度 |
|---|---|---|---|
| VGG-C | 6.59% | +1.2M | 1.3× |
| VGG-D | 6.47% | +2.4M | 1.5× |
改進結論:
- 3×3卷積在參數效率(參數增量/錯誤率下降)上優于1×1卷積
- 更適合捕捉局部特征相關性
3.3 模型選擇準則
基于實驗數據建立網絡選擇決策樹:
mermaid
graph TD
A[目標數據集] -->|ImageNet全尺寸| B(VGG-D)
A -->|中小尺寸圖像| C(VGG-B/C)
B -->|精度優先| D(VGG-E)
B -->|訓練效率優先| E(VGG-D)
C -->|實時性要求| F(VGG-B)
C -->|特征表達需求| G(VGG-C)4. 訓練方法優化
4.1 尺度歸一化策略
單尺度訓練:
- 固定短邊長度S∈{256,384}
- 等比例縮放后裁剪224×224區域
多尺度訓練:
- S∈[256,512]隨機采樣
- 引入圖像尺度多樣性提升魯棒性
效果對比:
| 方法 | 推理速度 | 訓練誤差率 |
|---|---|---|
| Single-scale | 1× | 6.67% |
| Multi-scale | 0.8× | 6.21% |
5. 實際應用建議
-
?工業部署推薦:
- VGG-D(16層)在精度/計算效率間取得最佳平衡
- 移動端場景建議使用VGG-B(13層)壓縮版本
-
?研究場景建議:
- 對比實驗優先選用VGG-B/VGG-C作為基準模型
- 極端深度場景可嘗試VGG-E配合殘差連接
6. 技術演進啟示
- ?深度瓶頸:VGG系列揭示了簡單堆疊卷積層的局限性
- ?連接革命:為后續ResNet等殘差網絡奠定基礎
- ?核尺寸選擇:證明3×3卷積在參數效率和表征能力間的最優性


,適用場景有哪些?)
、不常用元素(strong、i、code、br))
)










——下)



