
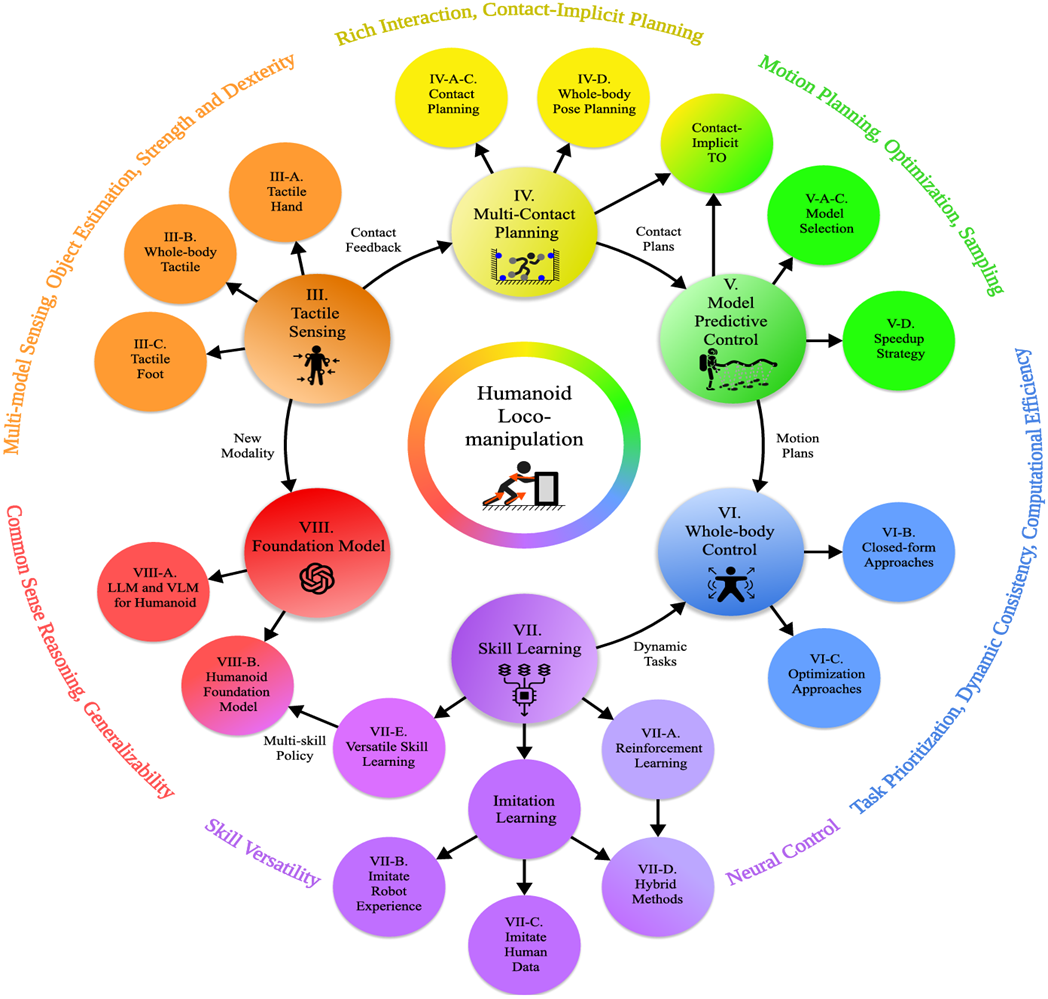
-
作者: Zhaoyuan Gu, Junheng Li, Wenlan Shen, Wenhao Yu, Zhaoming Xie, Stephen McCrory, Xianyi Cheng, Abdulaziz Shamsah, Robert Griffin, C. Karen Liu, Abderrahmane Kheddar, Xue Bin Peng, Yuke Zhu, Guanya Shi, Quan Nguyen, Gordon Cheng, Huijun Gao, and Ye Zhao
-
單位:喬治亞理工學院,南加州大學,慕尼黑工業大學,谷歌DeepMind,人工智能研究所,人機認知研究所,杜克大學,斯坦福大學,法國國家科學研究中心-蒙彼利埃大學,CNRS-AIST聯合機器人實驗室,西蒙弗雷澤大學,德克薩斯大學奧斯汀分校,NVIDIA,卡內基梅隆大學,哈爾濱工業大學
-
論文標題:Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
-
論文鏈接:https://arxiv.org/pdf/2501.02116
主要貢獻
-
論文回顧了近三十年仿人機器人領域基于模型的規劃與控制方法,同時探討了新興學習方法,尤其是強化學習和模仿學習。
-
討論了將基礎模型與仿人機器人結合的潛力,并評估了開發通用仿人智能體的前景,賦予仿人機器人更廣泛的知識和更強的推理能力。
-
強調了全身觸覺感知對于解鎖涉及物理交互的新仿人技能的重要性。觸覺傳感器能在視覺受限時提供更準確的環境感知,增強機器人的交互能力。
-
討論了當前面臨的挑戰和未來研究方向,包括數值優化、基準測試缺乏、數據稀缺以及基礎模型在仿人機器人中的應用。
介紹

仿人機器人(Humanoid Robots)因其類人形態,特別適合執行需要類似人類動作的任務,如全身運動和操作。它們在制造業和服務業中應用廣泛,能夠與人類協作完成復雜任務。
盡管仿人機器人潛力巨大,但同時實現復雜任務并應對高度復雜的機器人動力學仍充滿挑戰。這些任務要求機器人在動態環境中安全地與人協作,并在非結構化環境中進行操作。
為了快速獲取運動和認知技能,仿人機器人可以利用人類數據進行學習。借助人類知識,仿人機器人能夠實現快速的具身智能,從而加速技能獲取。
感知算法能夠實時檢測、分類和分割各種物體。基于模型的方法通過預測和反應控制,實現了敏捷且可靠的運動和操作。深度學習策略則通過探索和模仿,在機器人硬件上展示了良好的控制效果。
大型基礎模型的出現,為自主仿人機器人的構建提供了可能。這些模型經大規模數據訓練,具備開放世界推理能力,有力推動了仿人機器人領域的發展。
論文全面回顧了仿人機器人運動和操作的最新進展,以助力研究人員更好地把握該領域的最新動態和發展方向。
背景

仿人機器人
-
仿人機器人是指具有人類形態特征的機器人,通常具有軀干、雙臂和雙腿。盡管擬人化的程度可能有所不同,但這類機器人的目標是模仿人類的形態和功能。
-
論文強調,由于仿人機器人與人類在外觀和行為上的相似性,它們可以更方便地從人類演示中獲取技能數據。通過擴展數據和計算能力,仿人機器人可實現更廣泛的多功能性和泛化能力。
雙足行走和導航
-
雙足行走是仿人機器人的一個顯著特征,過去三十年中一直是研究的熱點領域。研究從被動行走發展到準靜態行走,再到動態行走。
-
研究還涉及在外部擾動和力負載下的雙足行走,為同時進行行走和操作奠定了基礎。基于模型的方法(如被動行走)和基于學習的方法(如強化學習和模仿學習)都取得了進展。
-
導航方面,雙足機器人需要能夠在復雜環境中有效導航,包括室內和室外環境。導航堆棧通常采用分層結構,包括全局路徑規劃器和局部步態規劃器。
全身操作
-
全身操作是指利用機器人所有部位進行交互的能力。這種能力在人類中很常見,例如使用肘部或臀部來保持門打開,或使用手掌提供更大的力量。
-
在機器人中實現全身操作面臨多重挑戰,包括系統層面的感知、估計、規劃和控制。機械設計、控制和規劃的突破已經實現了全身操作,但仍需進一步發展以應對復雜的接觸動力學和高維自由度系統的計算成本。
行走與操作
-
行走與操作是仿人機器人的關鍵特征之一,涉及同時進行行走和操作。這種方法要求機器人能夠利用整個身體與環境互動,以實現更廣泛的任務,如開門、推車等。
-
行走與操作需要整體和戰略性地使用整個身體,探索機器人的全部行為能力空間,并調度所有肢體的接觸以實現穩健的運動和安全的目標交互。

觸覺傳感器

觸覺傳感提供了一種直接且準確的感知方式,使機器人能夠更好地理解和適應復雜的環境和物體交互。
觸覺傳感的優勢
-
觸覺傳感模仿了人類的觸覺,能夠在機器人皮膚的大面積上提供比本體感受傳感器更準確的信息。它允許機器人在視覺被遮擋的情況下感知復雜環境并評估物體的屬性。
-
觸覺傳感可以用于估計接觸力、粗糙度、紋理和重量等信息,補充傳統的視覺信息(如位置、形狀和顏色)。
手部觸覺傳感
-
手部的觸覺傳感器用于復雜的操作任務,提供實時的接觸反饋。這些傳感器可以在力或阻抗控制回路中使用,以調節期望的物體行為。
-
基于觸覺的強化學習(RL)方法可以直接將觸覺測量整合到狀態空間中,訓練端到端的策略。然而,高維輸入空間和模擬接觸物理的困難是主要挑戰。
足部觸覺傳感
-
足部的觸覺傳感用于行走任務,估計地面反作用力(GRFs)和地形屬性。現有的工作使用力矩傳感器或負載單元傳感器來測量GRFs,但這些方法缺乏對接觸區域、力分布和地形細節的準確信息。
-
未來的研究方向包括如何準確估計更多的地形屬性(如硬度、阻尼、塑性、異質性和多孔性),以及如何將這些傳感信息與其他傳感模塊融合以提高機器人的地形感知能力。
全身觸覺傳感
-
全身觸覺傳感擴展了機器人的交互能力,使其不僅通過手或腳進行交互,還可以通過手臂、腿部和軀干進行交互。
-
這種傳感方式增強了機器人的平衡能力和碰撞避免能力,并在非結構化環境中提供了安全的物理人機交互。全身觸覺傳感在處理大物體和實現全身操作方面顯示出巨大潛力,但仍面臨動態感知和多模態傳感集成的挑戰。
多接觸規劃
多接觸規劃是指機器人在執行任務時與環境或物體進行多種接觸的規劃過程。
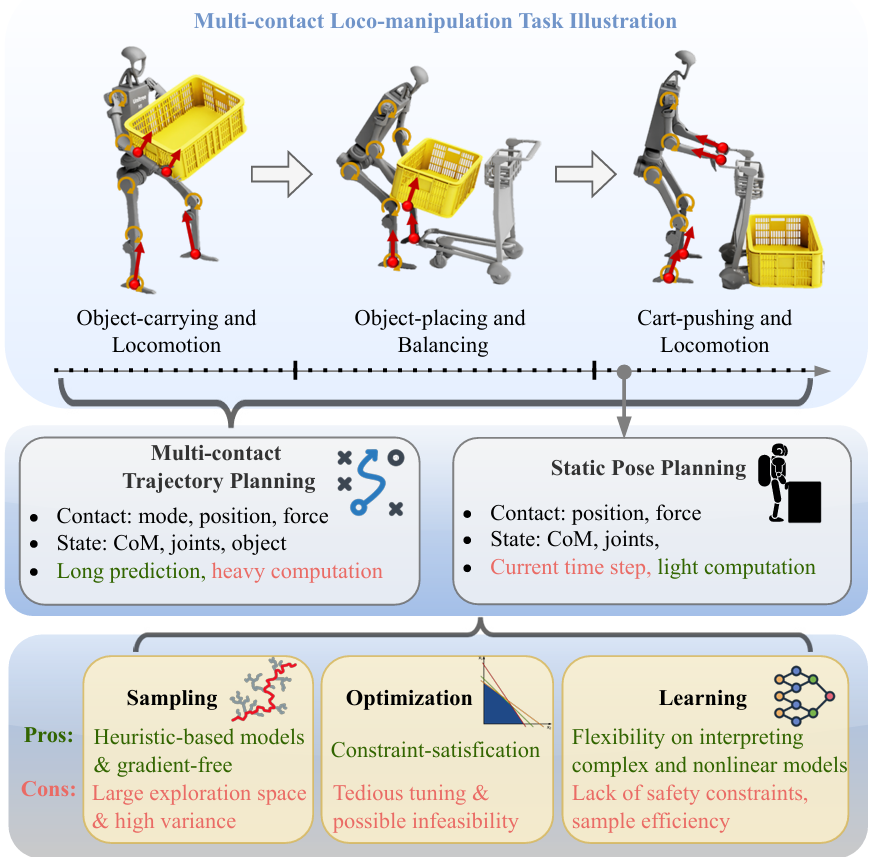
基于搜索的接觸規劃
-
這些方法通過狀態擴展來探索可能的配置,以創建和打破接觸。搜索過程中通常會檢查碰撞和運動可行性。
-
常用于腿部機器人的步態規劃。為了提高效率,研究者引入了統計方差減少技術(如控制變量和重要性采樣)來加速解決方案的收斂。
-
通過姿勢優化(Pose Optimization, PO)方法,可以在預定義的接觸模式下生成全身姿態和運動學配置,以減少搜索過程中的計算負擔。
基于優化方法的接觸規劃
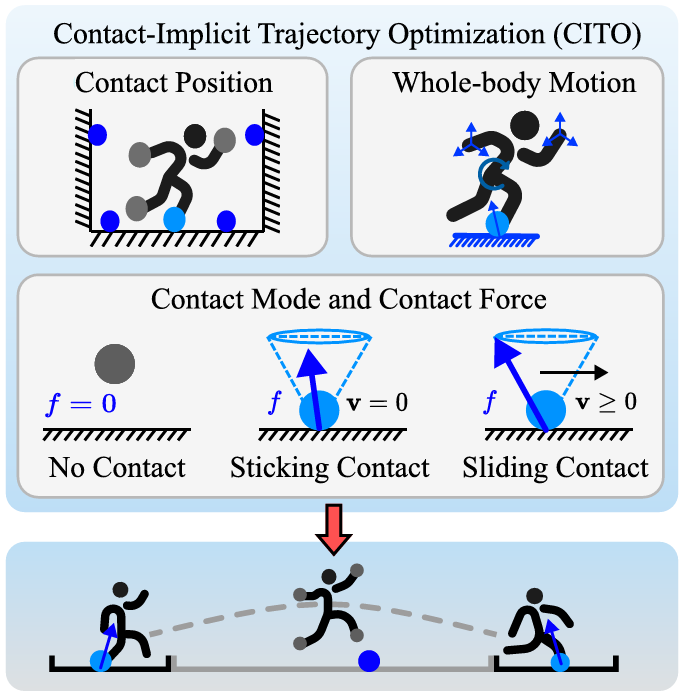
-
這些方法通過將接觸動力學納入軌跡優化公式,一次性確定接觸模式、接觸力、接觸位置和全身運動。
-
由于問題的規模較大,通常依賴于速度提升策略,如使用初始猜測進行快速收斂,或將問題分解為接觸規劃和全身運動規劃的子問題。
-
為了實現實時應用,研究人員還在探索混合方法,結合搜索和優化方法的優點。
基于學習的接觸規劃
-
學習方法,特別是強化學習(RL),通過試錯來發現新的行為。這些方法通常以模塊化的方式與基于模型的規劃器結合,形成層次結構。
-
學習方法可以提高多接觸規劃的效率,例如通過預測質心動力學演化來生成高效的接觸序列。
-
未來研究方向包括開發更集成的方法,結合搜索、優化和學習方法的優點,以解決計算復雜性和實時性能的問題。
模型預測控制
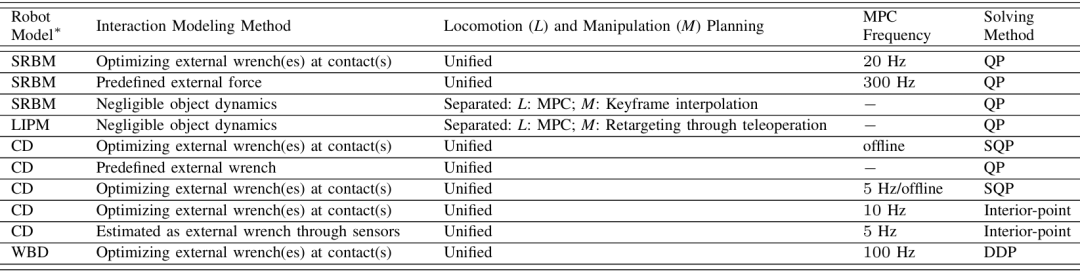
模型預測控制(MODEL PREDICTIVE CONTROL,MPC)是一種優化方法,通過在線求解最優控制問題來實現軌跡規劃和控制,用于仿人機器人移動與操作(loco-manipulation)
MPC的統一優化形式
-
MPC的目標是在未來有限的時間范圍內找到最優的狀態軌跡和控制輸入。其優化問題通常表示為一個最優控制問題(OCP),包含狀態軌跡、控制輸入和約束力的軌跡。
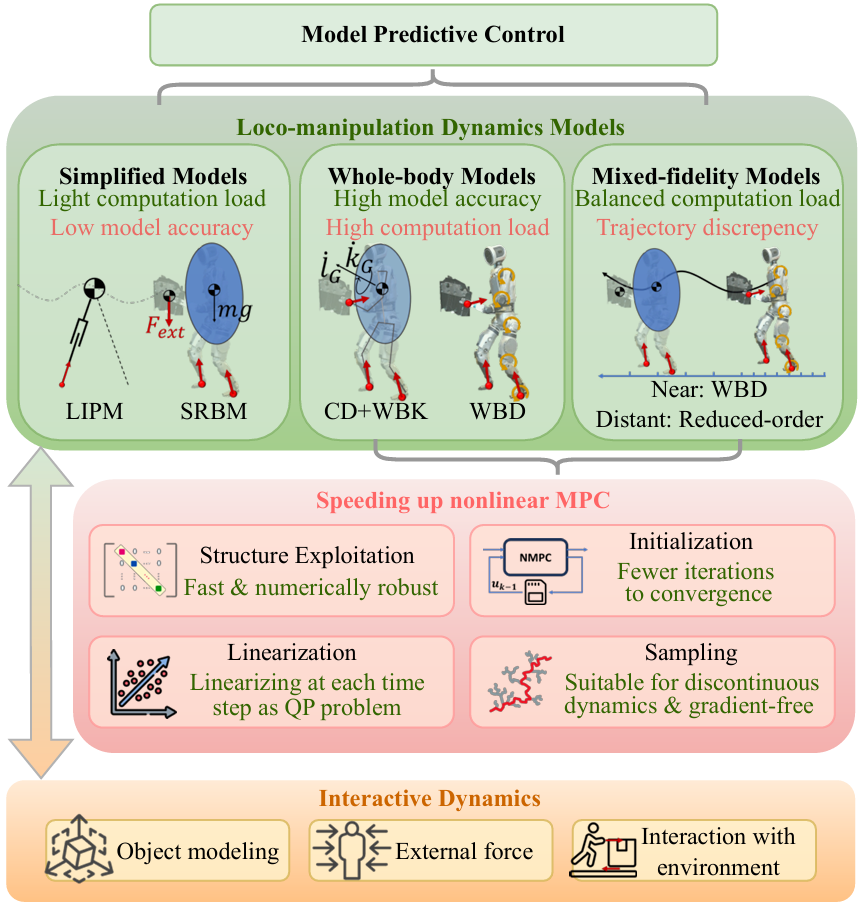
簡化模型
-
為了實現高頻在線規劃,研究者常使用簡化動力學模型(如單剛體模型SRBM和線性倒立擺模型LIPM)。這些模型通過線性化或近似來減少計算復雜性,適用于高頻控制。
-
例如,SRBM可以通過提供明確的足部位置序列參考來進行線性化,并在MIT仿人機器人上實現動態特技動作。
全身模型
-
全身模型(如質心動力學CD和全身動力學WBD)提供了更準確的機器人動力學表示,適用于規劃多樣化的運動和交互。
-
WBD模型在MPC中的應用需要處理高維度的非線性問題,計算復雜度較高,但能夠更好地捕捉機器人動力學特性。
混合保真度模型
-
混合保真度模型通過在MPC的不同時間范圍內使用不同精度的模型來提高性能和效率。例如,可以使用高保真模型在近時間段內進行精確計算,而在遠時間段內使用低保真模型以簡化計算。
MPC加速方法:
-
為了提高MPC的計算效率,研究者提出了多種加速方法,包括結構利用(Structure Exploitation)、線性化(Linearization)、預熱(Warm Start)和采樣(Sampling)。
-
結構利用通過提取問題中的結構來提高求解效率和數值穩定性。線性化通過逐時間步線性化來簡化問題,但可能會犧牲模型精度。預熱通過使用前一次迭代的解來初始化當前迭代,以提高收斂速度。采樣方法通過隨機采樣來擴大搜索空間,但需要有效的并行化技術。
環境和對象交互模型
-
在行走與操作的MPC中,需要考慮與靜態環境、操縱對象和動態環境的交互。
-
這些交互模型需要準確地建模接觸力和對象的動態特性,以實現穩定和可靠的機器人操作。
全身控制
全身控制(Whole-Body Control, WBC)旨在生成關節扭矩、約束力和廣義加速度,以實現給定的動態任務。
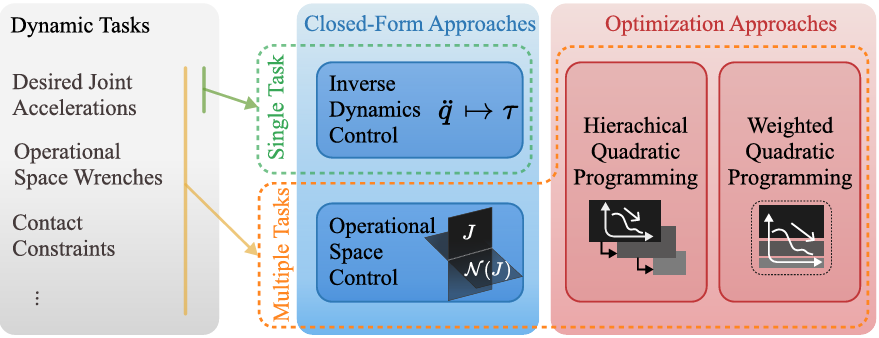
WBC的定義和應用場景
-
全身控制器用于生成關節級的控制信號,以跟蹤期望的軌跡并發送扭矩命令到物理機器人。它適用于三種常見的情況:基于簡化模型的軌跡計算、基于全階模型的軌跡規劃但計算過于復雜、以及在環境不確定性和規劃不準確性下需要魯棒的WBC。
WBC的動態任務
-
動態任務向量可以用決策變量的線性方程表示,涵蓋各種任務,如跟蹤參考關節空間加速度、操作空間加速度、質心動量率等。MPC常用于為WBC提供操作空間的動態任務。
WBC的封閉式方法
-
封閉式方法通過逆動力學控制器來解決WBC問題,通常用于單一動態任務。這些方法通過投影系統動力學來消除約束力,從而簡化計算。
-
盡管計算效率高,但封閉式方法難以處理不等式任務,如關節限制和障礙物避障。
WBC的優化方法
-
優化方法通過二次規劃(QP)或加權QP來增強WBC的靈活性,能夠處理多個動態任務和不等式任務。
-
嚴格任務層次結構通過順序求解多個QP子問題來確保任務優先級,而加權QP則通過軟約束來調整任務的相對優先級。
WBC在行走與操作中的應用
-
在行走與操作中,WBC需要同時實現期望的運動并保持瞬時平衡和接觸穩定性。根據環境或對象的動態特性,WBC可以分為兩種情況:作為外部力矩的交互和作為統一機器人-對象模型的交互。
移動與操作技能學習
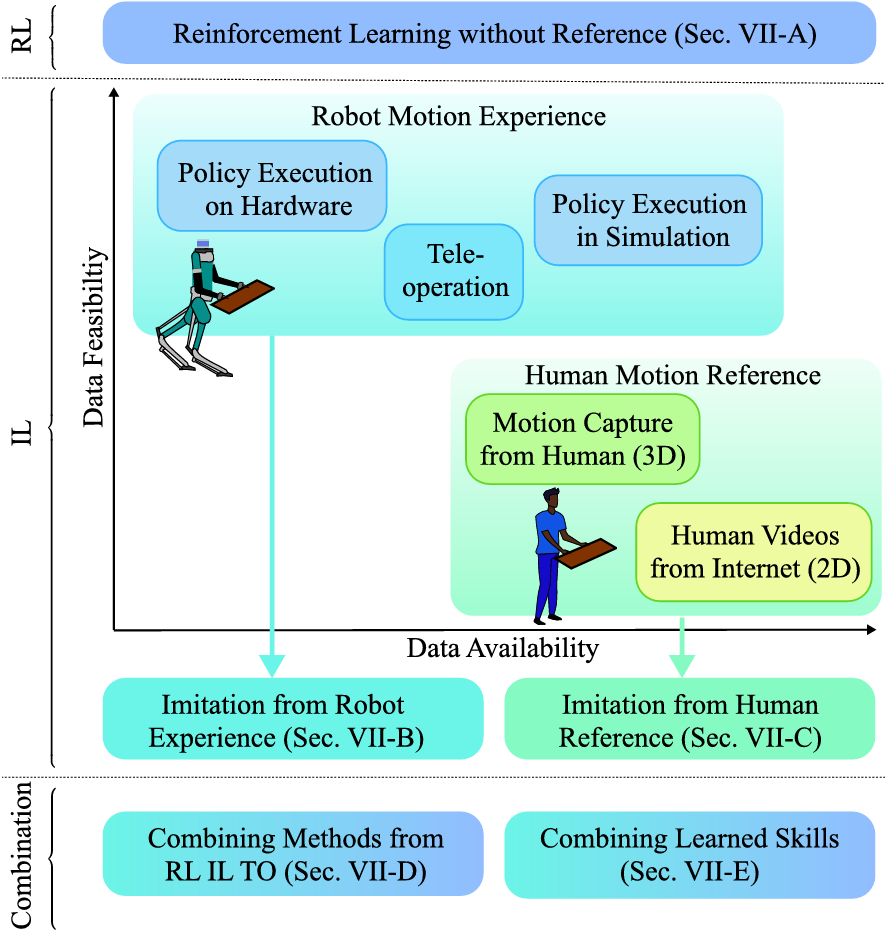
仿人機器人通過學習方法來獲取行走與操作(loco-manipulation)技能,主要包括兩種學習方法:強化學習(Reinforcement Learning, RL)和模仿學習(Imitation Learning, IL),以及它們的組合應用。

強化學習
RL通過獎勵和懲罰機制來學習任務,不需要示范數據,適合于探索未知行為。它可以直接將原始感知輸入轉換為動作輸出,適用于實時應用。
-
挑戰:
-
RL通常需要精心設計的獎勵函數來引導策略的學習,這在復雜任務中可能非常具有挑戰性。
-
此外,RL策略在仿真環境中訓練后,遷移到現實世界時可能會遇到“仿真到現實”(sim-to-real)遷移的問題。
-
RL在處理高維度系統和稀疏獎勵設置時效率較低,通常需要大量的交互來學習任務。
-
-
提高學習效率的方法:
-
為了提高學習效率,研究者們采用了多種策略,如課程學習(Curriculum Learning),通過逐步增加任務的難度來加速訓練。
-
好奇心機制(Curiosity Mechanism)通過鼓勵探索未訪問的狀態來激發內在動機,從而克服稀疏獎勵問題。
-
通過約束強化學習框架(Constrained RL Framework),可以將獎勵項替換為約束,簡化獎勵調優過程。
-
-
解決sim-to-real遷移的挑戰:
-
域隨機化(Domain Randomization, DR)通過在仿真環境中引入多種參數變化來提高策略的魯棒性,使其能夠在現實世界中更好地表現。
-
系統識別(System Identification, SI)通過從現實世界數據中估計系統輸入輸出行為來提高模型保真度。
-
域適應(Domain Adaptation, DA)通過使用現實世界數據微調仿真訓練的策略,以提高其在現實環境中的表現。
-
-
應用實例:
-
RL在行走與操作中的應用包括動態行走、跳躍、攀爬樓梯和在非周期性運動(如跑酷)中的表現。
-
盡管取得了進展,但RL在處理復雜的行走與操作任務時仍面臨挑戰。
-
模仿學習
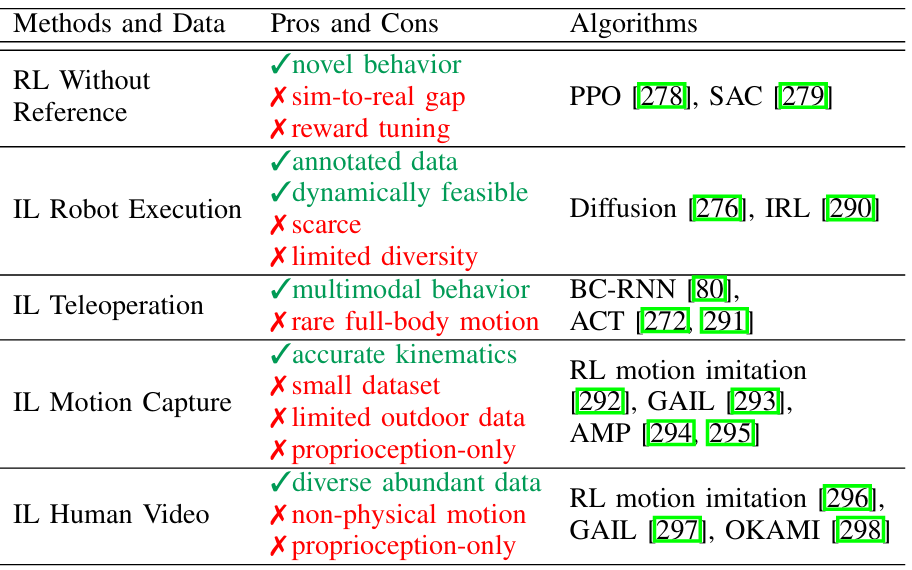
模仿學習主要關注如何利用機器人執行的數據(如策略執行和遙控操作)來訓練機器人技能。
-
數據獲取:
-
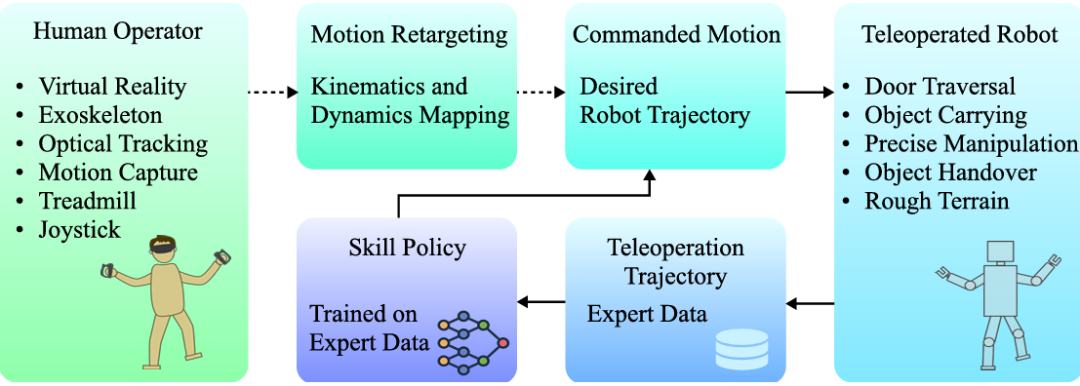
策略執行:通過執行現有的專家策略來收集數據。這種方法通常在模擬環境中進行,以減少物理設置的需求和安全性問題。
-
遙控操作:通過人類操作員遠程控制機器人來直接捕獲數據。遙控操作可以提供平滑、自然和精確的軌跡,適用于廣泛的任務。
-
-
學習方法:
-
行為克隆:將模仿學習視為監督學習問題,通過訓練一個模型來復制專家策略的行為。這是最直接的機器人技能學習方法之一。
-
逆強化學習:從數據中重建獎勵函數,并結合強化學習來訓練策略。IRL試圖理解專家行為的動機。
-
-
多模態數據處理:
-
機器人執行數據和遙控操作數據通常具有不同的特征。遙控操作數據可能包含多種可能的動作,而策略執行數據通常是單峰的。
-
為了處理這些多模態數據,研究者采用了如Action Chunking Transformer(ACT)等方法來捕捉分布變化并生成多樣化的未來動作。
-
-
結論:
-
盡管收集高質量數據需要大量努力和資源,但從機器人數據中學習技能仍然是實現專家級性能的可靠方法。
-
工業公司和研究實驗室正在越來越多地關注通過遙控操作擴展數據集,以開發更廣泛的多技能策略。
-
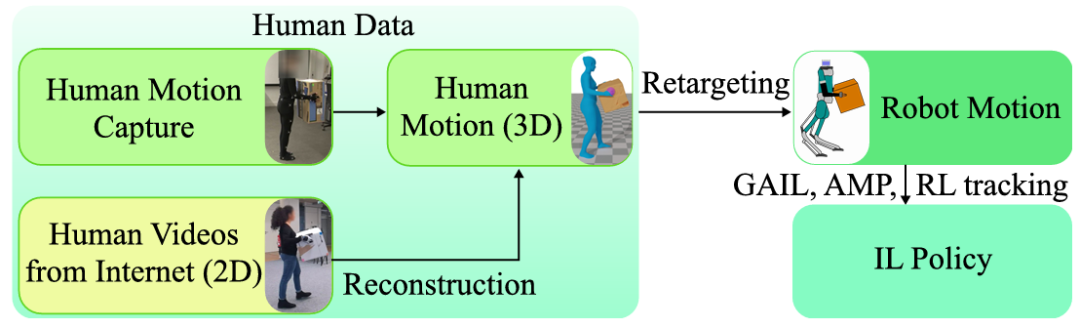
從人類數據中學習技能

-
數據獲取:
-
運動捕捉系統:直接從運動捕捉系統中記錄三維人體運動數據。這些數據通常需要在受控環境中進行,使用專業的設備和演員,因此成本較高且難以大規模擴展。
-
互聯網視頻:從互聯網上獲取的視頻數據,這些數據來源豐富且易于獲取,但質量較低,通常包含噪聲和失真。
-
動畫:通過動畫工具生成運動數據,雖然可以設計出表達性強的動作,但需要專業動畫師,且不如真實數據多樣化。
-
-
挑戰:
-
身體比例差異:人類和機器人在身體比例、關節配置和質量分布上存在差異,導致需要解決身體映射問題。
-
缺乏感官輸入:人類數據通常是僅基于本體感覺的,缺乏觸覺或力測量信息,限制了在復雜物理交互中的學習能力。
-
-
方法:
-
重定向(Retargeting):將人類運動數據映射到機器人模型上,涉及關節對應、任務空間對應等多種策略。
-
物理仿真:在物理仿真器中使用重定向后的數據進行訓練,以驗證策略的物理可行性。
-
-
應用:
-
人類樣機動作:通過生成對抗模仿學習(GAIL)和對抗運動先驗(AMP)等方法,訓練機器人模仿人類的行走、跳躍等動作。
-
復雜交互:學習在非結構化環境中與物體進行豐富的交互,例如通過視頻重建數據進行全身體操技能的學習。
-
-
結論:
-
雖然從人類數據中學習技能具有很大的潛力,但在現實世界機器人中實現這些技能仍面臨挑戰。
-
未來的研究應致力于開發更實惠和強大的機器人以及高保真度的仿真器,以加速這一領域的發展。
-
通過利用互聯網規模的數據集,機器人可以實現更廣泛的運動能力和適應性。
-
混合方法:
-
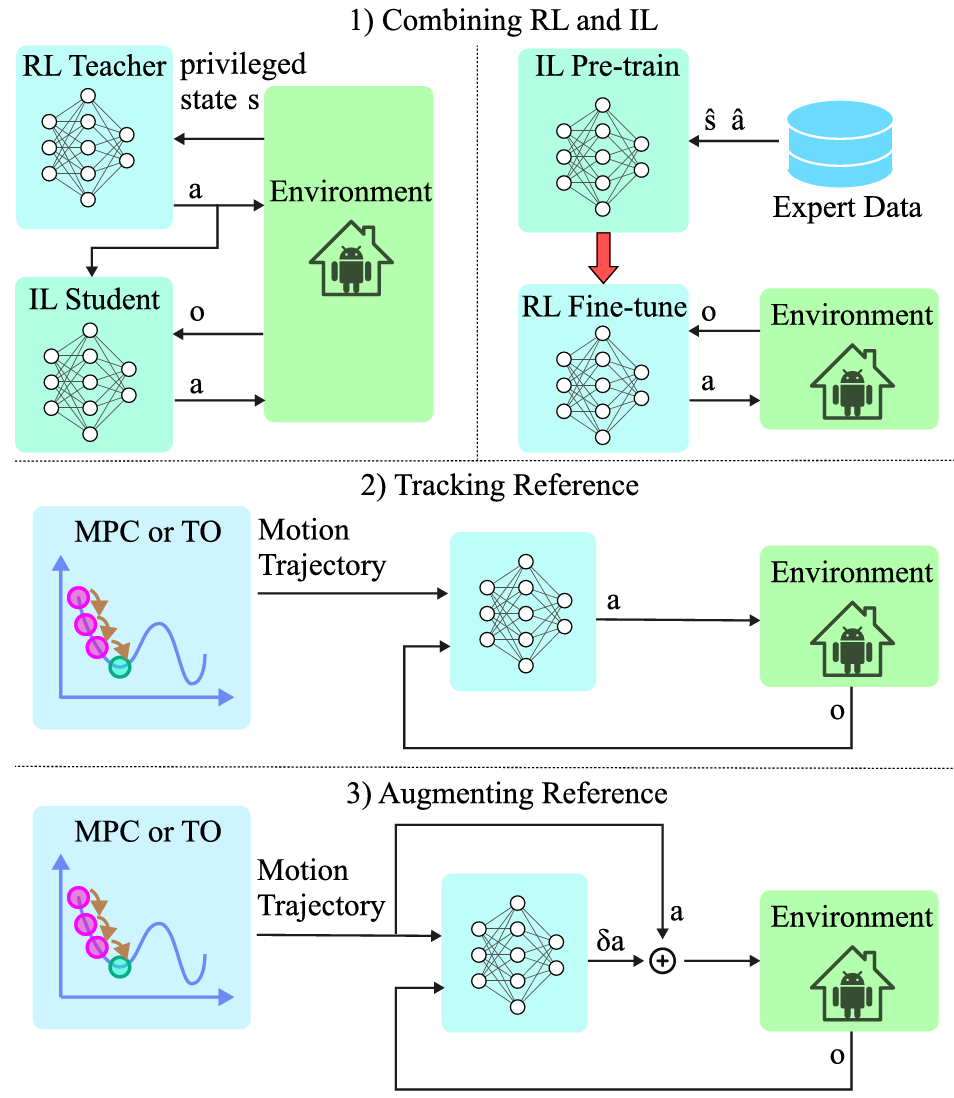
結合純強化學習和模仿學習(IL + RL):
-
兩階段教師-學生范式:首先使用純強化學習(RL)在模擬環境中訓練一個教師策略,然后使用模仿學習(IL)訓練一個學生策略,使其能夠在硬件上運行。這種方法通過模仿教師策略的行為來實現有效的遷移。
-
反向兩階段范式:首先使用IL預訓練一個模仿策略,然后使用RL進一步優化該策略,以適應不同環境或任務。
-
-
結合模型預測控制(MPC)和強化學習:
-
參考軌跡跟蹤:使用MPC生成參考軌跡,并將其作為模仿學習的獎勵信號。這種方法可以加速學習過程,但依賴于預定義的軌跡。
-
軌跡增強:通過在參考軌跡上增加殘差來增強軌跡,以實現動態運動。這種方法允許在保持參考軌跡的同時,增加策略的靈活性。
-
-
結論:
-
混合方法結合了基于模型和基于學習的優勢,能夠實現高效、靈活和高性能的機器人任務。純強化學習提供了魯棒和涌現的行為,而模仿學習則使復雜行為的訓練成為可能。
-
結合兩者的方法已經在多種機器人任務中顯示出成功,未來有望在更復雜的任務中發揮更大的作用。
-
技能的表示與組合
-
顯式表示與隱式表示:
-
技能可以被顯式地表示為完成任務的狀態-動作軌跡,或者被隱式地表示為網絡結構和其學到的權重。隱式表示方法通常更具靈活性,能夠更好地支持技能的組合和泛化。
-
-
技能組合方法:
-
專家混合(Mixture of Experts, MOE):使用分層架構,首先訓練多個獨立的專家策略,然后學習一個高層策略來選擇或混合這些專家網絡。這種方法允許在技能之間進行平滑過渡,但也可能遇到專家不平衡的問題。
-
結構化表示:通過運動表示、目標表示和狀態轉移表示來實現單一策略的多任務能力。這些方法通過結構化的表示來提高記憶效率,并允許單個策略實現多種任務。
-
-
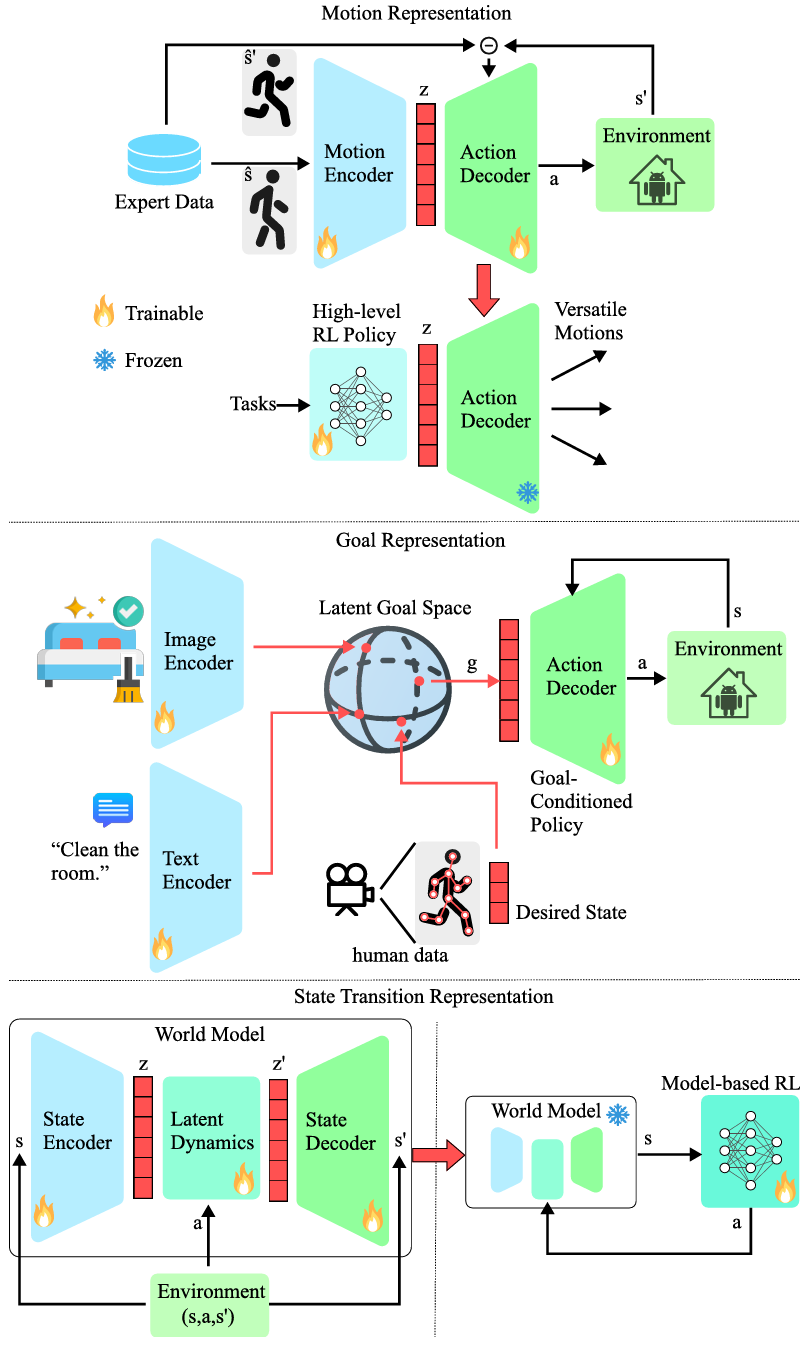
運動表示:
-
提取高維長時序運動的本質特征和時間依賴性。運動表示通常使用生成模型(如變分自編碼器和生成對抗網絡)將高維運動編碼到低維潛在空間中。這種方法可以生成多樣化的運動,并通過高階任務特定策略進行重用。
-
-
目標表示:
-
使用特征向量表示目標,可以從場景圖像、自然語言指令或觀察到的演示中編碼。目標條件策略(Goal-Conditioned Policies, GCPs)可以在單個通用策略中實現多種任務。
-
-
狀態轉移表示:
-
使用馬爾可夫決策過程(MDP)的潛在空間表示狀態轉移動力學。通過訓練一個動力學模型來預測抽象的MDP狀態之間的轉移概率,這種方法稱為世界模型(World Models)。世界模型可以通過采樣生成虛擬數據,從而提高數據效率,并有助于緩解模擬到現實遷移的問題。
-
-
結論:
-
實現機器人多樣化技能和多任務能力是機器人技能學習的主要趨勢之一。
-
盡管獲取和混合單一技能策略已被廣泛探索,但最近的方法更多地關注在單個策略中實現多種任務。
-
這些方法需要在計算機圖形學社區中進行進一步的研究和實現,以便在機器人硬件上應用。
-
基于學習的全身運動和操作

-
學習方法的挑戰:
-
全身運動和操作任務對學習方法提出了較高的要求,因為它們通常需要在復雜的物理環境中實現穩定接觸和精確的接觸力。 許多學習方法在模擬環境中展示了全身運動和操作技能,但在現實世界中的遷移仍然具有挑戰性。
-
-
強化學習(RL)的應用:
-
強化學習方法通過試錯來發現新的行為,通常需要精心設計的獎勵函數和大量的交互數據。 為了提高學習效率,研究人員采用了課程學習、好奇心機制和約束強化學習等方法。
-
在全身運動和操作任務中,RL方法通常需要明確接觸序列或通過獎勵設計來隱含接觸序列,以提高模擬到現實的遷移成功率。
-
-
模仿學習(IL)的應用:
-
通過從機器人經驗中學習,特別是通過遙控操作,IL方法已經在全身運動和操作任務中取得了顯著進展。這些方法利用人類專家的示范數據來訓練機器人,以實現類似的動作。
-
近年來,研究人員還探索了從人類數據中學習,以擴展機器人的運動能力。通過使用生成對抗模仿學習(GAIL)和對抗運動先驗(AMP)等方法,機器人可以模仿人類的高質量動作。
-
-
混合方法的應用:
-
結合模型基礎方法和學習方法(如MPC生成參考軌跡并結合RL進行模仿)可以提高學習效率和效果。混合方法利用人類知識來提供參考,同時利用學習方法的優勢來實現多樣化和適應性強的技能。
-
-
結論:
-
盡管學習方法在全身運動和操作任務中的應用仍處于發展階段,但其潛力不容忽視。學習方法可以適應無結構場景中的復雜任務,并發現模型基礎方法難以實現的涌現行為。
-
未來的研究應繼續探索如何將學習方法應用于更復雜的全身運動和操作任務,以實現更高級別的自主性和適應性。
-
基礎模型在仿人機器人中的應用
基礎模型通常是基于互聯網規模的數據進行預訓練的大型模型,已經在自然語言處理和計算機視覺等領域取得了顯著進展。
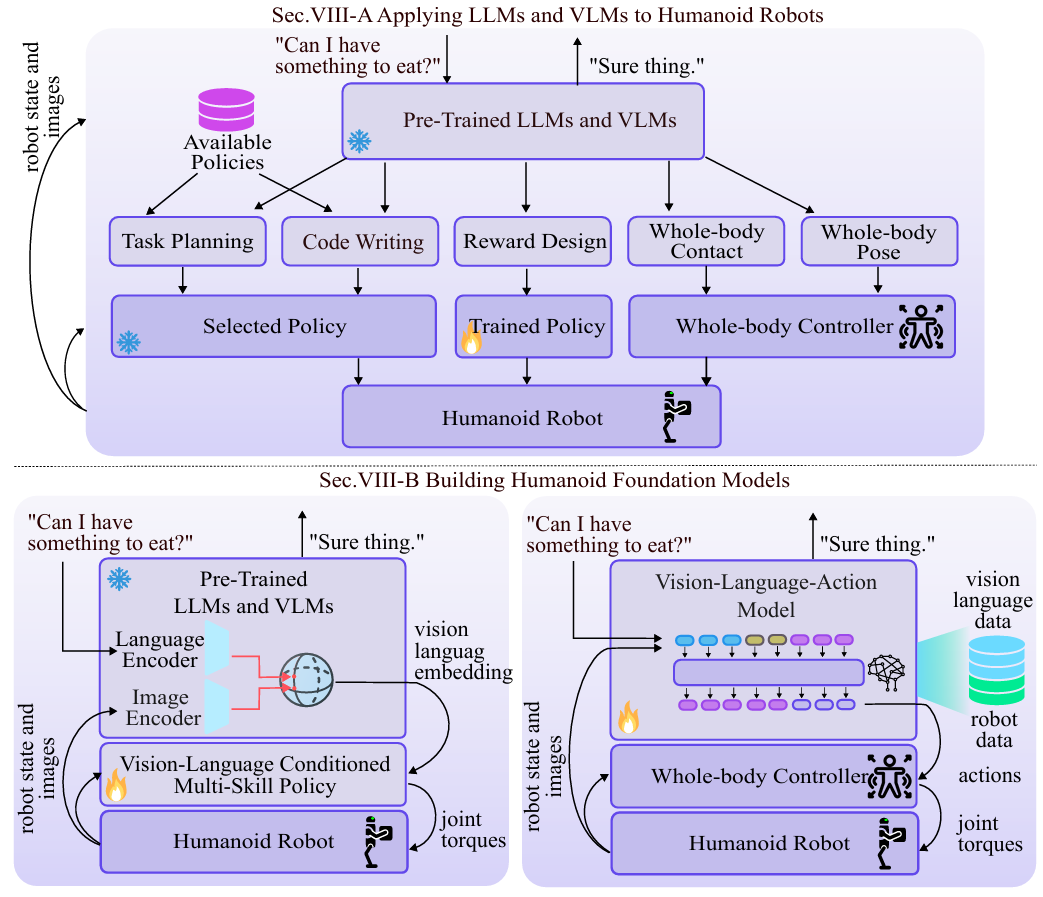
應用LLMs/VLMs到仿人機器人
-
預訓練模型的應用:
-
許多研究展示了如何在各種機器人平臺上應用預訓練的LLMs和VLMs,包括靈巧手、機械臂、移動機械臂、四足機器人和雙足機器人。
-
這些預訓練模型通常用于生成任務相關的中間表示,而不是直接生成機器人動作。這種方法的優勢在于,預訓練模型提供了強大的語義理解和上下文感知能力。
-
-
任務規劃機制:
-
由于預訓練模型缺乏對機器人任務的具身知識,研究者們開發了任務規劃機制來生成合理的動作計劃。
-
例如,SayCan通過價值函數對可用動作進行排序,以選擇在移動機械臂上可行的動作。VLM-PC則限制GPT-4輸出僅限于四足機器人導航的技能。
-
-
中間表示的應用:
-
研究者們提出了生成代碼和獎勵函數作為中間表示的方法,以增強雙足和四足機器人的靈活性。
-
這些方法允許在生成動作時進行調整,而不僅僅是選擇現有的低層次技能。
-
-
全身姿態和接觸生成:
-
一些研究探索了生成全身姿態和全身接觸的方法,使用戶可以通過自然語言、圖像甚至手勢直觀地指導機器人的行為。
-
這些技術允許更高級別的任務規劃和控制,特別是在需要復雜身體協調的任務中。
-
-
局限性:
-
盡管預訓練模型在語義理解和上下文感知方面表現出色,但它們在生成具體機器人動作時仍面臨挑戰。
-
未來的研究需要進一步探索如何有效地將預訓練模型的能力與機器人任務的具身知識相結合。
-
構建仿人機器人基礎模型
-
多模態輸入處理:
-
RFMs通常從互聯網規模的機器人數據中進行訓練,能夠處理多模態輸入,如自中心圖像和自然語言描述。
-
這些模型可以直接與物理世界交互,通過機器人動作來實現任務目標。
-
-
訓練挑戰:
-
構建RFMs的一個主要挑戰是收集足夠的高質量數據。成功的實現通常依賴于機器人擁有穩定的動態特性和大量的高質量數據。
-
仿人機器人在運動中的不穩定性以及靈巧手的高維動作空間使得數據收集和訓練變得更加困難。
-
-
分層框架:
-
為了實現高層次的推理和規劃,RFMs通常采用分層框架,結合預訓練的LLMs或VLMs與低層次的控制器策略。
-
這種設置允許跨模態能力,如語言到動作的轉換,并且可以在機器人任務中實現更廣泛的技能。
-
-
現有工作:
-
現有的RFMs工作主要集中在穩定動態特性的機器人上,如無人機和四足機器人。
-
對于仿人機器人,RFMs的構建仍然是一個具有挑戰性的任務,因為需要處理更復雜的動力學和更高的動作空間維度。
-
-
未來方向:
-
未來的研究將集中在開發更有效的算法和模型架構,以應對RFMs在仿人機器人中的應用挑戰。
-
這包括優化輸入和輸出表示,以適應復雜的任務需求,并確保模型能夠在實時環境中有效地運行。
-
未來挑戰與機會
數值優化的挑戰
-
非凸性和數值魯棒性:
-
機器人規劃和控制技術通常被形式化為數值優化問題,這些技術依賴于離散數學和優化理論的進步。
-
盡管取得了進展,但在處理非凸問題和確保數值魯棒性方面仍存在挑戰,尤其是在大規模系統中。
-
-
接觸顯式和隱式優化的局限性:
-
接觸顯式優化方法因其快速收斂和簡化公式而受到青睞,但面臨維度災難問題,難以生成復雜的運動。
-
接觸隱式優化方法通過引入互補條件來避免對接觸模式序列的嚴格依賴,但其非光滑性帶來了嚴重的計算挑戰。
-
-
全局最優解的保證:
-
現有方法通常只能提供局部最優解的保證,當問題的結構要求偏離局部候選接觸條件時,可能找不到可行解。
-
需要結合搜索技術和傳統軌跡優化方法來尋找全局最優解。
-
-
計算效率和并行化:
-
盡管并行化技術在提高計算效率方面取得了進展,但在處理大規模系統時,優化算法的計算復雜性仍然是一個挑戰。
-
需要進一步研究以提高優化算法的效率和可擴展性。
-
-
魯棒性和適應性:
-
在處理復雜系統動態和不確定性時,數值優化方法的魯棒性和適應性仍需改進。
-
需要開發新的方法來處理系統中的隨機性和不確定性。
-
缺乏全身運動和操作的基準測試
-
技能發展的初期階段:
-
仿人機器人的全身運動和操作技能相對于其他任務(如行走和桌面操作)仍處于初級階段。
-
這導致缺乏大規模和系統的基準測試來評估和比較不同算法的性能。
-
-
任務和評估指標的設計:
-
設計良好的任務和評估指標對于加速研究進展至關重要。
-
標準化的全身運動和操作任務可以幫助研究人員驗證算法的有效性,并促進技術的發展。
-
-
硬件平臺的標準化:
-
開發可負擔且功能強大的仿人機器人硬件平臺,以促進硬件評估和研究進展。
-
開源硬件和軟件的開發也在加速硬件發展,使得更多的研究團隊能夠進行實驗和驗證。
-
-
模擬和現實世界的對比:
-
模擬環境在算法開發和初步驗證中具有重要作用,但現實世界的應用需要更高的魯棒性和適應性。
-
開發能夠在多種環境和任務中表現良好的算法是未來的一個重要方向。
-
-
數據集和開源資源:
-
收集和共享高質量的全身運動和操作數據集有助于推動研究進展。
-
開源硬件和軟件平臺可以促進數據集的開發和共享,從而加速技術的普及和應用。
-
數據稀缺性挑戰
-
高質量數據的獲取:
-
機器人技能學習依賴于大量高質量的數據,特別是對于全身運動和操作任務。
-
數據稀缺性是機器人技能學習中的一個主要瓶頸,限制了算法的泛化能力和適應性。
-
-
數據規模與質量的權衡:
-
數據擴展是提高機器人技能學習效果的關鍵,但需要在數據規模和質量之間進行權衡。
-
過度追求數據規模可能導致數據質量下降,影響算法的學習效果。
-
-
人類數據的利用:
-
人類數據提供了豐富的運動和操作范例,但將其應用于機器人時存在形態差異和周圍環境的差異。
-
未來的研究需要開發更好的方法來縮小人類數據與機器人數據之間的差距。
-
-
多模態數據的整合:
-
為了實現更廣泛和適應性的機器人技能,未來的研究應關注整合多種傳感器數據(如力覺和視覺數據)。
-
多模態數據可以幫助機器人更好地理解和適應復雜的環境和任務。
-
-
數據采集方法的創新:
-
研究人員正在探索從視頻和動畫中生成數據的方法,以擴大數據集的多樣性和規模。
-
這些方法需要解決數據質量和真實性的問題,以確保其在機器人技能學習中的有效性。
-
基礎模型的機遇與挑戰
-
機遇
-
知識遷移:
-
基礎模型通常是基于互聯網規模的數據進行預訓練的,這些數據包含了大量的人類行為和知識。
-
仿人機器人可以利用這些模型中嵌入的人類知識,從而更快地學習和適應新任務。
-
-
自然交互:
-
基礎模型在自然語言處理和視覺理解方面的強大能力,使得仿人機器人能夠更好地理解和響應人類指令。
-
這為開發更自然和直觀的人機交互方式提供了可能。
-
-
泛化能力:
-
通過在大規模數據上進行訓練,基礎模型具有強大的泛化能力,能夠處理多種任務和環境。
-
這有助于仿人機器人在復雜和多變的環境中表現出色。
-
-
挑戰
-
控制和安全:
-
仿人機器人由于其雙足平臺的固有不穩定性,在控制和安全性方面面臨額外挑戰。
-
基礎模型需要在不犧牲安全性的前提下,提供靈活和高效的決策支持。
-
-
推理成本:
-
運行大型基礎模型需要強大的計算資源,這對仿人機器人的實時性能提出了挑戰。
-
需要開發高效的推理方法和硬件加速技術,以支持基礎模型在機器人中的應用。
-
-
訓練成本:
-
基礎模型的訓練成本高昂,消耗大量能源并產生二氧化碳排放。
-
未來的研究需要探索更高效的訓練方法和資源優化策略。
-
-
模型擴展性:
-
隨著基礎模型的規模不斷擴大,如何有效地擴展模型以適應機器人應用的需求是一個重要挑戰。
-
需要開發新的模型架構和算法,以支持更大規模和更高復雜度的機器人任務。
-
總結
本文綜述了類人運動與操作技能的當前進展和未來趨勢。基于模型的規劃與控制方法、強化學習、模仿學習和基礎模型在該領域中發揮了重要作用。
盡管取得了顯著進展,但仍存在許多挑戰,如數值優化的復雜性、缺乏基準測試和數據稀缺問題。
未來的研究方向包括開發更高效的優化算法、建立大規模基準測試、以及利用多模態感知和基礎模型與現有的規劃與控制系統無縫集成。

)

基于JAVA的網絡通訊系統設計與實現-畢業設計)






:Jenkins+Git+Allure實戰(自動化測試))




理解PG的編譯流程(make、Makefile、Makefile.global.in))
)



