文章目錄
- 前言
- 一、寬窄字節簡介
- 二、操作系統及VS編譯器對寬窄字節的編碼支持
- 1. 操作系統
- 2. 編譯器
- 三、寬窄字符串的優缺點
- 四、寬窄字節數據類型
- 總結
前言
Windows 程序設計3:寬窄字節的區別及重要性。
一、寬窄字節簡介
在C++中,常用的字符串指針就是char* ,字符串變量為string,內部也是對char* 的封裝,但是并不了解這些跟寬窄字節有什么關系。
實際上,最早的系統都是窄字節的,也就是我們最常用的char,因為都是英文的一共就26個字母,再加上其他的一些符號標點,char就足夠用了。無符號的char最多可以表示255個字符,已經足夠。
后來隨著操作系統的國際化,系統出現了很多語言版本。原來的char表示一個英文字符的方式已經無法表達一個中文漢字了。漢字有好幾萬個,單純的char取值范圍已經不夠了。此時有人想到,一個char表示不下那就用兩個char來表示一個漢字。因此,數字、字母等仍用窄字節,也就是一個char來表示;一個漢字或全角字符等使用兩個char來表示。
雖然這樣可以基本解決問題,即在中文系統上能正常顯示中文、在其他語言系統上也能夠正常顯示,但是如果想把一個在中文系統上寫的軟件拿到日文或韓文等其他語言的系統上就會出現亂碼,漢字是無法正常顯示的。同理,其他語言的軟件拿到中文系統上也會出現亂碼。
那么為了解決這樣國際化的問題,微軟在Windows系統中引入了寬字節的功能,即Unicode。Unicode中規定任意一個字符都占用兩個字節,即兩個char。無論是字符還是字母、數字、漢字都占用兩個字節。用兩個char難免造成不方便,因此微軟定義了一個新的類型:wchar_t,其原型實際上就是unsigner short,占用兩個字節。
二、操作系統及VS編譯器對寬窄字節的編碼支持
1. 操作系統
Windows提供了兩種類型的API函數,如MessageBox函數,實際上MessageBox函數只是一個宏,其對應了兩個版本的函數:MessageBoxA和MessageBoxW,在VS編譯器中使用時系統會根據是否定義了_UNICODE宏來進行判斷當前工程使用寬字節的Unicode編碼還是窄字節編碼,以此來決定使用哪個版本的函數。如果沒有定義,則使用窄字節的MessageBoxA;如果定義了就使用寬字節的MessageBoxW。
右鍵MessageBox,點擊轉到定義
可以看到該宏的具體定義

可以利用Depends工具查看動態鏈接庫中的函數,見https://blog.csdn.net/qq_59940419/article/details/144721964?spm=1001.2014.3001.5502,MessageBox在User32.dll中,打開如下路徑:C:\Windows\System32,找到User32.dll將其拖入到Depends工具中,可以找到兩個函數。
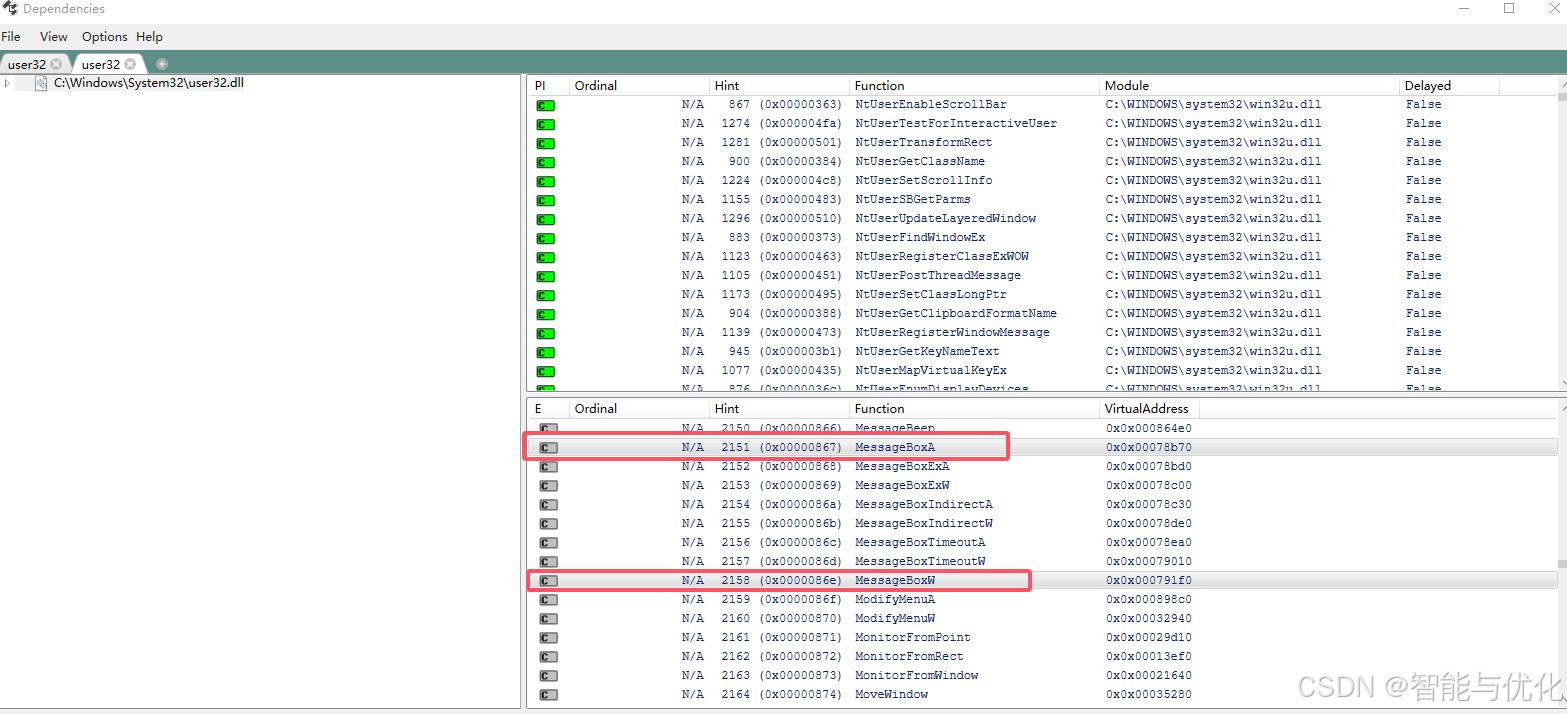
其他的很多函數也都是這樣進行區分寬窄字節的。大家可以自己看一看。
說明:Windows 2000以后的系統都是使用Unicode從頭進行開發的,如果調用任何一個Windows API函數并傳遞一個ANSI即窄字節的字符串,那么系統會首先將字符串轉換為Unicode,然后將Unicode即寬字節的字符串傳遞給操作系統。如果希望函數返回ANSI字符串,系統就會先將Unicode字符串轉換為ANSI字符串,然后將結果返回給應用程序。進行這些字符串的轉換需要占用系統的時間和內存,通過從頭開始使用Unicode來開發應用程序,可以使得應用程序運行得更加高效。因此開發時建議使用寬字節。
2. 編譯器
VC++6.0默認為窄字節編碼。vs2005, vs2008, vs2010, vs2012, vs2013, vs2015, vs2017等等都是默認Unicode編碼。也可以在工程中設置編碼方式。
右鍵項目,點擊屬性
可以在字符集處調整編碼方式

注意:從vs2013開始,如果要將工程默認的Unicode編碼轉為窄字節編碼,需要安裝多字節補丁。
三、寬窄字符串的優缺點
即便Unicode寬字節相對來說更好,但是其也有缺點。
一般來說,設計界面和跟字符串操作相關的,推薦使用寬字節。其他地方還是可以使用窄字節的,因為寬字節的占用空間是窄字節的二倍。這樣的話在本機還好,如果涉及字符串的網絡傳輸,那么傳輸量會偏大。所以也不是說什么時候都要使用Unicode寬字節。
在一個工程中,有的地方使用寬字節,有的地方使用窄字節(如一些代碼邏輯和網絡傳輸使用窄字節,界面設計使用寬字節),這就需要進行寬窄字節的轉換。微軟提供相應的API函數,直接使用即可。
四、寬窄字節數據類型
大家熟知的char, char* 都是窄字節的。常見的一些數據類型如下:
窄字節:
char, char* , const char*
CHAR, (PCHAR, PSTR, LPSTR), LPCSTR
Unicode寬字節:
wchar_t, wchar_t* , const wchar_t*
WCHAR, (PWCHAR, PWSTR, LPWSTR), LPCWSTR
_T通用類型:
TCHAR, (TCHAR* , PTCHAR, PTSTR, LPTSTR), LPCTSTR
其中,P代表指針的思想,STR表示字符串的意思,L是長指針的意思(在Win32平臺下可以忽略),C表示const常量的意思,W表示wide寬字節的意思,T可以理解為通用類型的意思。
可以根據工程中是否定義_UNICODE宏,來判斷當前工程的編碼是寬字節還是窄字節,然后再定義成不同的類型。比如TCHAR類型,如果工程中定義了_UNICODE宏,那么就表明工程是寬字節編碼的,其最終就被定義為wchar_t類型,如果工程中沒有定義_UNICODE宏,就表明工程是窄字節編碼的,其最終被定義為char類型。通用類型的優勢在于,在修改了工程的編碼格式之后不需要修改代碼,因此更加建議使用通用類型。
總結
Windows 程序設計3:寬窄字節的區別及重要性。
)
















-AutoSAR CP分層架構(2))
)
