本篇文章是對我們從高德拿到的公交/地鐵的json文件的精細化處理的一個深入解析,通過對這些原始數據進行詳細的清洗、轉換和分析,我們通過對數據的質量和可用性的提升,來為后續的數據精細化處理和研究做基礎數據的支撐,從而為后續的交通規劃、調度優化以及用戶服務提升提供了堅實的數據支持。
上篇的處理邏輯指路:利用高德API獲取整個城市的公交路線并可視化(六)_高德地圖公交線路的geojson文件-CSDN博客
第一部分:公交/地鐵雙線路徑處理
相對于之前的處理python腳本,增加字段,dir(上下行,環線無上下行),direc(線路編碼),這里的dir字段,原始數據沒有,是自定義的規則;
dir?值的確定規則
- 如果該線路只有一個方向,dir?為?'0'
- 如果有兩個方向,direc 值小的為?'0',大的為?'1'
文件路徑修改成自己的路徑,然后運行下面的腳本;
# 指定目錄路徑directory = 'D://data//高德json'csv_file_path = 'D://data//高德json//bus_route.csv'shp_file_path = 'D://data//高德json//bus_route.shp'完整代碼#運行環境 Python 3.11
import os
import json
import csv
import math
import geopandas as gpd
from shapely.geometry import LineString, Point
from collections import defaultdict# 高德GCJ02(火星坐標系)轉WGS84
x_pi = 3.14159265358979324 * 3000.0 / 180.0
pi = 3.1415926535897932384626 # π
a = 6378245.0 # 長半軸
ee = 0.00669342162296594323 # 扁率def gcj02towgs84(lng, lat):"""GCJ02(火星坐標系)轉WGS84:param lng: 火星坐標系的經度:param lat: 火星坐標系緯度:return: WGS84 經度, 緯度"""if out_of_china(lng, lat):return lng, latdlat = transformlat(lng - 105.0, lat - 35.0)dlng = transformlng(lng - 105.0, lat - 35.0)radlat = lat / 180.0 * pimagic = math.sin(radlat)magic = 1 - ee * magic * magicsqrtmagic = math.sqrt(magic)dlat = (dlat * 180.0) / ((a * (1 - ee)) / (magic * sqrtmagic) * pi)dlng = (dlng * 180.0) / (a / sqrtmagic * math.cos(radlat) * pi)mglat = lat + dlatmglng = lng + dlngreturn [lng * 2 - mglng, lat * 2 - mglat]def transformlat(lng, lat):"""計算緯度偏移量:param lng: 經度:param lat: 緯度:return: 緯度偏移量"""ret = -100.0 + 2.0 * lng + 3.0 * lat + 0.2 * lat * lat + 0.1 * lng * lat + 0.2 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 * math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lat * pi) + 40.0 * math.sin(lat / 3.0 * pi)) * 2.0 / 3.0ret += (160.0 * math.sin(lat / 12.0 * pi) + 320 * math.sin(lat * pi / 30.0)) * 2.0 / 3.0return retdef transformlng(lng, lat):"""計算經度偏移量:param lng: 經度:param lat: 緯度:return: 經度偏移量"""ret = 300.0 + lng + 2.0 * lat + 0.1 * lng * lng + 0.1 * lng * lat + 0.1 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 * math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lng * pi) + 40.0 * math.sin(lng / 3.0 * pi)) * 2.0 / 3.0ret += (150.0 * math.sin(lng / 12.0 * pi) + 300.0 * math.sin(lng / 30.0 * pi)) * 2.0 / 3.0return retdef out_of_china(lng, lat):"""判斷是否在國內,不在國內不做偏移:param lng: 經度:param lat: 緯度:return: 是否在國內"""if lng < 72.004 or lng > 137.8347:return Trueif lat < 0.8293 or lat > 55.8271:return Truereturn Falsedef process_json_files(directory, csv_file_path, shp_file_path):"""處理JSON文件并生成CSV和SHP文件"""# 首先收集所有線路的 direc 值route_direcs = defaultdict(list)# 第一次遍歷 - 收集所有線路的 direc 值print("第一次遍歷 - 收集線路方向信息...")for json_file in os.listdir(directory):if not json_file.endswith('.json'):continuejson_file_path = os.path.join(directory, json_file)try:with open(json_file_path, 'r', encoding='utf-8') as file:data = json.load(file)if isinstance(data, list):for item in data:name = item.get('name', '').split('(')[0] if item.get('name') else ''direc = str(item.get('direc', ''))if name and direc:route_direcs[name].append(direc)else:name = data.get('name', '').split('(')[0] if data.get('name') else ''direc = str(data.get('direc', ''))if name and direc:route_direcs[name].append(direc)except Exception as e:print(f"Error in first pass for {json_file}: {str(e)}")# 對每個線路的 direc 值進行排序for name in route_direcs:route_direcs[name] = sorted(route_direcs[name])# 初始化數據列表all_lines = []all_attributes = []# 第二次遍歷 - 處理數據并寫入文件print("第二次遍歷 - 處理數據并生成文件...")# 如果CSV文件已存在,則刪除if os.path.exists(csv_file_path):os.remove(csv_file_path)for json_file in os.listdir(directory):if not json_file.endswith('.json'):continuejson_file_path = os.path.join(directory, json_file)print(f"處理文件: {json_file}")try:with open(json_file_path, 'r', encoding='utf-8') as file:data = json.load(file)if isinstance(data, list):for item in data:if "name" in item and "path" in item:# 確定 dir 值name = item['name'].split('(')[0]direc = str(item.get('direc', ''))dir_value = '0' if direc == route_direcs[name][0] else '1' if len(route_direcs[name]) > 1 else '0'# 寫入CSVheader = ["type", "name", "lng", "lat", "dir", "direc"]with open(csv_file_path, 'a', newline='', encoding='utf-8-sig') as file:writer = csv.writer(file)if file.tell() == 0:writer.writerow(header)for point in item["path"]:wgs84_lng, wgs84_lat = gcj02towgs84(point["lng"], point["lat"])row = [item["type"], item["name"], wgs84_lng, wgs84_lat, dir_value, direc]writer.writerow(row)# 處理 Shapefile 數據wgs84_points = [Point(*gcj02towgs84(point["lng"], point["lat"])) for point in item["path"]]line = LineString(wgs84_points)all_lines.append(line)all_attributes.append({"type": item["type"],"name": item["name"],"dir": dir_value,"direc": direc})else:# 確定 dir 值name = data['name'].split('(')[0]direc = str(data.get('direc', ''))dir_value = '0' if direc == route_direcs[name][0] else '1' if len(route_direcs[name]) > 1 else '0'# 寫入CSVheader = ["type", "name", "lng", "lat", "dir", "direc"]with open(csv_file_path, 'a', newline='', encoding='utf-8-sig') as file:writer = csv.writer(file)if file.tell() == 0:writer.writerow(header)for point in data["path"]:wgs84_lng, wgs84_lat = gcj02towgs84(point["lng"], point["lat"])row = [data["type"], data["name"], wgs84_lng, wgs84_lat, dir_value, direc]writer.writerow(row)# 處理 Shapefile 數據wgs84_points = [Point(*gcj02towgs84(point["lng"], point["lat"])) for point in data["path"]]line = LineString(wgs84_points)all_lines.append(line)all_attributes.append({"type": data["type"],"name": data["name"],"dir": dir_value,"direc": direc})except Exception as e:print(f"Error processing {json_file}: {str(e)}")# 創建GeoDataFrame并保存print("創建和保存Shapefile...")gdf = gpd.GeoDataFrame(all_attributes, geometry=all_lines, crs="EPSG:4326")gdf.to_file(shp_file_path, driver='ESRI Shapefile', encoding='utf-8')def main():"""主函數"""# 指定目錄路徑directory = 'D://data//高德json'csv_file_path = 'D://data//高德json//bus_route.csv'shp_file_path = 'D://data//高德json//bus_route.shp'# 確保輸出目錄存在os.makedirs(os.path.dirname(csv_file_path), exist_ok=True)# 處理文件process_json_files(directory, csv_file_path, shp_file_path)print("CSV文件和SHP文件已成功創建")if __name__ == "__main__":main()腳本執行結束,我們會得到一個文件名為bus_route的csv文件,標簽包含線路direc、類型、站點名稱、xy坐標(wgs84)這些信息;
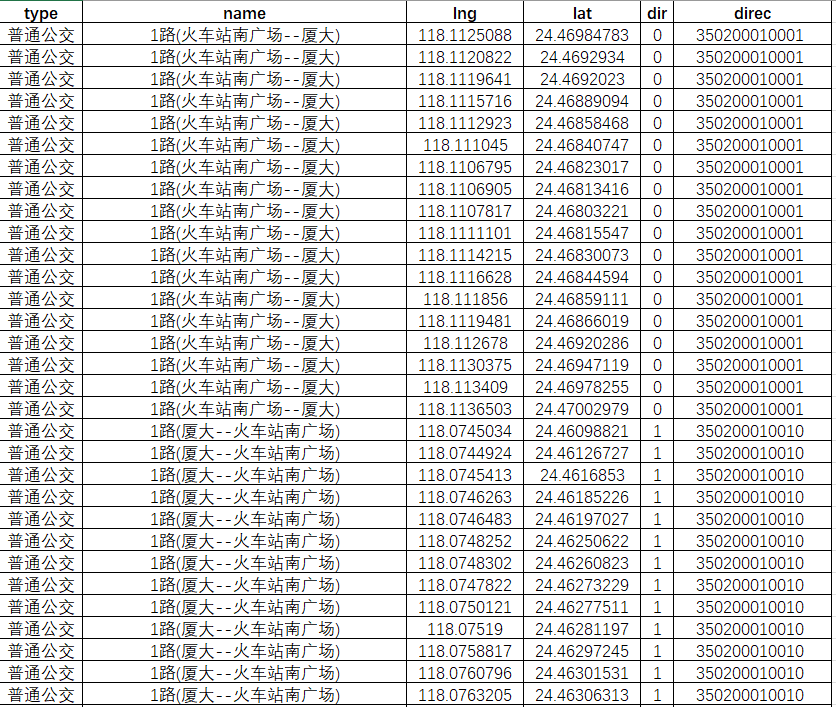
和一個文件名為bus_route的shp文件,包含了該線路兩個方向的線路路徑信息;
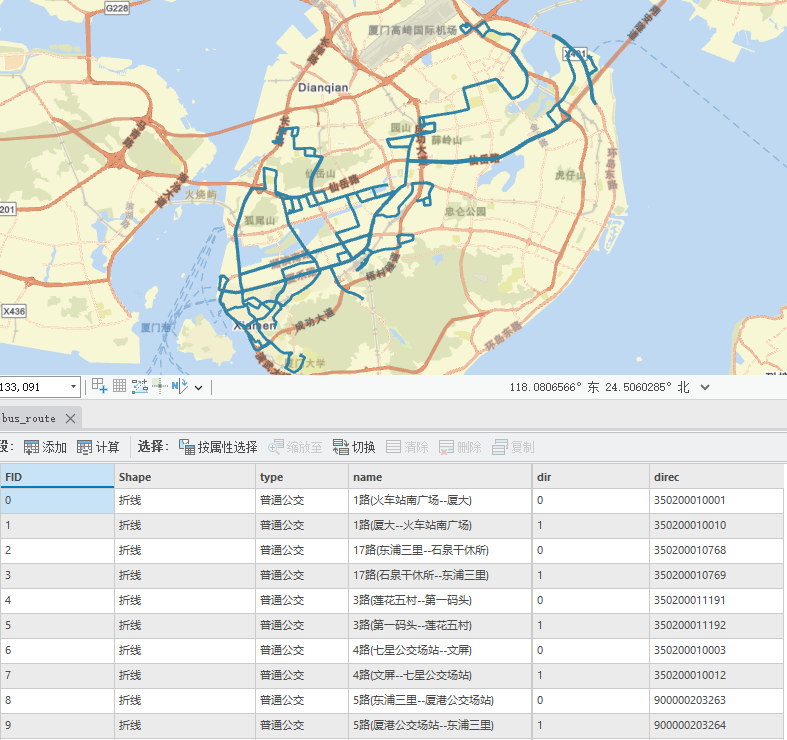
第二部分:公交/地鐵雙線站點處理
相對于之前的處理python腳本,增加字段,dir(上下行,環線無上下行),direc(線路編碼)loop(是否為環線),這里的dir字段,原始數據沒有,是自定義的規則(規則參考上面說明);
文件路徑修改成自己的路徑,然后運行下面的腳本;
folder_path = r'D://data//高德json' # 你的JSON文件夾路徑output_csv = r'D://data//高德json//output.csv' # 輸出的CSV文件路徑完整代碼#運行環境 Python 3.11
import json
import csv
import os
import math# 坐標轉換相關常量
x_pi = 3.14159265358979324 * 3000.0 / 180.0
pi = 3.1415926535897932384626 # π
a = 6378245.0 # 長半軸
ee = 0.00669342162296594323 # 扁率def gcj02towgs84(lng, lat):"""GCJ02(火星坐標系)轉WGS84:param lng: 火星坐標系的經度:param lat: 火星坐標系緯度:return: WGS84 經度, 緯度"""if out_of_china(lng, lat):return lng, latdlat = transformlat(lng - 105.0, lat - 35.0)dlng = transformlng(lng - 105.0, lat - 35.0)radlat = lat / 180.0 * pimagic = math.sin(radlat)magic = 1 - ee * magic * magicsqrtmagic = math.sqrt(magic)dlat = (dlat * 180.0) / ((a * (1 - ee)) / (magic * sqrtmagic) * pi)dlng = (dlng * 180.0) / (a / sqrtmagic * math.cos(radlat) * pi)mglat = lat + dlatmglng = lng + dlngreturn [lng * 2 - mglng, lat * 2 - mglat]def transformlat(lng, lat):"""計算緯度偏移量:param lng: 經度:param lat: 緯度:return: 緯度偏移量"""ret = -100.0 + 2.0 * lng + 3.0 * lat + 0.2 * lat * lat + 0.1 * lng * lat + 0.2 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 * math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lat * pi) + 40.0 * math.sin(lat / 3.0 * pi)) * 2.0 / 3.0ret += (160.0 * math.sin(lat / 12.0 * pi) + 320 * math.sin(lat * pi / 30.0)) * 2.0 / 3.0return retdef transformlng(lng, lat):"""計算經度偏移量:param lng: 經度:param lat: 緯度:return: 經度偏移量"""ret = 300.0 + lng + 2.0 * lat + 0.1 * lng * lng + 0.1 * lng * lat + 0.1 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 * math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lng * pi) + 40.0 * math.sin(lng / 3.0 * pi)) * 2.0 / 3.0ret += (150.0 * math.sin(lng / 12.0 * pi) + 300.0 * math.sin(lng / 30.0 * pi)) * 2.0 / 3.0return retdef out_of_china(lng, lat):"""判斷是否在國內,不在國內不做偏移:param lng: 經度:param lat: 緯度:return: 是否在國內"""if lng < 72.004 or lng > 137.8347:return Trueif lat < 0.8293 or lat > 55.8271:return Truereturn Falsedef process_json_files(folder_path, output_csv):"""Process all JSON files in a folder, extract route names and stop information, and save to CSV:param folder_path: Path to folder containing JSON files:param output_csv: Path to output CSV file"""# 創建一個字典來存儲每個線路名稱對應的 direc 值route_direcs = {}# 第一次遍歷 - 收集所有線路的 direc 值for filename in os.listdir(folder_path):if not filename.endswith('.json'):continuefile_path = os.path.join(folder_path, filename)try:with open(file_path, 'r', encoding='utf-8') as file:json_data = json.load(file)routes = json_data if isinstance(json_data, list) else [json_data]for data in routes:name = data.get('name', '').split('(')[0] if data.get('name') else '' # 獲取括號前的名稱direc = str(data.get('direc', ''))if name:if name not in route_direcs:route_direcs[name] = []route_direcs[name].append(direc)except Exception as e:print(f"Error in first pass for {filename}: {str(e)}")# 處理 route_direcs 確保每個線路的 direc 值被排序for name in route_direcs:route_direcs[name] = sorted(route_direcs[name])try:with open(output_csv, 'w', newline='', encoding='utf-8-sig') as csvfile:fieldnames = ['line', 'ID', 'name', 'lng', 'lat', 'seq', 'loop', 'direc', 'dir']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()# 第二次遍歷 - 寫入數據for filename in os.listdir(folder_path):if not filename.endswith('.json'):continuefile_path = os.path.join(folder_path, filename)try:with open(file_path, 'r', encoding='utf-8') as file:json_data = json.load(file)routes = json_data if isinstance(json_data, list) else [json_data]for data in routes:full_name = data.get('name', '')name = full_name.split('(')[0] if full_name else '' # 獲取括號前的名稱via_stops = data.get('via_stops', [])loop = data.get('loop', '')direc = str(data.get('direc', ''))if not (name and via_stops):print(f"Warning: Missing required data in {filename}")continue# 確定 dir 值dir_value = '0' if direc == route_direcs[name][0] else '1' if len(route_direcs[name]) > 1 else '0'for stop in via_stops:location = stop.get('location', {})gcj_lng = location.get('lng')gcj_lat = location.get('lat')if not (isinstance(gcj_lng, (int, float)) and isinstance(gcj_lat, (int, float))):print(f"Warning: Invalid coordinates in {filename} for stop {stop.get('name', '')}")continuewgs84_lng, wgs84_lat = gcj02towgs84(gcj_lng, gcj_lat)row = {'line': full_name, # 使用完整名稱'ID': f"'{str(stop.get('id', ''))}",'name': stop.get('name', ''),'lng': f"{wgs84_lng:.6f}",'lat': f"{wgs84_lat:.6f}",'seq': stop.get('sequence', ''),'loop': loop,'direc': f"'{direc}",'dir': dir_value}writer.writerow(row)print(f"Successfully processed: {filename}")except (json.JSONDecodeError, UnicodeDecodeError) as e:print(f"Error processing {filename}: {str(e)}")except Exception as e:print(f"Unexpected error processing {filename}: {str(e)}")except Exception as e:print(f"Error writing to CSV file: {str(e)}")def main():"""主函數,指定文件夾路徑和輸出 CSV 文件路徑,并調用處理函數"""folder_path = r'D://data//高德json' # 你的JSON文件夾路徑output_csv = r'D://data//高德json//output.csv' # 輸出的CSV文件路徑process_json_files(folder_path, output_csv)print(f"數據已成功保存到 CSV 文件: {output_csv}")if __name__ == "__main__":main()腳本執行結束,我們會得到一個文件名為output的csv文件,標簽包含line(線路名稱)、id、name (站點)、xy坐標(wgs84)、seq(站點順序編號),loop(是否為環線)這些信息,我們可以把這個數據在arcgis進行【顯示xy數據】的操作;
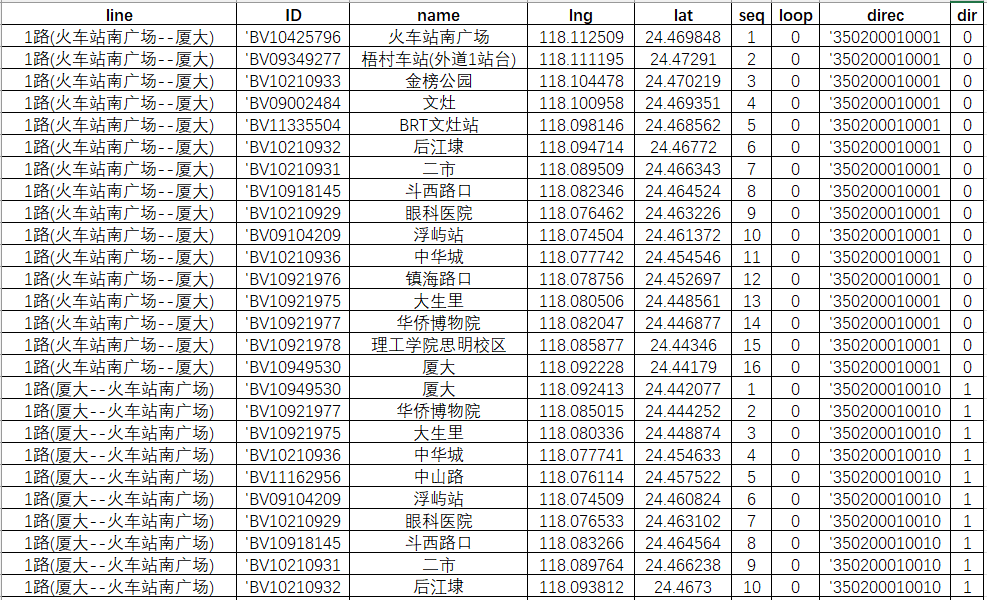
第三部分:公交/地鐵雙線線段化處理(新增)
線路本身是一條完整的線路,我們根據站點位置,對線路進行截斷,并提取這兩點之間的線段,這樣,站點之間就是一個個線段,從而可以滿足后續對線段客流量進行賦值可視化等需求;
這里需要把前面xy坐標轉點的圖層另存為新的bus_station圖層,文件路徑修改成自己的路徑,然后運行下面的腳本;
# 讀取線路和站點 shapefile 文件
lines_path = r'D:\data\高德json\bus_route.shp'
stations_path = r'D:\data\高德json\bus_station.shp'完整代碼#運行環境 Python 3.11
import geopandas as gpd
from shapely.geometry import LineString, Point
from shapely.ops import nearest_points
import pandas as pd
import re# 讀取線路和站點 shapefile 文件
lines_path = r'D:\data\高德json\bus_route.shp'
stations_path = r'D:\data\高德json\bus_station.shp'# 讀取線路和站點數據
gdf_lines = gpd.read_file(lines_path)
gdf_stations = gpd.read_file(stations_path)# 創建一個空的 GeoDataFrame 用于存儲截斷后的線路
truncated_lines = gpd.GeoDataFrame(columns=gdf_lines.columns)# 遍歷每條線路,逐條處理
for line_index, line in gdf_lines.iterrows():# 獲取當前線路的坐標line_coords = list(line.geometry.coords)# 獲取原始線路名稱(用于line字段)original_line = line['name']# 創建一個字典來存儲每個站點對應的最近線路點station_to_line_points = {}# 遍歷每個站點,找到最近的線路點,確保線路名匹配for idx, station in gdf_stations.iterrows():if station['line'] == line['name']:nearest_point = nearest_points(line.geometry, station.geometry)[1]station_to_line_points[station['name']] = nearest_point# 找到每個站點在當前線路上的最近點matched_points = []for station_name, station_point in station_to_line_points.items():nearest_point = nearest_points(line.geometry, station_point)[1]matched_points.append((station_name, nearest_point))# 根據匹配的點進行截斷for i in range(len(matched_points) - 1):start_station_name, start_point = matched_points[i]end_station_name, end_point = matched_points[i + 1]# 找到起始和結束點在原線路中的位置start_pos = min(range(len(line_coords)), key=lambda j: start_point.distance(Point(line_coords[j])))end_pos = min(range(len(line_coords)), key=lambda j: end_point.distance(Point(line_coords[j])))# 確保 start_pos 和 end_pos 的有效性if start_pos < end_pos and start_pos < len(line_coords) and end_pos < len(line_coords):# 創建截斷后的線段,保持原線路的路徑truncated_line = LineString(line_coords[start_pos:end_pos + 1])# 計算截斷線段的長度truncated_length = truncated_line.length# 創建新的 GeoDataFrame 行new_line = line.copy()new_line.geometry = truncated_line# 使用站點名稱創建名稱new_line['name'] = f"{start_station_name}—{end_station_name}"new_line['length_m'] = truncated_lengthnew_line['line'] = original_line # 添加原始線路信息# 將新行添加到截斷后的線路 GeoDataFrametruncated_lines = pd.concat([truncated_lines, gpd.GeoDataFrame([new_line])], ignore_index=True)# 保存截斷后的線路到新的 shapefile
truncated_lines.to_file(r'D:\data\高德json\lines.shp', encoding='utf-8')print("處理完成!")
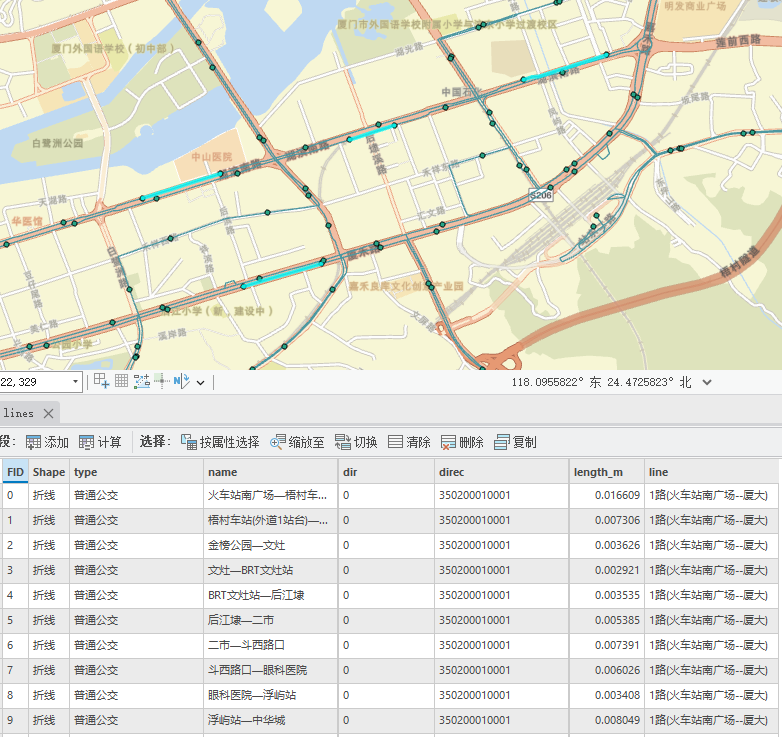
腳本執行結束,我們會得到一個文件名為lines的shp圖層,標簽包含line(線路名稱)、dir、?name(站點—站點名稱)、direc(線路編碼)、length_m(線段長度)這些信息,生成線段結果如下,每條線路都基于線路與站點的唯一對應關系進行截斷,并生成新的線段;
文章僅用于分享個人學習成果與個人存檔之用,分享知識,如有侵權,請聯系作者進行刪除。所有信息均基于作者的個人理解和經驗,不代表任何官方立場或權威解讀。






![[代碼隨想錄21二叉樹]二叉樹的修改和改造,修剪二叉樹,將有序數組轉為二叉搜索樹](http://pic.xiahunao.cn/[代碼隨想錄21二叉樹]二叉樹的修改和改造,修剪二叉樹,將有序數組轉為二叉搜索樹)
))











