K8S 如何創建容器?
下面這張圖,就是經典的 K8S 創建容器的步驟,可以說是冗長復雜,至于為什么設計成這樣的架構,繼續往下讀。
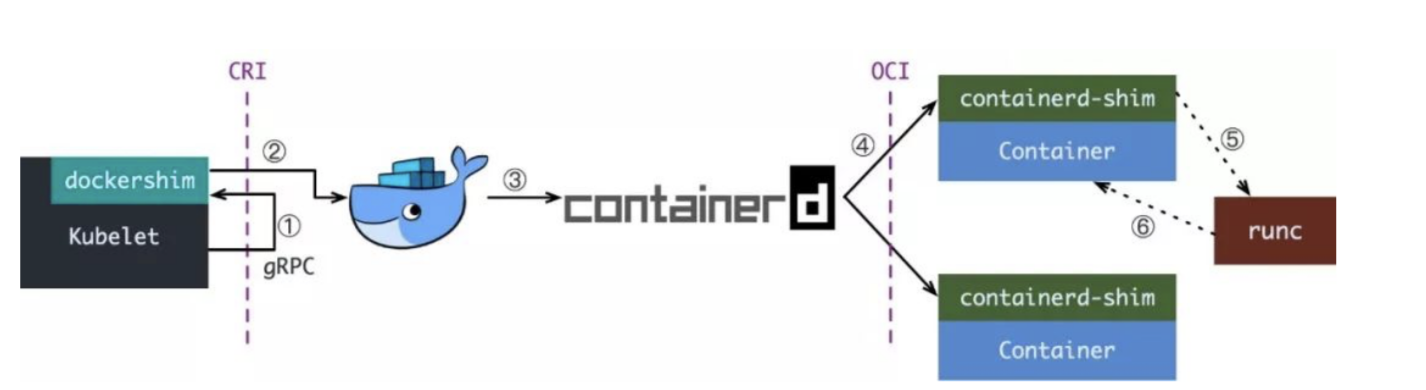
前半部分
-
CRI(Container Runtime Interface,容器運行時接口)
在 K8S 中,真正負責創建容器運行時的是 kubelet 這個組件。
當 kubelet 對容器運行時進行操作時,并不會直接調用 Docker 的 API,而是通過一組叫作 CRI 的 gRPC 接口來間接執行的。
其實對于 1.6 版本之前的 K8S 來講,kubelet 是直接與 Docker 的 API 交互的,為什么要單獨多出這一層抽象,其實是商戰的結果。
當時,Docker 風靡全球,許多公司都希望能在這一領域分一杯羹,紛紛推出了自家的容器運行時。其中最著名的要屬 CoreOS 公司的 rkt 項目。雖然 Docker 是 K8S 最依賴的容器運行時,但憑借與 Google 的特殊關系,CoreOS 公司在 2016 年成功地將對 rkt 容器的支持寫進了 kubelet 的主代碼里。
這下把專門維護 kubelet 的小組 sig-node 坑慘了。因為在這種情況下,kubelet 的任何重要功能更新都必須同時考慮 Docker 和 rkt 這兩種容器運行時的處理場景,并分別更新 Docker 和 rkt 的代碼。
更麻煩的是,由于 rkt 比較小眾,每次修改 rkt 代碼都必須依賴 CoreOS 公司的員工。這不僅降低了開發效率,還給項目的穩定性帶來了極大的隱患。
sig-node 一看這可不行,今天出個 rkt,明天出個 xxx,這下我們組也不用干活了,每天使勁折騰兼容性得了。所以把 kubelet 對容器運行時的操作統一抽象成了一個 gRPC 接口,然后告訴大家,你們想做容器運行時可以啊,我熱烈歡迎,但是前提是必須用我這個接口。
這一層統一的容器操作接口,就是 CRI ,這樣 kubelet 就只需要跟這個接口打交道就可以了。而作為具體的容器項目,比如 Docker、 rkt,它們就只需要自己提供一個該接口的實現,然后對 kubelet 暴露出 gRPC 服務即可。
下面這幅圖展示了 CRI 里主要的接口:

可以簡單把 CRI 分為兩組:
-
第一組,是?
RuntimeService。它提供的接口,主要是跟容器相關的操作。比如,創建和啟動容器、刪除容器、執行?exec?命令等等。 -
而第二組,則是?
ImageService。它提供的接口,主要是容器鏡像相關的操作,比如拉取鏡像、刪除鏡像等等。
-
CRI shim
但是說到底 CRI 只是 K8S 推出的一個標準而已,當時的 K8S 還沒有達到如今這般武林盟主的統治地位,各家公司的容器項目也不能說我只跟 K8S 綁死,只適配 CRI 接口。所以,?shim?(墊片)就誕生了。
一個?shim?的工作就是就是作為適配器將各種容器運行時本身的接口適配到 K8S 的 CRI 接口上,以便用來響應 kubelet 發起的 CRI 請求。
每一個容器運行時都可以自己實現一個 CRI shim,用來把 CRI 請求 “翻譯”成自家容器運行時能夠聽懂的請求。

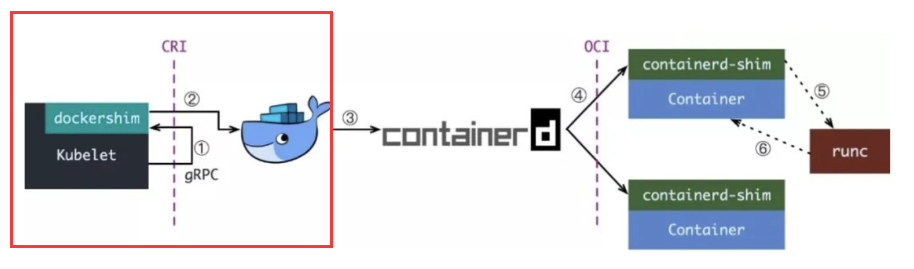
如果你用 Docekr 作為容器運行時,那你的 CRI shim 就是?dockershim,因為當時 Docker 的江湖地位很高,kubelet 是直接集成了?dockershim?的,所以 K8S 創建容器的前半部分如下圖紅框所示:
后半部分
當?dockershim?收到 CRI 請求之后,它會把里面的內容拿出來,然后組裝成 Docker API 請求發送給 Docker daemon。
請求到了 Docker daemon 之后就是 Docker 創建容器的流程了。
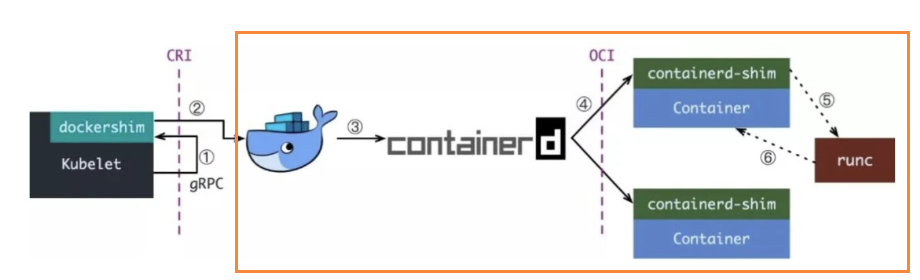
從 Docker 1.11 版本開始,Docker 容器就不再是通過簡單的 Docker Daemon 來啟動了,而是通過一個守護進程 containerd 來完成的,因此 Docker Daemon 仍然不能幫我們創建容器,而是要請求 containerd 創建一個容器。
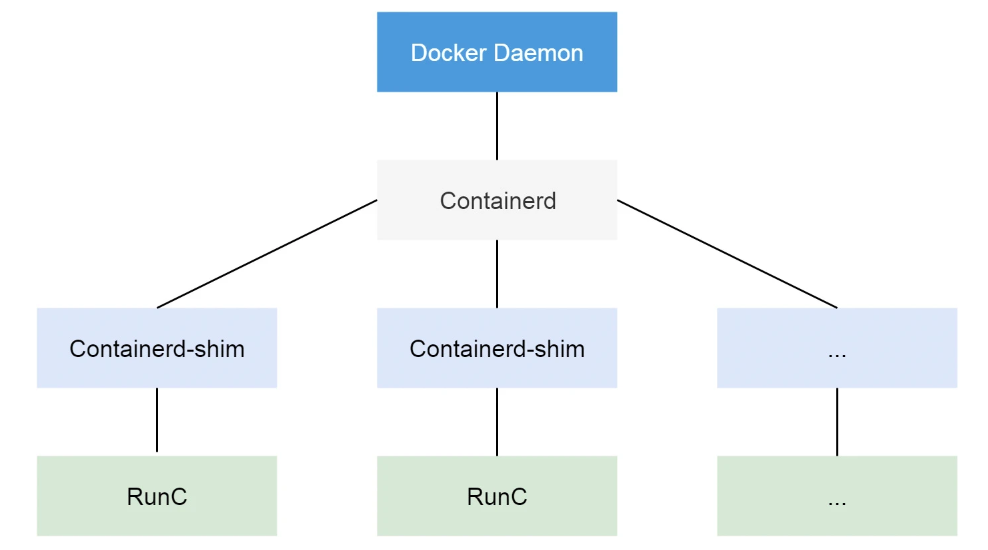
containerd 收到請求之后也并不會直接去操作容器,而是創建一個叫?containerd-shim?的進程來處理,這是因為容器需要一個父進程來做狀態收集、維持 stdin 等 fd 打開等工作的。
假如這個父進程就是 containerd,如果 containerd 掛掉的話,整個宿主機上所有的容器都得退出了,而引入?containerd-shim?就可以避免這種問題。
我在這篇文章《兩個關鍵詞帶你了解容器技術的實現》里提到過,容器其實是宿主機上的一個進程,只不過通過 Linux 內核的 namespace 和 cgroups 機制,以及掛載 root 文件系統等操作來實現隔離和資源限制。
對于 namespaces 和 cgroups 的配置,以及掛載 root 文件系統等操作這塊內容已經有了標準的規范,那就是 OCI (Open Container Initiative,開放容器標準)。
OCI 標準其實就是一個文檔,主要規定了容器鏡像的結構、以及容器需要接收哪些操作指令:
-
容器鏡像要長啥樣,即?
ImageSpec。里面的大致規定就是你這個東西需要是一個壓縮了的文件夾,文件夾里以 xxx 結構放 xxx 文件; -
容器要需要能接收哪些指令,這些指令的行為是什么,即?
RuntimeSpec。這里面的大致內容就是“容器”要能夠執行?create,start,stop,delete這些命令。
OCI 有一個參考實現,那就是?runc(Docker 被逼無耐將?libcontainer?捐獻出來然后改名為?runc?)。既然是標準肯定就有其他 OCI 實現,比如 Kata、gVisor 這些容器運行時都是符合 OCI 標準的。
所以實際上?containerd-shim?通過調用?runc?來創建容器,runc?啟動完容器后本身會直接退出,containerd-shim?則會成為容器進程的父進程, 負責收集容器進程的狀態, 上報給 containerd, 并在容器中 pid 為 1 的進程退出后接管容器中的子進程進行清理, 確保不會出現僵尸進程。
另一個容器運行時:containerd
從上面的內容我們可以看到,真正容器相關的操作其實在 containerd 那一塊,至于前面的 docker shim 和 docker daemon 的操作不但復雜,而且對 K8S 來講大部分功能都是用不上的。
所以從 K8S 1.20 版本開始,K8S 宣布棄用 Docker,推薦使用 containerd 作為容器運行時。
至于為什么要用 containerd 作為容器運行時,也有商業競爭的原因。當時 docker 公司為了跟 K8S 競爭,搞了個 Docker Swarm,并且把架構進行了切分:把容器操作都移動到一個單獨的 containerd 進程中去,讓 Docker Daemon 專門負責上層的封裝編排。
可惜在 K8S 面前 swarm 就是弟弟,根本打不過,于是 Docker 公司只能后退一步,將 containerd項目捐獻給 CNCF 基金會,而 K8S 也見好就收,既然 Docker 已先退了一步,那就干脆優先支持原生Docker 衍生的容器運行時:containerd 。

使用 containerd 作為容器運行時之后,就不能再使用?docker ps?或?docker inspect?命令來獲取容器信息。由于不能列出容器,因此也不能獲取日志、停止容器,甚至不能通過?docker exec?在容器中執行命令。
當然我們仍然可以下載鏡像,或者用?docker build?命令構建鏡像,但用 Docker 構建、下載的鏡像,對于容器運行時和 K8S,均不可見。
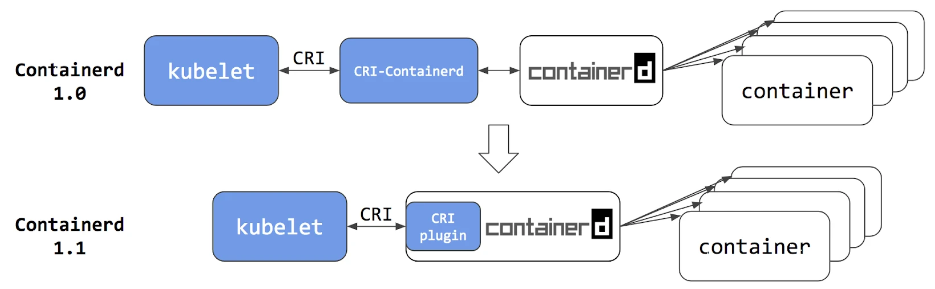
而且為了適配 CRI 標準,專門起了一個單獨的進程:CRI-containerd,這是因為還沒有捐給 K8S 的時候 containerd 會去適配其他的項目(Docker Swarm)
到了 containerd 1.1 版本,K8S 去掉了 CRI-Contained 這個 shim,直接把適配邏輯作為插件的方式集成到了 containerd 主進程中,現在這樣的調用就更加簡潔了。
除此之外,K8S 社區也做了一個專門用于 K8S 的運行時 CRI-O,它直接兼容 CRI 和 OCI 規范。上圖中的 conmon 對于?containerd-shim
文章轉載自:咸魚Linux運維
原文鏈接:https://www.cnblogs.com/edisonfish/p/18303667
體驗地址:引邁 - JNPF快速開發平臺_低代碼開發平臺_零代碼開發平臺_流程設計器_表單引擎_工作流引擎_軟件架構



)
)





)
:讀取,函數,正則表達式,文本處理工具cut和awk)







![[C++] 深度剖析C_C++內存管理機制](http://pic.xiahunao.cn/[C++] 深度剖析C_C++內存管理機制)