
Midjourney 的知識圖譜聊天機器人的想法。
大型語言模型 (LLM) 的第一波炒作來自 ChatGPT 和類似的基于網絡的聊天機器人,這些模型在理解和生成文本方面非常出色,這讓人們(包括我自己)感到震驚。
我們中的許多人登錄并測試了它寫俳句、動機信或電子郵件回復的能力。很快我們就發現,法學碩士不僅擅長生成創造性背景,還擅長解決典型的自然語言處理和其他任務。
LLM 炒作開始后不久,人們就開始考慮將其集成到他們的應用程序中。不幸的是,如果您只是圍繞 LLM API 開發包裝器,那么您的應用程序很可能會失敗,因為它沒有提供額外的價值。
LLM 的一個主要問題是所謂的知識截止。知識截止術語表示 LLM不知道他們接受培訓后發生的任何事件。例如,如果你向 ChatGPT 詢問 2023 年發生的某件事,你會得到以下回應。
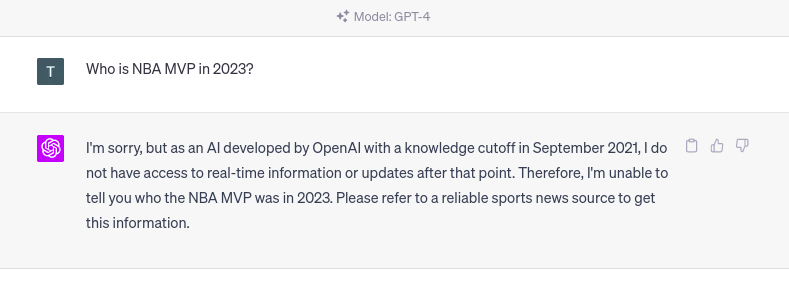
ChatGPT 的知識截止日期。圖片由作者提供。
如果您向法學碩士詢問其訓練數據集中不存在的任何事件,也會出現同樣的問題。雖然知識截止日期與任何公開可用的信息相關,但法學碩士并不了解在知識截止日期之前可能存在的私人或機密信息。
例如,大多數公司都有一些他們不會公開分享的機密信息,但可能對擁有能夠回答這些問題的定制法學碩士感興趣。另一方面,法學碩士知道的許多公開信息可能已經過時了。
因此,更新和擴展法學碩士學位的知識在今天非常重要。
LLM 的另一個問題是,它們被訓練來生成聽起來很逼真的文本,但這些文本可能并不準確。有些無效信息比其他信息更難發現。尤其是對于缺失數據,LLM 很可能會編造一個聽起來令人信服但實際上錯誤的答案,而不是承認它在訓練中缺乏基本事實。
例如,研究或法庭引證可能更容易驗證。幾周前,一名律師因盲目相信 ChatGPT 提供的法庭引證而陷入麻煩。
我還注意到,LLM 會持續提供有關任何類型的 ID(例如 WikiData 或其他識別號碼)的自信但虛假的信息。
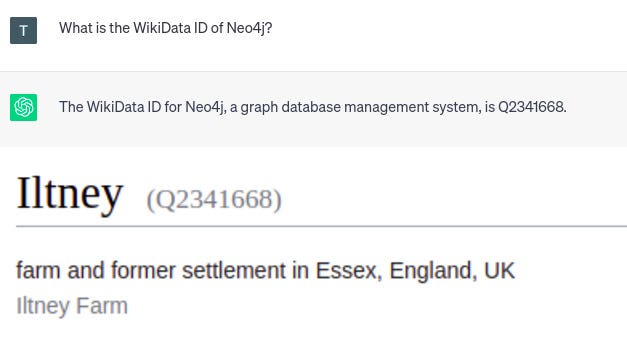
ChatGPT 的幻覺。圖片由作者提供。
由于 ChatGPT 的響應是肯定的,您可能希望它是準確的。但是,給定的 WikiData id 指向英格蘭的一個農場。因此,您必須非常小心,不要盲目相信 LLM 產生的一切。驗證答案或從 LLM 產生更準確的結果是另一個需要解決的大問題。
當然,LLM 還存在其他問題,例如偏見、即時注入等。不過,我們不會在這里討論這些問題。相反,在這篇博文中,我們將介紹并重點介紹微調和檢索增強型 LLM 的概念,并評估它們的優缺點。
法學碩士 (LLM) 的監督微調
解釋 LLM 的培訓方式超出了本博文的范圍。相反,您可以觀看Andrej Karpathy 的這段精彩視頻,了解 LLM 的最新情況并了解 LLM 培訓的不同階段。
通過微調 LLM,我們參考監督訓練階段,在此期間您提供額外的問答對以優化大型語言模型 (LLM) 的性能。
此外,我們還確定了兩種用于微調 LLM 的不同用例。
一個用例是微調模型以更新和擴展其內部知識。
相反,另一個用例則專注于針對特定任務(如文本摘要或將自然語言轉換為數據庫查詢)微調模型。
首先,我們將討論第一個用例,我們使用微調技術來更新和擴展 LLM 的內部知識。
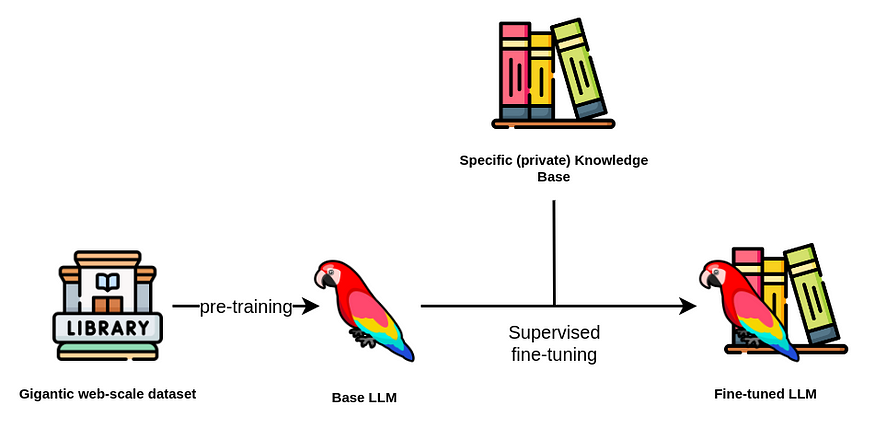
監督微調流程。圖片由作者提供。圖標來自Flaticons。
通常,你會想要避免對 LLM 進行預訓練,因為成本可能高達數十萬甚至數百萬美元。基礎 LLM 是使用龐大的文本語料庫進行預訓練的,通常有數十億甚至數萬億個標記。
雖然LLM 的參數數量至關重要,但它并不是選擇基礎 LLM 時應該考慮的唯一參數。除了許可證之外,您還應該考慮預訓練數據集和基礎 LLM 的偏差和毒性。
選擇基礎 LLM 后,您可以開始下一步微調。由于有 LoRa和QLoRA等可用技術,微調步驟的計算成本相對較低。
使用 LoRA 進行高效穩定擴散微調
但是,構建訓練數據集更加復雜,而且成本高昂。如果你負擔不起專門的注釋團隊,那么似乎趨勢是使用LLM 構建訓練數據集來微調你想要的 LLM(這真的很復雜)。
例如,斯坦福的羊駝訓練數據集是使用 OpenAI 的 LLM 創建的,生成 5.2 萬條訓練指令的成本約為 500 美元,相對便宜。
我們推出了 Alpaca 7B,這是基于 52K 指令遵循演示對 LLaMA 7B 模型進行微調的模型。在我們的……
另一方面,Vicuna 模型通過使用用戶在 ShareGPT.com 上發布的 ChatGPT 對話進行了微調。
Vicuna:一款開源聊天機器人,其 ChatGPT 質量達到 GPT-4 的 90%* | LMSYS Org
H2O還有一個相對較新的項目,名為 WizardLM,旨在將文檔轉換為可用于微調 LLM 的問答對。
我們還沒有發現任何最近的文章描述如何使用知識圖來準備可以用于微調 LLM 的良好問答對。
這是我們計劃在 NaLLM 項目中探索的一個領域。我們有一些利用 LLM 從知識圖譜上下文構建問答對的想法。
然而,目前仍有許多未知數。
例如,你能否對同一個問題提供兩個不同的答案,然后 LLM 以某種方式將它們合并到其內部知識庫中?
另一個考慮因素是,如果不考慮其關系,知識圖譜中的某些信息就不相關。因此,我們是否必須預先定義相關查詢,或者是否有更通用的方法來實現它?或者我們可以使用表示主語-謂語-賓語表達式的節點-關系-節點模式來生成相關對?
這些是我們打算在即將發布的博客文章中回答的一些問題。
想象一下,你以某種方式設法根據知識圖譜中存儲的信息生成包含問答對的訓練數據集。因此,LLM 現在包含更新的知識。
然而,對模型進行微調并不能解決知識截止問題,因為它只是將知識截止推遲到以后的日期。
因此,我們建議僅針對緩慢變化或更新的數據通過微調技術更新 LLM 的內部知識。例如,您可以使用微調模型來提供旅游信息。
但是,當您想在回復中包含特殊的時間相關(實時)或個性化促銷時,您就會遇到麻煩。同樣,微調模型對于分析工作流程來說并不理想,因為在分析工作流程中,您會詢問公司在過去一周內獲得了多少新客戶。
目前,微調方法可以幫助減輕幻覺,但不能完全消除幻覺。一個問題是,LLM在提供答案時不會引用其來源。因此,你不知道答案是來自預訓練數據、微調數據集還是由 LLM 編造的。此外,如果你使用 LLM 創建微調數據集,可能還有另一個可能的虛假來源。
最后,經過微調的模型無法根據用戶提出的問題自動提供不同的答案。同樣,也沒有訪問限制的概念,這意味著與 LLM 交互的任何人都可以訪問其所有信息。
檢索增強生成
大型語言模型在自然語言應用中表現非常出色,例如
- 文本摘要,
- 提取相關信息,
- 實體消歧
- 從一種語言翻譯成另一種語言,甚至
- 將自然語言轉換為數據庫查詢或腳本代碼。
此外,以前的 NLP 模型通常是針對特定領域和任務的,這意味著您很可能需要根據您的用例和領域訓練自定義自然語言模型。但是,得益于 LLM 的泛化能力,可以應用單個模型來解決各種任務集合。
我們觀察到使用檢索增強型 LLM 的趨勢相當明顯,即不再使用 LLM 來訪問其內部知識,而是使用 LLM作為自然語言界面您的公司或私人信息。
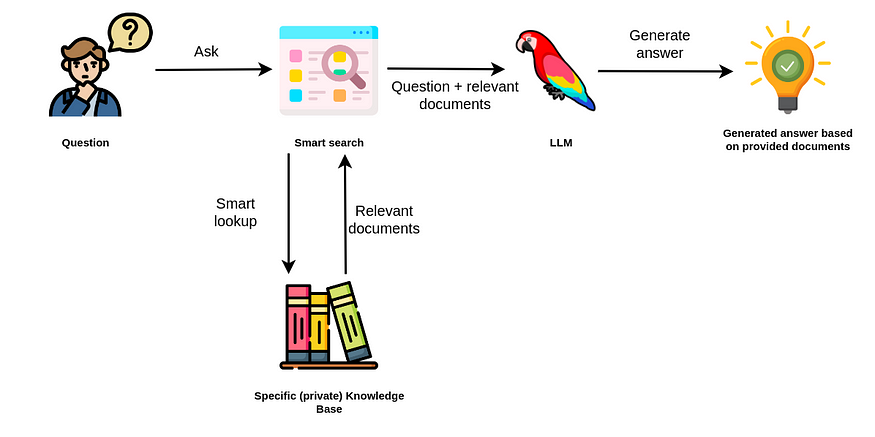
檢索增強生成。圖片由作者提供。圖標來自Flaticons。
檢索增強方法使用 LLM 根據從數據源額外提供的相關文檔生成答案。
因此,你不需要依賴 LLM 的內部知識來回答問題。相反,LLM 只用于從你傳入的文檔中提取相關信息并進行總結。
ChatGPT 插件
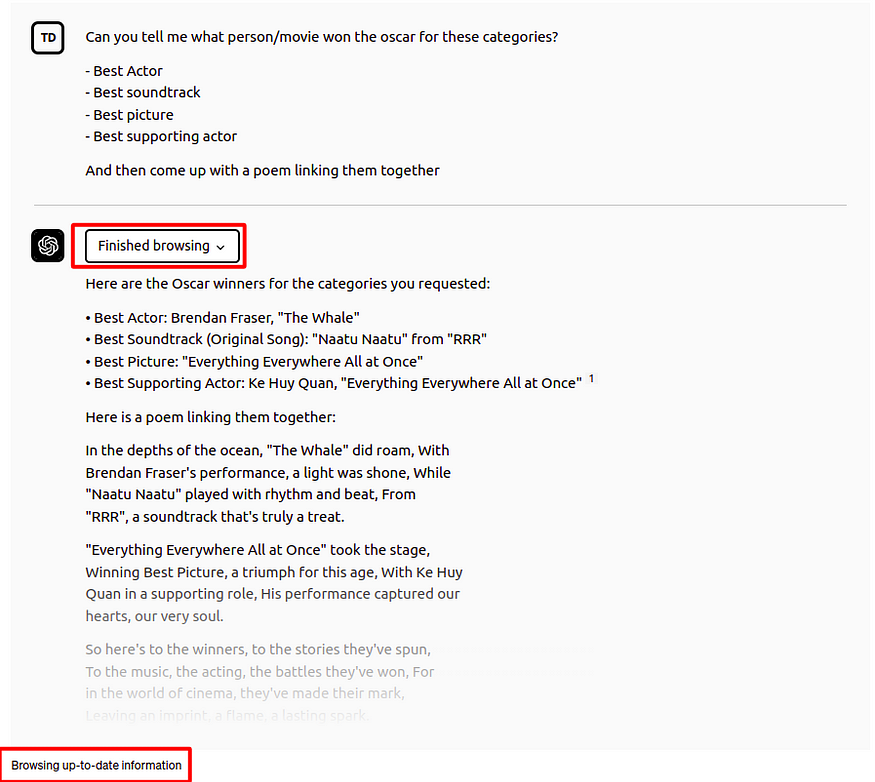
例如,ChatGPT 插件可以被視為 LLM 應用程序的檢索增強方法。啟用瀏覽插件的 ChatGPT 界面允許 LLM 搜索互聯網以訪問最新信息并使用它來構建最終答案。
 ?
?
帶有瀏覽插件的 ChatGPT。圖片由作者提供。
在這個例子中,ChatGPT 能夠回答誰在 2023 年獲得了奧斯卡各個獎項。但請記住,ChatGPT 的知識截止日期是 2021 年,因此它無法從其內部知識中知道誰獲得了 2023 年奧斯卡獎。因此,它通過瀏覽插件訪問外部信息,這使它能夠使用最新信息回答問題。這些插件在 OpenAI 平臺內部提供了一種集成的增強機制。
如果您一直關注 LLM 領域,您可能聽說過LangChain 庫。
LangChain 入門:構建 LLM 驅動應用程序的初學者指南
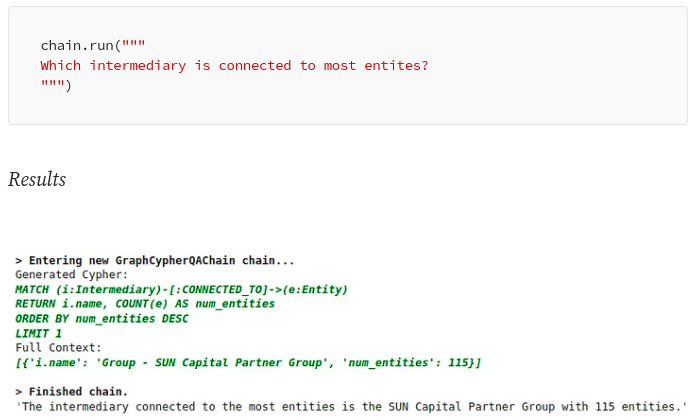
LangChain 庫可用于讓 LLM 訪問來自各種來源(如 Google 搜索、矢量數據庫或知識圖譜)的實時信息。例如,LangChain 添加了Cypher Search 鏈,它將自然語言問題轉換為 Cypher 語句,使用它從 Neo4j 數據庫中檢索信息,并根據提供的信息構建最終答案。
使用 LangChain 庫,您可以方便地生成 Cypher 查詢,從而高效檢索……
通過 Cypher 搜索鏈,LLM 不僅可用于構建最終答案,還可將自然語言問題轉化為 Cypher 查詢。
 ?
?
LangChain 中的 Cypher 搜索。圖片由作者提供。
另一個用于檢索增強型 LLM 工作流的流行庫是LlamaIndex (GPT Index)。LlamaIndex 是一個全面的數據框架,旨在通過使大型語言模型 (LLM) 能夠利用私有或自定義數據來提高其性能。
LlamaIndex 關于 TWIML AI:摘要(使用 LlamaIndex)
首先,LlamaIndex 提供數據連接器,方便接收各種數據源和格式的數據,涵蓋從 API、PDF、文檔到 SQL 或圖形數據的所有內容。
此功能可輕松將現有數據集成到 LLM 中。其次,它提供了使用索引和圖表構建所攝取數據的有效機制,確保數據經過適當排列以用于 LLM。此外,它還包括一個高級檢索和查詢界面,使用戶能夠輸入 LLM 提示并接收上下文檢索、知識增強的輸出。
ChatGPT Plugins 和 LangChain 等檢索增強型 LLM 應用程序的理念是避免僅依賴內部 LLM 知識來生成答案。相反,LLM 用于解決諸如從自然語言構建數據庫查詢以及根據外部提供的信息或利用插件/代理進行檢索來構建答案等任務。
檢索增強方法比微調方法具有一些明顯的優勢:
- 答案可以引用其信息來源,這允許您驗證信息并根據需要更改或更新基礎信息
- 幻覺不太可能發生,因為你不依賴法學碩士的內部知識來回答問題,而只使用相關文件中提供的信息
- 當你將問題從 LLM 維護轉變為數據庫維護、查詢和上下文構建問題時,更改、更新和維護 LLM 使用的底層信息會變得更加容易
- 答案可以根據用戶上下文或其訪問權限進行個性化
另一方面,使用檢索增強方法時應考慮以下限制:
- 答案與智能搜索工具一樣好
- 應用程序需要訪問您的特定知識庫,可以是數據庫或其他數據存儲
- 完全忽略語言模型的內部知識會限制可以回答的問題數量
- 有時 LLM 不遵循指示,因此如果在上下文中找不到相關的答案數據,則可能會忽略上下文或出現幻覺。
概括
這篇博文深入探討了大型語言模型 (LLM) 的局限性,例如
- 知識斷層,
- 幻覺,以及
- 缺乏用戶定制。
為了克服這些問題,我們探索了兩個概念,即微調和檢索增強 LLM 的使用。
微調 LLM涉及監督訓練階段,在此階段提供問答對以優化 LLM 的性能。這可用于更新和擴展 LLM 的內部知識或針對特定任務對其進行微調。但是,微調無法解決知識截止問題,因為它只是將截止時間推遲到以后。它也不能完全消除幻覺。因此,我們建議對允許某些幻覺的緩慢變化數據集使用微調方法。由于微調 LLM 相對較新,我們渴望了解有關微調方法和最佳實踐的更多信息。
克服 LLM 局限性的第二種方法是所謂的檢索增強生成,其中 LLM 充當訪問外部信息的自然語言接口,從而不僅僅依賴其內部知識來產生答案。檢索增強方法的優點包括來源引用、可忽略的幻覺、易于更改和更新信息以及個性化。
然而,它嚴重依賴智能搜索工具來檢索相關信息,并且需要訪問用戶的知識庫。此外,它只有在擁有解決問題所需的信息時才能回答查詢。
項目開源地址
NaLLM項目開源地址:GitHub - neo4j/NaLLM: Repository for the NaLLM project










)








