為什么選擇 RAG
新興能力
直到最近,人們發現 LLM 具有新興能力,即在與用戶或任務交互過程中出現的意外功能。
這些功能的示例包括:
解決問題:?LLM 可以利用其語言理解和推理能力,為未經過明確培訓的任務提供富有洞察力的解決方案。
適應用戶輸入:?LLM 可以根據特定用戶輸入或上下文定制其響應,從而在交互中展現一定程度的個性化。
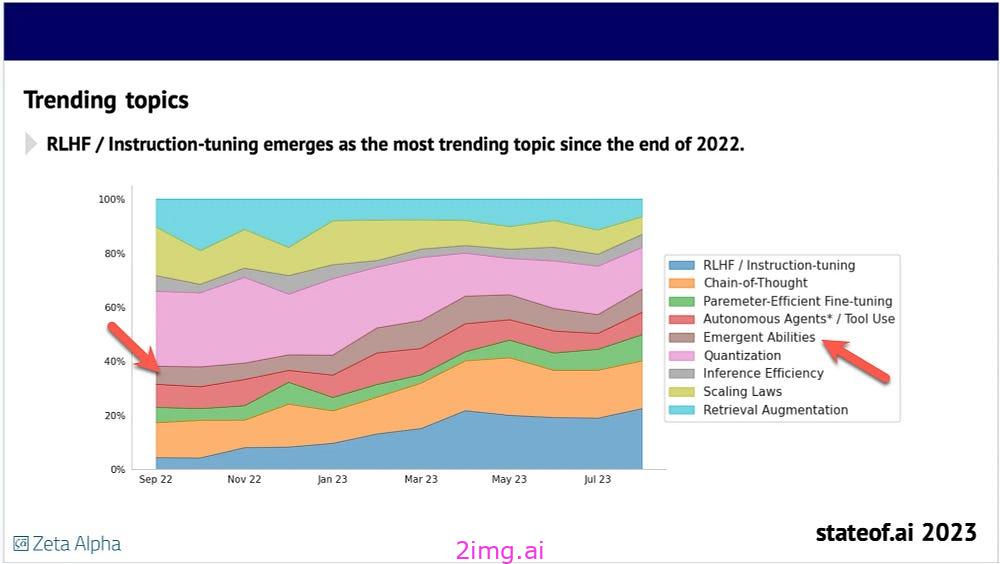
通過對上下文的理解,?LLM 可以生成與給定上下文相關且適當的響應,即使提示中沒有明確說明。
新興能力現象促使組織探索未知的大語言模型功能。然而,最近的一項研究推翻了這一概念,揭示了看似新興的能力實際上是大語言模型對給定背景的強烈反應。

指導和上下文參考
LLM 在推理時對指令反應良好,當提示包含上下文參考數據時,表現優異。大量研究已通過實證證明,LLM 優先考慮推理時提供的上下文知識,而不是經過微調的模型數據。
情境學習
上下文學習是模型根據用戶或任務提供的特定上下文調整和改進其響應的能力。
通過考慮模型的運行環境,該過程使模型能夠生成更相關、更一致的輸出。
幻覺
為大語言模型 (LLM) 提供推理時的上下文參考,從而實現上下文學習,可以減輕幻覺。
檢索增強生成 (RAG) 將大型語言模型 (LLM) 的生成能力與外部知識源相結合,以提供更準確、最新的響應。
RAG 的最新進展重點是通過迭代 LLM 細化或通過對 LLM 進行額外指令調整獲得的自我批評能力來改善檢索結果。
推測性 RAG
下圖展示了 RAG 的不同方法,包括:
- 標準 RAG,
- 自我反思 RAG &
- 校正 RAG。
標準 RAG:據 Google 稱,?標準 RAG 將所有文檔合并到提示中,這會增加輸入長度并減慢推理速度。原則上這是正確的,但存在使用摘要、重新排序和請求用戶反饋的變體。
對于分塊策略以及如何優化相關塊內上下文的分割也進行了深入研究。
自我反思 RAG需要對通用語言模型 (LM) 進行專門的指令調整,以生成用于自我反思的特定標簽。
校正 RAG使用外部檢索評估器來改進文檔質量。該評估器僅關注上下文信息,而不增強推理能力。
推測性 RAG利用更大的通用 LM 來有效地驗證由較小的專業 LM 并行生成的多個 RAG 草稿。
每個草稿都是從檢索到的文檔的不同子集生成的,提供對證據的不同視角,同時最小化每個草稿的輸入標記數量。
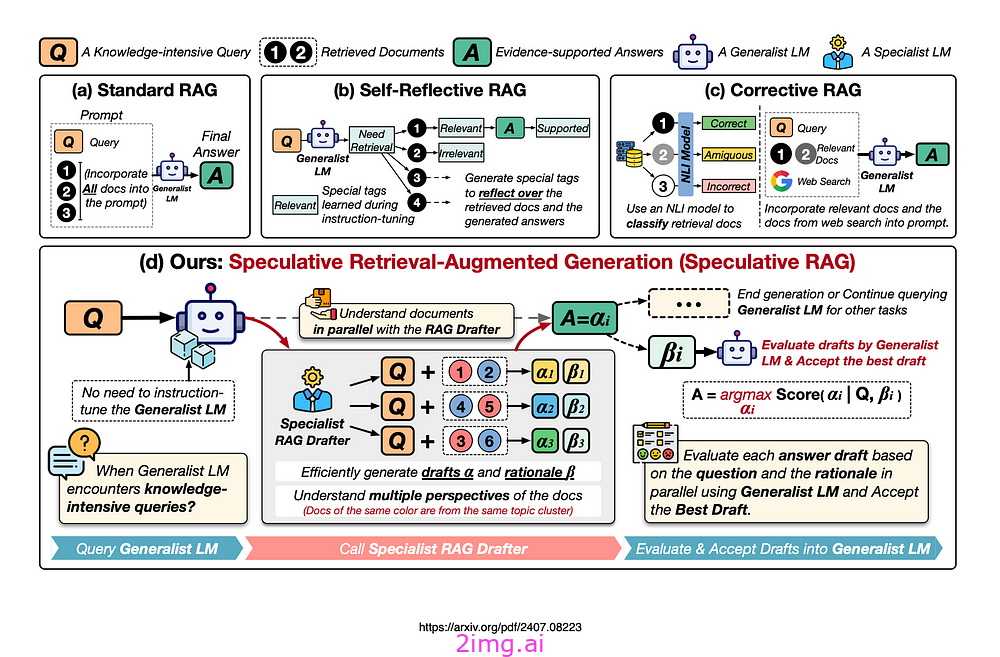
Speculative RAG 是一個框架,它使用更大的通用語言模型來有效地驗證由較小的、專門的提煉語言模型并行生成的多個 RAG 草稿。
每個草稿都基于檢索到的文檔的不同子集,提供不同的觀點并減少每個草稿的輸入標記數。
研究表明,這種方法可以增強理解力,并減輕長語境中的位置偏差。通過將起草工作委托給較小的模型,并讓較大的模型執行一次驗證,Speculative RAG 可以加速 RAG 過程。
實驗表明,Speculative RAG 在降低延遲的情況下實現了最先進的性能。
與傳統 RAG 系統相比,準確率提高 12.97%,延遲降低 51%。
如何
這個新的 RAG 框架使用較小的專業 RAG 起草器來生成高質量的草稿答案。
每個草稿均來自檢索到的文檔的不同子集,從而提供不同的觀點并減少每個草稿的輸入標記數。
通用 LM 可與 RAG 起草器配合使用,無需額外調整。
它驗證并將最有希望的草稿整合到最終答案中,增強對每個子集的理解,并減輕中間迷失現象。
谷歌認為,通過讓規模較小的專業 LM 處理起草,而規模較大的通用 LM 則并行對起草進行單次、公正的驗證,這種方法可以顯著加快 RAG 的速度。
在四個自由形式問答和閉集生成基準上進行的大量實驗證明了該方法的卓越有效性和效率。
主要考慮因素
- 這項研究很好地說明了小型語言模型如何在采用模型編排的更大框架中使用。
- SLM 因其推理能力而被充分利用,而這正是它們被專門創建的原因。
- SLM 是此場景的理想選擇,因為此實現本質上不需要知識密集型。相關和上下文知識在推理時注入。
- 該框架的目標是優化令牌數量,從而降低安全成本。
- 與傳統 RAG 系統相比,延遲減少了 51%。
- 準確率提高高達 12.97%。
- 避免對模型進行微調。
- 多個 RAG 草稿由較小的、專門的語言模型并行生成。
- 這種規模較小、專門化的 RAG 模型擅長對檢索到的文檔進行推理,并能快速生成準確的響應。這讓人想起經過訓練具有出色推理能力的 SLM Orca-2 和 Phi-3。
- 使用 Mistral 7B SLM 作為 RAG 牽引機取得了最佳效果。
- 以及驗證器 Mixtral 8x7B。



















