Abstract
三維目標檢測是自動駕駛中的關鍵任務之一。為了在實際應用中降低成本,提出了利用低成本的多視角相機進行3D目標檢測,以取代昂貴的LiDAR傳感器。然而,僅依靠相機很難實現高精度和魯棒性的3D目標檢測。解決這一問題的有效方法是將多視角相機與經濟的毫米波雷達傳感器相結合,以實現更可靠的多模態3D目標檢測。在本文中,我們介紹了RCBEVDet,這是一種在鳥瞰視角(BEV)下的雷達-相機融合3D目標檢測方法。具體而言,我們首先設計了RadarBEVNet用于雷達BEV特征提取。RadarBEVNet由一個雙流雷達骨干網和一個RCS(雷達截面)感知的BEV編碼器組成。在雙流雷達骨干網中,提出了基于點的編碼器和基于Transformer的編碼器用于提取雷達特征,并通過注入和提取模塊來促進兩個編碼器之間的通信。RCS感知的BEV編碼器以RCS作為對象大小的先驗信息,將點特征散布在BEV中。此外,我們提出了跨注意力多層融合模塊,利用可變形注意力機制自動對齊來自雷達和相機的多模態BEV特征,然后通過通道和空間融合層進行融合。實驗結果表明,RCBEVDet在nuScenes和view-of-delft(VoD)3D目標檢測基準測試中實現了新的最先進的雷達-相機融合結果。此外,RCBEVDet在21~28 FPS的更快推理速度下,實現了比所有實時相機僅和雷達-相機3D目標檢測器更好的3D檢測結果。源代碼將發布在https://github.com/VDIGPKU/RCBEVDet。
Introction
3D目標檢測技術在自動駕駛領域迅速發展,多視角相機因其成本效益和提供高分辨率語義信息而受到青睞。但單一相機存在深度信息捕捉不精確和在惡劣環境下性能下降的問題。結合經濟的毫米波雷達傳感器,可以提供距離和速度的高精度測量,且不受天氣和光照影響,實現更可靠的多模態目標檢測。
毫米波雷達雖然數據稀疏且缺乏語義信息,但作為輔助傳感器,與多視角相機結合使用,可提供互補信息,提高3D目標檢測的準確性。近年來,這種融合方法受到廣泛關注。
Method
1、RadarBEVNet
RCBEVDet的整體流程如下圖所示。多視角圖像被發送到圖像編碼器以提取特征。然后,應用視圖轉換模塊將多視角圖像特征轉換為圖像BEV特征。同時,通過提出的RadarBEVNet將對齊的雷達點云編碼為雷達BEV特征。隨后,通過跨注意力多層融合模塊融合圖像和雷達BEV特征。最后,融合的多模態BEV特征用于3D目標檢測任務。
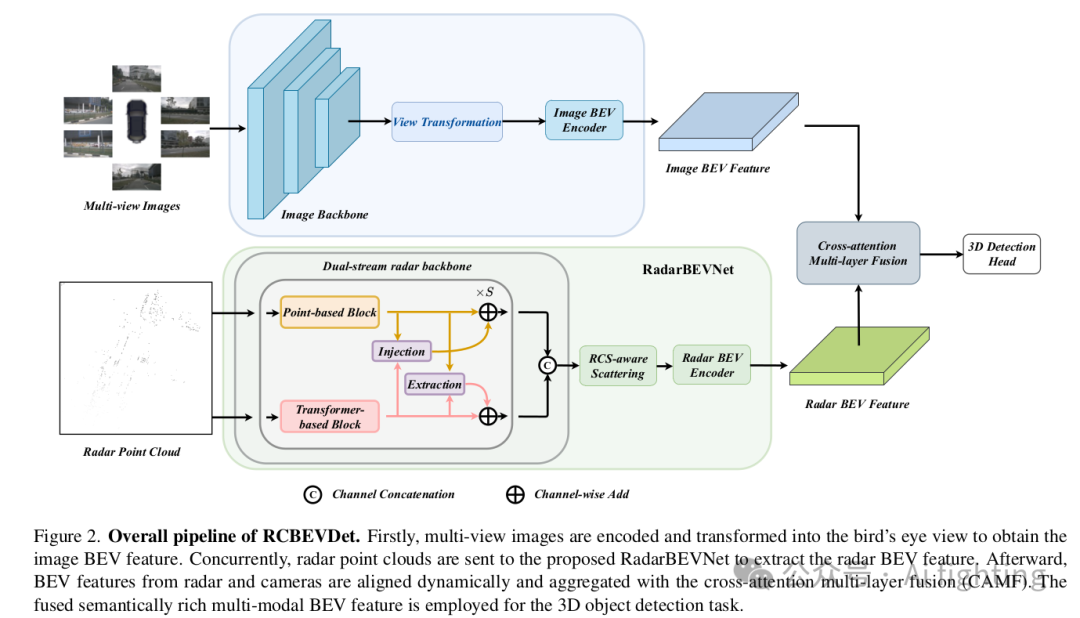
先前的雷達-相機融合方法主要采用為LiDAR點云設計的雷達編碼器,如PointPillars。相反,我們提出了RadarBEVNet,特別是用于高效的雷達BEV特征提取。
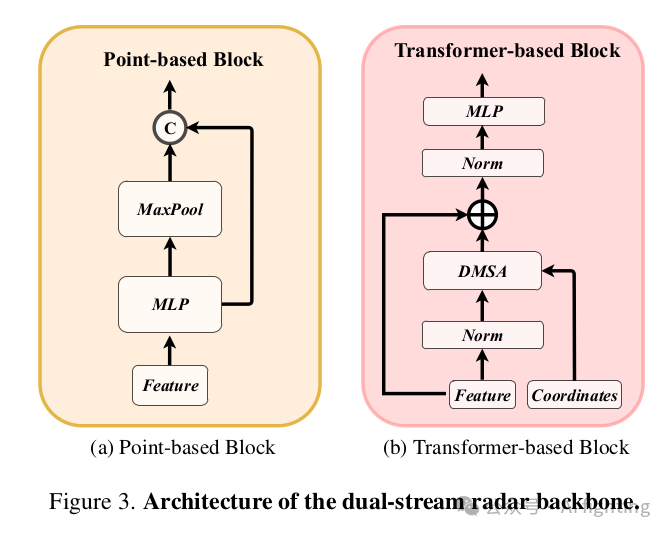
1.1 雙流雷達骨干網(Dual-stream radar backbone:雙流雷達骨干網有兩個骨干網,即基于點的骨干網和基于Transformer的骨干網。基于點的骨干網學習局部雷達特征,而基于Transformer的骨干網捕獲全局信息。具體來說,對于基于點的骨干網,我們采用類似于PointNet的簡單結構。如下圖所示,基于點的骨干網有S個塊,每個塊包含一個MLP和一個最大池化操作。輸入的雷達點特征首先發送到MLP以增加其特征維度。然后,通過對所有雷達點的最大池化操作提取全局信息,并將其與高維雷達特征連接。至于基于Transformer的骨干網,它包含S個標準的Transformer塊,具有注意力機制、前饋網絡和歸一化層,如下圖所示。由于自動駕駛場景的廣泛性,直接使用標準的自注意力機制可能使模型優化變得困難。為了解決這個問題,我們提出了一種距離調制自注意力機制(DMSA),以使模型在早期訓練迭代中聚合鄰近信息,從而促進模型收斂
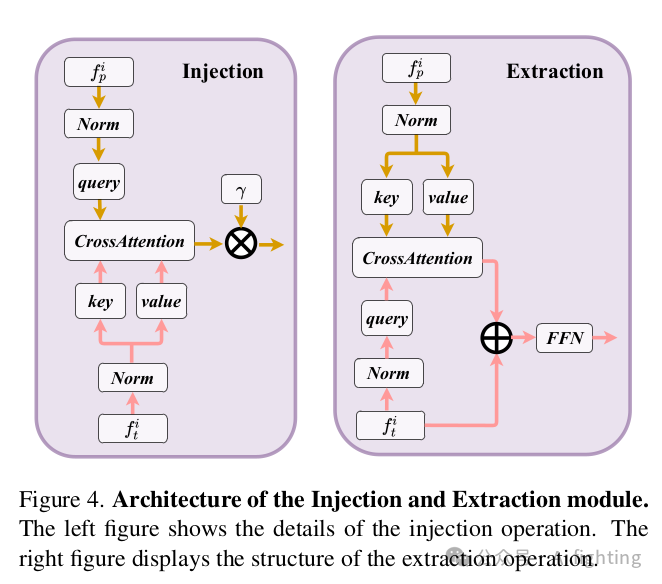
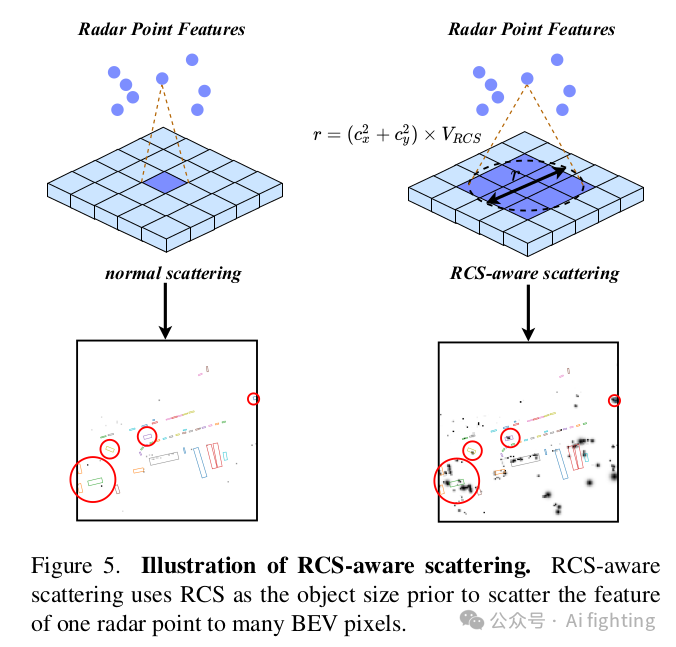
1.2 RCS感知的BEV編碼器:目前的雷達BEV編碼器通常根據點的3D坐標將點特征散布到體素空間,并壓縮z軸以生成BEV特征。然而,生成的BEV特征是稀疏的,也就是說,大多數像素的特征是零。有些像素很難聚集特征,這可能會影響檢測性能。一種解決方案是增加BEV編碼器層的數量,但這通常會導致小物體的特征被背景特征平滑掉。為了解決這個問題,我們提出了一種RCS感知的BEV編碼器。雷達截面積(RCS)衡量物體被雷達檢測到的能力。通常,較大的物體會產生較強的雷達波反射,導致較大的RCS測量值。因此,RCS可以提供物體大小的粗略測量。RCS感知的BEV編碼器的關鍵設計是RCS感知散布操作,它利用RCS作為物體大小的先驗,將一個雷達點的特征散布到多個像素,而不是在BEV空間中的一個像素,如圖5所示。
2、跨注意力多層融合模塊
2.1 利用跨注意力機制進行多模態特征對齊(Multi-modal Feature Alignment with Cross-Attention)。雷達點云經常受到方位誤差的影響。因此,雷達傳感器可能會獲取超出物體邊界的雷達點。結果,由RadarBEVNet生成的雷達特征可能會分配到相鄰的BEV網格上,導致來自相機和雷達的BEV特征對齊錯誤。為了解決這個問題,我們使用跨注意力機制動態對齊多模態特征。由于未對齊的雷達點會偏離其真實位置一定距離,我們建議使用可變形跨注意力機制來捕捉這種偏差。
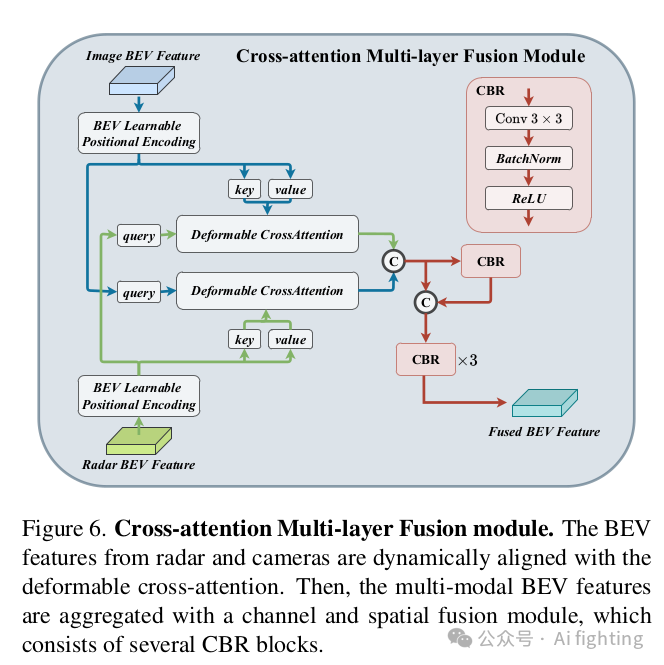
2.2 通道和空間融合(Channel and Spatial Fusion)。在通過交叉注意力對齊來自相機和雷達的BEV特征后,我們提出了通道和空間融合層來聚合多模態BEV特征.
Experiment
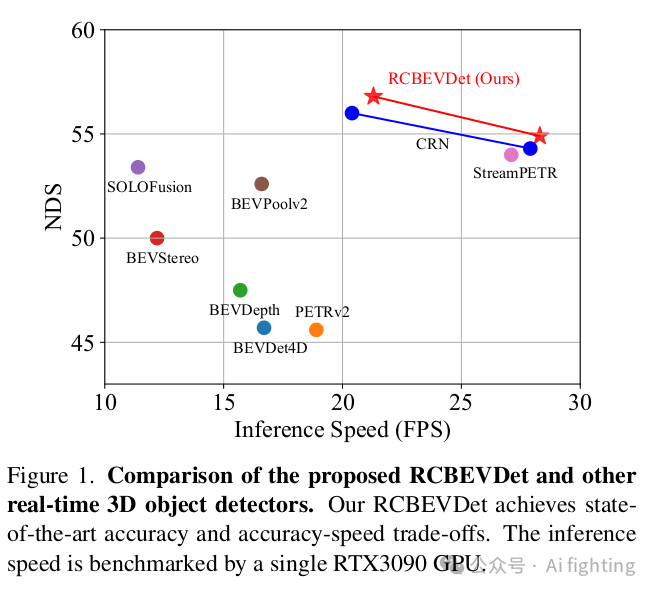
1.NuScenes 結果?:我們在 nuScenes 驗證集和測試集上將提出的 RCBEVDet 與之前的最先進的 3D 檢測方法進行了比較,如表 1 和表 2 所示。在各種主干設置下,RCBEVDet 在推理速度更快的情況下顯示出具有競爭力的 3D 物體檢測性能。值得注意的是,與之前最好的僅使用相機的方法(SOLOFusion)和雷達-相機方法(CRN)相比,RCBEVDet 使用 ResNet-50 將速度誤差(mAVE)分別減少了 14.7% 和 37.5%。此外,RCBEVDet 超越了所有基于相機的 3D 檢測方法,展示了使用互補雷達信息以實現更好的 3D 檢測的有效性。
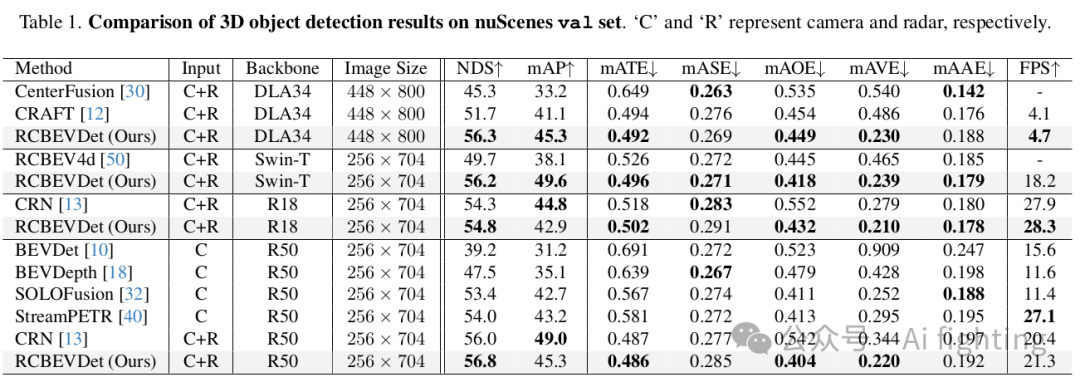
如表 1 所示,RCBEVDet 尤其在整體指標(NDS)和速度誤差(mAVE)方面顯示出競爭力。具體來說,RCBEVDet 在之前的雷達-相機融合方法中表現出色。
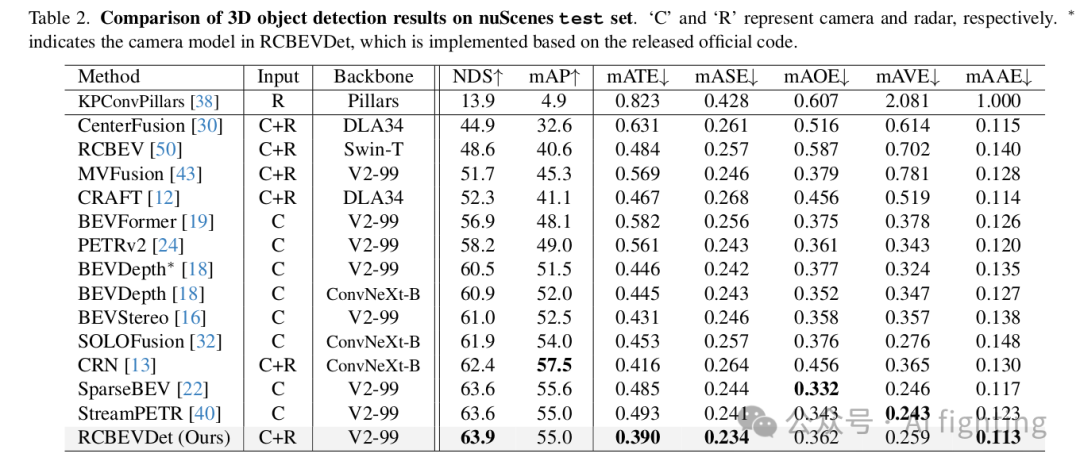
2.VoD 結果:為了進一步證明 RCBEVDet 的有效性,我們在 4D 毫米波雷達數據集 view-of-delft (VoD) 上訓練了 RCBEVDet。我們在 VoD 驗證集上的結果如表 3 所示。在整個區域內,RCBEVDet 比 RCFusion 高出 0.34 mAP。在感興趣區域,RCBEVDet 也以 69.80 mAP 達到了最先進的結果。

總結
文章的主要貢獻可以概括為以下幾點:
- 提出了一種名為RCBEVDet的雷達-相機多模態3D目標檢測器,旨在實現高精度、高效且魯棒的檢測。
- 設計了一種高效的雷達特征提取器RadarBEVNet,它包含雙流雷達骨干網絡,用于提取并編碼雷達特征到鳥瞰視圖(BEV)中。
- 引入了跨注意力多層融合模塊,通過可變形跨注意力機制實現雷達和相機特征的魯棒對齊和融合。
- RCBEVDet在nuScenes和VoD數據集上取得了雷達-相機多模態3D目標檢測的先進結果,并在實時檢測器中實現了精度和速度的最佳平衡。5. RCBEVDet在傳感器故障情況下展現出良好的魯棒性。
引用CVPR2024文章:?RCBEVDet: Radar-camera Fusion in Bird’s Eye View for 3D Object Detection
歡迎關注我的公眾號auto_driver_ai(Ai fighting), 第一時間獲取更新內容。
)









FFT、機械特性、閉環、慣量、剛性、抑制振動)


—— Git常用命令)

)



