前言
在上一章課程【課程總結】Day13(上):使用YOLO進行目標檢測,我們了解到目標檢測有兩種策略,一種是以YOLO為代表的策略:特征提取→切片→分類回歸;另外一種是以MTCNN為代表的策略:先圖像切片→特征提取→分類和回歸。因此,本章內容將深入了解MTCNN模型,包括:MTCNN的模型組成、模型訓練過程、模型預測過程等。
人臉識別
在展開了解MTCNN之前,我們對人臉檢測先做一個初步的梳理和了解。人臉識別細分有兩種:人臉檢測和人臉身份識別。
人臉檢測
簡述
人臉檢測是一個重要的應用領域,它通常用于識別圖像或視頻中的人臉,并定位其位置。
識別過程
- 輸入圖像:首先,將包含人臉的圖像輸入到人臉檢測模型中。
- 特征提取:深度學習模型將學習提取圖像中的特征,以便識別人臉。
- 人臉定位:模型通過在圖像中定位人臉的位置,通常使用矩形邊界框來框定人臉區域。
- 輸出結果:最終輸出包含人臉位置信息的結果,可以是邊界框的坐標或其他形式的標注。
輸入輸出
- 輸入:一張圖像
- 輸出:所有人臉的坐標框
應用場景
- 表情識別:識別人臉的表情,如快樂、悲傷等。
- 年齡識別:根據人臉特征推斷出人的年齡段。
- 人臉表情生成:通過檢測到的人臉生成不同的表情。
- …

人臉檢測特點
人臉檢測是目標檢測中最簡單的任務
- 類別少
- 人臉形狀比較固定
- 人臉特征比較固定
- 周圍環境一般比較好
人臉身份識別
簡述
人臉身份識別是指通過識別人臉上的獨特特征來確定一個人的身份。
識別過程
人臉錄入流程:
- 數據采集:采集包含人臉的圖像數據集。
- 人臉檢測:使用人臉檢測算法定位圖像中的人臉區域。
- 人臉特征提取:通過深度學習模型提取人臉圖像的特征向量。
- 特征向量存儲:將提取到的特征向量存儲在向量數據庫中。
人臉驗證流程:
- 人臉檢測:使用人臉檢測算法定位圖像中的人臉區域。
- 人臉特征提取:通過深度學習模型提取人臉圖像的特征向量。
- 人臉特征匹配:將輸入人臉的特征向量與向量數據庫中的特征向量進行匹配。
- 身份識別:根據匹配結果確定輸入人臉的身份信息。
應用領域
- 安防監控:用于門禁系統、監控系統等,實現人臉識別進出控制。
- 移動支付:通過人臉識別來進行身份驗證,實現安全的移動支付功能。
- 社交媒體:用于自動標記照片中的人物,方便用戶管理照片。
- 人機交互:實現人臉識別登錄、人臉解鎖等功能。

一般來說,一切目標檢測算法都可以做人臉檢測,但是由于通用目標檢測算法做人臉檢測太重了,所以會使用專門的人臉識別算法,而MTCNN就是這樣一個輕量級和專業級的人臉檢測網絡。
MTCNN模型
簡介
MTCNN(Multi-Task Cascaded Convolutional Neural Networks)是一種用于人臉檢測和面部對齊的神經網絡模型。
論文地址:https://arxiv.org/abs/1604.02878v1
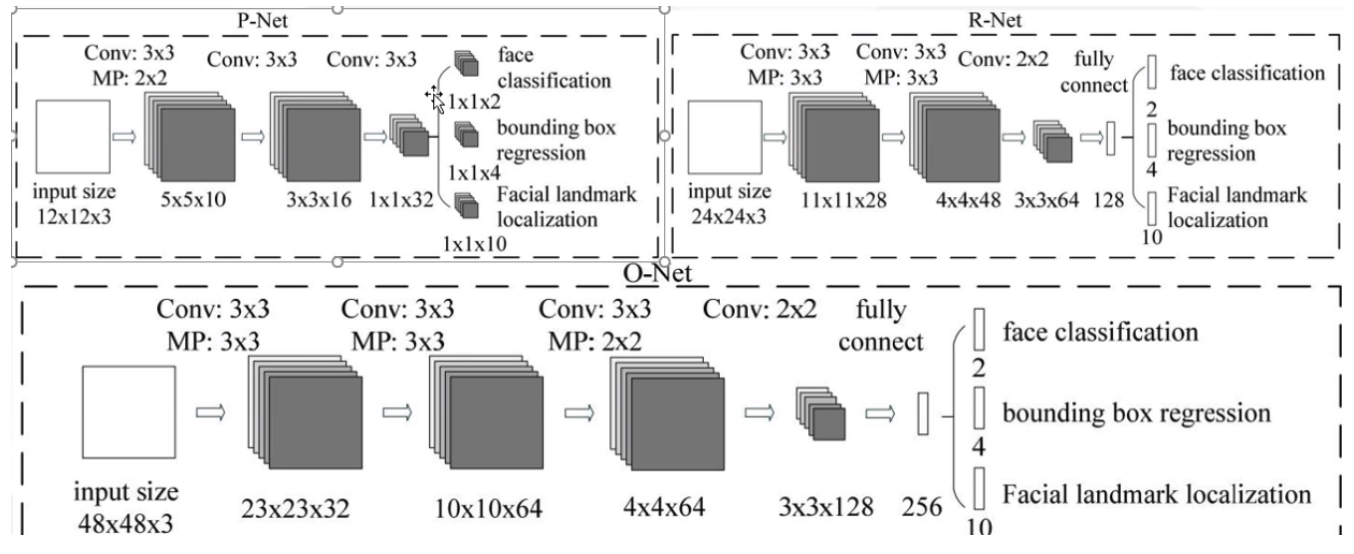
模型結構
- MTCNN采用了級聯結構,包括三個階段的深度卷積網絡,分別用于人臉檢測和面部對齊。
- 每個階段都有不同的任務,包括人臉邊界框回歸、人臉關鍵點定位等。
這個級聯過程,相當于
海選→淘汰賽→決賽的過程。
整體流程
上圖是論文中對于MTCNN整體過程的圖示,我們換一種較為容易易懂的圖示來理解整體過程:
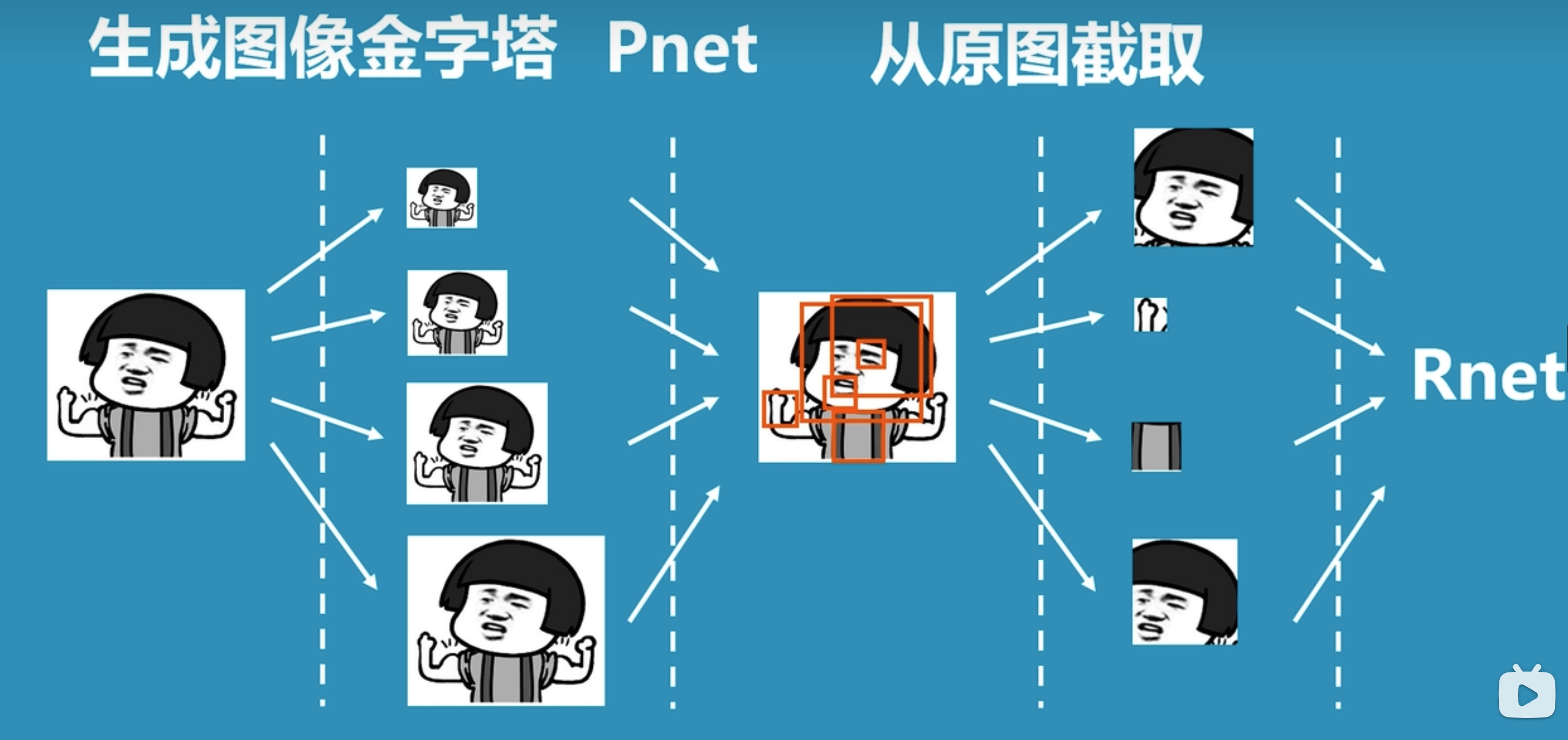
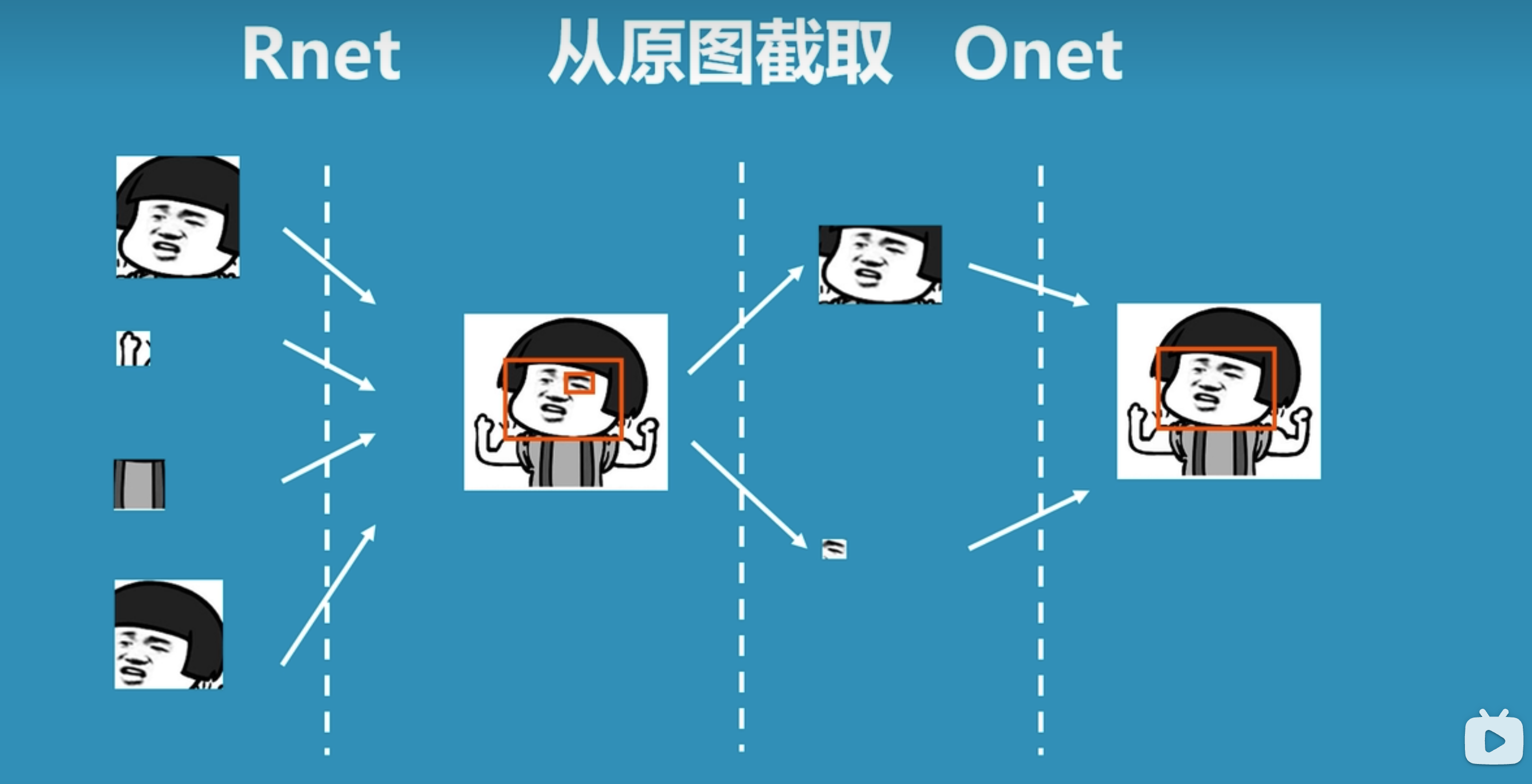
- 先將圖片生成不同尺寸的圖像金字塔,以便識別不同大小的人臉。
- 將圖片輸入到P-net中,識別出可能包含人臉的候選窗口。
- 將P-net中識別的可能人臉的候選窗口輸入到R-net中,識別出更精確的人臉位置。
- 將R-net中識別的人臉位置輸入到O-net中,進行更加精細化識別,從而找到人臉區域。
備注:上圖引用自科普:什么是mtcnn人臉檢測算法
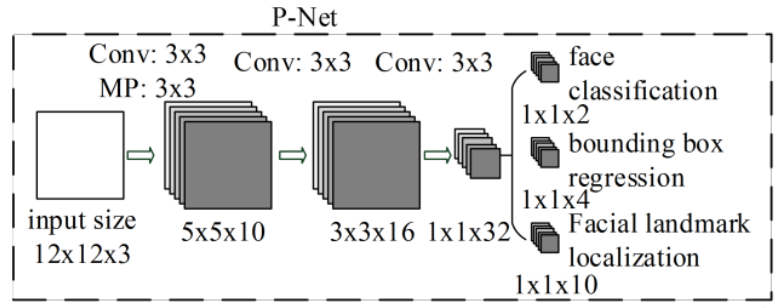
P-net:人臉檢測
- 名稱:提議網絡(proposal network)
- 作用:P網絡通過卷積神經網絡(CNN)對輸入圖像進行處理,識別出可能包含人臉的候選窗口,并對這些候選窗口進行邊界框的回歸,以更準確地定位人臉位置。
- 特點:
- 純卷積網絡,無全鏈接(精髓所在)
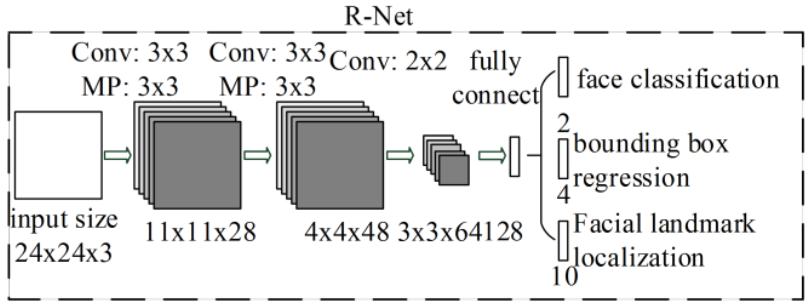
R-net:人臉對齊
- 名稱:精修網絡(refine network)
- 作用:R網絡通過分類器和回歸器對P網絡生成的候選窗口進行處理,進一步篩選出包含人臉的區域,并對人臉位置進行修正,以提高人臉檢測的準確性。
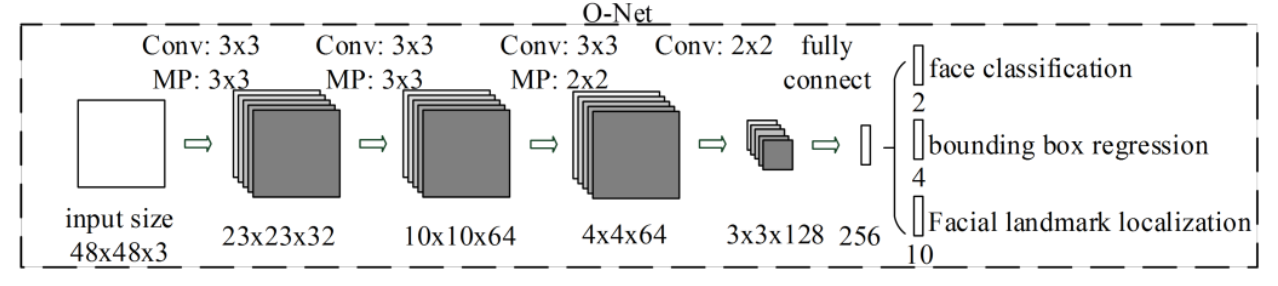
O-net:人臉識別
- 名稱:輸出網絡(output network)
- 作用:O網絡通過更深層次的卷積神經網絡處理人臉區域,優化人臉位置和姿態,并輸出面部關鍵點信息,為后續的面部對齊提供重要參考。
MTCNN用到的主要模塊
圖像金字塔
MTCNN的P網絡使用的檢測方式是:設置建議框,用建議框在圖片上滑動檢測人臉

由于P網絡的建議框的大小是固定的,只能檢測12*12范圍內的人臉,所以其不斷縮小圖片以適應于建議框的大小,當下一次圖像的最小邊長小于12時,停止縮放。
IOU
定義:IOU(Intersection over Union)是指交并比,是目標檢測領域常用的一種評估指標,用于衡量兩個邊界框(Bounding Box)之間的重疊程度。
兩種方式:
- 交集比并集
- 交集比最小集
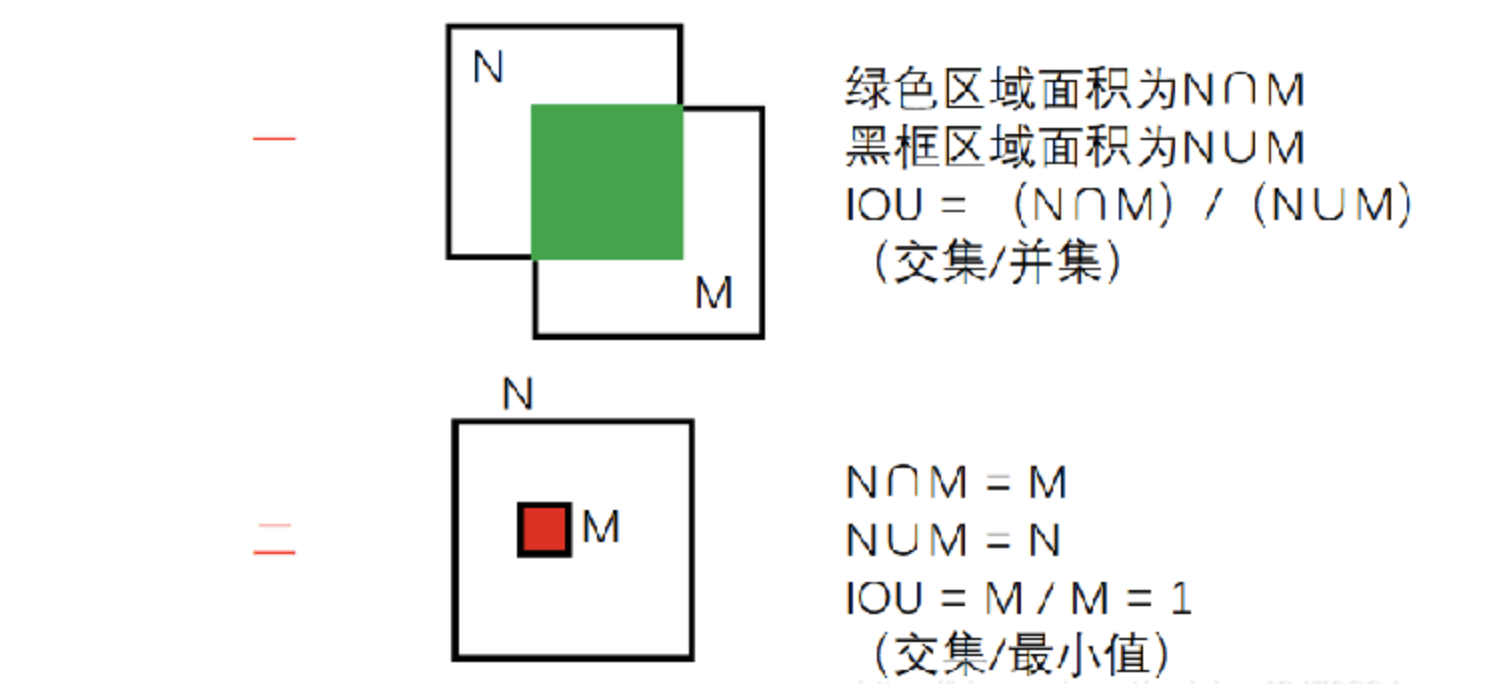
O網絡iou值大于閾值的框被認為是重復的框會丟棄,留下iou值小的框,但是如果出現了下圖中大框套小框的情況,則iou值偏小也會被保留,是我們不想看到的,因此我們在O網絡采用了第二種方式的iou以提高誤檢率。
NMS(Non-Maximum Suppression,非極大值抑制)
定義:
NMS是一種目標檢測中常用的技術,旨在消除重疊較多的候選框,保留最具代表性的邊界框,以提高檢測的準確性和效率。
工作原理:
NMS的工作原理是通過設置一個閾值,比如IOU(交并比)閾值,對所有候選框按照置信度進行排序,然后從置信度最高的候選框開始,將與其重疊度高于閾值的候選框剔除,保留置信度最高的候選框。

- 如上圖所示框出了五個人臉,置信度分別為0.98,0.83,0.75,0.81,0.67,前三個置信度對應左側的Rose,后兩個對應右側的Jack。
- NMS將這五個框根據置信度排序,取出最大的置信度(0.98)的框分別和剩下的框做iou,保留iou小于閾值的框(代碼中閾值設置的是0.3),這樣就剩下0.81和0.67這兩個框了。
- 重復上面的過程,取出置信度(0.81)大的框和剩下的框做iou,保留iou小于閾值的框。這樣最后只剩下0.98和0.81這兩個人臉框了。
代碼實現
P-Net
import torch
from torch import nn"""P-Net
"""class PNet(nn.Module):def __init__(self):super().__init__()self.features_extractor = nn.Sequential(# 第一層卷積nn.Conv2d(in_channels=3, out_channels=10, kernel_size=3, stride=1, padding=0),nn.BatchNorm2d(num_features=10),nn.ReLU(),# 第一層池化nn.MaxPool2d(kernel_size=3,stride=2, padding=1),# 第二層卷積nn.Conv2d(in_channels=10, out_channels=16, kernel_size=3, stride=1, padding=0),nn.BatchNorm2d(num_features=16),nn.ReLU(),# 第三層卷積nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=0),nn.BatchNorm2d(num_features=32),nn.ReLU())# 概率輸出self.cls_out = nn.Conv2d(in_channels=32, out_channels=2, kernel_size=1, stride=1, padding=0)# 回歸量輸出self.reg_out = nn.Conv2d(in_channels=32, out_channels=4, kernel_size=1, stride=1, padding=0)def forward(self, x):print(x.shape)x = self.features_extractor(x)cls_out = self.cls_out(x)reg_out = self.reg_out(x)return cls_out, reg_out
R-Net
import torch
from torch import nnclass RNet(nn.Module):def __init__(self):super().__init__()self.feature_extractor = nn.Sequential(# 第一層卷積 24 x 24nn.Conv2d(in_channels=3, out_channels=28, kernel_size=3, stride=1, padding=0),nn.BatchNorm2d(num_features=28),nn.ReLU(),# 第一層池化 11 x 11nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False),# 第二層卷積 9 x 9nn.Conv2d(in_channels=28, out_channels=48, kernel_size=3, stride=1, padding=0),nn.BatchNorm2d(num_features=48),nn.ReLU(),# 第二層池化 (沒有補零) 4 x 4nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=False),# 第三層卷積 3 x 3nn.Conv2d(in_channels=48, out_channels=64, kernel_size=2, stride=1, padding=0),nn.BatchNorm2d(num_features=64),nn.ReLU(),# 展平nn.Flatten(),# 全連接層 [batch_size, 128]nn.Linear(in_features=3 * 3 * 64, out_features=128))# 概率輸出self.cls_out = nn.Linear(in_features=128, out_features=1)# 回歸量輸出self.reg_out = nn.Linear(in_features=128, out_features=4)def forward(self, x):x = self.feature_extractor(x)cls = self.cls_out(x)reg = self.reg_out(x)return cls, reg
O-Net
import torch
from torch import nnclass ONet(nn.Module):def __init__(self):super().__init__()self.feature_extractor = nn.Sequential(# 第1層卷積 48 x 48nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=0),nn.BatchNorm2d(num_features=32),nn.ReLU(),# 第1層池化 11 x 11nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False),# 第2層卷積 9 x 9nn.Conv2d(in_channels=32, out_channels=64, kernel_size=







)










