前言
傳統的 RAG 方法在處理針對整個文本語料庫的全局性問題時存在不足,例如查詢:“數據中的前 5 個主題是什么?”

對于此類問題,是因為這類問題本質上是查詢聚焦的摘要(Query-Focused Summarization, QFS)任務,而不是傳統的顯式檢索任務。
Graph RAG 通過使用 LLM 構建基于圖的文本索引,從源文檔構建知識圖譜。通過構建知識圖譜,能夠將復雜的、大規模文本數據集轉化為易于理解和操作的知識結構,以便更好地理解實體(如人物、地點、機構等)之間的相互關系。
一、方法
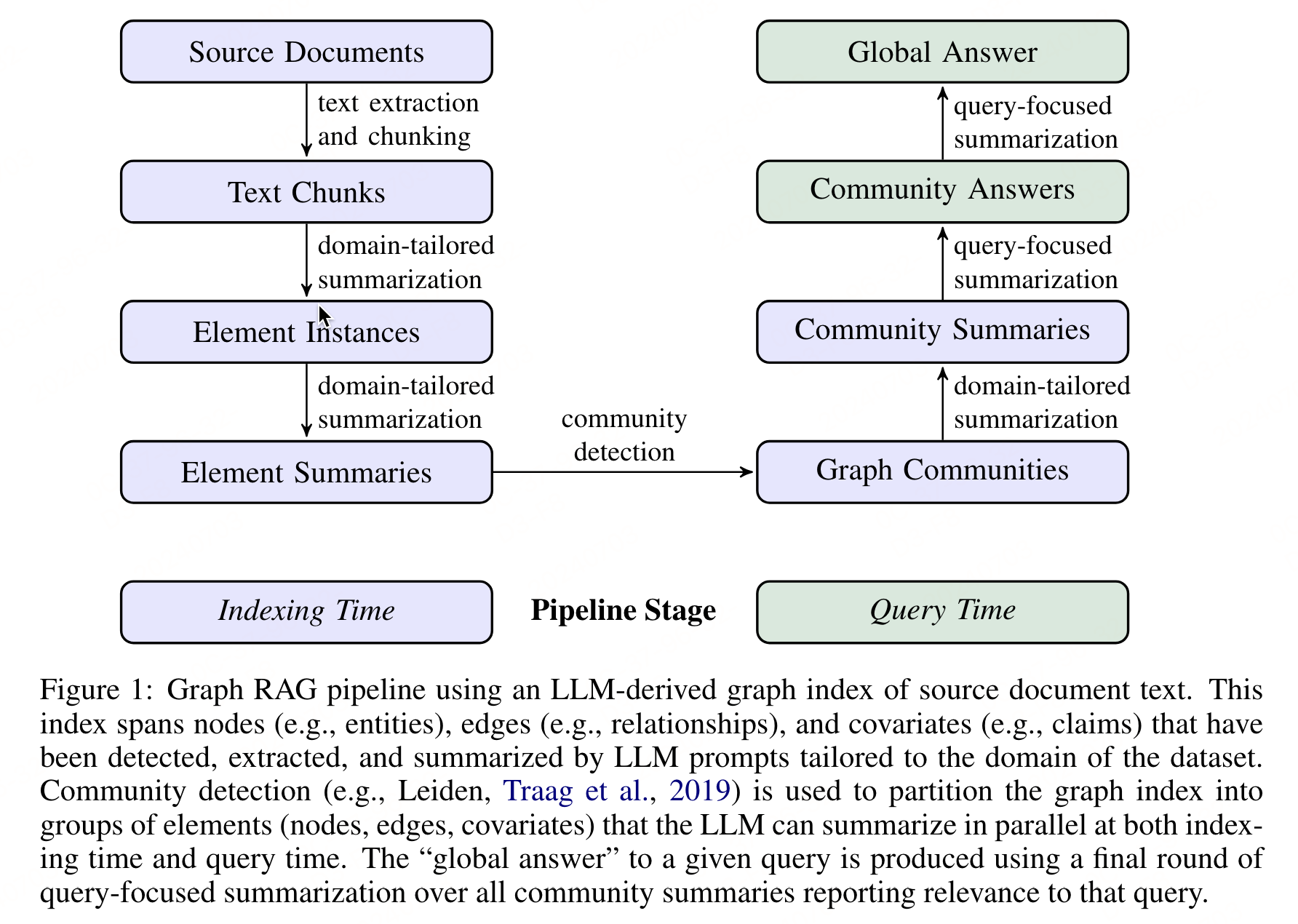
1.1 源文檔分塊
該步驟是 Graph RAG 流程的基礎,它決定了后續構建知識圖譜和生成摘要的質量。主要需要考慮的就是源文檔的分割粒度(《【RAG】Dense X Retrivel:合適的檢索粒度對RAG的重要性(淺看命題粒度的定義及分解方法)》),需要決定輸入文本從源文檔中提取出來后,應該以何種粒度分割成文本塊以供處理。這個決策會影響到后續步驟中 LLM 提取圖索引元素的效率和效果。塊大小的主要影響如下:
-
LLM 上下文窗口:文本塊的長度會影響 LLM 調用的次數以及上下文窗口的召回率(recall)。較長的文本塊可以減少對 LLM 的調用次數,但可能會因為更長的上下文而導致信息提取的召回率下降。
-
召回率與精度的平衡:在提取過程中,需要平衡召回率和精度。較長的文本塊可能提高召回率,但可能會犧牲精度。
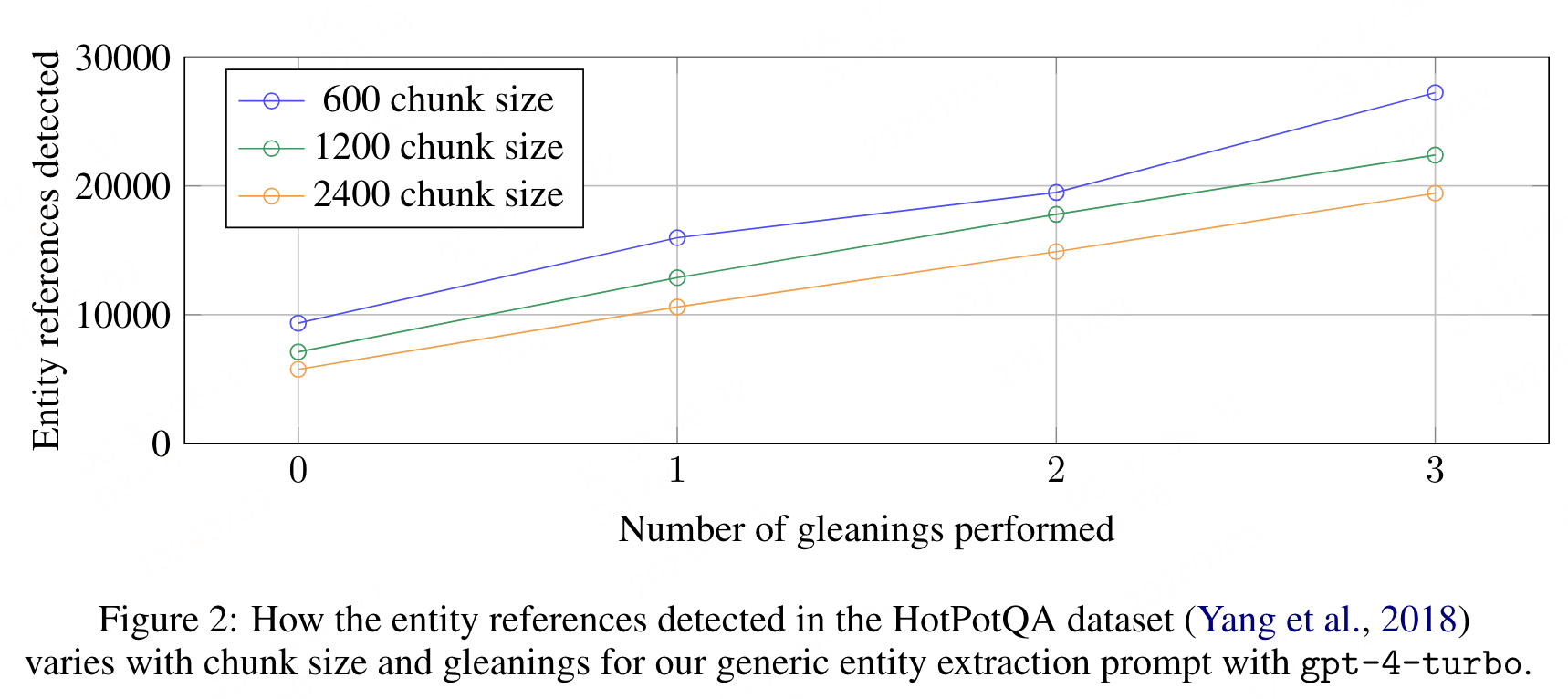
上圖展示了在 HotPotQA 數據集上,使用不同大小的文本塊(600、1200、2400 tokens)和 通用實體提取提示(entity extraction prompt)與 gpt-4-turbo 進行單次提取時,檢測到的實體引用數量的變化。結果表明,使用較小的文本塊(600 tokens)能夠提取出幾乎是使用較大文本塊(2400 tokens)兩倍的實體引用。
1.2 信息抽取(實例提取)
該步驟是構建圖索引的關鍵環節,它確保了從文本數據中提取出有用的結構化信息(KG)(識別并提取源文本中每個文本塊的圖節點和邊的實例),為后續的社區檢測和摘要生成打下了基礎。
方法:
-
KG構建:使用 LLM + prompt 來識別上一步得到的文本塊中的所有實體,包括它們的名稱、類型和描述。然后,識別實體之間的關系,包括源實體、目標實體以及關系的描述。
-
附加協變量提取:除了實體和關系之外,還可以使用次級提取提示來提取與提取的節點實例相關的附加協變量(covariates)。默認的協變量提示旨在提取與檢測到的實體相關的聲明,包括主題、對象、類型、描述、源文本跨度以及開始和結束日期。
-
漏提取兜底:為了平衡效率和質量的需要,使用多輪“gleanings”來鼓勵 LLM 檢測在先前提取輪次中可能遺漏的任何實體。這是一個多階段過程,首先要求 LLM 評估是否所有實體都已被提取,如果 LLM 響應有遺漏,則使用一個提示來鼓勵 LLM 提取這些遺漏的實體。

上圖中每個圓圈代表一個實體(例如,一個人、一個地點或一個組織),實體大小表示該實體具有的關系數量,顏色表示相似實體的分組。顏色分區是一種建立在圖形結構之上的自下而上的聚類方法,它使我們能夠回答不同抽象層次的問題。
1.3 實例提取->實例摘要
使用 LLM 提取實體、關系和聲明的描述,這本身就是一種抽象摘要的形式。LLM 需要能夠創建獨立有意義的摘要,這些摘要可能暗示了文本中未明確陳述的概念(例如,隱含的關系)。通過摘要化過程,能夠將大量文本信息濃縮成更加簡潔、易于處理的格式,這有助于提高后續處理步驟的效率。并且,在處理長文本時,實例摘要有助于避免信息在大型語言模型的長上下文中被忽略或丟失的問題。
1.4 實例摘要->圖社區
圖模型構建-同質無向加權圖:將實例摘要階段得到的信息構建成一個同質無向加權圖。在這個圖中,實體作為節點,它們之間的關系作為邊。邊的權重可以表示為檢測到的關系實例的歸一化計數,這有助于反映關系的強度或頻率。
社區檢測算法:
- 社區劃分:使用社區檢測算法將圖劃分為多個社區(communities)。這些社區由彼此之間聯系更緊密的節點組成,相對于圖中的其他節點,社區內部的節點之間的連接更為頻繁。
- Leiden算法:文章中特別提到了使用 Leiden 算法進行社區檢測,因為該算法能夠有效地恢復大規模圖的層次社區結構。Leiden 算法考慮了社區的模塊化,能夠提供不同層次的社區劃分。
1.5 圖社區到社區摘要
為每個社區創建報告式的摘要,這些摘要獨立于其他社區,但共同構成了對整個數據集全局結構和語義的理解。社區摘要本身對于理解數據集的全局結構和語義非常有用,可以作為在沒有具體問題時對整個語料庫進行探索和理解的工具。
1.6 社區摘要到社區答案再到全局答案
- 準備社區摘要
隨機分配:社區摘要被隨機打亂并分成預定大小的塊。這樣做是為了保證相關信息分散在不同的上下文窗口中,而不是集中在一個窗口中,從而避免了信息的潛在丟失。 - 生成中間答案(Map社區答案)
- 并行生成:對于每個社區摘要塊,LLM 被用來并行生成中間答案。同時,LLM 還被要求為生成的答案生成一個0到100之間的有用性得分,以指示生成的答案對目標問題的有用程度。
- 過濾:得分為0的答案將被過濾掉,因為它們對回答問題沒有幫助。
- 匯總成全局答案(Reduce到全局答案)
- 排序和匯總:根據有用性得分,將中間社區答案按降序排序,并將它們逐步添加到一個新的上下文窗口中,直到達到令牌限制。
- 生成最終答案:當所有相關的部分答案都被考慮后,最終的上下文窗口被用來生成返回給用戶的全局答案。
二、實驗
原文使用了兩個大規模數據集來驗證Graph RAG方法的有效性:一個包含1669個文本塊的播客轉錄數據集(約100萬個token)和一個包含3197個文本塊的新聞文章數據集(約170萬個token)。相當于10本小說。
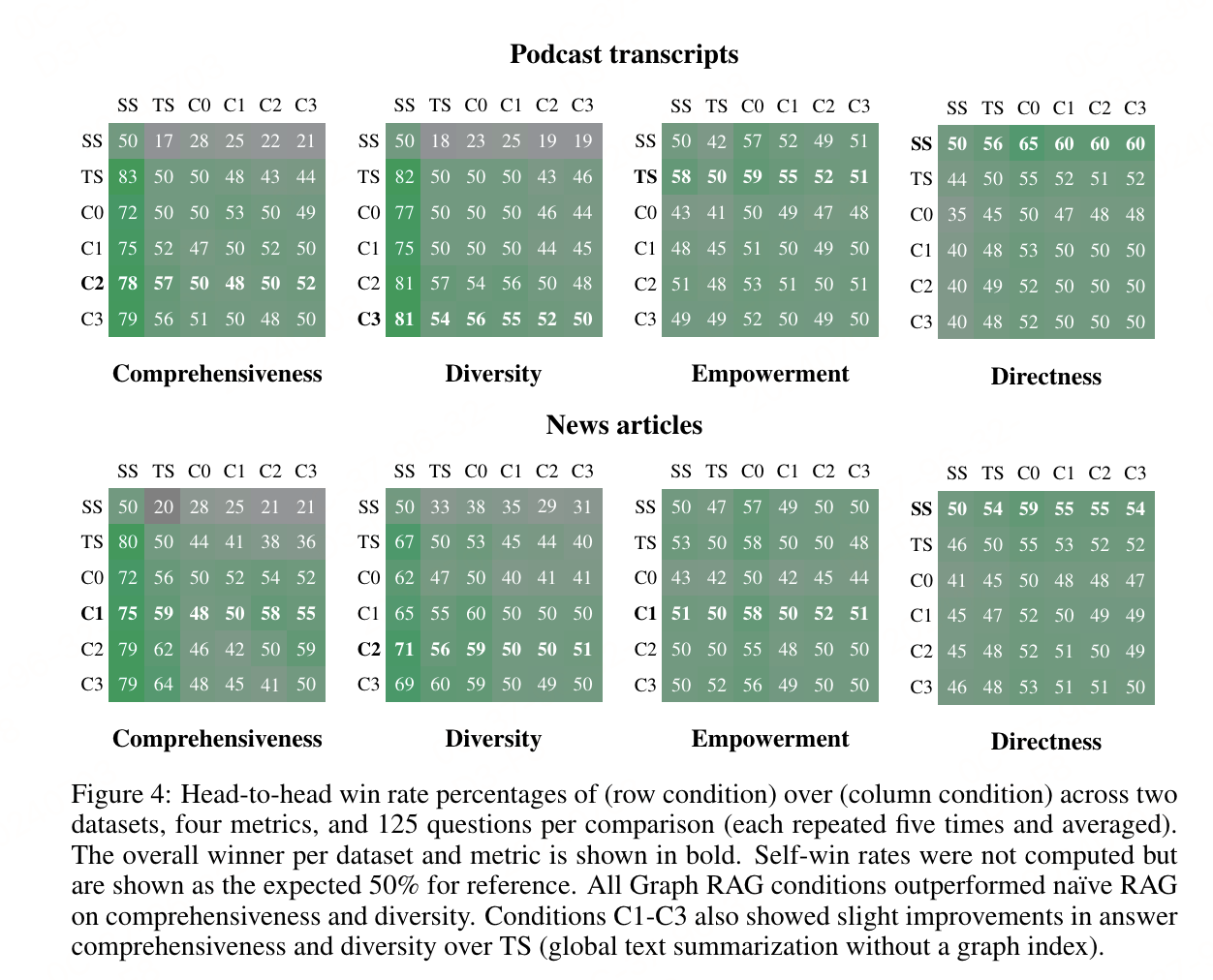
通過與naive RAG和全局文本摘要方法的比較,GraphRAG在全面性和多樣性上優勢明顯,尤其是在使用8k tokens上下文窗口時,測試的最小上下文窗口大小(8k)在所有比較中普遍表現更好,尤其是在全面性上(平均勝率為58.1%),同時在多樣性(平均勝率=52.4%)和授權性(平均勝率=51.3%)上與更大的上下文尺寸表現相當。
還有一個私有數據集上的實驗,鏈接如下:
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
參考文獻
-
私有數據集實驗:https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
-
paper:From Local to Global: A Graph RAG Approach to Query-Focused Summarization,https://arxiv.org/pdf/2404.16130
-
代碼已開源:https://github.com/microsoft/graphrag





)











)

