Redis原理篇
1、原理篇-Redis數據結構
1.1 Redis數據結構-動態字符串
我們都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可見字符串是Redis中最常用的一種數據結構。
不過Redis沒有直接使用C語言中的字符串,因為C語言字符串存在很多問題: 獲取字符串長度的需要通過運算 非二進制安全 不可修改 Redis構建了一種新的字符串結構,稱為簡單動態字符串(Simple Dynamic String),簡稱SDS。 例如,我們執行命令:

那么Redis將在底層創建兩個SDS,其中一個是包含“name”的SDS,另一個是包含“虎哥”的SDS。
Redis是C語言實現的,其中SDS是一個結構體,源碼如下:

例如,一個包含字符串“name”的sds結構如下:

SDS之所以叫做動態字符串,是因為它具備動態擴容的能力,例如一個內容為“hi”的SDS:

假如我們要給SDS追加一段字符串“,Amy”,這里首先會申請新內存空間:
如果新字符串小于1M,則新空間為擴展后字符串長度的兩倍+1;
如果新字符串大于1M,則新空間為擴展后字符串長度+1M+1。稱為內存預分配。


1.2 Redis數據結構-intset
IntSet是Redis中set集合的一種實現方式,基于整數數組來實現,并且具備長度可變、有序等特征。 結構如下:

其中的encoding包含三種模式,表示存儲的整數大小不同:

為了方便查找,Redis會將intset中所有的整數按照升序依次保存在contents數組中,結構如圖:
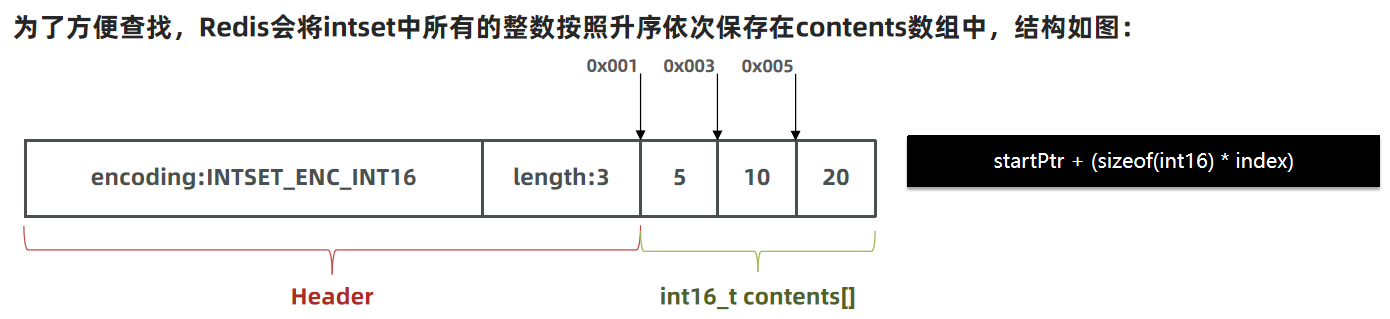
現在,數組中每個數字都在int16_t的范圍內,因此采用的編碼方式是INTSET_ENC_INT16,每部分占用的字節大小為: encoding:4字節 length:4字節 contents:2字節 * 3 = 6字節

我們向該其中添加一個數字:50000,這個數字超出了int16_t的范圍,intset會自動升級編碼方式到合適的大小。 以當前案例來說流程如下:
- 升級編碼為INTSET_ENC_INT32, 每個整數占4字節,并按照新的編碼方式及元素個數擴容數組
- 倒序依次將數組中的元素拷貝到擴容后的正確位置
- 將待添加的元素放入數組末尾
- 最后,將inset的encoding屬性改為INTSET_ENC_INT32,將length屬性改為4

源碼如下:


小總結:
Intset可以看做是特殊的整數數組,具備一些特點:
- Redis會確保Intset中的元素唯一、有序
- 具備類型升級機制,可以節省內存空間
- 底層采用二分查找方式來查詢
1.3 Redis數據結構-Dict
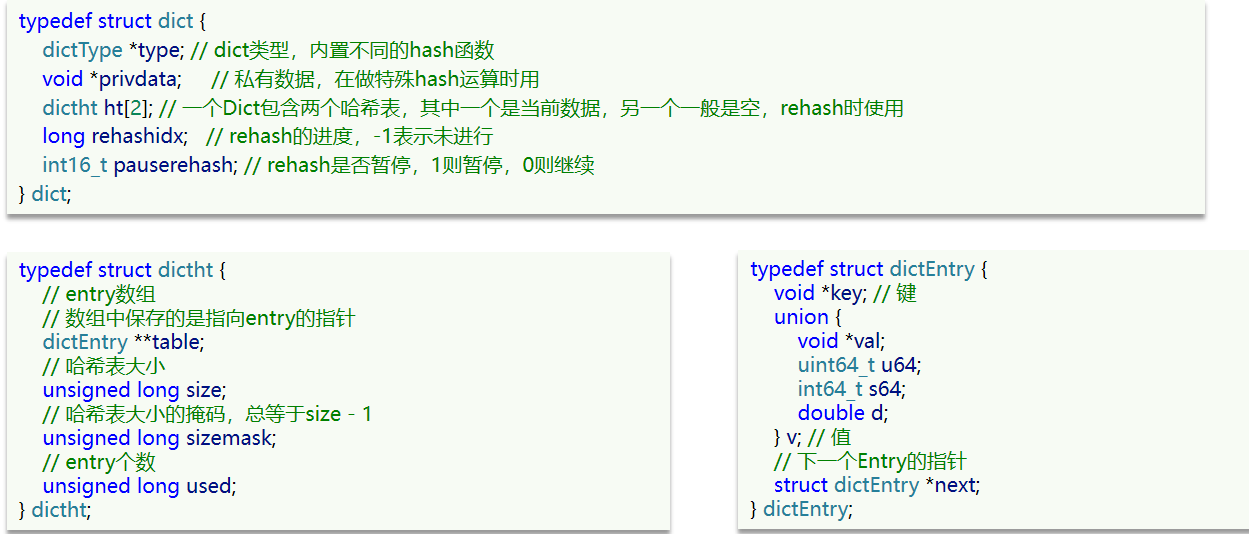
我們知道Redis是一個鍵值型(Key-Value Pair)的數據庫,我們可以根據鍵實現快速的增刪改查。而鍵與值的映射關系正是通過Dict來實現的。 Dict由三部分組成,分別是:哈希表(DictHashTable)、哈希節點(DictEntry)、字典(Dict)

當我們向Dict添加鍵值對時,Redis首先根據key計算出hash值(h),然后利用 h & sizemask來計算元素應該存儲到數組中的哪個索引位置。我們存儲k1=v1,假設k1的哈希值h =1,則1&3 =1,因此k1=v1要存儲到數組角標1位置。

Dict由三部分組成,分別是:哈希表(DictHashTable)、哈希節點(DictEntry)、字典(Dict)


Dict的擴容
Dict中的HashTable就是數組結合單向鏈表的實現,當集合中元素較多時,必然導致哈希沖突增多,鏈表過長,則查詢效率會大大降低。 Dict在每次新增鍵值對時都會檢查負載因子(LoadFactor = used/size) ,滿足以下兩種情況時會觸發哈希表擴容: 哈希表的 LoadFactor >= 1,并且服務器沒有執行 BGSAVE 或者 BGREWRITEAOF 等后臺進程; 哈希表的 LoadFactor > 5 ;


Dict的rehash
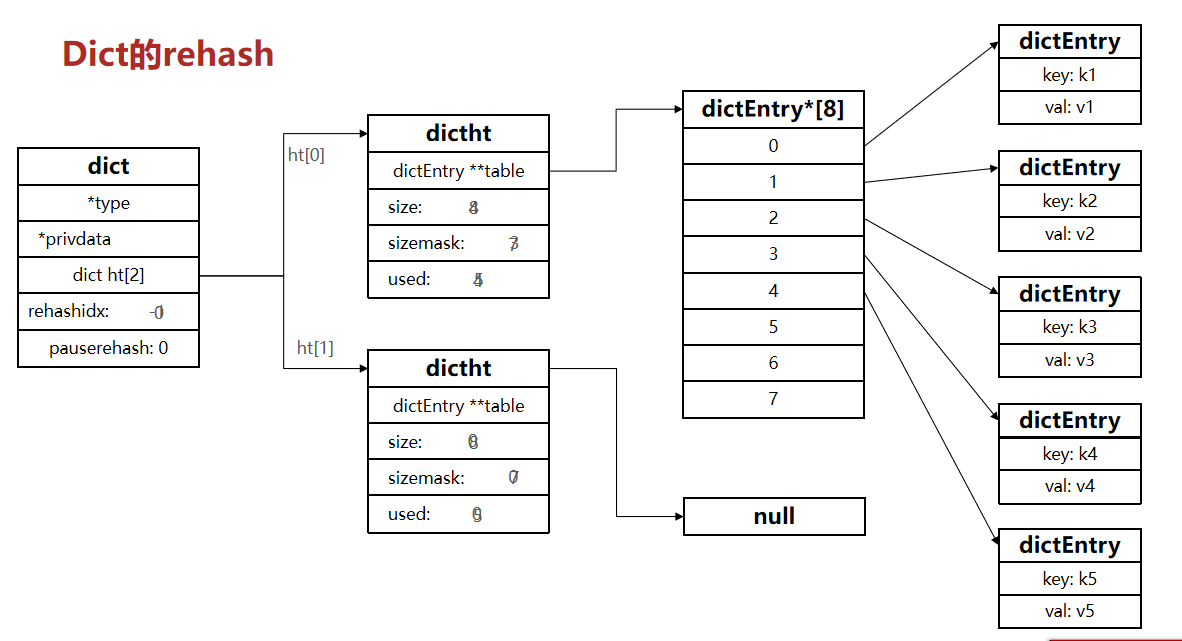
不管是擴容還是收縮,必定會創建新的哈希表,導致哈希表的size和sizemask變化,而key的查詢與sizemask有關。因此必須對哈希表中的每一個key重新計算索引,插入新的哈希表,這個過程稱為rehash。過程是這樣的:
-
計算新hash表的realeSize,值取決于當前要做的是擴容還是收縮:
- 如果是擴容,則新size為第一個大于等于dict.ht[0].used + 1的2^n
- 如果是收縮,則新size為第一個大于等于dict.ht[0].used的2^n (不得小于4)
-
按照新的realeSize申請內存空間,創建dictht,并賦值給dict.ht[1]
-
設置dict.rehashidx = 0,標示開始rehash
-
將dict.ht[0]中的每一個dictEntry都rehash到dict.ht[1]
-
將dict.ht[1]賦值給dict.ht[0],給dict.ht[1]初始化為空哈希表,釋放原來的dict.ht[0]的內存
-
將rehashidx賦值為-1,代表rehash結束
-
在rehash過程中,新增操作,則直接寫入ht[1],查詢、修改和刪除則會在dict.ht[0]和dict.ht[1]依次查找并執行。這樣可以確保ht[0]的數據只減不增,隨著rehash最終為空
整個過程可以描述成:
小總結:
Dict的結構:
- 類似java的HashTable,底層是數組加鏈表來解決哈希沖突
- Dict包含兩個哈希表,ht[0]平常用,ht[1]用來rehash
Dict的伸縮:
- 當LoadFactor大于5或者LoadFactor大于1并且沒有子進程任務時,Dict擴容
- 當LoadFactor小于0.1時,Dict收縮
- 擴容大小為第一個大于等于used + 1的2^n
- 收縮大小為第一個大于等于used 的2^n
- Dict采用漸進式rehash,每次訪問Dict時執行一次rehash
- rehash時ht[0]只減不增,新增操作只在ht[1]執行,其它操作在兩個哈希表
1.4 Redis數據結構-ZipList
ZipList 是一種特殊的“雙端鏈表” ,由一系列特殊編碼的連續內存塊組成。可以在任意一端進行壓入/彈出操作, 并且該操作的時間復雜度為 O(1)。


| 屬性 | 類型 | 長度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字節 | 記錄整個壓縮列表占用的內存字節數 |
| zltail | uint32_t | 4 字節 | 記錄壓縮列表表尾節點距離壓縮列表的起始地址有多少字節,通過這個偏移量,可以確定表尾節點的地址。 |
| zllen | uint16_t | 2 字節 | 記錄了壓縮列表包含的節點數量。 最大值為UINT16_MAX (65534),如果超過這個值,此處會記錄為65535,但節點的真實數量需要遍歷整個壓縮列表才能計算得出。 |
| entry | 列表節點 | 不定 | 壓縮列表包含的各個節點,節點的長度由節點保存的內容決定。 |
| zlend | uint8_t | 1 字節 | 特殊值 0xFF (十進制 255 ),用于標記壓縮列表的末端。 |
ZipListEntry
ZipList 中的Entry并不像普通鏈表那樣記錄前后節點的指針,因為記錄兩個指針要占用16個字節,浪費內存。而是采用了下面的結構:

-
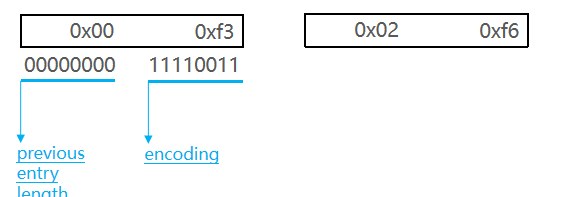
previous_entry_length:前一節點的長度,占1個或5個字節。
- 如果前一節點的長度小于254字節,則采用1個字節來保存這個長度值
- 如果前一節點的長度大于254字節,則采用5個字節來保存這個長度值,第一個字節為0xfe,后四個字節才是真實長度數據
-
encoding:編碼屬性,記錄content的數據類型(字符串還是整數)以及長度,占用1個、2個或5個字節
-
contents:負責保存節點的數據,可以是字符串或整數
ZipList中所有存儲長度的數值均采用小端字節序,即低位字節在前,高位字節在后。例如:數值0x1234,采用小端字節序后實際存儲值為:0x3412
Encoding編碼
ZipListEntry中的encoding編碼分為字符串和整數兩種: 字符串:如果encoding是以“00”、“01”或者“10”開頭,則證明content是字符串
| 編碼 | 編碼長度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我們要保存字符串:“ab”和 “bc”

ZipListEntry中的encoding編碼分為字符串和整數兩種:
- 整數:如果encoding是以“11”開始,則證明content是整數,且encoding固定只占用1個字節
| 編碼 | 編碼長度 | 整數類型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24位有符整數(3 bytes) |
| 11111110 | 1 | 8位有符整數(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存數值,范圍從0001~1101,減1后結果為實際值 |

1.5 Redis數據結構-ZipList的連鎖更新問題
ZipList的每個Entry都包含previous_entry_length來記錄上一個節點的大小,長度是1個或5個字節: 如果前一節點的長度小于254字節,則采用1個字節來保存這個長度值 如果前一節點的長度大于等于254字節,則采用5個字節來保存這個長度值,第一個字節為0xfe,后四個字節才是真實長度數據 現在,假設我們有N個連續的、長度為250~253字節之間的entry,因此entry的previous_entry_length屬性用1個字節即可表示,如圖所示:

ZipList這種特殊情況下產生的連續多次空間擴展操作稱之為連鎖更新(Cascade Update)。新增、刪除都可能導致連鎖更新的發生。
小總結:
ZipList特性:
- 壓縮列表的可以看做一種連續內存空間的"雙向鏈表"
- 列表的節點之間不是通過指針連接,而是記錄上一節點和本節點長度來尋址,內存占用較低
- 如果列表數據過多,導致鏈表過長,可能影響查詢性能
- 增或刪較大數據時有可能發生連續更新問題
1.6 Redis數據結構-QuickList
問題1:ZipList雖然節省內存,但申請內存必須是連續空間,如果內存占用較多,申請內存效率很低。怎么辦?
? 答:為了緩解這個問題,我們必須限制ZipList的長度和entry大小。
問題2:但是我們要存儲大量數據,超出了ZipList最佳的上限該怎么辦?
? 答:我們可以創建多個ZipList來分片存儲數據。
問題3:數據拆分后比較分散,不方便管理和查找,這多個ZipList如何建立聯系?
? 答:Redis在3.2版本引入了新的數據結構QuickList,它是一個雙端鏈表,只不過鏈表中的每個節點都是一個ZipList。

為了避免QuickList中的每個ZipList中entry過多,Redis提供了一個配置項:list-max-ziplist-size來限制。 如果值為正,則代表ZipList的允許的entry個數的最大值 如果值為負,則代表ZipList的最大內存大小,分5種情況:
- -1:每個ZipList的內存占用不能超過4kb
- -2:每個ZipList的內存占用不能超過8kb
- -3:每個ZipList的內存占用不能超過16kb
- -4:每個ZipList的內存占用不能超過32kb
- -5:每個ZipList的內存占用不能超過64kb
其默認值為 -2:

以下是QuickList的和QuickListNode的結構源碼:
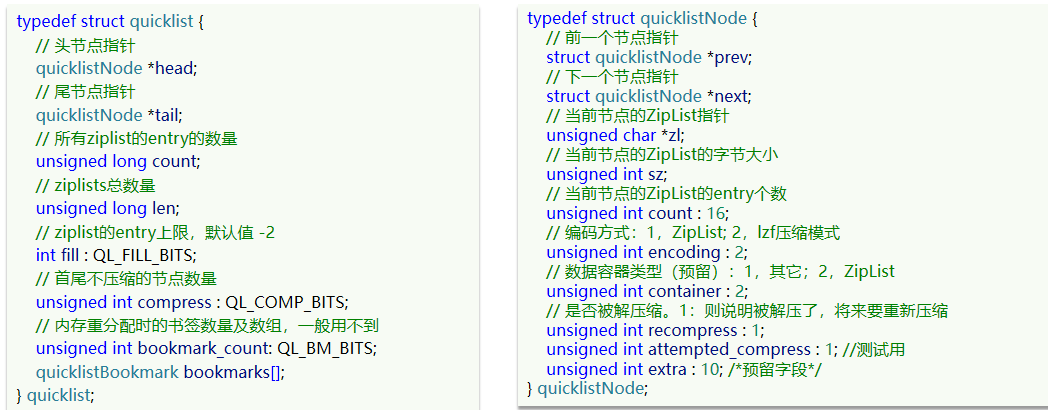
我們接下來用一段流程圖來描述當前的這個結構
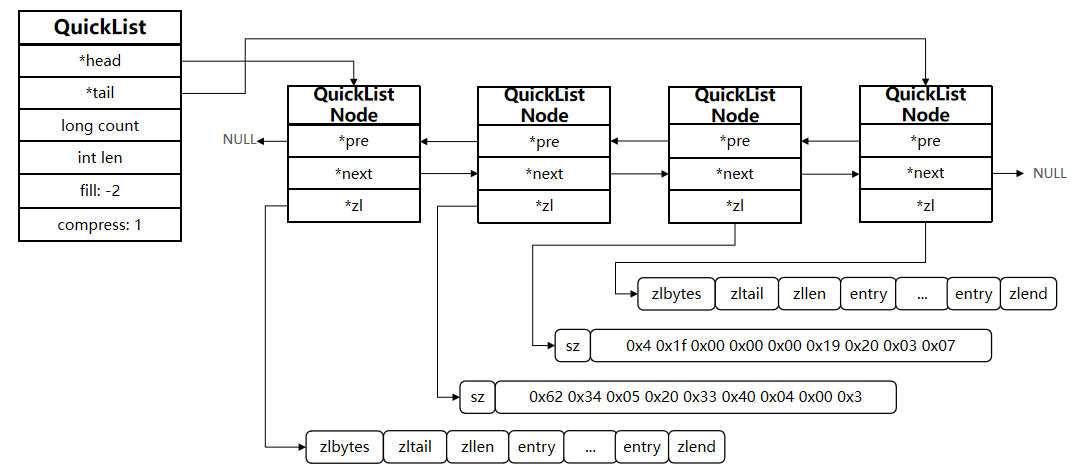
總結:
QuickList的特點:
- 是一個節點為ZipList的雙端鏈表
- 節點采用ZipList,解決了傳統鏈表的內存占用問題
- 控制了ZipList大小,解決連續內存空間申請效率問題
- 中間節點可以壓縮,進一步節省了內存
1.7 Redis數據結構-SkipList
SkipList(跳表)首先是鏈表,但與傳統鏈表相比有幾點差異: 元素按照升序排列存儲 節點可能包含多個指針,指針跨度不同。
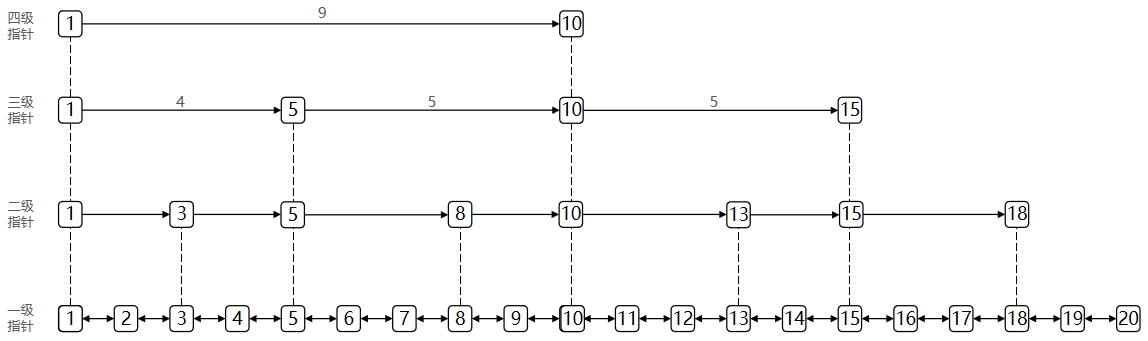
SkipList(跳表)首先是鏈表,但與傳統鏈表相比有幾點差異: 元素按照升序排列存儲 節點可能包含多個指針,指針跨度不同。

SkipList(跳表)首先是鏈表,但與傳統鏈表相比有幾點差異: 元素按照升序排列存儲 節點可能包含多個指針,指針跨度不同。

小總結:
SkipList的特點:
- 跳躍表是一個雙向鏈表,每個節點都包含score和ele值
- 節點按照score值排序,score值一樣則按照ele字典排序
- 每個節點都可以包含多層指針,層數是1到32之間的隨機數
- 不同層指針到下一個節點的跨度不同,層級越高,跨度越大
- 增刪改查效率與紅黑樹基本一致,實現卻更簡單
1.7 Redis數據結構-RedisObject
Redis中的任意數據類型的鍵和值都會被封裝為一個RedisObject,也叫做Redis對象,源碼如下:
1、什么是redisObject: 從Redis的使用者的角度來看,?個Redis節點包含多個database(非cluster模式下默認是16個,cluster模式下只能是1個),而一個database維護了從key space到object space的映射關系。這個映射關系的key是string類型,?value可以是多種數據類型,比如: string, list, hash、set、sorted set等。我們可以看到,key的類型固定是string,而value可能的類型是多個。 ?從Redis內部實現的?度來看,database內的這個映射關系是用?個dict來維護的。dict的key固定用?種數據結構來表達就夠了,這就是動態字符串sds。而value則比較復雜,為了在同?個dict內能夠存儲不同類型的value,這就需要?個通?的數據結構,這個通用的數據結構就是robj,全名是redisObject。

Redis的編碼方式
Redis中會根據存儲的數據類型不同,選擇不同的編碼方式,共包含11種不同類型:
| 編號 | 編碼方式 | 說明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw編碼動態字符串 |
| 1 | OBJ_ENCODING_INT | long類型的整數的字符串 |
| 2 | OBJ_ENCODING_HT | hash表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已廢棄 |
| 4 | OBJ_ENCODING_LINKEDLIST | 雙端鏈表 |
| 5 | OBJ_ENCODING_ZIPLIST | 壓縮列表 |
| 6 | OBJ_ENCODING_INTSET | 整數集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的動態字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
五種數據結構
Redis中會根據存儲的數據類型不同,選擇不同的編碼方式。每種數據類型的使用的編碼方式如下:
| 數據類型 | 編碼方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
1.8 Redis數據結構-String
String是Redis中最常見的數據存儲類型:
其基本編碼方式是RAW,基于簡單動態字符串(SDS)實現,存儲上限為512mb。
如果存儲的SDS長度小于44字節,則會采用EMBSTR編碼,此時object head與SDS是一段連續空間。申請內存時
只需要調用一次內存分配函數,效率更高。
(1)底層實現?式:動態字符串sds 或者 long String的內部存儲結構?般是sds(Simple Dynamic String,可以動態擴展內存),但是如果?個String類型的value的值是數字,那么Redis內部會把它轉成long類型來存儲,從?減少內存的使用。
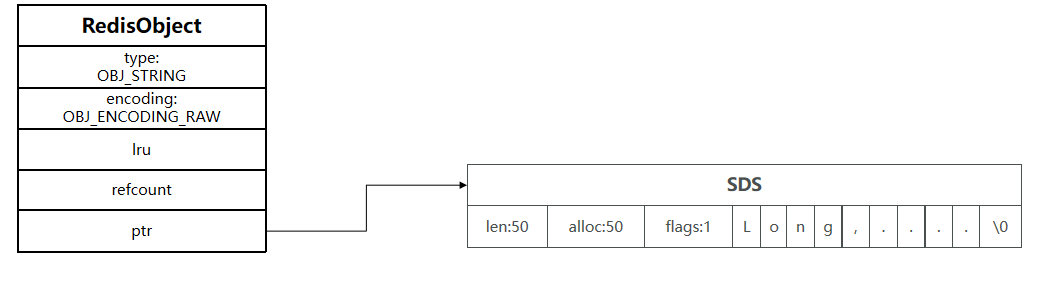
如果存儲的字符串是整數值,并且大小在LONG_MAX范圍內,則會采用INT編碼:直接將數據保存在RedisObject的ptr指針位置(剛好8字節),不再需要SDS了。



確切地說,String在Redis中是??個robj來表示的。
用來表示String的robj可能編碼成3種內部表?:OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT。 其中前兩種編碼使?的是sds來存儲,最后?種OBJ_ENCODING_INT編碼直接把string存成了long型。 在對string進行incr, decr等操作的時候,如果它內部是OBJ_ENCODING_INT編碼,那么可以直接行加減操作;如果它內部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR編碼,那么Redis會先試圖把sds存儲的字符串轉成long型,如果能轉成功,再進行加減操作。對?個內部表示成long型的string執行append, setbit, getrange這些命令,針對的仍然是string的值(即?進制表示的字符串),而不是針對內部表?的long型進?操作。比如字符串”32”,如果按照字符數組來解釋,它包含兩個字符,它們的ASCII碼分別是0x33和0x32。當我們執行命令setbit key 7 0的時候,相當于把字符0x33變成了0x32,這樣字符串的值就變成了”22”。?如果將字符串”32”按照內部的64位long型來解釋,那么它是0x0000000000000020,在這個基礎上執?setbit位操作,結果就完全不對了。因此,在這些命令的實現中,會把long型先轉成字符串再進行相應的操作。
1.9 Redis數據結構-List
Redis的List類型可以從首、尾操作列表中的元素:

哪一個數據結構能滿足上述特征?
- LinkedList :普通鏈表,可以從雙端訪問,內存占用較高,內存碎片較多
- ZipList :壓縮列表,可以從雙端訪問,內存占用低,存儲上限低
- QuickList:LinkedList + ZipList,可以從雙端訪問,內存占用較低,包含多個ZipList,存儲上限高
Redis的List結構類似一個雙端鏈表,可以從首、尾操作列表中的元素:
在3.2版本之前,Redis采用ZipList和LinkedList來實現List,當元素數量小于512并且元素大小小于64字節時采用ZipList編碼,超過則采用LinkedList編碼。
在3.2版本之后,Redis統一采用QuickList來實現List:

2.0 Redis數據結構-Set結構
Set是Redis中的單列集合,滿足下列特點:
- 不保證有序性
- 保證元素唯一
- 求交集、并集、差集

可以看出,Set對查詢元素的效率要求非常高,思考一下,什么樣的數據結構可以滿足? HashTable,也就是Redis中的Dict,不過Dict是雙列集合(可以存鍵、值對)
Set是Redis中的集合,不一定確保元素有序,可以滿足元素唯一、查詢效率要求極高。 為了查詢效率和唯一性,set采用HT編碼(Dict)。Dict中的key用來存儲元素,value統一為null。 當存儲的所有數據都是整數,并且元素數量不超過set-max-intset-entries時,Set會采用IntSet編碼,以節省內存

結構如下:
??

2.1、Redis數據結構-ZSET
ZSet也就是SortedSet,其中每一個元素都需要指定一個score值和member值:
- 可以根據score值排序后
- member必須唯一
- 可以根據member查詢分數

因此,zset底層數據結構必須滿足鍵值存儲、鍵必須唯一、可排序這幾個需求。之前學習的哪種編碼結構可以滿足?
- SkipList:可以排序,并且可以同時存儲score和ele值(member)
- HT(Dict):可以鍵值存儲,并且可以根據key找value

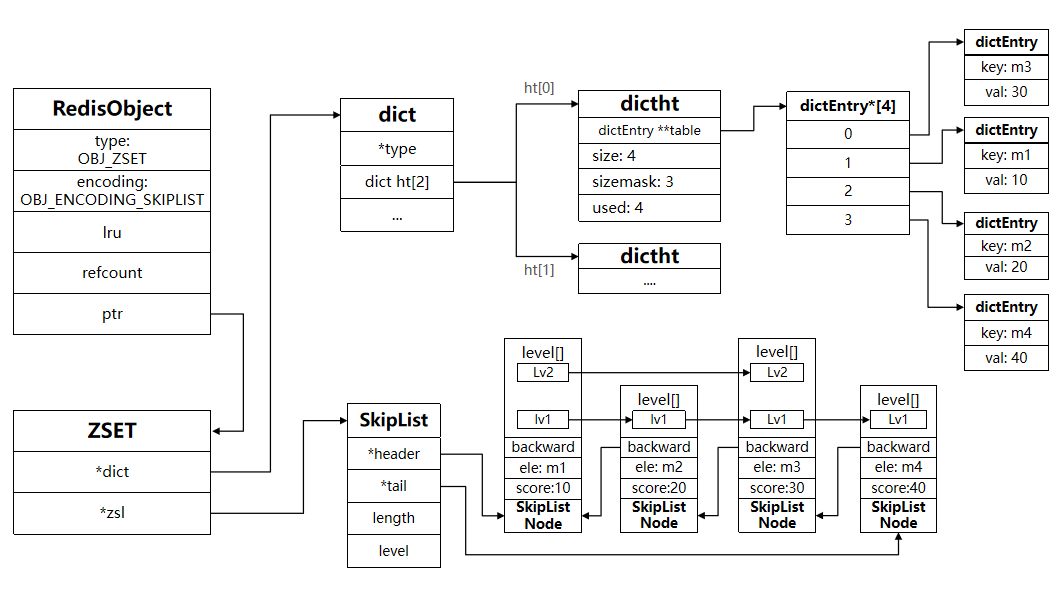
當元素數量不多時,HT和SkipList的優勢不明顯,而且更耗內存。因此zset還會采用ZipList結構來節省內存,不過需要同時滿足兩個條件:
- 元素數量小于zset_max_ziplist_entries,默認值128
- 每個元素都小于zset_max_ziplist_value字節,默認值64
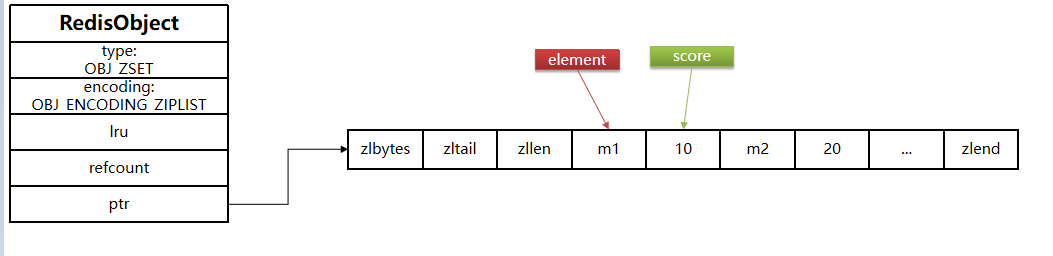
ziplist本身沒有排序功能,而且沒有鍵值對的概念,因此需要有zset通過編碼實現:
- ZipList是連續內存,因此score和element是緊挨在一起的兩個entry, element在前,score在后
- score越小越接近隊首,score越大越接近隊尾,按照score值升序排列

2.2 、Redis數據結構-Hash
Hash結構與Redis中的Zset非常類似:
- 都是鍵值存儲
- 都需求根據鍵獲取值
- 鍵必須唯一
區別如下:
- zset的鍵是member,值是score;hash的鍵和值都是任意值
- zset要根據score排序;hash則無需排序
(1)底層實現方式:壓縮列表ziplist 或者 字典dict 當Hash中數據項比較少的情況下,Hash底層才?壓縮列表ziplist進?存儲數據,隨著數據的增加,底層的ziplist就可能會轉成dict,具體配置如下:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
當滿足上面兩個條件其中之?的時候,Redis就使?dict字典來實現hash。 Redis的hash之所以這樣設計,是因為當ziplist變得很?的時候,它有如下幾個缺點:
- 每次插?或修改引發的realloc操作會有更?的概率造成內存拷貝,從而降低性能。
- ?旦發生內存拷貝,內存拷貝的成本也相應增加,因為要拷貝更?的?塊數據。
- 當ziplist數據項過多的時候,在它上?查找指定的數據項就會性能變得很低,因為ziplist上的查找需要進行遍歷。
總之,ziplist本來就設計為各個數據項挨在?起組成連續的內存空間,這種結構并不擅長做修改操作。?旦數據發?改動,就會引發內存realloc,可能導致內存拷貝。
hash結構如下:
zset集合如下:

因此,Hash底層采用的編碼與Zset也基本一致,只需要把排序有關的SkipList去掉即可:
Hash結構默認采用ZipList編碼,用以節省內存。 ZipList中相鄰的兩個entry 分別保存field和value
當數據量較大時,Hash結構會轉為HT編碼,也就是Dict,觸發條件有兩個:
- ZipList中的元素數量超過了hash-max-ziplist-entries(默認512)
- ZipList中的任意entry大小超過了hash-max-ziplist-value(默認64字節)

2、原理篇-Redis網絡模型
2.1 用戶空間和內核態空間
服務器大多都采用Linux系統,這里我們以Linux為例來講解:
ubuntu和Centos 都是Linux的發行版,發行版可以看成對linux包了一層殼,任何Linux發行版,其系統內核都是Linux。我們的應用都需要通過Linux內核與硬件交互

用戶的應用,比如redis,mysql等其實是沒有辦法去執行訪問我們操作系統的硬件的,所以我們可以通過發行版的這個殼子去訪問內核,再通過內核去訪問計算機硬件

計算機硬件包括,如cpu,內存,網卡等等,內核(通過尋址空間)可以操作硬件的,但是內核需要不同設備的驅動,有了這些驅動之后,內核就可以去對計算機硬件去進行 內存管理,文件系統的管理,進程的管理等等

我們想要用戶的應用來訪問,計算機就必須要通過對外暴露的一些接口,才能訪問到,從而簡介的實現對內核的操控,但是內核本身上來說也是一個應用,所以他本身也需要一些內存,cpu等設備資源,用戶應用本身也在消耗這些資源,如果不加任何限制,用戶去操作隨意的去操作我們的資源,就有可能導致一些沖突,甚至有可能導致我們的系統出現無法運行的問題,因此我們需要把用戶和內核隔離開
進程的尋址空間劃分成兩部分:內核空間、用戶空間
什么是尋址空間呢?我們的應用程序也好,還是內核空間也好,都是沒有辦法直接去物理內存的,而是通過分配一些虛擬內存映射到物理內存中,我們的內核和應用程序去訪問虛擬內存的時候,就需要一個虛擬地址,這個地址是一個無符號的整數,比如一個32位的操作系統,他的帶寬就是32,他的虛擬地址就是2的32次方,也就是說他尋址的范圍就是0~2的32次方, 這片尋址空間對應的就是2的32個字節,就是4GB,這個4GB,會有3個GB分給用戶空間,會有1GB給內核系統
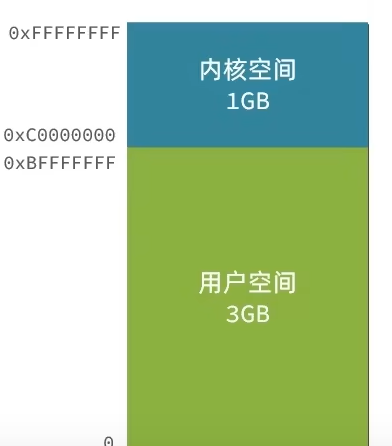
在linux中,他們權限分成兩個等級,0和3,用戶空間只能執行受限的命令(Ring3),而且不能直接調用系統資源,必須通過內核提供的接口來訪問內核空間可以執行特權命令(Ring0),調用一切系統資源,所以一般情況下,用戶的操作是運行在用戶空間,而內核運行的數據是在內核空間的,而有的情況下,一個應用程序需要去調用一些特權資源,去調用一些內核空間的操作,所以此時他倆需要在用戶態和內核態之間進行切換。
比如:
Linux系統為了提高IO效率,會在用戶空間和內核空間都加入緩沖區:
寫數據時,要把用戶緩沖數據拷貝到內核緩沖區,然后寫入設備
讀數據時,要從設備讀取數據到內核緩沖區,然后拷貝到用戶緩沖區
針對這個操作:我們的用戶在寫讀數據時,會去向內核態申請,想要讀取內核的數據,而內核數據要去等待驅動程序從硬件上讀取數據,當從磁盤上加載到數據之后,內核會將數據寫入到內核的緩沖區中,然后再將數據拷貝到用戶態的buffer中,然后再返回給應用程序,整體而言,速度慢,就是這個原因,為了加速,我們希望read也好,還是wait for data也最好都不要等待,或者時間盡量的短。

2.2.網絡模型-阻塞IO
在《UNIX網絡編程》一書中,總結歸納了5種IO模型:
- 阻塞IO(Blocking IO)
- 非阻塞IO(Nonblocking IO)
- IO多路復用(IO Multiplexing)
- 信號驅動IO(Signal Driven IO)
- 異步IO(Asynchronous IO)
應用程序想要去讀取數據,他是無法直接去讀取磁盤數據的,他需要先到內核里邊去等待內核操作硬件拿到數據,這個過程就是1,是需要等待的,等到內核從磁盤上把數據加載出來之后,再把這個數據寫給用戶的緩存區,這個過程是2,如果是阻塞IO,那么整個過程中,用戶從發起讀請求開始,一直到讀取到數據,都是一個阻塞狀態。

具體流程如下圖:
用戶去讀取數據時,會去先發起recvform一個命令,去嘗試從內核上加載數據,如果內核沒有數據,那么用戶就會等待,此時內核會去從硬件上讀取數據,內核讀取數據之后,會把數據拷貝到用戶態,并且返回ok,整個過程,都是阻塞等待的,這就是阻塞IO
總結如下:
顧名思義,阻塞IO就是兩個階段都必須阻塞等待:
階段一:
- 用戶進程嘗試讀取數據(比如網卡數據)
- 此時數據尚未到達,內核需要等待數據
- 此時用戶進程也處于阻塞狀態
階段二:
- 數據到達并拷貝到內核緩沖區,代表已就緒
- 將內核數據拷貝到用戶緩沖區
- 拷貝過程中,用戶進程依然阻塞等待
- 拷貝完成,用戶進程解除阻塞,處理數據
可以看到,阻塞IO模型中,用戶進程在兩個階段都是阻塞狀態。

2.3 網絡模型-非阻塞IO
顧名思義,非阻塞IO的recvfrom操作會立即返回結果而不是阻塞用戶進程。
階段一:
- 用戶進程嘗試讀取數據(比如網卡數據)
- 此時數據尚未到達,內核需要等待數據
- 返回異常給用戶進程
- 用戶進程拿到error后,再次嘗試讀取
- 循環往復,直到數據就緒
階段二:
- 將內核數據拷貝到用戶緩沖區
- 拷貝過程中,用戶進程依然阻塞等待
- 拷貝完成,用戶進程解除阻塞,處理數據
- 可以看到,非阻塞IO模型中,用戶進程在第一個階段是非阻塞,第二個階段是阻塞狀態。雖然是非阻塞,但性能并沒有得到提高。而且忙等機制會導致CPU空轉,CPU使用率暴增。

2.4 網絡模型-IO多路復用
無論是阻塞IO還是非阻塞IO,用戶應用在一階段都需要調用recvfrom來獲取數據,差別在于無數據時的處理方案:
如果調用recvfrom時,恰好沒有數據,阻塞IO會使CPU阻塞,非阻塞IO使CPU空轉,都不能充分發揮CPU的作用。 如果調用recvfrom時,恰好有數據,則用戶進程可以直接進入第二階段,讀取并處理數據
所以怎么看起來以上兩種方式性能都不好
而在單線程情況下,只能依次處理IO事件,如果正在處理的IO事件恰好未就緒(數據不可讀或不可寫),線程就會被阻塞,所有IO事件都必須等待,性能自然會很差。
就比如服務員給顧客點餐,分兩步:
- 顧客思考要吃什么(等待數據就緒)
- 顧客想好了,開始點餐(讀取數據)
要提高效率有幾種辦法?
方案一:增加更多服務員(多線程) 方案二:不排隊,誰想好了吃什么(數據就緒了),服務員就給誰點餐(用戶應用就去讀取數據)
那么問題來了:用戶進程如何知道內核中數據是否就緒呢?
所以接下來就需要詳細的來解決多路復用模型是如何知道到底怎么知道內核數據是否就緒的問題了
這個問題的解決依賴于提出的
文件描述符(File Descriptor):簡稱FD,是一個從0 開始的無符號整數,用來關聯Linux中的一個文件。在Linux中,一切皆文件,例如常規文件、視頻、硬件設備等,當然也包括網絡套接字(Socket)。
通過FD,我們的網絡模型可以利用一個線程監聽多個FD,并在某個FD可讀、可寫時得到通知,從而避免無效的等待,充分利用CPU資源。
階段一:
- 用戶進程調用select,指定要監聽的FD集合
- 核監聽FD對應的多個socket
- 任意一個或多個socket數據就緒則返回readable
- 此過程中用戶進程阻塞
階段二:
- 用戶進程找到就緒的socket
- 依次調用recvfrom讀取數據
- 內核將數據拷貝到用戶空間
- 用戶進程處理數據
當用戶去讀取數據的時候,不再去直接調用recvfrom了,而是調用select的函數,select函數會將需要監聽的數據交給內核,由內核去檢查這些數據是否就緒了,如果說這個數據就緒了,就會通知應用程序數據就緒,然后來讀取數據,再從內核中把數據拷貝給用戶態,完成數據處理,如果N多個FD一個都沒處理完,此時就進行等待。
用IO復用模式,可以確保去讀數據的時候,數據是一定存在的,他的效率比原來的阻塞IO和非阻塞IO性能都要高

IO多路復用是利用單個線程來同時監聽多個FD,并在某個FD可讀、可寫時得到通知,從而避免無效的等待,充分利用CPU資源。不過監聽FD的方式、通知的方式又有多種實現,常見的有:
- select
- poll
- epoll
其中select和pool相當于是當被監聽的數據準備好之后,他會把你監聽的FD整個數據都發給你,你需要到整個FD中去找,哪些是處理好了的,需要通過遍歷的方式,所以性能也并不是那么好
而epoll,則相當于內核準備好了之后,他會把準備好的數據,直接發給你,咱們就省去了遍歷的動作。
2.5 網絡模型-IO多路復用-select方式
select是Linux最早是由的I/O多路復用技術:
簡單說,就是我們把需要處理的數據封裝成FD,然后在用戶態時創建一個fd的集合(這個集合的大小是要監聽的那個FD的最大值+1,但是大小整體是有限制的 ),這個集合的長度大小是有限制的,同時在這個集合中,標明出來我們要控制哪些數據,
比如要監聽的數據,是1,2,5三個數據,此時會執行select函數,然后將整個fd發給內核態,內核態會去遍歷用戶態傳遞過來的數據,如果發現這里邊都數據都沒有就緒,就休眠,直到有數據準備好時,就會被喚醒,喚醒之后,再次遍歷一遍,看看誰準備好了,然后再將處理掉沒有準備好的數據,最后再將這個FD集合寫回到用戶態中去,此時用戶態就知道了,奧,有人準備好了,但是對于用戶態而言,并不知道誰處理好了,所以用戶態也需要去進行遍歷,然后找到對應準備好數據的節點,再去發起讀請求,我們會發現,這種模式下他雖然比阻塞IO和非阻塞IO好,但是依然有些麻煩的事情, 比如說頻繁的傳遞fd集合,頻繁的去遍歷FD等問題

2.6 網絡模型-IO多路復用模型-poll模式
poll模式對select模式做了簡單改進,但性能提升不明顯,部分關鍵代碼如下:
IO流程:
- 創建pollfd數組,向其中添加關注的fd信息,數組大小自定義
- 調用poll函數,將pollfd數組拷貝到內核空間,轉鏈表存儲,無上限
- 內核遍歷fd,判斷是否就緒
- 數據就緒或超時后,拷貝pollfd數組到用戶空間,返回就緒fd數量n
- 用戶進程判斷n是否大于0,大于0則遍歷pollfd數組,找到就緒的fd
與select對比:
- select模式中的fd_set大小固定為1024,而pollfd在內核中采用鏈表,理論上無上限
- 監聽FD越多,每次遍歷消耗時間也越久,性能反而會下降

2.7 網絡模型-IO多路復用模型-epoll函數
epoll模式是對select和poll的改進,它提供了三個函數:
第一個是:eventpoll的函數,他內部包含兩個東西
一個是:
1、紅黑樹-> 記錄的事要監聽的FD
2、一個是鏈表->一個鏈表,記錄的是就緒的FD
緊接著調用epoll_ctl操作,將要監聽的數據添加到紅黑樹上去,并且給每個fd設置一個監聽函數,這個函數會在fd數據就緒時觸發,就是準備好了,現在就把fd把數據添加到list_head中去
3、調用epoll_wait函數
就去等待,在用戶態創建一個空的events數組,當就緒之后,我們的回調函數會把數據添加到list_head中去,當調用這個函數的時候,會去檢查list_head,當然這個過程需要參考配置的等待時間,可以等一定時間,也可以一直等, 如果在此過程中,檢查到了list_head中有數據會將數據添加到鏈表中,此時將數據放入到events數組中,并且返回對應的操作的數量,用戶態的此時收到響應后,從events中拿到對應準備好的數據的節點,再去調用方法去拿數據。
小總結:
select模式存在的三個問題:
- 能監聽的FD最大不超過1024
- 每次select都需要把所有要監聽的FD都拷貝到內核空間
- 每次都要遍歷所有FD來判斷就緒狀態
poll模式的問題:
- poll利用鏈表解決了select中監聽FD上限的問題,但依然要遍歷所有FD,如果監聽較多,性能會下降
epoll模式中如何解決這些問題的?
- 基于epoll實例中的紅黑樹保存要監聽的FD,理論上無上限,而且增刪改查效率都非常高
- 每個FD只需要執行一次epoll_ctl添加到紅黑樹,以后每次epol_wait無需傳遞任何參數,無需重復拷貝FD到內核空間
- 利用ep_poll_callback機制來監聽FD狀態,無需遍歷所有FD,因此性能不會隨監聽的FD數量增多而下降
2.8、網絡模型-epoll中的ET和LT
當FD有數據可讀時,我們調用epoll_wait(或者select、poll)可以得到通知。但是事件通知的模式有兩種:
- LevelTriggered:簡稱LT,也叫做水平觸發。只要某個FD中有數據可讀,每次調用epoll_wait都會得到通知。
- EdgeTriggered:簡稱ET,也叫做邊沿觸發。只有在某個FD有狀態變化時,調用epoll_wait才會被通知。
舉個栗子:
- 假設一個客戶端socket對應的FD已經注冊到了epoll實例中
- 客戶端socket發送了2kb的數據
- 服務端調用epoll_wait,得到通知說FD就緒
- 服務端從FD讀取了1kb數據回到步驟3(再次調用epoll_wait,形成循環)
結論
如果我們采用LT模式,因為FD中仍有1kb數據,則第⑤步依然會返回結果,并且得到通知 如果我們采用ET模式,因為第③步已經消費了FD可讀事件,第⑤步FD狀態沒有變化,因此epoll_wait不會返回,數據無法讀取,客戶端響應超時。
2.9 網絡模型-基于epoll的服務器端流程
我們來梳理一下這張圖
服務器啟動以后,服務端會去調用epoll_create,創建一個epoll實例,epoll實例中包含兩個數據
1、紅黑樹(為空):rb_root 用來去記錄需要被監聽的FD
2、鏈表(為空):list_head,用來存放已經就緒的FD
創建好了之后,會去調用epoll_ctl函數,此函數會會將需要監聽的數據添加到rb_root中去,并且對當前這些存在于紅黑樹的節點設置回調函數,當這些被監聽的數據一旦準備完成,就會被調用,而調用的結果就是將紅黑樹的fd添加到list_head中去(但是此時并沒有完成)
3、當第二步完成后,就會調用epoll_wait函數,這個函數會去校驗是否有數據準備完畢(因為數據一旦準備就緒,就會被回調函數添加到list_head中),在等待了一段時間后(可以進行配置),如果等夠了超時時間,則返回沒有數據,如果有,則進一步判斷當前是什么事件,如果是建立連接時間,則調用accept() 接受客戶端socket,拿到建立連接的socket,然后建立起來連接,如果是其他事件,則把數據進行寫出

3.0 、網絡模型-信號驅動
信號驅動IO是與內核建立SIGIO的信號關聯并設置回調,當內核有FD就緒時,會發出SIGIO信號通知用戶,期間用戶應用可以執行其它業務,無需阻塞等待。
階段一:
- 用戶進程調用sigaction,注冊信號處理函數
- 內核返回成功,開始監聽FD
- 用戶進程不阻塞等待,可以執行其它業務
- 當內核數據就緒后,回調用戶進程的SIGIO處理函數
階段二:
- 收到SIGIO回調信號
- 調用recvfrom,讀取
- 內核將數據拷貝到用戶空間
- 用戶進程處理數據

當有大量IO操作時,信號較多,SIGIO處理函數不能及時處理可能導致信號隊列溢出,而且內核空間與用戶空間的頻繁信號交互性能也較低。
3.0.1 異步IO
這種方式,不僅僅是用戶態在試圖讀取數據后,不阻塞,而且當內核的數據準備完成后,也不會阻塞
他會由內核將所有數據處理完成后,由內核將數據寫入到用戶態中,然后才算完成,所以性能極高,不會有任何阻塞,全部都由內核完成,可以看到,異步IO模型中,用戶進程在兩個階段都是非阻塞狀態。

3.0.2 對比
最后用一幅圖,來說明他們之間的區別

3.1 、網絡模型-Redis是單線程的嗎?為什么使用單線程
Redis到底是單線程還是多線程?
- 如果僅僅聊Redis的核心業務部分(命令處理),答案是單線程
- 如果是聊整個Redis,那么答案就是多線程
在Redis版本迭代過程中,在兩個重要的時間節點上引入了多線程的支持:
- Redis v4.0:引入多線程異步處理一些耗時較舊的任務,例如異步刪除命令unlink
- Redis v6.0:在核心網絡模型中引入 多線程,進一步提高對于多核CPU的利用率
因此,對于Redis的核心網絡模型,在Redis 6.0之前確實都是單線程。是利用epoll(Linux系統)這樣的IO多路復用技術在事件循環中不斷處理客戶端情況。
為什么Redis要選擇單線程?
- 拋開持久化不談,Redis是純 內存操作,執行速度非常快,它的性能瓶頸是網絡延遲而不是執行速度,因此多線程并不會帶來巨大的性能提升。
- 多線程會導致過多的上下文切換,帶來不必要的開銷
- 引入多線程會面臨線程安全問題,必然要引入線程鎖這樣的安全手段,實現復雜度增高,而且性能也會大打折扣
3.2 、Redis的單線程模型-Redis單線程和多線程網絡模型變更

當我們的客戶端想要去連接我們服務器,會去先到IO多路復用模型去進行排隊,會有一個連接應答處理器,他會去接受讀請求,然后又把讀請求注冊到具體模型中去,此時這些建立起來的連接,如果是客戶端請求處理器去進行執行命令時,他會去把數據讀取出來,然后把數據放入到client中, clinet去解析當前的命令轉化為redis認識的命令,接下來就開始處理這些命令,從redis中的command中找到這些命令,然后就真正的去操作對應的數據了,當數據操作完成后,會去找到命令回復處理器,再由他將數據寫出。
3、Redis通信協議-RESP協議
Redis是一個CS架構的軟件,通信一般分兩步(不包括pipeline和PubSub):
客戶端(client)向服務端(server)發送一條命令
服務端解析并執行命令,返回響應結果給客戶端
因此客戶端發送命令的格式、服務端響應結果的格式必須有一個規范,這個規范就是通信協議。
而在Redis中采用的是RESP(Redis Serialization Protocol)協議:
Redis 1.2版本引入了RESP協議
Redis 2.0版本中成為與Redis服務端通信的標準,稱為RESP2
Redis 6.0版本中,從RESP2升級到了RESP3協議,增加了更多數據類型并且支持6.0的新特性--客戶端緩存
但目前,默認使用的依然是RESP2協議,也是我們要學習的協議版本(以下簡稱RESP)。
在RESP中,通過首字節的字符來區分不同數據類型,常用的數據類型包括5種:
單行字符串:首字節是 ‘+’ ,后面跟上單行字符串,以CRLF( "\r\n" )結尾。例如返回"OK": "+OK\r\n"
錯誤(Errors):首字節是 ‘-’ ,與單行字符串格式一樣,只是字符串是異常信息,例如:"-Error message\r\n"
數值:首字節是 ‘:’ ,后面跟上數字格式的字符串,以CRLF結尾。例如:":10\r\n"
多行字符串:首字節是 ‘$’ ,表示二進制安全的字符串,最大支持512MB:
如果大小為0,則代表空字符串:"$0\r\n\r\n"
如果大小為-1,則代表不存在:"$-1\r\n"
數組:首字節是 ‘*’,后面跟上數組元素個數,再跟上元素,元素數據類型不限:

3.1、Redis通信協議-基于Socket自定義Redis的客戶端
Redis支持TCP通信,因此我們可以使用Socket來模擬客戶端,與Redis服務端建立連接:
public class Main {static Socket s;static PrintWriter writer;static BufferedReader reader;public static void main(String[] args) {try {// 1.建立連接String host = "192.168.150.101";int port = 6379;s = new Socket(host, port);// 2.獲取輸出流、輸入流writer = new PrintWriter(new OutputStreamWriter(s.getOutputStream(), StandardCharsets.UTF_8));reader = new BufferedReader(new InputStreamReader(s.getInputStream(), StandardCharsets.UTF_8));// 3.發出請求// 3.1.獲取授權 auth 123321sendRequest("auth", "123321");Object obj = handleResponse();System.out.println("obj = " + obj);// 3.2.set name 虎哥sendRequest("set", "name", "虎哥");// 4.解析響應obj = handleResponse();System.out.println("obj = " + obj);// 3.2.set name 虎哥sendRequest("get", "name");// 4.解析響應obj = handleResponse();System.out.println("obj = " + obj);// 3.2.set name 虎哥sendRequest("mget", "name", "num", "msg");// 4.解析響應obj = handleResponse();System.out.println("obj = " + obj);} catch (IOException e) {e.printStackTrace();} finally {// 5.釋放連接try {if (reader != null) reader.close();if (writer != null) writer.close();if (s != null) s.close();} catch (IOException e) {e.printStackTrace();}}}private static Object handleResponse() throws IOException {// 讀取首字節int prefix = reader.read();// 判斷數據類型標示switch (prefix) {case '+': // 單行字符串,直接讀一行return reader.readLine();case '-': // 異常,也讀一行throw new RuntimeException(reader.readLine());case ':': // 數字return Long.parseLong(reader.readLine());case '$': // 多行字符串// 先讀長度int len = Integer.parseInt(reader.readLine());if (len == -1) {return null;}if (len == 0) {return "";}// 再讀數據,讀len個字節。我們假設沒有特殊字符,所以讀一行(簡化)return reader.readLine();case '*':return readBulkString();default:throw new RuntimeException("錯誤的數據格式!");}}private static Object readBulkString() throws IOException {// 獲取數組大小int len = Integer.parseInt(reader.readLine());if (len <= 0) {return null;}// 定義集合,接收多個元素List<Object> list = new ArrayList<>(len);// 遍歷,依次讀取每個元素for (int i = 0; i < len; i++) {list.add(handleResponse());}return list;}// set name 虎哥private static void sendRequest(String ... args) {writer.println("*" + args.length);for (String arg : args) {writer.println("$" + arg.getBytes(StandardCharsets.UTF_8).length);writer.println(arg);}writer.flush();}
}
Copy to clipboardErrorCopied3.2、Redis內存回收-過期key處理
Redis之所以性能強,最主要的原因就是基于內存存儲。然而單節點的Redis其內存大小不宜過大,會影響持久化或主從同步性能。 我們可以通過修改配置文件來設置Redis的最大內存:

當內存使用達到上限時,就無法存儲更多數據了。為了解決這個問題,Redis提供了一些策略實現內存回收:
內存過期策略
在學習Redis緩存的時候我們說過,可以通過expire命令給Redis的key設置TTL(存活時間):
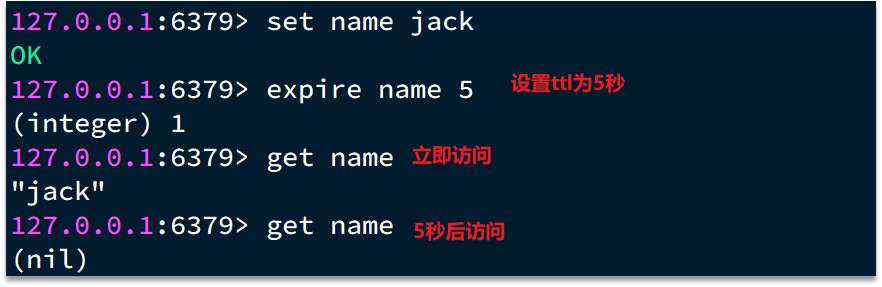
可以發現,當key的TTL到期以后,再次訪問name返回的是nil,說明這個key已經不存在了,對應的內存也得到釋放。從而起到內存回收的目的。
Redis本身是一個典型的key-value內存存儲數據庫,因此所有的key、value都保存在之前學習過的Dict結構中。不過在其database結構體中,有兩個Dict:一個用來記錄key-value;另一個用來記錄key-TTL。
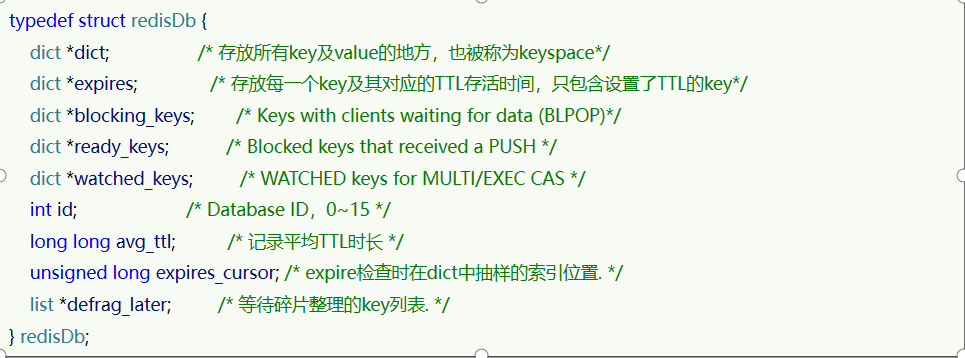

這里有兩個問題需要我們思考: Redis是如何知道一個key是否過期呢?
利用兩個Dict分別記錄key-value對及key-ttl對
是不是TTL到期就立即刪除了呢?
惰性刪除
惰性刪除:顧明思議并不是在TTL到期后就立刻刪除,而是在訪問一個key的時候,檢查該key的存活時間,如果已經過期才執行刪除。

周期刪除
周期刪除:顧明思議是通過一個定時任務,周期性的抽樣部分過期的key,然后執行刪除。執行周期有兩種: Redis服務初始化函數initServer()中設置定時任務,按照server.hz的頻率來執行過期key清理,模式為SLOW Redis的每個事件循環前會調用beforeSleep()函數,執行過期key清理,模式為FAST
周期刪除:顧明思議是通過一個定時任務,周期性的抽樣部分過期的key,然后執行刪除。執行周期有兩種: Redis服務初始化函數initServer()中設置定時任務,按照server.hz的頻率來執行過期key清理,模式為SLOW Redis的每個事件循環前會調用beforeSleep()函數,執行過期key清理,模式為FAST
SLOW模式規則:
- 執行頻率受server.hz影響,默認為10,即每秒執行10次,每個執行周期100ms。
- 執行清理耗時不超過一次執行周期的25%.默認slow模式耗時不超過25ms
- 逐個遍歷db,逐個遍歷db中的bucket,抽取20個key判斷是否過期
- 如果沒達到時間上限(25ms)并且過期key比例大于10%,再進行一次抽樣,否則結束
- FAST模式規則(過期key比例小于10%不執行 ):
- 執行頻率受beforeSleep()調用頻率影響,但兩次FAST模式間隔不低于2ms
- 執行清理耗時不超過1ms
- 逐個遍歷db,逐個遍歷db中的bucket,抽取20個key判斷是否過期 如果沒達到時間上限(1ms)并且過期key比例大于10%,再進行一次抽樣,否則結束
小總結:
RedisKey的TTL記錄方式:
在RedisDB中通過一個Dict記錄每個Key的TTL時間
過期key的刪除策略:
惰性清理:每次查找key時判斷是否過期,如果過期則刪除
定期清理:定期抽樣部分key,判斷是否過期,如果過期則刪除。 定期清理的兩種模式:
SLOW模式執行頻率默認為10,每次不超過25ms
FAST模式執行頻率不固定,但兩次間隔不低于2ms,每次耗時不超過1ms
3.3 Redis內存回收-內存淘汰策略
內存淘汰:就是當Redis內存使用達到設置的上限時,主動挑選部分key刪除以釋放更多內存的流程。Redis會在處理客戶端命令的方法processCommand()中嘗試做內存淘汰:

淘汰策略
Redis支持8種不同策略來選擇要刪除的key:
- noeviction: 不淘汰任何key,但是內存滿時不允許寫入新數據,默認就是這種策略。
- volatile-ttl: 對設置了TTL的key,比較key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:對全體key ,隨機進行淘汰。也就是直接從db->dict中隨機挑選
- volatile-random:對設置了TTL的key ,隨機進行淘汰。也就是從db->expires中隨機挑選。
- allkeys-lru: 對全體key,基于LRU算法進行淘汰
- volatile-lru: 對設置了TTL的key,基于LRU算法進行淘汰
- allkeys-lfu: 對全體key,基于LFU算法進行淘汰
- volatile-lfu: 對設置了TTL的key,基于LFI算法進行淘汰 比較容易混淆的有兩個:
- LRU(Least Recently Used),最少最近使用。用當前時間減去最后一次訪問時間,這個值越大則淘汰優先級越高。
- LFU(Least Frequently Used),最少頻率使用。會統計每個key的訪問頻率,值越小淘汰優先級越高。
Redis的數據都會被封裝為RedisObject結構:

LFU的訪問次數之所以叫做邏輯訪問次數,是因為并不是每次key被訪問都計數,而是通過運算:
- 生成0~1之間的隨機數R
- 計算 (舊次數 * lfu_log_factor + 1),記錄為P
- 如果 R < P ,則計數器 + 1,且最大不超過255
- 訪問次數會隨時間衰減,距離上一次訪問時間每隔 lfu_decay_time 分鐘,計數器 -1
最后用一副圖來描述當前的這個流程吧

4、結束語
親愛的小伙伴們,我們的redis到這里就結束了,希望小伙伴們好好學習,找到一份滿意的工作!傳智為你加油。

)+單片機數碼管基礎)


)



)










