一、研究背景
歐洲經濟長期以來是全球經濟體系中的重要組成部分。無論是在全球金融危機后的復蘇過程中,還是在新冠疫情期間,歐洲經濟的表現都對世界經濟產生了深遠的影響。歐洲各國經濟體之間既存在相似性,也存在顯著的差異。這些差異不僅體現在宏觀經濟指標上,如GDP增長率、通貨膨脹率、失業率等,還體現在政府預算、債務與GDP比例、經常賬戶余額等財務指標上。因此,通過聚類分析和主成分分析(PCA)來研究歐洲各國經濟指標的相似性和差異性,對于深入理解歐洲經濟體系內部的動態和結構具有重要意義。
近年來,全球化進程加速以及歐盟內部一體化的推進,使得歐洲各國經濟之間的聯系日益緊密。然而,各國在經濟政策、產業結構、資源分配等方面仍然存在顯著差異。通過聚類分析,可以將具有相似經濟特征的國家歸為一類,揭示出這些國家在經濟發展中的共同模式。而主成分分析則能夠簡化數據結構,提取出影響歐洲經濟的主要因素,幫助我們更好地理解復雜的經濟現象。
二、研究意義
-
揭示經濟模式:通過聚類分析可以識別出歐洲國家在經濟發展中的不同模式,幫助政策制定者了解不同經濟體的特征,從而制定更有針對性的經濟政策。
-
簡化數據分析:主成分分析能夠降低數據的維度,將多個經濟指標簡化為少數幾個主要成分,這有助于更直觀地理解影響歐洲經濟的關鍵因素,便于進行進一步的經濟分析和預測。
-
支持決策制定:本研究的結果可以為政府和企業提供參考依據,幫助他們在經濟規劃、投資決策和風險管理方面做出更明智的選擇。例如,通過了解哪些國家具有相似的經濟特征,可以在區域合作、市場開發等方面做出更有戰略性的布局。
-
學術貢獻:本研究將豐富聚類分析和主成分分析在經濟研究領域的應用案例,提供一種新的視角來審視歐洲經濟,有助于推動相關學術研究的發展。
三、實證分析
代碼和數據
讀取數據
import numpy as np
import pandas as pd import os
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as snsimport datetimeimport warnings
warnings.filterwarnings('ignore')
df=pd.read_csv('Economy_Indicators.csv')
df.head() ?查看數據類型
?查看數據類型
數據預處理
df=df.replace(' NA',np.nan,regex=True)
df['GDP Quarter-over-Quarterr'] = df['GDP Quarter-over-Quarterr'].astype(float)
df['Interest Rate'] = df['Interest Rate'].astype(float)
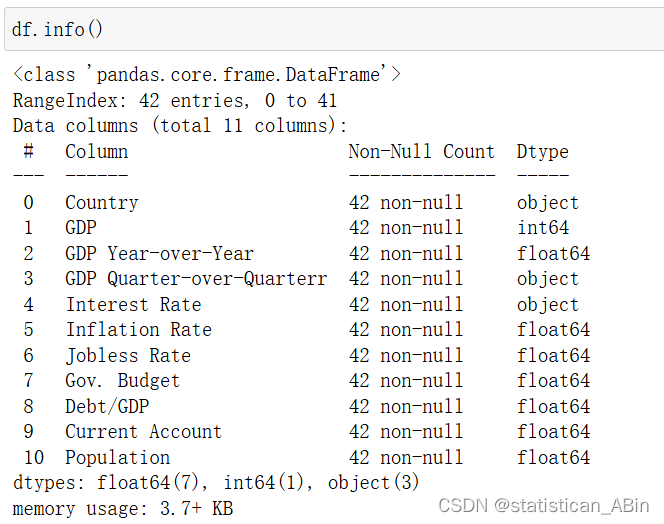
df.info()?
接下來對數據特征可視化
fig = plt.figure(figsize=(15,15))for i in range(len(col)):plt.subplot(4,3,i+1)plt.title(col[i])sns.boxplot(data=df,y=df[col[i]])plt.tight_layout()
plt.show()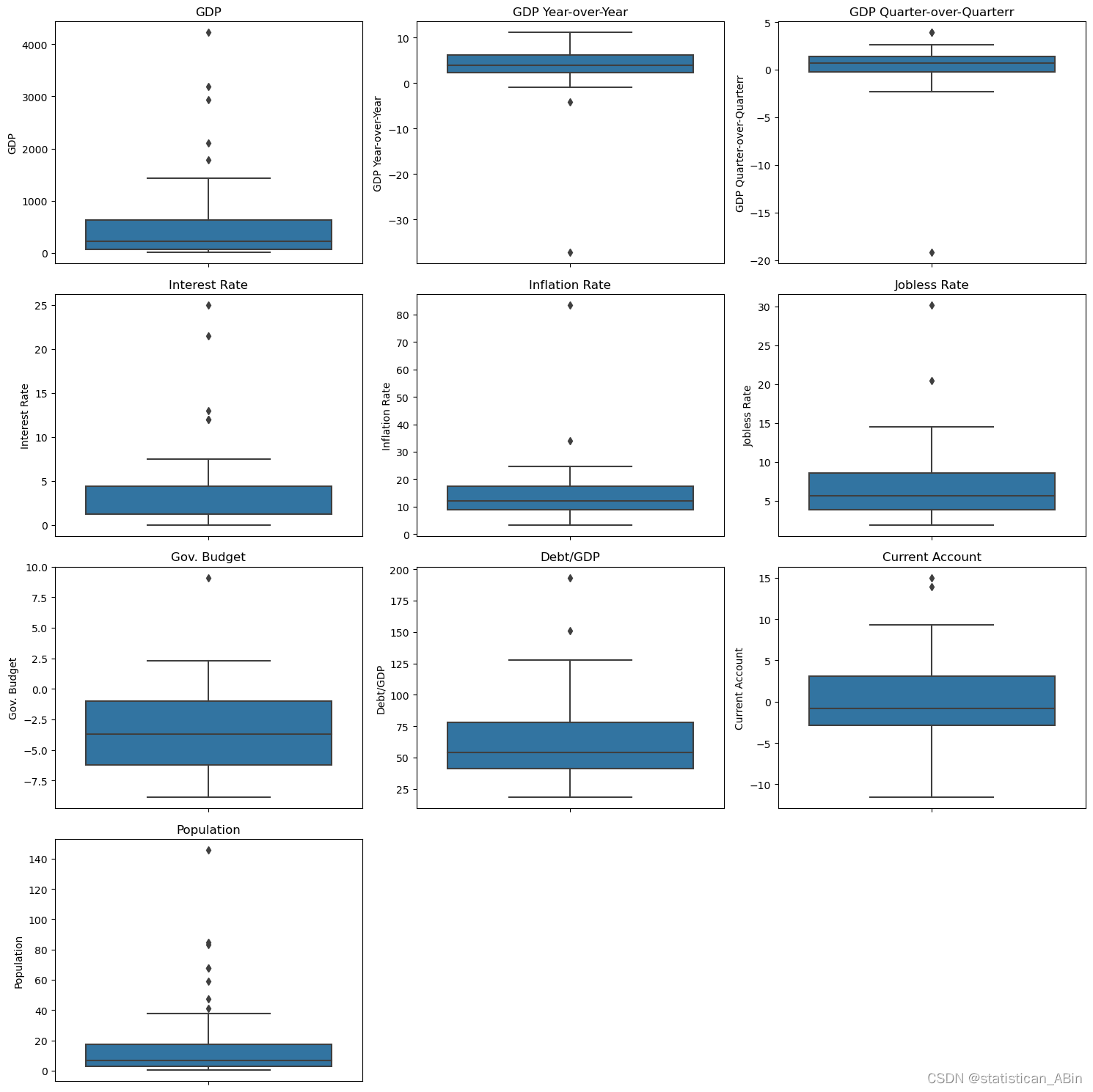
fig = plt.figure(figsize=(15,15))for i in range(len(col)):plt.subplot(4,3,i+1)plt.title(col[i])sns.histplot(data=df,x=df[col[i]])plt.tight_layout()
plt.show()?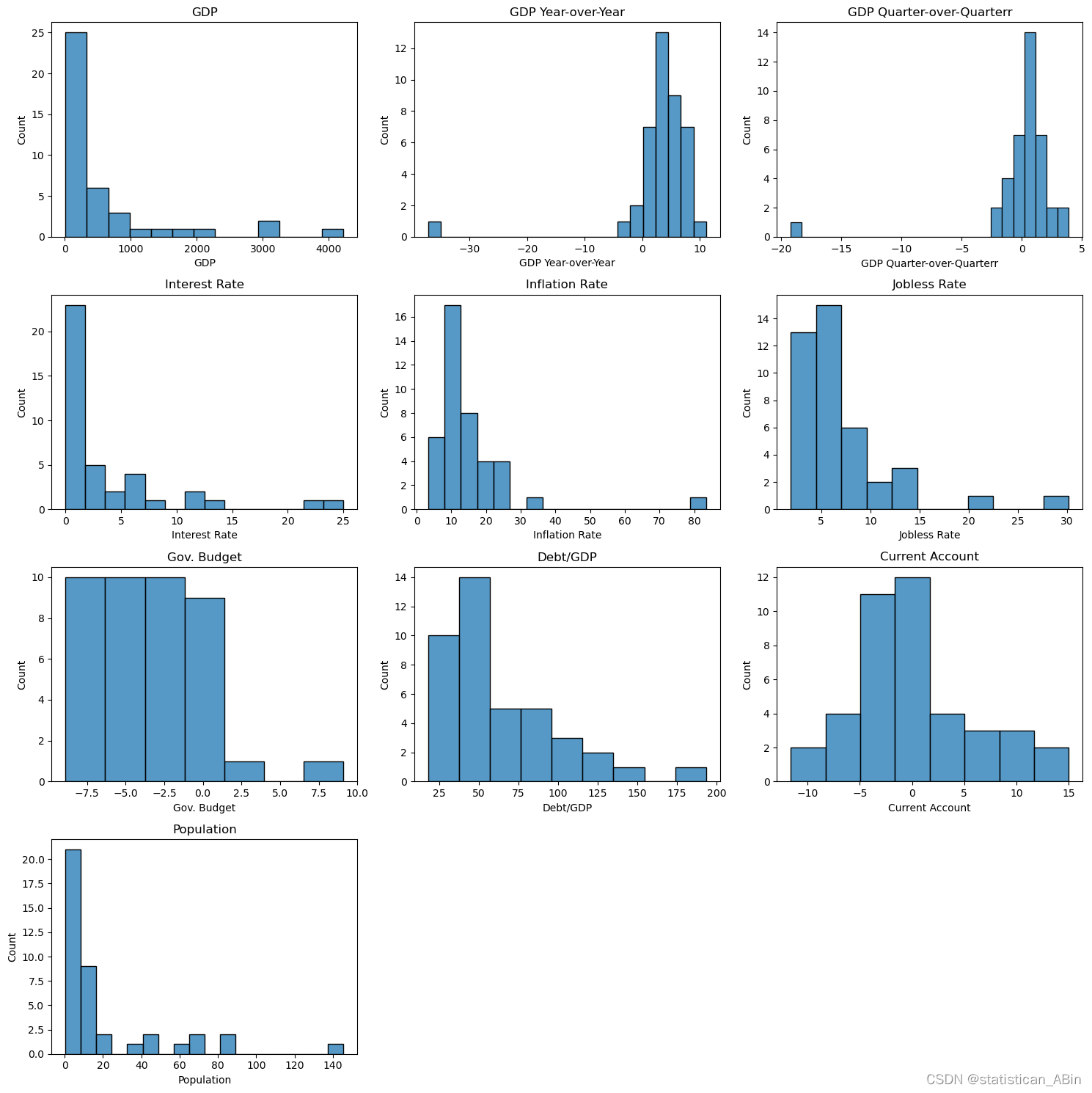
每個特征的最小值和最大值之間的差距都很大。這說明歐洲國家之間的經濟差距很大。
相關系數熱力圖
corr_matrix = numeric_df.corr()plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cbar=False, cmap='Blues', fmt='.1f')
plt.show()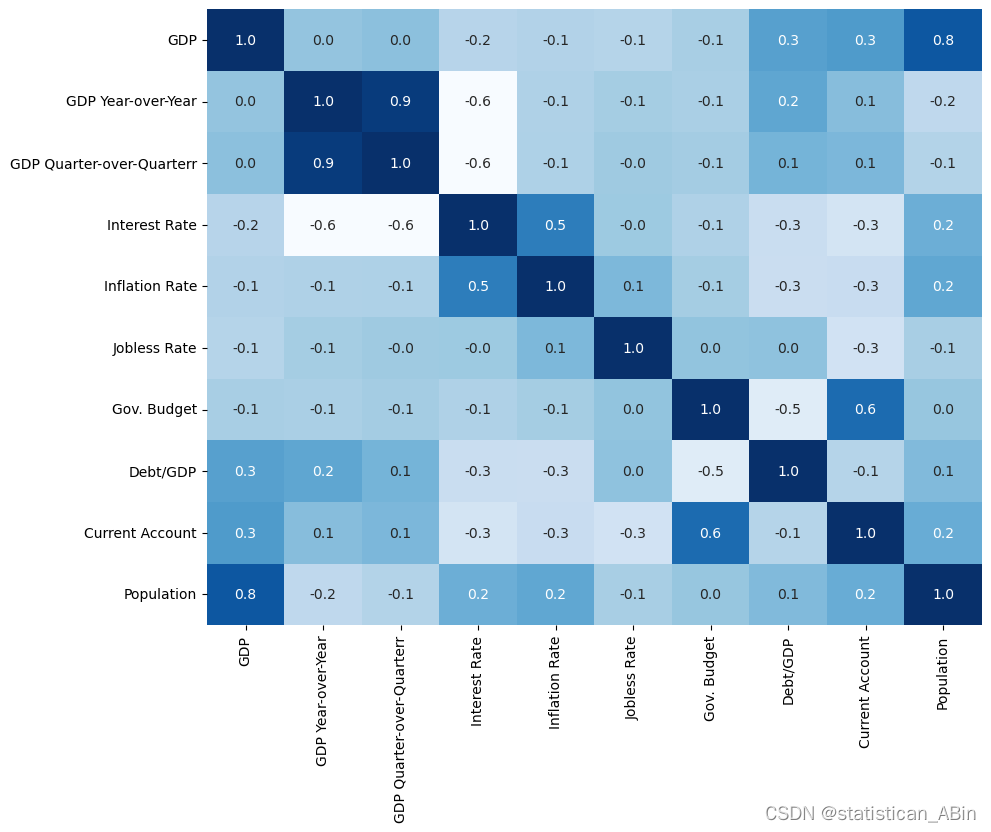
其中,高度正相關 (>=0.5)
國內生產總值與人口:0.8 經常賬戶與政府預算:0.6 利率與通貨膨脹率:0.5 強負相關(<=-0.5)
國內生產總值年度同比與利率:-0.6 國內生產總值季度同比與利率:-0.6 政府預算與債務/GDP : -0.5
?接下來進行聚類分析
添加人均 GDP?
df['GDP_per_Population']=df['GDP']/df['Population']標準化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
df_sc = sc.fit_transform(df1)
df_sc = pd.DataFrame(df_sc, columns=df1.columns)
?首先按 4 個群組進行 KMeans 建模
model = KMeans(n_clusters=4, random_state=1)
model.fit(df_sc)用肘法確定聚類的數量。?
for i in range(1,11):km = KMeans(n_clusters=i,init='k-means++',n_init=10,max_iter=300,random_state=0)km.fit(df_sc)distortions.append(km.inertia_)plt.plot(range(1,11),distortions,marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()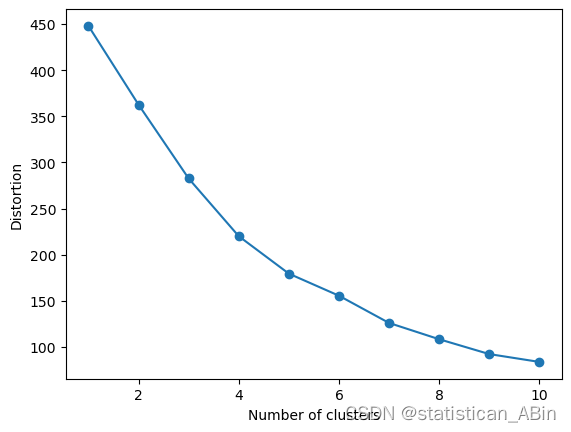
#我們可以將數據分為四個聚類
df['Cluster']=cluster
df.head()
可以看到每個樣本后面都有了聚類數
numeric_df = df.select_dtypes(include=[float, int])
# 將非數值列與 Cluster 列連接起來,以便進行分組
numeric_df['Cluster'] = df['Cluster']
# 按 Cluster 分組并計算均值
grouped_mean = numeric_df.groupby('Cluster').mean()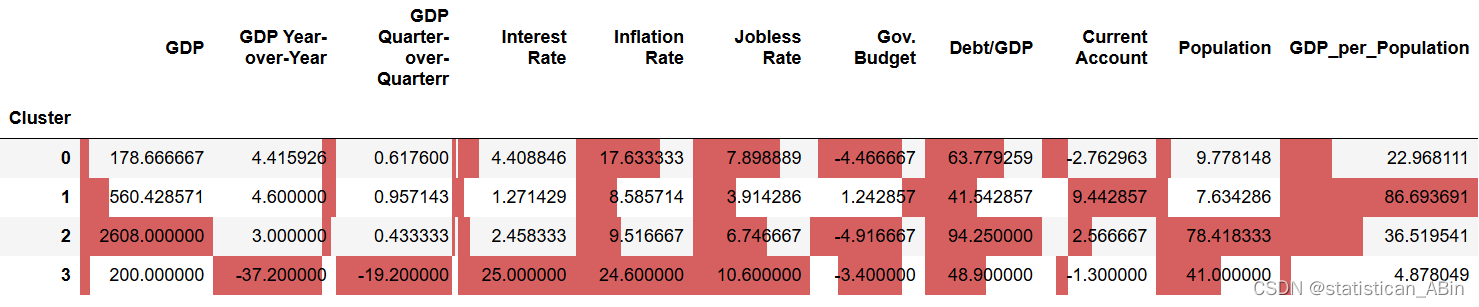
fig = plt.figure(figsize=(15,15))for i in range(len(col2)):plt.subplot(4,3,i+1)plt.title(col2[i])sns.boxplot(data=df,y=df[col2[i]],x=df['Cluster'])plt.tight_layout()
plt.show()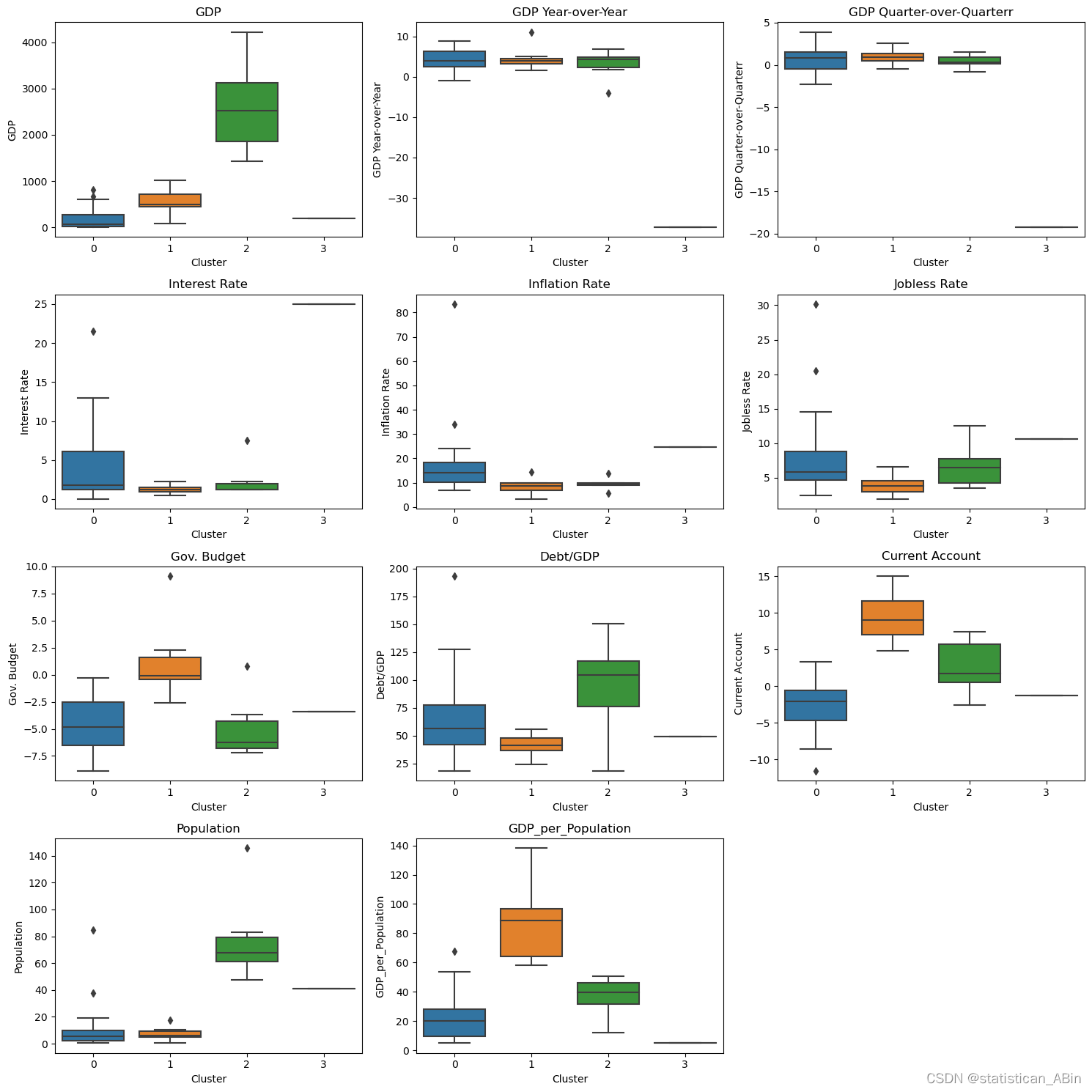
各組之間有一些不同的特點。
查看第0組的國家

第 0 組包括國內生產總值和人口規模不大,但人均國內生產總值較高的國家。

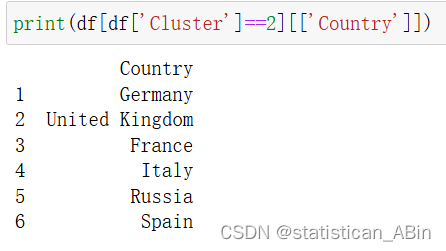
組群 2 包括較大的國內生產總值和較多的人口。
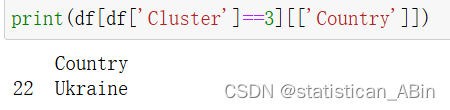
第 3 組只有一個國家,即烏克蘭。烏克蘭的核試驗率最高、通貨膨脹率最高、失業率最高。它的 GDP 年同比和季度同比都是最低的。這顯示了巨大的損失。
接下來進行主成分分析
from sklearn.decomposition import PCA
pca = PCA(n_components=3, random_state=1)
pca.fit(df_sc)
feature = pca.transform(df_sc)grouped_mean = df.groupby('Cluster')[['PCA1', 'PCA2', 'PCA3']].mean().T
# 應用樣式并顯示條形圖
styled_grouped_mean = grouped_mean.style.bar(axis=1)
styled_grouped_mean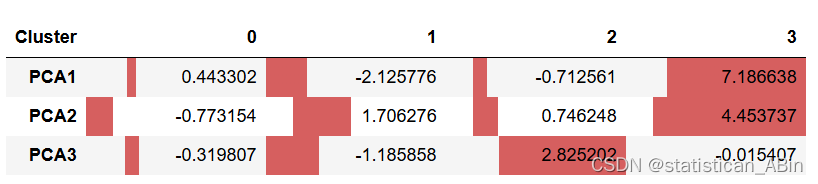
PCA1 在第 1 組中最高,其次是第 2 組。
PCA2 在第 1 組中最高,其次是第 0 組。
PCA3 在第 2 組中最高,其次是第 1 組。

PCA1 在利率方面最高,其次是通貨膨脹率。
PCA2 的最高值是人口,其次是人均國內生產總值(GDP_per_Population)。
PCA3 在 GDP 中最高,其次是人口。
?接下來用3D圖來可視化一下
fig=plt.figure(figsize=(10, 10))
ax = fig.add_subplot(projection='3d')scatter=ax.scatter(df['PCA1'], df['PCA2'],df['PCA3'],alpha=0.8, c=cluster)
ax.set_xlabel('principal component 1')
ax.set_ylabel('principal component 2')
ax.set_zlabel('principal component 3')
plt.legend(handles=scatter.legend_elements()[0], labels=['Cluster0','Cluster1','Cluster2','Cluster3'],title="Cluster",loc='upper left', bbox_to_anchor=(1, 1))
plt.show()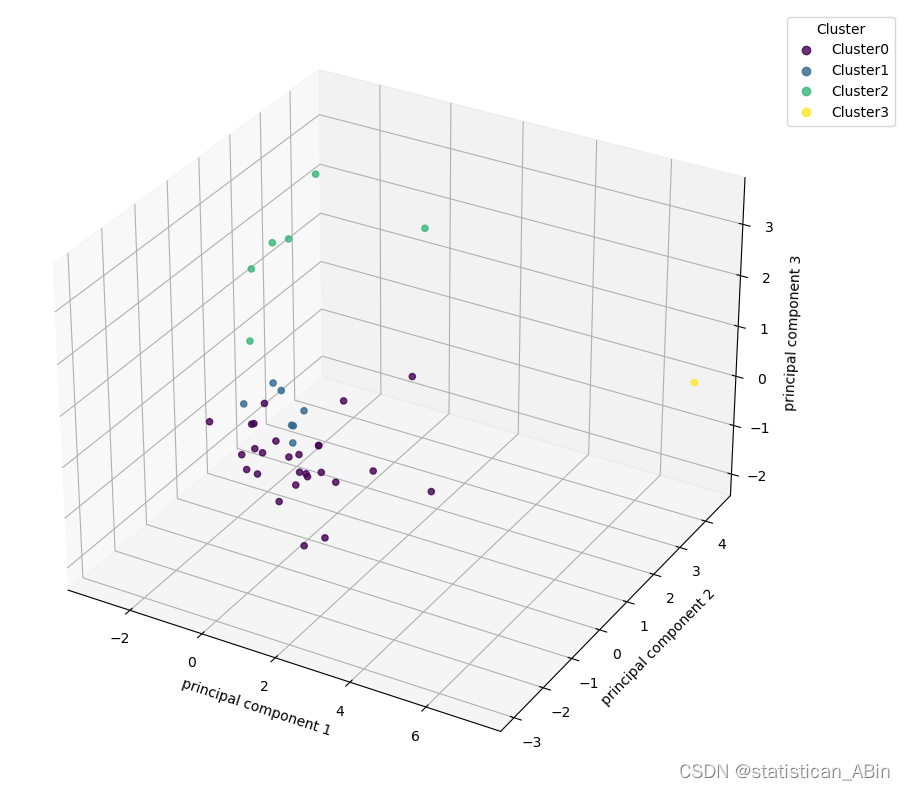 ?接下來再查看一下各個主成分的解釋率
?接下來再查看一下各個主成分的解釋率
pd.DataFrame(pca.explained_variance_ratio_)
PCA1、PCA2 和 PCA3 的解釋率約為 66%。?
四、結論
通過聚類分析和主成分分析,我們對歐洲各國的經濟特征進行了深入研究。聚類分析結果表明,歐洲國家可以根據其經濟指標分為幾個具有相似特征的集群,每個集群內部的國家在GDP增長率、通貨膨脹率、失業率等方面表現出較高的相似性。這表明盡管歐洲整體經濟一體化進程不斷推進,但各國之間仍存在顯著的經濟差異。
主成分分析結果顯示,影響歐洲經濟的主要因素可以歸納為少數幾個主成分,如宏觀經濟增長、通貨膨脹和就業狀況、財政健康狀況等。這些主成分在很大程度上解釋了原始數據的變化,證明了主成分分析在簡化數據和提取關鍵信息方面的有效性。
總體而言,本研究不僅揭示了歐洲各國經濟的內在聯系和差異,還為進一步的經濟分析和政策制定提供了重要的理論和實證依據。未來的研究可以在此基礎上,結合更多的動態數據和更復雜的經濟模型,進一步探索歐洲經濟的發展趨勢和內在機制。 ?
?創作不易,希望大家多點贊關注評論!!!(類似代碼或報告定制可以私信)





)




)



(完))
 同步互斥)



