0 簡介
今天學長向大家介紹LSTM基礎
基于LSTM的預測算法 - 股票預測 天氣預測 房價預測
這是一個較為新穎的競賽課題方向,學長非常推薦!
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate
1 基于 Keras 用 LSTM 網絡做時間序列預測
時間序列預測是一類比較困難的預測問題。
與常見的回歸預測模型不同,輸入變量之間的“序列依賴性”為時間序列問題增加了復雜度。
一種能夠專門用來處理序列依賴性的神經網絡被稱為 遞歸神經網絡(Recurrent Neural
Networks、RNN)。因其訓練時的出色性能,長短記憶網絡(Long Short-Term Memory
Network,LSTM)是深度學習中廣泛使用的一種遞歸神經網絡(RNN)。
在本篇文章中,將介紹如何在 R 中使用 keras 深度學習包構建 LSTM 神經網絡模型實現時間序列預測。
- 如何為基于回歸、窗口法和時間步的時間序列預測問題建立對應的 LSTM 網絡。
- 對于非常長的序列,如何在構建 LSTM 網絡和用 LSTM 網絡做預測時保持網絡關于序列的狀態(記憶)。
2 長短記憶網絡
長短記憶網絡,或 LSTM 網絡,是一種遞歸神經網絡(RNN),通過訓練時在“時間上的反向傳播”來克服梯度消失問題。
LSTM 網絡可以用來構建大規模的遞歸神經網絡來處理機器學習中復雜的序列問題,并取得不錯的結果。
除了神經元之外,LSTM 網絡在神經網絡層級(layers)之間還存在記憶模塊。
一個記憶模塊具有特殊的構成,使它比傳統的神經元更“聰明”,并且可以對序列中的前后部分產生記憶。模塊具有不同的“門”(gates)來控制模塊的狀態和輸出。一旦接收并處理一個輸入序列,模塊中的各個門便使用
S 型的激活單元來控制自身是否被激活,從而改變模塊狀態并向模塊添加信息(記憶)。
一個激活單元有三種門:
- 遺忘門(Forget Gate):決定拋棄哪些信息。
- 輸入門(Input Gate):決定輸入中的哪些值用來更新記憶狀態。
- 輸出門(Output Gate):根據輸入和記憶狀態決定輸出的值。
每一個激活單元就像是一個迷你狀態機,單元中各個門的權重通過訓練獲得。
3 LSTM 網絡結構和原理
long short term memory,即我們所稱呼的LSTM,是為了解決長期以來問題而專門設計出來的,所有的RNN都具有一種重復
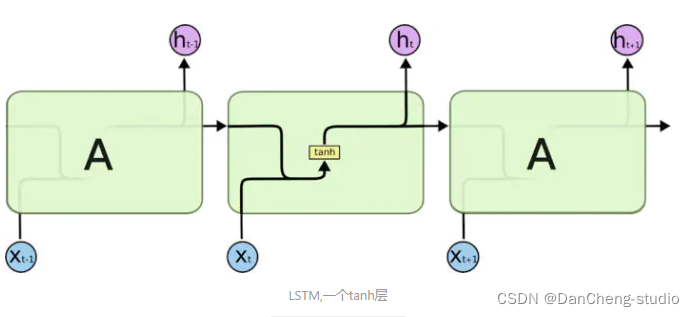
LSTM 同樣是這樣的結構,但是重復的模塊擁有一個不同的結構。不同于單一神經網絡層,這里是有四個,以一種非常特殊的方式進行交互。
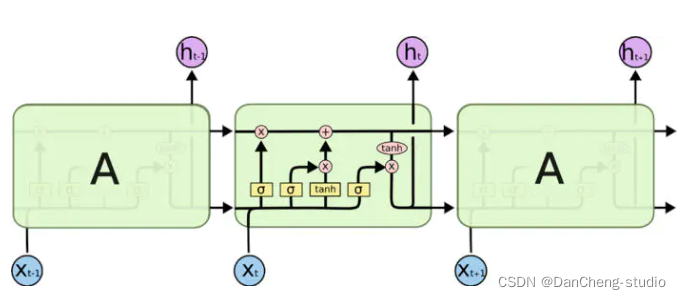
不必擔心這里的細節。我們會一步一步地剖析 LSTM 解析圖。現在,我們先來熟悉一下圖中使用的各種元素的圖標。
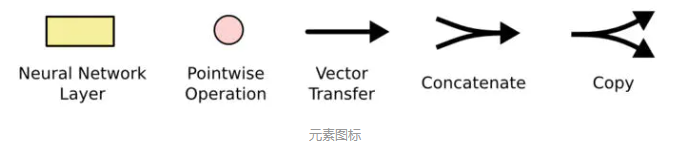
在上面的圖例中,每一條黑線傳輸著一整個向量,從一個節點的輸出到其他節點的輸入。粉色的圈代表 pointwise
的操作,諸如向量的和,而黃色的矩陣就是學習到的神經網絡層。合在一起的線表示向量的連接,分開的線表示內容被復制,然后分發到不同的位置。
3.1 LSTM核心思想
LSTM的關鍵在于細胞的狀態整個(如下圖),和穿過細胞的那條水平線。
細胞狀態類似于傳送帶。直接在整個鏈上運行,只有一些少量的線性交互。信息在上面流傳保持不變會很容易。

門可以實現選擇性地讓信息通過,主要是通過一個 sigmoid 的神經層 和一個逐點相乘的操作來實現的。
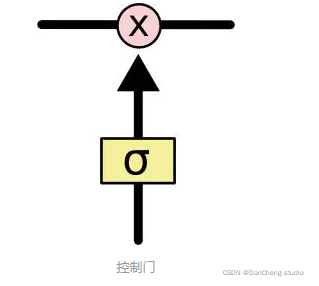
sigmoid 層輸出(是一個向量)的每個元素都是一個在 0 和 1 之間的實數,表示讓對應信息通過的權重(或者占比)。比如, 0
表示“不讓任何信息通過”, 1 表示“讓所有信息通過”。
LSTM通過三個這樣的本結構來實現信息的保護和控制。這三個門分別輸入門、遺忘門和輸出門。
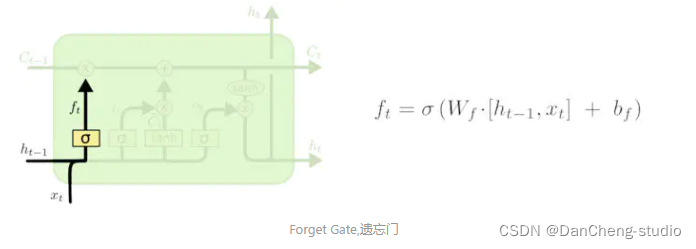
3.2 遺忘門
在我們 LSTM 中的第一步是決定我們會從細胞狀態中丟棄什么信息。這個決定通過一個稱為忘記門層完成。該門會讀取和,輸出一個在 0到
1之間的數值給每個在細胞狀態中的數字。1 表示“完全保留”,0 表示“完全舍棄”。
讓我們回到語言模型的例子中來基于已經看到的預測下一個詞。在這個問題中,細胞狀態可能包含當前主語的性別,因此正確的代詞可以被選擇出來。當我們看到新的主語,我們希望忘記舊的主語。
其中
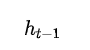
表示的是 上一時刻隱含層的 輸出,
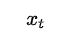
表示的是當前細胞的輸入。σ表示sigmod函數。
3.3 輸入門
下一步是決定讓多少新的信息加入到 cell 狀態 中來。實現這個需要包括兩個步驟:首先,一個叫做“input gate layer ”的 sigmoid
層決定哪些信息需要更新;一個 tanh 層生成一個向量,也就是備選的用來更新的內容。在下一步,我們把這兩部分聯合起來,對 cell 的狀態進行一個更新。

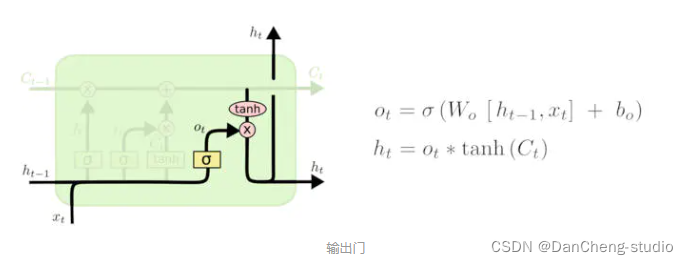
3.4 輸出門
最終,我們需要確定輸出什么值。這個輸出將會基于我們的細胞狀態,但是也是一個過濾后的版本。首先,我們運行一個 sigmoid
層來確定細胞狀態的哪個部分將輸出出去。接著,我們把細胞狀態通過 tanh 進行處理(得到一個在 -1 到 1 之間的值)并將它和 sigmoid
門的輸出相乘,最終我們僅僅會輸出我們確定輸出的那部分。
在語言模型的例子中,因為他就看到了一個代詞,可能需要輸出與一個動詞相關的信息。例如,可能輸出是否代詞是單數還是負數,這樣如果是動詞的話,我們也知道動詞需要進行的詞形變化。
4 基于LSTM的天氣預測
4.1 數據集
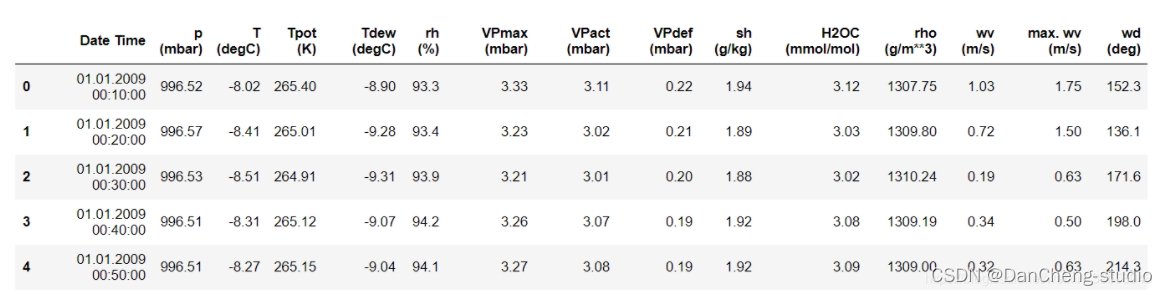
如上所示,每10分鐘記錄一次觀測值,一個小時內有6個觀測值,一天有144(6x24)個觀測值。
給定一個特定的時間,假設要預測未來6小時的溫度。為了做出此預測,選擇使用5天的觀察時間。因此,創建一個包含最后720(5x144)個觀測值的窗口以訓練模型。
下面的函數返回上述時間窗以供模型訓練。參數 history_size 是過去信息的滑動窗口大小。target_size
是模型需要學習預測的未來時間步,也作為需要被預測的標簽。
下面使用數據的前300,000行當做訓練數據集,其余的作為驗證數據集。總計約2100天的訓練數據。
4.2 預測示例
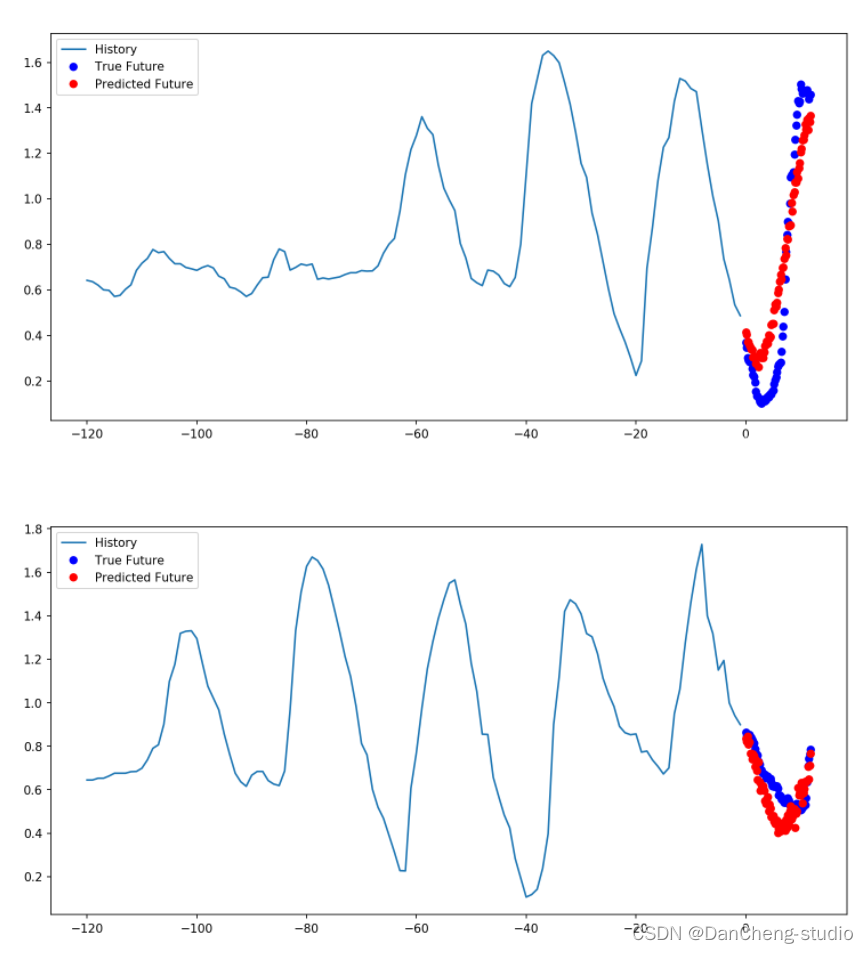
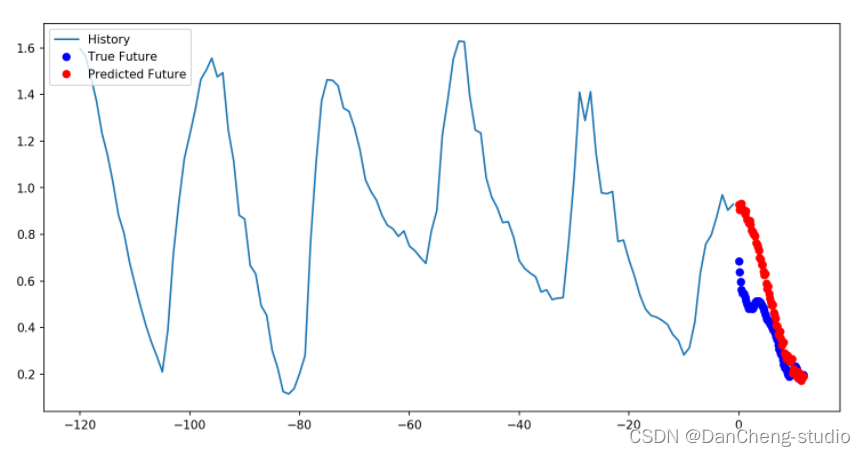
多步驟預測模型中,給定過去的采樣值,預測未來一系列的值。對于多步驟模型,訓練數據再次包括每小時采樣的過去五天的記錄。但是,這里的模型需要學習預測接下來12小時的溫度。由于每10分鐘采樣一次數據,因此輸出為72個預測值。
future_target = 72x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,TRAIN_SPLIT, past_history,future_target, STEP)x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],TRAIN_SPLIT, None, past_history,future_target, STEP)
劃分數據集
? train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi))
? train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
? val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi))val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat()繪制樣本點數據
? def multi_step_plot(history, true_future, prediction):
? plt.figure(figsize=(12, 6))
? num_in = create_time_steps(len(history))
? num_out = len(true_future)
? plt.plot(num_in, np.array(history[:, 1]), label='History')plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',label='True Future')if prediction.any():plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',label='Predicted Future')plt.legend(loc='upper left')plt.show()for x, y in train_data_multi.take(1):multi_step_plot(x[0], y[0], np.array([0]))?

此處的任務比先前的任務復雜一些,因此該模型現在由兩個LSTM層組成。最后,由于需要預測之后12個小時的數據,因此Dense層將輸出為72。
? multi_step_model = tf.keras.models.Sequential()
? multi_step_model.add(tf.keras.layers.LSTM(32,
? return_sequences=True,
? input_shape=x_train_multi.shape[-2:]))
? multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
? multi_step_model.add(tf.keras.layers.Dense(72))
? multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae')?
訓練
multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_data_multi,validation_steps=50)
5 基于LSTM的股票價格預測
5.1 數據集
股票數據總共有九個維度,分別是

5.2 實現代碼
?
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport tensorflow as tfplt.rcParams['font.sans-serif']=['SimHei']#顯示中文plt.rcParams['axes.unicode_minus']=False#顯示負號
?
def load_data():
test_x_batch = np.load(r’test_x_batch.npy’,allow_pickle=True)
test_y_batch = np.load(r’test_y_batch.npy’,allow_pickle=True)
return (test_x_batch,test_y_batch)
#定義lstm單元
def lstm_cell(units):cell = tf.contrib.rnn.BasicLSTMCell(num_units=units,forget_bias=0.0)#activation默認為tanhreturn cell#定義lstm網絡
def lstm_net(x,w,b,num_neurons):#將輸入變成一個列表,列表的長度及時間步數inputs = tf.unstack(x,8,1)cells = [lstm_cell(units=n) for n in num_neurons]stacked_lstm_cells = tf.contrib.rnn.MultiRNNCell(cells)outputs,_ = tf.contrib.rnn.static_rnn(stacked_lstm_cells,inputs,dtype=tf.float32)return tf.matmul(outputs[-1],w) + b#超參數
num_neurons = [32,32,64,64,128,128]#定義輸出層的weight和bias
w = tf.Variable(tf.random_normal([num_neurons[-1],1]))
b = tf.Variable(tf.random_normal([1]))#定義placeholder
x = tf.placeholder(shape=(None,8,8),dtype=tf.float32)#定義pred和saver
pred = lstm_net(x,w,b,num_neurons)
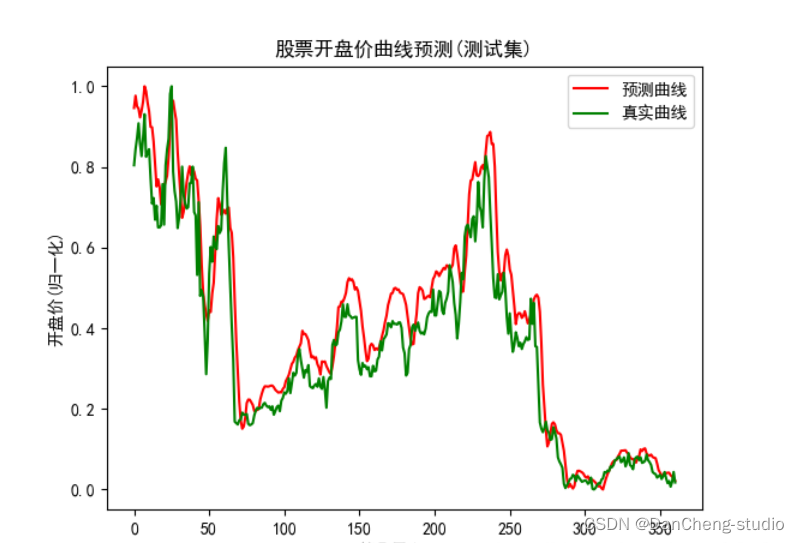
saver = tf.train.Saver(tf.global_variables())if __name__ == '__main__':#開啟交互式Sessionsess = tf.InteractiveSession()saver.restore(sess,r'D:\股票預測\model_data\my_model.ckpt')#載入數據test_x,test_y = load_data()#預測predicts = sess.run(pred,feed_dict={x:test_x})predicts = ((predicts.max() - predicts) / (predicts.max() - predicts.min()))#數學校準#可視化plt.plot(predicts,'r',label='預測曲線')plt.plot(test_y,'g',label='真實曲線')plt.xlabel('第幾天/days')plt.ylabel('開盤價(歸一化)')plt.title('股票開盤價曲線預測(測試集)')plt.legend()plt.show()#關閉會話sess.close()
6 lstm 預測航空旅客數目
數據集
airflights passengers dataset下載地址
https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-
passengers.csv
這個dataset包含從1949年到1960年每個月的航空旅客數目,共12*12=144個數字。
下面的程序中,我們以1949-1952的數據預測1953的數據,以1950-1953的數據預測1954的數據,以此類推,訓練模型。
預測代碼
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport torchimport torch.nn as nnfrom sklearn.preprocessing import MinMaxScalerimport os
?
# super parameters
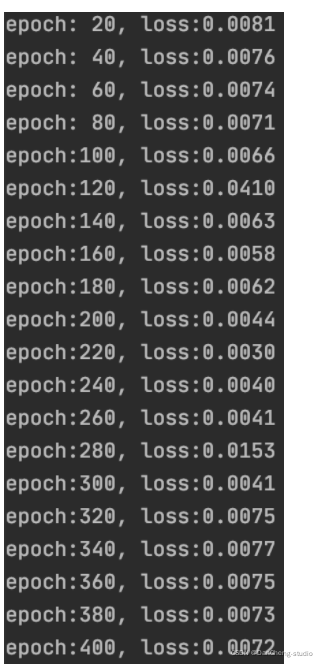
EPOCH = 400
learning_rate = 0.01
seq_length = 4 # 序列長度
n_feature = 12 # 序列中每個元素的特征數目。本程序采用的序列元素為一年的旅客,一年12個月,即12維特征。
# data
data = pd.read_csv('airline-passengers.csv') # 共 "12年*12個月=144" 個數據
data = data.iloc[:, 1:5].values # dataFrame, shape (144,1)
data = np.array(data).astype(np.float32)
sc = MinMaxScaler()
data = sc.fit_transform(data) # 歸一化
data = data.reshape(-1, n_feature) # shape (12, 12)trainData_x = []
trainData_y = []
for i in range(data.shape[0]-seq_length):tmp_x = data[i:i+seq_length, :]tmp_y = data[i+seq_length, :]trainData_x.append(tmp_x)trainData_y.append(tmp_y)# model
class Net(nn.Module):def __init__(self, in_dim=12, hidden_dim=10, output_dim=12, n_layer=1):super(Net, self).__init__()self.in_dim = in_dimself.hidden_dim = hidden_dimself.output_dim = output_dimself.n_layer = n_layerself.lstm = nn.LSTM(input_size=in_dim, hidden_size=hidden_dim, num_layers=n_layer, batch_first=True)self.linear = nn.Linear(hidden_dim, output_dim)def forward(self, x):_, (h_out, _) = self.lstm(x) # h_out是序列最后一個元素的hidden state# h_out's shape (batchsize, n_layer*n_direction, hidden_dim), i.e. (1, 1, 10)# n_direction根據是“否為雙向”取值為1或2h_out = h_out.view(h_out.shape[0], -1) # h_out's shape (batchsize, n_layer * n_direction * hidden_dim), i.e. (1, 10)h_out = self.linear(h_out) # h_out's shape (batchsize, output_dim), (1, 12)return h_outtrain = True
if train:model = Net()loss_func = torch.nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# trainfor epoch in range(EPOCH):total_loss = 0for iteration, X in enumerate(trainData_x): # X's shape (seq_length, n_feature)X = torch.tensor(X).float()X = torch.unsqueeze(X, 0) # X's shape (1, seq_length, n_feature), 1 is batchsizeoutput = model(X) # output's shape (1,12)output = torch.squeeze(output)loss = loss_func(output, torch.tensor(trainData_y[iteration]))optimizer.zero_grad() # clear gradients for this training iterationloss.backward() # computing gradientsoptimizer.step() # update weightstotal_loss += lossif (epoch+1) % 20 == 0:print('epoch:{:3d}, loss:{:6.4f}'.format(epoch+1, total_loss.data.numpy()))# torch.save(model, 'flight_model.pkl') # 這樣保存會彈出UserWarning,建議采用下面的保存方法,詳情可參考https://zhuanlan.zhihu.com/p/129948825torch.save({'state_dict': model.state_dict()}, 'checkpoint.pth.tar')else:# model = torch.load('flight_model.pth')model = Net()checkpoint = torch.load('checkpoint.pth.tar')model.load_state_dict(checkpoint['state_dict'])# predict
model.eval()
predict = []
for X in trainData_x: # X's shape (seq_length, n_feature)X = torch.tensor(X).float()X = torch.unsqueeze(X, 0) # X's shape (1, seq_length, n_feature), 1 is batchsizeoutput = model(X) # output's shape (1,12)output = torch.squeeze(output)predict.append(output.data.numpy())# plot
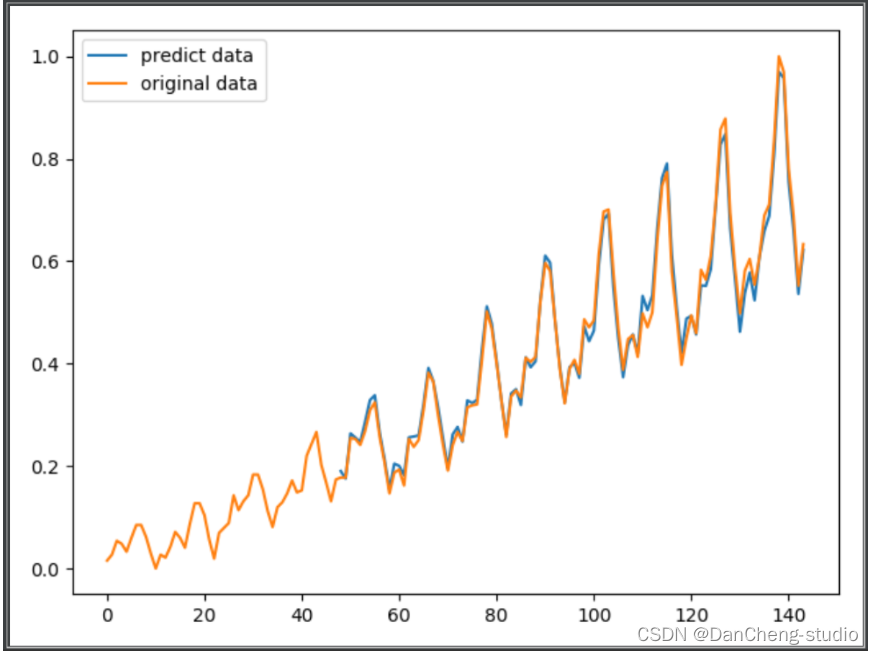
plt.figure()
predict = np.array(predict)
predict = predict.reshape(-1, 1).squeeze()
x_tick = np.arange(len(predict)) + (seq_length*n_feature)
plt.plot(list(x_tick), predict, label='predict data')data_original = data.reshape(-1, 1).squeeze()
plt.plot(range(len(data_original)), data_original, label='original data')plt.legend(loc='best')
plt.show()
運行結果
7 最后
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate

)



(完))
 同步互斥)








)



