Diffusion Models專欄文章匯總:入門與實戰
前言:如何優雅地進行大規模數據清洗是一門藝術,特別對于大模型,數據的質量是決定模型成功最關鍵的因素之一。阿里巴巴最近開源了一項專門針對大語言模型和視頻生成大模型的數據清洗框架,值得關注!
目錄
主要特點
數據處理
分布式數據處理
數據分析
數據可視化
沙盒實驗室
視頻增強菜譜算子
示例:使用DataJuicer處理視頻數據
2.1 克隆data-juicer源代碼
2.2 運行data-juicer
預置模型
主要特點
-
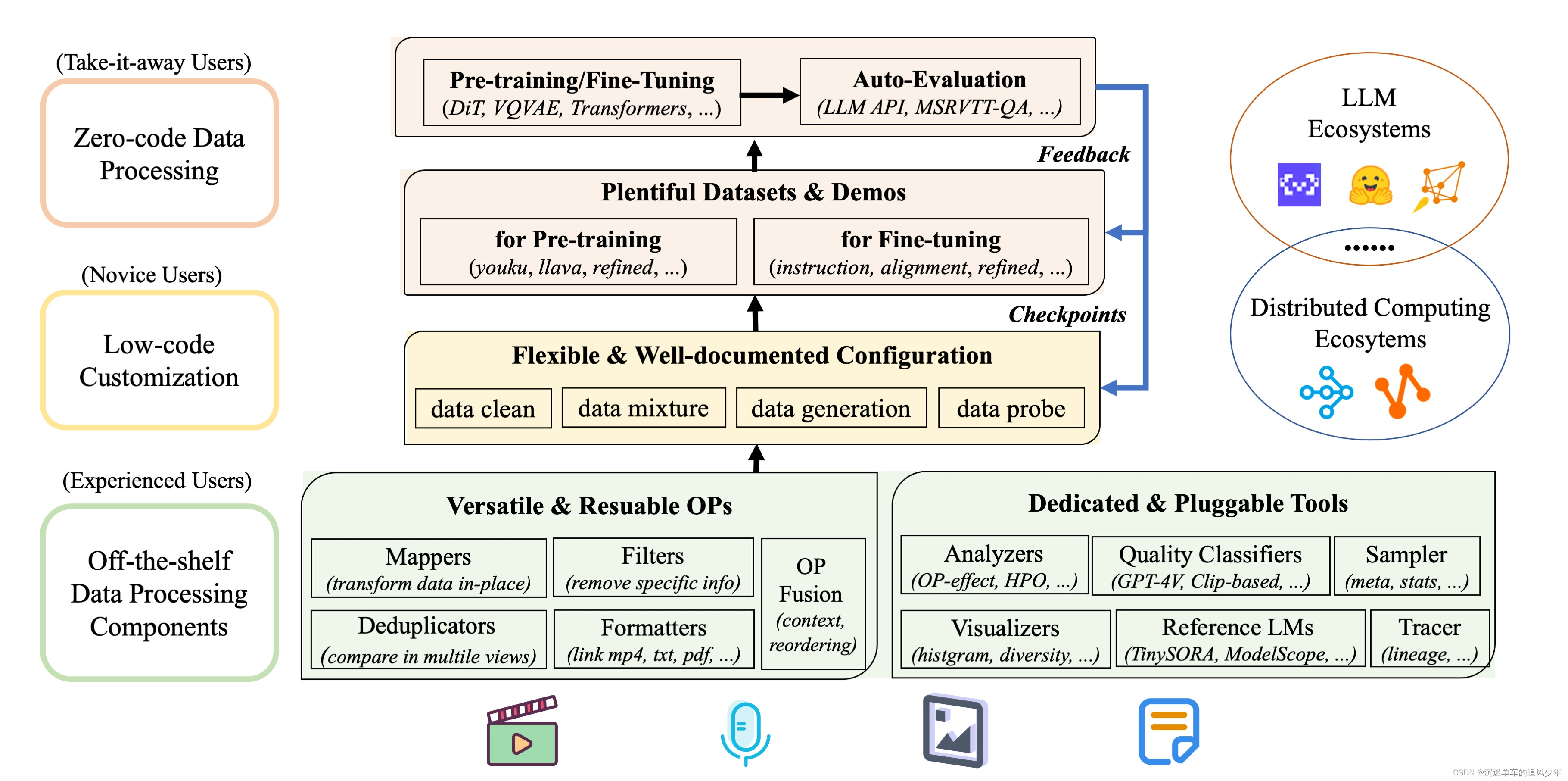
系統化 & 可復用:為用戶提供系統化且可復用的80+核心算子,20+配置菜譜和20+專用工具池,旨在讓多模態數據處理獨立于特定的大語言模型數據集和處理流水線。
-
數據反饋回路 & 沙盒實驗室:支持一站式數據-模型協同開發,通過沙盒實驗室快速迭代,基于數據和模型反饋回路、可視化和多維度自動評估等功能,使您更了解和改進您的數據和模型。
-
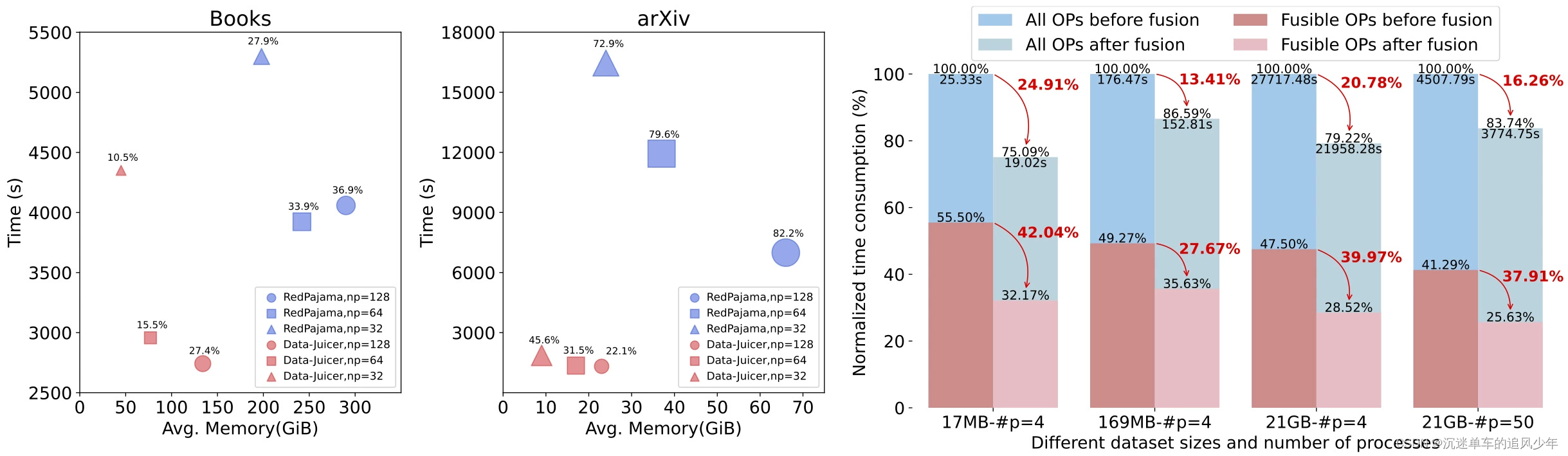
效率增強:提供高效并行化的數據處理流水線(Aliyun-PAI\Ray\Slurm\CUDA\算子融合),減少內存占用和CPU開銷,提高生產力。?
-
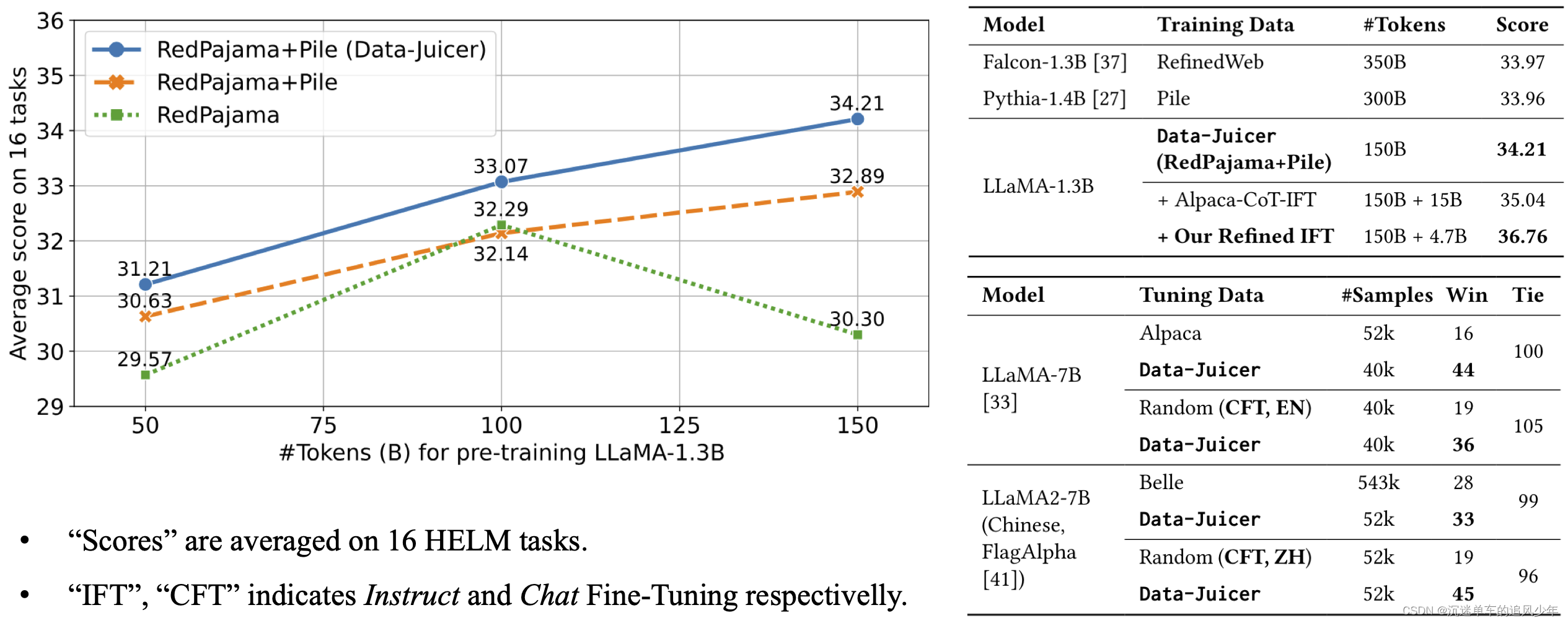
全面的數據處理菜譜:為pre-training、fine-tuning、中英文等場景提供數十種預構建的數據處理菜譜。 在LLaMA、LLaVA等模型上有效驗證。?
-
用戶友好:設計簡單易用,提供全面的文檔、簡易入門指南和演示配置,并且可以輕松地添加/刪除現有配置中的算子。
-
靈活 & 易擴展:支持大多數數據格式(如jsonl、parquet、csv等),并允許靈活組合算子。支持自定義算子,以執行定制化的數據處理。
數據處理
- 以配置文件路徑作為參數來運行?
process_data.py?或者?dj-process?命令行工具來處理數據集。
# 適用于從源碼安裝 python tools/process_data.py --config configs/demo/process.yaml# 使用命令行工具 dj-process --config configs/demo/process.yaml
-
注意:使用未保存在本地的第三方模型或資源的算子第一次運行可能會很慢,因為這些算子需要將相應的資源下載到緩存目錄中。默認的下載緩存目錄為
~/.cache/data_juicer。您可通過設置 shell 環境變量?DATA_JUICER_CACHE_HOME?更改緩存目錄位置,您也可以通過同樣的方式更改?DATA_JUICER_MODELS_CACHE?或?DATA_JUICER_ASSETS_CACHE?來分別修改模型緩存或資源緩存目錄: -
注意:對于使用了第三方模型的算子,在填寫config文件時需要去聲明其對應的
mem_required(可以參考config_all.yaml文件中的設置)。Data-Juicer在運行過程中會根據內存情況和算子模型所需的memory大小來控制對應的進程數,以達成更好的數據處理的性能效率。而在使用CUDA環境運行時,如果不正確的聲明算子的mem_required情況,則有可能導致CUDA Out of Memory。
# 緩存主目錄 export DATA_JUICER_CACHE_HOME="/path/to/another/directory" # 模型緩存目錄 export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models" # 資源緩存目錄 export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"
分布式數據處理
Data-Juicer 現在基于RAY實現了多機分布式數據處理。 對應Demo可以通過如下命令運行:
# 運行文字數據處理 python tools/process_data.py --config ./demos/process_on_ray/configs/demo.yaml# 運行視頻數據處理 python tools/process_data.py --config ./demos/process_video_on_ray/configs/demo.yaml
- 如果需要在多機上使用RAY執行數據處理,需要確保所有節點都可以訪問對應的數據路徑,即將對應的數據路徑掛載在共享文件系統(如NAS)中。
- RAY 模式下的去重算子與單機版本不同,所有 RAY 模式下的去重算子名稱都以?
ray?作為前綴,例如?ray_video_deduplicator?和?ray_document_deduplicator。這些去重算子依賴于?Redis?實例.因此使用前除啟動 RAY 集群外還需要啟動 Redis 實例,并在對應的配置文件中填寫 Redis 實例的?host?和?port。
用戶也可以不使用 RAY,拆分數據集后使用?Slurm?/?阿里云 PAI-DLC?在集群上運行,此時使用不包含 RAY 的原版 Data-Juicer 即可。
數據分析
- 以配置文件路徑為參數運行?
analyze_data.py?或者?dj-analyze?命令行工具來分析數據集。
# 適用于從源碼安裝 python tools/analyze_data.py --config configs/demo/analyser.yaml# 使用命令行工具 dj-analyze --config configs/demo/analyser.yaml
- 注意:Analyser 只計算 Filter 算子的狀態,其他的算子(例如 Mapper 和 Deduplicator)會在分析過程中被忽略。
數據可視化
- 運行?
app.py?來在瀏覽器中可視化您的數據集。 - 注意:只可用于從源碼安裝的方法。
streamlit run app.py
沙盒實驗室
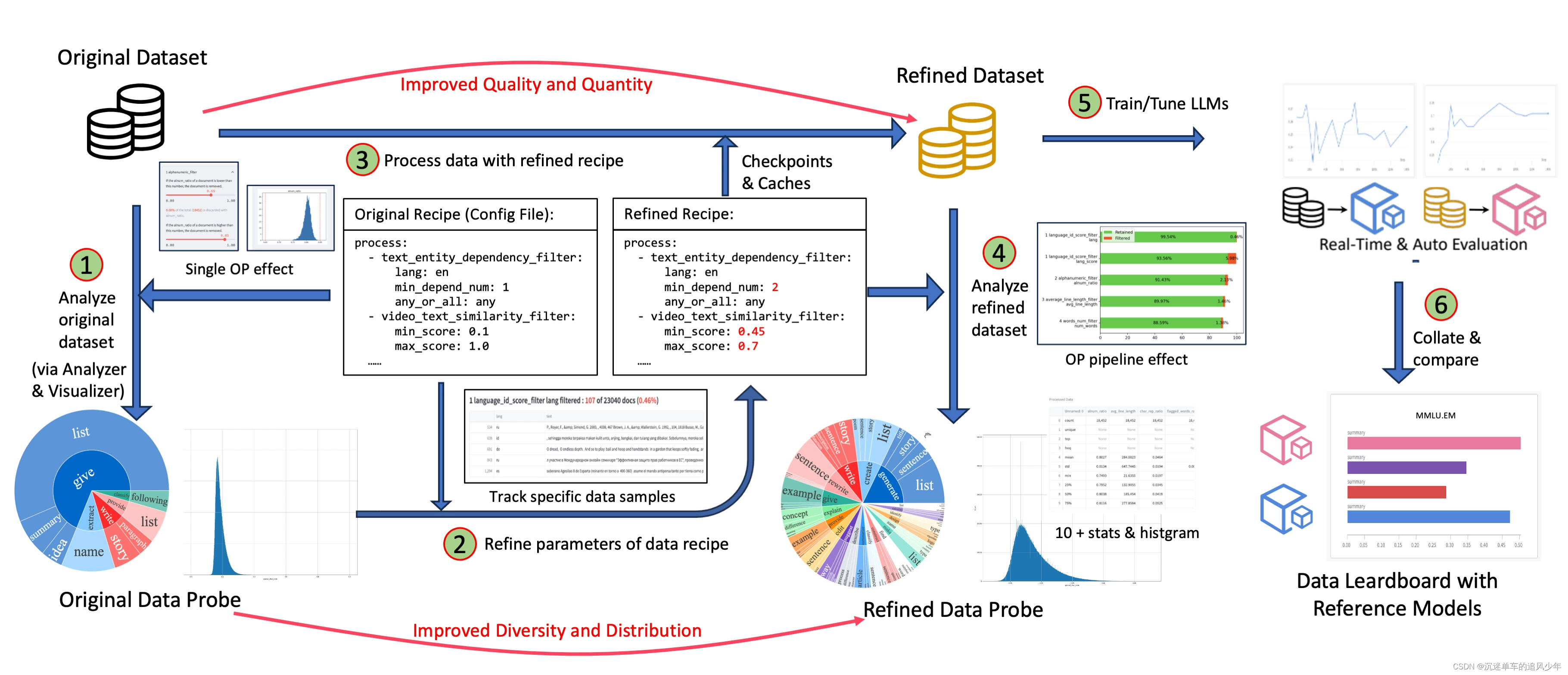
數據沙盒實驗室 (DJ-Sandbox) 為用戶提供了持續生產數據菜譜的最佳實踐,其具有低開銷、可遷移、有指導性等特點。
- 用戶在沙盒中可以基于一些小規模數據集、模型對數據菜譜進行快速實驗、迭代、優化,再遷移到更大尺度上,大規模生產高質量數據以服務大模型。
- 用戶在沙盒中,除了Data-Juicer基礎的數據優化與數據菜譜微調功能外,還可以便捷地使用數據洞察與分析、沙盒模型訓練與評測、基于數據和模型反饋優化數據菜譜等可配置組件,共同組成完整的一站式數據-模型研發流水線。
沙盒默認通過如下命令運行,更多介紹和細節請參閱沙盒文檔.
python tools/sandbox_starter.py --config configs/demo/sandbox/sandbox.yaml
視頻增強菜譜算子
# Process config example including:
# - all global arguments
# - all ops and their arguments# global parameters
project_name: 'all' # project name for distinguish your configs
dataset_path: '/path/to/a/video-text/dataset.jsonl'# accepted format: 'weight1(optional) dataset1-path weight2(optional) dataset2-path'
export_path: '/path/to/store/refined/dataset.jsonl'
np: 48 # number of subprocess to process your dataset# Note: currently, we support specify only ONE key for each op, for cases requiring multiple keys, users can specify the op multiple times. We will only use the first key of `text_keys` when you set multiple keys.
open_tracer: true # whether to open the tracer to trace the changes during process. It might take more time when opening tracer# for multimodal data processing
video_key: 'videos' # key name of field to store the list of sample video paths.
video_special_token: '<__dj__video>' # the special token that represents a video in the text. In default, it's "<__dj__video>". You can specify your own special token according to your input dataset.eoc_special_token: '<|__dj__eoc|>' # the special token that represents the end of a chunk in the text. In default, it's "<|__dj__eoc|>". You can specify your own special token according to your input dataset.# process schedule: a list of several process operators with their arguments
# hyperparameters are set according to the 3-sigma stats on MSR-VTT dataset
process:- language_id_score_filter: # filter text in specific language with language scores larger than a specific max valuelang: en # keep text in what languagemin_score: 0.26311219 # the min language scores to filter text- perplexity_filter: # filter text with perplexity score out of specific rangelang: en # compute perplexity in what languagemax_ppl: 7376.81378 # the max perplexity score to filter text- video_aesthetics_filter: # filter samples according to the aesthetics score of frame images extracted from videos.hf_scorer_model: shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE # Huggingface model name for the aesthetics predictormin_score: 0.31767486 # the min aesthetics score of filter rangemax_score: 1.0 # the max aesthetics score of filter rangeframe_sampling_method: 'uniform' # sampling method of extracting frame images from the videos. Should be one of ["all_keyframe", "uniform"]. The former one extracts all key frames and the latter one extract specified number of frames uniformly from the video. Default: "uniform" with frame_num=3, considering that the number of keyframes can be large while their difference is usually small in terms of their aesthetics.frame_num: 3 # the number of frames to be extracted uniformly from the video. Only works when frame_sampling_method is "uniform". If it's 1, only the middle frame will be extracted. If it's 2, only the first and the last frames will be extracted. If it's larger than 2, in addition to the first and the last frames, other frames will be extracted uniformly within the video duration.reduce_mode: avg # reduce mode to the all frames extracted from videos, must be one of ['avg','max', 'min'].any_or_all: any # keep this sample when any/all images meet the filter condition- video_frames_text_similarity_filter: # keep samples those similarities between sampled video frame images and text within a specific range.hf_clip: openai/clip-vit-base-patch32 # clip model name on huggingface to compute the similarity between frame image and text. It's kind of language-related. For example, for Chinese datasets, ChineseCLIP might be a better choice.min_score: 0.16571071 # the min similarity to keep samples.max_score: 1.0 # the max similarity to keep samples.frame_sampling_method: all_keyframes # sampling method of extracting frame images from the videos. Should be one of ["all_keyframes", "uniform"]. The former one extracts all key frames and the latter one extract specified number of frames uniformly from the video. Default: "all_keyframes".frame_num: 3 # the number of frames to be extracted uniformly from the video. Only works when frame_sampling_method is "uniform". If it's 1, only the middle frame will be extracted. If it's 2, only the first and the last frames will be extracted. If it's larger than 2, in addition to the first and the last frames, other frames will be extracted uniformly within the video duration.horizontal_flip: false # flip frame image horizontally (left to right).vertical_flip: false # flip frame image vertically (top to bottom).reduce_mode: avg # reduce mode when one text corresponds to multiple videos in a chunk, must be one of ['avg','max', 'min'].any_or_all: any # keep this sample when any/all videos meet the filter condition- video_motion_score_filter: # Keep samples with video motion scores within a specific range.min_score: 0.25 # the minimum motion score to keep samplesmax_score: 10000.0 # the maximum motion score to keep samplessampling_fps: 2 # the samplig rate of frames_per_second to compute optical flowany_or_all: any # keep this sample when any/all videos meet the filter condition- video_nsfw_filter: # filter samples according to the nsfw scores of videos in themhf_nsfw_model: Falconsai/nsfw_image_detection # Huggingface model name for nsfw classificationscore_threshold: 0.34847191 # the nsfw score threshold for samples, range from 0 to 1frame_sampling_method: all_keyframes # sampling method of extracting frame images from the videos. Should be one of ["all_keyframes", "uniform"]. The former one extracts all key frames and the latter one extract specified number of frames uniformly from the video. Default: "all_keyframes".frame_num: 3 # the number of frames to be extracted uniformly from the video. Only works when frame_sampling_method is "uniform". If it's 1, only the middle frame will be extracted. If it's 2, only the first and the last frames will be extracted. If it's larger than 2, in addition to the first and the last frames, other frames will be extracted uniformly within the video duration.reduce_mode: avg # reduce mode for multiple sampled video frames to compute nsfw scores of videos, must be one of ['avg','max', 'min'].any_or_all: any # keep this sample when any/all images meet the filter condition- video_watermark_filter: # filter samples according to the predicted watermark probabilities of videos in themhf_watermark_model: amrul-hzz/watermark_detector # Huggingface model name for watermark classificationprob_threshold: 0.96510297 # the predicted watermark probability threshold for samples, range from 0 to 1frame_sampling_method: all_keyframes # sampling method of extracting frame images from the videos. Should be one of ["all_keyframes", "uniform"]. The former one extracts all key frames and the latter one extract specified number of frames uniformly from the video. Default: "all_keyframes".frame_num: 3 # the number of frames to be extracted uniformly from the video. Only works when frame_sampling_method is "uniform". If it's 1, only the middle frame will be extracted. If it's 2, only the first and the last frames will be extracted. If it's larger than 2, in addition to the first and the last frames, other frames will be extracted uniformly within the video duration.reduce_mode: avg # reduce mode for multiple sampled video frames to compute final predicted watermark probabilities of videos, must be one of ['avg','max', 'min'].any_or_all: any # keep this sample when any/all images meet the filter condition示例:使用DataJuicer處理視頻數據
2.1 克隆data-juicer源代碼
# 如已經下載,可跳過此步驟 !cd dj_sora_challenge/toolkit && git clone https://github.com/modelscope/data-juicer
2.2 運行data-juicer
DataJuicer 通過config文件來指定進行數據處理的算子,您可以根據需要使用不同的算子/參數組合來調節數據預處理的鏈路。
為了方便您更好地體驗DJ-SORA,運行下面的代碼來下載一個供參考的config文件。
樣例展示了使用datajuicer進行文本過濾 (video_ocr_area_ratio_filter) + 美學過濾 (video_aesthetics_filter) 的例子。
算子的詳細介紹在 DJ-SORA官方文檔:?data-juicer/docs/DJ_SORA_ZH.md at main · modelscope/data-juicer · GitHub
您可在 data-juicer/data_juicer/ops 文件夾中查看相關算子定義及參數含義,并進行相應的修改來調整數據預處理鏈路。
# 下載參考的配置文件(無需重復執行) !wget https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/config/demo_config.yaml
# 下載相關的模型文件 (無需重復執行)
dj_path = os.path.join(os.getcwd(),'dj_sora_challenge/toolkit/data-juicer')
download_dj_preprocess_model('video_ocr_area_ratio_filter', dj_path)
download_dj_preprocess_model('video_aesthetics_filter', dj_path)
# 數據預處理 (修改配置文件來執行不同的數據預處理鏈路)
dj_path = os.path.join(os.getcwd(),'dj_sora_challenge/toolkit/data-juicer')
config_path = os.path.join(os.getcwd(), 'demo_config.yaml')
!cd {dj_path} && PATHPATH=./ python tools/process_data.py --config {config_path}# 預處理后的結果存放在 dj_sora_challenge/output/processed_data/processed_data.jsonl
預置模型
為了方便您使用DJ,我們提供了常用算子的預置模型,您可通過調用?download_dj_preprocess_model(op_name, dj_path)?使用。
預置模型列表:
| 算子名稱 | 功能 | 地址 |
|---|---|---|
| video_ocr_area_ratio_filter | 移除文本區域過大的樣本 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/craft_mlt_25k.pth |
| video_aesthetics_filter | 拆幀后,進行美學度打分過濾 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/models_aesthetic.tar.gz |
| video_frames_text_similarity_filter | 在時空一致性維度過濾,計算關鍵/指定幀 和文本的匹配分 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/models_clip.tar.gz |
| video_nsfw_filter | 移除不合規的樣本 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/models_nsfw.tar.gz |
| video_watermark_filter | 移除帶水印的樣本 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/models_watermark.tar.gz |
| video_tagging_from_frames_filter | 輕量圖生文模型,密集幀生成空間 概要信息 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/ram_plus_swin_large_14m.pth |
| video_captioning_from_frames_mapper | 更重的圖生文模型,少量幀生成更詳細空間信息 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/models_blip.tar.gz |
| video_captioning_from_video_mapper | 視頻生文模型,連續幀生成時序信息 | https://pai-vision-data-wlcb.oss-cn-wulanchabu.aliyuncs.com/aigc-data/easyanimate/models/preprocess/models_video_blip.tar.gz |
# 下載預置模型
# download_dj_preprocess_model('video_nsfw_filter', dj_path)
# download_dj_preprocess_model('video_frames_text_similarity_filter', dj_path)
# download_dj_preprocess_model('video_watermark_filter', dj_path)
# download_dj_preprocess_model('video_tagging_from_frames_mapper', dj_path)
# download_dj_preprocess_model('video_captioning_from_frames_mapper', dj_path)
# download_dj_preprocess_model('video_captioning_from_video_mapper', dj_path)
項目地址:
GitHub - modelscope/data-juicer: A one-stop data processing system to make data higher-quality, juicier, and more digestible for (multimodal) LLMs! 🍎 🍋 🌽 ?? ??🍸 🍹 🍷為大模型提供更高質量、更豐富、更易”消化“的數據!



如何在 MyBatis 中使用 XML 和注解混合配置方式)
)
)

)
- 模型微調之自定義訓練循環)




基礎介紹)


![[AI 大模型] OpenAI ChatGPT](http://pic.xiahunao.cn/[AI 大模型] OpenAI ChatGPT)
)

