目錄
一. Kafka介紹
1. 應用場景
2. 版本對比
二. Kafka安裝
1. 前置環境
(1)安裝JDK
2. 軟件安裝
(3)環境變量配置
(3)服務啟動
三. Console測試
基礎命令
(1)列出Kafka集群中所有存在的主題
(3)創建一個新的主題
(3)刪除主題
(4)描述主題
(5)啟動生產者
(6)啟動消費者
四. 注冊系統服務
1. Systemd服務配置
2. Kafka服務控制
一. Kafka介紹
Kafka是由Apache軟件基金會開發的一個開源流處理平臺,由Scala和Java編寫。該項目的目標是為處理實時數據提供一個統一、高吞吐、低延遲的平臺。其持久化層本質上是一個“按照分布式事務日志架構的大規模發布/訂閱消息隊列”,這使它作為企業級基礎設施來處理流式數據非常有價值。
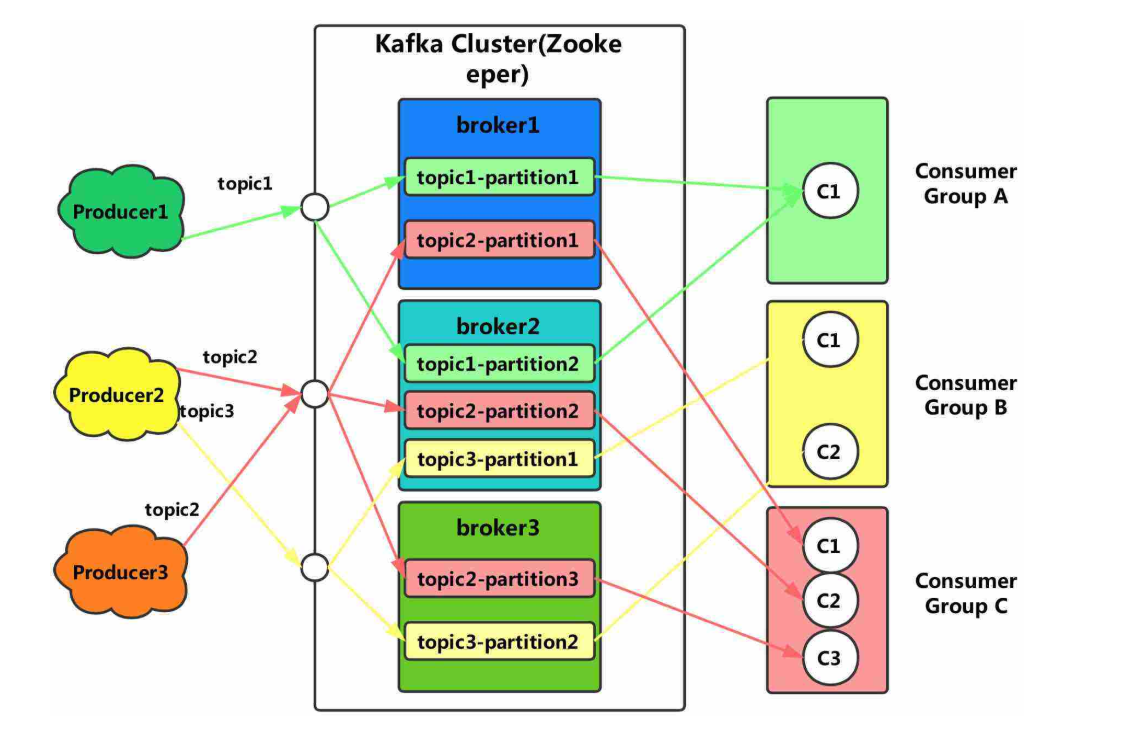
1. 應用場景
Kafka可以看作是一個能夠處理消息隊列的中間件,適用于實時的流數據處理,主要用于平衡好生產者和消費者之間的關系。
- 生產者
生產者可以看作是數據源,可以來自于日志采集框架,如Flume,也可以來自于其它的流數據服務。當接收到數據后,將根據預設的Topic暫存在Kafka中等待消費。對于接收到的數據將會有額外的標記,用于記錄數據的被消費【使用】情況。
- 消費者
消費者即數據的使用端,可以是一個持久化的存儲結構,如Hadoop,也可以直接接入支持流數據計算的各種框架,如Spark - Streaming。消費者可以有多個,通過訂閱不同的Topic來獲取數據。
2. 版本對比
Kafka的0.x和1.x可以看作是上古版本了,最近的更新也是幾年以前,從目前的場景需求來看,也沒有什么特別的理由需要使用到這兩個版本了。
- 2.x
在進行版本選擇時,通常需要綜合考慮整個數據流所設計到的計算框架和存儲結構,來確定開發成本以及兼容性。目前2.x版本同樣是一個可以用于生產環境的版本,并且保持著對Scala最新版本的編譯更新。
- 3.x
3.x是目前最新的穩定版,需要注意的是,Kafka的每個大版本之間的差異較大,包括命令參數以及API調用,所以在更換版本前需要做好詳細的調查與準備,本文以3.x的安裝為例。
二. Kafka安裝
解壓安裝的操作方式可以適用于各種主流Linux操作系統,只需要解決好前置環境問題。
1. 前置環境
此前,運行Kafka需要預先安裝Zookeeper。在Kafka 2.8.0版本以后,引入了Kraft(Kafka Raft)模式,可以使Kafka在不依賴外部Zookeeper的前提下運行。除此之外Kafka由Scala語言編寫,需要JVM的運行環境。
(1)安裝JDK
?Ubuntu/Debian:
sudo apt install openjdk-8-jdk? CentOS/RedHat:
sudo yum install java-1.8.0-openjdk安裝完成后可以使用java-version命令驗證【可省去環境變量配置】。

2. 軟件安裝
- 下載Kafka ,鏈接如下:
# 離線下載安裝包
https://downloads.apache.org/kafka/3.5.2/kafka_2.12-3.5.2.tgz# 在線利用wget遠程下載?
wget https://downloads.apache.org/kafka/3.5.2/kafka_2.12-3.5.2.tgz- 解壓安裝??
tar -zvxf kafka_2.12-3.5.2.tgz(3)環境變量配置
需要在環境變量中指定Kafka的安裝目錄以及命令文件所在目錄,系統環境變量與用戶環境變量配置其中之一即可。
/etc/profile 文件最下方添加如下兩行命令--配置全局環境。
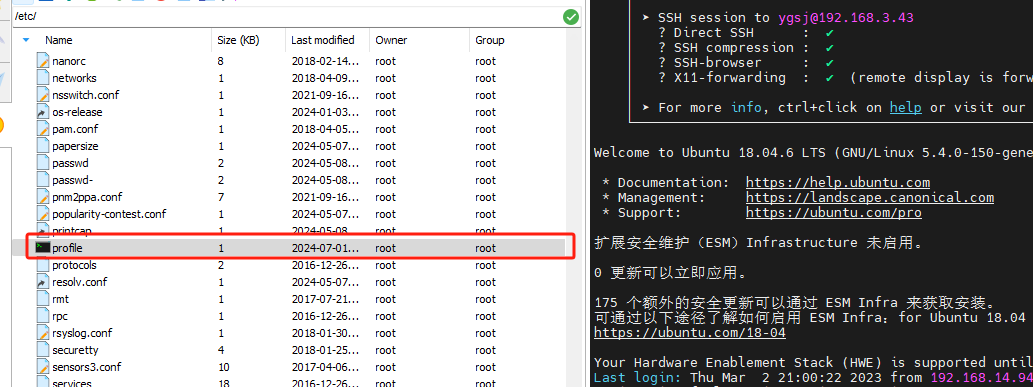
export KAFKA_HOME=/home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2
export PATH=$PATH:$KAFKA_HOME/bin在文件結尾添加以上內容后執行source命令,使其立即生效。
source /etc/profile[Ubuntu/Debian] source ~/.bashrc[CentOS/RedHat] source ~/.bash_profile
執行后可以輸入kafka,然后按Tab嘗試補全【需要按多次】,如果出現命令列表則證明配置成功。

(3)服務啟動
使用Kraft模式,則需要先進行集群初始化【即使是單個節點】,以下為操作步驟:
- 目錄下創建 kafka-logs文件夾
- 修改配置文件
修改Kafka的/config/kraft/server.properties文件,更換其中的log.dirs目錄指向創建目錄,防止默認的/tmp被清空:
log.dirs=/home/ygsj/Config_files/kafka_server/kafka-logs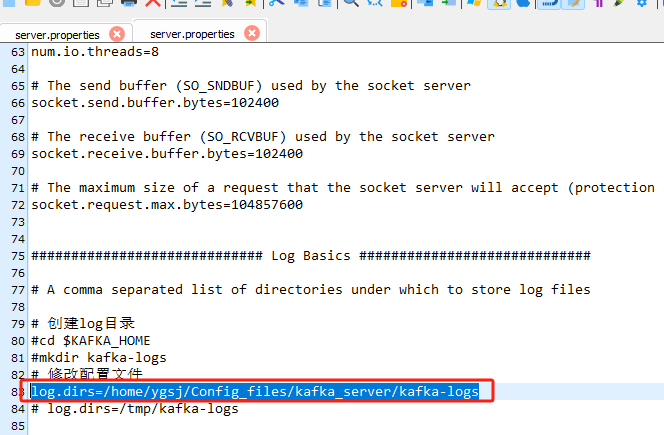
- 創建Kafka的集群ID?
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"調用?kafka-storage.sh?生成一個UUID

將獲得的 UUID?放到 kafka_2.12-3.5.2/config/kraft/server.properties 文件中 如下:
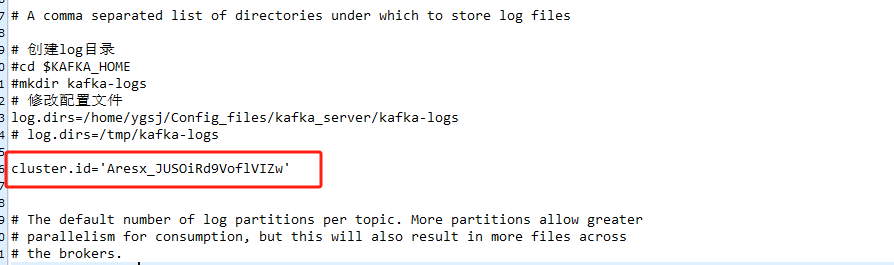
相同文件內修改:遠程連接開啟 (紅框內寫服務器ip)---自己測試0.0.0.0無效
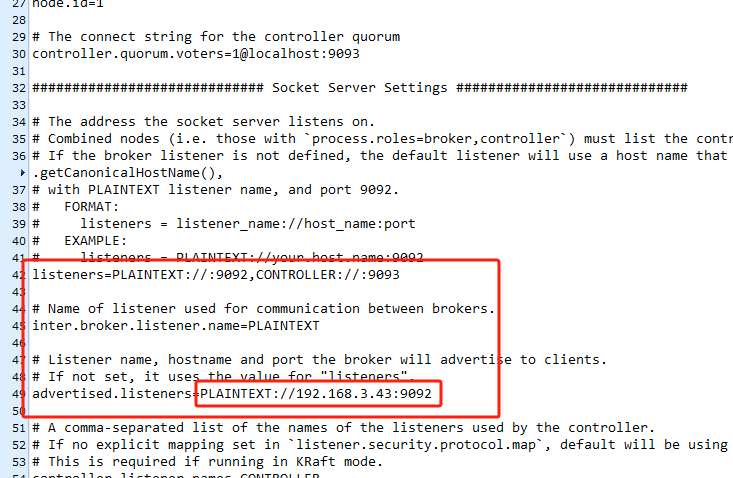
進入到Kafka的家目錄后,執行以下命令?
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties# bin/kafka-server-start.sh config/kraft/server.properties ?這種方式并不是后臺運行,需要保證終端開啟,等測試穩定后可以在后臺執行或者注冊為系統服務。?
?這種方式并不是后臺運行,需要保證終端開啟,等測試穩定后可以在后臺執行或者注冊為系統服務。?
三. Console測試
基礎命令
(1)列出Kafka集群中所有存在的主題
kafka-topics.sh --list --bootstrap-server localhost:9092
--bootstrap-server localhost:9092 指定了Kafka集群的連接地址(在這里是本地的Kafka服務器)
如果集群中沒有主題,命令不會返回任何內容
當你創建主題后,這條命令會返回集群中存在的主題列表
(3)創建一個新的主題
kafka-topics.sh --create --topic my-topic --bootstrap-server localhost:9092這條命令用于創建一個名為 my-topic 的新主題。
--create 指定了創建操作。
--topic my-topic 指定了要創建的主題名稱。
--bootstrap-server localhost:9092 指定了Kafka集群的連接地址。
Created topic my-topic. 表示主題 my-topic 已成功創建。
(3)刪除主題
kafka-topics.sh --delete ?--topic my-topic --bootstrap-server localhost:9092--delete: 指定要刪除一個主題。
--topic my-topic: 指定要刪除的主題名稱是 my-topic。
--bootstrap-server localhost:9092: 指定Kafka集群的連接地址(在此是本地的Kafka服務器)。
(4)描述主題
?kafka-topics.sh --describe ?--topic my-topic --bootstrap-server localhost:9092獲取指定主題 my-topic 的詳細信息。
--describe 指定了描述操作。
--topic my-topic 指定了要描述的主題名稱。
--bootstrap-server localhost:9092 指定了Kafka集群的連接地址。
(5)啟動生產者
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-topic啟動一個基于console的生產者腳本,可以方便的進行數據輸入的測試,直接進行數據輸入即可。

(6)啟動消費者
?kafka-console-consumer.sh --help? 打印所有參數
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning添加from-beginning參數來從頭消費數據。

四. 注冊系統服務
?為了方便的控制Kafka服務的啟動和停止,可以將其注冊為系統服務。
1. Systemd服務配置
創建Systemd服務文件
sudo vim /etc/systemd/system/kafka.service
在文件中添加以下內容,需要手動替換ExecStart和ExecStop中關于路徑的部分:
[Unit]
Description=Apache Kafka
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
ExecStart=/home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2/bin/kafka-server-start.sh /home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2/config/kraft/server.properties
ExecStop=/home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target?重新加載Systemd配置?
sudo systemctl daemon-reload2. Kafka服務控制
- 開機自動啟動
sudo systemctl enable kafka.service- 啟動Kafka服務
sudo systemctl start kafka.service- 檢查Kafka狀態?
sudo systemctl status kafka.service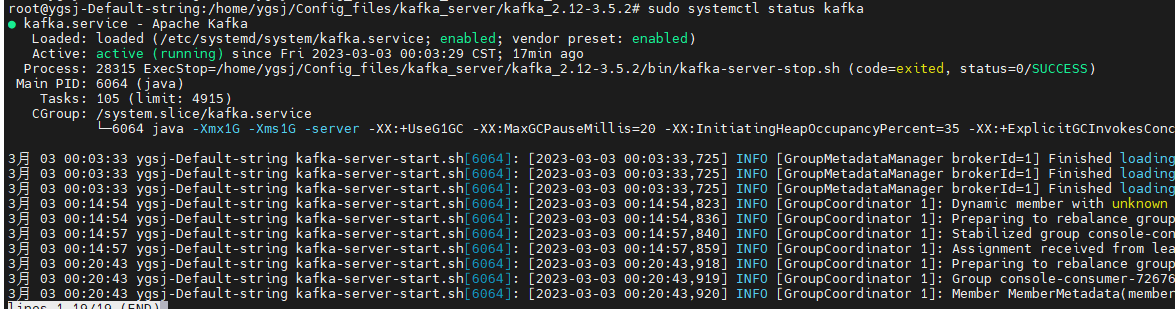
- 停止Kafka服務
sudo systemctl stop kafka.service- 重啟Kafka服務
sudo systemctl restart kafka.service



-更新中)






)







