開源模型
- 平臺:https://huggingface.co/
- ars-語言轉文本: pipeline("automatic-speech-recognition", model="openai/whisper-large-v3", device=0 )
- hf:?https://huggingface.co/openai/whisper-large-v3?
-
github:?https://github.com/openai/whisper
- tts-文本轉語音:pipeline("text-to-speech", "microsoft/speecht5_tts", device=0)
- hf:?https://huggingface.co/microsoft/speecht5_tts?
-
github:?https://github.com/microsoft/SpeechT5?
- 文本語言識別:pipeline("text-classification", model="papluca/xlm-roberta-base-language-detection", device=0)
- hf:?https://huggingface.co/papluca/xlm-roberta-base-language-detection
-
github:? https://github.com/saffsd/langid.py
- 文本翻譯--zh-en:
- pipeline("translation", model="Helsinki-NLP/opus-mt-en-zh", device=0, torch_dtype=torch_dtype)
- pipeline("translation", model="Helsinki-NLP/opus-mt-zh-en", device=0, torch_dtype=torch_dtype)
- hf:?https://huggingface.co/Helsinki-NLP/opus-mt-zh-en?
-
github:?https://github.com/Helsinki-NLP/OPUS-MT-train?
- 流程
- 網頁端提交:當前批次,文本,音頻base64數據,通過給python-flask后端產生一個處理任務(mongo)
- 后端循環處理要處理的任務
- 網頁端查詢已處理好的任務--批次
代碼
## 接口from flask import Flask, request
from flask_cors import CORSimport time
import json
from datetime import datetimeimport mongo_util
import audio_message_util as amutil
import audio_util as autilapp = Flask(__name__)
CORS(app)client = mongo_util.get_client()
db = mongo_util.get_db(client, "")class DateTimeEncoder(json.JSONEncoder):def default(self, obj):if isinstance(obj, datetime):return obj.isoformat()return json.JSONEncoder.default(self, obj)@app.route('/audio/totxt', methods=['POST'])
def totxt():base64data = request.json['data']batch = request.json['batch']filename = 'webm/' + batch + '/' + str(time.time()).replace('.', '_')+'.webm'out_file = filename.replace('webm', 'mp3')autil.base64_tomp3(base64data, filename, out_file)print(datetime.now(), batch, filename, out_file)c = {'batch': batch,'original_path': filename,'audio_path': out_file,'type': 1,'status': 1,}amutil.save(db, c)return 'ok'@app.route('/txt/toaudio', methods=['POST'])
def toaudio():text = request.json['data']batch = request.json['batch']print(datetime.now(), batch, text)c = {'batch': batch,'original_text': text,'type': 2,'status': 1,}amutil.save(db, c)return 'ok'@app.route('/audio/gettxt', methods=['POST'])
def gettxt():batch = request.json['batch']cs = amutil.get(db, {'status':2, 'batch':batch})csj = []for c in cs:# print(c)if c['type'] == 2 and c['audiofile'] != None:c['audiourl'] = 'data:audio/webm;codecs=opus;base64,' + autil.get_audio_base64(c['audiofile'])if c['type'] == 1 and 'audio_path' in c and c['audio_path'] != None:c['audiourl'] = 'data:audio/webm;codecs=opus;base64,' + autil.get_audio_base64(c['audio_path'])csj.append(c)return json.dumps(csj, cls=DateTimeEncoder)if __name__ == '__main__':app.run(debug=True, port="8080")結果
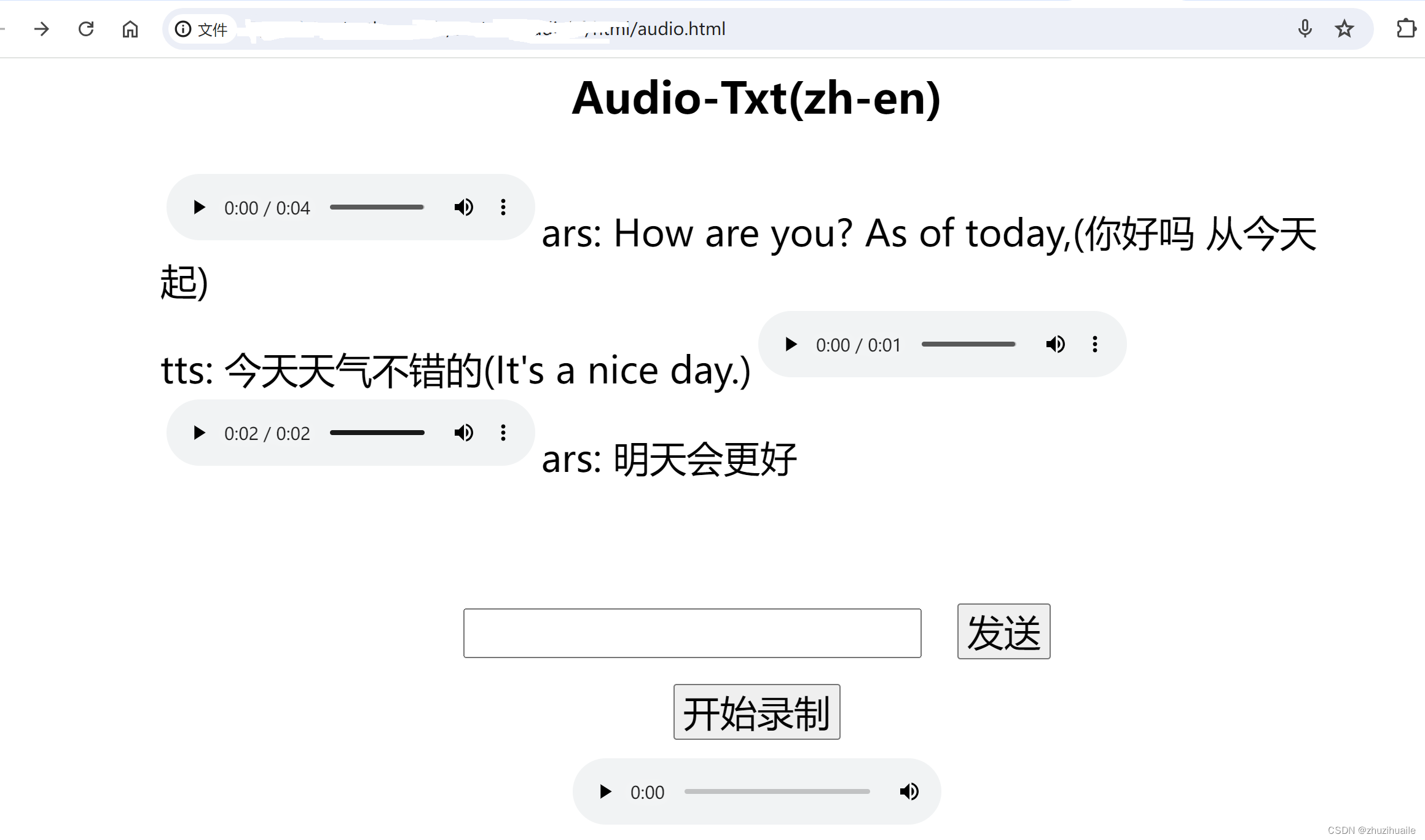


)
















