這篇文章中個人結合自己的實踐經驗把 OpenAI 官方文檔解讀一遍。但是原文檔涉及內容眾多,包括微調,嵌入(Embeddings)等眾多主題,我這里重點挑選自己開發高頻使用到的,需要詳細了解的可以自行前往官網閱讀。
API 介紹
-
所有 API 演示均使用 Python 代碼作為示例,所以確保已經安裝官方 Python 包:
pip install openai,同時配置 API 密鑰的環境變量OPENAI_API_KEY。 -
認證:OpenAI API 使用 API 密鑰進行身份驗證, API 密鑰頁面可以獲取使用的 API 密鑰。除了密鑰,對于屬于多個組織的用戶,可以傳遞一個 Requesting organization 字段(可以在組織設置頁面上找到組織 ID)來指定用于 API 請求的組織,這些 API 請求的使用將計入指定組織的訂閱配額。
arduino復制代碼import os import openai # openai.organization = "org-gth0C8mT2wnKealyDkrSrpQk" openai.api_key = os.getenv("OPENAI_API_KEY") openai.Model.list()
Chat Completions 會話補全
這個是使用頻次最高的接口,幾乎當前所有的套殼 ChatGPT 應用都是基于這個接口封裝的,所以將其放在第一個。給定一組描述對話的消息列表,模型將返回一個回復。
ini復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")# https://api.openai.com/v1/chat/completions
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": "Hello!"}]
)print(completion.choices[0].message)
響應 :
swift復制代碼{"id": "chatcmpl-123","object": "chat.completion","created": 1677652288,"choices": [{"index": 0,"message": {"role": "assistant","content": "\n\nHello there, how may I assist you today?",},"finish_reason": "stop"}],"usage": {"prompt_tokens": 9,"completion_tokens": 12,"total_tokens": 21}
}
Request body(常用入參詳解) :
model(string,必填)要使用的模型 ID。有關哪些模型適用于 Chat API 的詳細信息,請查看 模型端點兼容性表
messages(array,必填)迄今為止描述對話的消息列表
role(string,必填)發送此消息的角色。
system、user或assistant之一(一般用 user 發送用戶問題,system 發送給模型提示信息)
content(string,必填)消息的內容
name(string,選填)此消息的發送者姓名。可以包含 a-z、A-Z、0-9 和下劃線,最大長度為 64 個字符
stream(boolean,選填,是否按流的方式發送內容)當它設置為 true 時,API 會以 SSE( Server Side Event )方式返回內容。SSE 本質上是一個長鏈接,會持續不斷地輸出內容直到完成響應。如果不是做實時聊天,默認 false 即可。請參考 OpenAI Cookbook 以獲取 示例代碼。
max_tokens(integer,選填)在聊天補全中生成的最大 tokens 數。
輸入 token 和生成的 token 的總長度受模型上下文長度的限制。
temperature(number,選填,默認是 1)采樣溫度,在 0 和 2 之間。
較高的值,如 0.8 會使輸出更隨機,而較低的值,如 0.2 會使其更加集中和確定性。
通常建議修改這個(
temperature)或者top_p,但兩者不能同時存在,二選一。
Completions (文本和代碼)補全
給定一個提示,模型將返回一個或多個預測的補全,并且還可以在每個位置返回替代 token 的概率。
ini復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/completions
openai.Completion.create(model="text-davinci-003",prompt="Say this is a test",max_tokens=7,temperature=0
)
響應 :
swift復制代碼 "id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7","object": "text_completion","created": 1589478378,"model": "text-davinci-003","choices": [{"text": "\n\nThis is indeed a test","index": 0,"logprobs": null,"finish_reason": "length"}],"usage": {"prompt_tokens": 5,"completion_tokens": 7,"total_tokens": 12}
}
Request body(入參詳解) :
model(string,必填)要使用的模型的 ID。可以參考 模型端點兼容性表
prompt(string or array,選填,Defaults to <|endoftext|>)生成補全的提示,編碼為字符串、字符串數組、token 數組或 token 數組數組。
注意 <|endoftext|> 是模型在訓練過程中看到的文檔分隔符,所以如果沒有指定提示符,模型將像從新文檔的開頭一樣生成。
stream(boolean,選填,默認 false)當它設置為 true 時,API 會以 SSE( Server Side Event )方式返回內容,即會不斷地輸出內容直到完成響應,流通過
data: [DONE]消息終止。
max_tokens(integer,選填,默認是 16)補全時要生成的最大 token 數。
提示
max_tokens的 token 計數不能超過模型的上下文長度。大多數模型的上下文長度為 2048 個 token(最新模型除外,它支持 4096)
temperature(number,選填,默認是 1)使用哪個采樣溫度,在 0 和 2 之間。
較高的值,如 0.8 會使輸出更隨機,而較低的值,如 0.2 會使其更加集中和確定性。
通常建議修改這個(
temperature)或top_p但兩者不能同時存在,二選一。
n(integer,選填,默認為 1)每個
prompt生成的補全次數。注意:由于此參數會生成許多補全,因此它會快速消耗 token 配額。小心使用,并確保對
max_tokens和stop進行合理的設置。
Embeddings 嵌入
將一個給定輸入轉換為向量表示,提供給機器學習模型算法使用。
ini復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/embeddings
openai.Embedding.create(model="text-embedding-ada-002",input="The food was delicious and the waiter..."
)
響應 :
css復制代碼{"object": "list","data": [{"object": "embedding","embedding": [0.0023064255,-0.009327292,.... (1536 floats total for ada-002)-0.0028842222,],"index": 0}],"model": "text-embedding-ada-002","usage": {"prompt_tokens": 8,"total_tokens": 8}
}
Request body(入參詳解) :
model(string,必填)要使用的 模型 ID,可以參考 模型端點兼容性表
input(string or array,必填)輸入文本以獲取嵌入,編碼為字符串或 token 數組。要在單個請求中獲取多個輸入的嵌入,請傳遞字符串數組或 token 數組的數組。每個輸入長度不得超過 8192 個 token。
user(string,選填)一個唯一的標識符,代表終端用戶,可以幫助 OpenAI 檢測濫用。
Fine-tuning 微調
使用自定義的特定訓練數據,定制自己的模型。
Create fine-tune
創建一個微調作業,從給定的數據集中微調指定模型。
ini復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# POST https://api.openai.com/v1/fine-tunes
openai.FineTune.create(training_file="file-XGinujblHPwGLSztz8cPS8XY")
響應(響應包括已入隊的作業的詳細信息,包括微調作業狀態和完成后微調模型的名稱):
json復制代碼{"id": "ft-AF1WoRqd3aJAHsqc9NY7iL8F","object": "fine-tune","model": "curie","created_at": 1614807352,"events": [{"object": "fine-tune-event","created_at": 1614807352,"level": "info","message": "Job enqueued. Waiting for jobs ahead to complete. Queue number: 0."}],"fine_tuned_model": null,"hyperparams": {"batch_size": 4,"learning_rate_multiplier": 0.1,"n_epochs": 4,"prompt_loss_weight": 0.1,},"organization_id": "org-...","result_files": [],"status": "pending","validation_files": [],"training_files": [{"id": "file-XGinujblHPwGLSztz8cPS8XY","object": "file","bytes": 1547276,"created_at": 1610062281,"filename": "my-data-train.jsonl","purpose": "fine-tune-train"}],"updated_at": 1614807352,
}
Request body(入參詳解) :
training_file(string,必填)包含 訓練數據 的已上傳文件的 ID。
請參閱 upload file 以了解如何上傳文件。
數據集必須格式化為 JSONL 文件,其中每個訓練示例都是一個帶有 “prompt” 和 “completion” keys 的 JSON 對象。
validation_file(string,選填)包含 驗證數據 的已上傳文件的 ID。
如果提供此文件,則數據將在微調期間定期用于生成驗證指標。這些指標可以在 微調結果文件 中查看,訓練和驗證數據應該是互斥的。
model(string,選填,默認是 curie)要微調的基礎模型名稱。
可以選擇其中之一:“ada”、“babbage”、“curie”、“davinci”,或 2022 年 4 月 21 日 后創建的經過微調的模型。要了解這些模型的更多信息,請參閱 Models 文檔。
n_epochs(integer,選填,默認是 4)訓練模型的批次數。一個 epoch 指的是完整地遍歷一次訓練數據集
batch_size(integer,選填)用于訓練的批次大小,指的是每次迭代中同時處理的樣本數量。
默認情況下,批次大小將動態配置為訓練集示例數量的約 0.2%,上限為 256。
通常,發現較大的批次大小對于更大的數據集效果更好。
learning_rate_multiplier(number,選填)用于訓練的學習率倍增器。微調學習率是預訓練時使用的原始學習率乘以此值得到的(🤖? 微調學習率(Learning Rate)指的是神經網絡在進行梯度下降優化算法時,每次更新參數的步長。學習率越大,神經網絡的參數更新越快,但可能會導致優化過程不穩定甚至無法收斂;學習率越小,神經網絡的參數更新越慢,但可能會導致優化過程過于緩慢或者陷入局部最優解。)
默認情況下,學習率的倍增器為 0.05、0.1 或 0.2,具體取決于最終
batch_size(較大的批次大小通常使用較大的學習率效果更好),建議嘗試在 0.02 到 0.2 范圍內實驗不同值以找出產生最佳結果的值。
prompt_loss_weight(number,選填,默認是 0.01)“prompt_loss_weight” 是指在使用 Prompt-based Learning(基于提示的學習)方法進行訓練時,用于調整提示損失(Prompt Loss)對總體損失(Total Loss)的相對權重。
Prompt-based Learning 是一種利用人類先驗知識來輔助神經網絡學習的方法,其中提示損失是指利用人類先驗知識設計的提示(Prompt)與模型生成的結果之間的損失。
在 Prompt-based Learning 中,通過調整 prompt_loss_weight 的大小來平衡總體損失和提示損失的貢獻,從而使模型更好地利用人類先驗知識進行預測。如果 prompt_loss_weight 較大,模型會更加依賴提示損失,更好地利用人類先驗知識;如果 prompt_loss_weight 較小,模型會更加依賴總體損失,更好地適應當前數據集的特征和分布。
compute_classification_metrics(boolean,選填,默認是 false)如果設置了,會在每個 epoch 結束時使用驗證集計算特定于分類的指標,例如準確率和 F-1 分數。這些指標可以在 微調結果文件 中查看。為了計算分類指標,必須提供一個
validation_file(驗證文件)。此外,對于多類分類,必須指定
classification_n_classes;對于二元分類,則需要指定classification_positive_class。
suffix(string,選填,默認為 null)一個長度最多為 40 個字符 的字符串,將被添加到微調模型名稱中。
例如,
suffix為 “custom-model-name” 會生成一個模型名稱,如ada:ft-your-org:custom-model-name-2022-02-15-04-21-04。
List fine-tunes
列出所屬組織下的微調作業列表
arduino復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# GET https://api.openai.com/v1/fine-tunes
openai.FineTune.list()
響應 :
json復制代碼{"object": "list","data": [{"id": "ft-AF1WoRqd3aJAHsqc9NY7iL8F","object": "fine-tune","model": "curie","created_at": 1614807352,"fine_tuned_model": null,"hyperparams": { ... },"organization_id": "org-...","result_files": [],"status": "pending","validation_files": [],"training_files": [ { ... } ],"updated_at": 1614807352,},{ ... },{ ... }]
}
Retrieve fine-tune
獲取有關微調作業的信息
ini復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/fine-tunes/{fine_tune_id}
openai.FineTune.retrieve(id="ft-AF1WoRqd3aJAHsqc9NY7iL8F")
響應 :
css復制代碼{"id": "ft-AF1WoRqd3aJAHsqc9NY7iL8F","object": "fine-tune","model": "curie","created_at": 1614807352,"events": [{"object": "fine-tune-event","created_at": 1614807352,"level": "info","message": "Job enqueued. Waiting for jobs ahead to complete. Queue number: 0."},{"object": "fine-tune-event","created_at": 1614807356,"level": "info","message": "Job started."},{"object": "fine-tune-event","created_at": 1614807861,"level": "info","message": "Uploaded snapshot: curie:ft-acmeco-2021-03-03-21-44-20."},{"object": "fine-tune-event","created_at": 1614807864,"level": "info","message": "Uploaded result files: file-QQm6ZpqdNwAaVC3aSz5sWwLT."},{"object": "fine-tune-event","created_at": 1614807864,"level": "info","message": "Job succeeded."}],"fine_tuned_model": "curie:ft-acmeco-2021-03-03-21-44-20","hyperparams": {"batch_size": 4,"learning_rate_multiplier": 0.1,"n_epochs": 4,"prompt_loss_weight": 0.1,},"organization_id": "org-...","result_files": [{"id": "file-QQm6ZpqdNwAaVC3aSz5sWwLT","object": "file","bytes": 81509,"created_at": 1614807863,"filename": "compiled_results.csv","purpose": "fine-tune-results"}],"status": "succeeded","validation_files": [],"training_files": [{"id": "file-XGinujblHPwGLSztz8cPS8XY","object": "file","bytes": 1547276,"created_at": 1610062281,"filename": "my-data-train.jsonl","purpose": "fine-tune-train"}],"updated_at": 1614807865,
}
Cancel fine-tune
立即取消微調工作
ini復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/fine-tunes/{fine_tune_id}/cancel
openai.FineTune.cancel(id="ft-AF1WoRqd3aJAHsqc9NY7iL8F")
響應 :
json復制代碼{"id": "ft-xhrpBbvVUzYGo8oUO1FY4nI7","object": "fine-tune","model": "curie","created_at": 1614807770,"events": [ { ... } ],"fine_tuned_model": null,"hyperparams": { ... },"organization_id": "org-...","result_files": [],"status": "cancelled","validation_files": [],"training_files": [{"id": "file-XGinujblHPwGLSztz8cPS8XY","object": "file","bytes": 1547276,"created_at": 1610062281,"filename": "my-data-train.jsonl","purpose": "fine-tune-train"}],"updated_at": 1614807789,
}
List fine-tune events
獲取微調作業各階段運行狀態(事件)詳情
ini復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/fine-tunes/{fine_tune_id}/events
openai.FineTune.list_events(id="ft-AF1WoRqd3aJAHsqc9NY7iL8F")
響應 :
css復制代碼{"object": "list","data": [{"object": "fine-tune-event","created_at": 1614807352,"level": "info","message": "Job enqueued. Waiting for jobs ahead to complete. Queue number: 0."},{"object": "fine-tune-event","created_at": 1614807356,"level": "info","message": "Job started."},{"object": "fine-tune-event","created_at": 1614807861,"level": "info","message": "Uploaded snapshot: curie:ft-acmeco-2021-03-03-21-44-20."},{"object": "fine-tune-event","created_at": 1614807864,"level": "info","message": "Uploaded result files: file-QQm6ZpqdNwAaVC3aSz5sWwLT."},{"object": "fine-tune-event","created_at": 1614807864,"level": "info","message": "Job succeeded."}]
}
Query parameters :
stream(boolean,選填)對于微調作業運行狀態是否以事件流的方式返回
如果設置為 true,則會不斷地輸出微調作業運行最新狀態信息,直到微調作業完成(成功、取消或失敗)時,以
data:[DONE]消息終止。如果設置為 false,則僅返回到目前為止生成的事件。
Delete fine-tune model
刪除微調的模型(前提是有權限)
arduino復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/models/{model}
openai.Model.delete("curie:ft-acmeco-2021-03-03-21-44-20")
響應 :
json復制代碼{"id": "curie:ft-acmeco-2021-03-03-21-44-20","object": "model","deleted": true
}
Models 模型管理
列出并描述 API 中可用的各種模型,可以參考 模型文檔 以了解可用的模型以及它們之間的差異。
列出模型
列出當前可用的模型,并提供有關每個模型的基本信息,例如所有者和可用性。
arduino復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/models
openai.Model.list()
響應 :
css復制代碼{"data": [{"id": "model-id-0","object": "model","owned_by": "organization-owner","permission": [...]},{"id": "model-id-1","object": "model","owned_by": "organization-owner","permission": [...]},{"id": "model-id-2","object": "model","owned_by": "openai","permission": [...]},],"object": "list"
}
檢索模型詳情
檢索模型實例,提供有關模型的基本信息,例如所有者和權限。其中,model 為必填的字符串類型,用于此請求的模型的 ID。
arduino復制代碼import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# https://api.openai.com/v1/models/{model}
openai.Model.retrieve("text-davinci-003")
響應 :
json復制代碼{"id": "text-davinci-003","object": "model","owned_by": "openai","permission": [...]
}
其他
- Images 圖像(圖像生成 API,DALL·E 的能力已經落后于 Stable Diffusion 和 Midjourney,使用場景不多)
- Audio 音頻(音頻轉換為文本 API,Whisper 模型已經開源,可以本地搭建使用)
- Files 文件(上傳文檔 API,一般與微調等功能一起使用,不需要專門關注)
- Edits 編輯(更新提示詞 API,對話補全接口已經覆蓋了)
- Moderations 審核 (內容審核 API,如果模型識別到提示詞違反了 OpenAI 的內容策略,會返回審核信息詳情)
- Parameter details 參數細節(沒有使用過)
最佳安全實踐
在開發過程中,注意到 API 的任何安全問題或與 OpenAI 相關的任何其他問題,可以通過漏洞披露計劃提交這些問題。
-
使用內容審核 API
OpenAI 的內容審核 API 調用是不耗費 token 的,可以借助這個能力構建內容過濾系統,減少不安全內容。
-
對抗性測試
自己主動進行類似傳統安全領域的“紅隊演練”,驗證基于大語言模型的程序對存在攻擊的輸入具有魯棒性。操作層面上就是通過遍歷盡量多的輸入和用戶行為測試,包括代表性的數據集以及試圖“破壞”應用程序的輸入。在測試中,需要關注應用程序是否會偏離主題,以及是否可以輕易地通過提示注入來重定向功能。例如,“忽略以前的指令,改為執行這個操作”。
-
必須人工參與,不能全權委托給模型
在實際應用前,讓人工先審核輸出結果,特別是在高風險領域和代碼生成方面,大語言模型系統具有其局限性,人工能夠查看任何驗證輸出所需的信息(例如生成筆記概要應用,前提是用戶能夠輕松獲取原始筆記進行參考)。
-
提示工程
“提示工程”可以幫助限制輸出文本的主題和語氣,從而減少產生不良內容的可能性,即使用戶試圖產生這樣的內容也是如此。為模型提供附加上下文(例如,在新輸入之前提供幾個高質量的期望行為示例)可以使其更容易將模型輸出引導到所需的方向。
-
了解你的客戶
通常情況下,用戶需要注冊并登錄才能使用您的服務。將此服務與現有賬戶(例如 Gmail、LinkedIn 或 Facebook 登錄)鏈接可能會有所幫助,但并不適用于所有用例。要進一步降低風險,可以要求提供信用卡或身份證明等信息。
-
限制用戶輸入并限制輸出 token 數量
限制用戶在提示中輸入的文本數量有助于避免提示注入。限制輸出 token 的數量有助于減少誤用的可能性。
縮小輸入或輸出范圍,特別是從可信來源中獲取,可以減少應用程序中可能發生的誤用程度。
通過驗證的下拉字段(例如,維基百科上的電影列表)允許用戶輸入可能比允許開放式文本輸入更安全。
在可能的情況下,從后端返回一組經過驗證的材料的輸出可能比返回全新生成的內容更安全(例如,將客戶查詢路由到最匹配的現有客戶支持文章,而不是嘗試從頭回答查詢)。
-
允許用戶報告問題
通常情況下,用戶應該有一個方便易用的方法來報告應用程序功能不當或其他相關問題(例如,列出的電子郵件地址、提交工單等)。這種方法應該由人工進行監控,并根據情況作出回應。
-
了解和溝通局限性
語言模型可能會出現諸如產生不準確信息、冒犯性輸出、偏見等問題,這些問題可能需要進行顯著的修改才能適用于每個用例。在考慮使用語言模型之前,請評估模型是否適合您的目的,并在廣泛的潛在輸入上測試 API 的性能,以確定 API 性能可能下降的情況。同時,考慮您的客戶群體以及他們將要使用的輸入范圍,并確保他們的期望得到適當的調整。
-
終端用戶 ID
在請求中發送終端用戶 ID 可以幫助 OpenAI 監測和檢測濫用行為,這是一個有用的工具,這可以讓 OpenAI 在檢測到應用程序違反任何政策的情況下,提供更具有操作性的反饋。
這些 ID 應該是一個字符串,用于唯一標識每個用戶。建議對其用戶名或電子郵件地址進行哈希處理,以避免發送任何身份信息。如果向非登錄用戶提供產品預覽,可以發送一個會話 ID。
可以通過
user參數在 API 請求中包含終端用戶 ID,如下所示:ini復制代碼response = openai.Completion.create(model="text-davinci-003",prompt="This is a test",max_tokens=5,user="user123456" )
最佳生產實踐
本指南提供了一套全面的最佳實踐,可幫助您從原型過渡到生產。無論您是經驗豐富的機器學習工程師還是新近的愛好者,本指南都將為您提供成功將平臺投入生產環境所需的工具:從保護對我們 API 的訪問到設計一個能夠處理大流量的強大架構。使用本指南幫助您制定一個盡可能順利和有效的應用程序部署計劃。
-
設置您的組織
一旦您登錄到 OpenAI 帳戶,您可以在組織設置中找到組織名稱和 ID。組織名稱是您的組織的標簽,顯示在用戶界面中。組織 ID 是您的組織的唯一標識符,可用于 API 請求中。
屬于多個組織的用戶可以傳遞一個標題來指定用于 API 請求的組織。這些 API 請求的使用將計入指定組織的配額。如果沒有提供標題,則會計費默認組織。您可以在用戶設置中更改默認組織。
您可以從成員設置頁面邀請新成員加入您的組織。成員可以是閱讀者或所有者。閱讀者可以進行 API 請求并查看基本組織信息,而所有者可以修改計費信息并管理組織中的成員。
-
管理計費限額
新的免費試用用戶將獲得 5 美元的初始信用額,有效期為三個月。一旦信用額已被使用或到期,您可以選擇輸入計費信息以繼續使用 API。如果沒有輸入計費信息,您仍然可以登錄訪問,但將無法進行任何進一步的 API 請求。
一旦您輸入了計費信息,您將獲得 OpenAI 設置的每月 120 美元的批準使用限制。如果您想增加超過每月 120 美元的配額,請提交配額增加請求。
如果您希望在使用量超過一定金額時收到通知,您可以通過使用限制頁面設置軟限制。當達到軟限制時,組織的所有者將收到電子郵件通知。您還可以設置硬限制,以便一旦達到硬限制,任何后續的 API 請求都將被拒絕。請注意,這些限制是盡力而為,使用量和限制之間可能會有 5 到 10 分鐘的延遲。
-
API 密鑰
OpenAI API 使用 API 密鑰進行身份驗證。訪問您的 API 密鑰頁面以檢索您將在請求中使用的 API 密鑰。
這是一種相對簡單的控制訪問方式,但您必須注意保護這些密鑰。避免在您的代碼或公共存儲庫中公開 API 密鑰;相反,將它們存儲在安全的位置。您應該使用環境變量或密鑰管理服務將您的密鑰暴露給您的應用程序,這樣您就不需要在代碼庫中硬編碼它們。
-
暫存帳戶
隨著規模的擴大,您可能希望為暫存和生產環境創建單獨的組織。請注意,您可以使用兩個單獨的電子郵件地址(例如 bob+prod@widgetcorp.com 和 bob+dev@widgetcorp.com)進行注冊,以創建兩個組織。這將允許您隔離您的開發和測試工作,這樣您就不會意外地中斷您的實時應用程序。您還可以通過這種方式限制對生產組織的訪問。
-
擴展您的解決方案架構
當設計你的應用程序或服務使用我們的 API 進行生產時,重要的是要考慮你將如何擴展以滿足流量需求。無論你選擇什么樣的云服務提供商,你都需要考慮幾個關鍵領域:
橫向擴展:你可能想橫向擴展你的應用程序,以適應來自多個來源的應用程序的請求。這可能涉及到部署額外的服務器或容器來分配負載。如果你選擇這種類型的擴展,請確保你的架構是為處理多個節點而設計的,并且你有機制來平衡它們之間的負載。
垂直擴展:另一個選擇是縱向擴展你的應用程序,這意味著你可以加強單個節點的可用資源。這將涉及升級你的服務器的能力,以處理額外的負載。如果你選擇這種類型的擴展,確保你的應用程序被設計成可以利用這些額外的資源。 緩存:通過存儲經常訪問的數據,你可以提高響應時間,而不需要重復調用我們的 API。你的應用程序將需要被設計成盡可能地使用緩存數據,并在添加新信息時使緩存失效。有幾種不同的方法可以做到這一點。例如,你可以將數據存儲在數據庫、文件系統或內存緩存中,這取決于什么對你的應用程序最有意義。 負載平衡:最后,考慮負載平衡技術,以確保請求被均勻地分布在你的可用服務器上。這可能涉及到在你的服務器前使用一個負載平衡器或使用 DNS 輪流。平衡負載將有助于提高性能和減少
-
延遲
延遲是處理請求和返回響應所需的時間,完成請求的延遲主要受兩個因素影響:模型和生成的 token 數量。完成請求的生命周期如下所示(大部分延遲通常來自 token 生成步驟):
- 網絡:最終用戶到 API 延遲
- 服務器:處理提示 token 的時間
- 服務器:采樣/生成 to ken 的時間
- 網絡:API 到最終用戶延遲
-
影響延遲的常見因素和可能的緩解技術
現在我們已經了解了延遲的基礎知識,讓我們看一下可能影響延遲的各種因素,大致按照從影響最大到最小的順序排列。
-
模型
我們的 API 提供了不同程度的復雜性和通用性的不同模型。最有能力的模型,例如
gpt-4,可以生成更復雜和多樣化的完成,但它們也需要更長的時間來處理您的查詢。gpt-3.5-turbo等模型可以生成更快、更便宜的聊天完成,但它們生成的結果可能不太準確或與您的查詢不相關。您可以選擇最適合您的用例的模型以及速度和質量之間的權衡。 -
補全 token 的數量
請求大量生成的 token 完成會導致延遲增加:
- 較低的最大 token 數:對于具有相似 token 生成計數的請求,具有較低
max_tokens參數的請求會產生較少的延遲。 - 包括停止序列:為防止生成不需要的 token,請添加停止序列。例如,您可以使用停止序列生成包含特定數量項目的列表。在這種情況下,通過使用
11.作為停止序列,您可以生成一個只有 10 個項目的列表,因為當到達11.時完成將停止。 - 生成更少的完成:盡可能降低
n和best_of的值,其中n是指為每個提示生成多少個完成,best_of用于表示每個標記具有最高對數概率的結果。如果n和best_of都等于 1(這是默認值),則生成的 token 數最多等于max_tokens。如果n(返回的完成數)或best_of(生成以供考慮的完成數)設置為> 1,每個請求將創建多個輸出。在這里,您可以將生成的 token 數視為[ max_tokens * max (n, best_of) ]
- 較低的最大 token 數:對于具有相似 token 生成計數的請求,具有較低
-
流式傳輸
在請求中設置
stream: true會使模型在 token 可用時立即開始返回 token,而不是等待生成完整的 token 序列。它不會改變獲取所有 token 的時間,但它會減少我們想要顯示部分進度或將停止生成的應用程序的第一個 token 的時間。這可能是更好的用戶體驗和 UX 改進,因此值得嘗試流式傳輸。 -
批處理
根據您的用例,批處理可能會有所幫助。如果您向同一個端點發送多個請求,您可以批處理要在同一個請求中發送的提示。這將減少您需要提出的請求數量。 prompt 參數最多可以包含 20 個不同的提示。我們建議您測試此方法,看看是否有幫助。在某些情況下,您最終可能會增加生成的 token 數量,這會減慢響應時間。
-
-
MLOps 策略
當您將原型投入生產時,您可能需要考慮制定 MLOps 策略。 MLOps(機器學習操作)是指管理機器學習模型的端到端生命周期的過程,包括您可能使用我們的 API 進行微調的任何模型。設計 MLOps 策略時需要考慮多個方面。這些包括
- 數據和模型管理:管理用于訓練或微調模型以及跟蹤版本和更改的數據。
- 模型監控:隨著時間的推移跟蹤模型的性能并檢測任何潛在的問題或退化。
- 模型再訓練:確保您的模型與數據變化或不斷變化的需求保持同步,并根據需要進行再訓練或微調。
- 模型部署:自動化將模型和相關工件部署到生產中的過程。
讀者福利:如果大家對大模型感興趣,這套大模型學習資料一定對你有用
對于0基礎小白入門:
如果你是零基礎小白,想快速入門大模型是可以考慮的。
一方面是學習時間相對較短,學習內容更全面更集中。
二方面是可以根據這些資料規劃好學習計劃和方向。
資源分享

大模型AGI學習包


資料目錄
- 成長路線圖&學習規劃
- 配套視頻教程
- 實戰LLM
- 人工智能比賽資料
- AI人工智能必讀書單
- 面試題合集
《人工智能\大模型入門學習大禮包》,可以掃描下方二維碼免費領取!

1.成長路線圖&學習規劃
要學習一門新的技術,作為新手一定要先學習成長路線圖,方向不對,努力白費。
對于從來沒有接觸過網絡安全的同學,我們幫你準備了詳細的學習成長路線圖&學習規劃。可以說是最科學最系統的學習路線,大家跟著這個大的方向學習準沒問題。
2.視頻教程
很多朋友都不喜歡晦澀的文字,我也為大家準備了視頻教程,其中一共有21個章節,每個章節都是當前板塊的精華濃縮。
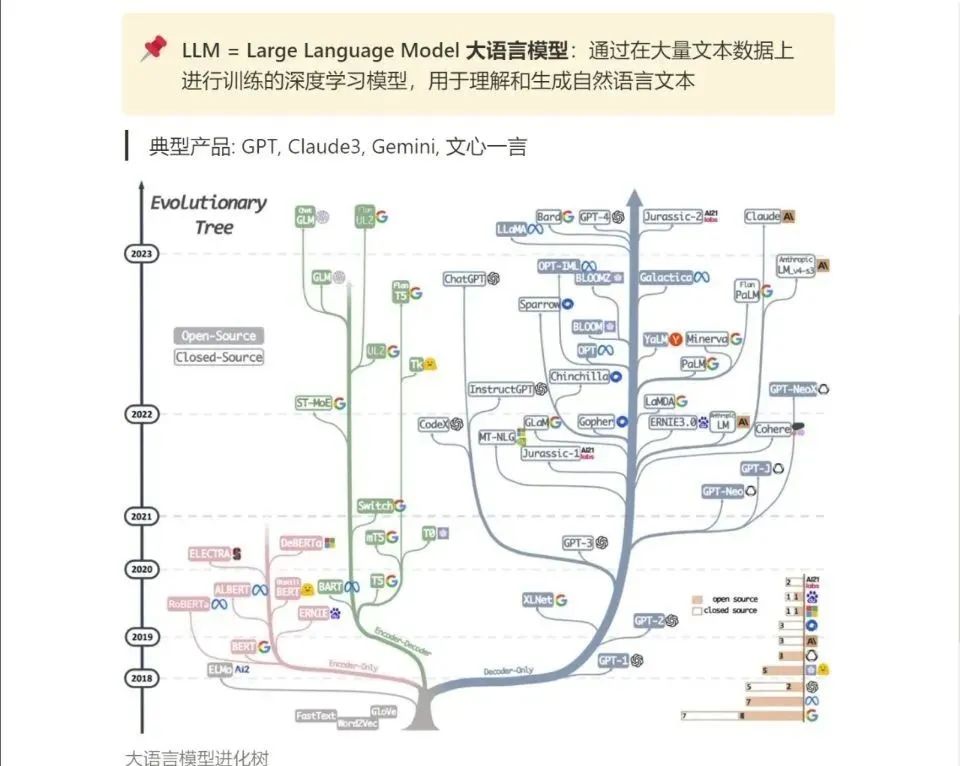
3.LLM
大家最喜歡也是最關心的LLM(大語言模型)
《人工智能\大模型入門學習大禮包》,可以掃描下方二維碼免費領取!


:內存函數)








)




![[leetcode hot 150]第五百三十題,二叉搜索樹的最小絕對差](http://pic.xiahunao.cn/[leetcode hot 150]第五百三十題,二叉搜索樹的最小絕對差)


