文章目錄
- 題目
- 摘要
- 方法
- 實驗
- 消融實驗
題目
大語言模型融合知識圖譜的問答系統研究

論文地址:http://fcst.ceaj.org/CN/10.3778/j.issn.1673-9418.2308070
項目地址:https://github.com/zhangheyi-1/llmkgqas-tcm/
摘要
????問答系統(Question Answering,QA)能夠自動回答用戶提出的自然語言問題,是信息檢索和自然語言處理的交叉研究方向,將知識圖譜(Knowledge Graph,KG)與問答系統融合,正確理解用戶語義是一大挑戰。雖然知識圖譜問答能夠通過對問題進行分析理解,最終獲取答案,但面對自然語言的靈活性與模糊性,如何處理復雜問題的語義信息、如何提高復雜推理問答的高效性仍是研究難點。
????近年來,大型語言模型(Large Language Models,LLM)在多種自然語言處理任務上取得了令人印象深刻的結果,并表現出若干涌現能力。Instruct GPT、ChatGPT1、GPT4等自回歸大型語言模型通過預訓練、微調(Fine-tuning)等技術理解并遵循人類指令,使得其能夠正確理解并回答復雜問題。LLM在各種自然語言處理任務上表現卓越,甚至能夠在從未見過的任務上表現出不錯的性能,這為正確處理復雜問題展示了統一解決方案潛力。然而,這些模型都存在一些固有局限性,包括處理中文能力較差,部署困難,無法獲得關于最近事件的最新信息以及產生有害幻覺事實(Hallucinatory Fact)等。由于這些局限性,將大型語言模型直接應用于專業領域問答仍然存在諸多問題。
????一方面難以滿足大型語言模型對于硬件資源的要求;另一方面,面對專業領域,大型語言模型的能力仍然有所不足。面對專業領域的問題,大型語言模型的生成結果可能缺乏真實性和準確性,甚至會產生“幻覺事實”。為了增強大型語言模型應對專業領域問題的能力,很多工作采取數據微調的方式修改模型參數,從而讓大模型具有更高的專業能力,然而一些文獻指出這些數據微調的方法會產生災難性遺忘(Catastrophic Forgetting),致使模型原始對話能力喪失,甚至在處理非微調數據時會出現混亂結果。為了應對這些問題,本文結合大型語言模型與知識圖譜,設計了一種應用于專業領域的問答系統。該問答系統通過將知識庫(Knowledge Base ,KB)中的文本知識、知識圖譜的結構化知識、大型語言模型中的參數化知識三者融合,生成專業問答結果,因此無需使用數據微調的方式修改模型參數,就能夠理解用戶語義并回答專業領域的問題。同時,通過采用類似于ChatGLM-6B這樣對硬件資源要求較低的模型,以降低硬件對系統的約束。另外,隨著大型語言模型技術的發展,研究認知智能范式的轉變,是接下來的研究重點,如何將大型語言模型與知識圖譜進行有效結合是一個值得研究的課題。因此,本文以研究問答系統的形式,進一步研究大型語言模型+知識圖譜的智能信息系統新范式,探索知識圖譜與大型語言模型的深度結合,利用專業性知識圖譜來增強LLM的生成結果,并利用LLM理解語義抽取實體對知識圖譜進行檢索與增強。
????本文主要貢獻有兩點:1.提出大型語言模型+專業知識庫的基于提示學習(Prompt Learning)的問答系統范式,以解決專業領域問答系統數據+微調范式帶來的災難性遺忘問題。在提升大模型專業能力的同時,保留其回答通用問題的能力。并在硬件資源不足的情況下,選擇較小的大模型部署專業領域的問答系統,實現能和較大的大模型在專業領域相媲美甚至更好效果。2.探索了大型語言模型和知識圖譜兩種知識范式的深度結合。實現了將大型語言模型和知識圖譜的雙向鏈接,可以將易讀的自然語言轉換為結構化的數據進而和知識圖譜中的結構化數據匹配以增強回答專業性;可以將KG中的結構化知識轉換為更易讀的自然語言知識來方便人們理解。
方法
????系統實現了以下功能:信息過 濾、專業問答、抽取轉化。 為了實現這些功能,系統基于專業知識與大語言模型,利用 LangChain 將兩者結合,設計并實現了大型語言模型與知識圖譜的深度結合新模式。信息過濾模塊旨在減少大型語言模型生成虛假信息的可能性,以提高回答的準確性。專業問答模塊通過將專業知識庫與大型語言模型結合, 提供專業性的回答。這種方法避免了重新訓練大語言模型所需的高硬件要求和可能導致的災難性遺忘后果。
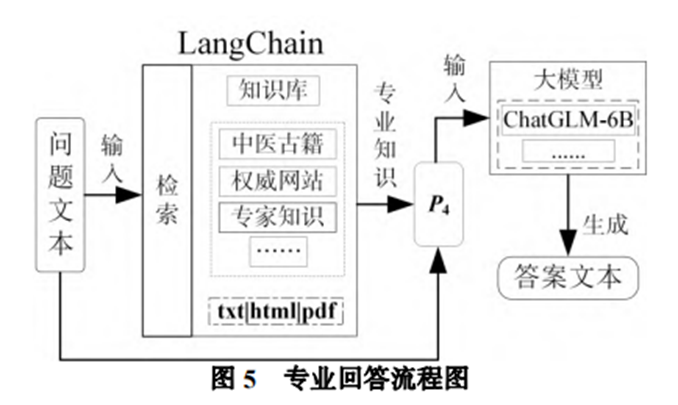
????抽取轉化(從自然語言文本抽取出知識圖譜結構化數據;將知識圖譜結構化數據轉化為自然語言文本)是為了進一步探索問答系統新范式而設計。一方面基于大型語言模型提取出專業知識, 將知識圖譜結構化數據轉化為自然語言文本,易于用戶理解;另一方面利用知識抽取出三元組和知識圖譜對比驗證,可以增強大語言模型回答專業性,同時抽取出的三元組在經專家驗證后可 以插入知識圖譜中以增強知識圖譜。除此之外, 本系統還實現了用戶友好的交互服務。如下圖所示,系統交互流程是(1)用戶向系統提出問題,問題通過信息過濾后,與知識庫中的相關專業知識組成提示,輸入到專業問答模塊中得到答案;(2)信息抽取模塊從回答中提取出三元組,與知識圖譜進行匹配,獲取相關節點數據;(3)這些節點數據可以經用戶選擇后,同樣以提示的形式輸入專業問答模塊得到知識圖譜增強的回答。這種雙向交互實現了大型語言模型和知識圖譜的深度結合。
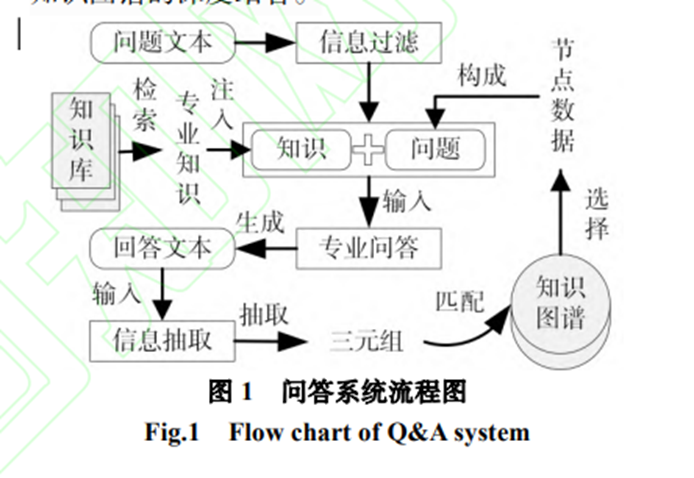
????總而言之,本文提出的專業問答系統通過大語言模型與知識圖譜深度結合,實現了專業的垂直領域問答效果,并提供用戶友好的交互服務。 系統的信息過濾模塊減少了虛假信息生成的可能性,專業問答模塊提供了專業性的回答,抽取轉化模塊進一步增強了回答的專業性,并可以對結構化數據進行解釋,降低用戶理解難度,同時可用專家確認無誤的知識進一步增強知識圖譜。這種新的問答系統范式為用戶提供了更準確、更專業的答案,同時保持了用戶友好的交互體驗。
????從數據構造與預處理、信息過濾、專業問 答、抽取轉化四個方面,以中醫藥方劑領域的應用為例,介紹如何構建系統。 本文針對專業領域,收集相關領域數據進行預處理,設計流程來訓練一套易于部署的專業領域問答系統,并探索大型語言模型與知識圖譜的融合。 該系統具備三種能力:(1)信息過濾;(2)專業問答;(3)抽取轉化。
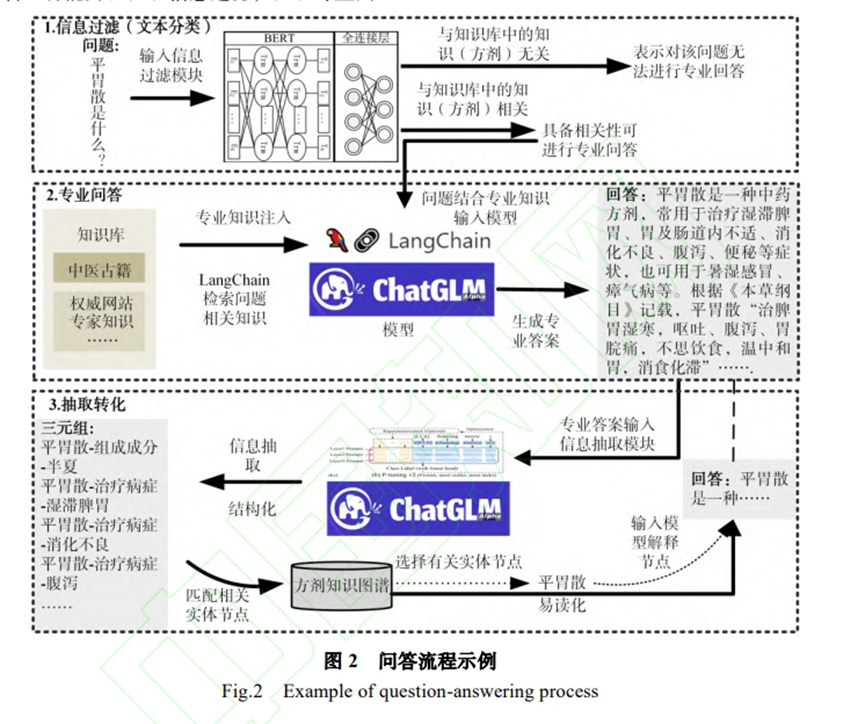
????以中醫藥方劑專業領域為例展示了該系統的問答流程。首先,對輸入的中醫藥方劑相關問題文本進行信息過濾,即文本分類,判斷出該文本是否與中醫藥方劑相關,然后通過 LangChain 在知識庫中檢索與文本相關的知識,以提示的方式和問題一起輸入大模型(ChatGLM-6B),大模型通過推理生成具備專業知識的答案。然后對該回答進行知識抽取,從回答中抽取出三元組。將抽取出的三元組和已有的方劑知識圖譜進行匹配,以驗證回答的專業性,同時可將知識圖譜中的節點以問題的形式輸入大模型,獲取易讀的自然語言解釋,從而實現了大模型和知識圖譜的雙向轉換。
????本系統的實現需要收集整理專業數據集,以支持系統的實現。本文基于多種數據構造系統所需的數據集、知識庫,并對這些數據進行數據預處理。 (1)基于已有的專業領域數據集。本文直接搜集專業領域已有的相關數據集,參考其構成,從中整理篩選出所需的數據。對于中醫藥方劑領域,參考以下數據集整理并構建相關專業數據 : MedDialog、CBLUE、COMETA、CMeKG。 相關介紹如下表所示:
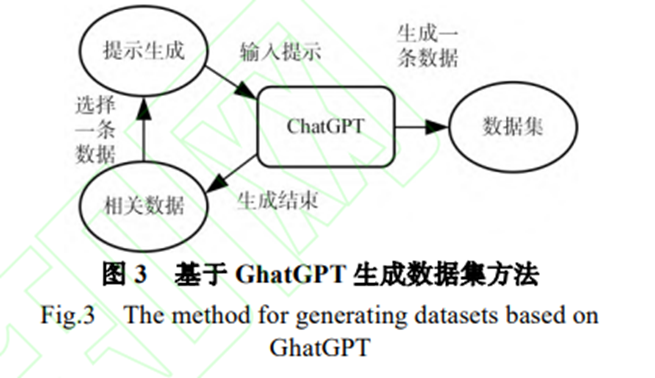
????權威數據從專業書籍或權威網站收集。這部分數據來自于相關領域的專業書籍和權威網站,用于構建知識庫,為大模型的回答提供專業知識支撐。對于中醫藥方劑領域,主要基于方劑學等專業書籍構建了中醫藥方劑專業知識庫,同 時從 NMPA(國家藥品監督管理局)、藥融云-中醫藥數據庫群、TCMID 中醫藥數據庫、中醫藥證候關聯數據庫等專業權威網站收集中醫藥方劑領域的相關數據知識。 (3)問題數據。問題數據用來訓練信息過濾模型。因為某些專業領域存在問題數據缺失的情況, 本文設計了一種基于提示的方法,使用大模型生成問題數據,首先從相關數據中選擇一條數據用來生成提示,將提示輸入大模型生成一條數據,重復以上述步驟,直到相關數據被選完。

????在上表中 D 表示所有的相關數據,d 表示一條相關數據,R 表示所有生成的問題數據,r 表示一條生成的數據。create 根據用戶提供的 API_KEY 創建 與 ChatGPT 的鏈接,select 表示選擇一條數據,P 表示根據數據生成合適的提示,chatgpt 表示獲取 ChatGPT 生成的回復,abstract 表示從生成回復中提取出問題數據并進行匯總。 在中醫藥方劑領域,如下表中 P1 所示,將提示 P1 輸入 ChatGPT,生成相關問題。中醫藥方劑領域問答系統的問題數據,80%來自于現有的問答數據集如 MultiMedQA、CMRC2018、CMedQASystem、cMedQA等,本文從中整理相關問題, 并將其按照是否為中醫藥方劑專業領域添加標簽。 20%的中醫藥方劑相關問題使用大模型生成的方式構建。
????針對專業領域的問答,大型語言模型無需回答其他領域的問題,為此本系統添加了基于 BERT的文本過濾器對問題進行過濾,以限制大模型可以回答的問題范圍。 其他模型在面對專業領域的邊界問題或交叉問題時往往會產生微妙的幻覺事實,生成錯誤文本。 盡管使用微調的形式同樣也可以使得大模型具備一定的問題甄別能力,但是這種能力在面對和微調數據集中相似的其他問題時,仍然會被迷惑,甚至對于原本可以正確回答的問題也會生成錯誤的答案。 因此需要單獨設計文本過濾器以對信息進行過濾。 假設可輸入大模型的所有的問題集合為 Q,大模型在某一專業領域可以回答的問題集合為 R,可以生成專業回答的問題集合為 D,顯然有 Q>R>D。 使用微調方式限制將使得 R→D,會讓模型回答能力減弱。而使用過濾器的形式,使得 Q→R,將盡可能保證詢問的問題在 R 的范圍之內,雖然會有部分 R 之外的數據進入大模型,但是由于本文設計的專業增強問答系統仍然保留一定的通用能力,因此對 R 之外的問題也可以進行無專業驗證的回答。 信息過濾將保證本系統可以盡可能回答在系統能力范圍以內的問題,以減少其產生幻覺事實的可能。
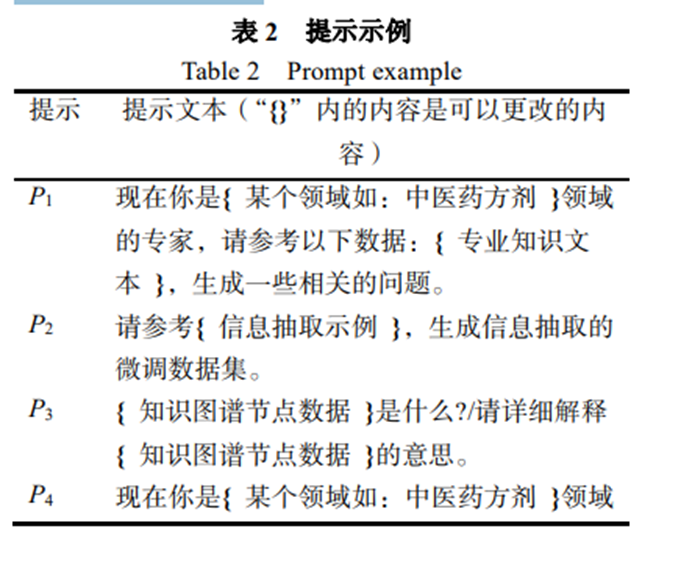
????訓練過程如下圖所示,將訓練數據輸入 BERT,再將 BERT 的結果輸入全連接層(Fully Connected Layer,FCL)得到對本文的分類結果[CLS]。根據數據集中的標簽,訓練時只需要更新全連接層的參數即可。 一般來說使用 BERT 進行文本分類任務,會采用BERT 結果的分類詞向量 H ,基于 softmax 做一個簡單的分類器,預測類別的標簽 L的概率:P(L|H)= softmax(WH) 這里 W 是分類任務的參數矩陣,最終通過最大化正確標簽的對數概率來微調 BERT 和 W 中的所有參數。將其修改為使用全連接層得到每個標簽的概率:P(L|H)= FC(H) 訓練時輸入全連接層的向量維度為 768,具有兩個隱藏層,維度分別為 384、768,輸出維度為類別個數,這里是一個二分類任務,因此為 2。最終選擇概率更大的標簽作為分類的結果[CLS]。在中醫藥方劑學領域中,[CLS]為問題是否與中醫藥方劑相關,通過過濾問題,減少生成幻覺事實的可能,并同檢索結果一起判斷能否進行專業回答。
????在本文中,我們提出了 FoodGPT,一個用于食品測試領域的大型語言模型。 FoodGPT 基于 Chinese-LLaMA2-13B 基礎模型構建,具有增量預訓練、指令微調和外部知識圖集成。由于圖像、掃描文檔和私有結構化知識庫中存在大量知識,而基礎模型缺乏這些知識,因此我們認為有必要進行增量預訓練。我們提出了處理這些數據的新方法,并將它們與其他數據一起合并到我們的增量預訓練數據庫中。在指令微調階段,我們從論壇中抓取問題答案對,并在領域專家提供的種子指令的指導下,使用 evol-instruct 構建微調數據集。鑒于食品檢測領域對輸出指標的嚴格要求,我們還構建了一個知識圖作為外部數據庫,以協助FoodGPT生成輸出。值得一提的是,本文是FoodGPT預發布版本的技術報告,我們將在未來的版本中詳細闡述實驗細節和分析。
????為了使得大模型知識圖譜問答系統的回答更具備專業性,本文通過提示的方式注入知識庫中的專業知識,增強回答的專業性。通過檢索知識庫,大模型可以回答其本身能力之外的專業問題,這使得大型語言模型支持的問題邊界擴大。這種方式和引入專業數據的微調方法對比,無需重新訓練就可以部署一個專業領域大型語言模型。 如下圖所示,在中醫藥方劑領域,本文使用 LangChain+ChatGLM-6B,生成更具備專業知識的回答。本系統基于 LangChain 在知識庫中檢索與問題相關的專業知識,然后專業知識和問題文本一起 構成 P4輸入大模型,最終得到答案文本,這里選擇使用 ChatGLM-6B 作為大模型。
????假設知識庫中的第 i 個文件為𝐹𝑖(𝑖 = 1,2,3, … , 𝑛), 基于 LangChain 進行檢索會將各個文件中的文本進行分塊,𝐷𝑖𝑗(𝑖 = 1,2,3, … , 𝑛;𝑗 = 1,2,3, … , 𝑚. )表示對 第 i 個文件的第 j 個文本塊。然后對每一塊文本建立為向量索引𝑽𝒊(𝑖 = 1,2,3, … , 𝑛 × 𝑚),在檢索時將問題文本向量化,得到問題文本向量 Q,最后通過向量相似度計算出和 Q 最相似的 k 個向量索引,并返回其對應的文本塊。將匹配到的專業知識文本 D 和問題文本以𝑃4的形式拼接,最終輸入 ChatGLM6B 中得到大模型生成的專業回答。該過程的偽代碼如下表所示:

????在上表中,q 表示問題文本, f 表示知識庫文件,d 表示知識文本塊,Q 表示問題文本向量,V 表示文本塊的向量索引,split 表示劃分文本塊的過程,trans 表示從文本轉化為向量,de_trans 表示從向量轉化為文本,score 將返回 k 個最相似的向量索引,model(P4(q,dk))表示將問題文本和專業知識文本以 P4 形式輸入大模型 ChatGLM-6B。
????該節探索大型語言模型和知識圖譜的深度結合。 大模型的回答是易讀的自然語言數據,而知識圖譜的數據是結構化的知識。為了將兩者交互結合,需 要實現兩者的相互轉換:(1)實現對自然語言的結構化;(2)可將結構化的知識轉換為自然語言。前者是信息抽取的任務,后者可以通過提示的方式輸入大模型轉換成自然語言文本。 以中醫藥方劑領域的應用為例,(1)對于信息抽取,使用 P-tuning v2 微調的方式強化 ChatGLM6B 的信息抽取能力。具體來說,在語言模型的每一 層上將𝑙個可訓練的注意力鍵和值嵌入連接到前綴 上,給定原始的鍵向量𝑲 ∈ 𝑹 𝒍×𝒅和值向量𝑽 ∈ 𝑹 𝒍×𝒅, 可訓練的向量𝑷𝒌,𝑷𝒗將分別與𝑲和𝑽連接。注意力機制頭的計算就變為:headi(x)=Attention(xW(i), [P(i)k :K(i)], [P(i)v :V(i)]) 其中上標(𝑖)代表向量中與第𝑖個注意力頭對應的部分,本文通過這種方法來微調大語言模型。 將大模型生成的自然語言答案文本, 輸入經過信息抽取增強微調后的大模型中,提取出結構化的三元組信息,將其與知識圖譜進行匹配, 進行專家驗證后,可以存儲到方劑知識圖譜中,效果見下圖。對于結構數據的易讀化,使用提示的方式,將知識圖譜相關節點轉換為 P3 后,再將 P3 輸入大模型得到自然語言的回答,效果見下圖。 本文嘗試將專業知識圖譜與大語言模型結合, 利用大模型生成自然語言回答,抽取出專業的結構化知識,并和已有的專業方劑知識圖譜進行知識匹配,以進行專業驗證,同時可以將知識圖譜中的結構化知識轉化成易讀的自然語言。
實驗
????對于問題 1,由于知識庫中存在相關的知識, 專家問答系統可以進行專業回答,ChatGLM 則無法生成方劑學的專業回答,相比于 ChatGPT 的回答專家問答系統更精細,不僅有方劑名稱、適用范圍還有具體的方劑信息。對于問題 2,此問題是數學和方劑學的交叉問題,知識庫中并沒有相關信息,直接由 ChatGLM 回答,會生成幻覺事實。專業問答系統可以判斷無足夠專業知識進行回答,進而避免生成幻覺事實。這些結果表明,本文設計的系統具備良好的專業回答能力,同時也能對自身無法專業回復的問題表示拒絕 。 專業問答系統仍然保留 ChatGLM 本身的能力,能對一些繞過信息過濾的問題進行回答,這種能力能夠保證在面對專業領域邊界問題或交叉問題時可以有較好的回答。

????本實驗請三個中醫藥方面的專家對不同模型的回答進行評估,用以驗證系統效果。將 100 個問題分別輸入三個不同的模型生成答案,然后把來自不同模型的每個問題的結果,交給專家進行評估,比較對于同一個問題,專家更喜歡哪一個模型的回答。 如下圖所示,橫坐標表示不同的專家,縱坐標表示最滿意問題所占問題總數比例。模型 1 是本文所提專業問答系統,模型 2 表示 ChatGLM,模型 3 表示 ChatGPT。由于是對比三個模型的結果,因此只需專家最滿意比例大于總體三分之一就可以證明專業問答系統的回答更好。專家們對模型 1 的回答結果最滿意總個數分別是 37、42、42,都超過總問題個數的三分之一,因此本文所設計的系統更受專家喜歡。

????實驗過程中,問題被分為兩類,一種是普通問題,另一種是專業問題,兩者分別有 50 個問題,共 100 個問題。普通問題是相對常見的問題,對專業知識需求較低;專業問題是考驗式問題,類似于考試題,回答專業問題需要具備更多的知識。模型 1 取得了最高的滿意率, 可看出本系統提出的方法更受中醫藥專家的喜歡。 對于簡單問題,遠遠優于其他兩個模型,對于專業問題,雖然 ChatGPT 取得最優的結果,但是模型 1 相對于模型 2 仍更受專家喜歡。相對于其他模型,模型 1 的回復更加詳細,會補充更多專業知識。但是當問題難度上升,回答問題需求知識更多,當知識庫中沒有這部分知識時,模型 1 的回答專業性就不如 ChatGPT。這是可能是因為 ChatGPT 訓練時所用的語料中涉及專業問題,因此 ChatGPT 在回答專業問題時更具備優勢。 結果表明,總體上本文所提系統更受專家喜歡。 雖然面對復雜問題時,表現不如 ChatGPT,但是相對其基線模型 ChatGLM-6B 仍保持更高的滿意率。 這表明了本文所提系統的有效性。
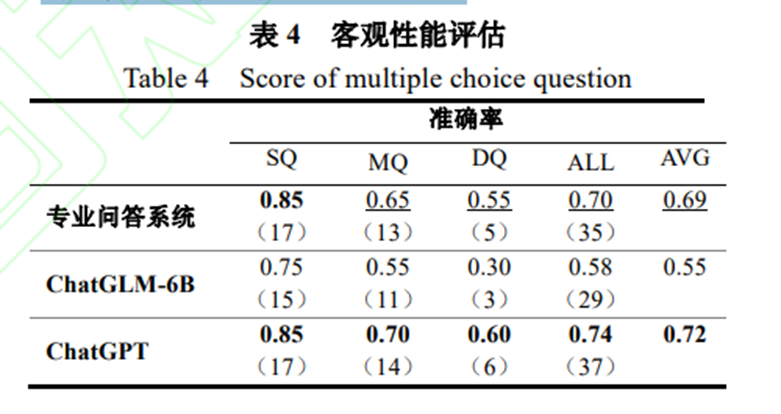
????實驗過程中,問題按照問題的難度分為三類, 簡單題(Simple Question,SQ)、中等題(Medium Question,MQ)、困難題(Difficult Question,DQ)。 準確率以正確問題個數除以總問題個數進行計算。 小括號中的數字表示正確回答問題的個數。從其中結果看,顯然隨著問題難度提升, 回答的正確率依次下降。對于平均正確率而言,專業問答系統顯著高于 ChatGLM-6,略低于 ChatGPT。 說明專業問答系統能夠顯著提升大模型的專業能力, 甚至能夠達到和 ChatGPT 相媲美的結果。 結果表明,和 ChatGLM-6B 相比專業問答系統答對題目的數量更多,從客觀上驗證了系統的性能。
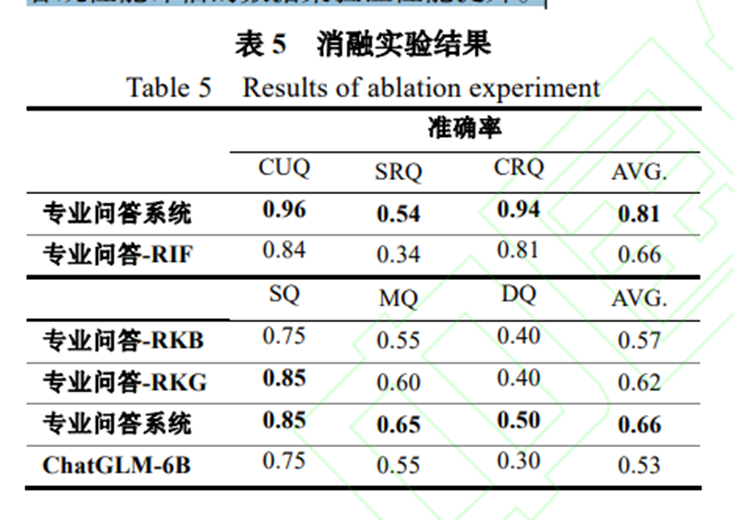
消融實驗
????實驗過程中,為了驗證信息過濾模塊的能力, 將輸入的問題按照相關程度劃分了三種類型的問題, 無關問題(Completely Unrelated Question,CUQ)、 部分相關問題(Some Related Question, SRQ)、完全相關問題(Completely Related Question, CRQ)。對于部分相關問題,是在無關問題的基礎上增加相關的信息或在相關問題的基礎上增加無關信息,作為干擾。通過將無關信息和相關信息混合的方式制造部分相關問題,可以驗證信息過濾的魯棒性。準確率使用正確過濾問題個數除以問題總個數進行計算。 RIF(Remove Information Filter)表示去除信息過濾,RKB(Remove Knowledge Base) 表示去除知識庫,RKG(Remove Knowledge Graph) 表示去除知識圖譜交互。去除信息過濾模塊后,專業問答系統可以通過合適的提示機制進行信息過濾,從結果看,專業問答-RIF 的過濾準確率低于專業問答系統的過濾準確率,說明了去除信息過濾模塊后系統的信息過濾能力有所降低,驗證了信息過濾模塊的有效性。對于簡單問題的回答,專業問答-RKB 的準確率與 ChatGLM-6B 基本相同,專業問答-RKG 的準確率與專業問答系統基本相同,說明對于 SQ, 大模型本身具備一定的回答能力,其增幅主要依靠知識庫,知識圖譜進行交互增強不明顯。對于困難問題,專業問答-RKB 和專業問答-RKG 的準確率低于專業問答系統高于 ChatGLM-6B,可見對于 MQ、 DQ,通過知識圖譜進行交互發揮一定的作用,猜測這可能是因為知識圖譜能夠注入相關知識或輔助大模型進行推理,激活大模型的邊緣知識。總體來說 RKB、RKG 都會使得專業問答系統的回答準確率下降,并且高于 ChatGLM-6B 的準確率,由此驗證了系統各個模塊均發揮作用。對于簡單問題知識圖譜作用不明顯,我們猜測這是因為,回答問題相對簡單時,所需要知識是孤立的,無需通過深度推理得出,當不存在相應知識時,就無法通過知識圖譜輔助推理得到正確的答案, 因此知識圖譜交互對回答的增強不明顯。
????系統界面截圖,展示了系統問答、圖譜數據易讀化、自然語言回答結構化的效果。左上角的問答截圖是用戶向系統發出提問,系統生成答案,然后對答案進行結構化,生成三元組,并和已有的知識圖譜進行匹配后,展示出右上角的知識圖譜節點。用戶可以選擇其中的節點,用戶選擇相關節點,系統將其轉化為問題再次生成答案,最終兩個答案相結合就是系統的回復。 這樣即為用戶提供了良好的交互服務,也實現了大語言模型與知識圖譜的雙向交互。 在中醫藥方劑領域,系統生成的回復有一定的參考價值,但是由于中醫藥方劑領域本身的一些特性,系統還具有很多可以改進的地方,比如加入中醫如何開方的數據和相關問診的多模態數據如:患者的舌苔、脈象、氣色等。該系統針對不同的領域,需有相應的調整。




報錯的解決辦法)




)
)




)

)


