

個人主頁:歡迎來到?Papicatch的博客
?課設專欄 :學生成績管理系統
專業知識專欄:?專業知識?

文章目錄
🍉引言
🍉概述
🍈基本概念
🍍定義
🍍結構?
🍌輸入層
🍌隱藏層
🍌輸出層
🍌擴展結構
🍈工作原理
🍍基本流程
🍍隱藏狀態的計算
🍍輸出的生成
🍍處理長序列時的挑戰
🍍解決長期依賴問題的改進
🍈優勢與局限
🍍優勢
🍍局限
🍈面臨的挑戰
🍍長期依賴問題
🍍梯度消失和梯度爆炸
🍍計算效率低下
🍍內存占用?
🍍過擬合風險
🍈改進與變體
🍍長短期記憶網絡(Long Short-Term Memory,LSTM)
🍍門控循環單元(Gate Recurrent Unit,GRU)
🍍雙向循環神經網絡(Bidirectional RNN)
🍍深度循環神經網絡(Deep RNN)
🍈應用領域
🍍自然語言處理(NLP)
🍍語音處理
🍍金融預測
🍍?醫學
?🍍工業控制
🍍視頻處理
🍍交通預測
🍉理論基礎
🍈神經網絡理論
🍈?信息處理理論
🍈動態系統理論
🍈概率論與統計學
🍈優化理論
🍉長短期記憶網絡
🍈結構與原理
🍈優勢
🍈應用
🍉示例(股票預測)
🍈方法解析
🍍數據準備
🍍特征工程
🍍RNN 模型構建
🍍訓練模型
🍍模型評估
🍈代碼實現(使用 Python 和 TensorFlow 庫)
🍈代碼解析
🍍數據加載和預處理
🍍序列創建
🍍模型構建
🍍模型編譯
🍍模型訓練
🍍預測和評估
🍉總結
🍉引言
????????在當今這個數據驅動的時代,序列數據無處不在。從自然語言中的文本,到語音的音頻流,再到金融市場中的時間序列數據,如何有效地處理和理解這些具有先后順序和時間依賴關系的數據,成為了人工智能領域的一個關鍵挑戰。
????????循環神經網絡(Recurrent Neural Network,RNN)應運而生,它以獨特的架構和計算方式,為處理序列數據帶來了全新的思路和方法。
????????RNN 打破了傳統神經網絡在處理序列數據時的局限性,能夠捕捉數據中的長期依賴關系和動態模式。它如同一位善于傾聽和記憶的智者,在接收每一個新的輸入時,都會回顧過去的信息,從而做出更加準確和全面的判斷。
????????無論是讓機器生成如人類般流暢自然的文本,還是精準地預測股票價格的走勢,RNN 都展現出了巨大的潛力和應用價值。然而,如同任何一項技術,RNN 也并非完美無缺,它在訓練和應用中面臨著諸多挑戰,但這也正是推動其不斷發展和創新的動力源泉。
????????在接下來的篇章中,我們將深入探索循環神經網絡的奧秘,揭開其神秘的面紗,一同領略它在處理序列數據方面的獨特魅力和強大能力。
🍉概述
🍈基本概念
🍍定義
????????循環神經網絡是一類具有反饋連接的神經網絡,能夠處理任意長度的序列數據,通過在隱藏層中引入循環連接,使得網絡能夠記住過去的信息,并將其用于當前的計算。
🍍結構?
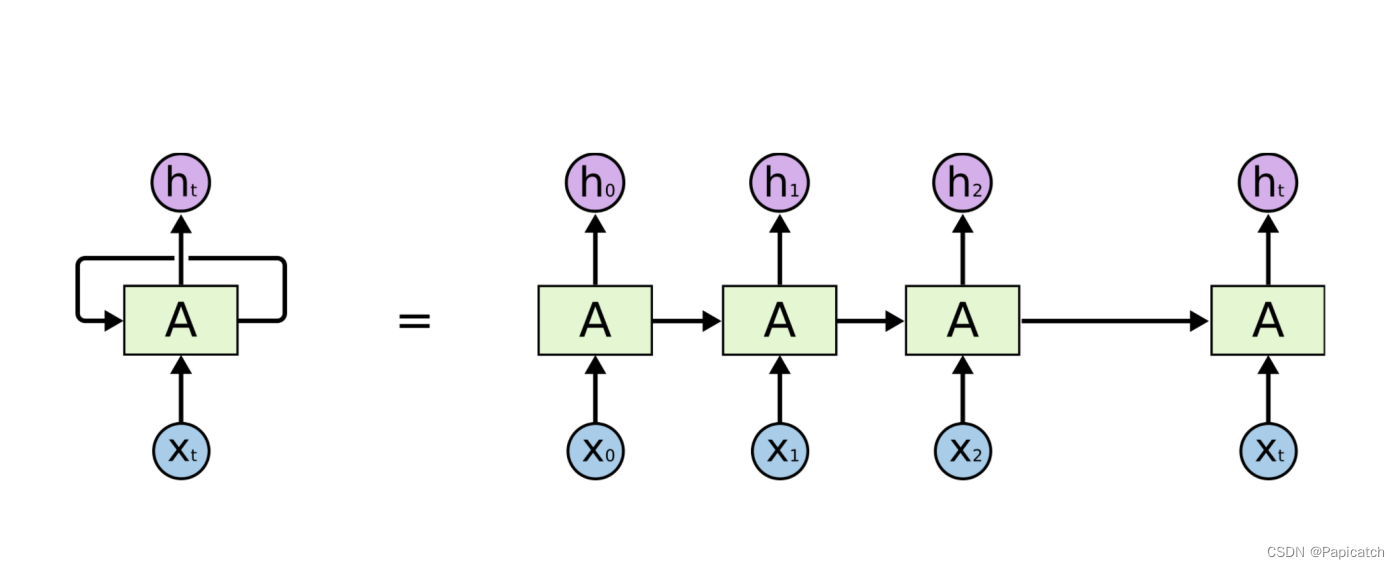
????????循環神經網絡(RNN)的結構主要由輸入層、隱藏層和輸出層組成。
🍌輸入層
- 輸入層負責接收序列數據中的每個元素。假設輸入的序列為?
x = [x1, x2, x3,..., xt]?,其中每個?xt?都是一個向量。
🍌隱藏層
????????隱藏層是 RNN 的核心部分,其狀態不僅取決于當前的輸入,還依賴于上一時刻隱藏層的狀態。
????????在每個時間步?t?,隱藏層的狀態?ht?通過以下公式計算:
ht = f(U * xt + W * ht-1 + b)
????????其中,f?通常是一個非線性激活函數,如?tanh?或?ReLU?。U?是輸入權重矩陣,它將當前輸入?xt?映射到隱藏層空間。W?是循環權重矩陣,用于連接上一時刻的隱藏狀態?ht-1?。b?是偏置項。
這種循環連接使得隱藏層能夠保存歷史信息,并在處理當前輸入時加以利用。
🍌輸出層
????????輸出層根據隱藏層的狀態生成最終的輸出。輸出層的計算方式取決于具體的任務。
????????例如,如果是分類任務,輸出層可能是一個全連接層加上一個 softmax 激活函數,以輸出每個類別的概率分布。
????????如果是回歸任務,輸出層可能是一個簡單的線性層,直接輸出預測值。
????????假設輸出層的計算為:
yt = g(V * ht + c)?
????????其中,g?是輸出層的激活函數(或沒有激活函數,取決于任務),V?是輸出權重矩陣,c?是輸出偏置。
🍌擴展結構
- 為了應對 RNN 存在的長期依賴問題,出現了一些改進的結構,如長短期記憶網絡(LSTM)和門控循環單元(GRU)。
- LSTM 引入了輸入門、遺忘門和輸出門,以及一個長期記憶單元來更好地控制信息的流動和保存。
- GRU 則將遺忘門和輸入門合并為一個更新門,并引入了重置門,簡化了 LSTM 的結構,同時保持了較好的性能。
🍈工作原理
????????循環神經網絡(RNN)的工作原理基于其對序列數據中時間依賴關系的處理能力。
🍍基本流程
????????在處理序列數據時,RNN 按時間步依次處理輸入。假設我們有一個輸入序列?x = [x1, x2, x3,..., xt]?,每個時間步?t?都有一個對應的輸入?xt?。
🍍隱藏狀態的計算
????????在每個時間步?t?,隱藏狀態?ht?的計算如下:
?ht = f(U * xt + W * ht-1 + b)
????????這里,f?是一個非線性激活函數,常見的如?tanh?或?ReLU?。U?是輸入權重矩陣,用于將當前輸入?xt?映射到隱藏層空間。W?是循環權重矩陣,用于連接上一時刻的隱藏狀態?ht-1?,b?是偏置項。
????????這意味著當前隱藏狀態不僅取決于當前輸入,還依賴于上一時刻的隱藏狀態,從而實現了對歷史信息的記憶和利用。
🍍輸出的生成
????????輸出?yt?通常根據隱藏狀態?ht?計算得出:
yt = g(V * ht + c)?
????????其中,g?是輸出層的激活函數(或沒有激活函數,取決于具體任務),V?是輸出權重矩陣,c?是輸出偏置。
🍍處理長序列時的挑戰
????????當處理較長的序列時,RNN 可能會面臨梯度消失或梯度爆炸的問題。這是因為在反向傳播過程中,梯度需要通過多個時間步進行傳播,由于反復的乘法操作,梯度可能會迅速減小(梯度消失)或急劇增大(梯度爆炸)。
🍍解決長期依賴問題的改進
- 為了解決長期依賴問題,出現了一些改進的 RNN 架構,如長短期記憶網絡(LSTM)和門控循環單元(GRU)。
- 以 LSTM 為例,它引入了輸入門、遺忘門和輸出門,以及一個細胞狀態來更有效地控制信息的流動和保存。輸入門決定當前輸入有多少信息被存儲,遺忘門決定過去的信息有多少被遺忘,輸出門決定當前細胞狀態有多少信息被輸出到隱藏狀態。
- 例如,在文本生成任務中,RNN 可以根據已經生成的單詞序列來預測下一個單詞。在每個時間步,它會綜合當前輸入的單詞和之前積累的語義信息來做出預測。
- 又如,在語音識別中,RNN 可以根據音頻信號的時間序列特征來識別語音內容,通過不斷積累和利用過去的音頻信息來提高識別的準確性。
🍈優勢與局限
🍍優勢
- 處理序列數據:RNN 天生適合處理具有時間順序或序列特征的數據,如自然語言中的文本、語音信號、股票價格的時間序列等。它能夠捕捉數據中的時間依賴關系,這是傳統前饋神經網絡無法直接做到的。
- 例如,在機器翻譯中,能夠根據源語言句子的先后順序來生成目標語言的句子。
- 內存高效:與需要為每個輸入單獨存儲大量參數的一些模型相比,RNN 在處理不同長度的序列時,其參數數量相對固定,對內存的需求較為穩定。
- 模型簡潔:RNN 的結構相對簡單,易于理解和實現,這使得它在研究和應用中都具有較高的可操作性。
- 靈活性:可以應用于各種不同類型的序列數據,并且能夠適應不同長度的序列,無需對輸入序列的長度進行固定的限制。
🍍局限
- 梯度消失和梯度爆炸:在處理長序列時,由于反復的乘法操作,梯度在反向傳播過程中可能會迅速減小(梯度消失)或急劇增大(梯度爆炸),導致模型難以訓練,無法有效地學習長期依賴關系。
- 例如,在處理非常長的文本時,可能會丟失早期輸入的重要信息。
- 計算效率低:由于其順序處理的特性,RNN 在處理長序列時計算效率較低,難以進行并行化計算。
- 對復雜模式的學習能力有限:對于一些復雜的序列模式,RNN 可能無法準確地捕捉和學習。
- 容易過擬合:在數據量較小的情況下,RNN 容易出現過擬合現象,導致模型在新數據上的泛化能力較差。
????????盡管 RNN 存在一些局限性,但通過不斷的改進和創新,如發展出長短期記憶網絡(LSTM)和門控循環單元(GRU)等變體,在很大程度上緩解了這些問題,使得循環神經網絡在處理序列數據方面的性能得到了顯著提升。
🍈面臨的挑戰
🍍長期依賴問題
- 在處理長序列數據時,RNN 難以有效地捕捉早期輸入與當前輸出之間的長期依賴關系。隨著序列長度的增加,信息在傳播過程中逐漸衰減,導致模型對遠距離的上下文理解能力不足。
- 例如,在一個長篇文章中,開頭的關鍵信息可能對結尾處的理解至關重要,但 RNN 可能無法很好地將這種遙遠的關聯傳遞過來。
🍍梯度消失和梯度爆炸
- 在訓練過程中,由于反復的矩陣乘法運算,梯度可能會出現消失或爆炸的情況。
- 當梯度消失時,模型參數的更新變得非常緩慢,導致訓練效率低下,難以學習到有效的模式。而梯度爆炸則可能導致模型的不穩定,參數更新幅度過大,使訓練無法收斂。
🍍計算效率低下
????????RNN 是按照時間順序依次處理輸入數據的,難以進行并行計算。這在處理大規模數據和長序列時,會導致訓練和預測的時間成本較高。?
🍍內存占用?
????????在處理長序列時,RNN 需要保存每個時間步的隱藏狀態,這會占用大量的內存資源,尤其當序列長度較長時,內存壓力可能成為限制模型應用的一個因素。
🍍過擬合風險
- 如果訓練數據有限,RNN 容易出現過擬合現象,即在訓練集上表現良好,但在新的、未見過的數據上性能不佳。
- 例如,在文本分類任務中,如果訓練數據的多樣性不足,RNN 可能會過度適應訓練數據中的特定模式,而無法泛化到新的文本。
🍈改進與變體
🍍長短期記憶網絡(Long Short-Term Memory,LSTM)
????????LSTM 通過引入門控機制來更好地控制信息的流動和保存,從而有效地解決了 RNN 的長期依賴問題。
????????LSTM 包含三個門:輸入門、遺忘門和輸出門,以及一個記憶單元。
- 輸入門決定當前輸入有多少信息被存儲到細胞狀態中。
- 遺忘門決定過去的細胞狀態有多少信息被丟棄。
- 輸出門控制細胞狀態有多少信息被輸出到隱藏狀態。
????????例如,在自然語言處理中,LSTM 能夠更好地記住文本中的長期依賴關系,從而提高文本生成和機器翻譯的質量。
🍍門控循環單元(Gate Recurrent Unit,GRU)
????????GRU 是 LSTM 的一種簡化變體,它將遺忘門和輸入門合并為一個更新門,并引入了重置門。
- 更新門用于控制前一時刻的狀態信息被帶入到當前狀態中的程度。
- 重置門用于決定如何將新的輸入與之前的記憶相結合。
????????GRU 在保持性能的同時減少了參數數量,計算效率相對較高。
????????在語音識別任務中,GRU 能夠有效地對語音信號的時間序列進行建模,提高識別準確率。
🍍雙向循環神經網絡(Bidirectional RNN)
- 傳統的 RNN 只能從前向處理序列信息,而雙向 RNN 則同時考慮了前向和后向的序列信息。
- 它由兩個獨立的 RNN 組成,一個按照正常的順序處理輸入,另一個按照相反的順序處理輸入,然后將兩個 RNN 的輸出進行組合。
- 這在許多自然語言處理任務中非常有用,例如詞性標注,因為當前詞的標注可能依賴于前后的詞。
🍍深度循環神經網絡(Deep RNN)
- 類似于深度前饋神經網絡,深度循環神經網絡通過增加隱藏層的數量來構建更深的網絡結構,從而能夠學習更復雜的模式。
- 但深度 RNN 也面臨著梯度消失和爆炸等問題,需要配合合適的訓練方法和正則化技術。
- 在股票價格預測等復雜的時間序列預測任務中,深度 RNN 可能會表現出更好的性能。
🍈應用領域
🍍自然語言處理(NLP)
- 機器翻譯:將一種語言的文本序列轉換為另一種語言的文本序列。
- 文本生成:創作文章、故事、詩歌等。
- 問答系統:理解問題并生成準確的回答。
- 情感分析:判斷文本所表達的情感傾向,如積極、消極或中性。
🍍語音處理
- 語音識別:將語音信號轉換為文字。
- 語音合成:根據輸入的文本生成自然流暢的語音。
🍍金融預測
- 股票價格預測:基于歷史價格數據預測未來的走勢。
- 匯率預測:分析匯率的時間序列數據以預測未來的匯率變化。
🍍?醫學
- 心電圖(ECG)分析:解讀心臟活動的時間序列數據。
- 疾病預測:根據患者的病史和癥狀序列預測疾病的發展。
?🍍工業控制
- 預測設備的故障和維護需求,基于傳感器采集的時間序列數據。
🍍視頻處理
- 理解視頻中的動作序列和事件發展。
🍍交通預測
- 預測交通流量、擁堵情況等。
🍉理論基礎
????????循環神經網絡(RNN)建立在以下幾個重要的理論基礎之上:
🍈神經網絡理論
????????RNN 本質上仍然是一種神經網絡,它繼承了神經網絡的基本概念,如神經元、權重、激活函數等。神經元通過權重連接,對輸入進行加權求和,并通過激活函數進行非線性變換,以產生輸出。
🍈?信息處理理論
- 序列數據的表示:RNN 旨在有效地處理序列形式的數據,將其視為一系列按時間順序排列的信息單元。
- 信息的傳遞和保存:通過在隱藏層中引入循環連接,RNN 能夠傳遞和保存歷史信息,從而利用過去的輸入來影響當前的處理和輸出。
🍈動態系統理論
- 時間依賴性建模:RNN 可以看作是一個動態系統,其狀態(隱藏層的激活值)隨時間(輸入序列的時間步)而變化。
- 穩定性和收斂性:在訓練過程中,需要關注模型的穩定性和收斂性,以確保能夠學習到有效的模式。
🍈概率論與統計學
- 參數估計:通過優化算法(如隨機梯度下降)來估計模型的參數,以最大化數據的似然或最小化損失函數。
- 不確定性處理:在預測時,RNN 可以給出輸出的概率分布,以反映預測的不確定性。
🍈優化理論
- 梯度計算:在訓練 RNN 時,需要計算損失函數關于模型參數的梯度,以進行參數更新。
- 避免過擬合:采用正則化技術(如 L1 和 L2 正則化)來防止模型過擬合訓練數據。
????????例如,從信息處理的角度來看,在文本分類任務中,RNN 會隨著輸入單詞的依次到來,逐步整合和更新對文本整體含義的理解;在動態系統理論方面,就像股票價格的預測,RNN 模型的狀態會隨著時間步的推進而動態調整,以反映價格變化的趨勢和規律。
🍉長短期記憶網絡
????????長短期記憶網絡(LSTM)是對傳統循環神經網絡(RNN)的一種重要改進,旨在更好地處理序列數據中的長期依賴問題。
🍈結構與原理
????????LSTM 引入了特殊的單元結構,稱為記憶單元(Memory Cell),以及三個門控機制:輸入門(Input Gate)、遺忘門(Forget Gate)和輸出門(Output Gate)。
- 輸入門決定了當前輸入有多少信息可以被存儲到記憶單元中。
- 遺忘門控制著從記憶單元中遺忘多少過去的信息。
- 輸出門則決定了記憶單元中的信息有多少可以被輸出到隱藏狀態。
????????通過這些門控機制,LSTM 能夠更加靈活地控制信息的流動和保存,從而有效地解決了 RNN 中存在的長期依賴問題。
🍈優勢
- 更好的長期記憶能力:能夠在處理長序列時記住重要的早期信息。
- 減輕梯度消失和爆炸:由于其獨特的結構,LSTM 在反向傳播時能夠更好地保持梯度的穩定性,減少梯度消失和爆炸的影響。
🍈應用
LSTM 在眾多領域都有出色的表現:
- 自然語言處理:如機器翻譯、文本生成、情感分析等。
- 語音識別:對語音信號的序列進行建模和識別。
- 時間序列預測:例如股票價格預測、氣象預測等。
????????例如,在機器翻譯中,LSTM 可以記住源語言文本中較遠位置的關鍵信息,從而生成更準確的目標語言翻譯;在股票價格預測中,它能夠捕捉到長期的價格趨勢和周期性模式,提供更可靠的預測結果。
🍉示例(股票預測)
🍈方法解析
🍍數據準備
- 收集歷史股票價格數據,包括開盤價、收盤價、最高價、最低價、成交量等。
- 對數據進行預處理,如歸一化、去除異常值等,以提高模型的訓練效果。
🍍特征工程
- 提取有用的特征,如移動平均線(MA)、相對強弱指標(RSI)、布林帶(Bollinger Bands)等技術指標。
- 將特征和目標變量(如未來一段時間的收盤價)組合成適合 RNN 輸入的格式。
🍍RNN 模型構建
- 選擇合適的 RNN 架構,如簡單的 RNN、長短期記憶網絡(LSTM)或門控循環單元(GRU)。
- 確定隱藏層的數量和神經元個數,以平衡模型的復雜度和性能。
🍍訓練模型
- 使用準備好的數據進行訓練,通常采用反向傳播算法來更新模型的參數。
- 選擇合適的優化器(如 Adam 優化器)和損失函數(如均方誤差)。
🍍模型評估
- 使用測試集數據對訓練好的模型進行評估,常見的評估指標包括均方誤差(MSE)、平均絕對誤差(MAE)等。
- 根據評估結果對模型進行調整和優化。
🍈代碼實現(使用 Python 和 TensorFlow 庫)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM# 加載股票數據
data = pd.read_csv('stock_data.csv')# 數據預處理
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)# 劃分訓練集和測試集
train_size = int(len(data) * 0.8)
train_data = data_scaled[:train_size]
test_data = data_scaled[train_size:]# 構建輸入序列和目標值
def create_sequences(data, sequence_length):X = []y = []for i in range(len(data) - sequence_length):X.append(data[i:i + sequence_length])y.append(data[i + sequence_length])return np.array(X), np.array(y)sequence_length = 10
X_train, y_train = create_sequences(train_data, sequence_length)
X_test, y_test = create_sequences(test_data, sequence_length)# 調整輸入維度
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))# 構建 LSTM 模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(sequence_length, 1)))
model.add(LSTM(50))
model.add(Dense(1))# 編譯模型
model.compile(optimizer='adam', loss='mean_squared_error')# 訓練模型
model.fit(X_train, y_train, epochs=50, batch_size=32)# 預測
y_pred = model.predict(X_test)# 反歸一化預測結果和真實值
y_pred_original = scaler.inverse_transform(y_pred)
y_test_original = scaler.inverse_transform(y_test)# 評估模型
mse = np.mean((y_pred_original - y_test_original)**2)
mae = np.mean(np.abs(y_pred_original - y_test_original))
print(f"均方誤差(MSE): {mse}")
print(f"平均絕對誤差(MAE): {mae}")# 繪制預測結果和真實值
plt.plot(y_test_original, label='True')
plt.plot(y_pred_original, label='Predicted')
plt.legend()
plt.show()🍈代碼解析
🍍數據加載和預處理
- 使用?
pandas?庫讀取股票數據文件。- 通過?
MinMaxScaler?對數據進行歸一化處理,將數據范圍縮放到?[0, 1]?之間。
🍍序列創建
create_sequences?函數用于將數據構建為輸入序列?X?和對應的目標值?y?,每個序列的長度由?sequence_length?決定。
🍍模型構建
- 使用?
tensorflow.keras?的?Sequential?類構建 LSTM 模型。- 首先添加兩個具有 50 個神經元的 LSTM 層,其中第一個 LSTM 層?
return_sequences=True?表示返回每個時間步的輸出,以便后續的 LSTM 層能夠處理。- 最后添加一個全連接層?
Dense(1)?用于輸出預測值。
🍍模型編譯
- 選擇?
adam?優化器和均方誤差作為損失函數。
🍍模型訓練
- 使用訓練數據?
X_train?和?y_train?進行訓練,設置訓練輪數?epochs?和批量大小?batch_size?。
🍍預測和評估
- 使用訓練好的模型對測試數據進行預測。
- 對預測結果和真實值進行反歸一化處理,以恢復到原始數據的范圍。
- 計算均方誤差和平均絕對誤差來評估模型的性能。
- 繪制預測結果和真實值的對比圖,直觀地觀察預測效果。
🍉總結
????????循環神經網絡為處理序列數據提供了一種強大的工具,盡管存在一些挑戰,但通過不斷的改進和創新,其在眾多領域都取得了顯著的成果,并將繼續在人工智能的發展中發揮重要作用。
????????例如,在機器翻譯任務中,使用基于 RNN 的架構能夠顯著提高翻譯的準確性和流暢性;在文本情感分析中,能夠更準確地捕捉文本中的情感傾向。隨著技術的不斷進步,我們有理由相信 RNN 及其衍生架構將在更多的應用場景中展現出強大的能力。










)









)