圖像語義分割是計算機視覺領域中的一個重要任務,它旨在對圖像中的每個像素進行分類,從而實現對圖像內容的詳細理解。在眾多圖像語義分割算法中,全卷積網絡(Fully Convolutional Networks, FCN)因其端到端的訓練方式和高效的像素級預測能力而備受關注。本教程將帶領你使用MindSpore實現FCN-8s模型,進行圖像語義分割任務。通過該教程,你將學習數據預處理、網絡構建、模型訓練、評估和推理的完整流程。
全卷積網絡(Fully Convolutional Networks,FCN)是UC Berkeley的Jonathan Long等人于2015年在論文《Fully Convolutional Networks for Semantic Segmentation》中提出的用于圖像語義分割的一種框架。FCN是首個端到端(end to end)進行像素級(pixel level)預測的全卷積網絡。
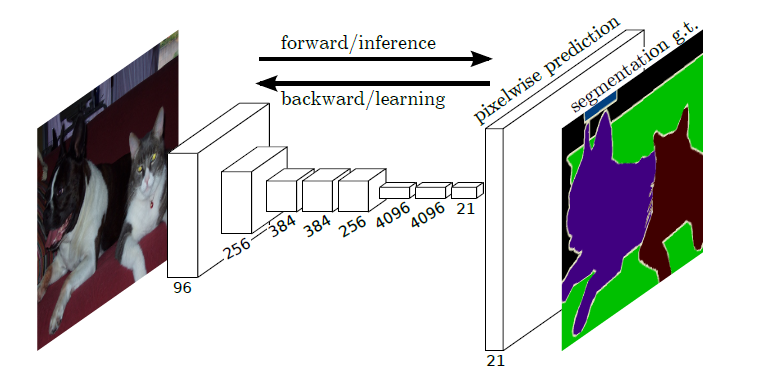
語義分割簡介
語義分割(semantic segmentation)是圖像處理和機器視覺技術中關于圖像理解的重要一環,常被應用于人臉識別、物體檢測、醫學影像、衛星圖像分析、自動駕駛感知等領域。語義分割的目的是對圖像中每個像素點進行分類。與普通的分類任務只輸出某個類別不同,語義分割任務輸出與輸入大小相同的圖像,輸出圖像的每個像素對應了輸入圖像每個像素的類別。

模型簡介
FCN主要用于圖像分割領域,是一種端到端的分割方法。通過進行像素級的預測直接得出與原圖大小相等的label map。因FCN丟棄全連接層替換為全卷積層,網絡所有層均為卷積層,故稱為全卷積網絡。
全卷積神經網絡主要使用以下三種技術:
-
卷積化(Convolutional):
使用VGG-16作為FCN的backbone。VGG-16的輸入為224*224的RGB圖像,輸出為1000個預測值。VGG-16中共有三個全連接層,全連接層也可視為帶有覆蓋整個區域的卷積。將全連接層轉換為卷積層能使網絡輸出由一維非空間輸出變為二維矩陣,利用輸出能生成輸入圖片映射的heatmap。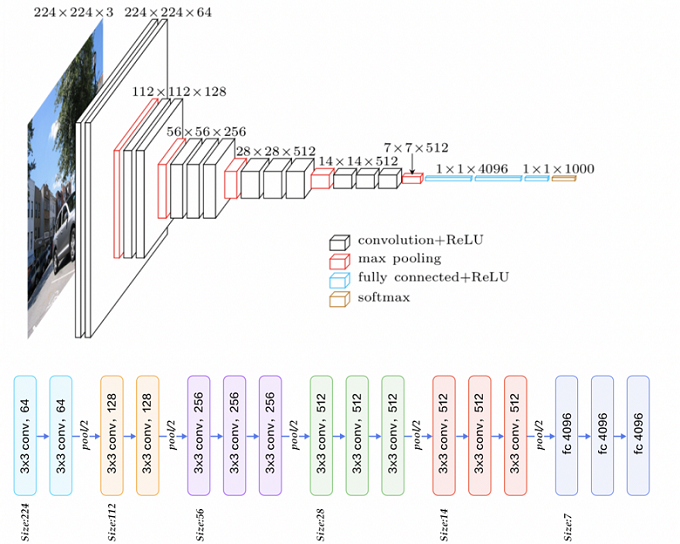
-
上采樣(Upsample):
在卷積過程的卷積操作和池化操作會使得特征圖的尺寸變小,為得到原圖的大小的稠密圖像預測,需要對得到的特征圖進行上采樣操作。使用雙線性插值的參數來初始化上采樣逆卷積的參數,后通過反向傳播來學習非線性上采樣。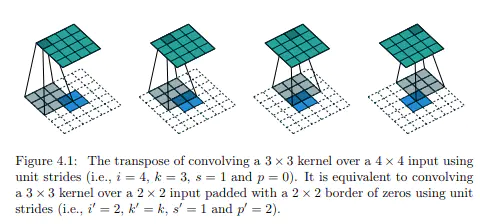
-
跳躍結構(Skip Layer):
利用上采樣技巧對最后一層的特征圖進行上采樣得到原圖大小的分割是步長為32像素的預測,稱之為FCN-32s。由于最后一層的特征圖太小,損失過多細節,采用skips結構將更具有全局信息的最后一層預測和更淺層的預測結合,使預測結果獲取更多的局部細節。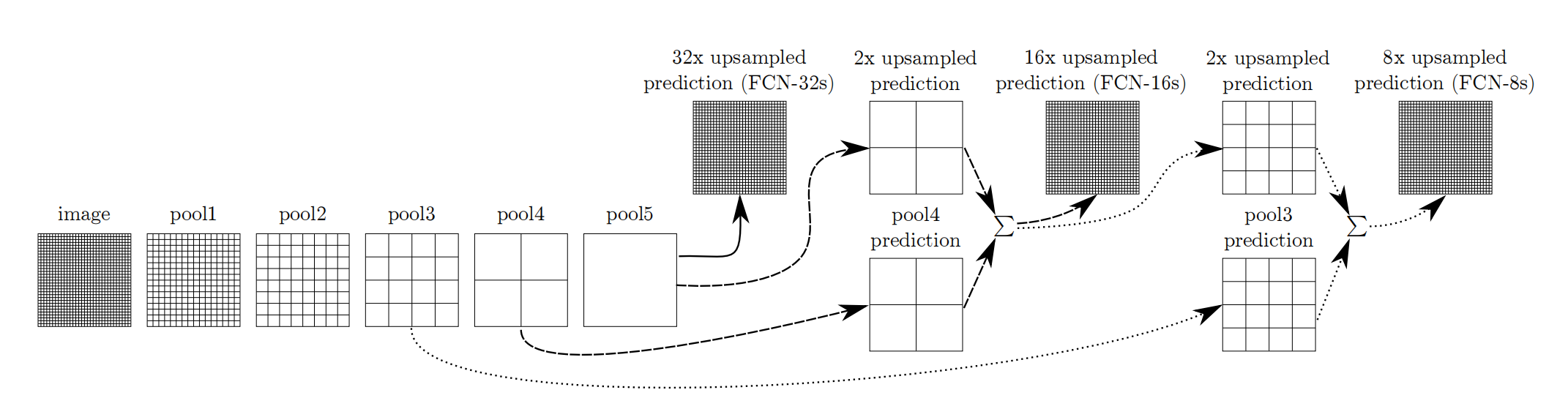
網絡特點
- 不含全連接層(fc)的全卷積(fully conv)網絡,可適應任意尺寸輸入。
- 增大數據尺寸的反卷積(deconv)層,能夠輸出精細的結果。
- 結合不同深度層結果的跳級(skip)結構,同時確保魯棒性和精確性。
數據處理
數據預處理和標準化:
- 為什么要標準化數據? 標準化數據有助于加速模型的收斂速度,并且可以防止數值過大或過小導致的數值不穩定問題。
- 為什么要進行數據增強? 數據增強(如隨機裁剪、翻轉等)可以增加數據的多樣性,從而提高模型的泛化能力,減少過擬合。
下載并解壓數據集:
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset_fcn8s.tar"
download(url, "./dataset", kind="tar", replace=True)
數據預處理
由于PASCAL VOC 2012數據集中圖像的分辨率大多不一致,無法放在一個tensor中,故輸入前需做標準化處理。
數據加載
將PASCAL VOC 2012數據集與SDB數據集進行混合。
import numpy as np
import cv2
import mindspore.dataset as dsclass SegDataset:def __init__(self,image_mean,image_std,data_file='',batch_size=32,crop_size=512,max_scale=2.0,min_scale=0.5,ignore_label=255,num_classes=21,num_readers=2,num_parallel_calls=4):self.data_file = data_fileself.batch_size = batch_sizeself.crop_size = crop_sizeself.image_mean = np.array(image_mean, dtype=np.float32)self.image_std = np.array(image_std, dtype=np.float32)self.max_scale = max_scaleself.min_scale = min_scaleself.ignore_label = ignore_labelself.num_classes = num_classesself.num_readers = num_readersself.num_parallel_calls = num_parallel_callsmax_scale > min_scaledef preprocess_dataset(self, image, label):image_out = cv2.imdecode(np.frombuffer(image, dtype=np.uint8), cv2.IMREAD_COLOR)label_out = cv2.imdecode(np.frombuffer(label, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)sc = np.random.uniform(self.min_scale, self.max_scale)new_h, new_w = int(sc * image_out.shape[0]), int(sc * image_out.shape[1])image_out = cv2.resize(image_out, (new_w, new_h), interpolation=cv2.INTER_CUBIC)label_out = cv2.resize(label_out, (new_w, new_h), interpolation=cv2.INTER_NEAREST)image_out = (image_out - self.image_mean) / self.image_stdout_h, out_w = max(new_h, self.crop_size), max(new_w, self.crop_size)pad_h, pad_w = out_h - new_h, out_w - new_wif pad_h > 0 or pad_w > 0:image_out = cv2.copyMakeBorder(image_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=0)label_out = cv2.copyMakeBorder(label_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=self.ignore_label)offset_h = np.random.randint(0, out_h - self.crop_size + 1)offset_w = np.random.randint(0, out_w - self.crop_size + 1)image_out = image_out[offset_h: offset_h + self.crop_size, offset_w: offset_w + self.crop_size, :]label_out = label_out[offset_h: offset_h + self.crop_size, offset_w: offset_w+self.crop_size]if np.random.uniform(0.0, 1.0) > 0.5:image_out = image_out[:, ::-1, :]label_out = label_out[:, ::-1]image_out = image_out.transpose((2, 0, 1))image_out = image_out.copy()label_out = label_out.copy()label_out = label_out.astype("int32")return image_out, label_outdef get_dataset(self):ds.config.set_numa_enable(True)dataset = ds.MindDataset(self.data_file, columns_list=["data", "label"],shuffle=True, num_parallel_workers=self.num_readers)transforms_list = self.preprocess_datasetdataset = dataset.map(operations=transforms_list, input_columns=["data", "label"],output_columns=["data", "label"],num_parallel_workers=self.num_parallel_calls)dataset = dataset.shuffle(buffer_size=self.batch_size * 10)dataset = dataset.batch(self.batch_size, drop_remainder=True)return dataset# 定義創建數據集的參數
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"# 定義模型訓練參數
train_batch_size = 4
crop_size = 512
min_scale = 0.5
max_scale = 2.0
ignore_label = 255
num_classes = 21# 實例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,image_std=IMAGE_STD,data_file=DATA_FILE,batch_size=train_batch_size,crop_size=crop_size,max_scale=max_scale,min_scale=min_scale,ignore_label=ignore_label,num_classes=num_classes,num_readers=2,num_parallel_calls=4)dataset = dataset.get_dataset()
訓練集可視化
運行以下代碼觀察載入的數據集圖片(數據處理過程中已做歸一化處理)。
import numpy as np
import matplotlib.pyplot as pltplt.figure(figsize=(16, 8))# 對訓練集中的數據進行展示
for i in range(1, 9):plt.subplot(2, 4, i)show_data = next(dataset.create_dict_iterator())show_images = show_data["data"].asnumpy()show_images = np.clip(show_images, 0, 1)
# 將圖片轉換HWC格式后進行展示plt.imshow(show_images[0].transpose(1, 2, 0))plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0)
plt.show()
網絡構建
網絡流程
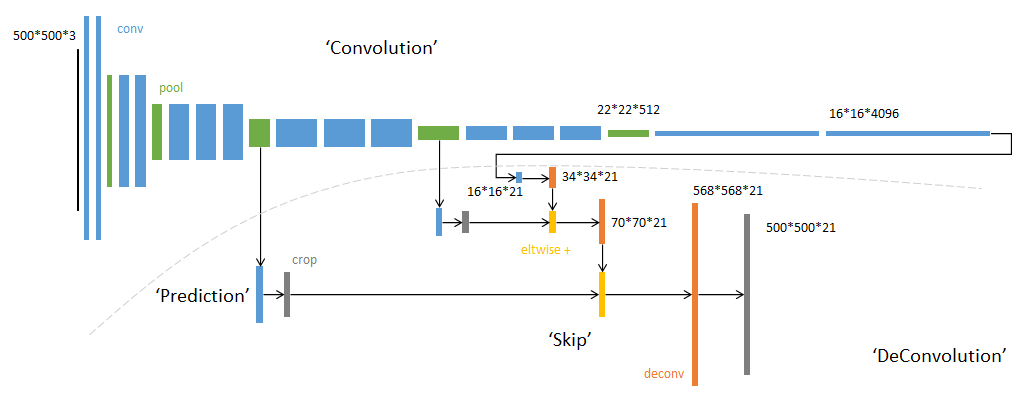
FCN網絡的流程如下圖所示:
- 輸入圖像image,經過pool1池化后,尺寸變為原始尺寸的1/2。
- 經過pool2池化,尺寸變為原始尺寸的1/4。
- 接著經過pool3、pool4、pool5池化,大小分別變為原始尺寸的1/8、1/16、1/32。
- 經過conv6-7卷積,輸出的尺寸依然是原圖的1/32。
- FCN-32s是最后使用反卷積,使得輸出圖像大小與輸入圖像相同。
- FCN-16s是將conv7的輸出進行反卷積,使其尺寸擴大兩倍至原圖的1/16,并將其與pool4輸出的特征圖進行融合,后通過反卷積擴大到原始尺寸。
- FCN-8s是將conv7的輸出進行反卷積擴大4倍,將pool4輸出的特征圖反卷積擴大2倍,并將pool3輸出特征圖拿出,三者融合后通反卷積擴大到原始尺寸。
使用以下代碼構建FCN-8s網絡。
import mindspore.nn as nnclass FCN8s(nn.Cell):def __init__(self, n_class):super().__init__()self.n_class = n_classself.conv1 = nn.SequentialCell(nn.Conv2d(in_channels=3, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(in_channels=64, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU())self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.SequentialCell(nn.Conv2d(in_channels=64, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(in_channels=128, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU())self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.SequentialCell(nn.Conv2d(in_channels=128, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU())self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.SequentialCell(nn.Conv2d(in_channels=256, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU())self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv5 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU())self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv6 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=4096,kernel_size=7, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)self.conv7 = nn.SequentialCell(nn.Conv2d(in_channels=4096, out_channels=4096,kernel_size=1, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)self.score_fr = nn.Conv2d(in_channels=4096, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore2 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')self.score_pool4 = nn.Conv2d(in_channels=512, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore_pool4 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')self.score_pool3 = nn.Conv2d(in_channels=256, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore8 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=16, stride=8, weight_init='xavier_uniform')def construct(self, x):x1 = self.conv1(x)p1 = self.pool1(x1)x2 = self.conv2(p1)p2 = self.pool2(x2)x3 = self.conv3(p2)p3 = self.pool3(x3)x4 = self.conv4(p3)p4 = self.pool4(x4)x5 = self.conv5(p4)p5 = self.pool5(x5)x6 = self.conv6(p5)x7 = self.conv7(x6)sf = self.score_fr(x7)u2 = self.upscore2(sf)s4 = self.score_pool4(p4)f4 = s4 + u2u4 = self.upscore_pool4(f4)s3 = self.score_pool3(p3)f3 = s3 + u4out = self.upscore8(f3)return out
訓練準備
導入VGG-16部分預訓練權重
加載預訓練的VGG-16權重:
- 為什么要使用預訓練模型? 使用預訓練模型可以利用在大規模數據集上預訓練的權重,從而加速訓練過程,并且在數據量較小時,預訓練模型可以提供更好的初始權重,提升模型性能。
FCN使用VGG-16作為骨干網絡,用于實現圖像編碼。使用下面代碼導入VGG-16預訓練模型的部分預訓練權重。
from download import download
from mindspore import load_checkpoint, load_param_into_neturl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/fcn8s_vgg16.ckpt"
download(url, "./fcn8s_vgg16.ckpt", kind="file", replace=True)# 加載預訓練模型的參數
param_dict = load_checkpoint("fcn8s_vgg16.ckpt")# 創建FCN8s網絡實例
net = FCN8s(n_class=21)# 加載參數到網絡中
load_param_into_net(net, param_dict)
定義損失函數和優化器
- 為什么選擇交叉熵損失函數? 交叉熵損失函數適用于多分類任務,它可以衡量模型輸出的概率分布與真實分布之間的差異,是圖像語義分割任務中常用的損失函數。
- 為什么選擇Adam優化器? Adam優化器結合了動量和RMSProp的優點,具有較快的收斂速度和較好的魯棒性,是深度學習中常用的優化器。
使用交叉熵損失函數(Cross Entropy Loss)和Adam優化器。
import mindspore.nn as nn
import mindspore.ops as opsclass CrossEntropyLoss(nn.Cell):def __init__(self, num_classes, ignore_label=255):super(CrossEntropyLoss, self).__init__()self.num_classes = num_classesself.ignore_label = ignore_labelself.one_hot = ops.OneHot()self.on_value = ops.OnesLike()(1.0)self.off_value = ops.ZerosLike()(0.0)self.ce = ops.SoftmaxCrossEntropyWithLogits()def construct(self, logits, labels):labels = ops.Reshape()(labels, (-1,))valid_mask = ops.NotEqual()(labels, self.ignore_label)labels = ops.MaskedSelect()(labels, valid_mask)logits = ops.Reshape()(logits, (-1, self.num_classes))logits = ops.MaskedSelect()(logits, valid_mask)logits = ops.Reshape()(logits, (-1, self.num_classes))one_hot_labels = self.one_hot(labels, self.num_classes, self.on_value, self.off_value)loss = self.ce(logits, one_hot_labels)return loss.mean()loss_fn = CrossEntropyLoss(num_classes=21)
optimizer = nn.Adam(net.trainable_params(), learning_rate=0.001)
定義訓練函數
from mindspore import Model, context
from mindspore.train.callback import LossMonitor, TimeMonitorcontext.set_context(mode=context.GRAPH_MODE, device_target="CPU")# 創建模型
model = Model(net, loss_fn=loss_fn, optimizer=optimizer, metrics={"accuracy"})# 訓練模型
epoch_size = 10
model.train(epoch_size, dataset, callbacks=[LossMonitor(), TimeMonitor()], dataset_sink_mode=False)
模型評估
為什么使用mIoU作為評估指標? mIoU(Mean Intersection over Union)是語義分割任務中的常用評估指標,它可以衡量預測結果與真實標簽的重疊程度,反映模型的分割性能。
定義評估函數
from mindspore import Tensor
import numpy as npdef evaluate_model(model, dataset):model.set_train(False)total_inter, total_union = 0, 0for data in dataset.create_dict_iterator():image, label = data["data"], data["label"]pred = model.predict(image)pred = ops.ArgMaxWithValue(axis=1)(pred)[0].asnumpy()label = label.asnumpy()inter = np.logical_and(pred == label, label != 255)union = np.logical_or(pred == label, label != 255)total_inter += np.sum(inter)total_union += np.sum(union)return total_inter / total_union# 評估模型
miou = evaluate_model(model, dataset)
print("Mean Intersection over Union (mIoU):", miou)
模型推理
定義推理函數
def infer(model, image):model.set_train(False)pred = model.predict(image)pred = ops.ArgMaxWithValue(axis=1)(pred)[0].asnumpy()return pred# 推理示例
image = next(dataset.create_dict_iterator())["data"]
pred = infer(model, image)# 可視化結果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("Input Image")
plt.imshow(image[0].asnumpy().transpose(1, 2, 0))
plt.axis("off")plt.subplot(1, 2, 2)
plt.title("Predicted Segmentation")
plt.imshow(pred[0])
plt.axis("off")plt.show()
[外鏈圖片轉存中…(img-IzGdBwQG-1719545128292)]













: ADC(SPL庫函數版)(2))





