李宏毅深度學習筆記
https://blog.csdn.net/Tink1995/article/details/105080033
https://blog.csdn.net/leonardotu/article/details/135726696
https://blog.csdn.net/u012856866/article/details/129790077
Transformer 是一個基于自注意力的序列到序列模型,與基于循環神經網絡的序列到序列模型不同,其可以能夠并行計算
Transformer架構
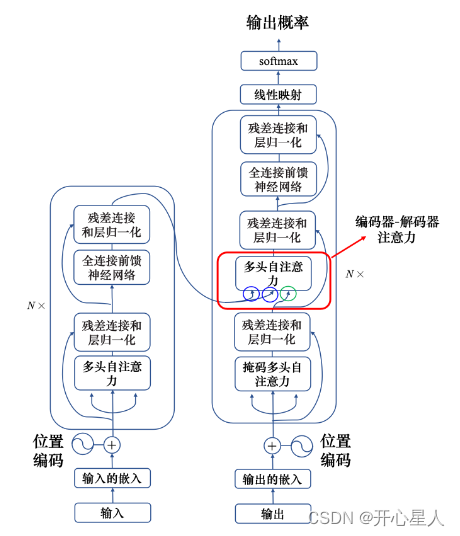
Transformer主要由輸入部分(輸入輸出嵌入與位置編碼)、多層編碼器、多層解碼器以及輸出部分(輸出線性層與Softmax)四大部分組成。
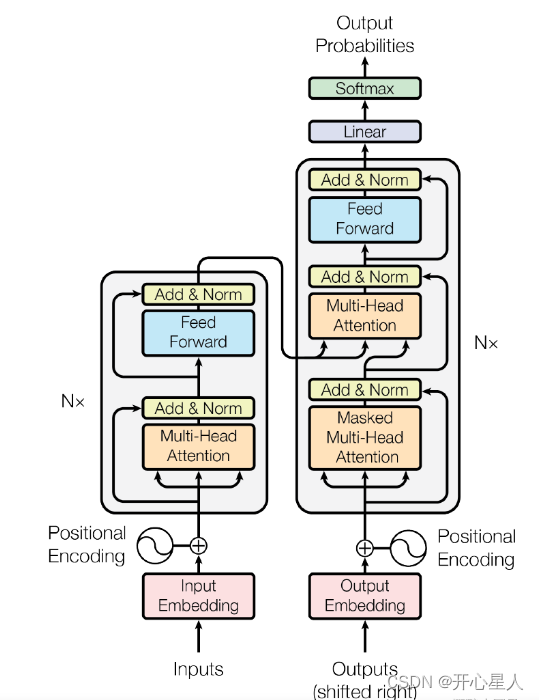
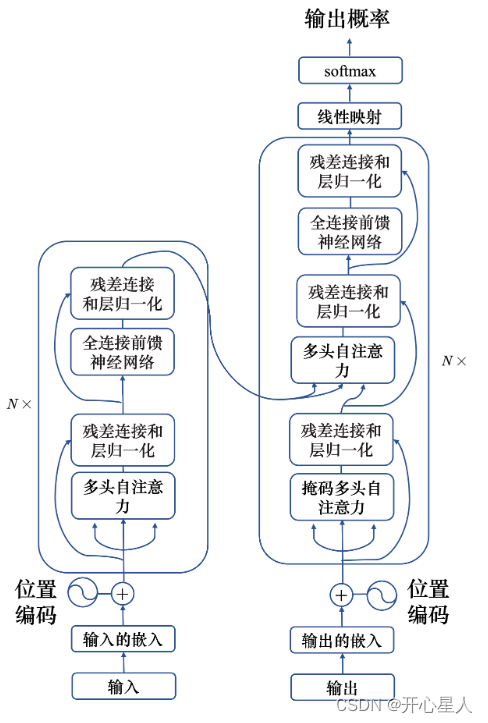
(1)輸入部分
- 源文本嵌入層:將源文本中的詞匯數字表示轉換為向量表示,捕捉詞匯間的關系。
- 位置編碼層:為輸入序列的每個位置生成位置向量,以便模型能夠理解序列中的位置信息。
- 目標文本嵌入層(在解碼器中使用):將目標文本中的詞匯數字表示轉換為向量表示。
(2)編碼器部分
- 由N個編碼器層堆疊而成。
- 每個編碼器層由兩個子層連接結構組成:第一個子層是多頭自注意力子層,第二個子層是一個前饋全連接子層。每個子層后都接有一個規范化層和一個殘差連接。
(3)解碼器部分
- 由N個解碼器層堆疊而成。
- 每個解碼器層由三個子層連接結構組成:第一個子層是一個帶掩碼的多頭自注意力子層,第二個子層是一個多頭注意力子層(編碼器到解碼器),第三個子層是一個前饋全連接層。每個子層后都接有一個規范化層和一個殘差連接。
(4)輸出部分
- 線性層:將解碼器輸出的向量轉換為最終的輸出維度。
- Softmax層:將線性層的輸出轉換為概率分布,以便進行最終的預測。
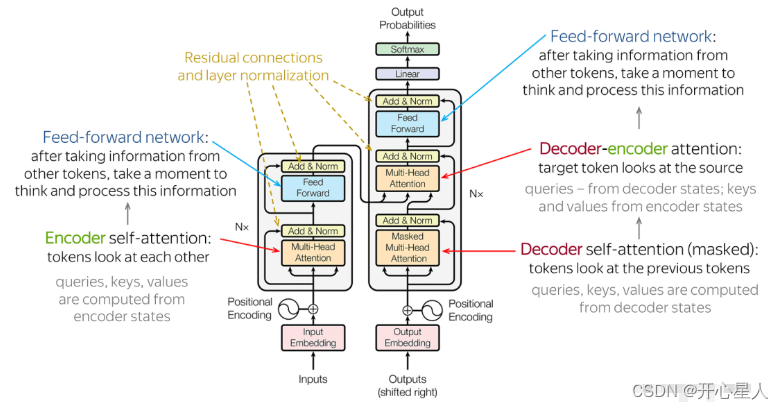
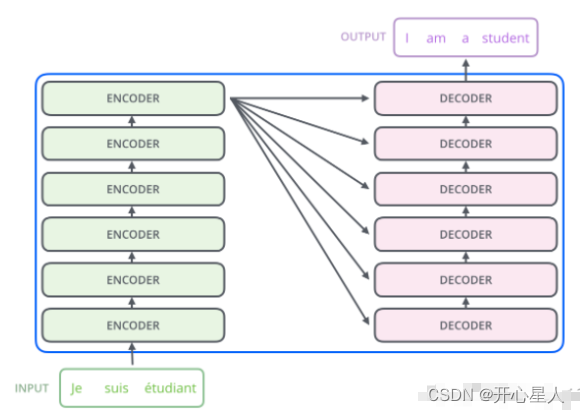
編碼器-解碼器
左邊是N個編碼器,右邊是N個解碼器,Transformer中的N為6。
編碼器
每個編碼器層都有兩個子層,即多頭自注意力層(考慮整個序列的信息)和逐位置的前饋神經網絡(Position-wise Feed-Forward Network)。在每個子層后面都有殘差連接(圖中的虛線)和層歸一化(LayerNorm)操作,二者合起來稱為 Add&Norm 操作
殘差連接:最左邊的向量 b 輸入到自注意力層后得到向量 a,輸出向量 a 加上其輸入向量 b 得到新的輸出。
層歸一化:層歸一化比信念網絡更簡單,不需要考慮批量的信息,而批量歸一化需要考慮批量的信息。層歸一化輸入一個向量,輸出另外一個向量。層歸一化會計算輸入向量的平均值和標準差。(批量歸一化是對不同樣本不同特征的同一個維度去計算均值跟標準差,但層歸一化是對同一個特征、同一個樣本里面不同的維度去計算均值跟標準差,接著做個歸一化。)
解碼器
每個解碼器層都有三個子層,掩碼自注意力層(Masked Self-Attention)、Encoder-Decoder自注意力層、逐位置的前饋神經網絡。同樣,在每個子層后面都有殘差連接(圖中的虛線)和層歸一化(LayerNorm)操作。
掩蔽自注意力可以通過一個掩碼來阻止每個位置選擇其后面的輸入信息。
原來的自注意力輸入一排向量,輸出另外一排向量,這一排中每個向量都要看過完整的輸入以后才做決定。根據 a1 到 a4 所有的信息去輸出 b1。掩蔽自注意力的不同點是不能再看右邊的部分。產生 b1 的時候,只能考慮 a1 的信息,不能再
考慮 a2、a3、a4。產生 b2 的時候,只能考慮 a1、a2 的信息,不能再考慮 a3、a4 的信息。
一開始解碼器的輸出是一個一個產生的,所以是先有 a1 再有 a2,再有 a3,再有a4。這跟原來的自注意力不一樣,原來的自注意力 a1 跟 a4 是一次整個輸進去模型里面的。編碼器是一次把 a1 跟 a4 都整個都讀進去。但是對解碼器而言,先有 a1 才有a2,才有 a3 才有 a4。所以只能考慮其左邊的東西,沒有辦法考慮其右邊的東西。
編碼器-解碼器注意力
編碼器和解碼器通過編碼器-解碼器注意力(encoder-decoder attention)傳遞信息,編碼器-解碼器注意力是連接編碼器跟解碼器之間的橋梁。解碼器中編碼器-解碼器注意力的鍵和值來自編碼器的輸出,查詢來自解碼器中前一個層的輸出。







——巧用序列化反序列化及BeanUtils反射等工具解決開發時對象、集合、字符串等多種形式間相互轉換的方法及技巧)











