在廣告行業一個吸引人的視覺布局能夠顯著提升信息的傳播效果。但對于非專業設計師來說,創建既美觀又功能性強的布局常常是一項挑戰。他們往往缺乏必要的設計技能、審美訓練或資源來快速實現創意構想。傳統的設計軟件和在線工具雖然提供了一些模板和指導,但這些往往限制了設計的個性化和創新性,難以滿足用戶多樣化和不斷變化的設計需求。
本文旨在解決這一問題,介紹一種基于指令跟隨模型的自動布局規劃方法。這種方法利用最新的人工智能技術,特別是大模型(LLMs)的指令跟隨能力,為用戶提供一種新的、用戶友好的設計工具。通過簡單的指令輸入,用戶可以指導模型理解設計目的和畫布尺寸,自動地將各種視覺元素(如文本、圖片、標志等)排列組合,生成符合特定應用場景(如海報、書籍封面、宣傳冊等)的定制化布局。

方法
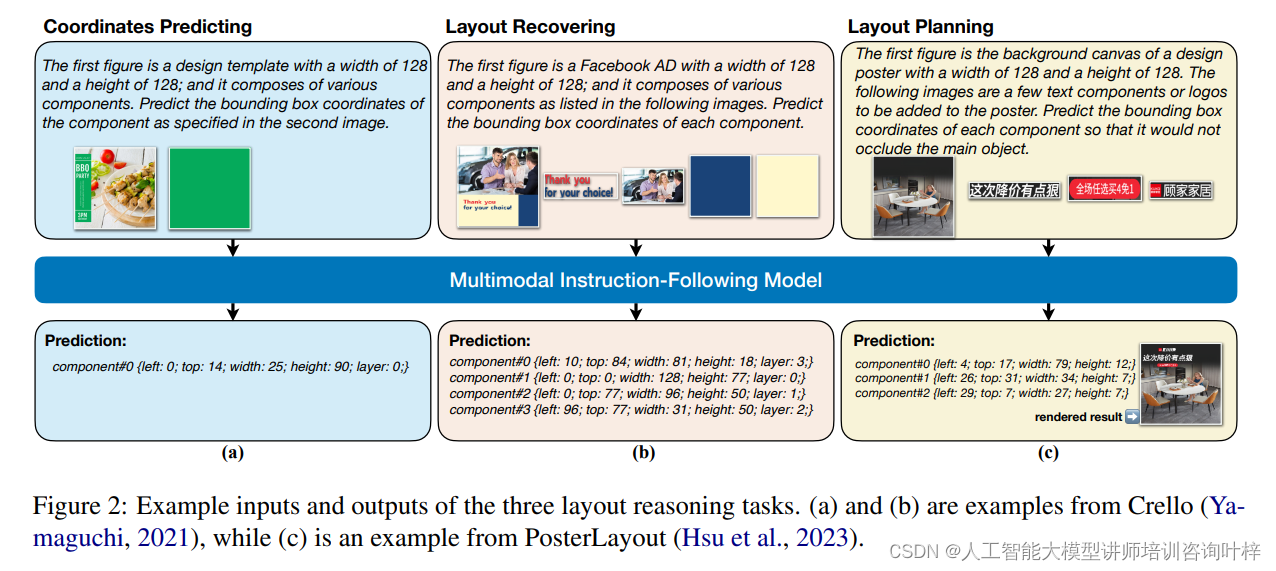
圖2為三個布局推理任務的示例輸入和輸出。這些任務是模型訓練的關鍵部分,旨在提高模型對布局指令的理解和執行能力。
(a) 和 (b) 的示例來自Crello數據集,由Yamaguchi在2021年提出。Crello數據集基于在線服務收集的設計模板,這些模板通常從一個空畫布開始,要求模型能夠組織所提供視覺組件的布局。這些示例展示了模型如何預測每個組件的邊界框坐標,以確保它們不會遮擋主要對象。例如,一個設計模板可能包含文本組件或標志,模型需要預測這些組件在畫布上的具體位置,同時考慮到它們之間的相互關系和視覺平衡。
(c) 的示例來自PosterLayout數據集,由Hsu等人在2023年提出。與Crello不同,PosterLayout數據集的畫布不是從空開始,而是已經包含了背景圖像,特別是針對海報的設計。在這種情況下,模型的任務是戰略性地放置文本、標簽和徽標等組件。這要求模型不僅要理解各個組件的視覺特性,還要考慮它們與背景圖像的關系,以及如何在保持設計美觀的同時傳達必要的信息。
這些示例展示了模型在不同設計場景下的應用能力,包括從空白畫布開始的布局規劃和在有背景的畫布上進行組件放置。通過這些任務的訓練,模型能夠學習如何在不同的設計約束下有效地安排視覺元素,以實現既定的設計目的和審美要求。
在視覺豐富文檔的創建過程中,設計元素的多樣性和畫布上的分布對于實現有效的視覺傳達至關重要。為了保持原始文本設計的完整性,文本內容在實驗設置中被轉換成圖像。布局規劃任務涉及將這些設計組件,以圖像序列的形式提供,例如![]() 其中 n 代表組件的數量,按照特定應用場景 a(如海報、Instagram帖子、書籍封面)和定義好的尺寸 w(寬度)和 ?(高度)進行排列。畫布可能是空白的,或者有預定義的背景。
其中 n 代表組件的數量,按照特定應用場景 a(如海報、Instagram帖子、書籍封面)和定義好的尺寸 w(寬度)和 ?(高度)進行排列。畫布可能是空白的,或者有預定義的背景。
為了提供更適應性強的解決方案并增強用戶體驗,研究者采用了指令跟隨的方式來處理視覺豐富的布局規劃任務。模型除了接收設計組件的序列外,還會根據應用場景和畫布尺寸接收詳細的指令 I。模型的任務是預測每個組件的布局,并以結構化格式輸出,包括CSS樣式,如上、左、寬、高以及層級屬性,后者管理可能重疊元素的堆疊順序。
研究者提出的模型 DocLap 擴展了 mPLUG-Owl,這是一個集成了大型語言模型(LLM)、視覺編碼器和視覺抽象器模塊的多模態框架。它采用了 Llama-7b v1 作為大型語言模型,CLIP ViT-L/14 作為視覺編碼器。視覺抽象器模塊將 CLIP 的視覺特征轉換為64個標記,與文本嵌入的維度相匹配,允許同時處理多個視覺輸入。研究者擴展了 Llama v1 的詞匯表,增加了0到128范圍內的數值標記,并在進一步的指令調整中調整了這些擴展標記的嵌入。
?實驗設置
研究者在兩個視覺豐富文檔的布局規劃基準測試上進行了實驗:Crello和PosterLayout。Crello數據集基于從在線服務收集的設計模板構建,挑戰模型從空白畫布開始組織所提供視覺組件的布局。而PosterLayout數據集則從帶有背景圖像的非空白畫布開始,要求模型策略性地放置文本、標簽和徽標。為了確保實驗的公平性,驗證示例被限制為不超過4個圖像,這與提交時GPT-4V的輸入約束一致。
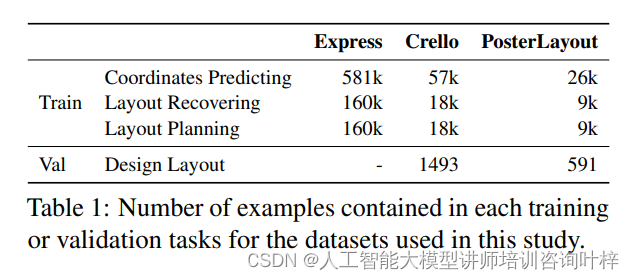
研究者的訓練數據得到了Adobe Express設計模板的補充。具體到每個訓練或驗證任務的數據集示例數量,如表1所示。在預處理階段,小于畫布大小5%的組件被排除,所有模板都被調整大小以確保最長邊不超過128像素。
為了評估所提出模型的性能,研究者將其與Crello上的CanvasVAE和FlexDM,以及PosterLayout上的DSGAN進行了比較。此外,還包括了GPT-4和GPT-4V的文本版本進行比較評估。對于這些文本版本的評估,視覺組件不直接提供,而是通過BLIP-2生成每個組件的文本描述。
對于Crello的評估,研究者測量了預測和實際邊界框之間的平均交并比(mIoU),以及左、上、寬、高維度的準確性。準確性通過將預測值與真實值進行64-bin量化范圍比較來量化,如果預測值落在與真實值相同的范圍內,則得分為1,否則為0。在PosterLayout的評估中,研究者采用了內容感知度量標準,包括遮擋率(表示主要對象被設計元素遮擋的百分比)、效用率(反映設計組件覆蓋非主要對象區域的程度)和不可讀性(測量包含文本元素的區域的均勻性)。
結果
結果顯示在模型間交并比(mIoU)和各方面(左、上、寬、高)的精度上,DocLap模型超過了少量GPT-4(V)模型,但與FlexDM相比仍有提升空間。
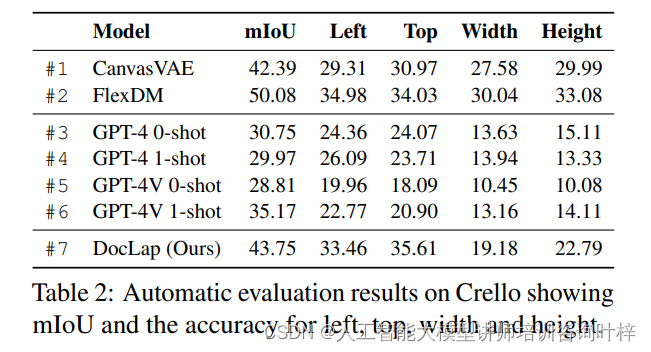
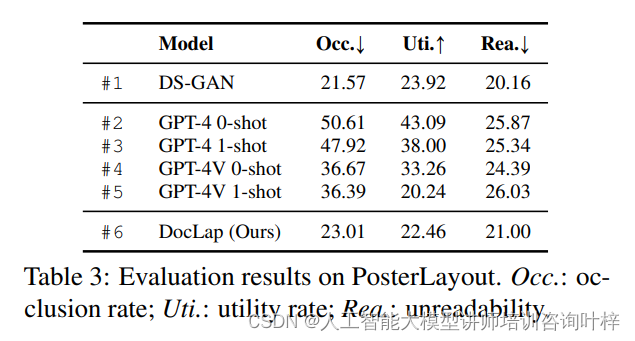
表2展示了Crello數據集上的評估結果,包括mIoU和各個維度的準確性。表3則展示了PosterLayout數據集上的評估結果,其中包括遮擋率、效用率和不可讀性等指標。?
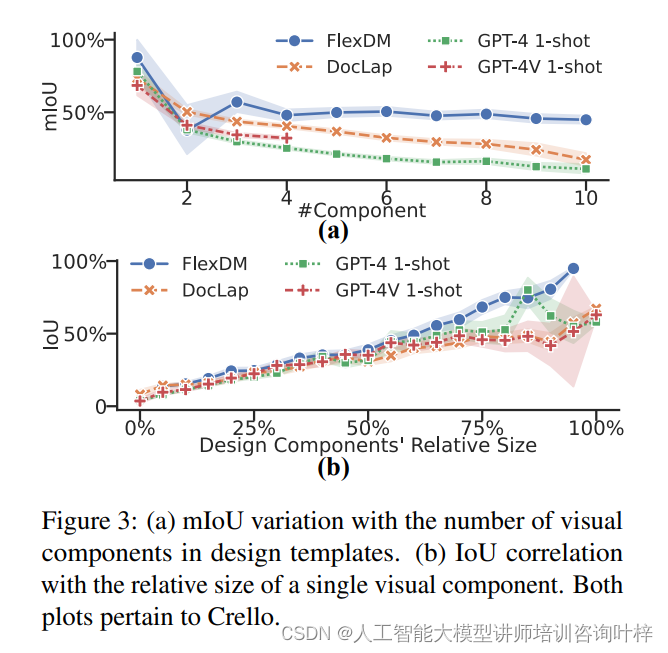
(b)單個視覺組件的相對大小與模型預測與真實值的IoU之間的相關性
圖3(a)揭示了所有列出的模型在只有一個組件的模板上展現出高mIoU。隨著組件數量的增加,DocLap和GPT-4(V)的mIoU呈現下降趨勢,這表明涉及更多視覺組件的更復雜場景可能對當前的指令跟隨模型構成挑戰。
圖3(b)展示了單一視覺組件的相對大小與模型預測的IoU與真實值之間的線性相關性。這表明較小的視覺組件在布局規劃中實現精確放置面臨更大挑戰。這些小組件,如標志、小文本框或裝飾元素,在布局中具有一定的位置靈活性,允許多種有效的放置方式。


圖4和圖5分別展示了Crello和PosterLayout的布局規劃結果示例。這些示例包括了真實情況、DocLap模型的輸出、GPT4V模型的輸出以及FlexDM和DS-GAN模型的輸出。通過這些示例,研究者展示了不同模型在處理具有挑戰性的設計任務時的表現。
通過定量和定性的結果分析,研究者揭示了其在簡化設計流程和提升非專業設計者效率方面的顯著潛力,同時也指出了在面對復雜設計任務時的局限性:盡管DocLap在簡化設計過程和提高非專業用戶的設計效率方面顯示出潛力,但在處理更復雜的設計場景時,模型的性能有所下降。盡管如此,這項工作為設計自動化領域提供了寶貴的見解,并強調了開發更全面的評估體系的重要性。
論文鏈接:https://arxiv.org/abs/2404.15271


(postrender 事件和 render 方法))
















