目錄
一、實驗目的... 1
二、實驗環境... 1
三、實驗內容... 1
1)Python縱向柱狀圖實訓... 1
2)Python水平柱狀圖實訓... 3
3)Python多數據并列柱狀圖實訓.. 3
4)Python折線圖實訓... 4
5)Python直方圖實訓... 5
6)機器學習中的可視化應用... 6
四、思考問題... 8
五、總結與心得體會... 8
一、實驗目的
掌握python工具,能夠進行數據可視化;
掌握商業案例中的數據分析與數據可視化
二、實驗環境
硬件:微型圖像處理系統,
包括:主機, PC機;
操作系統:Windows 11????????
應用軟件:Jupyter Notebook, pycharm
數字圖像處理軟件:Excel/Python
三、實驗內容
1)Python縱向柱狀圖實訓
為了顯示男女愛好的人數分布,本實驗使用Python繪制縱向柱狀圖實現數據可視化。編寫以下代碼:
| import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', family='SimHei', size=15)
plt.title("男女愛好人數分布圖"); #圖標題
num = np.array([14325, 9403, 13227, 18651])
ratio = np.array([0.75, 0.6, 0.22, 0.1])
men = num * ratio
women = num * (1-ratio)
x = ['足球','游泳','看劇','逛街']
width = 0.5
idx = np.arange(len(x))
plt.bar(idx, men, width, color='red', label='男性用戶')
plt.bar(idx, women, width, bottom=men, color='gray', label='女性用戶')? #這一塊可設置bottom,top,如果是水平放置的,可以設置right或者left。
plt.xlabel('應用類別')
plt.ylabel('男女分布')
plt.xticks(idx+width/2, x, rotation=40)
#bar圖上顯示數字
for a,b in zip(idx,men):
??? plt.text(a, b+0.05, '%.0f' % b, ha='center', va= 'bottom',fontsize=12)
for a,b,c in zip(idx,women,men):
??? plt.text(a, b+c+0.5, '%.0f' % b, ha='center', va= 'bottom',fontsize=12)
plt.legend()
plt.show() |
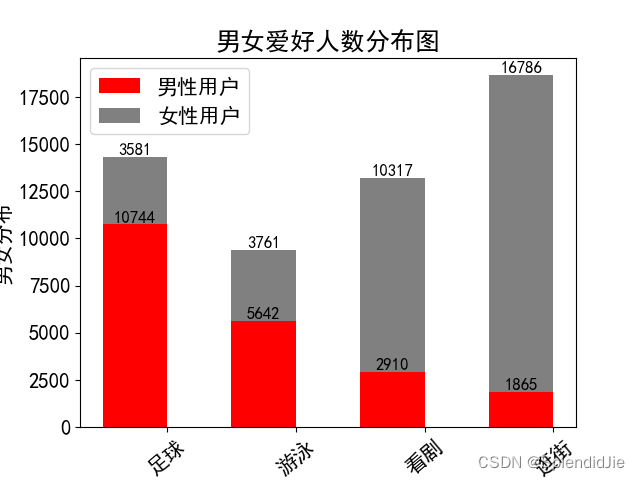
運行結果如下,可以看出男性的愛好多數為足球和游泳,女生的愛好多數為看劇和逛街:
2)Python水平柱狀圖實訓
為了繪制水平柱狀圖,編寫以下代碼:
| import matplotlib.pyplot as plt
plt.rc('font', family='SimHei', size=15)
# 假設我們有一組數據,表示不同的類別的值
categories = ['類別 A', '類別 B', '類別 C', '類別 D', '類別 E']
values = [20, 35, 30, 10, 25]
# 創建水平柱狀圖
plt.barh(categories, values, color='skyblue')
# 添加標簽和標題
plt.xlabel('值')
plt.ylabel('類別')
plt.title('水平柱狀圖實訓')
# 可選:顯示每個條形上方的值
for index, value in enumerate(values):
??? plt.text(value, index, str(value))
# 顯示圖形
plt.show() |
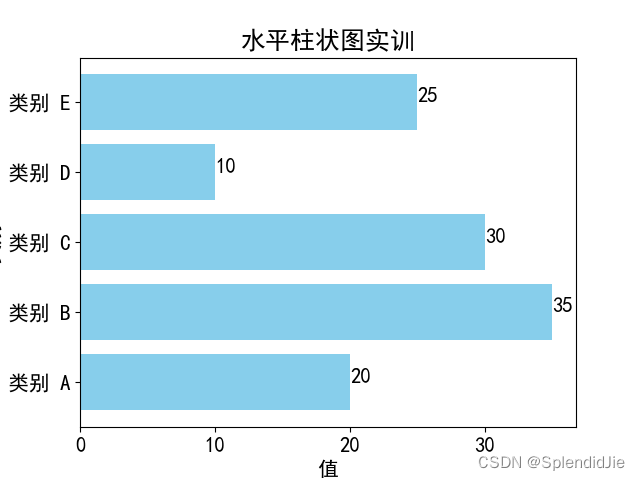
運行結果如下:
3)Python多數據并列柱狀圖實訓
本實驗展示了不同的專業在不同學校的招收人數分布圖情況。編寫以下代碼:
| import matplotlib.pyplot as plt
import numpy as np
plt.rcParams[ 'font.sans-serif'] =[ 'Microsoft YaHei'] #設置字體
plt.title("不同學校專業招生人數分布圖"); #圖標題
x=np.arange(5)
y=[400,170,160,90,50]
y1=[300,180,150,70,90]
bar_width=0.5
tick_label=["計算機","機械","電子","管理","物理"]
plt.bar(x,y,bar_width,color="r",align="center",label="學校A")
plt.bar(x+bar_width,y1,bar_width,color="y",align="center",label="學校B")
plt.xlabel("專業")
plt.ylabel("招生人數")
plt.xticks(x+bar_width/2,tick_label)
plt.legend()
plt.show() |
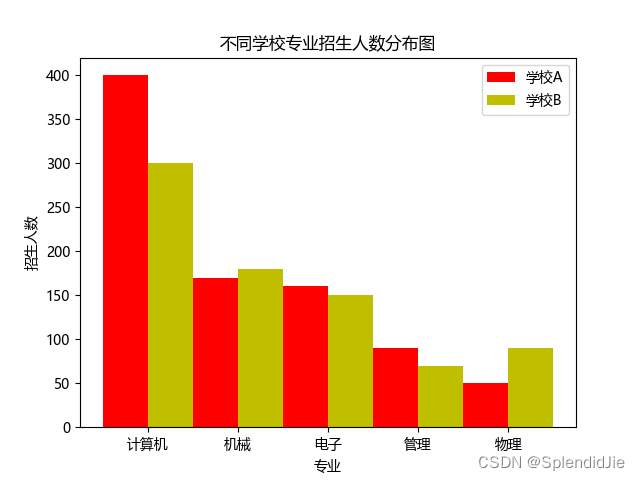
根據結果顯示,學校a和學校b均在計算機專業招收人數最多,具體的情況如下圖:
4)Python折線圖實訓
本實驗繪制2019年1月~2019年12月的房價變化折線圖,編寫以下代碼:
| import matplotlib.pyplot as plt
plt.rcParams[ 'font.sans-serif'] =[ 'Microsoft YaHei'] #設置字體
x1 = ['2019-01', '2019-02', '2019-03', '2019-04', '2019-05', '2019-06', '2019-07', '2019-08',
????? '2019-09', '2019-10', '2019-11', '2019-12']
y1 = [9700, 9800, 9900, 12000, 11000, 12400, 13000, 13400, 14000, 14100, 13900, 13700]
plt.figure(figsize=(10, 8))
# 標題
plt.title("房價變化")
plt.plot(x1, y1, label='房價變化', linewidth=2, color='r', marker='o',
???????? markerfacecolor='blue', markersize=10)
# 橫坐標描述
plt.xlabel('月份')
# 縱坐標描述
plt.ylabel('房價')
for a, b in zip(x1, y1):
??? plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.legend()
plt.show() |
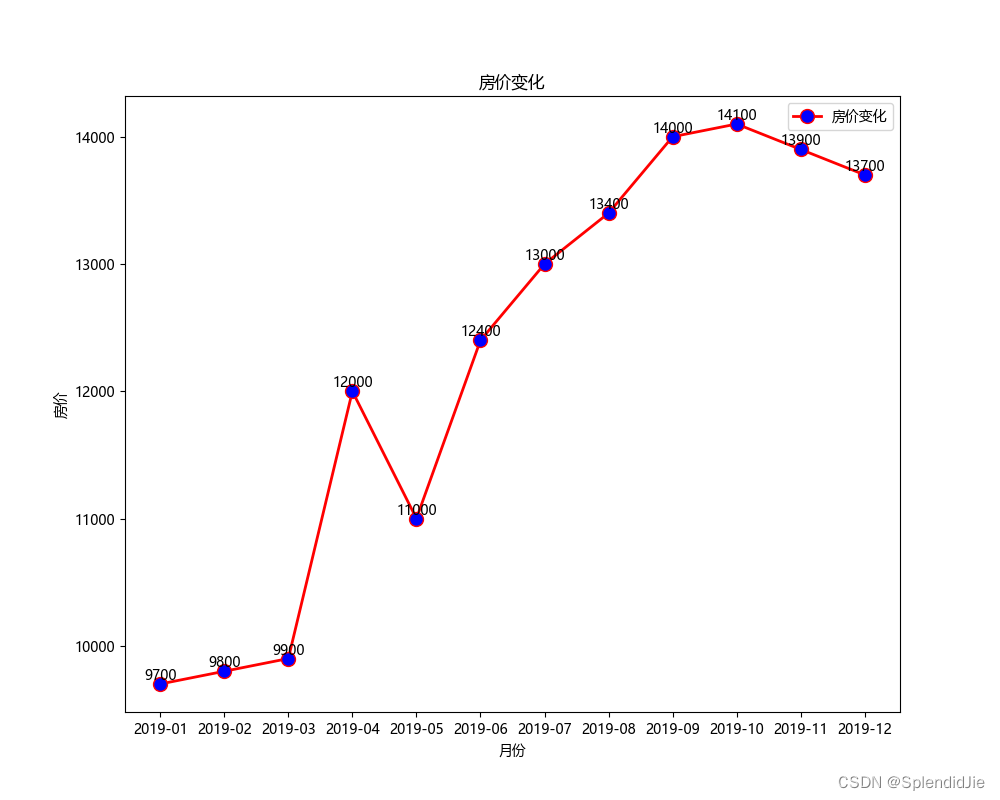
從結果可以看出,在2019年1月的時候房價最低,在2019年12月的時候,房價最高整體呈上升趨勢,其中在2019年5月的時候下降。運行結果如下:
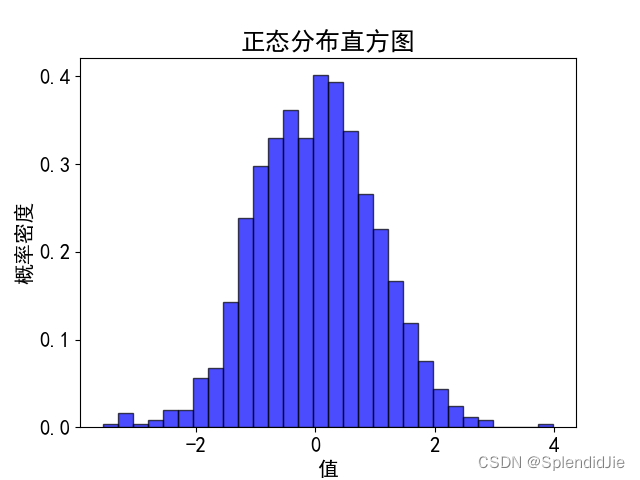
5)Python直方圖實訓
本實驗繪制正態分布直方圖,圖的值表示當前值的概率密度,為了方便信息展示只展示-4到4的概率密度,編寫以下代碼:
| import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', family='SimHei', size=15)
plt.rcParams['axes.unicode_minus'] = False? # 解決保存圖像是負號'-'顯示為方塊的問題
# 生成一個隨機樣本數據集
# 假設我們有一個正態分布的隨機樣本
data = np.random.normal(loc=0, scale=1, size=1000)
# 創建直方圖
# bins 參數定義了直方圖的箱數
# density 參數設置為 True,可以展示概率密度而不是頻率
plt.hist(data, bins=30, density=True, alpha=0.7, color='blue', edgecolor='black')
# 設置直方圖的標題和坐標軸標簽
plt.title('正態分布直方圖')
plt.xlabel('值')
plt.ylabel('概率密度')
# 可選:顯示直方圖的均值和標準差
mean = np.mean(data)
std_dev = np.std(data)
plt.text(60, 0.0075, f'Mean: {mean:.2f}')
plt.text(60, 0.005, f'Std Dev: {std_dev:.2f}')
# 顯示圖形
plt.show() |
運行結果如下:
6)機器學習中的可視化應用
在機器學習中,可視化是一個重要的工具,它可以幫助我們理解數據的特征、模型的性能以及數據點之間的關系。以下是一個簡單的Python代碼示例,展示了如何在機器學習中應用可視化。編寫以下代碼:
| import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
import seaborn as sns
# 創建一個簡單的二分類數據集
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2,
?????????????????????????? random_state=1, n_clusters_per_class=1)
# 使用邏輯回歸模型
model = LogisticRegression()
model.fit(X, y)
# 繪制決策邊界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
???????????????????? np.arange(y_min, y_max, 0.01))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 6))
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary using Logistic Regression')
plt.show() |
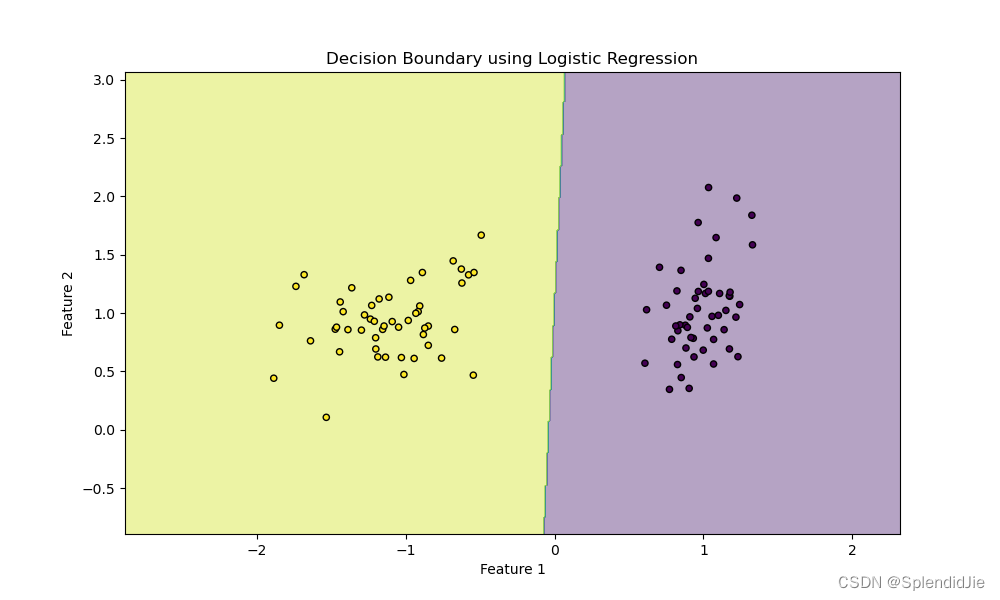
這段代碼首先導入了所需的庫,然后創建了一個簡單的二分類數據集。接著,使用LogisticRegression模型進行擬合。
在繪制決策邊界的部分,我們首先定義了x和y的最小值和最大值,然后創建了一個網格來覆蓋整個數據點的范圍。使用模型在這些網格點上的預測結果來填充這個區域,從而繪制出決策邊界。
最后,使用plt.scatter繪制了原始數據點,并用不同的顏色表示不同的類別。plt.contourf用于繪制決策邊界的填充圖。運行結果如下:
四、思考問題
Python軟件功能強大,除了上述要實現的功能,大家可以自己進行擴展。
五、總結與心得體會
在完成上述的可視化制作實驗后,我有以下幾點心得體會:
- 理解數據分布:通過制作直方圖和折線圖,我更好地理解了數據的分布情況和隨時間的變化趨勢。直方圖特別適合展示連續數據的分布,而折線圖則能夠清晰地展示數據隨時間的變化。
- 比較不同類別:縱向柱狀圖和水平柱狀圖都是比較不同類別之間數值大小的有效工具。我學會了如何根據需要選擇使用縱向或水平柱狀圖,這取決于我希望強調的信息和圖表的布局。
- 并列柱狀圖的挑戰:在制作多數據并列柱狀圖時,我意識到需要仔細選擇顏色和標簽,以確保每個數據集都能被清晰地區分和理解。
- 技術實現:通過這些實驗,我加深了對matplotlib和seaborn庫的了解,學會了如何使用這些工具來創建各種圖表。我也認識到了代碼的可讀性和模塊化設計的重要性,這使得代碼更易于維護和更新。
- 數據可視化的重要性:我了解到,良好的數據可視化可以幫助觀眾快速抓住數據的關鍵信息。圖表的清晰度和準確性對于有效傳達分析結果至關重要。
- 機器學習可視化的洞察:在機器學習項目中,可視化不僅用于展示數據,還可以用于展示模型的決策過程,如決策邊界。這有助于理解模型是如何工作的,以及它在特定情況下可能的優缺點。
- 迭代與改進:在實驗過程中,我學會了如何根據反饋不斷迭代和改進我的圖表。一個好的圖表往往需要多次修改,包括調整顏色、字體大小、標簽和布局。
- 工具的局限性:我也意識到了可視化工具的局限性。例如,某些類型的數據或分布可能不適合用柱狀圖或直方圖來展示。因此,選擇最合適的圖表類型來傳達特定的信息是一項重要的技能。
- 注釋和解釋:我學會了在圖表中添加適當的注釋和解釋,這對于使圖表自解釋非常重要。這包括軸標簽、圖例、標題和任何必要的文本說明。
- 未來方向:最后,我意識到數據可視化是一個不斷發展的領域,總有新的技術和方法出現。我計劃繼續學習,以便能夠利用最新的工具和技術來提高我的可視化技能。
- 通過這些實驗,我不僅提升了我的技術技能,而且對如何有效地傳達數據信息有了更深刻的理解。這些經驗對我的數據科學職業生涯將是寶貴的資產。


















![洛谷 P3954 [NOIP2017 普及組] 成績](http://pic.xiahunao.cn/洛谷 P3954 [NOIP2017 普及組] 成績)
