文章目錄
- 前言
- 入門基本指令篇章
- 字符集設置
- cd
- ls
- date
- mkdir
- touch
- -d
- -m
- 修改主機名
- rm
- shred
- rename重命名
- mv移動
- tar打包與壓縮
- 打包但是不壓縮
- 打包且壓縮
- 更新包文件
- 解壓對應的包
- zip壓縮文件命令
- cat查看
- 顯示行號
- 交互寫入(追加)
- 顯示空行
- more和less
- head和tail
- head
- tail (能夠實時監測內容)
- -F
- -f
- tac
- wc
- du
- -s
- -h
- find
- -exec
- -ok
- -mtime
- grep
- xargs -i(神器)
- 其他參數
- stat
- history
- history的工作流程
- 其他指令
- vim
- write寫入
- 命令行模式搜索字符
- 取消搜索的高亮
- 替換內容
- 單行替換(替換一次)
- 單行替換(替換所有)
- 全文匹配替換(每行替換一次)
- 全文替換(全部搜索符合的都替換)
- 可視化快(進行列操作)
- 粘貼模式
- 設置和取消行號
- 復制、粘貼
- 刪除和剪切
- 撤銷
- 恢復
- 回到整個文檔開頭段
- 回到整個文檔末尾段
- 回到行首
- 回到行尾
- 定位到第幾行
- 命令行模式光標移動
- .swp文件
- 環境變量(個性化自定義設置)
- env 和 set
- PS1
- 臨時生效
- 永久生效
- 用戶bash損壞修復
- 用戶管理篇章
- useradd
- passwd
- usermod
- userdel
- id
- 用戶相關的配置文件
- 組管理
- groupadd
- groupmod
- groupdel
- whoami/who/w/last/lastlog
- sudo
- 文件權限篇章
- 權限了解
- chmod
- 文件權限的數字表示法
- chown
- chgrp
- ln
- suid
- sgid
- sbit
- 系統服務篇章
- ssh服務
- network服務
- 配置網絡服務
- 服務管理
- systemctl
- systemctl
- 總結
- service
- chkconfig
- scp文件傳輸服務
- ntp時間服務
- 同步時間
- 更改時區
- 定時任務
- 基本設置
- 黑白名單限制
- 進程管理篇章
- 孤兒進程
- 僵尸進程
- ps
- top
- lsof
- 找回文件之練習題
- kill
- pkill
- 后臺運行命令
- 三劍客篇章
- 通配符
- find找文件與通配符
- 特殊符號
- cd路徑相關
- 引號相關
- 重定向
- 命令執行
- 正則表達式
- 基本正則表達式
- 擴展正則表達式
- 注意點
- grep
- ( ) 括號、分組符。很好用!!!
- 分組與向后引用
- sed
- 參數
- 命令
- 增
- 刪
- 查
- 改
- 注意
- 其他命令
- 多次編輯-e
- 寫入文件w命令
- ;分號
- awk
- 動作
- NR內置變量
- NF內置變量
- 其他變量
- BEGIN 和 END
- 參數
- 系統資源篇章
- 軟件包篇章
- 磁盤篇章
前言
本文章僅僅是我個人學習過程中,覺得會在安全領域用的比較多的命令,也有一些本散修在Linux入門學習中的一些命令與總結心得。
道友們可參考一二我的修煉心得,切勿無腦修煉,適合自己的才是最好。
入門基本指令篇章
字符集設置
很多shell腳本里都有這么一個語句如下
LC_ALL=C
這個變量賦值的動作,是等于還原linux系統的字符集
因為我們系統本身是支持多語言的
德文
英文
中文
每一個語言都有其特有的語言,字符,計算機為了統一字符,生成了編碼表
比如你平時喜歡讓linux支持中文,如果你的系統編碼是中文,很可能導致你的正則出錯,因此要還原系統的編碼
LANG=‘zh_CN.UTF-8’
執行一個還原本地所有編碼信息的變量
LC_ALL=C
- LC_ALL是表示設置全局變量,所以shell腳本里為了腳本不出錯就會經常先設置這個
- 設置全局通用用法是輸入如下指令:
export LC_ALL=C - 如果要還原就輸入如下指令即可:(就是讓他變回空即可)
export LC_ALL= - 要查看你是否設置成功,可以直接使用如下兩個指令查看
第一個: locale第二個: 一般我們會使用$LANG變量來設置linux的字符集,一般設置為我們所在的地區,如zh_CN.UTF-8 直接echo $LANG 也可以看到你設置了哪個字符集
cd
cd ~ #當前用戶的家目錄
cd - #回到上次你所在的目錄,比如有時候我從home目錄中操作完了,然后去到/etc/目錄下,然后又想回到home目錄的話就要重新輸入路徑,這樣很麻煩,那么我們就可以使用cd -,然后回到上次訪問的目錄
cd .. #回到上一層目錄
ls
ll #能看到屬性,并且以列形式查看
ls #一行一行顯示文件和文件夾
ls -l == ll #-l參數加在ls等于llls/ll -a # -a參數表示查看所有文件,隱藏文件也能看到ll -d 目錄名 # 只看目錄的屬性ls -i #顯示文件的i節點號,相當于文件的身份id
date
[root@localhost ~]# date '+%F %T'
2024-06-28 14:39:39
[root@localhost ~]# date '+%F&&%T'
2024-06-28&&14:40:36
mkdir
遞歸創建
mkdir -p /xxx/xxx/xxx
創建單個目錄,mkdir即可
touch
創建多個文件
touch 1 2 3 4
用空格隔開即可創建多個文件
可以通過批量創建 touch a{1..100}.log #會以a1.log a2.log ... 以此類推進行,同時還可以{a..z} {A..Z}
-d
-d參數可以指定時間 比如 touch -d ‘2024-01-01’ 他的最近改動時間就會以你的時間進行創建出來
一般你想要修改時間基本使用這個就行了。
-m
-m參數,改變檔案的修改時間記錄,這個和-d一起使用的時候,會將文件的最近訪問時間也一起修改成當前時間。
以下是實踐出來的例子

修改主機名
查看主機名指令:hostname
臨時修改主機名:hostname xxx
永久修改主機名:hostnamectl set-hostname xxx
rm
rm刪除動作
-r 遞歸刪除 (要刪除目錄的時候必須要用到)
-f 強制刪除
-i 刪除的時候進行提示 (因為我們alias中就已經將rm == rm -i , 所以我們使用刪除rm都是自帶-i參數,除非你自己改過)
shred
粉碎文件,導致文件無法恢復或者說難以通過數據恢復技術進行恢復shred file #就是粉碎一個文件,過程是將該文件輸入一些二進制數據,但是該文件還在的,只是內容無法恢復回來了而已。
rename重命名
rename 源字符 替換字符 文件名
# 源字符就是在你給出的文件名的這個文件,進行找到源字符,然后使用替換字符進行替換,這樣就是一個重命名過程。這個和mv進行重命名操作有點不同,rename就是直接的為重命名而生,rename可以挑選文件名中某個字符進行重命名,而mv是你給的名字就是直接覆蓋源文件名。
mv移動
mv 源 目的
比如:
mv a.txt /etc/a.txt #這個就是移動過去就叫a.txt
或者
mv a.txt /etc/b.txt #這個相當于重命名,其實mv移動的時候就是相當于一個復制+重命名的操作mv a.txt /etc #這樣也可以,就是把a.txt移動到etc目錄下
tar打包與壓縮
tar在壓縮和打包過程中是可以直接將文件夾直接壓縮的,不會像rm或者其他命令一樣需要加一個r遞歸參數(zip命令壓縮文件夾就需要)
tar命令
-f 必須要加的參數且加在最后,后面要跟打包的名字 tar -cvf 打包名 要打包的一些文件-c 創建包
-v 顯示打包過程
-t 查看一下包中有什么文件
-u 往你包中添加文件,就是更新的意思-z 壓縮包,這個是.gz格式,還有其他壓縮格式
-j 壓縮為.bz2格式
-J 壓縮為.xz格式記住一點:f參數一定要放在所有參數后面,因為要接打包名字
打包但是不壓縮
tar -cf 包名.tar 要打包的文件
打包且壓縮
tar -czf 包名.tar.gz 要打包的文件
更新包文件
tar -uf 包名.tar[.gz] 要添加進去的文件
解壓對應的包
解壓.gz包:tar -xzf 包名
解壓.bz2包:tar -xjf 包名
解壓.xz包:tar -xJf 包名
以上均沒有添加-v參數,但是奉勸一句,建議都加上,例子不加是因為怕混淆,加上-v既裝逼又能夠詳細的知道解壓了哪些文件出來。
zip壓縮文件命令
壓縮文件(普通壓縮)
zip 壓縮包名.zip 文件1 文件2 。。。
壓縮文件夾
zip -r 壓縮包名.zip 文件夾
解壓縮
unzip 壓縮包 #解壓到當前文件夾unzip 壓縮包 -d 指定解壓位置 #解壓到指定文件夾
cat查看
顯示行號
cat -n 文件名 #查看出來的文件內容顯示行號
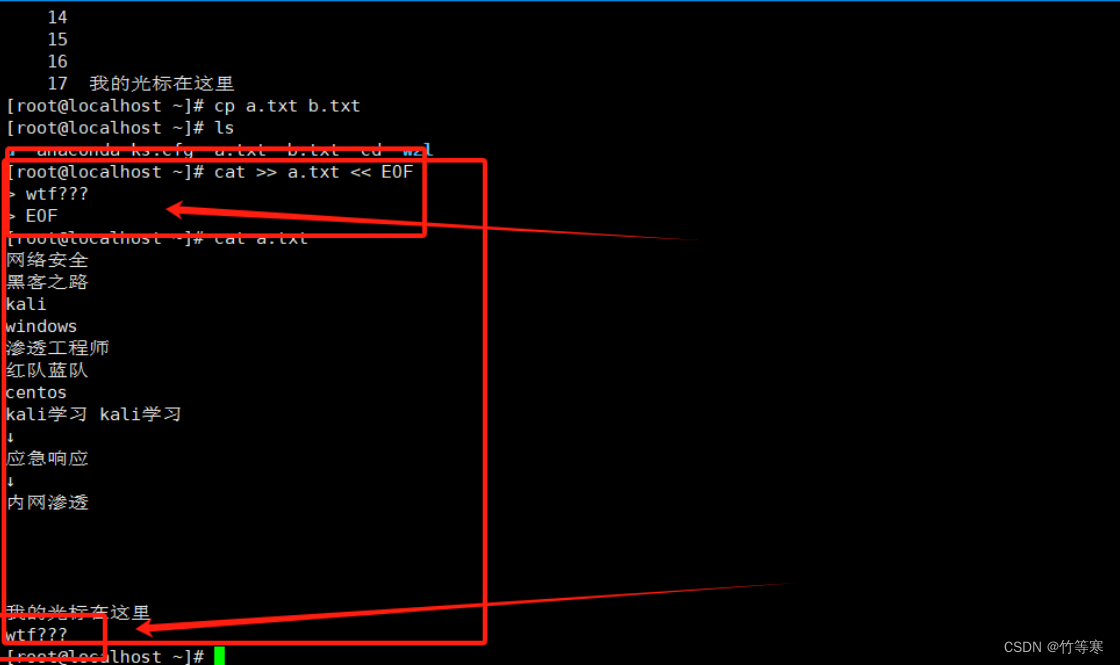
交互寫入(追加)
cat >> 文件名 << EOF
這個可以進入一個交互式輸入模式,用了兩個>> 和<<,那就代表是追加模式,所以我們進入交互模式后輸入的東西,一直到你輸入EOF表示結束,然后內容就會被追加進去。
顯示空行
(目前不知道誰能和它組合一起使用)
cat -b 文件名

more和less
more和cat都是一次性讀取文件內容到內存中,對于大文件來說十分消耗資源。
less就是一行一行的讀取,一點點的加載。
more和less的效果是一樣的,只是底層加載不一樣。
more是你讀取完之后直接退出,less是要按q按鍵才能退出。
head和tail
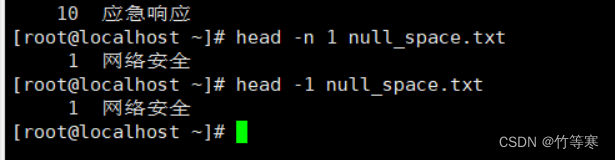
head
理解:head是想看文件頭幾行,tail是你新加入了文件內容后,你想看新加入的內容就使用tail
head -行數 文件名
或者
head -n 行數 文件名 #這個兩個一樣
tail (能夠實時監測內容)
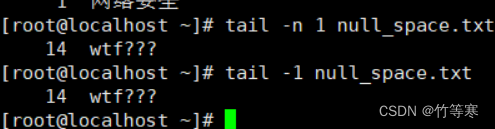
同理
tail -行數 文件名
或者
tail -n 行數 文件名 #這個兩個一樣
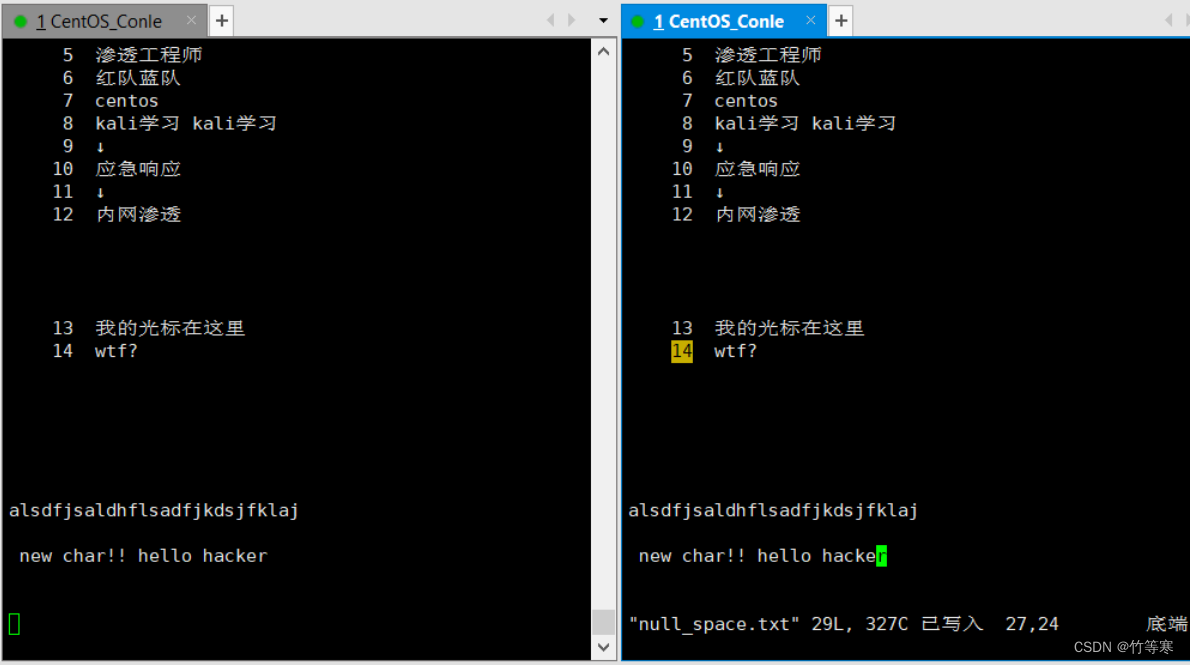
-F
實時監測內容參數是**-F**
同時他還能檢測還問創建的文件,這個就像是一個蜜罐一樣,有人碰了一個文件,被創建出來了那就中圈套了。而-f卻不可以,-f只能監測已經被創建出來的文件。
tail -F 文件名 #目前測試過好像不能加 -n參數

保存后即可就顯示過來了(注意我源數據本身就有標行號,加進去后就沒有行號,所以我這里是沒有加-n參數的哈)
- 同時他還能完成-f的動作,實時監測程序追加進去的內容,比如追蹤log日志文件。個人感覺直接用-F就行了。
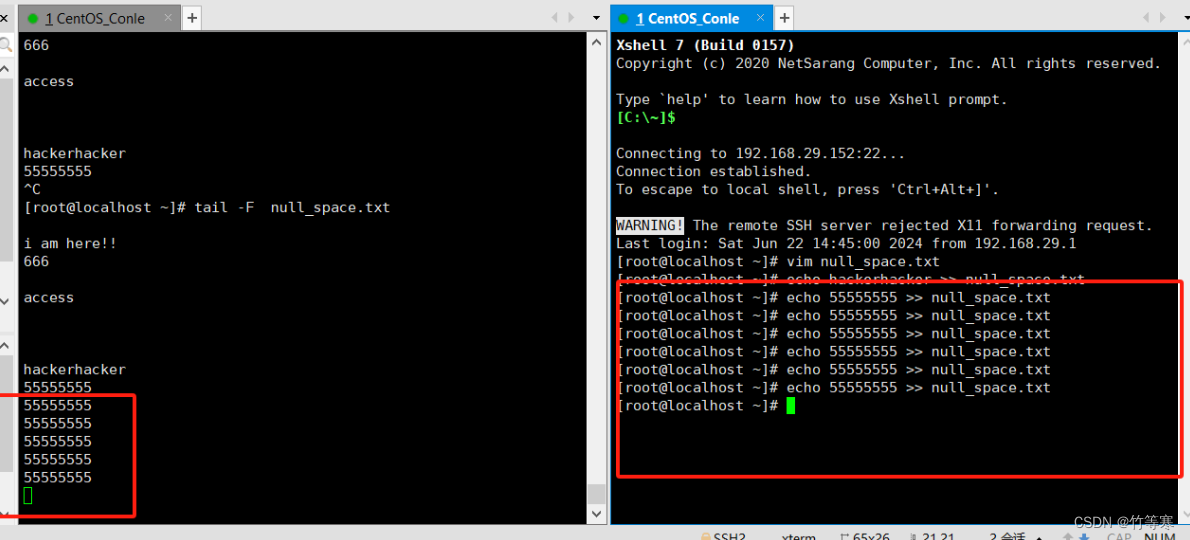
- 可以檢測未存在的文件
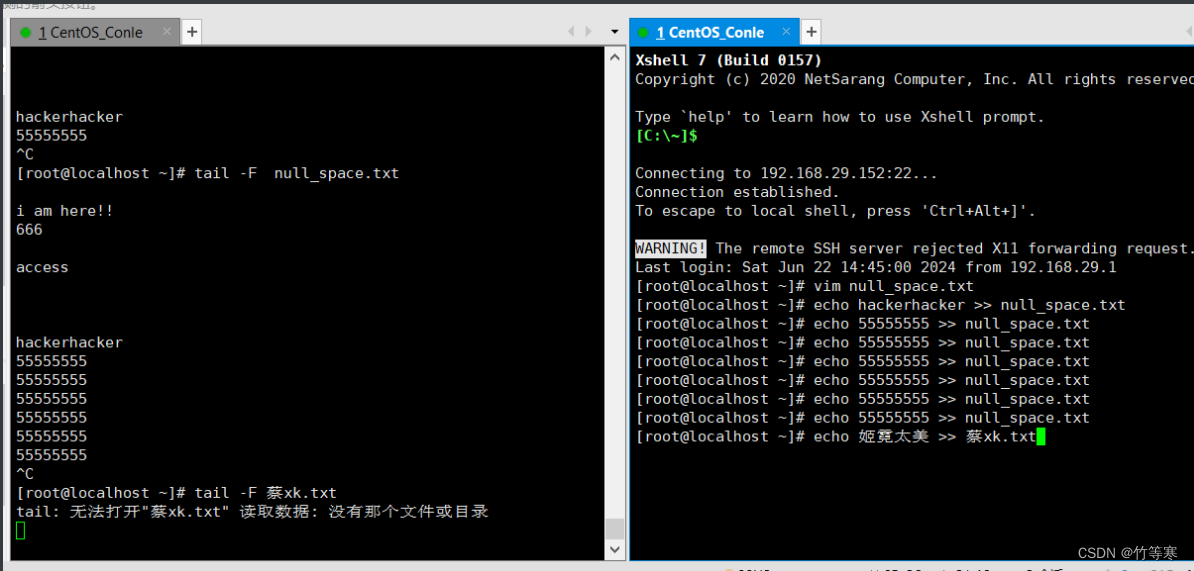
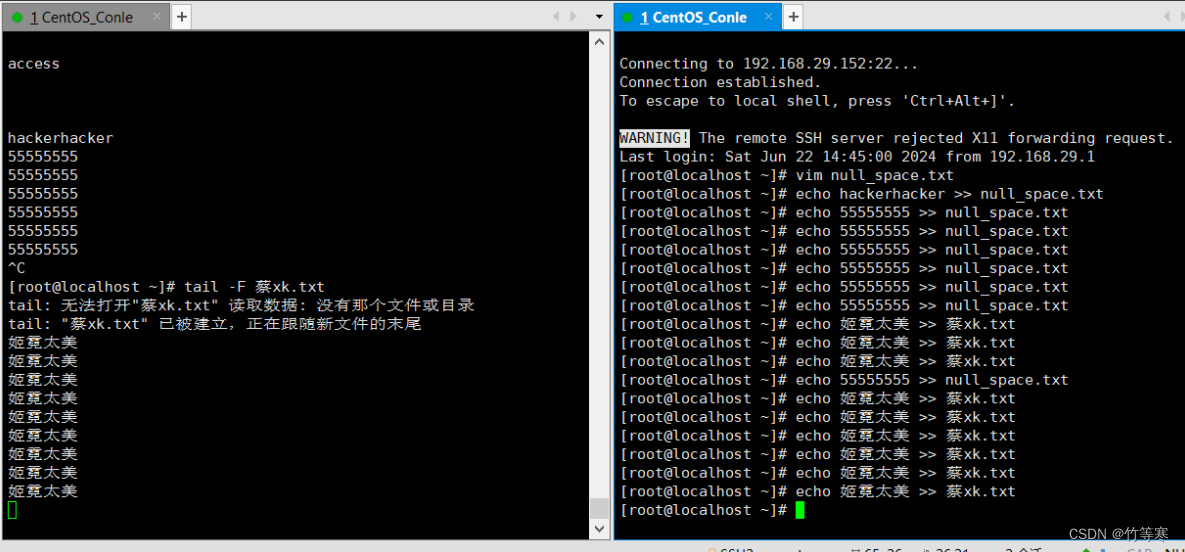
-f
只能監測已經被創建出來的文件,而-F能檢測還未被創建出來的文件。
這個是程序往文件追加的時候能夠顯示的追蹤,
比如我們echo >>追加內容就會在-f參數跟蹤后顯示出來,一般輸入追蹤log日志的比較多,-F可能協同辦公用的比較多,因為大家都要保存
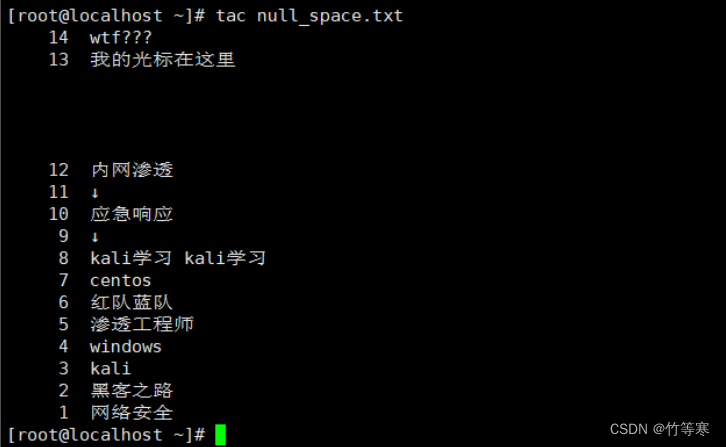
tac
文件內容倒過來讀取
wc
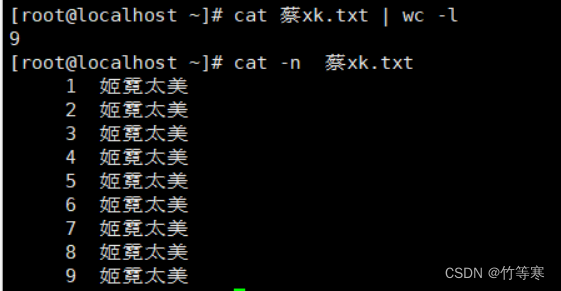
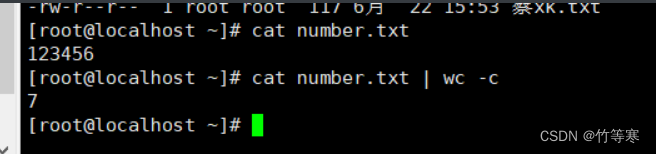
統計行數與字符數
-l 統計行數-c 統計字符數
統計行數
統計字符
du
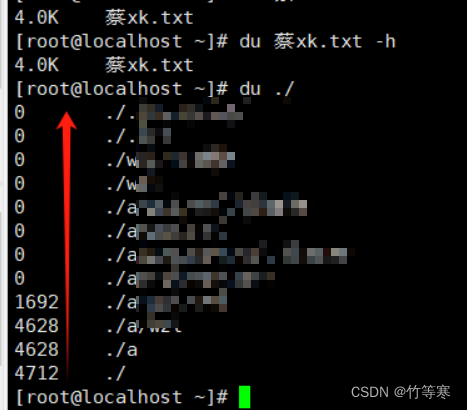
主要是用于計算文件夾大小的,du同時能夠計算文件大小只是一個理所應當的功能
使用du命令一般都會將兩個參數同時使用-sh,除非你要遞歸統計當前目錄下所有文件夾分別占多大空間的時候就需要去掉s參數
下面對兩個參數進行講解
顯示指定文件夾(默認當前pwd目錄)或指定文件名大小
會對文件夾進行遞歸統計,比如從最低下的./文件夾所有文件大小的一個統計,慢慢往上./a 在往上./a/wzl文件夾一直遞歸
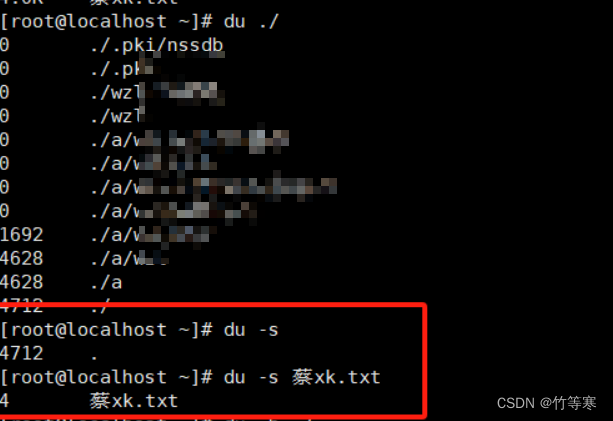
-s
只統計你給定的目錄或文件夾的總大小,不會給你將所在目錄所有文件夾都遞歸統計一遍出來
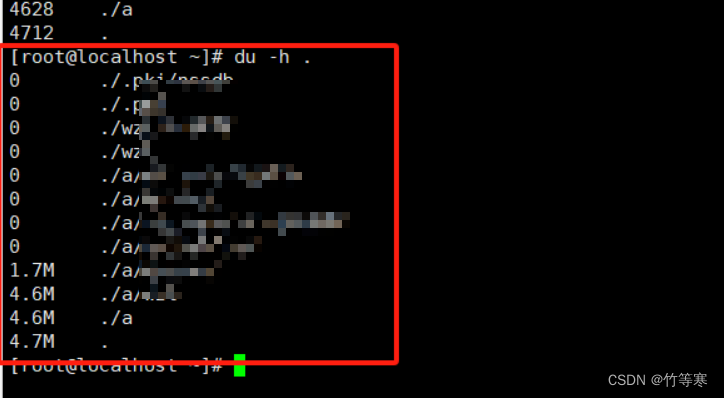
-h
統計出來的單位以m為單位
find
-tyep f 表示搜索的類型是文本類型
-type d 表示搜索的類型是文件夾類型
-type l 表示搜索的類型是軟連接類型-iname 忽略文件名的大小寫
-a:and 必須滿足兩個條件才顯示
-o:or 只要滿足一個條件就顯示UNIX/Linux文件系統每個文件都有三種時間戳:
訪問時間(-atime/天,-amin/分鐘):用戶最近一次訪問時間。
修改時間(-mtime/天,-mmin/分鐘):文件最后一次修改時間
變化時間(-ctime/天,-cmin/分鐘):文件數據元(例如權限等)最后一次修改時間。-size 文件大小單元b —— 塊(512字節)c —— 字節w —— 字(2字節)k —— 千字節M —— 兆字節G —— 吉字節其中比如 +10k 表示大于10kb的文件 -就是小于 不加符號就是等于常用查找格式:find (搜索目錄位置) [-type f 搜索的類型] (-name) '文件名,可以進行模糊匹配,使用*進行模糊匹配'
例子:
-
查找 /home/ 下所有以.txt或.pdf結尾的文件
find /home/ -name "*.txt" -o -name "*.pdf" -
查找 /home/ 下所有以a開頭和以.txt結尾的文件
find /home/ -name "*.txt" -a -name "a*" -
搜索最近七天內被訪問過的所有文件
find /etc/ -type f -atime -7 -
搜索大于10KB的文件
find /etc/ -type f -size +10k #小于的話就把+換成-
-exec
我們find命令查找出來文件無非是將其批量操作,所以find命令提供了這些可對你查找出來的文件進行批量操作
find / -name '*.log' -exec rm -f {} \;
切記切記:\; 在尾部一定要加,固定語法,下面的-ok也是一樣的哈
-ok
這個同-exec的作用,但是他在你使用rm 的時候會自動帶上 rm -i參數,而-exec在你使用rm的時候不會帶上-i參數,所以交互的時候可能會欠佳,除非你確定了你匹配的文件是要刪除的了。
find / -name '*.log' -ok rm -f {} \; #這里相當于后面執行的rm -f -i 也就是說刪除的時候會帶上提示
當然exec和ok參數不僅僅能夠執行rm參數而已,還可以執行其他命令,這里只是做一個提醒,rm的時候使用ok參數會帶上 -i參數,當然其他指令可能也會有類似的操作。
-mtime
根據給出的時間進行查找,mtime是根據天數為單位進行查找
-
-mtime +1
表示find一天前的文件 1天前到今天都查 ,2 就是一天前到今天的文件都查
-
-mtime -1
表示find一天內的文件,2就是兩天內的,這很明顯了
-
-mtime 1
表示查找前1天的,僅僅是那天的文件,2就是前2天的那一天的文件
grep
后面三劍客會經常用到grep
-n 匹配出來的內容顯示行號
-i 關鍵字匹配忽略大小寫 # grep -i '關鍵字' 文件名
-o 顯示出你篩選出來的結果,而不是grep出來的那一行數據。(這里就是為了契合正則表達式的參數)
-v 將你篩選的結果取反 (這里就是和正則表達式使用的時候取反篩選內容搭配的)
-
grep ‘關鍵字’ 文件1 文件2 文件3 文件4 …
-
grep -n ‘關鍵字’ 文件名 #表示查找出你要匹配的內容然后-n表示顯示找出來的內容在你文件中的行號
-
grep -n ‘關鍵字’ ./* #查看當前文件夾中所有文件是否包含你要查找的關鍵字,但是記住grep無法查看文件夾的,只能去匹配文本文件
xargs -i(神器)
理解:xargs -i 能夠將你傳輸過來的內容一個一個的進行傳入到{}中,然后你直接使用{}進一步的執行你所要執行的命令。(用于批量處理十分方便)
#該命令能夠將你過濾出來的內容進行進一步的處理#比如:
#該指令就是通過find指令找文件后,將查找到的文件 傳到xargs的{}內,-i 參數要加,然后執行命令grep過濾{}傳過來的文件中是否含有內容hacker,有的話直接打印出來
[root@localhost ~]# find ./ -type f -name '*.*' | xargs -i grep -n 'hacker' {}
27: new char!! hello hacker#該指令就是在grep 中多了一個-l參數,就是過濾出含有hacker的文件后,不是打印那一行內容,而是打印包含該內容的文件。
[root@localhost ~]# find ./ -type f -name '*.*' | xargs -i grep -l 'hacker' {}
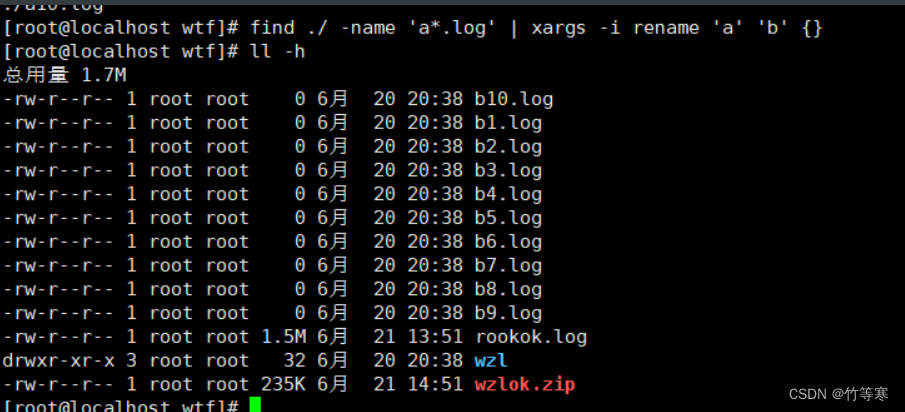
./null_space.txt再舉個例子:批量重命名文件
我要將所有的a*.log重命名為b*.log

find ./ -name 'a*.log' #測試是否匹配成功找到對應文件find ./ -name 'a*.log' | xargs -i rename 'a' 'b' {}
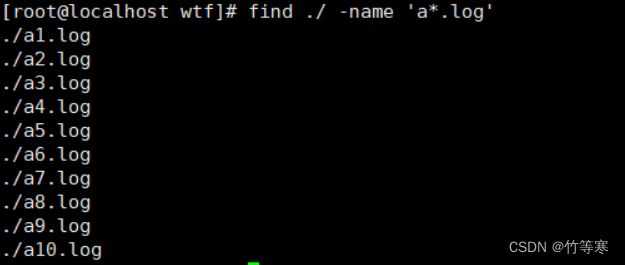
成功批量重命名
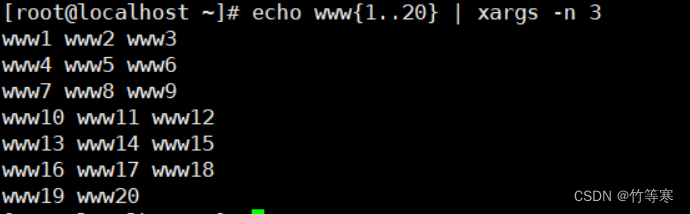
其他參數
-n #表示限制每一行輸出兩個echo www{1..20} | xargs -n 3
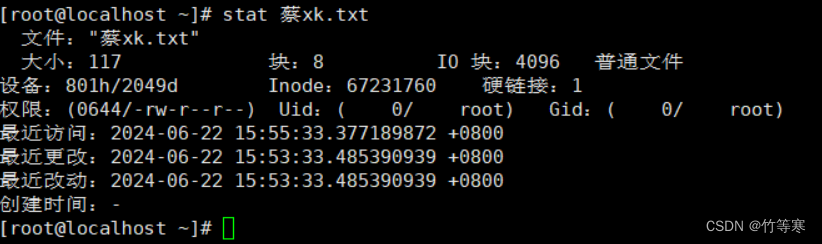
stat
可以列出文件和文件夾屬性
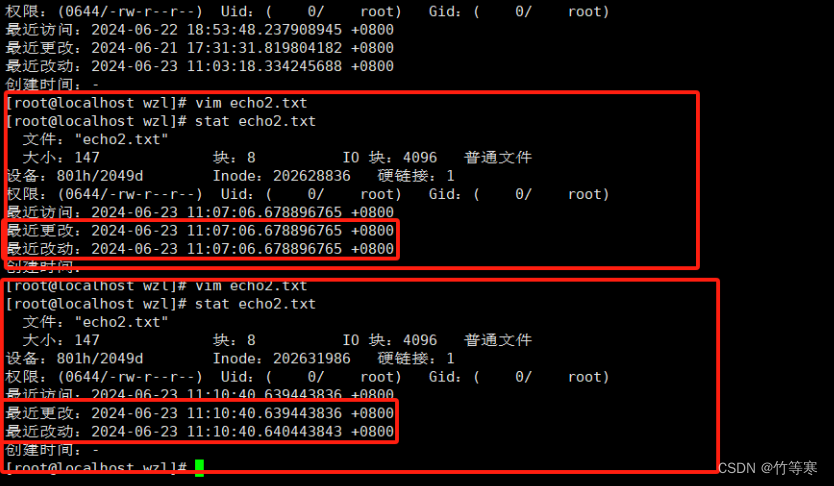
提前提醒:modify文件內容變化會導致文件屬性也改變,因為你修改了文件內容,文件屬性各方面都會變!!!!
最近訪問==access:最后一次讀取的時間,讀取命令可以是->cat / more / less / grep 等等最近改動==change:最后一次修改文件屬性的時間,這些命令可以是->chmod / chown / mv 等等最近更改==modify:最后一次內容修改的時間。(只要文件內容被修改了就會更改時間)
注意:modify文件內容變化會導致文件屬性也改變,因為你修改了文件內容,文件屬性各方面都會變!!!!
注意下面的順序是最近范文、最近更改、最近改動,我上面解釋的順序是訪問、改動、更改,因為中文和英文版的順序不一樣
下面是文件內容修改后導致文件屬性也發生變化的例子,可以看到每次修改文件內容都會導致最近改動時間也發生變化。
history
history的工作流程
首先history命令:顯示的是你當前的歷史指令,這些都是臨時存儲cat /home/用戶名/.bash_history
這個文件記錄的是你這個用戶做的一些歷史指令,如果不做任何動作,你的history歷史指令是不會直接存儲進去.bash_history的exit退出登錄后,你的臨時存儲才會將歷史指令存儲進去(追加進去)
其他指令
history -c #清空歷史指令history -W #寫入.bash_history文件中,這里-w是將你的臨時存儲的歷史指令將其文件內容覆蓋掉
tips:
作為一個黑客,那么想要做到滴水不漏,可能他做的就是清空歷史指令動作history -c #清空臨時存儲的歷史指令,這樣登錄出去后我們之前的歷史指令就不會存儲進去了
history -w 或者 > .bash_history #同時還可以對其進行情況文件信息,這樣做到萬無一失,更加惡心的就是不斷的對.bash_history文件進行內容覆蓋,讓其歷史指令的難以數據恢回來。(> .bash_history就是寫入一個空字符串進去,那不就是清空了。)總之你要抹除痕跡,那就是先清空當前臨時存儲的歷史指令,這樣才不會在你登錄出去的時候又記錄進去.bash_history文件中。vim
write寫入
:w #表示保存不退出:w /opt/temp.txt #表示你該文件另存為/opt目錄下的temp.txt文件中
注意:
:x! #表示強制寫入且退出,知道即可,平時使用w q !三個已經夠用了
隨機記錄一些vim中很容易忘記的命令
命令行模式搜索字符
命令
直接 / 或者 : -> /
下面采用 :/字符


取消搜索的高亮
:noh
替換內容
單行替換(替換一次)
單行替換需要你把光標定位到對應的行進行替換才行,而且替換一次而已。
如果進入:命令之前光標所在的行沒有你要替換的字符就無法替換,根據你當前光標的行內容進行替換的。
:s/原字符/替換字符/
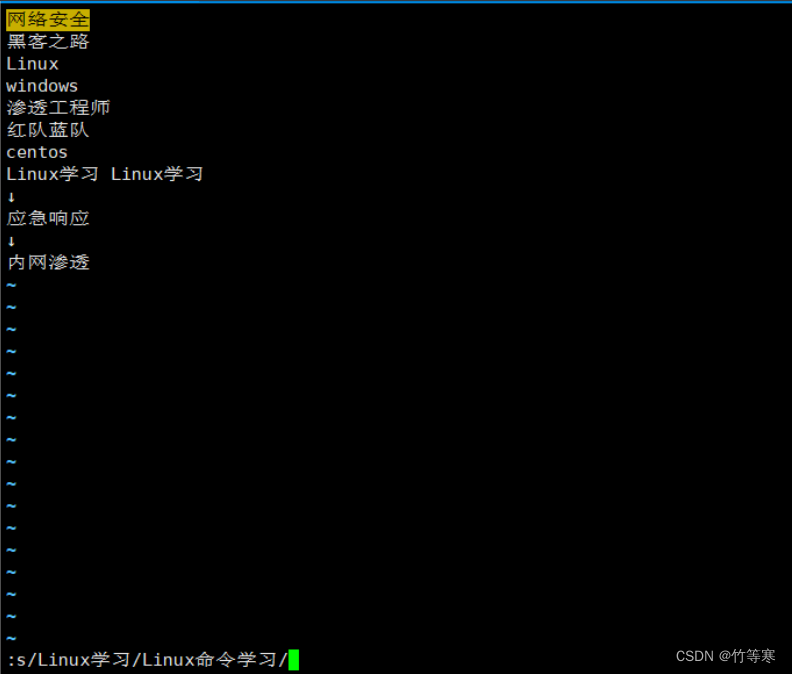
這個是光標不在那一行導致沒有匹配成功的例子

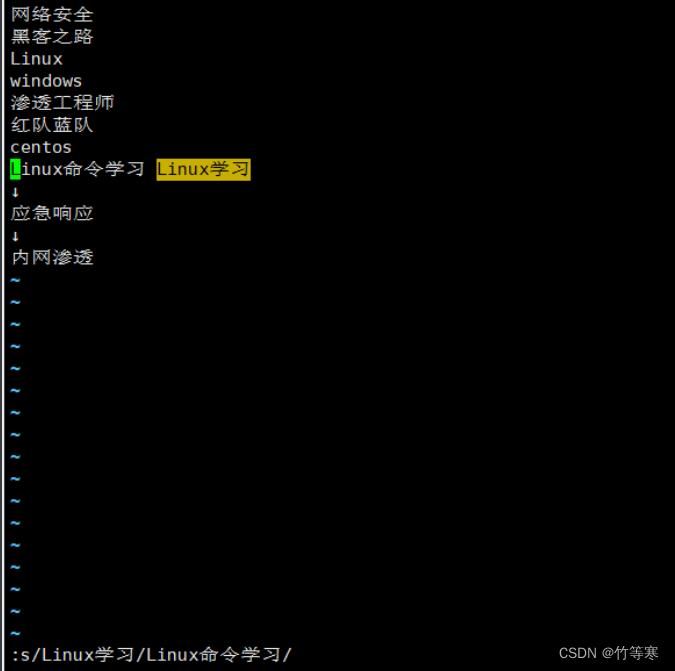
單行替換(替換所有)
只需要在最后多加一個g即可
:s/原字符/替換字符/g
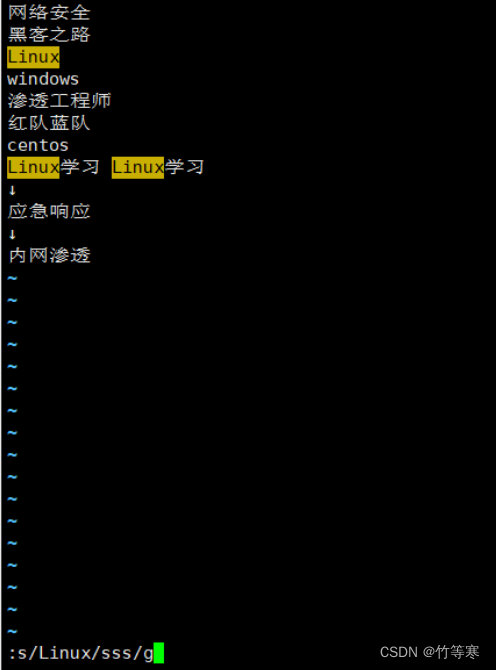
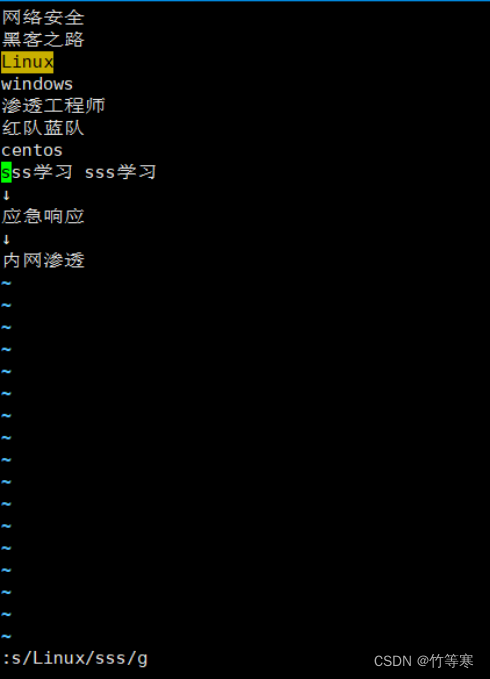
全文匹配替換(每行替換一次)
逐行查看,從第一行開始匹配到第一個就替換,接著到第二行中匹配到第一個就替換,接著第三行以此類推
:%s/原字符/替換字符/
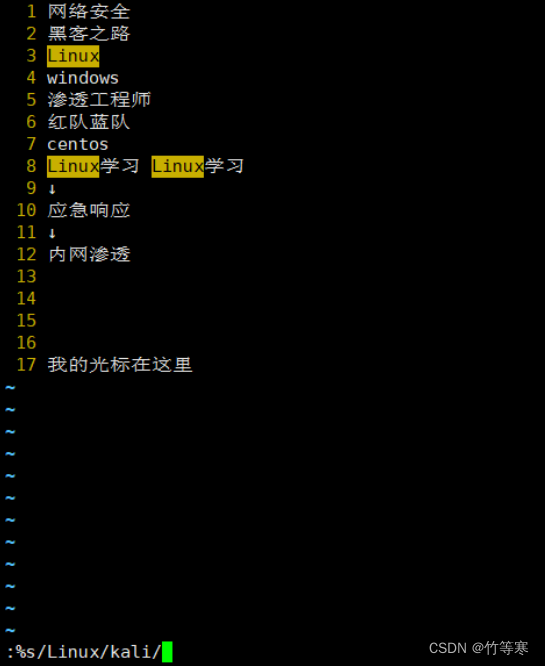
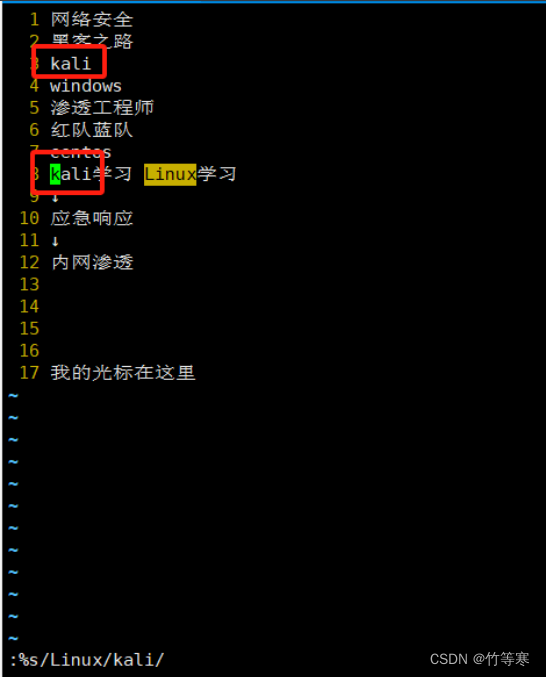
全文替換(全部搜索符合的都替換)
%s/原字符/替換字符/g
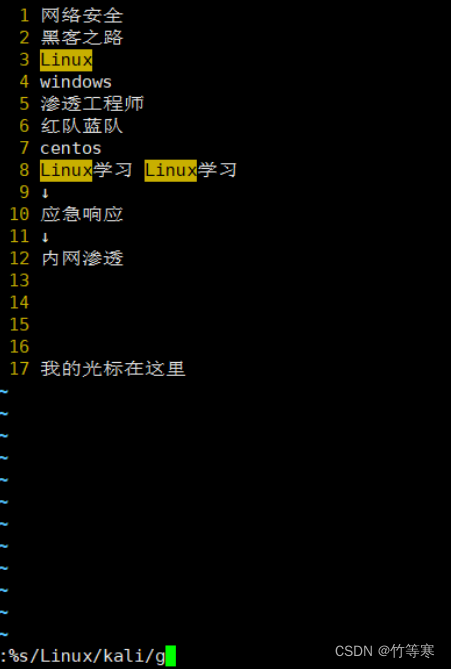
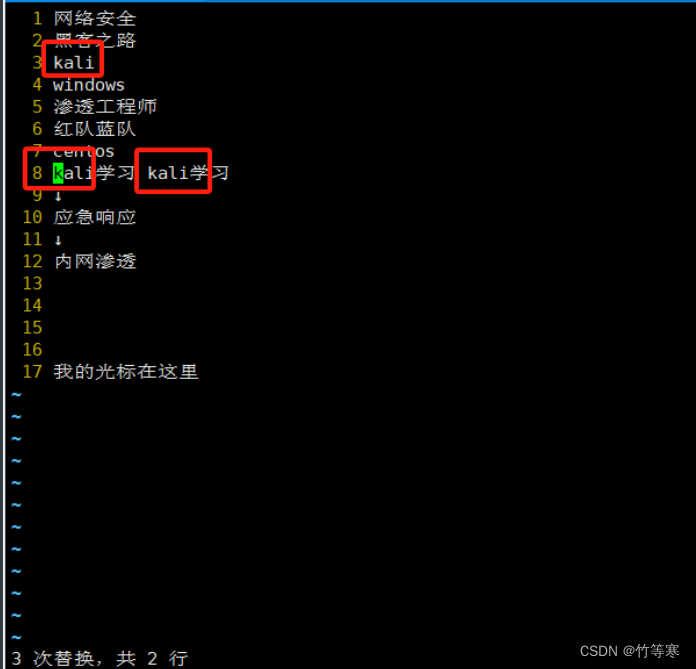
可視化快(進行列操作)
該功能是為了能夠讓你選擇多個地方同步操作,一般是用于操作同一列上的數據,然后能夠同時修改這一列的數據第一步:選擇你光標位置第二步:ctrl + v進入可視化快比如我想同時操作這一列的12數字改為34
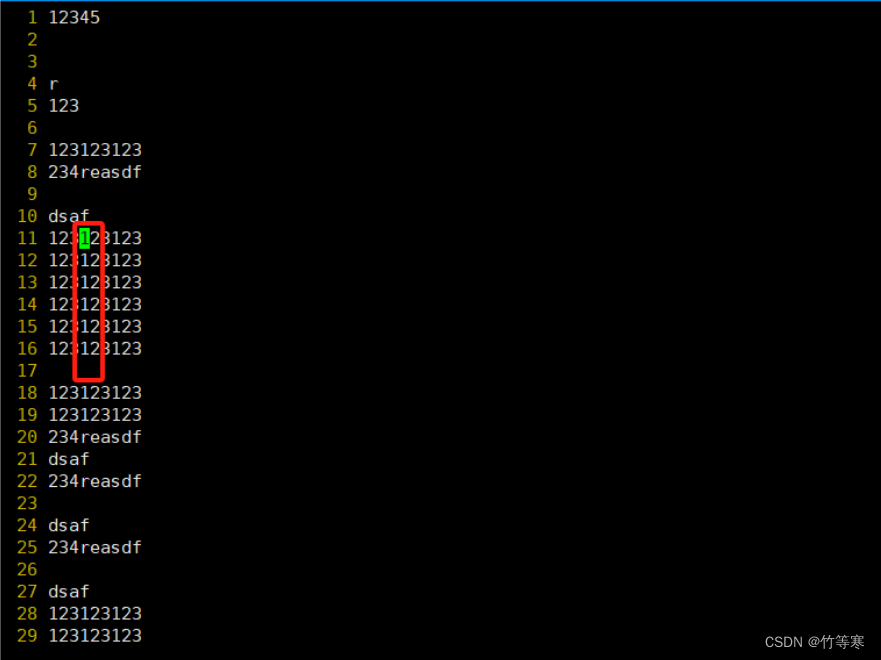
步驟都是一樣的,進入可視化快后直接移動光標即可,光標移動的地方都是被標記選中
這樣就是選中了你的這一列
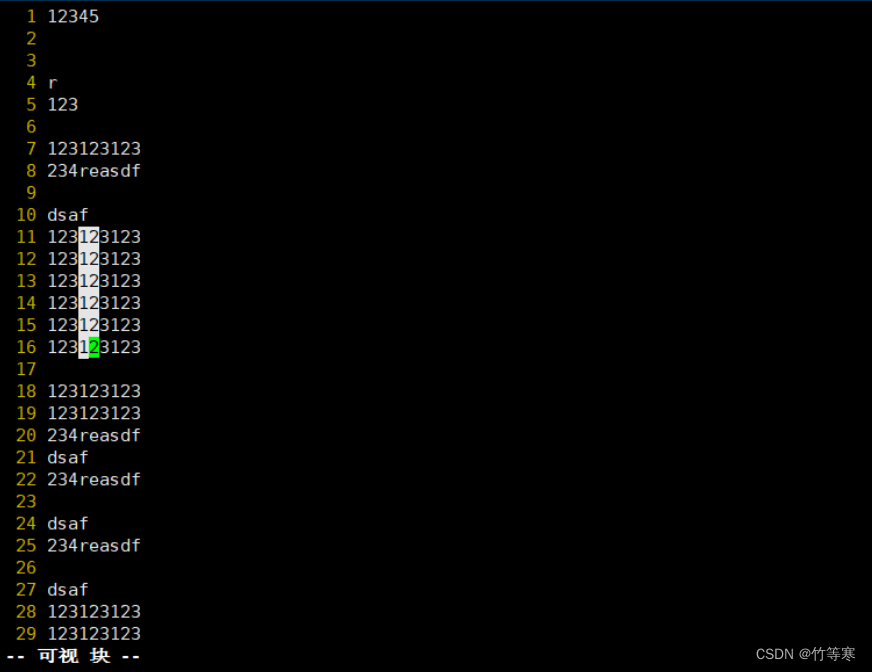
然后選好后只能進行一個命令行下的操作
按下 d 就是刪除按下 y 就是復制
如果你要進入編輯模式
選好后按下大寫的I編輯好后按兩下esc鍵退出,就能夠自動幫你批量修改好你剛剛可視化選中的內容了。這里進入編輯是只能看到編輯了一行,退出后才能看到你選中的都被修改了
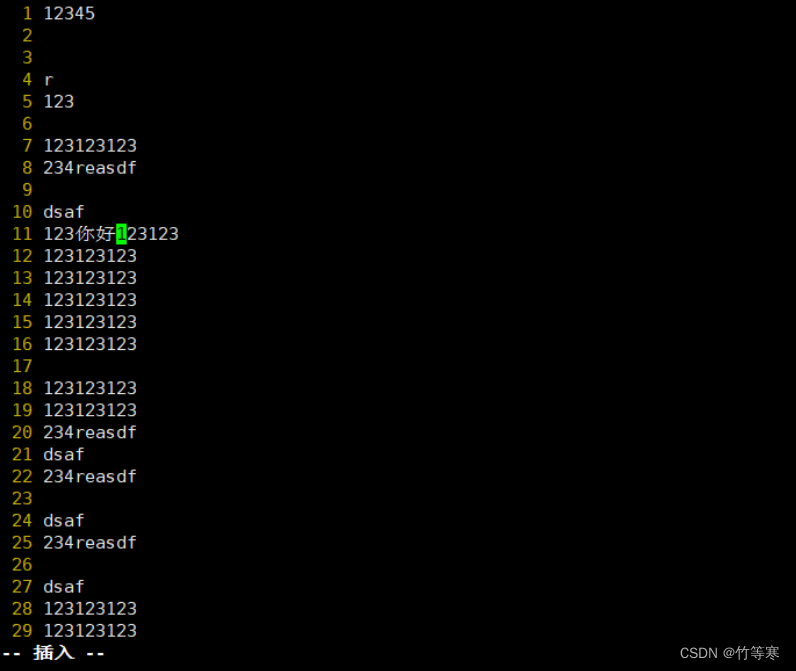
然后按兩下esc直接就幫你批量修改好了
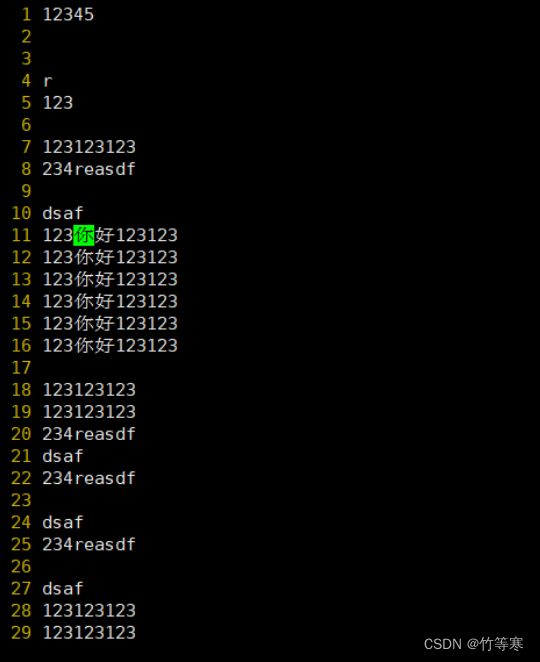
粘貼模式
因為有時候如果不進入粘貼模式進行粘貼你復制好的內容的話,可能會出現一些錯誤。
如果是中英文的一些字符的話直接粘貼就還好,如果是你要粘貼一些配置信息,帶格式的那種,最好是先進入粘貼模式再粘貼進去。
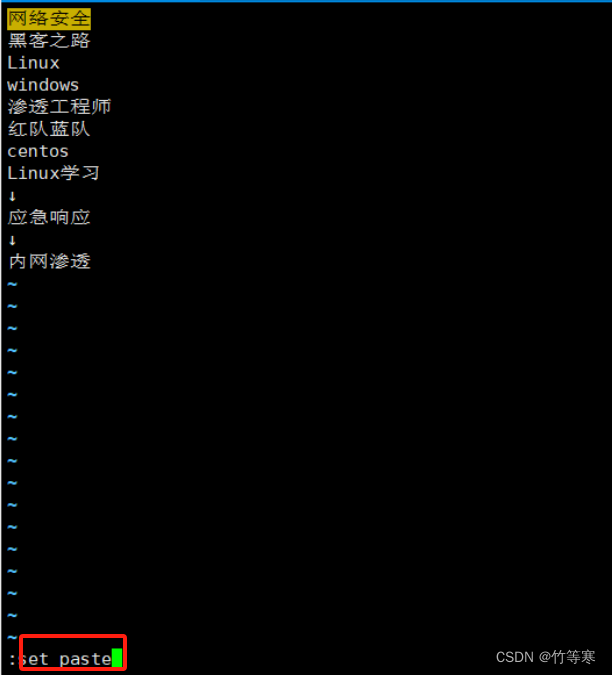
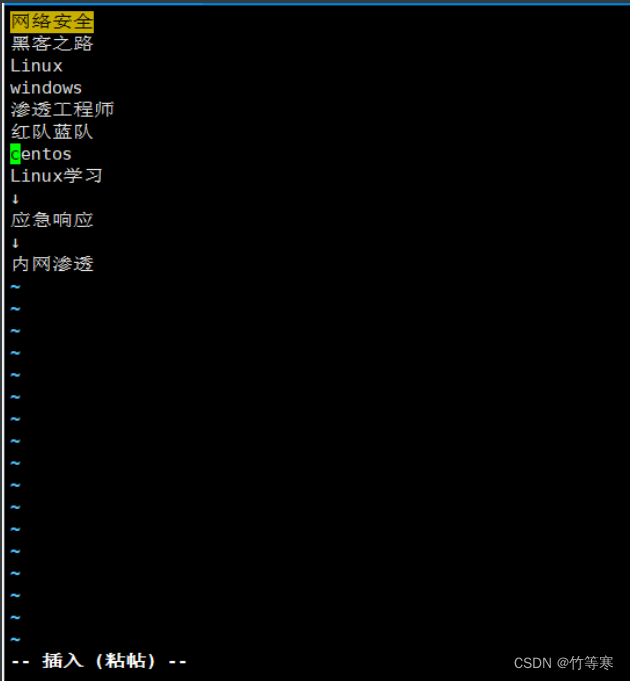
命令
:set paste
然后當你進入寫模式的時候就會顯示為paste模式
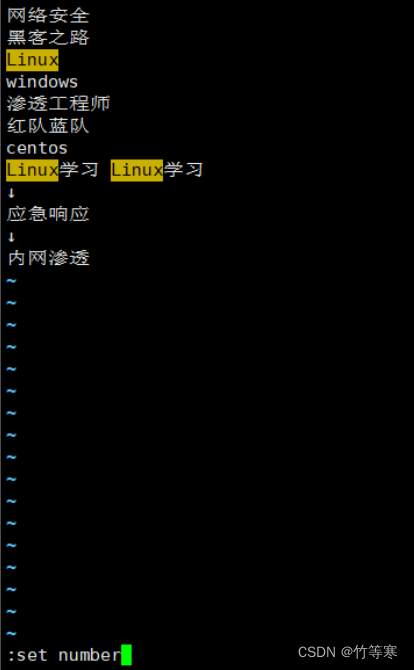
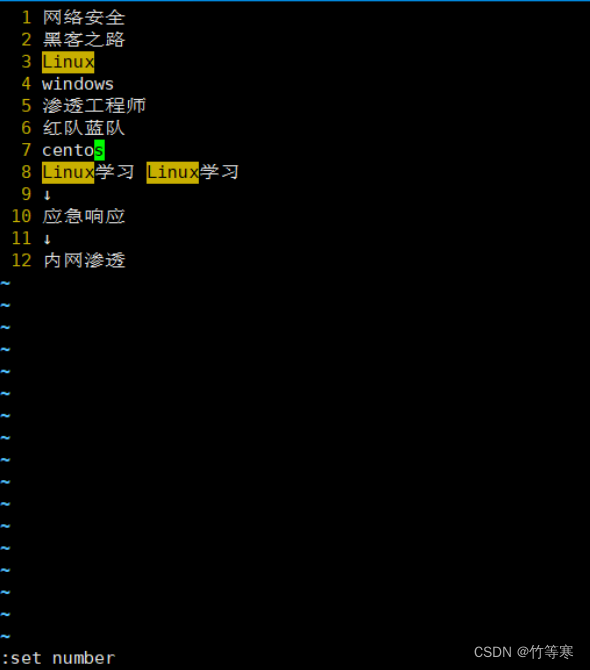
設置和取消行號
進入vim后看不到行號很煩惱?
不妨試試
:set nu
或者
:set number
取消行號就是
set nonu
或者
set nonumber
復制、粘貼
都是在命令模式下進行的
復制
yy # 復制一行
復制多行
復制那幾行取決于你光標所在位置(包含光標行)
3yy == 復制你光標所在的地方三行
粘貼
命令行中比如你yy復制好了一行,那么命令行中直接使用p就能夠粘貼了
刪除和剪切
刪除光標所在字符
x
單行操作
dd 表示剪切,如果不粘貼那就是刪除了
D 刪除光標所位置的當前行的往后內容,注意不是刪除當前行所有,而是光標所在位置的往后的內容,并且在當前行
多行操作
先按下你要刪除或者剪切的行數,都是在你光標當前位置進行操作的。3dd 表示剪切光標所在位置的三行內容3D 表示刪除光標所在位置的往后的內容的三行內容,注意光標前面的內容不進行刪除,是從光標往后的內容開始刪除
當前光標刪除到末尾
光標位置定好后,直接命令模式中輸入:dG
這樣即可從光標位置直接刪除后面所有文本內容。
撤銷
u
恢復
ctrl + r
回到整個文檔開頭段
gg
回到整個文檔末尾段
G
回到行首
0
回到行尾
$
定位到第幾行
第一種方法:
進入命令模式后,冒號+行數即可跳轉: 20 == 跳到20行
第二種方法:(比較裝逼的方法)
先按你要跳轉的行號 , 然后按下G,這里要大寫,所以我一般都是shift + g或者先按你要跳轉的行號 , 然后按下gg也能實現同樣的跳轉裝逼是因為你沒有顯示任何東西就直接給你跳轉到你要的行號了。
命令行模式光標移動
hjkl
h = ←
j = ↓
k = ↑
l = →
.swp文件
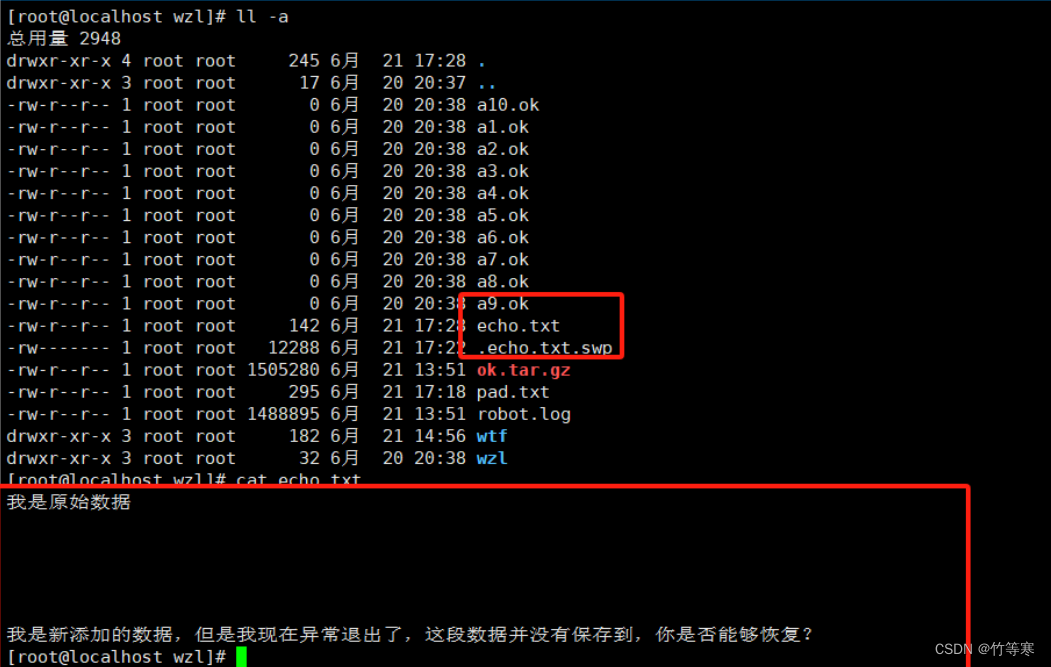
該文件的出現是因為你編輯文件的過程中異常退出或者多人同時編輯了該文件的時候就會發生。
那么我們一般vim這個.swp文件的時候,我們就會進入一個選項模式,直接根據需求恢復還是刪掉即可。一般來說如果要恢復的話會有。
下面演示一個我復制回話后,編輯一個文件不保存退出的情況,我回到原會話中就會發現出現該文件
現在存在echo.txt文件如下
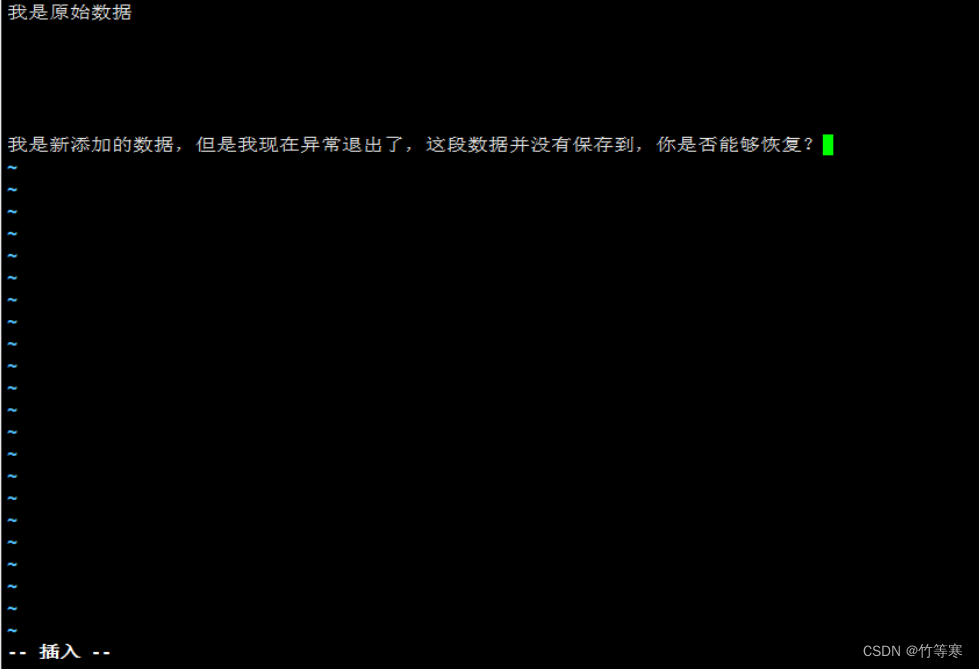
如果你不要這個剛剛編輯添加好的內容的話直接刪掉.swp文件即可
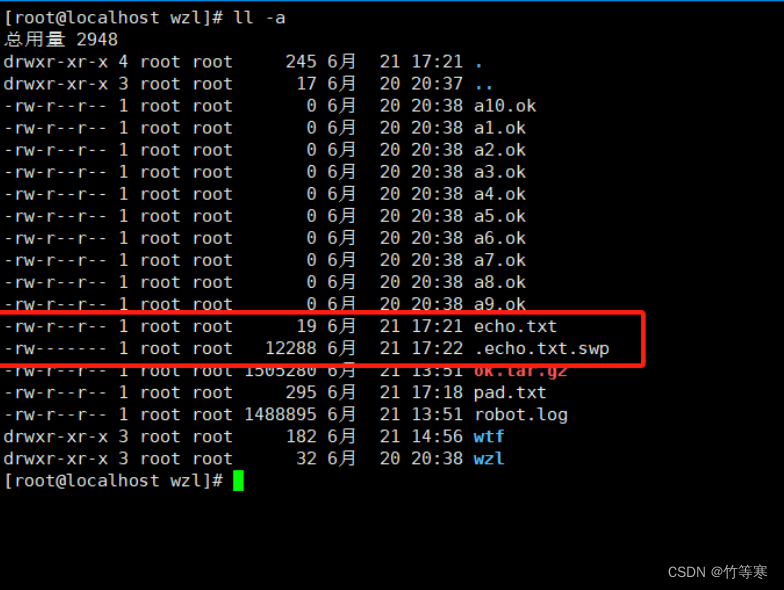
但是我們真的是不小心斷開連接了,需要對文件內容進行恢復,我們vim echo.txt就會出現提示。
我們就直接vim echo.txt吧,不要vim那個.swp,那文件是給內存看的,不是給我們看的。

只讀模式o(不管大小寫的哈)直接編輯e恢復r刪除交換.swp文件d退出q中止a
我們現在需要恢復之前編輯的內容就直接r
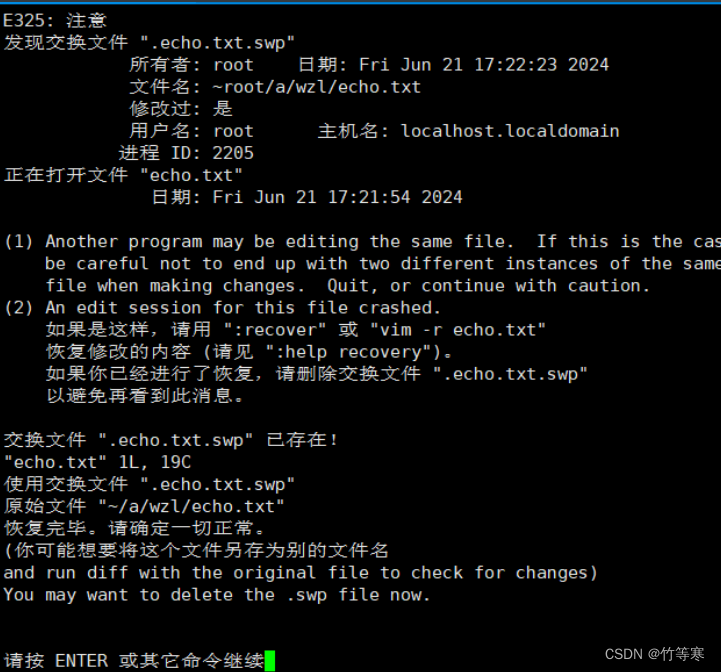
然后回車就能夠看到恢復成功了
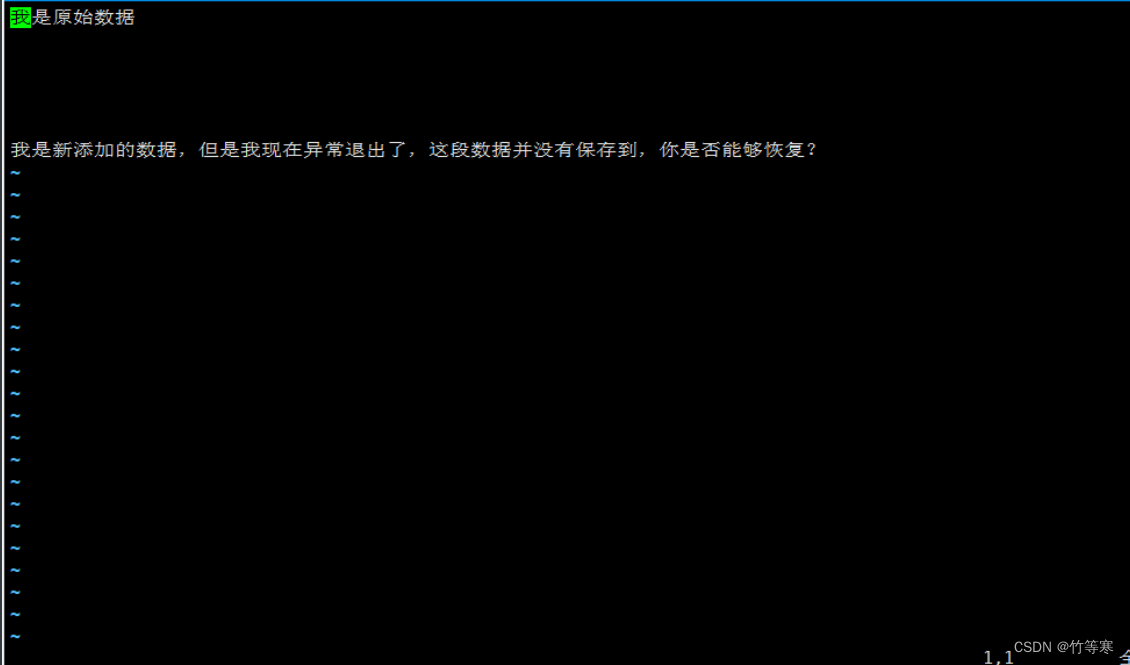
現在來看的話我們已經恢復成功了,只是我們的交換文件還存在,還是要手動給他刪掉
如果不刪掉的話再次vim echo.txt的時候還是回出現提示,因為那個文件不會自動刪除
這里有兩種方法,
-
一種是你手動rm刪除.swp文件
-
第二種是你再次vim echo.txt的時候,提供了命令d讓你去刪除
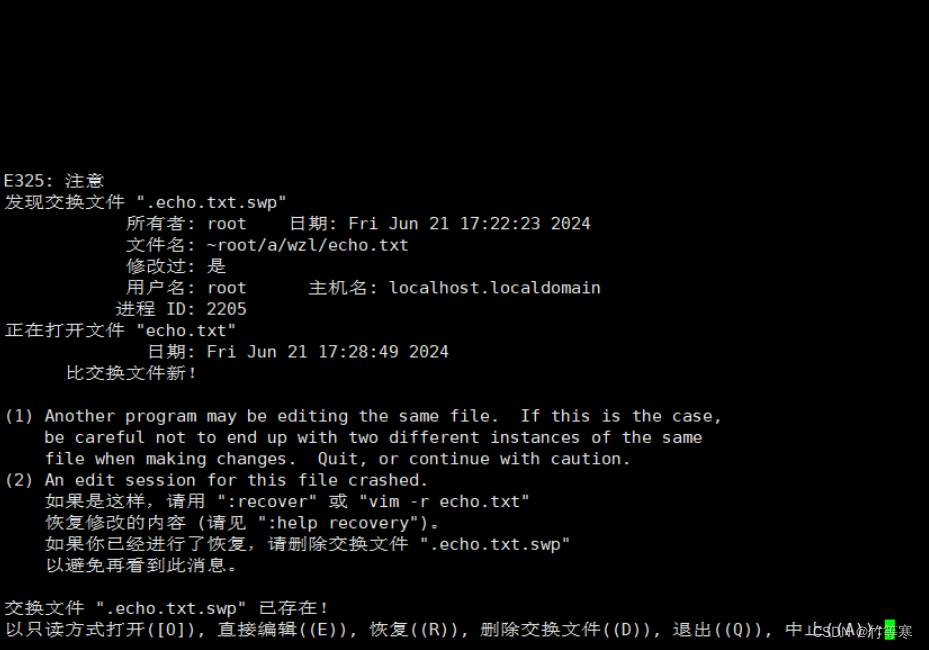
d刪除后,發現已經刪掉了該文件,注意,前提是你已經恢復好了二次進入后再d命令刪掉,否則你想要恢復但是還沒恢復好久d掉了那就神也救不了你。

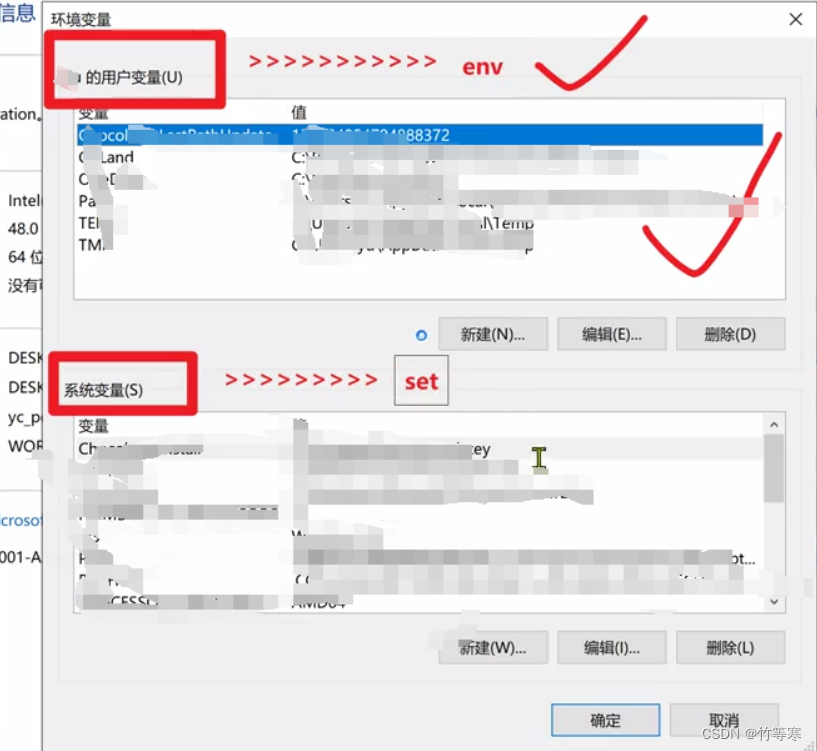
環境變量(個性化自定義設置)
env 和 set
env #相當于windows中的用戶變量set #相當于windows中的系統變量
PS1
PS1變量可用參數
\d 日期,格式為weekdat month date
\H 完整的主機名稱
\h 僅取主機的第一個名字
\t 顯示時間為24小時格式,如:HH:MM:SS
\T 顯示時間為12小時格式
\A 顯示時間為24小時格式:HH:MM
\u 當前用戶的賬號名稱
\v bash版本信息
\w 完整的工作目錄名稱。家目錄會以~代替
\W 利用basename取得工作目錄名稱,所以只會列出最后一個目錄
# 下達的第幾個命令
$ 提示字符,如果是root,提示符為:#,普通用戶則為:$
! 命令行動態統計歷史命令次數
臨時生效
[root@localhost a]# set | grep PS1
PS1='[\u@\h \W]\$ 'PS1是控制命令變量提示符
\u顯示用戶名
\h顯示主機名
\W顯示根目錄
\w顯示pwd當前目錄
\t顯示當前時間由于它是一個變量,所以我們可以直接在命令行中直接對其進行修改
PS1='[\u@\h \w \t]\$ '這種方法只是臨時生效,當你重啟后系統就會重新加載環境變量,然后你設置的東西就會失效。
永久生效
直接修改配置文件
/etc/profile #這個是針對全局的,系統的,那么想要修改他肯定只有root用戶才可以修改。用戶的home/.bash_profile #這個是針對某個用戶生效的。我們對這兩個文件進行修改即可永久生效了那么比如說我們要修改用戶下的.bash_profile
[wzl01@localhost ~]$ ls -a
. .. .bash_history .bash_logout .bash_profile .bashrc .viminfo
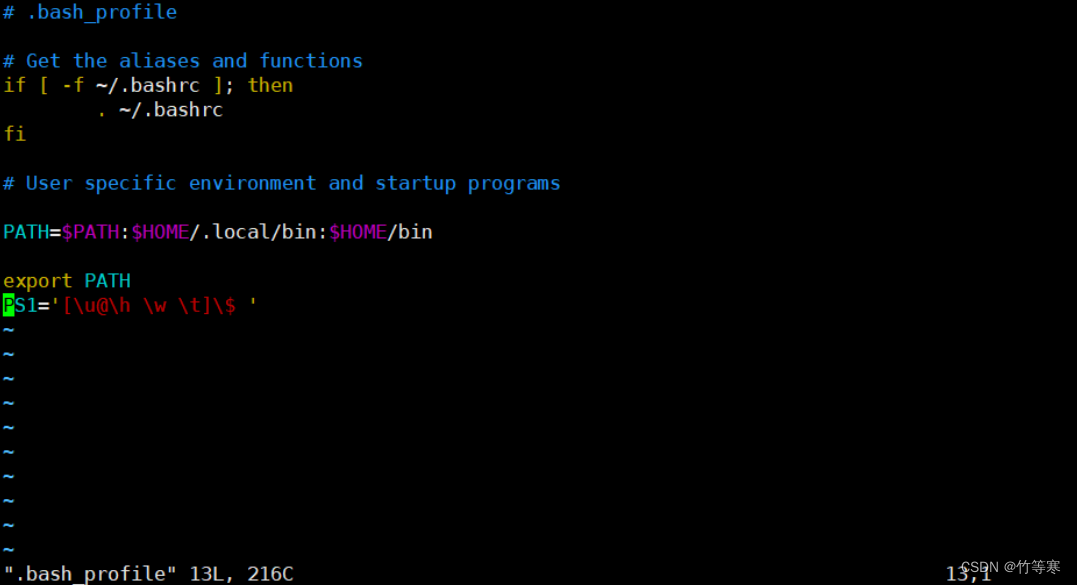
[wzl01@localhost ~]$ cat .bash_profile
# .bash_profile# Get the aliases and functions
if [ -f ~/.bashrc ]; then. ~/.bashrc
fi# User specific environment and startup programsPATH=$PATH:$HOME/.local/bin:$HOME/binexport PATH
那么我們現在修改一下這個配置文件,在最后面加上PS1='[\u@\h \w \t]\$ '即可
然后使用指令
source .bash_profile #讓配置文件生效即可

用戶bash損壞修復
當出現用戶的bash變成了:
-bash-4.2$
這種情況下,用戶輸入pwd,大概率會回顯tmp目錄,因為你家沒有了,那你.bash_profile也沒了這種情況十有八九是該用戶的家目錄沒有了,被掏家了
假設該用戶叫做admin,
那么我們只需要將模版文件復制過來即可。
cp -r /etc/skel/ /home/admin/
# -r參數 遞歸復制目錄及其子目錄內的所有內容
也就是說我們要同時創建/home/admin才能將其admin恢復回來,那么我們cp -r其實就是順便幫忙把目錄也創建出來了。
用戶管理篇章
useradd
useradd 用戶名 #添加用戶-u #設置用戶的id
比如我設置1234為新用戶的id
useradd -u 1234 用戶名 -s #指定用戶登錄進來后所使用的shell解釋器,
解釋:這里的解釋器就是你在cat /etc/passwd出來后,每一行最后那個,比如能夠登錄進來的就是 /bin/bash,不能登陸進來的解釋器就是/sbin/nologin
比如我設置一個不能登陸的用戶wtf(已實驗過確實不能登陸進去)
ueradd -s /sbin/nologin wtf -g #注意該參數是設置用戶的主組
useradd -g 組名/組id 用戶名 #在創建用戶的使用就把該用戶添加到某個組里面作為該用戶的主組-G #注意該參數是設置有用戶的附加組,因為用戶在不設置組的時候默認用自己的用戶名創建一個組然后作為自己的主組
useradd -G 組名/組id 用戶名

細節:useradd創建的用戶的id號默認是從1000開始的,然后id號遞增
passwd
passwd 用戶名 #回車后就能修改該用戶名的密碼了
超級用戶的UID是0
-
查看該用戶是否可登錄狀態
cat /etc/passwd后, 如果對應用戶后面是sbin/nologin表示無法登錄。 如果是bin/bash的話就是可以使用ssh進行登錄的。
用戶可以屬于多個組,默認主組是你創建該用戶的時候相應的用該用戶名創建一個組,然后這就是你的主組。
用戶可以加入多個組。
usermod
usermod -L user //L表示lock , 鎖定,禁用帳號,帳號無法登錄 /etc/shadow第二欄為!開頭 user表示你查到的用戶名
usermod -g 組名/組id 用戶名 //-g小寫g表示改的時候用戶的主組
usermod -G 組名/組id 用戶名 //-G大寫的G表示改的是用戶的附屬組,注意這里是直接修改你的附屬組,也就是說你原本的附屬組會被覆蓋
usermod -a -G 組名/組id 用戶名 //這里多了個-a表示追加附屬組,因為你直接用-G就會覆蓋以前的附屬組,所以-a可以追加
userdel
userdel user //刪除user用戶
userdel -r user // 將刪除user用戶,并且將/home目錄下的user目錄一并刪除,有些人入侵完成刪除自己用戶的時候,可能忘記了加-r,那么在/home目錄下是有它用戶名的文件夾的,也就是存有相關信息。
id
id 用戶名 / 直接id命令
發現:whoami 指令可以等于 id -un ,以后獲取用戶名又多了一條指令
查詢用戶的id和用戶組-u #查詢uid
-g #查詢組id
-un #顯示用戶名 == whoami
-gn #顯示組名[root@localhost ~]# id
uid=0(root) gid=0(root) 組=0(root)
[root@localhost ~]# id -u wzl01
1000
[root@localhost ~]# id -un wzl01
wzl01
[root@localhost ~]# id -un
root
[root@localhost ~]# id -gn
root
[root@localhost ~]# id -gn wzl01
wzl666
[root@localhost ~]# id -g
0
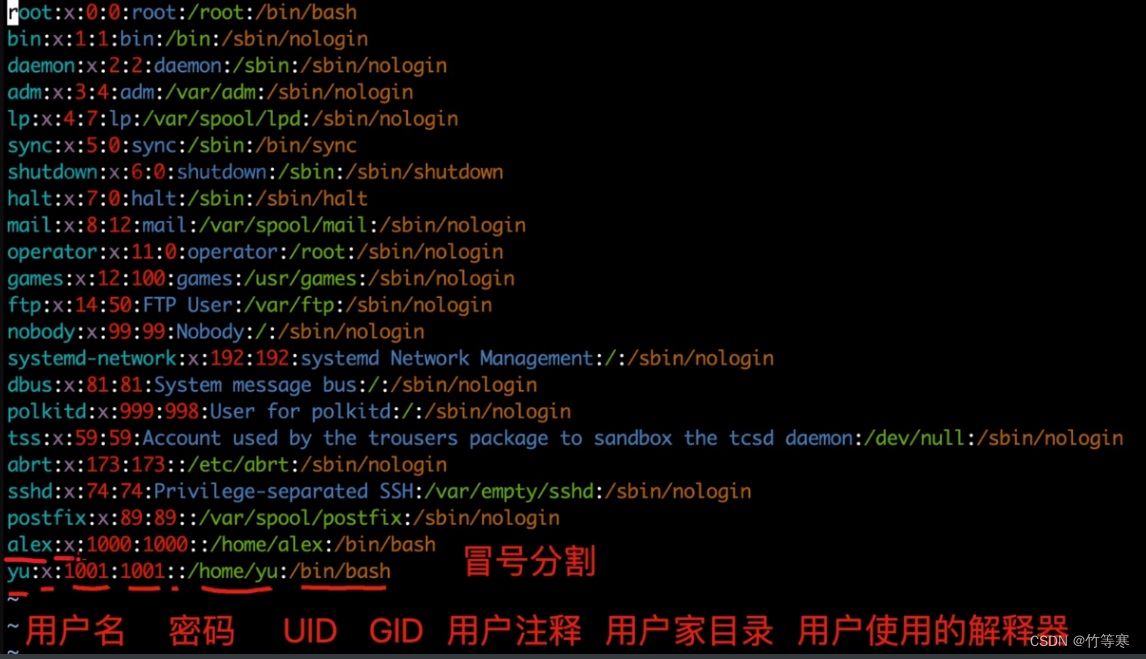
解釋/etc/passwd文件內容:
密碼都是x加密,不會直接顯示出來。
用戶相關的配置文件
useradd命令執行后,以下文件都會發生變化:
/etc/passwd 用戶信息
/etc/shadow 用戶密碼信息
/etc/group 用戶組信息
/etc/gshadow 用戶組密碼信息(一般公司中用戶和組數量很大的時候就會用到這個組密碼)
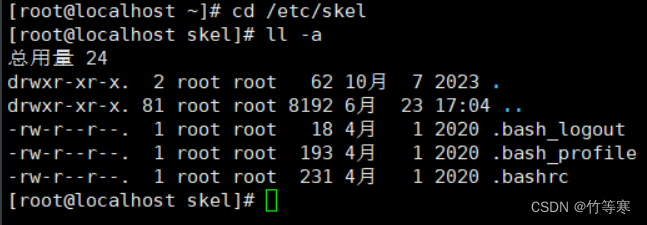
/etc/skel
skel是skeleton的縮寫,表示骨骼框架的意思,那么就是說當你useradd執行創建一個用戶的時候,一般都會有一個home目錄,那么home目錄系統幫你創建完成后,里面的一些比如.bash_history之類的文件模板就是從這個文件拷貝過去的。
下面是/etc/skel目錄下的模板文件:
組管理
groupadd
groupadd 組名 #添加組 這個組默認是從組的id1000開始遞增-g
groupadd -g 1111 組名 #設置組id,注意這里是在添加的過程中直接指定組id,當然我們添加完成后也是可以通過groupmod -g來進行id修改的
groupmod
-g
groupmod -g 6666 src #這樣就是將組名為src的id改成6666-n修改組名
groupmod -n des src #這樣就是把src組名改成des名
groupdel
groupdel 組名 #刪除組
whoami/who/w/last/lastlog
whoami #打印當前用戶名
[root@localhost ~]# whoami
rootwho #顯示已登錄的用戶信息
[root@localhost ~]# who
root pts/0 2024-06-23 10:28 (192.168.29.1)w #顯示系統登錄用戶信息,以及負載信息
[root@localhost ~]# w16:39:01 up 6:10, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 192.168.29.1 10:28 5.00s 0.66s 0.00s wlast #顯示近期登錄的終端有哪些
last -5 #表示顯示最近登錄的5條信息
[root@localhost ~]# last
wtf pts/1 192.168.29.1 Sun Jun 23 15:40 - 15:40 (00:00)
wtf pts/1 192.168.29.1 Sun Jun 23 15:39 - 15:39 (00:00)
wzl01 pts/1 192.168.29.1 Sun Jun 23 15:21 - 15:39 (00:17)
....
....
....
reboot system boot 3.10.0-1127.el7. Sun Oct 8 00:03 - 11:54 (29+11:51)
wtmp begins Sun Oct 8 00:03:00 2023lastlog #顯示關于所有用戶的登錄記錄
[root@localhost ~]# lastlog
用戶名 端口 來自 最后登陸時間
root pts/0 日 6月 23 15:20:40 +0800 2024
bin **從未登錄過**
wzl01 pts/1 192.168.29.1 日 6月 23 15:21:28 +0800 2024
wtf pts/1 192.168.29.1 日 6月 23 15:40:00 +0800 2024sudo
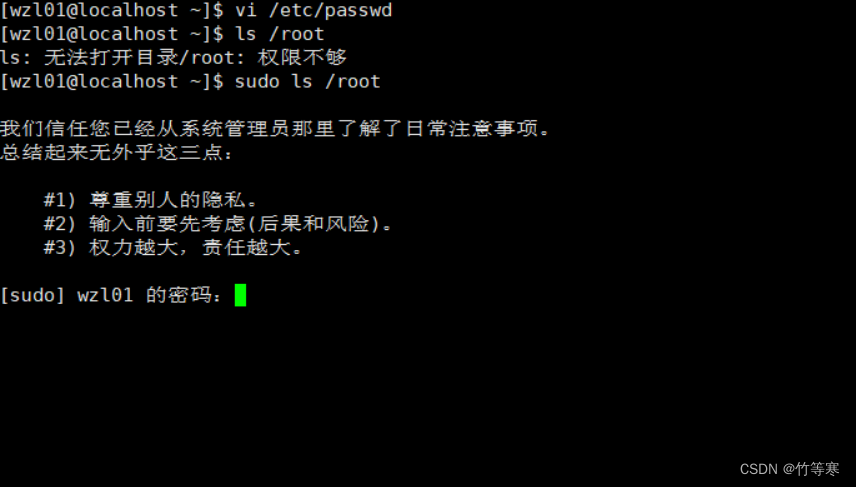
舉一個例子即可:普通用戶想要執行管理員權限的指令需要用sudo,
但是我們不想要輸入root的密碼,因為他不是隨便給人的,
那么我們就可以請求他去執行一下:visudo,這個命令
然后去到大概100行左右,加上我的用戶名,然后給權限,這樣我sudo,輸入自己賬號密碼就行了,不用輸入root的密碼!就可以直接用了

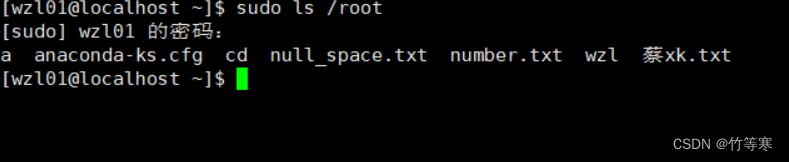
這里我輸入自己的密碼就可以查看root下的目錄了
文件權限篇章
如何查看文件屬性
ll
stat 文件名
權限了解
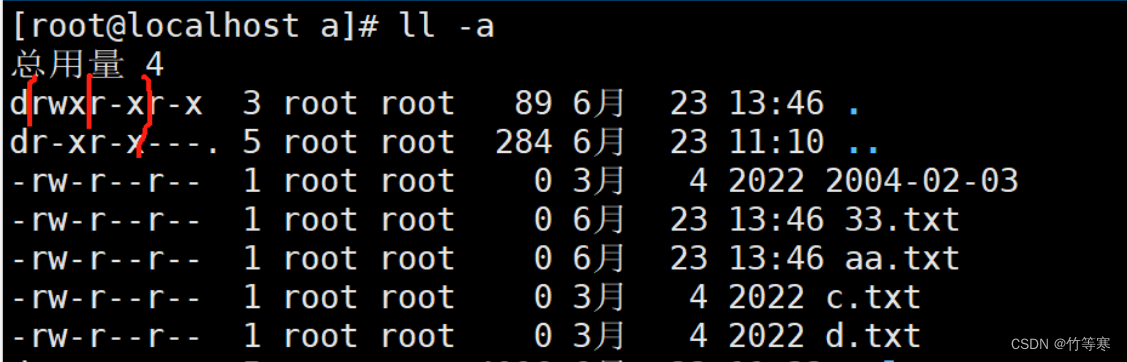
文件屬性 d - l 屬主user 屬組group 屬其他other
三個常見的文件類型:
d 文件夾
- 普通文本
l 軟鏈接
記住屬誰的英文后面修改權限的時候就很容易了。
all=a user=u group=g other=o
還有一個all,別忘了。
d rwx r-x r-x 3 root root
第一個d表示這個是一個目錄,如果是-那就表示是一個文本文件rwx
這里表示是屬主的權限,比如這里后面顯示root root那就是代表屬主和屬組都是root。
那么rwx就是root這個屬組擁有讀寫和執行權限r-x
這里表示屬組權限,那么我們剛剛說到屬組還是root,
那么我們的root組中,對該文件有讀和執行權限,沒有寫權限r-x
最后一個是other,其他人的權限,只有讀和執行,同樣沒有寫權限
疑問和細節:為什么屬主我自己登上去還要搞能不能執行能不能讀取這些??我本人不應該默認讀寫執行都可以嗎?
答:不是的,有時候需要自己去劃分權限,比如該文件就是為了防止被亂改,那我就需要禁用寫權限。
chmod
了解了上面的權限分類后,使用chmod就得心應手了
chmod是修改這個文件所屬于那個屬主和屬組是否有權限
例子:drwxr-xr-x 3 root root 89 6月 23 13:46 .
chmod a+r file #表示對file文件進行權限修改為all所有用戶和組都可以進行+r,即加了一個讀權限chmod u-r file #表示對文件修改,讓屬主沒有r讀權限,-表示去掉,所以-r就是去掉讀權限
注意u這里是rootchmod g+w file #表示修改該文件權限,讓屬組有對文件進行寫權限操作,+w就是加一個w寫權限
住惡意g這里是root組,主要看文件屬于的屬主和屬組是誰,u和g都是針對這兩個進行修改的哈。chmod o-w file #這里表示對其他用戶和組進行-掉w寫的權限,讓其他的用戶和不屬于該用戶組的都沒有寫權限。還可以進行多個權限加減,只需要用逗號分隔即可
chmod u+r,u+w,o-x file 還可以直接等于
chmod u=rwx file如果要給某個權限位設置為空,即設置為---,可以給空字符
chmod o='' file
疑問:root root 屬主和屬組我們怎么修改呢?
答:我們還有另外一個指令chown,很明顯的名字了change改變own文件擁有者,即文件是屬于誰的和哪個組的,這個是chown命令修改的,而chmod只是針對于文件擁有者進行權限修改還有對非文件擁有者進行權限修改,而不是修改文件在水戶口本下的。
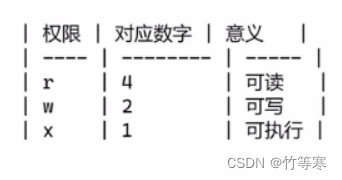
文件權限的數字表示法
比如
chmod 777 file #就是將u g o 三個的讀寫執行權限都給了,因為 4 + 2 + 1 = 7
chown
chown 用戶名 file
注意:要修改目錄內容,必須要對目錄有x可執行權限,這樣才能cd進去,并且touch或者其他修改目錄內容的命令。
chgrp
該操作只能root操作,因為涉及到安全問題,不可能你所屬于a組,你就想把你這個文件改到b組吧?
chgrp 組名 file
ln
創建軟連接
不帶-s參數的是硬鏈接
-s參數是創建軟鏈接
ln -s 源文件 鏈接存放路徑/鏈接存放的路徑+名字 Linux會自動區分,因為沒找到目錄名字的時候會當作鏈接名字命名該鏈接
比如ln -s /etc/okok.sh /usr/bin/ok.sh
suid
chmod u+s file
suid:因為有一些執行的指令需要普通用戶臨時申請一下root權限去執行一下指令,比如ping或者find等等,這些本身都是只有root才能去執行的指令,那我們就可以打上suid標志,然后普通用戶也能夠執行該指令和文件了。
-rwx------ file
當我執行chmod 4000 file 或者 chmod u+s file的時候就會變成下面權限
-rws------ file-rw------- file
當我執行chmod 4000 file 或者 chmod u+s file的時候就會變成下面權限
-rwS------ file總結;
suid權限八進制表示是4000,那么同理可以和其他權限組合起來用,比如4777
當文件本身對屬主有x執行權限的時候,添加suid權限的時候x會變成s
當文件本身對屬性沒有x執行權限的時候,添加suid權限的時候就會變成S
sgid
chmod g+s dir
---rws--- nb nb dir這是一個目錄
這里g屬組中有s,表示sgid,然后屬主和屬組是nb
意思是我們該目錄在root進入后,在此目錄進行創建文件的時候,就會以nb屬組創建出來的文件而不是root也就是說目錄下誰進來創建文件,那么這些文件和文件夾都會繼承為nb屬組,而不是他們所屬的組
好處:能夠限制在該目錄中所有文件都屬于nb組
sbit
chmod o+t dir
粘滯位
------rwt nb nb dir這是一個目錄
t表示sbit,
如果一個目錄chmod 777 dir后,那么無論誰進來該目錄創建文件后,不同的用戶都能夠對其對方的文件進行刪除或者甚至可能可以修改(不確定是否有的Linux可以修改),這就很危險了,因為可以刪除對方文件。
那么在該目錄下,就應該需要加一個粘滯位chmod o+t dir ,比如tmp目錄就有t粘滯位。那么假設真的有這么一個目錄share 擁有777權限,甚至還在根目錄下,沒有在某個目錄中包含,所以他無論誰進來創建的文件,那么其他人都可以對他創建的文件進行刪除,就需要加一個粘滯位了。
當然我們想要在根目錄下創建這么一個目錄是不太可能的,除非你是root用戶才可以。所以這也就是為什么粘滯位已經快無人問津了,基本用戶都是在自己家目錄下進行文件的創建和修改,家目錄肯定是屬于自己的而不是777權限誰都可以進來,所以安全性就有了。
系統服務篇章
理解systemctl如何管理服務的,如果看不懂先看后面的服務解釋。
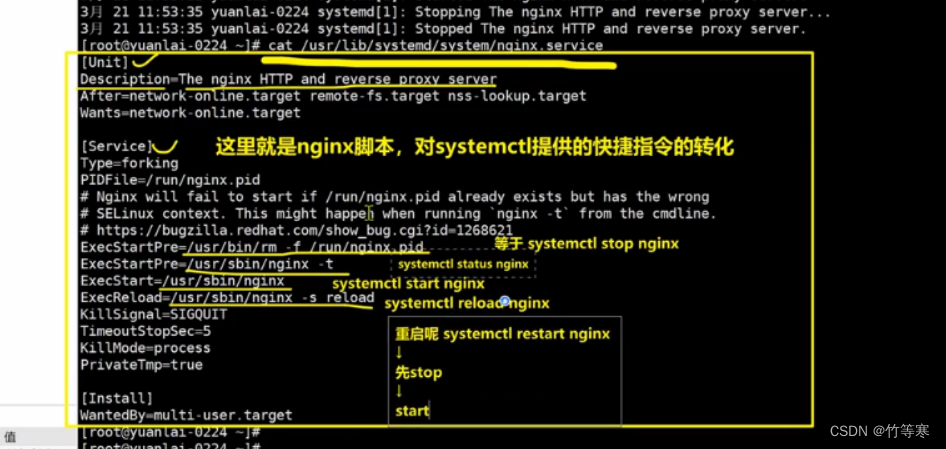
如果我們平時使用的軟件其實都是需要去到對應的腳本目錄下進行運行起來,
當我們不用該軟件的時候,需要停下來的時候,其實是使用kill 他的pid號來進行停止,
但是我們的systemctl管理服務的這個指令就完成了我們的任務,
比如nginx下就有一個nginx.service文件,里面寫著就是我們怎么去關閉軟件,
本質上都是找到pid然后進行kill,開啟的時候同理,都是找到對應的文件腳本啟動。也就是說我們systemctl start nginx就能夠完成我們上面那一步去到腳本目錄下執行快多了,
同理停下程序只需要:systemctl stop nginx即可停掉。
ssh服務
systemctl start sshd #啟動ssh服務
systemctl stop sshd #關閉ssh服務
systemctl restart sshd #重啟ssh服務
systemctl status sshd #查看ssh服務狀態
network服務
systemctl start network #啟動網絡功能
systemctl stop network #關閉網絡功能
systemctl restart network #重啟網絡功能systemctl status network #查看網絡服務狀態
配置網絡服務
Centos系統
進入配置網卡目錄
cd /etc/sysconfig/network-scripts/
找到對應的網卡文件
[root@localhost network-scripts]# ls | grep ens
ifcfg-ens33#注意ifcfg-ens33是你ifconfig查看網卡信息的時候,你那個使用的網卡名字叫做ens33那就是編輯這個。文件名和ifconfig顯示網卡信息是對應的,所以你可以通過這個方式來查看。
編輯該文件
vim ifcfg-ens33#設置的是dhcp模式 ,重要的信息我加上注釋解釋一下
TYPE="Ethernet" #網卡類型,以太網
BOOTPROTO="dhcp" # boot啟動協議proto是dhcp,這里可以改成static靜態
DEFROUTE="yes"
NAME="ens33" #這個就是你ifconfig顯示出來的網卡名字
DEVICE="ens33"
ONBOOT="yes"#設置的是static模式
TYPE="Ethernet"
BOOTPROTO="static"
IPADDR="xxx.xxx.xxx.xxx"
GATEWAY="xxx.xxx.xxx.xxx"
NETMASK="255.255.255.0" #通常掩碼都是這個,根據你實際情況修改
DNS1='' #根據你要的對你說服務器,自己設置即可
DNS2=''
DEFROUTE="yes"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
重啟網絡服務
systemctl restart network
服務管理
注意區分:
在CentOS 7及以后版本中,雖然 systemctl 是主要的服務管理工具,但為了兼容性,仍然保留了 service 命令,并且 service 命令在這些版本中通常會調用 systemctl 來執行相應的操作。因此,即使在systemd系統中,也可以使用 service 命令進行基本的服務管理。
systemctl
在centos6和7的系統版本中,為了方便理解,可以暫時理解為:systemctl = service + chkconfig
對這些服務,進行管理
- 啟動
- 停止
- 重啟
- 重新加載
- 開機自啟(持久化)
- 禁止開機自啟
- 查詢是否持久化(是否開機自啟)
centos7,用這個命令,同時對服務進行啟停管理,以及開機自啟
systemctl start/stop/restart/reload/enable/disable/is-enabled 服務名使用語法:systemctl [OPTIONS...] COMMAND [UNIT...] 參數:unit 是要配置的服務名稱。command 選項字如下: unit(單元,服務,指的是如sshd,network,nginx,這樣的服務名(unit))這幾個指令,就替代了舊版的service 服務名 start/stop/等等
start:啟動指定的 unit。
stop:關閉指定的 unit。
restart:重啟指定 unit。
reload:重載指定 unit。
status:查看指定 unit 當前運行狀態。
is-enabled :查看是否設置了開機自啟。替代了舊版的chkconfig 服務名 on/off
enable:系統開機時自動啟動指定 unit,前提是配置文件中有相關配置。 設置開機自啟
disable:開機時不自動運行指定 unit。 禁用開機自啟參數:unit 是要配置的服務名稱。
systemctl
-
查看所有服務
systemctl list-unit-files #這是查看所有服務 systemctl list-unit-files | grep enabled #意思是過濾開機自啟的服務 -
列出系統中,所有的內置服務,名字,和狀態
systemctl list-units --type service --all 運行中 掛掉的 都幫你全列出來,一般服務名字都是以 .service結尾 -
只列出,active運行中的服務
systemctl list-units --type service可以利用該命令,搜索出,系統內置服務名的完整名稱,才可以去管理
其實也可以:systemctl list-unit-files | grep ssh,這樣也可以過濾出來。一樣的,只是下面的會告訴你哪些是runing哪些是dead了。
下面加上 –all 是包括未激活的單元。
systemctl list-units --type service --all |grep ssh ↓↓↓sshd-keygen.service loaded inactive dead OpenSSH Server Key Generationsshd.service loaded active running OpenSSH server daemonsystemctl is-enabled sshd.service #然后你才可以根據以上命令查找出來的完整服務將其開機自啟關掉。 ↓↓↓ enabled

systemctl list-unit-file 和 systemctl list-units 的區別
-
systemctl list-unit-files
用途: 列出所有單元文件及其啟用狀態。
輸出: 顯示系統上所有的單元文件,包括服務(service)、掛載點(mount)、設備(device)等的文件名及其啟用狀態(如 enabled, disabled, static 等)。
-
systemctl list-units
用途: 列出當前加載的單元及其狀態。
輸出: 顯示當前加載的單元,包括正在運行的、失敗的和其他狀態的單元。默認情況下,只顯示活動(active)的單元。
總結
systemctl list-units | grep 服務名 #這個就能夠完成你查找服務名的操作了,grep能夠進行模糊查找
service
service命令用于對系統服務進行管理,比如啟動(start)、停止(stop)、重啟(restart)、重新加載配置(reload)、查看狀態(status)等。
# service mysqld 指令 #打印指定服務mysqld的命令行使用幫助。# service mysqld start #啟動mysqld# service mysqld stop #停止mysqld# service mysqld restart #重啟mysqld (先停止,再運行 ,進程會斷開,id會變化)# service mysqld reload # 當你修改了mysqld程序的配置文件,需要重新加載該配置文件,而不重啟
chkconfig
備注
在centos7中,service啟停服務的命令和 chkconfig命令,都被統一整合為了systemctl
并且你依然可以使用舊的命令,系統會自動的轉變為systemctl去執行。
做了向下兼容的操作,新命令,兼容舊命令。
說人話:哪個能用用哪個,他會有以下提示給你的
注:該輸出結果只顯示 SysV 服務,并不包含
原生 systemd 服務。SysV 配置數據
可能被原生 systemd 配置覆蓋。要列出 systemd 服務,請執行 ‘systemctl list-unit-files’。
查看在具體 target 啟用的服務請執行
‘systemctl list-dependencies [target]’。
chkconfig: 指定服務是否開機啟動
sshd 遠程連接服務
network 提供網絡的服務設置開機自啟提供了一個維護/etc/rc[0~6] d 文件夾的命令行工具,它減輕了系統直接管理這些文件夾中的符號連接的負擔。chkconfig主要包括5個原始功能:為系統管理增加新的服務、為系統管理移除服務、列出單簽服務的啟動信息、改變服務的啟動信息和檢查特殊服務的啟動狀態。當單獨運行chkconfig命令而不加任何參數時,他將顯示服務的使用信息。[root@localhost www]# chkconfig --list #查看系統程序列表[root@localhost www]# chkconfig httpd on #將httpd加入開機啟動[root@localhost www]# chkconfig httpd off #關閉httpd開機啟動
scp文件傳輸服務
scp語法
無論你使用scp服務進行傳過去還是拉取文件,都需要輸入對方的密碼
#把文件發給root@192.168.1.1,回車后需要輸入他的密碼
scp /etc/passwd root@192.168.1.1:/opt #傳輸文件夾到對方目錄中 -r 參數
scp -r /var/log root@192.168.1.1:/opt#把文件拉取到自己本地目錄中
scp root@192.168.1.1:/etc/passwd /opt#把文件夾拉取到本地目錄中 -r 參數
scp -r root@192.168.1.1:/var/log /opt/
ntp時間服務
同步時間
如果沒有ntpdate那就安裝一下,yum install ntpdate -y
1.找到時間服務器地址,強制更新即可
[root@yuanlai-0224 ~]# ntpdate -u ntp.aliyun.com[root@yuanlai-0224 ~]# ntpdate -u ntp.aliyun.com
21 Mar 12:31:11 ntpdate[19892]: step time server 203.107.6.88 offset 106194278.720730 sec[root@yuanlai-0224 ~]# timedatectl statusLocal time: 一 2022-03-21 12:31:32 CSTUniversal time: 一 2022-03-21 04:31:32 UTCRTC time: 四 2018-11-08 02:06:54Time zone: Asia/Shanghai (CST, +0800)NTP enabled: no
NTP synchronized: noRTC in local TZ: noDST active: n/a
更改時區
修改時區
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
查看系統中有哪些時區文件
ls /usr/share/zoneinfo/
ll /usr/share/zoneinfo/Asia/Shanghai
定時任務
基本設置
crontab提供最小分鐘級別的任務,想完成秒級別的任務,得通過編程語言自己寫。
每個用戶對應的定時任務文件存儲在:
/var/spool/cron/root的定時任務文件名在該目錄下就叫root
/var/spool/cron/root
-
列出當前用戶有哪些計劃任務
crontab -l -
編輯當前用戶的計劃任務
crontab -e -
刪除當前用戶的計劃任務
crontab -r
定時任務難點就是理解他設置時間的格式,但是無他,唯手熟爾!
分 時 日 月 周
每分或者每時或者。。。那就用 */ ,
每30分 */30 * * * *
每15天 * * */15 * *時間段,那就用-,
每小時15-20分 * 15-20 * * *
每個月的1-5日 * * 1-5 * *指定某幾天某幾分鐘,那就用,逗號
每個月的1,6,20天 * * 1,6,20 * *
每天的1,5,19小時 * 1,5,19 * * *
無他,唯手熟爾,再看完下面你就理解定時任務怎么寫了!
學習定時任務,最簡單的,就是直接通過案例,掌握其語法
* * * * *
分 時 日 月 周 命令的絕對路徑從左 向右,依次去寫,不要跳級問題1:每月1、10、22 日的4:45 重啟network 服務
45 4 1,10,22 * * /usr/bin/systemctl restart network問題2:每周六、周日的下午1:10 重啟network 服務
10 13 * * 6,7 /usr/bin/systemctl restart network問題3:每天18:00 至23:00 之間每隔30 分鐘重啟network 服務
*/30 18-23 * * * /usr/bin/systemctl restart network問題4:每隔兩天的上午8點到11點的第3和第15分鐘執行一次重啟
* * * * *
分 時 日 月 周 命令的絕對路徑
3,15 8-11 */2 * * 問題5 :每天凌晨整點重啟nginx服務。
* * * * *
分 時 日 月 周 命令的絕對路徑
0 0 * * * /usr/bin/systemctl restart nginx問題6:每周4的凌晨2點15分執行命令
15 2 * * 4 問題7:工作日的工作時間內的每小時整點執行腳本。
工作日 1-5
工時 9-18
* * * * *
分 時 日 月 周 命令的絕對路徑
0 9-18 * * 1-5如果定時任務的時間,沒法整除,定時任務就沒有意義了,得通過其他手段,自主控制定時任務頻率。
crontab提供最小分鐘級別的任務,想完成秒級別的任務,得通過編程語言自己寫。問題10:每1分鐘向文件里寫入一句話"超哥666",且實時監測文件內容變化。
* * * * * /usr/bin/echo "好快樂啊" >> /tmp/t1.txt問題11:每天凌晨2點30,執行ntpdate命令同步ntp.aliyun.com,且不輸出任何信息,把命令結果,重定向到黑洞文件
/dev/null
備注:定時任務的命令執行,會產生日志
30 2 * * * /usr/sbin/ntpdate -u ntp.aliyun.com &> /dev/null
黑白名單限制
白名單高于黑名單,也就是說,白名單上的用戶,即使在黑名單中被禁了也可以使用crontab -e進行定時任務編輯
/etc/cron.deny 黑名單文件 (將系統中,所有uid大于1000的用戶,全部寫入黑名單)
/etc/cron.allow 白名單 ,優先級高于黑名單#可能默認沒有該文件,沒有就創建出來即可
定時任務,默認存放的路徑
[root@yuchao-linux01 ~]# ls /var/spool/cron/
jerry01 root
定時任務,服務端的運行日志,可以用于給運維,進行故障排查
/var/log/cron
最后,定時任務,crontab會在系統中,生成大量的郵件日志,會占用磁盤,因此我們都會關閉郵件服務即可
[root@yuchao-linux01 ~]# find / -type f -name 'post*.service'
/usr/lib/systemd/system/postfix.servicesystemctl服務管理命令
[root@yuchao-linux01 ~]# systemctl list-units |grep post
postfix.service loaded active running Postfix Mail Transport Agentsystemctl status postfixsystemctl stop postfix禁止開機自啟
systemctl disable postfix
進程管理篇章
linux系統啟動產生1號進程
孤兒進程
子進程的父進程掛掉后,子進程沒有父進程了,那么就會將該子進程給到1號進程,然后這個就叫做孤兒進程,1號進程過一段時間會對該孤兒進程進行資源回收。換句話說就是孤兒進程的ppid就是1號進程。孤兒進程釋放后,釋放執行的相關文件,數據,以及釋放進程id號(系統id號是有固定的數量)。
僵尸進程
僵尸進程就是子進程掛掉了,但是父進程沒有被通知到,他還以為子進程還在運行著,那么父進程就會一直拿著子進程的一些資源和其他數據,就不會釋放,那么這就是一個僵尸進程了。
ps
ps -ef == ps aux
linux風格的組合參數,一般都是攜帶短橫線
ps -ef unix操作系統下,查看進程,用如下不帶短橫線的參數選項
ps aux
ps兩種風格,分別是unix和liunx風格,但是作用都是一樣的
# UNIX風格,沒有短橫線
a # 顯示所有終端、所有用戶執行的進程
u # 以用戶顯示出進程詳細信息
x # 顯示操作系統所有進程信息
f # 顯示進程樹形結構
o # 格式化顯示進程信息,指定如pid
k # 對進程屬性排序,如k %mem ,正序排序 ,k -%mem 逆序
--sort,再進行排序,如 --sort %mem 根據內存使用率顯示linux標準參數用法
-e # 顯示所有進程
-f # 顯示進程詳細,pid,udi,進程名
-p # 指定pid,顯示其信息,如 ps -fp 2609
-C # 指定進程的名字查看,如sshd.service
-U # 指定用戶名,查看用戶進程信息 ps -fU yuchao01ps -fp 22 #用p參數的話建議配合f參數,因為你看的不就是詳細信息嗎,只用p的話只有端口號,而且參數順序是fp。
top
P:以CPU的使用資源降序排序顯示,默認
M:以內存的使用資源降序排序顯示
N:以pid降序排序顯示
T:由進程使用的時間累計排序顯示
k:給某一個pid一個信號。可以用來殺死進程
r:給某個pid重新定制一個nice值(即優先級)
q:退出top(用ctrl+c也可以退出top)。
1:數字1,可以查看CPU核心的個數及詳細信息
lsof
有的系統沒有安裝該命令,需要安裝lsof工具。比如:yum install lsof -y
這個是list open file 的意思
所以是列出進程運行起來后已經打開了的文件,很有用的一個命令,對于網絡安全應急響應過程中。
-
-p #指定PID,查看該進程使用打開了哪些文件
比如我想找到ssh打開了哪些日志文件,那么我就可以通過這種方式查看: ps -ef | grep nginx #先篩選出nginx的進程號 lsof -p 進程號 | grep log -
-u #查看某個用戶打開了哪些文件
lsof -u 用戶名
找回文件之練習題
nginx已經啟動了,日志一直記錄著黑客刪除了日志文件
rm -f /var/log/nginx/access.log #刪除日志文件黑客不夠細節,忘記了日志文件能夠恢復,nginx還運行著,你應該如何恢復日志文件呢?
答:
ps -ef | nginx #找到nginx的pid號,假設為1234ls /proc/1234/fd/* #根據正在運行的進程號找到proc進程文件,里面的fd文件夾里面所有的文件就是正在運行的文件數據,也就是說我們的access.log日志文件也無非就是從這些文件內容中拷貝過去的。 比如某個 /fd/5的內容就是日志文件,這里數據數據就是輸入進access.log文件中的。kill
kill
-15 #正常的發送kill信號,如果關不掉就關不掉進程了,可能就要用-9
-9 #強制殺死
-1 #重新加載reload進程,比如你修改了配置文件,只需要kill -1 pid即可,省掉了重新啟動服務動作。
pkill
根據進程名字批量殺進程
pkill ping #批量殺死進程ping這個應急響應的時候可能會有大作用,比如shell腳本名字都是一個名,加上他可能是守護進程,殺不完,除了用三劍客語法進程批量殺出之外還可以進行pkill進行批量刪除。
后臺運行命令
jobs #查看后臺進程列表,后臺進程列表順序號從1開始。ctrl + z #暫停進程,進程放到后臺列表中,比如ping是前臺一直進行的,我們可以ctrl + z進行暫停。bg #把進程放入后臺運行,不是暫停哦~ 一般是你暫停后,jobs的id號,bg id這樣子放入后臺fg #將后臺任務放在前臺運行,比如ping,不管你ctrl + z還是bg放在后臺了,都可以通過fg放到前臺來運行或者繼續運行。

三劍客篇章
三劍客大名如下:
- sed
- grep
- awk
通配符
在命令行中,我們想要輸入什么就得到什么,即不會被轉義成某個命令的話就使用’'單引號,
而雙引號,如果你輸入了某些指令或者符號就會當作命令給你執行
以下是兩種不同輸出信息區別:
[root@localhost ~]# echo '123$(pwd)'
123$(pwd)
[root@localhost ~]# echo "123$(pwd)"
123/root
| 字符 | 說明 | 示例 |
|---|---|---|
| * | 匹配任意字符數。 您可以在字符串中使用星號 (*****)。 | ls /opt/my*.txt |
| ? | 在特定位置中匹配單個字母。 | ls /opt/myfis?.txt |
| [ ] | 匹配方括號中的字符。[abd],[a-z] | ls /opt/myfirs[a-z].txt |
| ! | 在方括號中排除字符 [!abcd] [!a-z] | ls myfirs[!a-g].txt |
| - | 匹配一個范圍內的字符。 記住以升序指定字符(A 到 Z,而不是 Z 到 A)。 | [a-z] 小寫的a一直到z的序列 [A-Z] [0-9a-zA-Z] |
| ^ | 同感嘆號、在方括號中排除字符,用法和感嘆號一樣 | ls [^a-c]yfirst.txt |
find找文件與通配符
- 關于文件名的搜索
搜索/etc下所有包含hosts相關字符的文件
find /etc -name '*hosts*'搜索/etc下的以ifcfg開頭的文件(網卡配置文件)
ifcfg*
find /etc -name 'ifcfg*'只查找以數字結尾的網卡配置文件(ifcfg開頭的)
find /etc -name 'ifcfg*[0-9]'找到系統中的第一塊到第四塊磁盤,注意磁盤的語法命名
/dev/sda sdb sdd sdc sde sdf
/dev/sda1
/dev/sda2
/dev/sda3ls /dev/sd[abcd]找找sdb硬盤有幾個分區,請考慮到* ? [] 通配符
-這個不對,不嚴謹
ls /dev/sdb*
等于找到
/dev/sdb
ls /dev/sdb1
ls /dev/sdb2
ls /dev/sdb3
-正確的寫法
[0-9]
ls /tmp/dev/sdb[0-9]
-還有寫法嗎?
問號
ls /tmp/dev/sdb?
練習二
測試數據源準備
[yuchao-linux01 root ~/test_shell]$touch {a..h}.log
[yuchao-linux01 root ~/test_shell]$touch {1..10}.txt
[yuchao-linux01 root ~/test_shell]$ls
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt a.log b.log c.log d.log e.log f.log g.log h.log
[yuchao-linux01 root ~/test_shell]$找出a到e的log文件
ls [a-e].log找出除了3到5的txt文件
ls [!3-5].txt
ls [^3-5].txt找出除了2,5,8,9的txt文件
兩個寫法
ls [!2589].txt
ls [!2,5,8,9].txt尖角號一樣和感嘆號
[242-yuchao-class01 root ~]#ls [^2,5,8,9].txt
1.txt 3.txt 4.txt 6.txt 7.txt
[242-yuchao-class01 root ~]#ls [^2589].txt
1.txt 3.txt 4.txt 6.txt 7.txt找出除了a,e,f的log文件
ls [!aef].log
ls [^aef].log
ls [^a,e,f].log
特殊符號
比起通配符來說,linux的特殊符號更加雜亂無章,但是一個專業的linux hacker
孰能生巧,這些都不是問題
cd路徑相關
| 符號 | 作用 |
|---|---|
| ~ | 當前登錄用戶的家目錄,對目錄操作的命令,cd ,ls,touch,mkdir,find,cat |
| - | 上一次工作路徑,僅僅是在shell命令行里的作用 |
| . | 當前工作路徑,表示當前文件夾本身;或表示隱藏文件 .yuchao.linux |
| … | 上一級目錄 |
引號相關
引號意義,為什么要用引號
- 在于區分一個字符串的邊界
- 因為linux識別,命令,參數,文件對象,中間是以空格區分的
- echo ‘hello world’
'' 單引號、所見即所得,引號里的所有內容,原樣輸出
[242-yuchao-class01 root ~]#echo 'hello&*('
hello&*(
[242-yuchao-class01 root ~]#echo 'hello!!*('
hello!!*(
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo 'hello!!*($(pwd)'
hello!!*($(pwd)
"" 雙引號、可以解析變量、及引用、linux命令
[242-yuchao-class01 root ~]#echo 'hello!!*($(pwd)' "現在時間是$(date)"
hello!!*($(pwd) 現在時間是Mon Apr 11 11:04:53 CST 2022
[242-yuchao-class01 root ~]#echo "現在時間是 $(date '+%F %T')"
現在時間是 2022-04-11 11:08:26
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo '現在時間是 $(date '+%F %T')'
現在時間是 $(date +%F %T)[242-yuchao-class01 root ~]#name='吳彥祖'
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo "別人都喊我${name}"
別人都喊我吳彥祖
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo '別人都喊我${name}'
別人都喊我${name}
```反引號、可以解析命令`
輸出一段話
當前時間是:時間格式化
引號嵌套
[242-yuchao-class01 root ~]#echo "當前時間是:`date '+%F %T'`"
當前時間是:2022-04-11 11:11:23
作用同上
$(linux命令)
無引號,一般我們都省略了雙引號去寫linux命令,但是會有歧義,比如空格,建議寫引號
重定向
數據流代號
0 stdin 數據輸入,如鍵盤的輸入,如文件數據的導入
1 stdout ,cat /etc/passwd
2 stderr , cat /etc/passwdddddddddddddddddddddd
2>&1 stderr重定向
把stderr當做stdout進行處理
[242-yuchao-class01 root ~]#ls /opt/ttttttttt > /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
2>&1 stderr追加重定向
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
命令執行
-
command1 && command2 #command1成功后執行command2
編譯安裝軟件 make && make install 例子,多個 && 多個命令成功后,向后執行 #ls && cd /opt && pwd -
|| 符 #只有前面命令失敗、才執行后面命令
# 用戶創建 判斷用戶已經存在了,就刪掉用戶 useradd wenjie || userdel -f wenjie -
分號,執行多個linux命令
[242-yuchao-class01 root /opt]#cd /opt ; pwd ;cd ~; /opt -
\ # 轉義特殊字符,還原字符原本含義
需要和雙引號結合使用 [242-yuchao-class01 root ~]#touch "\$name的文件" [242-yuchao-class01 root ~]# [242-yuchao-class01 root ~]#ls $name的文件 -
$() # 執行小括號里的命令
[242-yuchao-class01 root ~]#echo "opt下的內容是$(ls /opt)" opt下的內容是mm8888888.sh M.sh myfirst.txt -
`` # 反引號,和$()作用一樣
[242-yuchao-class01 root ~]#echo "opt下的內容是`ls /opt`" opt下的內容是mm8888888.sh M.sh myfirst.txt 創建一個log文件,以當前時間命名 文件名是 "nginx_日期.log"當你進行引號嵌套時,請你這樣用, 最外層用雙引號,內層用單引號 touch "nginx_`date '+%F#%T'`.log" -
| # 管道符
管道符,是命令二多次加工處理找出某進程 ps -ef|grep 進程名 -
{} # 生成序列
生成英文字母序列,數字序列,用于文件拷貝的文件名簡寫
正則表達式
使用正則表達式的時候盡量使用單引號,因為雙引號一般是用于你要執行某些命令或者要打印某些變量的時候要用的。
- 通配符和正則的區別
從語法上:只有awk grep sed才能識別正則表達式,其他的都是通配符 比如其他linux命令的操作其實都是通配符的概念記住一個點就是:正則就是在引號里面的,通配符可以不在引號里面的, 比如:ls [a-z].log 這個就是通配符,可能你已經忘掉了。
Linux下普通命令無法使用正則表達式的,只能使用linux下的三個命令,結合正則表達式處理。
- sed
- grep
- awk
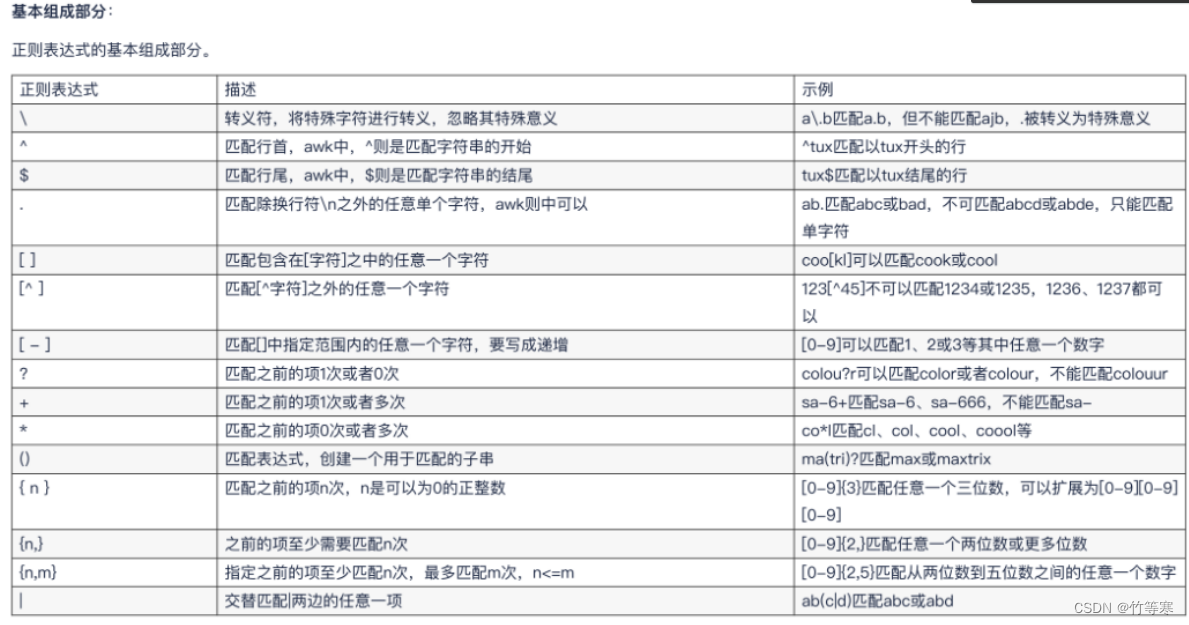
基本正則表達式
BRE對應元字符有
^ $ . [ ] *
擴展正則表達式
ERE在在BRE基礎上,增加了
( ) { } ? + | 等元字符
其實用的比較多的擴展正則式( ),因為我們使用這個可以進行多次匹配,() () \1 \2,就是對應的第幾個括號內匹配好的正則,能夠重復使用。
grep使用擴展正則的參數是-E
sed使用擴展正則的參數是-r
注意點
首先,不匹配換行這事,是因為 . 的作用
.* 是重復前面這個字符0次或N次
- 例如關于多行數據
i love you
i hate you love.*hate 這樣的正則是不可用的,拿不到的數據的
-
轉義符: \
-
空白行
^$
grep
grep有些參數就是為了正則而生的
-v #取反,使用正則匹配到的結果取反
-o #只看你篩選到的那一個字符,而不是直接打印出整行
-E #擴展正則表達式就要用這個 ,如果你忘記了哪個是擴展正則表達式符號,那就每一個都適用正則表達式就行了。
-w #選項默認匹配一個單詞。
( ) 括號、分組符。很好用!!!
語法
() 作用是將一個或者多個字符捆綁在一起,當做一個整體進行處理1.可以用括號,把正則括起來,以及系統最多支持9個括號小括號功能之一是分組過濾被括起來的內容,括號內的內容表示一個整體括號內的數據,可以向后引用,其實就是\1代表你第一個括號寫的內容或者正則表達式,\1省去了再次重復()內的內容或者正則表達式而已
() () () () \1 \2 \3 \4 括號()內的內容可以被后面的"\n"正則引用,n為數字,表示引用第幾個括號的內容\1:表示從左側起,第一個括號中的模式所匹配到的字符
\2:從左側起,第二個括號中的模式所匹配到的字符
測試數據
測試數據
[root@yuchao-tx-server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
I am glad to see you, god,you are a good god!
要求僅僅匹配出glad和good
分組的第一個用法,將數據,正則當做一個整體處理
grep -E 'glad|good' god.log括號用法
grep -E 'g(la|oo)d' god.log
g.........d
分組與向后引用
-
向后引用用法, 在grep中不容易體現
-
但是用在sed中就非常牛掰了
語法
()
分組過濾,被括起來的內容表示一個整體,另外()的內容可以被后面的\n引用,n為數字,表示引用第幾個括號的內容\n
引用前面()里的內容,例如(abc)\1 表示匹配abcabc
測試數據
[root@yuchao-tx-server test]# cat lovers.log
I like my lover.
I love my lover.
He likes his lovers.
He love his lovers.
提取love出現2次的行
[242-yuchao-class01 root ~]#grep -E '^.*(love).*\1.*' lovers.txt -o
I love my lover.
He love his lovers.
sed
sed默認是一行一行,處理文件中每一行的數據
工作里用的最多的還是指定數字行號,或者完整字符精確匹配,不容易出錯,
而正則或是其他模糊匹配,很容易改錯,了解即可。
參數
-n 取消默認的 sed 軟件的輸出,常與 sed 命令的 p 連用
-e 說白了-e就是實現多次編輯,-e告訴sed你編輯完后可以第二次使用-e參數繼續編輯你第一輪搞好的數據,一行命令語句可以執行多條 sed 命令
-f 選項后面可以接 sed 腳本的文件名
-r 使用正則拓展表達式,默認情況 sed 只識別基本正則表達式
-i 直接修改文件內容,而不是輸出終端, 如果不使用-i 選項 sed 軟件只是修改在 內存中的數據,并不影響磁盤上的文件
命令
個人比較常用的命令
a 追加,在指定行后添加一行或多行文本
p 打印模式空間的內容,通常 p 會與選項-n 一起使用
d 刪除指定的行
i 插入,在指定的行前添加一行或多行文本
s 取代,s#old#new#g==>這里 g 是 s 命令的替代標志,注意和 g 命令區分。g命令是全局替換,而不加g參數的話就是每一行的第一個匹配成功的就替換。同時s命令不僅僅可以使用#進行分割,還能使用@或者/,用#是因為好區分,不容易混淆。
c 直接替換指定的行,語法是:c命令后面接要替換的數據 sed '1 c data' file.txt其他命令
D 刪除模式空間的部分內容,直到遇到換行符\n 結束操作,與多行模式相關
h 把模式空間的內容復制到保持空間
H 把模式空間的內容追加到保持空間
g 把保持空間的內容復制到模式空間
G 把保持空間的內容追加到模式空間
x 交換模式空間和保持空間的內容
l 打印不可見的字符
n 清空模式空間,并讀取下一行數據并追加到模式空間
N 不清空模式空間,并讀取下一行數據并追加到模式空間
P(大寫) 打印模式空間的內容,直到遇到換行符\你結束操作
q 退出 sed
r 從指定文件讀取數據
w 另存,把模式空間的內容保存到文件中
y 根據對應位置轉換字符
:label 定義一個標簽
t 如果前面的命令執行成功,那么就跳轉到 t 指定的標簽處,繼續往下執行后 續命令,否則,仍然繼續正常的執行流程
對sed軟件的一些理解:
命令模式是在引號中使用的,參數就是正常的加參數一樣即可。
sed主要是用于搜索內容和進行文本替換的,因為是一個軟件,所以能夠用于進行shell腳本的編寫。
格式:sed '行號 命令(可以多個)' file
這個行號可以是一個范圍,下面就是一個行范圍語法↓↓↓↓↓↓↓
關于sed處理文件行范圍語法
| sed命令語法 | 作用 |
|---|---|
| 3 {sed-commands} | 操作第三行 |
| 3,6 {sed-commands} | 操作3~6行,包括3和6行 |
| 3,+5 {sed-commands} | 操作3到3+5(8)行,包括3,8行 |
| 1~2 {sed-commands} | 步長為2,操作1,3,5,7…行 |
| 3,$ {sed-commands} | 對3到末尾行操作,包括3行 |
| /yuchao/ {sed-commands} | 對匹配字符yuchao的該行操作 |
| /yuchao/,/chaoge/ {sed-commands} | 對匹配字符yuchao到chaoge之間的行操作 |
| /yuchao/,$ {sed-commands} | 對匹配字符yuchao到結尾的行操作 |
| /yuchao/,+2 {sed-commands} | ‘/yuchao/,+2p’,打印匹配到yuchao的行,包括其后2行 |
| /yuchao/ {!d} # 這里!表示取反的意思,其他命令能用的話也是一個道理 | 找到yuchao行,然后不刪除他,刪除除了yuchao的行 |
| 備注:使用//,里面匹配的內容可以是正則表達式,所以sed功能非常強大 |
—shell
下面介紹增刪查改,但是不管是增刪查改,里面處理文件行范圍或者方式都是通用的,只不過使用的參數和命令不一樣罷遼。
增
增加數據的命令有:a 和 i
在第二行進行添加數據(沒有要求修改文件那就不用 -i 參數)
sed '2 i 添 加 的 內 容 ' file.txt #這里添加的內容可以是有空格的,因為你命令i后面接的本來就是文本內容注意:添加多行的話,直接輸入\n即輸入了回車換行
刪
sed不指定行號的話,默認匹配所有行,執行d刪除命令
sed 'd' file.txt
刪除第二行數據
sed '2 d' file.txt
刪除第二行到第五行數據
sed '2,5 d' file.txt
刪除第二行和往下的兩行
sed '2,+2 d' file.txt
只保留第一和第二行
sed '3,$ d' file.txt
只保留奇數行
sed '1~2 d' file.txt #從1行開始,步長為2,那么就是1 3 5 7 9,保留偶數行那就是2~2
根據正則匹配刪除對應的行數據
sed '/正則表達式/ d' file.txt
刪除兩個正則表達式之間的行數據
sed '/正則1/,/正則2/ d' file.txt
刪除指定的兩個正則表達式匹配成功的行數據(注意,兩個正則式不一樣的,只要兩個其中一個匹配都要刪除)
sed '/正則1/;/正則2/ d' file.txt
刪除以.結尾的行
sed '/\.$/ d' file.txt
查
查的話就是找出來然后打印出來,那么就要用到p命令
根據正則表達式找到對應的行,然后打印出來(僅打印你找到的行即可)
需要用到 -n 參數和 p 命令
sed -n '/正則表達式/ p' file.txt
忽略大小寫匹配正則表達式,然后打印出來
sed -n '/正則/ I p' file.txtsed -n '/正則/ Ip' file.txtsed -n '/正則/Ip' file.txt以上三個都是一樣的結果,因為這里參數用的比較多,就在這里作為一個例子,命令和參數其實都可以進行堆疊在一起使用
改
行替換:替換第二行數據為xxx OK
sed '2 c xxx OK' file.txt
字符替換:將每一行第一處匹配的字符替換,將www替換為xxx
(以下三種方式都是可以,但是用#居多)
sed 's#www#xxx#' file.txtsed 's@www@xxx@' file.txtsed 's/www/xxx/' file.txt
字符替換:全局匹配的字符,將所有www替換為xxx
(g為全局替換)
sed 's#www#xxx# g' == sed 's#www#xxx#g'
指定最后一行($) 字符www替換為hacker
-
第一個匹配成功的替換
sed '$ s#www#hacker#' file.txt -
所有匹配成功的都替換
sed '$ s#www#hacker#g' file.txt
指定數據中,根據字符替換提取出welcome字符
echo 'I am teacher yuchao,welcome my linux course'
echo 'I am teacher yuchao,welcome my linux course' | sed -r 's#.*,(.*)\sm.*#\1#g'
\s表示單個空格
分組取出ip
使用命令ip a,用sed將其ip提取出來
ip a | sed -rn 's#^.*inet\s([0-9]{,3}.[0-9]{,3}.[0-9]{,3}.[0-9]{,3})/[0-9]{,2}\sbrd.*#\1#g p'

注意
如果要使用shell腳本變量的話記得使用雙引號,不要忘記了單引號是你給啥就輸出啥,還有用正則的時候使用單引號s###替換字符中,你在##之間是可以直接寫正則表達式的,然后如果你不是使用替換字符命令的話就需要使用//字符中間才能夠寫正則表達式進行操作。
其他命令
多次編輯-e
找出http和linux的行
sed -e '/http/p' -e '/linux/p' -n t1.log
解釋:
sed -e ‘/http/p’ 是在打印所有文本的過程中,如果找到匹配的數據后將那個數據再打印一份,
第一次出來的數據,同時還使用了p命令存儲了一次匹配的數據,給到下一次匹配的話還是完整的數據,
那么這樣的話我們第二次-e后面那個就能夠繼續使用正則匹配繼續匹配,然后還是使用p命令進行存儲
然后接著-n參數就能夠將兩次p命令存儲的匹配出來的數據進行一次性打印了。
寫入文件w命令
sed '/正則/ w 要寫入的文件路徑' file.txt
比如:
匹配http的正則表達式,然后寫入/etc/ok.ok文件中
sed -n '/http/ w /etc/ok.ok' file.txt #注意:這里使用-n意思是不打印出來文件中的內容,最好習慣性的加上該參數,因為以后要處理的文件數據量會十分大,-n參數不會影響操作,只是一個打印和不打印的區別而已。
;分號
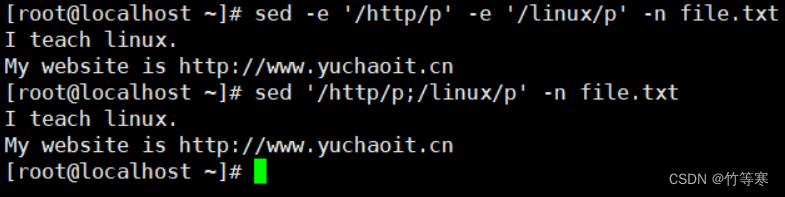
分號也用于執行多條命令,這里和-e能夠實現一樣的效果
比如:我要同時提取出http和linux相關的行。
-e參數寫法
sed -e '/http/p' -e '/liunx/p' -n file.txt分號寫法
sed '/http/p;/linux/p' -n file.txt
awk
對行操作、對列操作
-
如何分割數據,
-
如何輸出數據,指定第一行,到第三行
語法:
awk 參數 '模式 {動作}' test.txt模式可以理解為是一種判斷,那么就是可以用&& || ,就是說可以是一個判斷比如NR判斷行號,或者是正則匹配。
模式是這樣指定正則的:awk '/正則/{print $0}'
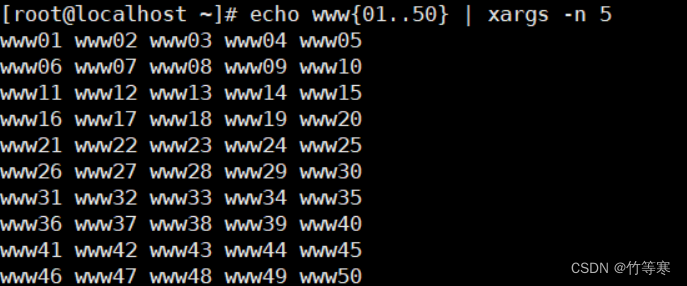
測試數據生成指令:
echo www{01..50} | xargs -n 5 > test.txt #xargs -n參數是排版,每一行只打印5列,然后輸入文件中即可
動作
| awk變量符號 | 作用 | 名稱翻譯 |
|---|---|---|
| NR | 行記錄、行數據、awk處理的第幾行 | umber of record |
| NF | 字段的數量,表示這一行數據分了幾列, | Number of filed, |
| $1 | 第一個字段的數據、$2、$3以此類推 |
$0表示打印所有列數
awk '{print $0}' test.txt
打印每一行數據的第一列數據
awk '{print $1}' test.txt
打印每一行數據的第二列數據
awk '{print $2}' test.txt
打印每一行的第一和第三列
awk '{print $1,$3}' test.txt
NR內置變量
NR內置行變量
直接打印這個內置變量,表示取當前行的號碼
NR == number of record 行記錄,你也可以記住row表示行,我個人覺得這樣好記一點
NR>= 大于等于行
NR<= 小于等于
NR>=N && NR<=M 從N行到M行
|| 或的用法
開頭顯示行號
awk '{print NR,$0}' test.txt
結尾顯示行號
awk '{print $0,NR}' test.txt
打印第二行的所有字段數據(同理可以打印其他行的數據)
awk 'NR==2 {print $0}' test.txt
打印第一行到第三行的所有字段
awk 'NR>=1&&NR<=3 {print $0}' test.txt
NF內置變量
NF內置列變量
直接寫NF變量表示每一行字段的總數
number of field (字段的數量) 等于列的總數
請注意理解:NF表示每一行的列數,那么我們NF打印的就是每一行的列數,那么加個$的話就是$NF,那不就是變成了每一行的最后一列了嗎!!!!!!!!!!!
在所有數據后面加上每一行的列數
awk '{print $0,NF}' test.txt

僅僅打印最后一列的數據
awk '{print $NF}' test.txt那么同理輸出倒數第2列
awk '{print $(NF-1)}' test.txt
打印第二列到第五列的數據
awk '{print $2,$3,$4,$5}' test.txt
NR 和 NF 結合一下就可以美化輸出了。
-
輸出全部數據的同時,輸出每一行分別有多少列和同時輸出行號
awk '{print $0,NF,NR}' test.txt[root@localhost ~] awk '{print $0,NF,NR}' test.txt www01 www02 www03 www04 www05 5 1 www06 www07 www08 www09 www10 5 2 www11 www12 www13 www14 www15 5 3 www16 www17 www18 www19 www20 5 4 www21 www22 www23 www24 www25 5 5 www26 www27 www28 www29 www30 5 6 www31 www32 www33 www34 www35 5 7 www36 www37 www38 www39 www40 5 8 www41 www42 www43 www44 www45 5 9 www46 www47 www48 www49 www50 5 10
其他變量
下面兩個變量都是可以通過-v參數進行修改的
RS ##行分隔符,默認行分隔符是\n換行符,你可以通過-v參數修改,awk -v RS=' '進行修改,比如修改成空格為行分割符,那就碰到空格為一行
ORS ##輸出行分隔符,默認輸出的行分隔符是\n,這個對我們將輸出美化來說很重要,下面用一個例子進行舉例說明
FS ##列分隔符,默認列分隔符是空格,你可以通過-v參數修改,awk -v FS=':'進行修改,比如修改成:列分割符,那就是碰到:為一列
OFS ##輸出列分隔符,默認是空格,這個也是對我們輸出美化很重要。
注意:修改列分割符一般不這么使用,我們一般是使用-F參數,比如:awk -F ‘:’ … 這樣就是修改了列分隔符為:
-
RS
測試數據為:
[root@localhost ~]# echo 111@@222@@333@@444@@555 > RS.txt [root@localhost ~]# cat RS.txt 111@@222@@333@@444@@555第一種美化數據,因為ORS默認就是\n為行分割符號:
awk -v RS='@@' '{print $0}' RS.txt當然你也可以多此一舉加一個: -v ORS='\n' awk -v RS='@@' -v ORS='\n' '{print $0}' RS.txt第二中美化數據,自己指定ORS行分割符號:
awk -v RS='@@' -v ORS='---------' '{print $0}' RS.txt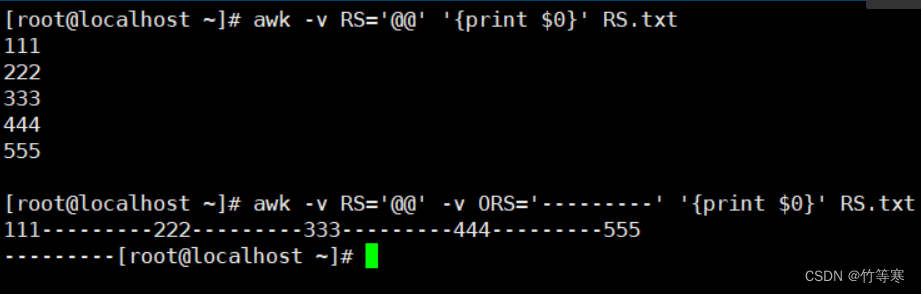
-
ORS
測試數據為:
[root@localhost ~]# cat ORS.txt 111 222 333 444 555將行分隔符換成@@
awk -v ORS='@@' '{print $0}' ORS.txt[root@localhost ~]# awk -v ORS='@@' '{print $0}' ORS.txt 111@@222@@333@@444@@555@@總結:
一般來說,如果你僅僅要修改為換行符為\n,那么直接使用RS進行切割開即可,因為ORS默認就是\n,
而你要使用ORS進行修改的通常是希望數據不以\n進行分割的。 -
OFS
測試數據為:
這個故意設置分隔符號為@@,我們下面進行變量設置的時候理解的更加到位
[root@localhost ~]# cat OFS.txt 111@@222@@333@@444@@555下面指令是一樣的,只不過是直接使用了-F參數[root@localhost ~]# awk -F @@ -v OFS=':' '{print $1,$2}' OFS.txt 111:222目標是將@@分隔符修改為冒號 :
[root@localhost ~]# awk -v OFS=':' -v FS='@@' '{print $1,$2}' OFS.txt 111:222總結:
不要忘記了FS默認列分隔符是空格,所以我們這里測試數據就是故意用@@作為分隔符,
所以我們就需要特地的修改FS變量為@@,這樣才能取到對應的列出來,
然后我們通過OFS修改輸出的列分隔符號即可。
BEGIN 和 END
一道題就能理解了
無非就是
BEGIN就是開頭
END就是結尾
就是在開頭和結尾加上你要加的東西即可,然后格式的話只不過是位置和多了BEGIN或者END而已
head -5 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologinawk -v FS=':' 'BEGIN{print "用戶名","uid","gid","家目錄","登錄解釋器" } NR<=5{print $1,$3,$4,$6,$7} END{print "awk_over~"}' /etc/passwd | column -tcolumn -t是美化輸出的

參數
-v 修改awk內置變量RS 設置哪個為你的數據行分隔符ORS 修改要輸出的行分隔符FS 設置哪個為你的數據列分隔符OFS 修改要輸出的列分隔符
-F 修改列分隔符
系統資源篇章
正在努力完善中…
軟件包篇章
正在努力完善中…
磁盤篇章
正在努力完善中…
)













-- 全局常用導出組件Export封裝)




