一、集群模式概述
Redis 中哨兵模式雖然提高了系統的可用性,但是真正存儲數據的還是主節點和從節點,并且每個節點都存儲了全量的數據,此時,如果數據量過大,接近或超出了 主節點 / 從節點機器的物理內存,就會出現嚴重的問題;
集群模式就是為了解決這個問題的,它通過引入更多的主節點和從節點,每一組主節點及其所對應的從節點存儲了數據全集的一部分,多組這個的結構構成了一個更大的整體,這就是集群;
如下圖所示,假定引入了三組主從節點來存儲全量數據,那么每組機器只需要存儲全集的 1/3 即可,其中每組機器中的每個節點保存的數據內容是一樣的,這樣的一組機器(包含一個主節點和多個從節點)也稱為一個分片;
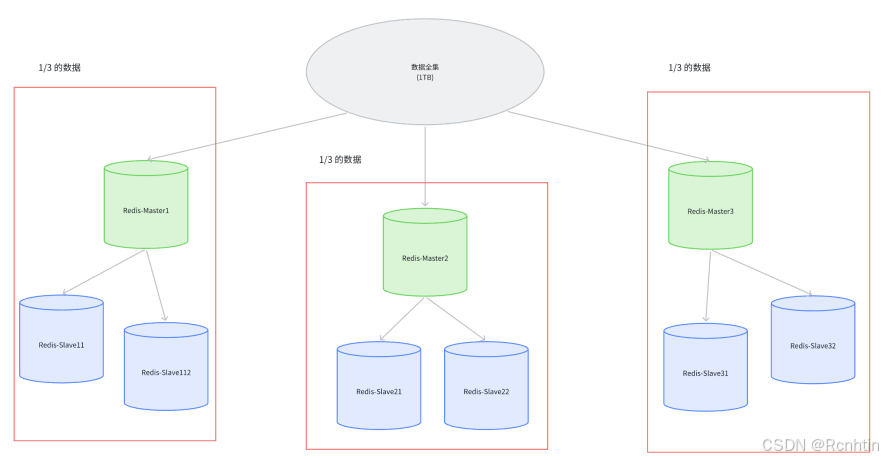
?此時,如果全量數據繼續增加,就只需引入更多的分片即可;
二、數據分片算法
1. 哈希求余
設有 N 個分片,使用 [0,N-1] 來編號;
哈希求余就是針對給定的 key,先根據一個 hash 函數計算出 hash 值(例如使用 MD5 算法計算 hash 值),再把得到的結果進行 % N,得到的結果就是其所對應的分片編號;
優點:簡單高效,數據分配均勻;
缺點:一旦需要進行擴容,N 就會改變,導致原有的映射規則被破壞(hash(key) % N),就需要讓節點之間的數據相互傳輸,重新排列,以滿足新的映射規則,此時需要搬運的數據量非常多,開銷很大;
2. 一致性哈希算法
首先,把 [0,2^32-1] 這個數據空間,映射到一個圓環上,數據按照順時針方向增長;
假設存在三個分片,如下圖所示
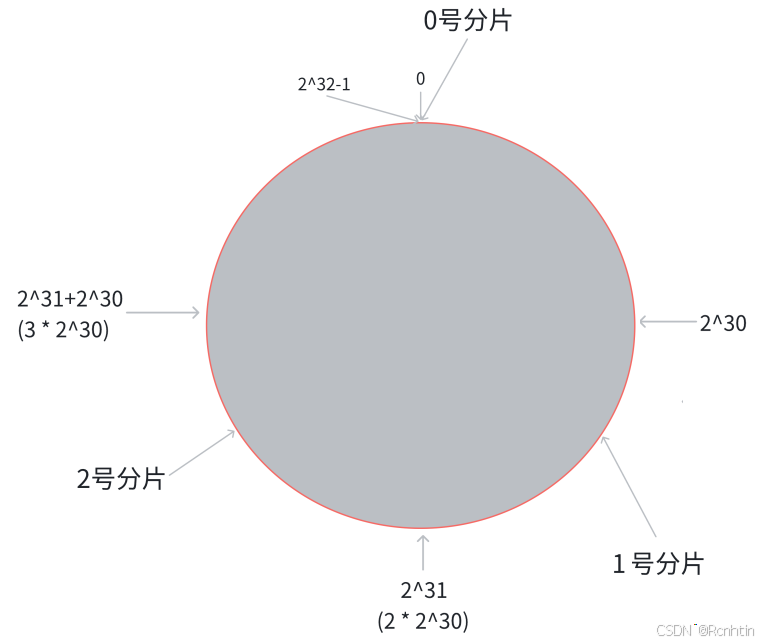
假設有一個 key,通過 hash 函數計算得到 hash 值 H,那么這個 key 對應的分片就是從 H 所在位置,順時針往下找,找到的第一個分片;
這就相當于,N 個分片的位置,把整個圓環分成了 N 個區間,key 的 hash 值落在某個區間內,就歸對應區間管理;
當需要擴容時,原有分片在環上的位置不動,只需要在環上新安排一個分片位置即可;
優點:大大降低了擴容時數據搬運的規模,提高了擴容操作的效率;
缺點:數據分配不均勻(有的分片數據多,有的少,數據傾斜);
3. 哈希槽分區算法(Redis 采用)
為了解決上述搬運成本高 和 數據分配不均勻的問題,Redis cluster 引入了哈希槽 (hash slots) 算法;
hash_slot = crc16(key) % 1638416384 = 16 * 1024 = 2 ^ 14,這就相當于把整個 hash 值,映射到 16384 個槽位上,即[0,16383]然后再把這些槽位比較均勻的分配給每個分片,同時每個分片的節點都要記錄自己持有哪些分片;
比如有三個分片,則槽位的分配方式可能為:
- 0 號分片:[0,5461],共 5462 個槽位
- 1 號分片:[5462,10923],共 5462 個槽位
- 2 號分片:[10924,16383],共 5460 個槽位
每個分片的節點使用 位圖 來表示自己持有哪些槽位,對于 16384 個槽位來說,需要 2048 個字節即 2 KB 大小的內存空間來表示;
當需要進行擴容時,比如新加一個 3 號分片,就可以針對原有的槽位進行重新分配,分配的結果可能為:
- 0 號分片:[0,4095],共 4096?個槽位
- 1 號分片:[5462,9557],共 4096 個槽位
- 2 號分片:[10924,15019],共 4096 個槽位
- 3 號分片:[4096,5461],[9558,10923],[15020,16383],共 4096 個槽位
在實際使用 Redis 集群分片的時候,不需要手動指定哪些槽位分配給某個分片,只需要告訴某個分片應該持有多少個槽位即可,Redis 會自動完成后續的槽位分配,以及對應的 key 搬運的工作;
為什么是 16384 個槽位呢?
Redis 官方的解釋是:節點之間通過心跳包通信,心跳包中包含了該節點持有哪些 slots,這個是使用位圖這樣的數據結構表示的,表示 16384 (16k) 個 slots,需要的位圖大小是 2KB,如果給定的 slots 數更多了,比如 65536 個了,此時就需要消耗更多的空間,8 KB 位圖表示了,8 KB,對于內存來說不算什么,但是在頻繁的網絡心跳包中,還是?個不小的開銷的;
另一方面,Redis 集群一般不建議超過 1000 個分片,所以 16k 對于最大 1000 個分片來說是足夠用的,同時也會使對應的槽位配置位圖體積不至于很大;
三、集群故障處理
1. 故障判定
集群中的所有節點,都會周期性的使用心跳包進行通信;
- 當節點 A 給節點 B 發送 ping 包,B 就會給 A 返回一個 pang 包;每個節點,每秒鐘,都會給一些隨機的節點發起 ping 包,這樣設定是為了避免在節點很多的時候,心跳包也非常多;
- 若節點 A 給節點 B 發起 ping 包,B 不能如期回應時,此時?A 就會嘗試重置和 B 的 tcp 連接,看能否連接成功,如果仍然連接失敗,A 就會把 B 設為 PFAIL 狀態(相當于主觀下線);
- 當A 判定 B 為 PFAIL 之后,會通過 redis 內置的 Gossip 協議,和其他節點進行溝通,向其他節點確認 B?的狀態,(每個節點都會維護一個自己的 "下線列表",由于視角不同,每個節點的下線列表也不?定相同);
- 此時 A 發現其他很多節點,也認為 B 為 PFAIL,并且數目超過總集群個數的一半,那么 A 就會把 B 標記成 FAIL (相當于客觀下線),并且把這個消息同步給其他節點 (其他節點收到之后,也會把 B 標記成 FAIL)
至此 B 就被徹底判定為故障節點了;
若某部分節點宕機,有可能會引起整個集群宕機 (整個集群處于 fail 狀態),主要有以下三種情況:
- 某個分片上的主節點和所有從節點都掛了
- 某個分片上的主節點掛了,并且沒有從節點(可歸納為第一種)
- 超過半數的主節點掛了(此時就無法完成投票選舉主節點的工作了)
2. 故障遷移
在上述故障判定中,若 B 是從節點,則不需要進行故障遷移,若 B 是主節點,并假設 B 有兩個從節點 C 和 D,此時就會由 從節點 C D 觸發故障遷移(把從節點提拔為主節點);
故障遷移的具體步驟為:
- 從節點判定自己是否具有參選資格:?如果從節點和主節點已經太久沒通信(此時認為從節點的數據和主節點差異太大了), 時間超過閾值, 就失去競選資格; ??
- 具有資格的節點,比如?C?和?D,會先休眠一定時間,休眠時間?=?500ms?基礎時間?+?[0, 500ms]?隨機時間?+?排名?*?1000ms,offset?的值越大,則排名會越靠前(越小);?
- 比如?C?的休眠時間到了,C?就會給其他所有集群中的節點,進行拉票操作,但是只有主節點才有投票資格;
- 主節點就會把自己的票投給?C?(每個主節點只有?1?票); 當?C?收到的票數超過主節點數目的一半, C?就會晉升成主節點; (C?自己負責執行?slaveof?no?one, 并且讓?D?執行?slaveof?C);
- 同時,C?還會把自己成為主節點的消息,同步給其他集群的節點;大家也都會更新自己保存的集群結構信息;
四、集群擴容
1. 把新的主節點加入到集群
redis-cli --cluster add-node (新的主節點的ip地址和端口號) (集群中任意節點的ip地址和端口號)2. 重新分配 slots
redis-cli --cluster reshard (集群中任意節點的ip地址和端口號)3. 給新的主節點添加從節點
redis-cli --cluster add-node (新的從節點的ip地址和端口號) (集群中任意節點的ip地址和端口號) --cluster-slave --cluster-master-id (新的主節點的 nodeId)








)






:了解Python語言基礎以及數據類型轉換、基礎輸入輸出)


