“我們正處在全新起點,這是一個以大模型為核心的人工智能新時代,大模型改變了人工智能,大模型即將改變世界。”——5月26日,百度創始人、董事長兼CEO李彥宏先生在2023中關村論壇發表了《大模型改變世界》演講。
李彥宏指出,大模型成功地壓縮了人類對于整個世界的認知,讓我們看到了實現通用人工智能的路徑。
越來越多的人相信,第四次產業革命正在到來,而這次革命正是以人工智能為標志的。
人工智能技術再次成為人類創新的焦點,大模型在許多領域的應用越來越廣泛,今年以來更是在全球掀起了狂潮。一夜之間,什么元宇宙、區塊鏈、Web3.0之類的風口全都消失了,只有大模型才是唯一的C位。
😝有需要的小伙伴,可以V掃描下方二維碼免費領取🆓

01
AI大模型到底是什么?
**
**
大模型(Foundation Model)是指通過大規模的數據、算法和計算能力訓練出的高精度深度學習模型,通常具有千萬億次的計算能力,可以在語音識別、自然語言處理、圖像識別等領域,實現人類甚至超越人類的性能表現。
大模型通常有以下幾大特點:
1、巨大的參數量:大模型通常包含數十億個參數,需要大量的數據和計算資源來訓練。
2、強大的內容生成能力:能夠生成高質量的文本和圖像,為自然語言處理和計算機視覺等領域的應用提供了強大的工具。
3、深厚的語義理解:能夠理解文本和圖像的深層語義信息,為自然語言處理和計算機視覺等領域的應用提供了深厚的語義理解能力。
4、高效的推理能力:能夠進行高效的推理和推斷,為自然語言處理和計算機視覺等領域的應用提供了高效的推理能力。
5、需要的計算資源較多:訓練和推理需要大量的計算資源,如GPU和TPU等,需要高性能的計算集群和云計算平臺。
提到大模型,我們不得不再次提起今年爆火的chatGPT來:
人工智能的四層架構分別是:算力層、框架層、模型層和應用層,其中:
1、算力層:主要包括芯片、處理器、云計算和超算等硬件等基礎設施, AI需要有強大的計算能力來支持各種算法和應用的訓練、推斷和分析,算力層就是為人工智能提供強大的計算和存儲能力的基礎。
2、框架層:人工智能算法的開發需要使用各種編程語言和框架,框架層是人工智能的基石,例如TensorFlow、PyTorch、MXNet等。這些框架能夠提供高效的計算圖優化、分布式訓練等功能,提高人工智能應用的開發和訓練效率。
3、模型層:指的是在框架層中訓練好的各種人工智能模型,包括深度學習模型、傳統機器學習模型、強化學習模型等,典型的預訓練大語言模型八廓openAI 的GPT、百度的文心大模型,以及Google的bard大模型等。這些模型是人工智能應用的核心,能夠解決各種問題,例如圖像識別、自然語言處理、推薦系統等。
4、應用層:應用層處于人工智能的最上層,指的是人工智能技術在各個領域的應用,例如智能客服、人臉識別、自動駕駛等。這些應用能夠幫助企業和用戶提升效率、改善體驗、實現創新等,同時應用需求也會反向推動模型、框架和算力的升級和創新。
我們大多數人所接觸到的AI,往往是處于應用層。
但是ChatGPT和文心一言比較特殊,既屬于模型層,也屬于應用層。
GPT是基于人工智能領域的大數據和機器學習技術,通過大量的訓練和優化,可以用來生成人類自然語言的大模型;同時,它也是一個應用,可以通過與用戶的交互和對話,提供有用的信息和幫助,比如回答問題、提供建議、生成文本摘要等。因此,他們處于模型層和應用層之間。
所以如果把每天來跟我們進行直接對話交互的chatGPT圖文界面比喻成它的“嘴巴”,那么背后思考我們所提出這些問題的“大腦”,正是大模型這種東西。
02
國內外的大模型玩家有哪些?
在國外,大模型的研究起步較早,其中的重量級玩家主要包括谷歌、微軟、亞馬遜、Facebook等大型科技公司。

圖:國外知名大模型簡介
在國內,隨著人工智能技術的不斷發展,大模型的應用也越來越廣泛。目前國內的大模型玩家主要包括百度、阿里巴巴、騰訊、華為等大型科技公司。其中,百度的文心一言、阿里巴巴的通義系列、騰訊的混元、華為的盤古等是大模型領域的代表作品。這些公司擁有龐大的數據和計算資源,以及豐富的應用場景,可以支持大模型的開發和應用。

03
AI大模型,真的是風口嗎?
“今天的初創公司,很多叫做大模型的,包括創業者,也包括互聯網大廠我們都不 投。” ——嘉御基金創始合伙人、董事長衛哲表示嘉御基金會投有數據的具體應用,但不投大模型 。
今年以來,投資界對大模型相關公司出現了很微妙的態度:既有一些機構回避投資大模型公司,而與此同時,投資大模型的“入場券”(投資門檻)卻悄然從5000萬美元提高到了1億美元。
5月7日,AIGC創建者大會在上海舉行。線性資本創始合伙人兼CEO王淮發表了他的看法:“我們個人感覺這里面創業公司的機會相對小。”王淮表示,“歷史上創業公司能夠成功很大的原因是你‘為別人所不敢為’,或者做別人認為不會起來、不太看得重的東西,這一類的創業模式我們稱之為‘桃花源式的創業’。而大模型需要一些必須成功的要素,要有算力,要有錢;在中國,還必須要有政府支持。”
從王淮等人的介紹來看,大模型的應用前景的確是非常廣闊,但并不是所有企業和創業者都可以在這個領域取得成功,特別是中小創業公司。大模型需要大量的數據和計算資源來進行訓練和優化,需要有強大的技術團隊和豐富的應用場景來支持。對于中小企業和初創公司來說,進入大模型領域會面臨很多困難和挑戰。
究其原因,從我們前面說過的大模型的特點就可以看出來:
首先,大模型需要消耗大量的計算資源進行訓練和優化,需要有足夠的資金來支持,作為一個初創企業,就算融資到了獨角獸級別,在大模型領域10億美元這錢也根本不經燒。
其次,大模型的開發和應用需要有一個相對穩定且強大的技術團隊和管理團隊,需要大把大把很貴且很有經驗的人長期來進行調參和優化。對于創業公司,其組織和管理經驗往往不是很足,很難長期順利運行下去這樣的項目。
最后,由于大模型的應用場景非常廣泛,因此其需要有豐富的數據和場景來進行不斷滋養,作為一個沒什么用戶基礎和數據基礎的中小公司,很難訓練得出來。
因此,對于中小企業和初創公司來說,還是需要謹慎考慮直接進入大模型領域。

04
創業的機會在哪里?
在這個時代,創業公司的機會和大模型的發展非常相似,長期發展一定是技術驅動為主,但在落地的時候對需求的拆解、分析、梳理和把控,也要綜合考慮自身的實力和條件,以此來進行探索和發展。
而對于小的創業公司來說,可以考慮以下幾方面:
1、基于大模型構建行業模型
正如李彥宏先生所說:“未來所有的應用都將基于大模型來開發,每一個行業都應該有屬于自己的大模型,大模型會催生AI原生應用。未來需要用AI原生思維重構所有的產品、服務和工作流程。”
因此,中小企業可以針對不同的行業的特點和需求,在大模型的基礎上,針對某個行業進行定制化的開發。比如,醫療、金融、能源等各個行業都有自己的痛點和需求,可以利用垂類大模型的能力來解決這些問題。
2、聚焦小場景
雖然大模型在通用自然語言處理任務上表現出色,但在針對性場景中,大模型性能可能不如專業化的小模型。
舉個簡單的例子,在語音識別的時候,如果有噪聲干擾,或者比較小眾地區的方言,通用的語音識別大模型可能就束手無策了,因此,小公司可以聚焦小場景訓練小模型,針對特定的語音識別任務,如噪聲干擾、不同口音等,以此提高性能,解決用戶的具體痛點。
3、給大模型公司提供服務
“淘金“的活動風險高不說,而且還不是誰都能賺到,但是”賣水的生意“卻是幾乎恒定的穩賺不賠。未來隨著行業的井噴,大模型掘金領域的“買水買鍋鏟”等需求會愈加強烈。因此,創業公司可以不急著構建自己的大模型,轉身給大模型公司提供服務也是一個不錯的選擇,比如以下幾個方向:
數據標注:數據標注是機器學習中重要的環節,創業公司可以提供數據標注服務,幫助大模型公司訓練更好的模型。
環境部署:創業公司可以提供模型部署服務,幫助大模型公司將模型部署到生產環境中,使其能夠更好地為用戶提供服務。
監控和分析:所有大模型訓練出來之后,都是需要不斷更新和優化的,因此創業公司可以提供監控和分析服務,幫助大模型公司監測模型的性能和用戶行為,幫助大模型公司優化已經訓練好的模型,提高模型的精度和效率。
安全和隱私:未來隨著AI應用的泛化,人的信息安全和隱私問題也必會愈來愈受到重視,因此創業公司可以提供安全和隱私服務,幫助大模型公司保護用戶的數據和隱私,以便更好地遵守法律法規和保障用戶安全。
讀者福利:如果大家對大模型感興趣,這套大模型學習資料一定對你有用
對于0基礎小白入門:
如果你是零基礎小白,想快速入門大模型是可以考慮的。
一方面是學習時間相對較短,學習內容更全面更集中。
二方面是可以根據這些資料規劃好學習計劃和方向。
資源分享

大模型AGI學習包


資料目錄
- 成長路線圖&學習規劃
- 配套視頻教程
- 實戰LLM
- 人工智能比賽資料
- AI人工智能必讀書單
- 面試題合集
《人工智能\大模型入門學習大禮包》,可以掃描下方二維碼免費領取!

1.成長路線圖&學習規劃
要學習一門新的技術,作為新手一定要先學習成長路線圖,方向不對,努力白費。
對于從來沒有接觸過網絡安全的同學,我們幫你準備了詳細的學習成長路線圖&學習規劃。可以說是最科學最系統的學習路線,大家跟著這個大的方向學習準沒問題。
2.視頻教程
很多朋友都不喜歡晦澀的文字,我也為大家準備了視頻教程,其中一共有21個章節,每個章節都是當前板塊的精華濃縮。
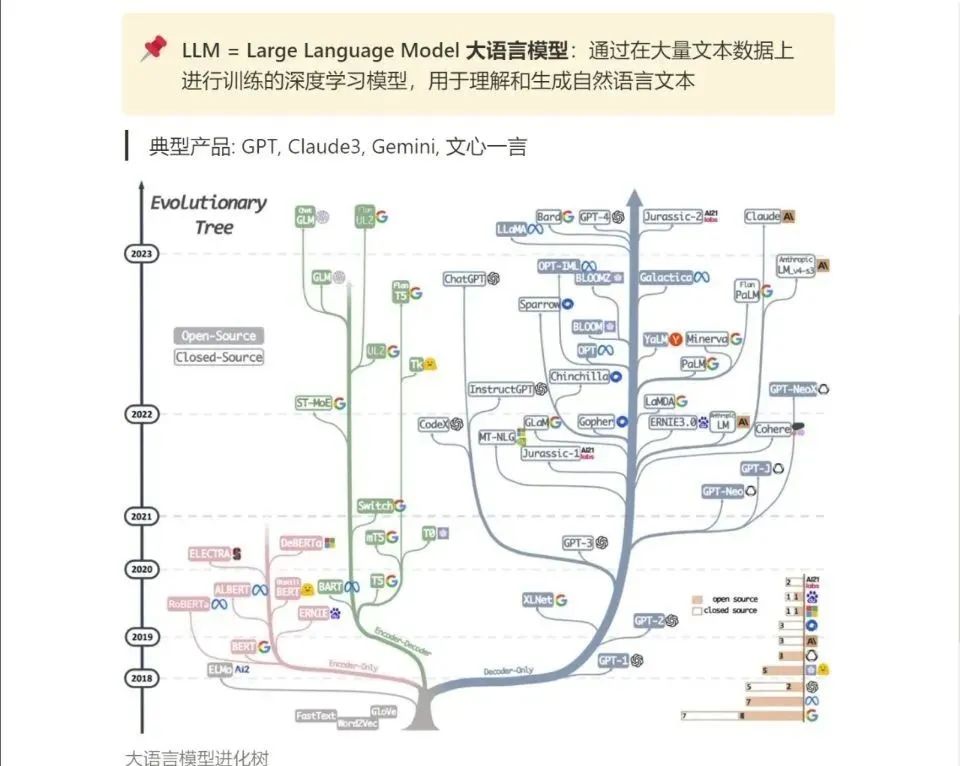
3.LLM
大家最喜歡也是最關心的LLM(大語言模型)
《人工智能\大模型入門學習大禮包》,可以掃描下方二維碼免費領取!


)












)



