深度學習基準模型Mamba
Mamba(英文直譯:眼鏡蛇)具有選擇性狀態空間的線性時間序列建模,是一種先進的狀態空間模型 (SSM),專為高效處理復雜的數據密集型序列而設計。
Mamba是一種深度學習基準模型,專為處理長序列數據而設計,尤其是在自然語言處理(NLP)和其他涉及序列建模的任務中。
以下是關于MAMBA模型的一些關鍵特性與優勢:
- 選擇性結構狀態空間模型(Selective Structural State-Space Model):MAMBA的核心在于它引入了一種選擇機制,這一機制能夠高效地決定序列中每個標記的相關性信息是否值得傳播或丟棄。這種策略通過優化信息流,顯著加快了推理速度,提高了模型的吞吐量,據稱相比標準的Transformer模型,其吞吐率提高了五倍。
- 全局感受野與動態加權:MAMBA通過其獨特的設計,能夠全局地感知序列信息,并依據序列上下文動態地調整權重。這不僅緩解了傳統卷積神經網絡(CNN)在長序列建模中可能遇到的限制,還提供了與Transformer模型相媲美的高級序列建模能力,但同時在資源消耗和計算效率方面表現更優。
- 基于上下文的推理能力增強:MAMBA通過將模型參數設計為輸入上下文的函數,增強了SSM(Structured State Space Models,如S4模型中所用)的上下文推理能力。這樣的設計允許模型更加靈活地根據輸入調整其行為,從而提高了模型的適應性和表達能力。
- 簡化特征工程:與深度學習的一般原則相符,MAMBA也強調了自動特征學習的重要性,即模型能夠直接從原始數據中學習到有用的特征表示,減少了手動特征工程的需求。這使得MAMBA不僅在理論上具有吸引力,而且在實踐中易于應用到多種序列數據相關的任務中。
- 應用案例:雖然具體的應用案例細節未在摘要信息中明確列出,但提及了“U-Mamba”作為相關模型應用的一個實例,這暗示了MAMBA框架在實際任務中的潛力和靈活性,可能涵蓋了諸如文本生成、機器翻譯、語音識別、時間序列預測等多個領域。
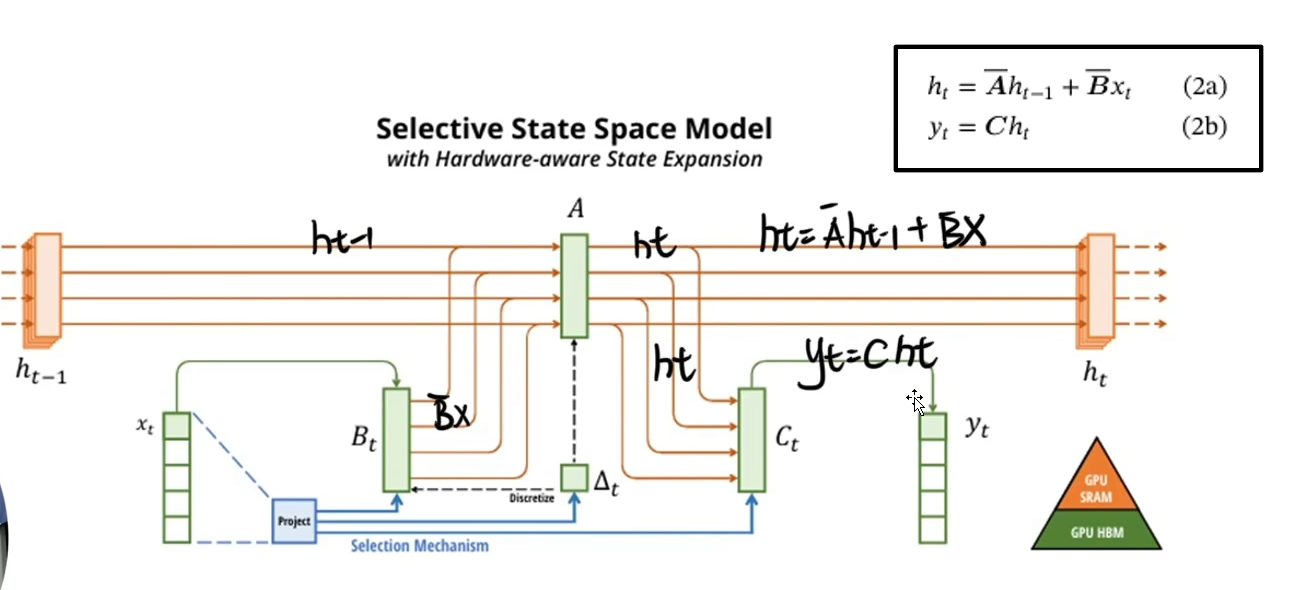
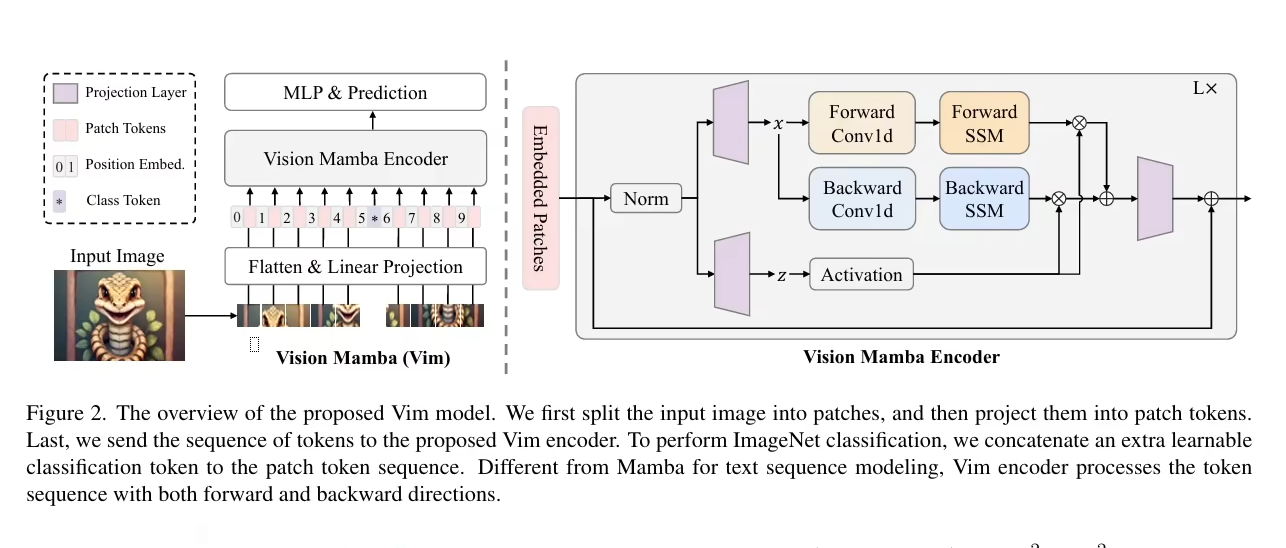
綜上所述,MAMBA模型以其創新的選擇性結構和高效的信息處理機制,為序列建模任務提供了一個有競爭力的解決方案,旨在克服現有模型在處理長序列數據時面臨的挑戰,同時推動深度學習技術在序列分析領域的進步。
了解更多知識請戳下:
@Author:懶羊羊

(優化版2))
:如何防止一個賬號多個地方登陸)


)


 ,是否有其他進程正占用它?)







——死鎖)


