目錄
摘要
Abstract
文獻閱讀:應用于地表水總磷濃度預測的可解釋CEEMDAN-FE-LSTM-Transformer混合模型
一、現有問題
二、提出方法
三、方法論
1、CEEMDAN(帶自適應噪聲的完全包絡經驗模式分解)
2、FE(模糊熵 )
3、 LSTM-Transformer
4、SHAP(特征選擇與解釋)
四、所提出的方法(CF-LT模型)
五、研究實驗
1、數據集
2、評估指標
3、實驗過程
4、實驗結果
六、代碼實現
總結
摘要
本周閱讀的文獻《Interpretable CEEMDAN-FE-LSTM-Transformer Hybrid Model for Predicting Total Phosphorus Concentrations in Surface Water》提出了一種用于預測地表水中總磷(TP)的濃度預測模型CF-LT,該模型融合了完全集成經驗模態分解帶自適應噪聲(CEEMDAN)、模糊熵(FE)、長短期記憶(LSTM)網絡與Transformer架構。首先利用CEEMDAN-FE對原始數據集進行預處理,通過將特征分解為多個固有模態函數(IMFs),并基于模糊熵值重組為高頻、中頻、低頻和趨勢成分,以反映數據的不同方面。其次,模型的LSTM部分與Transformer相結合,通過在編碼器和解碼器中嵌入Transformer的位置編碼,增強了對輸入數據時間序列依賴性的捕捉能力。CF-LT模型不僅提升了總磷濃度預測的精度,還通過SHAP方法提供了預測結果的可解釋性,為理解影響地表水總磷濃度變化的主要驅動因素提供了科學依據,對水體富營養化管理和生態健康評估具有重要價值。
Abstract
The literature "Interpretable CEEMDAN-FE-LSTM Transformer Hybrid Model for Predicting Total Phosphorus Concentrations in Surface Water" read this week?proposes a concentration prediction model CF-LT for predicting total phosphorus (TP) in surface water. This model integrates fully integrated empirical mode decomposition with adaptive noise (CEEMDAN), fuzzy entropy (FE), long short-term memory (LSTM) network, and Transformer architecture. Firstly, CEEMDAN-FE is used to preprocess the original dataset by decomposing features into multiple intrinsic mode functions (IMFs) and recombining them into high-frequency, intermediate frequency, low-frequency, and trend components based on fuzzy entropy values to reflect different aspects of the data. Secondly, the LSTM part of the model is combined with the Transformer, which enhances the ability to capture the temporal dependencies of input data by embedding the Transformer's position encoding in the encoder and decoder. The CF-LT model not only improves the accuracy of predicting total phosphorus concentration, but also provides interpretability of prediction results through the SHAP method, providing scientific basis for understanding the main driving factors affecting changes in total phosphorus concentration in surface water. It has important value for water eutrophication management and ecological health assessment.
文獻閱讀:應用于地表水總磷濃度預測的可解釋CEEMDAN-FE-LSTM-Transformer混合模型Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water https://doi.org/10.1016/j.jhydrol.2024.130609
https://doi.org/10.1016/j.jhydrol.2024.130609
PDF:Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water (sciencedirectassets.com)
一、現有問題
在當前環境科學研究中,準確預測地表水中總磷(Total Phosphorus, TP)濃度面臨著嚴峻挑戰,這主要歸因于磷的生物地球化學循環機制復雜性。湖泊等淡水系統中的磷輸入量增加導致嚴重的富營養化問題,而傳統機器學習模型在處理高維數據時易出現過擬合或欠擬合問題,且難以建立長期數據依賴關系以進行長期預測,限制了其預測效率與準確性。此外,這些“黑箱”模型在工程應用上缺乏透明度,限制了實際操作中的信任度和可解釋性。
二、提出方法
提出了一種創新的混合模型——CEEMDAN-FE-LSTM-Transformer(CF-LT)模型,該模型結合了多種先進技術,包括完全集成經驗模態分解自適應噪聲、模糊熵、長短時記憶網絡,以及Transformer架構。數據分頻重構的引入有效地解決了以前的機器學習模型在面對高維數據時遇到的過度擬合和欠擬合問題,而注意力機制克服了這些模型在進行長期預測時無法建立數據之間的長期依賴關系的問題,目的在于提高預測總磷濃度的精確度與可解釋性。
三、方法論
1、CEEMDAN(完全自適應噪聲集合經驗模態分解)
作為一種先進的時間序列分析方法,CEEMDAN通過在經驗模態分解(EMD)過程中加入自適應噪聲,有效減少了傳統EMD中存在的模式混疊問題。它能將原始信號分解為一系列固有模態函數(IMFs),每個IMF代表信號的不同時間尺度特征,從而使得復雜信號的分析更加直觀和準確。在本研究中,CEEMDAN用于處理來自泰湖三個監測站的每日水質數據,將總磷濃度與其他水質參數如水溫、pH值、溶解氧等分離成不同頻帶的信號,為后續的特征重組和模型訓練打下基礎。

2、FE(模糊熵 )
此方法被用來評估時間序列的不確定性和復雜度,通過計算相鄰數據點間相似度來反映時間序列的規律性。在CEEMDAN分解后,基于FE的結果對IMFs進行分類,將其分為高頻、中頻、低頻和趨勢成分,即IMFH、IMFM、IMFL和IMFT,這一步驟稱為“分頻重構”。這種重組方式不僅降低了數據的維度,還增強了數據的規律性,有助于模型學習關鍵特征。
3、 LSTM-Transformer
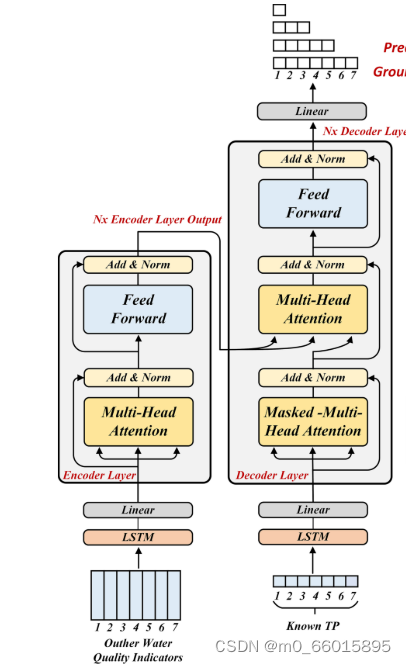
LSTM能夠選擇性地遺忘舊信息、存儲新信息,并決定如何更新隱藏狀態,特別適合處理如時間序列數據這類需要記住歷史信息的任務。相較于傳統的循環神經網絡,Transformer通過自注意力(Self-Attention)機制,實現了序列數據中所有元素的相互依賴關系的并行計算,顯著提高了模型處理長序列數據的能力和效率。它由編碼器和解碼器組成,編碼器通過多頭自注意力層捕捉輸入序列的全局依賴,而解碼器則在編碼器輸出的基礎上預測序列的下一個元素。彌補了LSTM在處理長序列時的不足。模型中的編碼器和解碼器結構包含多頭自注意力層和前饋網絡,通過位置編碼注入序列順序信息。多頭注意力的結構如下圖所示:

?
其中K和V相同。當給定Q、K和V的相同組合時,模型應該學習不同的信息,例如捕獲不同的子空間表示(短期和長期依賴)。多頭注意力層使用h組線性投影變換Q、K和V。轉換后的Q、K和V的h個集合是并行計算的。最終,這些h個注意力值的輸出被組合,并且結果由另一線性投影生成。為了避免在解碼過程中將未來知識泄漏到當前預測時間點,解碼器層使用掩蔽多頭注意力。
LSTM-Transformer模型,即在編碼器和解碼器中,LSTM的隱藏層被Transformer位置編碼取代,以建立輸入數據之間的時間依賴關系。
?
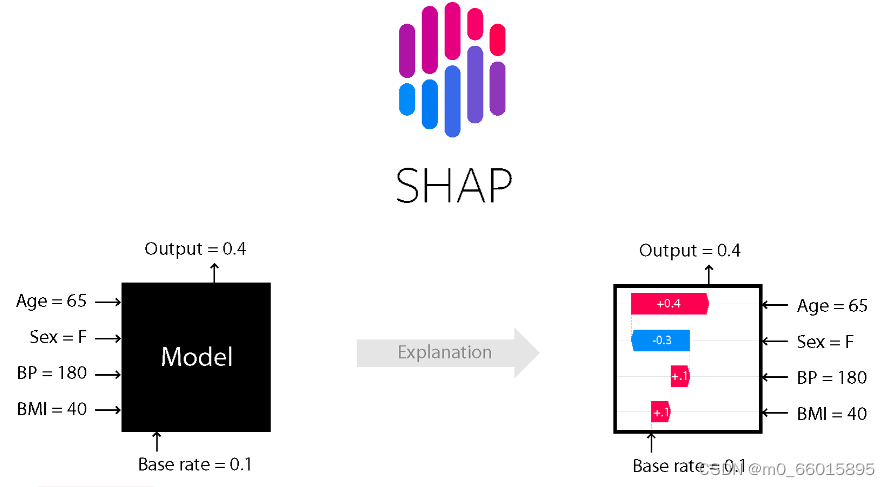
4、SHAP(特征選擇與解釋)
為了提高模型的可解釋性,研究采用了Shapley Additive Explanations方法。SHAP基于博弈論的Shapley值概念,為每個特征分配一個貢獻值,表明其對模型預測結果的影響程度。這種方法能夠具體展示哪些輸入特征對最終預測結果起到了決定性作用。SHAP value最大的優勢是SHAP能對于反映出每一個樣本中的特征的影響力,而且還表現出影響的正負性。
?
當我們進行模型的 SHAP 事后解釋時,需要明確標記已知數據集(設有 M 個特征變量,n 個樣本),原始模型 f,以及原始模型 f 在數據集上的所有預測值。貢獻值計算:

?
四、所提出的方法(CF-LT模型)
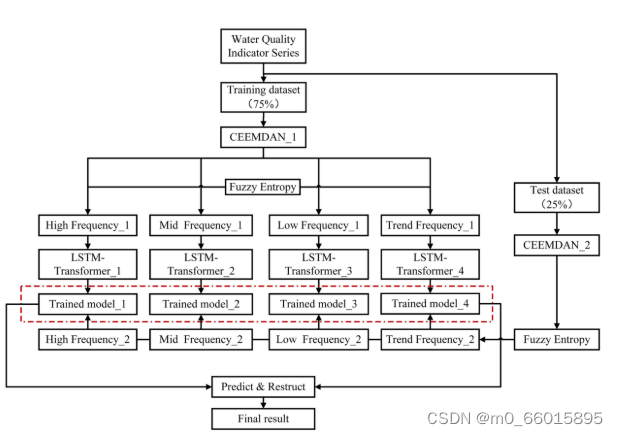
CF-LT模型的構建結合了上述技術的優點,形成了一個多層次、多維度的數據處理與預測框架。首先,利用CEEMDAN對原始數據進行預處理,將復雜的高維數據分解為不同頻率的IMFs及趨勢項,再利用FE對這些IMFs進行分類重組,降低維度同時保留關鍵信息。其次,將重構后的特征輸入到LSTM-Transformer混合架構中,其中LSTM層捕獲短期時間依賴,而Transformer通過自注意力機制強化了長期依賴的學習能力。模型輸入包括水溫、pH值、溶解氧、化學需氧量、電導率、濁度、氨氮和總氮等多個水質參數。
- 模型輸入包含兩個特征輸入。編碼器層包含水溫(WT),pH值(PH),溶解氧(DO),化學需氧量(COD),電導率(EC),濁度(TU),銨(NH3-N)和總氮(TN)的數據,解碼器層包含第一預測時間點之前七天的TP時間序列。
- 在通過LSTM和線性層之后,兩個特征數據集分別被發送到編碼器層和解碼器層。
- 兩個子層組成編碼器層。多頭注意力層計算輸入特征的注意力矩陣,然后前饋層改變數據維度。最后,數據被輸入到下一個編碼器或解碼器層。
- 三個子層構成解碼器層。在掩蔽多頭注意力層已經計算輸入特征的注意力矩陣之后,多頭注意力層從編碼器層的輸出建立注意力連接。前饋層將其傳遞到下一個解碼器層或線性層以獲得最終的模型輸出。?
- 最終,在訓練數據集上確定每個頻率的最佳模型,并用于從測試數據集獲得預測。將所有頻率的預測結果相加,以確保TP濃度的最佳預測。
五、研究實驗
1、數據集
本研究的數據集來源于中國江蘇省環境監測中心提供的泰湖流域三個國家水質監測站——姚巷橋、直湖港和觀渡橋站的水質量監測數據。數據涵蓋了從2015年1月1日至2020年12月31日的每日觀測記錄,涉及九個水質指標:水溫(WT)、pH值、溶解氧(DO)、化學需氧量(COD)、電導率(EC)、濁度(TU)、氨氮(NH3-N)、總氮(TN)和總磷(TP)。
2、評估指標
模型的性能評估采用了幾項關鍵指標:決定系數(R2),均方誤差(MSE),以及平均絕對百分比誤差(MAPE)。R2衡量模型預測值與實際值的擬合程度,接近1表示模型預測能力強;MSE衡量預測誤差的平方和,值越小說明預測誤差越小;MAPE則從百分比角度反映預測誤差的大小,值越低意味著預測越準確。
 ?
?
3、實驗過程
實驗過程包括數據預處理、模型訓練和測試。建立了一個完整的實驗程序,以評估所提出的模型在不同的數據集和預測時間窗口的性能。首先,數據經過CEEMDAN-FE方法進行預處理,通過添加自適應噪聲的完全集成經驗模態分解去除信息干擾,提取多尺度信息,并利用模糊熵降低子信號的數量。接著,將處理后的數據按75%和25%的比例分為訓練集和測試集。訓練階段,將預處理的訓練數據集輸入到LSTM-Transformer模型。使用反向傳播和Adam優化器更新模型權重,并采用網格搜索來識別LSTMTransformer模塊的最佳超參數,確保模型在不同預測時間窗口(7天、5天、3天、1天)下的性能最佳。
4、實驗結果
模型性能比較
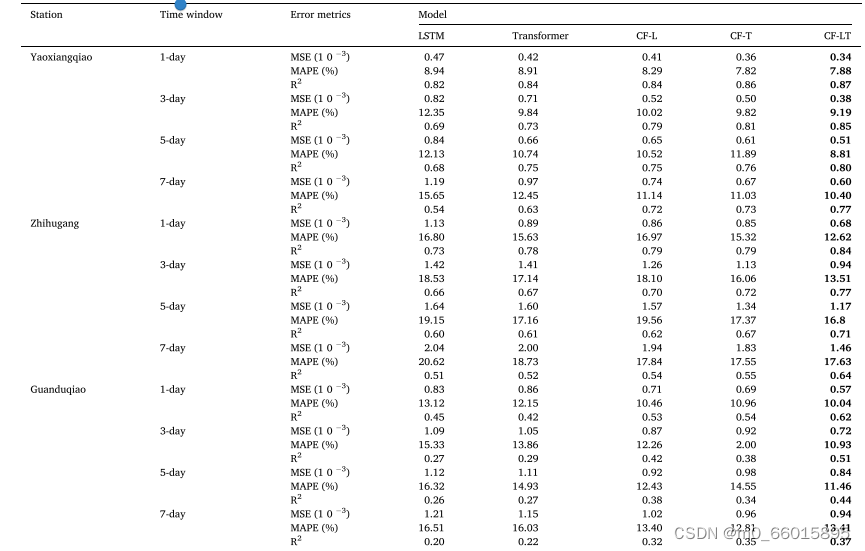
將最佳訓練模型應用于測試數據集,表總結了CF-LT、LSTM、Transformer、CF-L和CF-T模型在不同站點和不同預測時間窗下給出的TP濃度預測。所提出的CF-LT模型給出了所有三個評估指標的最佳結果。就R2而言,CF-LT模型的范圍為0.37至0.87,而次佳的CF-L和CF-T模型分別為0.32-0.84和0.35-0.86。這表明,將LSTM的長期記憶與Transformer的注意力機制相結合,可以提高預測精度。將最差的LSTM和Transformer模型與CF-L和CF-T模型進行比較,MAPE的范圍從8.94%-20.62%(LSTM)和8.91%-18.73%(Transformer)變為8.29%-19.56%(CF-L)和7.82%-17.55%(CF-T)。這些結果表明,數據分解和分頻建模通過捕獲更多隱藏在原始數據中的信息來顯著提高預測準確性。
 ?
?
影響TP濃度預測的因素
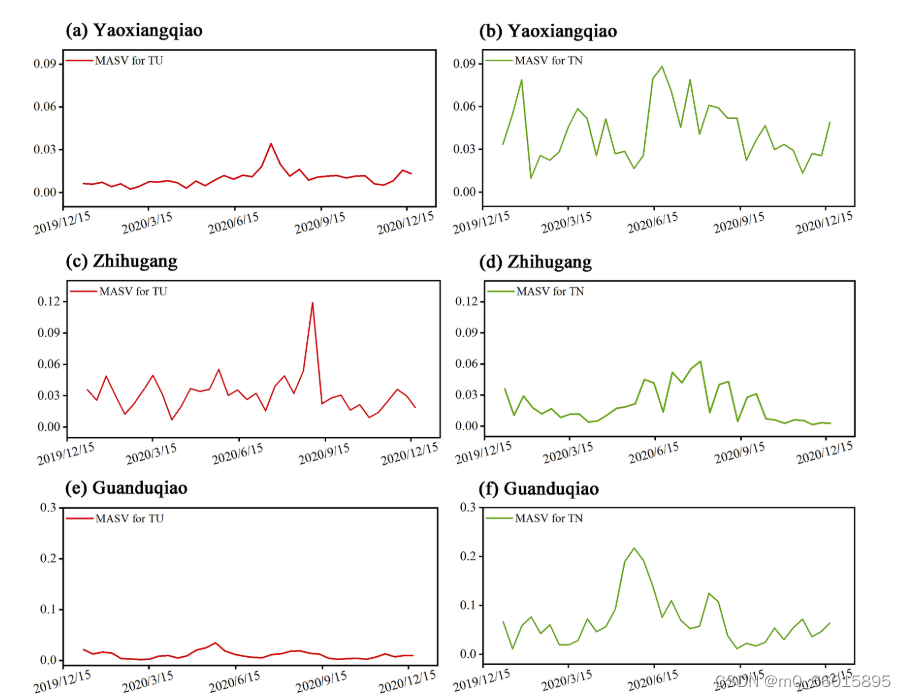
采用平均絕對SHAP值(MASV)量化輸入特征(WT、PH、DO、COD、EC、TU、TN、NH3-N、TP)對TP預測結果的貢獻程度,MASV越大,對模型預測結果的影響越大。研究表明,除了過去的TP濃度序列本身,總氮(TN)和濁度(TU)是影響TP預測的兩個主要因素。這表明,TP的變化不僅受歷史濃度的直接影響,還與非點源污染排放及水體中氮磷比相關聯的藻類生長動態緊密相關。特別是,TN與TP之間的顯著相關性,強調了兩者在湖泊營養鹽循環中的耦合效應,突顯了非點源氮輸入對磷濃度預測的重要性。
 ?
?
TP濃度預測中TU和TN貢獻的動態演變
在不同時間窗口內,TU和TN對TP濃度預測的貢獻呈現出動態變化,尤其在雨季更為顯著。通過分析2020年全年在姚巷橋、直湖港和觀渡橋三個監測站的數據發現,TU和TN的平均絕對SHAP值(MASV)在濕季達到高峰,暗示了非點源污染在此期間的增強。在姚巷橋站,盡管存在特定平季時段TN也有較高MASV值,這可能歸因于該地區點源污染的輸入。相比之下,觀渡橋站的TN貢獻度更高,這與該區域周圍耕地較多,而非林地或城市土地占主導的其他兩站不同,導致非點源污染類型和主要貢獻因子存在差異。這些發現表明,CF-LT模型不僅能有效預測TP濃度,還能揭示環境條件變化下TP響應機制的動態,為理解和管理湖泊富營養化提供寶貴洞見。
 ?
?
六、代碼實現
CEEMDAN和FE數據預處理
def ceemdan_fe_preprocessing(data):# CEEMDAN分解imfs, residue = ceemdan(data, **ceemdan_params)# 計算各個IMF的模糊熵fe_values = []for imf in imfs:fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy為計算模糊熵的函數# 根據FE值重組IMFsimfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)# 應用到數據上
preprocessed_data = ceemdan_fe_preprocessing(original_data)構建LSTM-Transformer混合模型????????
def get_positional_encoding(max_len, d_model):pe = np.zeros((max_len, d_model))position = np.arange(0, max_len).reshape(-1, 1)div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))pe[:, 0::2] = np.sin(position * div_term)pe[:, 1::2] = np.cos(position * div_term)return pedef transformer_encoder(inputs, d_model, num_heads, ff_dim):x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)x = LayerNormalization()(Add()([inputs, x]))x = Dense(ff_dim, activation='relu')(x)x = Dense(d_model)(x)x = LayerNormalization()(Add()([inputs, x]))return xdef transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):# 注意力機制,包括自注意力和編碼器-解碼器注意力# 這里簡化了多頭注意力和殘差連接的具體實現return decoder_outputinput_features = Input(shape=(input_shape)) # 假定input_shape為特征維度
lstm_out = LSTM(lstm_units)(input_features) # LSTM層# 假設我們已經得到了位置編碼向量
pos_encodings = get_positional_encoding(max_seq_length, d_model)# 將LSTM輸出與位置編碼結合,然后送入Transformer
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)# 解碼器部分可以類似實現
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)model.compile(optimizer=Adam(learning_rate), loss='mse')總結
研究開發了一種可解釋的CEEMDAN-FE-LSTM-Transformer混合模型,針對地表水中總磷濃度預測,該模型通過先進的數據預處理技術和深度學習模型的融合,顯著提高了預測精度,并通過SHAP提供了清晰的特征解釋。實驗結果證實了模型的有效性,尤其是對關鍵環境因素的識別,為水體富營養化管理和污染控制提供了有力的工具。未來的研究方向可以考慮遷移學習和物理-深度學習模型的結合,進一步提高模型的泛化能力和解釋力。


)













——搭建開發環境)


