目錄
- 1. nn.Module
- 2. nn.Sequential容器
- 3. 網絡參數parameters
- 4. Modules內部管理
- 5. checkpoint
- 6. train/test狀態切換
- 6. 實現自己的網絡層
- 6.1 實現打平操作
- 6.2 實現自己的線性層
- 7. 代碼
1. nn.Module
是所有nn.類的父類,其中包括nn.Linear nn.BatchNorm2d nn.Conv2d nn.ReLU nn.Sigmoid等等
2. nn.Sequential容器
如下圖,定義一個net網絡,將所有繼承自nn.Module的子類定義的網絡層加入到了nn.Sequential容器中,與一層一層的單獨調用模塊組成序列相比,nn.Sequential() 可以允許將整個容器視為單個模塊(即相當于把多個模塊封裝成一個模塊),forward()方法接收輸入之后,nn.Sequential()按照內部模塊的順序自動依次計算并輸出結果。因此可以利用nn.Sequential()搭建模型架構。

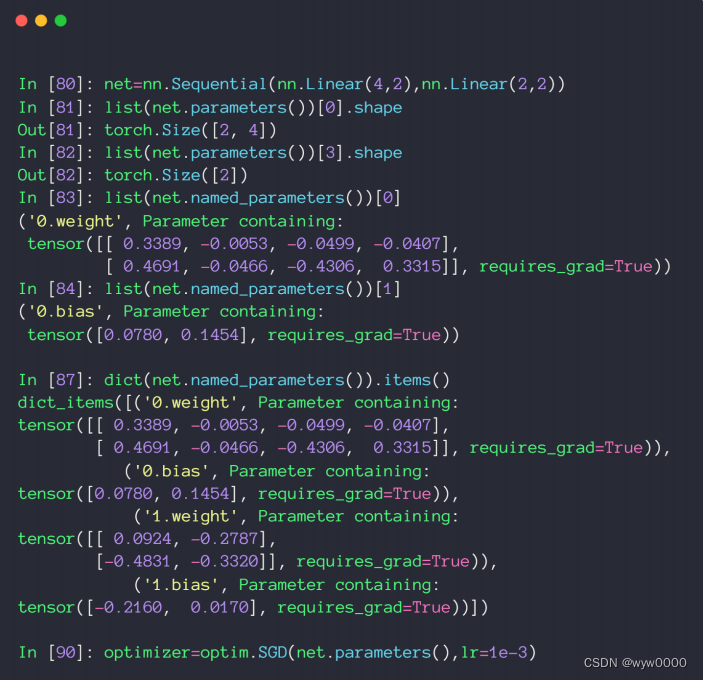
3. 網絡參數parameters
如下圖,通過net.parameters()可以獲取到net的參數,轉換成list后,通過index訪問第幾個參數,比如:圖中的list(net.named_parameters())[0]就可以獲取到網絡的第一個參數,也就是網絡第一層的w參數。
通過list(net.named_parameters()).items()獲取到所有網絡層,從獲取結果可以看到,每一層都被pytorch命名了,比如:‘0.weight’,‘0.bias’,即第一層網絡的weight和bias.
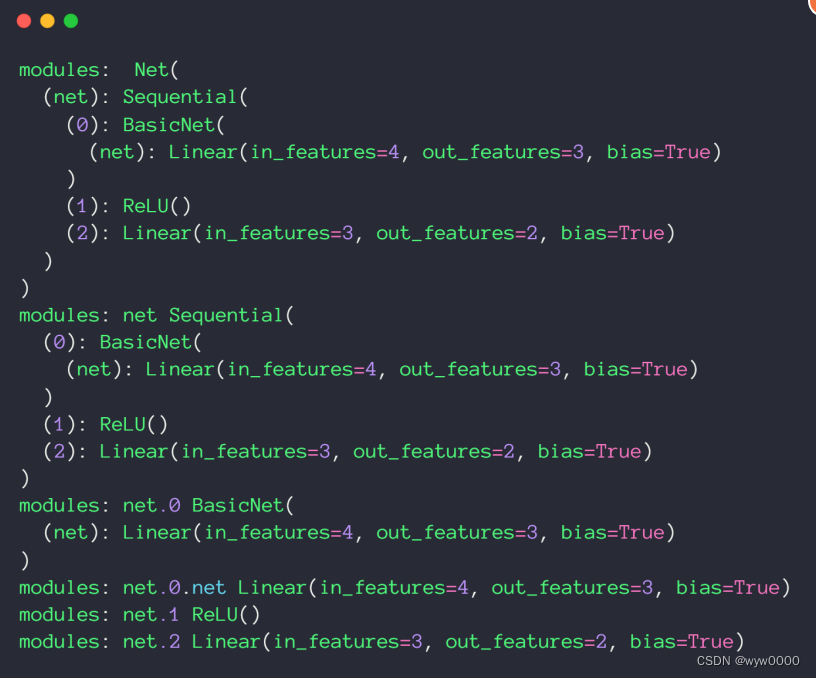
4. Modules內部管理
與根節點相連的直系親屬叫children,其他再與children連接的節點都叫modules
如下圖,nn.Sequential是Net的children,其他的是modules,包括nn.ReLU、nn.Linear、BasicNet

從下面這張截圖可以看出,Net本身和Children也都是modules
5. checkpoint
為了防止train過程意外停止,需從頭train的問題,train過程需要定期保持checkpoint,而一旦出現train意外停止,就可以從最后一次checkpoint接著訓練。
torch.save保存checkpoint
torch.load_state_dict(torch.load(‘chpt.md’))用于load checkpoint

6. train/test狀態切換
所有nn.類都繼承自nn.Module,因此在切換train和test狀態時,只需要調用一次net.train()或net.eval即可,而不需要那些train和test(dropout)行為不一致的類每個單獨去切換.

6. 實現自己的網絡層
6.1 實現打平操作
全連接層層需要打平輸入,打平操作通過.view方法實現,由于Flatten繼承自nn.Module,因此可以直接放到nn.Sequential中。

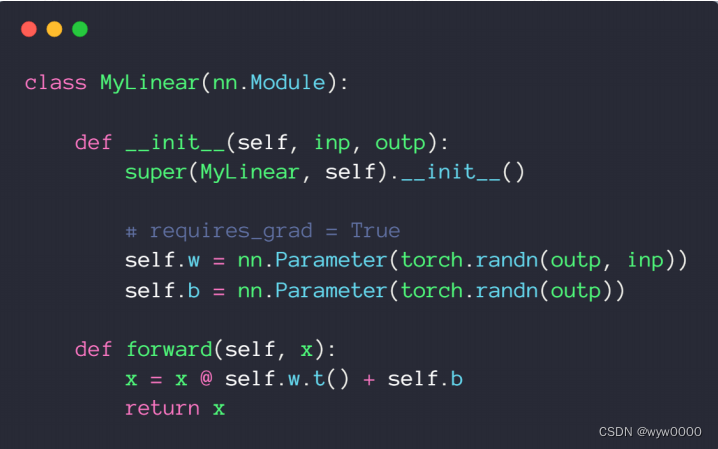
6.2 實現自己的線性層
通過net.parameters()可以將網絡參數加到優化器中。

troch.tensor是不會自動加到nn.parameters中,因此需要使用nn.Parameter將tensor加到nn.parameters,從而才能加到SGD等優化器中。
7. 代碼
import torch
from torch import nn
from torch import optimclass MyLinear(nn.Module):def __init__(self, inp, outp):super(MyLinear, self).__init__()# requires_grad = Trueself.w = nn.Parameter(torch.randn(outp, inp))self.b = nn.Parameter(torch.randn(outp))def forward(self, x):x = x @ self.w.t() + self.breturn xclass Flatten(nn.Module):def __init__(self):super(Flatten, self).__init__()def forward(self, input):return input.view(input.size(0), -1)class TestNet(nn.Module):def __init__(self):super(TestNet, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 16, stride=1, padding=1),nn.MaxPool2d(2, 2),Flatten(),nn.Linear(1*14*14, 10))def forward(self, x):return self.net(x)class BasicNet(nn.Module):def __init__(self):super(BasicNet, self).__init__()self.net = nn.Linear(4, 3)def forward(self, x):return self.net(x)class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.net = nn.Sequential(BasicNet(),nn.ReLU(),nn.Linear(3, 2))def forward(self, x):return self.net(x)def main():device = torch.device('cuda')net = Net()net.to(device)net.train()net.eval()# net.load_state_dict(torch.load('ckpt.mdl'))### torch.save(net.state_dict(), 'ckpt.mdl')for name, t in net.named_parameters():print('parameters:', name, t.shape)for name, m in net.named_children():print('children:', name, m)for name, m in net.named_modules():print('modules:', name, m)if __name__ == '__main__':main()








。)

及物聯網網絡協議面試題及參考答案(2萬字長文))








