1.背景
- 會不會寫makefile,從一個側面說明了一個人是否具備完成大型工程的能力
- 一個工程中的源文件不計數,其按類型、功能、模塊分別放在若干個目錄中,makefile定義了一系列的 規則來指定,哪些文件需要先編譯,哪些文件需要后編譯,哪些文件需要重新編譯,甚至于進行更復雜 的功能操作
- makefile帶來的好處就是——“自動化編譯”,一旦寫好,只需要一個make命令,整個工程完全自動編 譯,極大的提高了軟件開發的效率。
- make是一個命令工具,是一個解釋makefile中指令的命令工具,一般來說,大多數的IDE都有這個命 令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可見,makefile都成為了一 種在工程方面的編譯方法。
- make是一條命令,makefile是一個文件,兩個搭配使用,完成項目自動化構建
2.make/Makefile?
2.1.見一見make/Makefile是怎么工作的
make是一個命令,Makefile是一個文件,當前目錄下的文件
可以寫makefile也可以寫Makeile

?![]()
我們在里面寫下

第一行的意思就是mycode.c編譯成名字叫mycode的可執行程序,這個叫依賴關系
第二行是怎么編譯,這個是依賴方法
完成了以后,我們再也不用使用gcc命令來編譯了

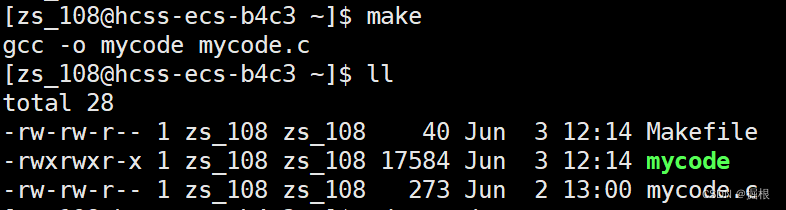
直接生成了一個可執行程序
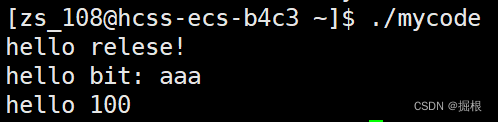
后面我們不想要可執行程序mycode了,我們直接打開Makefile
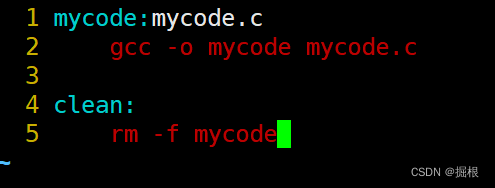

這樣子我們就刪掉了那個可執行程序

我們寫代碼就不用gcc了
我們系統自動存在make命令
它和Makefile一起配對使用的

我們現在了解make/Makefile是怎么使用的了
那么問題來了
2.2.什么是依賴關系?什么是依賴方法?
我們看個例子就明白了
- 假如你是個在校大學生,快要到月底了,這時候你可能就要打電話給你爸要生活費了。你打電話給你爸爸,說 "爸,我是你兒子。",這就是表明依賴關系。你打電話告訴你爸你是他兒子的時候,實際上你的潛臺詞就是 "我要依賴你"。
- 你給你爸打電話說:"爸我是你兒子",說完就把電話一掛,對于你爸來說會一臉懵逼 —— "這孩子今天怎么了,這是被綁架了?",你爸就不太清楚了。也就是說,你在打電話時只是表明了依賴關系,但你并沒有達到你想要做的目的(要下個月的生活費),所以正確的方法應該是:"爸,我是你兒子,我要下個月的生活費。",你表達了你是誰,并且要求給你打錢。
- 我是你兒子 —— 表明了 "依賴關系",因為依賴關系的存在,所以才能給你打錢。
- 打錢 —— 就是 "依賴方法",當你把依賴關系和依賴方法表明時,你就能達到要錢的目的。
- 依賴關系不對,依賴方法再對也沒有用,比如你的舍友給你爸打電話,說:"我是你兒子的舍友,給我打錢!",你爸絕對不會打錢的。
- 依賴方法表明了,依賴方法不正確同樣沒有用,比如你打電話給你爸:說:"我是你兒子,給我打錢我要充游戲!",你爸也不會給你打錢的!
通過上面的比喻,相信你已經知道什么是依賴關系和依賴方法了,他們必須都為真。
依賴關系和依賴方法都要為真,才能達成要錢的目的!
依賴關系:我們上面mycode的形成需要依賴于mycode.c
依賴方法:只有依賴關系可不夠,還需要指明怎么依賴
上面那個依賴關系是簡寫的,下面我們故意寫點繁瑣的?
我們把上面那個修改成下面這個更繁瑣的
我們報存,去使用它
這個好像沒有什么問題
我們看看啊,我們書寫的時候是從上往下寫的,但是它是從下面往上執行的,為什么呢?


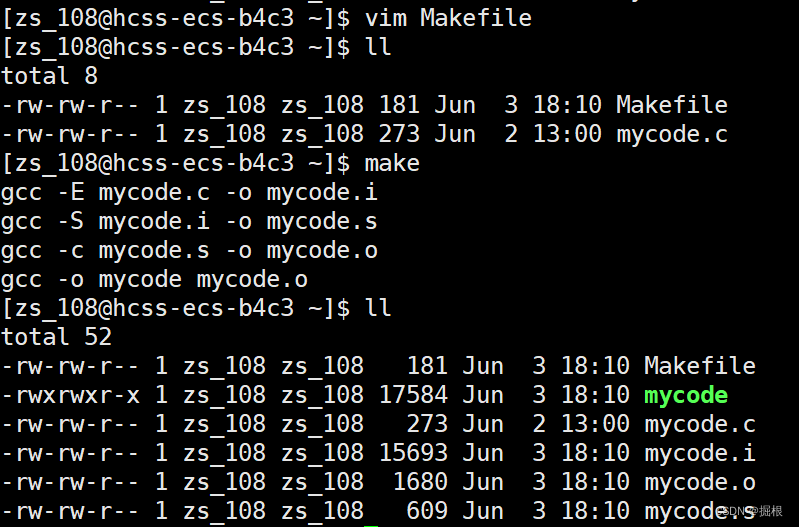
這個是因為make在掃描makefile時是從上往下的,但是當前目錄沒有提供mycode.o,所以往下先生成mycode.o,而形成mycode.o又要形成mycode.s,依次類推,所以先生成mycode.i,剛好生成mycode.i需要mycode.c,剛好當前目錄有
這個過程特別像棧
這個是makefile依賴文件的自動化推導
有人說,它既然能推導,我們要是把它變亂序還能不能推導了?
事實證明,完全沒有任何問題!!!!!
我要是故意漏掉一行會怎么樣!
結果是不能正常使用
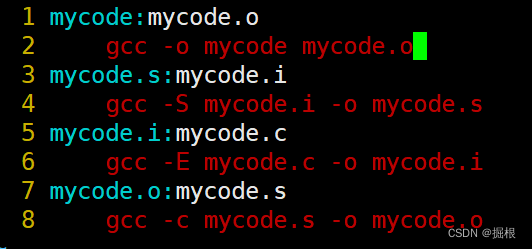
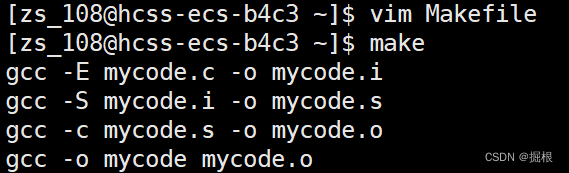

由此,我們得到一個結論:make會自動推導Makefile中的依賴結構,棧式結構
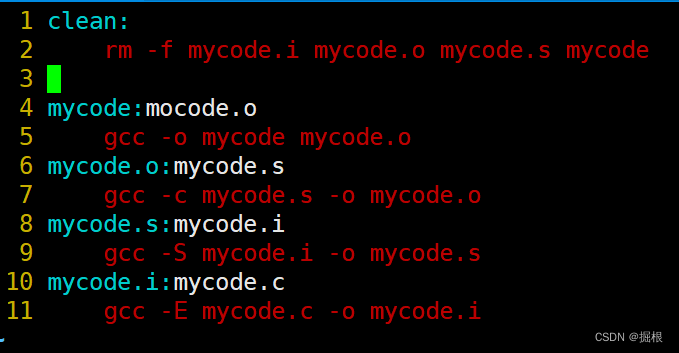
2.3.如何清理make生成的臨時文件
我們使用make生成的東西里面有很多臨時文件
比如下面的mycode.i,mycode.o,mycode.s文件
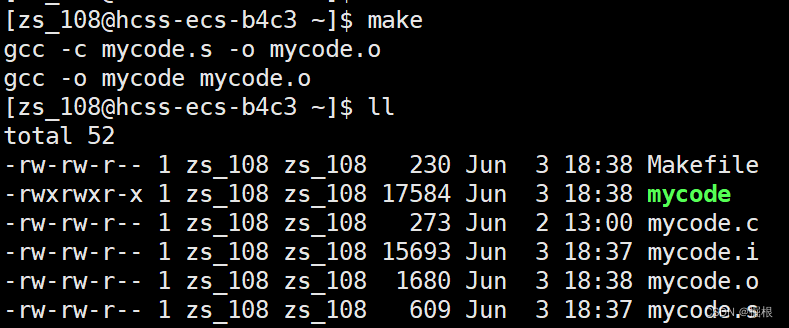
我們需要引入一個東西來清理這些臨時文件
我們打開Makefile
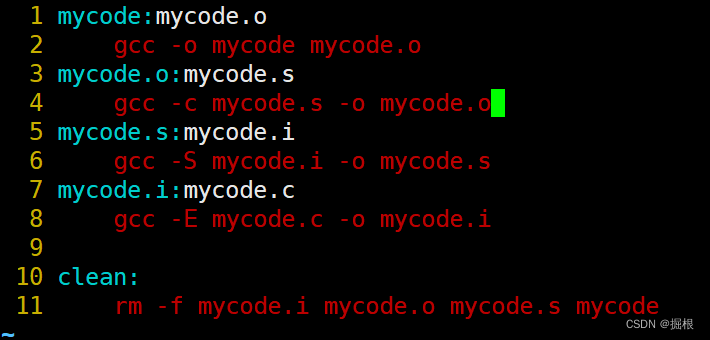
clean沒有依賴關系,只執行刪除功能?
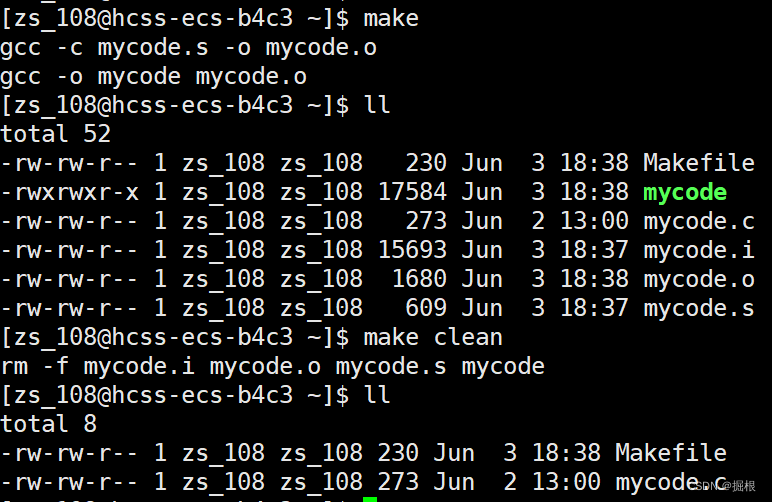
很好,全刪除了
新的問題又來了,我們看下面
我們可以使用make clean,那么是不是意味著我們可以使用make mycode ,make mycode.o,make mycode.i , make mycode .s?我們驗證一下
事實證明確實如此
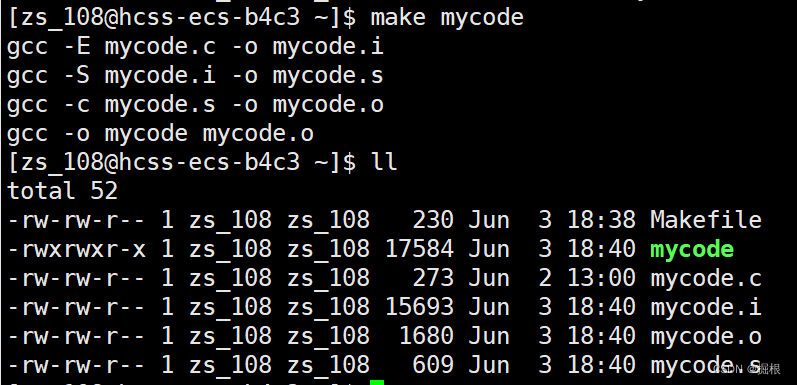
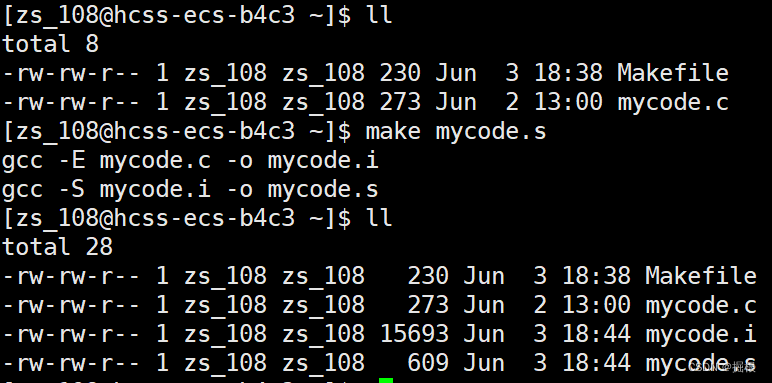
我們接著看啊,我們直接把clean放到前面
我們此時再執行make指令會有什么反應?

我靠,怎么變刪除了!!!
所以make會自頂向下查找第一個依賴關系,并執行該依賴關系的依賴方法
所以我們不要把清理工作放在最前面
2.4.為什么我們只可以make一次 ,后面make多次就不行?怎么做到的?
我們看看下面這個情況

我們make使用一次之后就不讓我編譯了
為了方便,我們把Makefile全改回來簡單版本

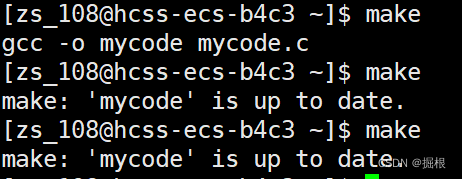
只讓我們make一次
我們將代碼修改,再make一下,發現又可以了,再make又不行了
為什么不讓我們編譯了?
因為源文件沒有更新的話,沒有必要,提高編譯效率
那它是怎么做到的?
- 先有源文件,再有可執行程序——源文件一定比可執行文件先進行修改
- 如果我們更改了源文件,歷史上曾經還有可執行,那么源文件的最近修改時間,一定比可執行程序要新!
一般而言,源文件的最近修改時間會不會和可執行程序最近修改時間是不會一樣的,除非我們去修改了設置
基于上面兩個常識,我們就能知道為什么了
我們只需比較可執行程序的最近修改時間和源文件最近修改時間,
- 如果可執行程序的修改時間比源文件的修改時間新,那么說明源文件是舊的,不需要重新編譯;
- 如果可執行程序的修改時間比源文件的修改時間舊,那么說明源文件是新的,需要重新編譯;
我們來驗證一下上面的猜想
我們先補充一下知識
linux有一條指令stat,專門用來查看文件的生成時間
對于文件有3個時間(簡稱Acm)
- Access(進入):最近被訪問時間
- Modify(改變):最近文件內容被修改時間
- Change(更改):?最近文件屬性被修改時間
?文件=文件內容+文件屬性
?在linux中,我們把文件內容改了,文件屬性也改了(大小)
我們很容易知道Access更改的頻率是非常高的,但是文件是存在在外部磁盤里,當用戶一多,更改頻率太大容易影響性能,所以Access不會每次都更改
我們去修改一下mycode.c
我們發現 全變了
?我們發現上面的Change改變了

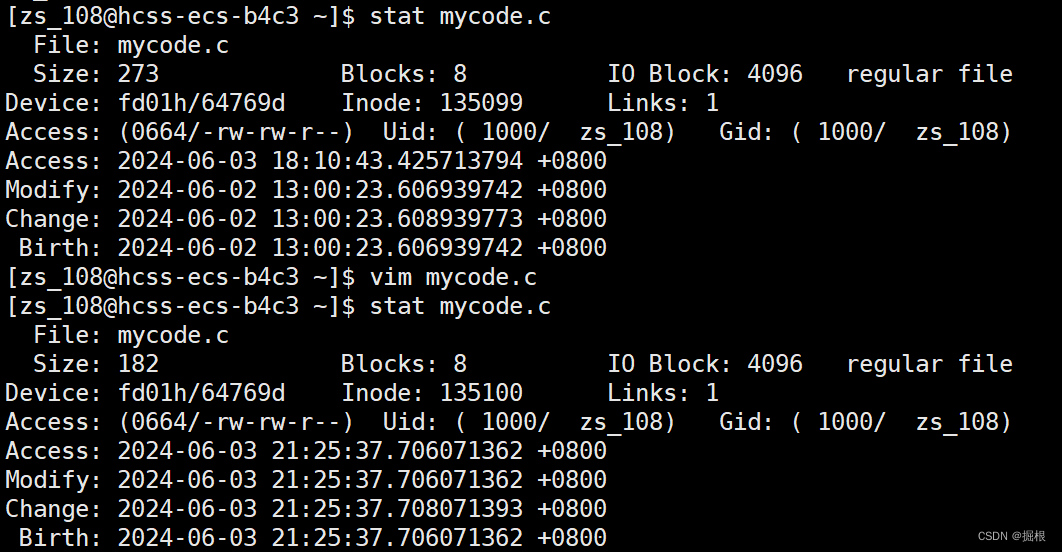
?我們回頭去驗證
我們怎么判斷可執行程序和源文件的新舊啊?
我們一般比較Modify
其實最簡單的方法就是把它們各自的時間轉換為時間戳進行對比
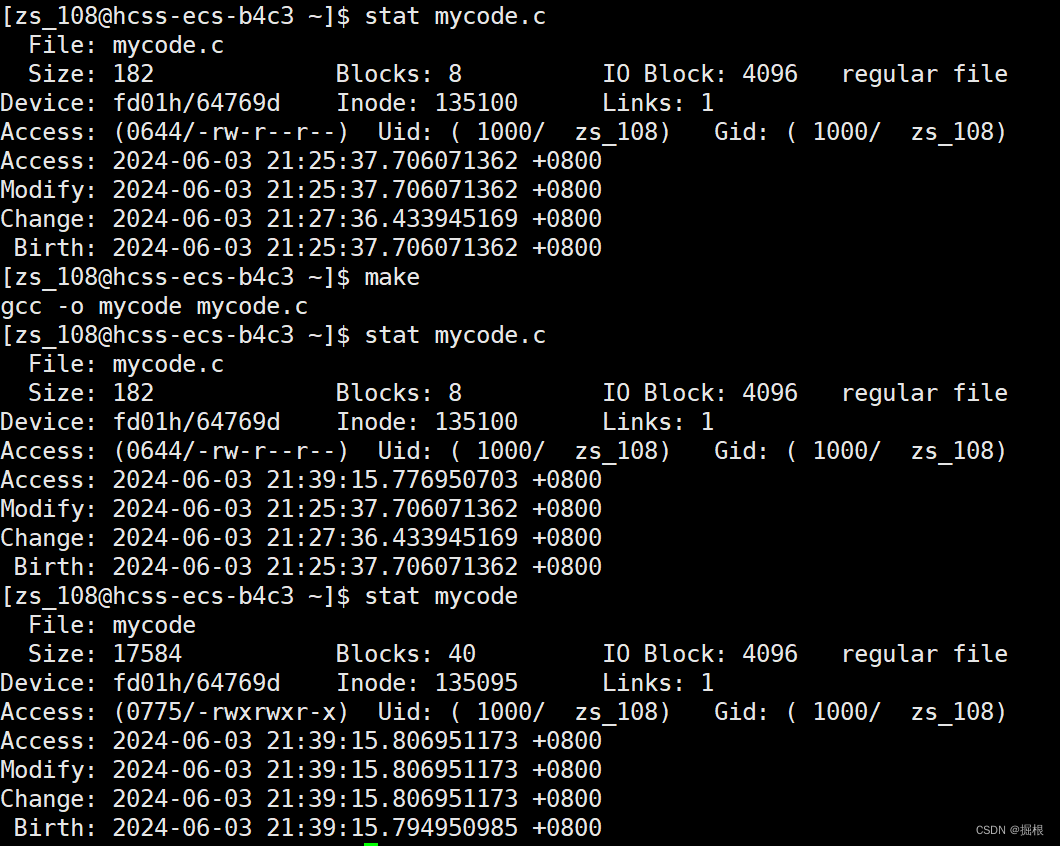
mycode.c的Access更改的原因是因為gcc編譯時讀取了mycode.c
我們比較可執行程序和源文件的Modify時間,顯然可執行程序的更新
?
這里不讓我們make了
我們直接創建一個新的mycode.c
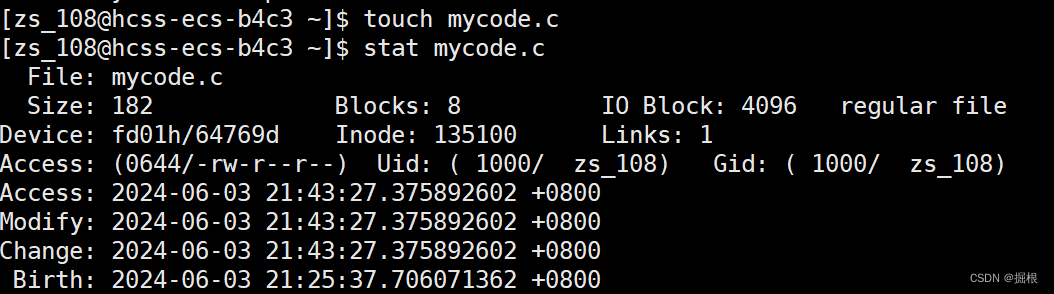
時間全更新了
這個新的mycode.c會覆蓋舊的mycode.c

這個時候啊,源文件的Modify時間比可執行程序的新,肯定可以執行make

我們看看可執行程序的Modify時間和源文件的
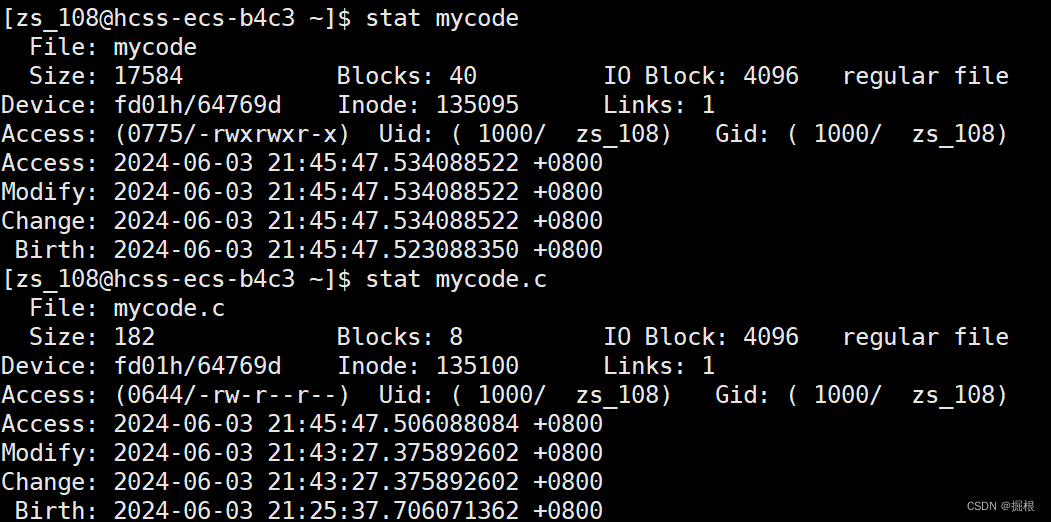
可執行程序的時間更新啊
?不能執行make

依次類推
我們得出結論:make會根據源文件和目標文件的新舊,判斷是否需要重新執行依賴關系!它不一定總是執行的
今天我就是想對應的依賴關系被執行呢?
那么就引入了新的語法
我們打開Makefile
改成下面這樣子

這樣子就能總是執行mycode的依賴關系啦
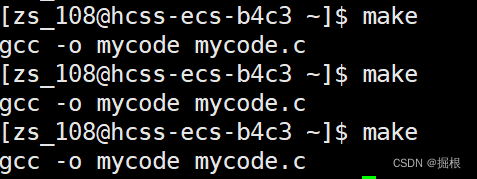
但是我們一般不會把這個語法用在這里
我們常常把這個語法用到清理工作,因為清理工作需要總是被執行
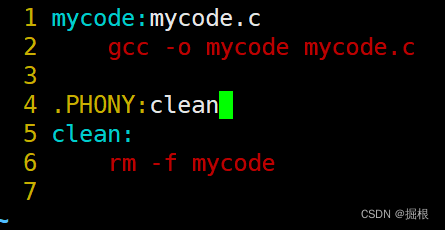
這樣子清理工作就能多次被執行了
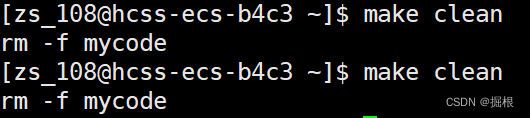
2.5.特殊符號
我們在上面的Makefile文件里面寫的是
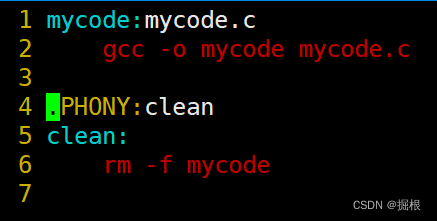
我們可以將其修改成下面這樣子

- $@代表依賴關系的目標文件,冒號的左側
- $^代表冒號的右側
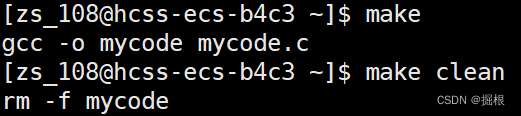
?也能正常運轉,我們發現使用make就會回顯,我們不想回顯,怎么做呢?
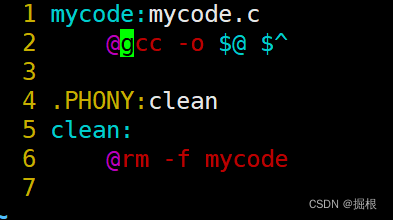
這樣子即可
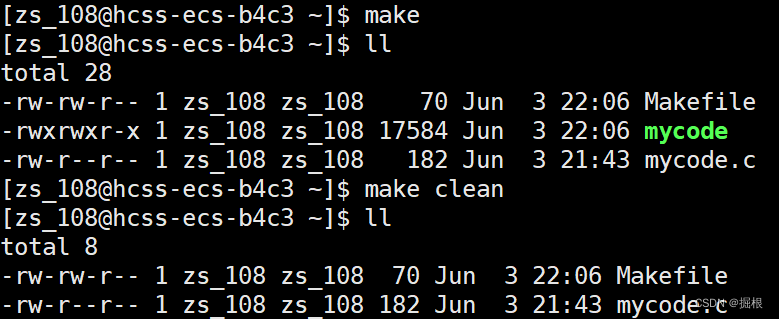
3.Linux第一個項目——進度條
制作進度條,我們需要一些儲備知識
3.1.回車換行
我們對回車換行可能有的誤解
真正的回車換行應該是下面這樣子的
- 回車(Carriage Return):在打字機時代,回車指的是將打字機的打印頭(稱為"carrier")移回到行首的操作。在計算機時代,回車通常表示將光標移動到當前行的開頭,而不會換到下一行。在ASCII字符集中,回車通常用"\r"表示。
- 換行(Line Feed)::換行是指將光標移動到下一行的操作,使得文本在縱向上向下移動一個行高。在ASCII字符集中,換行通常用"\n"表示。
- 在Unix和類Unix系統(如Linux和macOS)中:通常使用換行字符(“\n”)來表示換行。
- 在Windows系統中:,通常使用回車和換行的組合來表示換行,即"\r\n"。
?3.2.緩沖區
緩沖區(Buffer)是計算機內存中的一塊特定區域,用于臨時存儲數據。它在許多計算機系統和應用程序中發揮著重要作用,通常用于臨時存儲輸入數據、輸出數據或在內存和其他設備之間進行數據傳輸。
輸入緩沖區:用于暫時存儲從輸入設備(如鍵盤、鼠標、網絡接口等)接收到的數據,直到程序能夠處理它們。輸入緩沖區使得程序可以按需處理輸入,而不必擔心輸入數據的速度與程序處理速度不匹配的問題。輸出緩沖區:用于暫時存儲將要發送到輸出設備(如顯示器、打印機、網絡接口等)的數據,直到設備準備好接收它們。輸出緩沖區可以提高數據傳輸的效率,因為程序不必等待設備就緒就可以繼續執行。
3.2.1.緩沖區何時被清理
拿C語言舉個例子:
在C語言中,標準庫函數printf()用于將格式化的數據打印到標準輸出流(通常是終端)。但是,printf()函數并不會立即將數據顯示到終端上。相反,它會將數據寫入到輸出緩沖區中。輸出緩沖區是一個臨時存儲區域,用于存放printf()函數打印的數據,直到滿足一定條件時才將其刷新(即將數據發送到終端并顯示出來)。
這些條件包括:
- 遇到換行符 \n:當printf()函數遇到換行符時,輸出緩沖區會被自動刷新,將緩沖區中的數據輸出到終端并顯示出來。
- 緩沖區滿:當輸出緩沖區滿了,它也會被自動刷新。
- 調用fflush()函數:顯式調用fflush(stdout)函數可以強制刷新輸出緩沖區,將其中的數據輸出到終端。
- 程序結束:當程序正常終止時,所有的緩沖區都會被刷新。
3.2.2.驗證緩沖區存在
我們先寫出基本的代碼結構
processBar.h
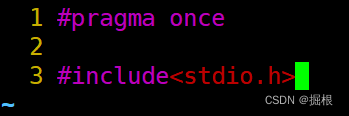
processBar.c我們暫時不寫
main.c
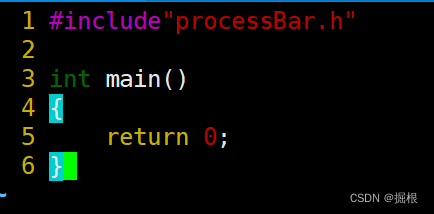
我們新建一個makefile,寫成下面這個
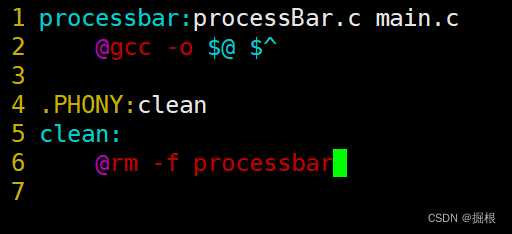
我們為什么只寫兩個源文件,不寫頭文件呢?
這個是因為頭文件在makefile的同一目錄里,我們的main.c包含了這個頭文件,make會自動尋找頭文件

沒有任何問題?
我們基于這個結構來驗證一下緩沖區的問題
我們可以查找sleep函數
我們編譯運行上面那個代碼
發現hello world直接出來了,沒有等待3ms?
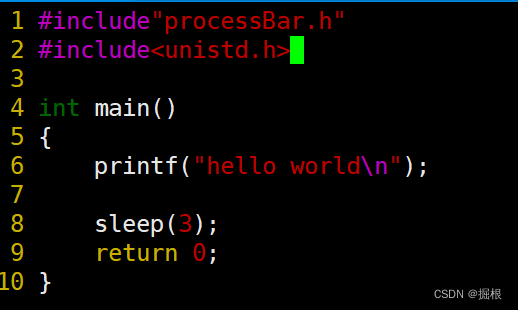
我們更新一下代碼
helloworld居然沒有先出來出來
在等待的這段時間里,helloworld是在輸出緩沖區里
后出來的helloworld



我們再更新 一下代碼
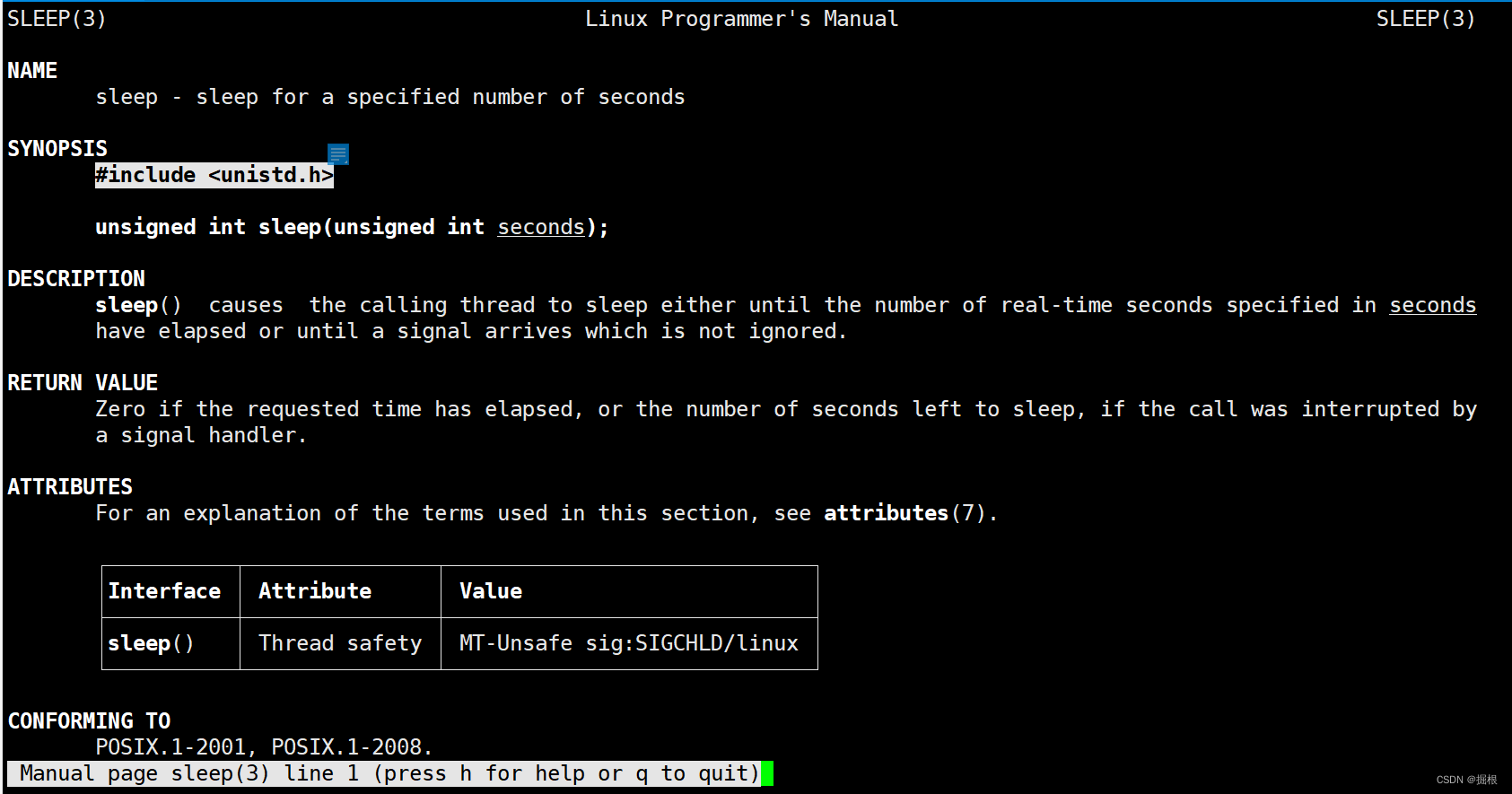
fflush函數可以去man3號手冊查
直接輸出了

3.3.代碼?
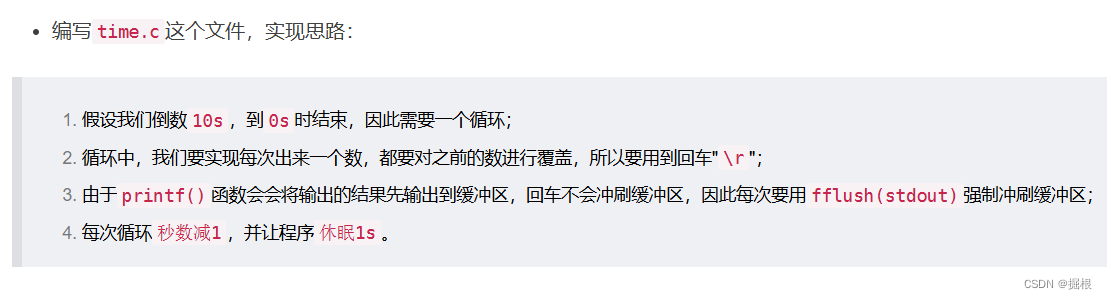
有了以上的知識儲備,咱們就可以嘗試編寫一下簡單的倒計時程序了,思路如下:
- 首先新建一個
time.c文件,然后再用我們之前講的makefile工具來實現time.c文件的自動構建:
#include <stdio.h>
#include <unistd.h>
int main()
{int cnt = 10;while(cnt >= 0){// 打印的時候每次覆蓋上一次出現的數字printf("倒計時:%2d\r",cnt);// 強制沖刷緩沖區fflush(stdout);--cnt;sleep(1);}printf("\n");return 0;
}用make命令進行編譯:?
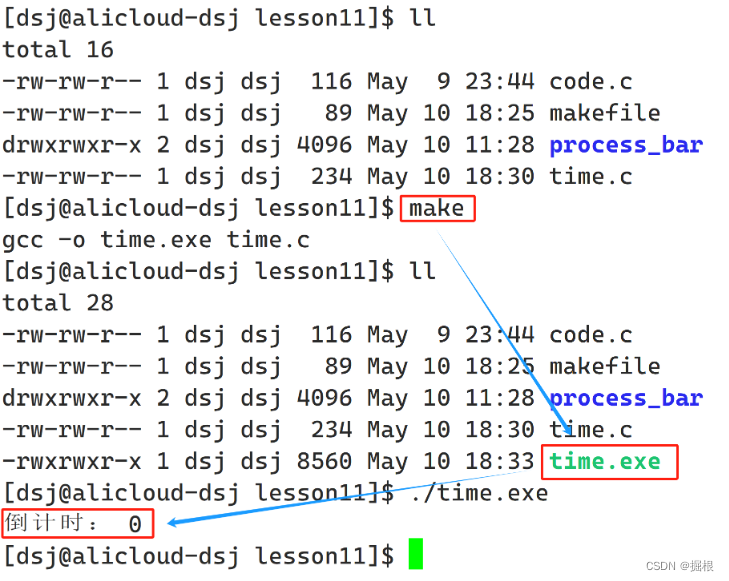
- 這里有個小拓展,如果我們要覆蓋上次的數字是4位,這次是三次(比如1000到999),可以用
%4d這個輸出形式來解決,也可以用下面這種方法:
#include <stdio.h>
#include <unistd.h>
int main()
{int cnt = 1000;int tmp = cnt;int num = 0;while (tmp){++num;tmp /= 10;}while(cnt >= 0){// 主要就是這里的變化,用最大數字的位數來做占位符printf("倒計時:%*d\r",num, cnt);fflush(stdout);--cnt;sleep(1);}printf("\n");return 0;
}總共有三個部分:
?
1. 我們要實現的進度條用#來進行加載;
2. 后面要有數據來表示現在加載的進度是多少(百分數);
3. 最后用一個動態旋轉的類?來表示程序還在繼續加載。
1. 動態加載的過程
動態加和之前的倒計時差不多,每次都要覆蓋上次出現的#,具體思路如下:
1. 定義一個字符類型數組char *str,用memset()函數進行初始化(‘\0’);2. 循環100次,每次循環都在數組中加一個#,并打印str('\r’進行覆蓋);
3. 強制沖刷緩沖區;
2. 進度加載
我們可以用每次循環的次數來當作是當前加載的進度,當然還要進行覆蓋,具體思路如下:
1. 每次循環都以當前的循環次數作為加載進度;2. 每次覆蓋上一次的進度;
3. 強制沖刷緩沖區。
4. 程序休眠(可以用usleep()函數,單位是微秒)
3. 動態旋轉
定義一個數組,并初始化為-\\/-,覆蓋的方法和之前類似,就不詳細說了。
#include "process_bar.h"
#include <memory.h>
#include <unistd.h>
#define style '#'
#define round "-\\/-"
void test()
{int i = 0;char str[100];memset(str,'\0',sizeof(str));while (i <= 100){str[i] = style;printf("[%-100s][%d%%][%c]\r",str,i,round[i % 4]);fflush(stdout);++i;usleep(10000);}printf("\n");
}?3.4.第二版本
我們正常用進度條肯定不是單獨使用的,會結合其他的場景,例如下載界面,登陸界面。
對于要下載的文件,肯定有文件大小,下載的時候網絡也有它的帶寬,所以在下載的時候,每次下載的大小都是一個帶寬,我們可以先寫一個下載的函數:
void download()
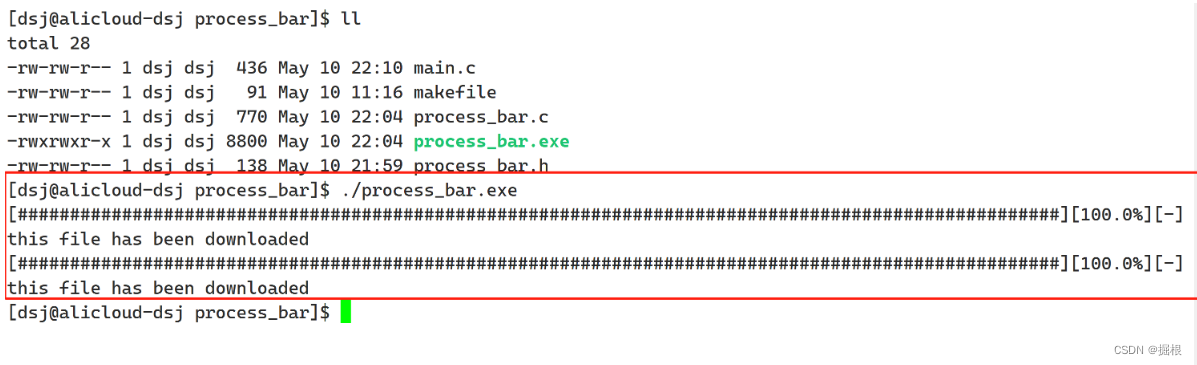
{double bandwidth = 1024 * 1024 * 1.0;double filesize = 1024 * 1024 * 10.0;double cur = 0.0;while (cur <= filesize){// 調用進度條函數test(filesize, cur);// 每次增加帶寬cur += bandwidth;usleep(20000);}printf("\n");printf("this file has been downloaded\n");
}void test(double total, double current)
{char str[101];memset(str,'\0',sizeof(str));int i = 0;// 這次的比率double rate = (current * 100) / total;// 循環次數int loop_count = (int)rate;while (i <= loop_count){str[i++] = style; }printf("[%-100s][%.1lf%%][%c]\r",str,rate,round[loop_count % 4]);fflush(stdout);
}// 頭文件 process_bar.h
#include <stdio.h>typedef void(*callback_t)(double, double);// 函數指針(回調函數)void test(double total, double current);// 函數實現文件 process_bar.c
#include "process_bar.h"
#include <memory.h>
#include <unistd.h>
#define style '#'
#define round "-\\/-"void test(double total, double current)
{char str[101];memset(str,'\0',sizeof(str));int i = 0;double rate = (current * 100) / total;int loop_count = (int)rate;while (i <= loop_count){str[i++] = style; }printf("[%-100s][%.1lf%%][%c]\r",str,rate,round[loop_count % 4]);fflush(stdout);
}// main.c 主函數和 download 函數
#include "process_bar.h"
#include <unistd.h>double bandwidth = 1024 * 1024 * 1.0;
void download(double filesize, callback_t cb)
{double cur = 0.0;while (cur <= filesize){cb(filesize, cur);cur += bandwidth;usleep(20000);}printf("\n");printf("this file has been downloaded\n");
}int main()
{download(1024*1024*100.0,test);download(1024*1024*20.0,test);return 0;
}



“泰迪杯”數據挖掘挑戰賽成績公示)










——體系:監控數據采集——概述、關注焦點)



JobSystem+Burst+批處理)
