?
目錄
1聚合函數
1.1SQL類別高難度試卷得分的截斷平均值
1.2統計作答次數
1.3?得分不小于平均分的最低分
2?分組查詢
2.1平均活躍天數和月活人數
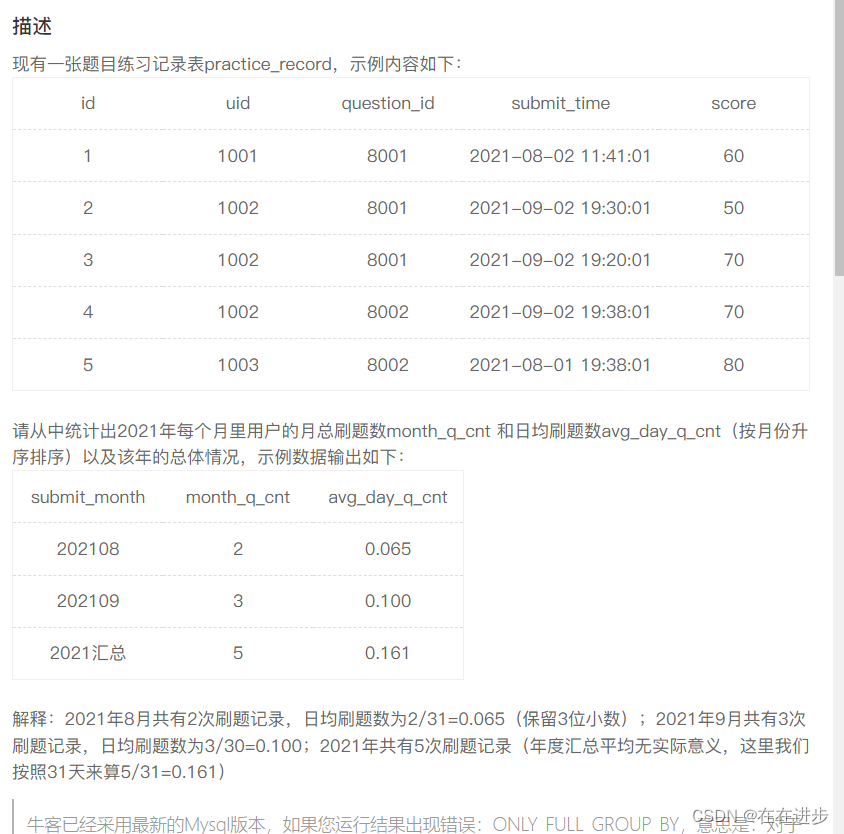
2.2?月總刷題數和日均刷題數
2.3未完成試卷數大于1的有效用戶
1聚合函數
1.1SQL類別高難度試卷得分的截斷平均值
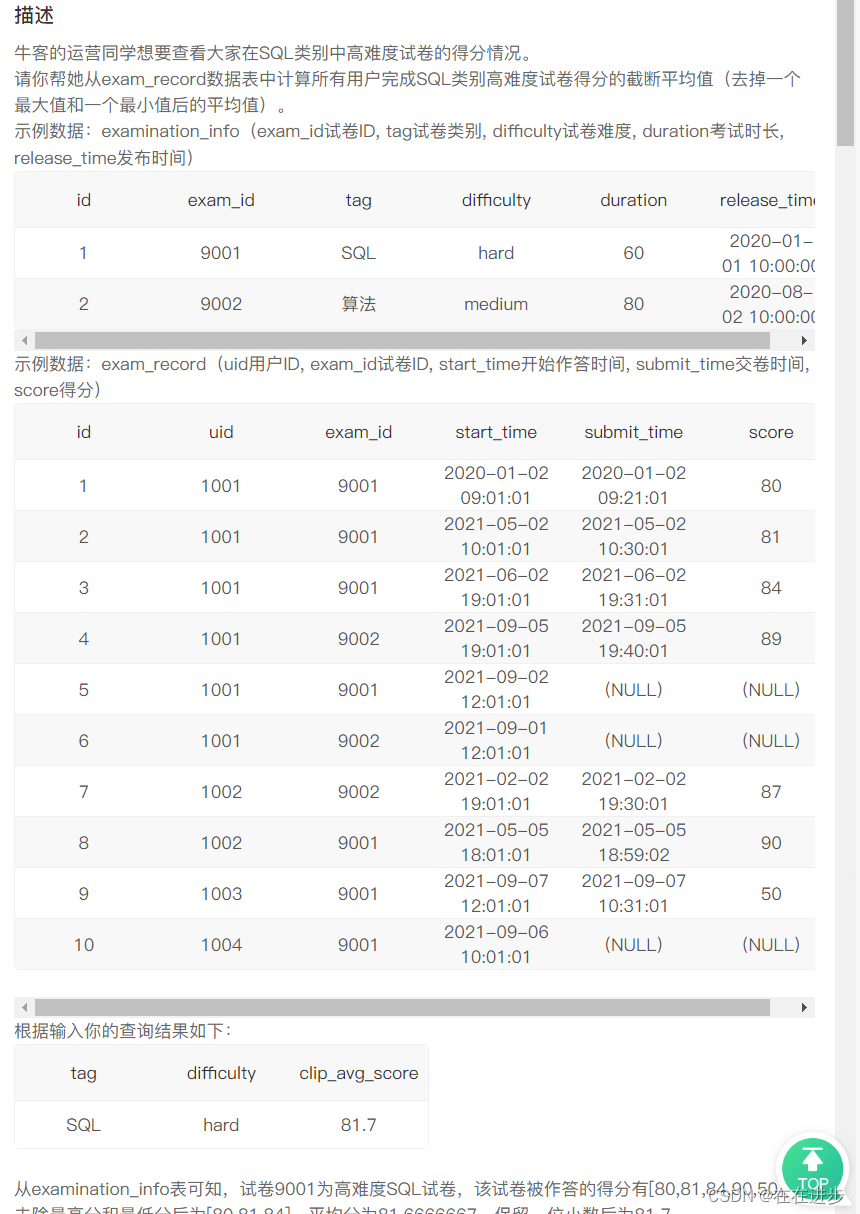
我的錯誤代碼:截斷平均值是有專門的函數嗎?
select tag,difficulty,avg(score) clip_avg_score
from examination_info ei join exam_record
using(id)
group by tag
where tag = 'SQL' and difficulty='hard'
and score not in (max(score),min(score))我的思路改正:用 (全部值 - 最大值 - 最小值) / (總數-2) ,但是缺點就是,如果最大值和最小值有多個,這個方法就很難篩選出來
SELECT ei.tag,ei.difficulty,ROUND((SUM(er.score)-MIN(er.score)-MAX(er.score)) / (COUNT(er.score)-2),1) AS clip_avg_score
FROM examination_info ei join exam_record er
on ei.exam_id = er.exam_id
where ei.tag = "SQL"
AND ei.difficulty = "hard";標準正確代碼:
使用in子句將最大值和最小值排除掉,再求平均值
- 懶人寫法,可以用with...as句式將要多次使用的表只寫1次即可(WITH AS 語法是MySQL中的一種臨時結果集,它可以在SELECT、INSERT、UPDATE或DELETE語句中使用。通過使用WITH AS語句,可以將一個查詢的結果存儲在一個臨時表中,然后在后續的查詢中引用這個臨時表。這樣可以簡化復雜的查詢,提高代碼的可讀性和可維護性。但是不知道哪個MySQL版本開始支持with...as句式的,我的本地電腦里面是Navicat 15 for MySQL,不支持)
- 用union把max和min的結果集中在一行當中,這樣形成一列多行的效果,不用多寫一次代碼
# t1篩選出SQL高難度的數據
WITH t1 as(SELECT er.*,ei.tag,ei.difficultyFROM exam_record er INNER JOINexamination_info eiON er.exam_id = ei.exam_idWHERE tag = "SQL" and difficulty = "hard"
)# 在t1的基礎上計算均值
SELECT tag,difficulty,round(avg(score),1)
FROM t1# 用in子句將最大值和最小值排除掉,再求平均值 not in
WHERE score not in (SELECT max(score)FROM t1UNIONSELECT min(score)FROM t1
)Q:為什么這里where換成and也不報錯,因為前面有on?那么where和on有啥區別呢,可以只有一個嗎?
A:
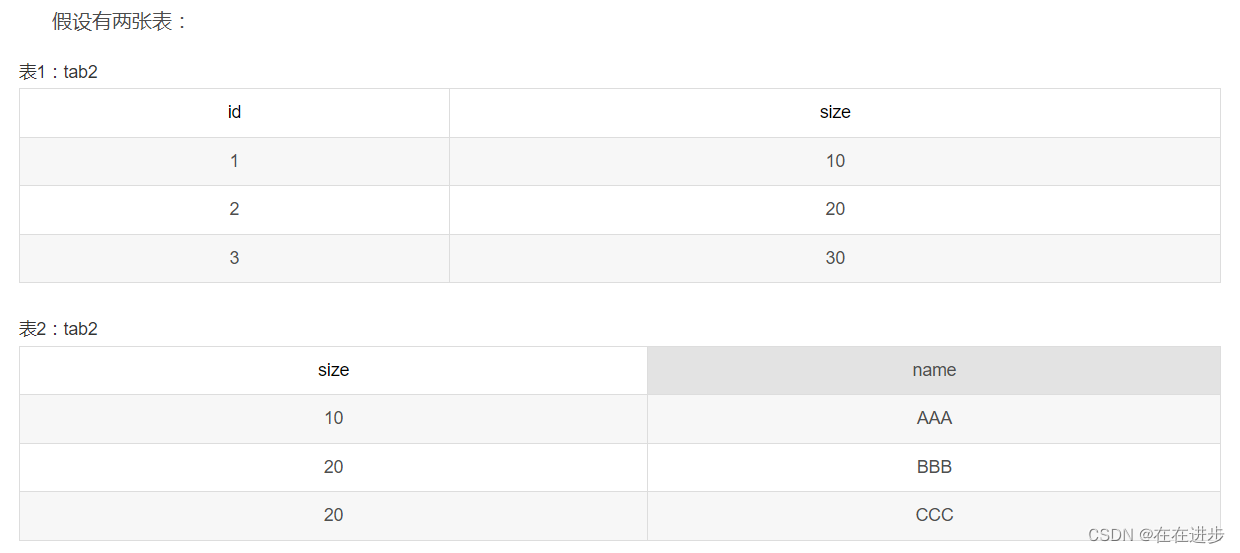
(1)where和having是在臨時表生產之后,對臨時表中的數據進行過濾用的。
如SQL語句:select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’
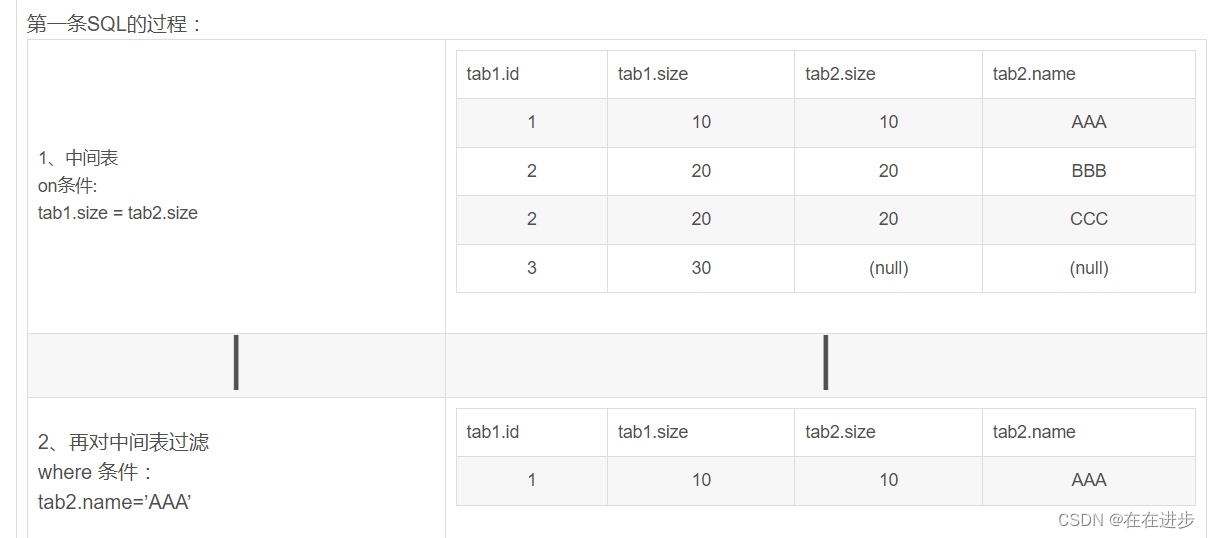
(2)?on是在生成中臨時表之前就去作用的,它會在數據源那里就把不符合要求的數據給過濾掉,即是先把不符合條件的記錄過濾后才進行統計,它就可以減少中間運算要處理的數據所以on運行的速度最快。
如SQL語句:select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’)
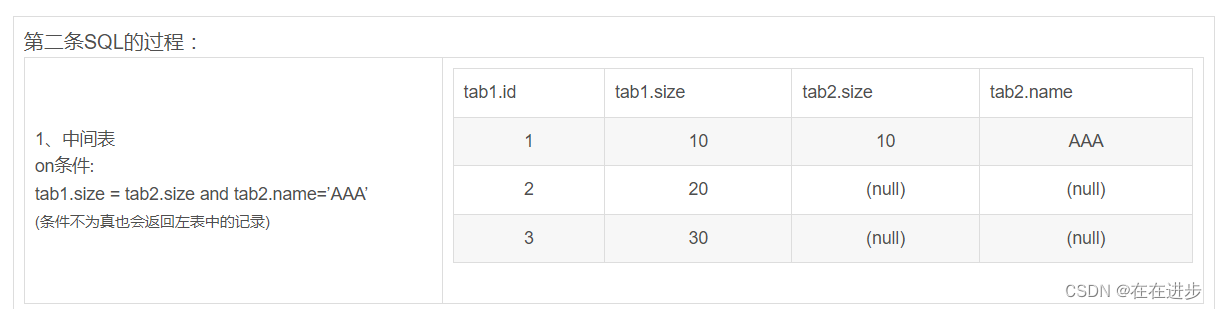
(3)在兩個表聯接時才用on的,所以在一個表的時候,就剩下where跟having比較了。在這單表查詢統計的情況下,如果要過濾的條件沒有涉及到要計算字段,那它們的結果是一樣的,但是where可以使用rushmore技術,而having就不能,在速度上后者要慢。
(4)? 如果要涉及到計算的字段,where的作用時間是在計算之前就完成的,而having就是在計算后才起作用的,所以在這種情況下,兩者的結果會不同。???
(5) 在多表聯接查詢時,on比where更早起作用。系統首先由on根據各個表之間的聯接條件,把多個表合成一個臨時表后,再由where進行過濾,然后再計算,計算完后再由having進行過濾。
1.2統計作答次數

我的報錯代碼:求已完成的試卷數時應該要分組一下,exam_id
select count(er.id) total_pv,
count(er.submit_time) complete_pv,
count(t2.exam_id) complete_exam_cnt
from exam_record er,(select count(exam_id) from exam_record
group by exam_id) t2正確代碼1:
主要在于已完成的試卷數的統計,因為這個帶有條件,且需要統計聚合結果,可以使用 聚合函數與case when 結合。count中是可以加條件的
select
count(*) total_pv,
count(score) complete_pv,
count(distinct case when score is null then null else exam_id end) complete_exam_cnt
from exam_record復習case when:
(1)case expr when v1 then r1 [when v2 then r2] ...[else rn] end
?????? 例如:case 2 when 1 then 'one' when 2 then 'two' else 'more' end 返回two
?????? case后面的值為2,與第二條分支語句when后面的值相等相等,因此返回two
(2)case when v1 then r1 [when v2 then r2]...[else rn] end
?????? 例如:case when 1<0 then 'T' else 'F' end返回F
?????? 1<0的結果為false,因此函數返回值為else后面的F
正確代碼2:
select count(*) as total_pv,
count(score) as complete_pv,
count(distinct exam_id,score IS NOT NULL or null) as complete_exam_cnt
# 是逗號,連接不是and連接
from exam_record在select和count后面都可以加條件的,但是要明白內核:
count(distinct exam_id,score IS NOT NULL or null) as complete_exam_cnt (正確)
不能是
count(distinct exam_id and score IS NOT NULL or null) as complete_exam_cnt (錯誤,結果永遠為2, 這個題只是碰巧結果為2,改一個數據就不對了)
1 用and:
(1)一般在where后篩選過濾,還是得到的滿足條件的score
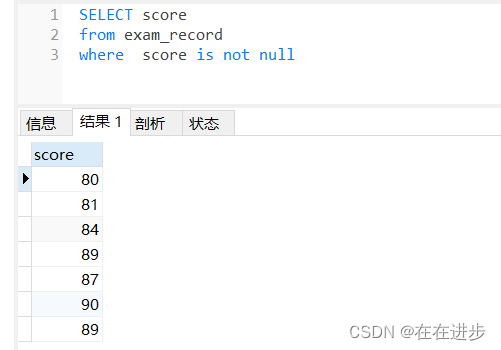
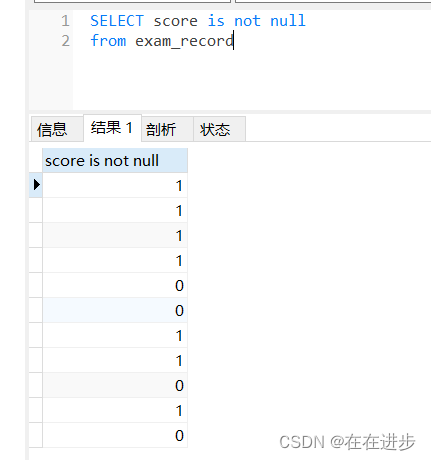
(2)如果在select后直接加條件判斷:這里的score is not null 是判斷
- 符合條件的返回 true ,即為1
- 不符合的返回 false ,即為0?
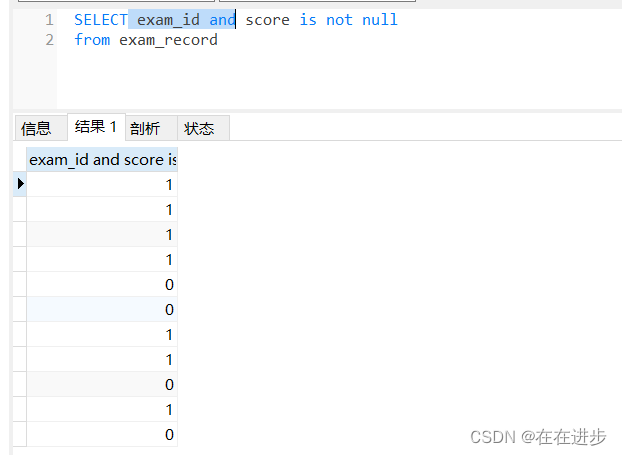
(3) 加上exam_id,進行and邏輯運算
- exam_id 本身為值,可以理解為真 在 and 邏輯下,所以上一步的1,0并不會變化,后面加上or NULL,否則會把0也計算上。
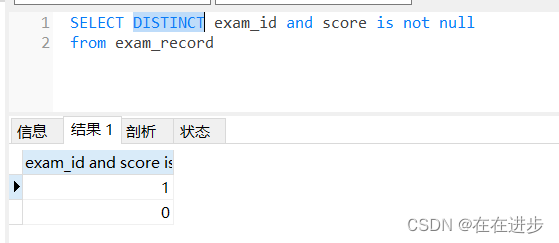
(4) 在上一步的基礎上去重,則只會剩下1和0
- 經過and運算之后,只剩下一列數據,多行1和0
- distinct 去重后,就只剩下兩行數據 1 和 0
(5)所以這時候再進行count計算,結果恒為2 (兩行數據)

?2 正確答案的執行邏輯:
(1)用,連接(從之前的邏輯判斷,變為多列組合)
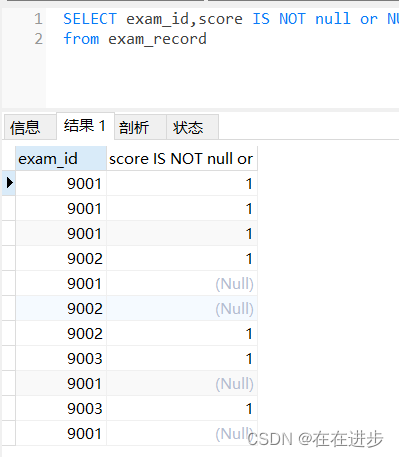
(2)這時候distinct 去重后,就不是只剩下兩行數據 1 和 0,而是會把score為null也會考慮進去。
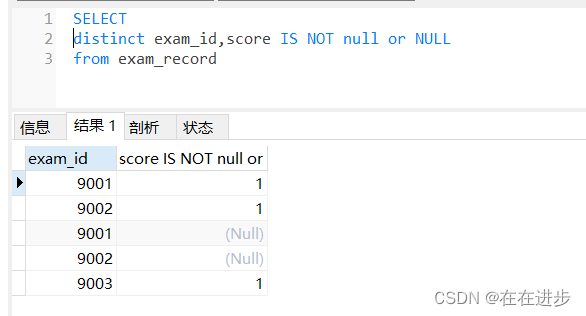
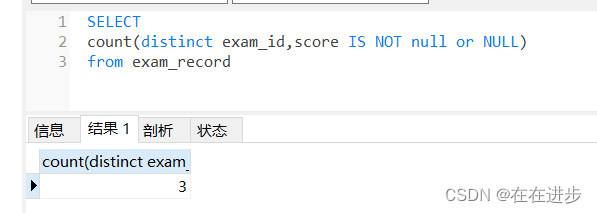
(3)結果應該是3,如果沒有or NULL,就是5行了(null為0會被計數)
1.3?得分不小于平均分的最低分
?
我的代碼:where后面的條件錯了,但是思路大概這樣。
select score min_score_over_avg
from exam_record er join examination_info ei
on er.id = ei.id
group by exam_id
where score>=avg(score) and ei.tag = 'SQL'
order by score asc
limit 1修改我的代碼:
select er.score min_score_over_avg
from exam_record er
left join examination_info ei
on er.exam_id = ei.exam_id # 不是按照id連接
where ei.tag = 'SQL'
and score>= (SELECT avg(er.score) from exam_record er
left join examination_info ei
on er.exam_id=ei.exam_id
where ei.tag='SQL')
order by score asc
limit 1(1)表連接是按照exam_id ,不是按照id連接?
(2)score>=某個值,這里不能直接score>=avg(score),而是應該通過表查詢返回得到avg(score),然后在進行比較。
改進我的代碼:
這里有表查詢的部分重復了兩次,可以用with...as句式將要多次使用的表命名,這樣可以只寫一次,多次調用。
此外,order by score asc? limit 1? 可以換為min函數。
with t as
(SELECT score from exam_record er
left join examination_info ei
on er.exam_id=ei.exam_id
where ei.tag='SQL')select min(score) min_score_over_avg
from t
where score>=
(SELECT avg(t.score) from t)2?分組查詢
2.1平均活躍天數和月活人數
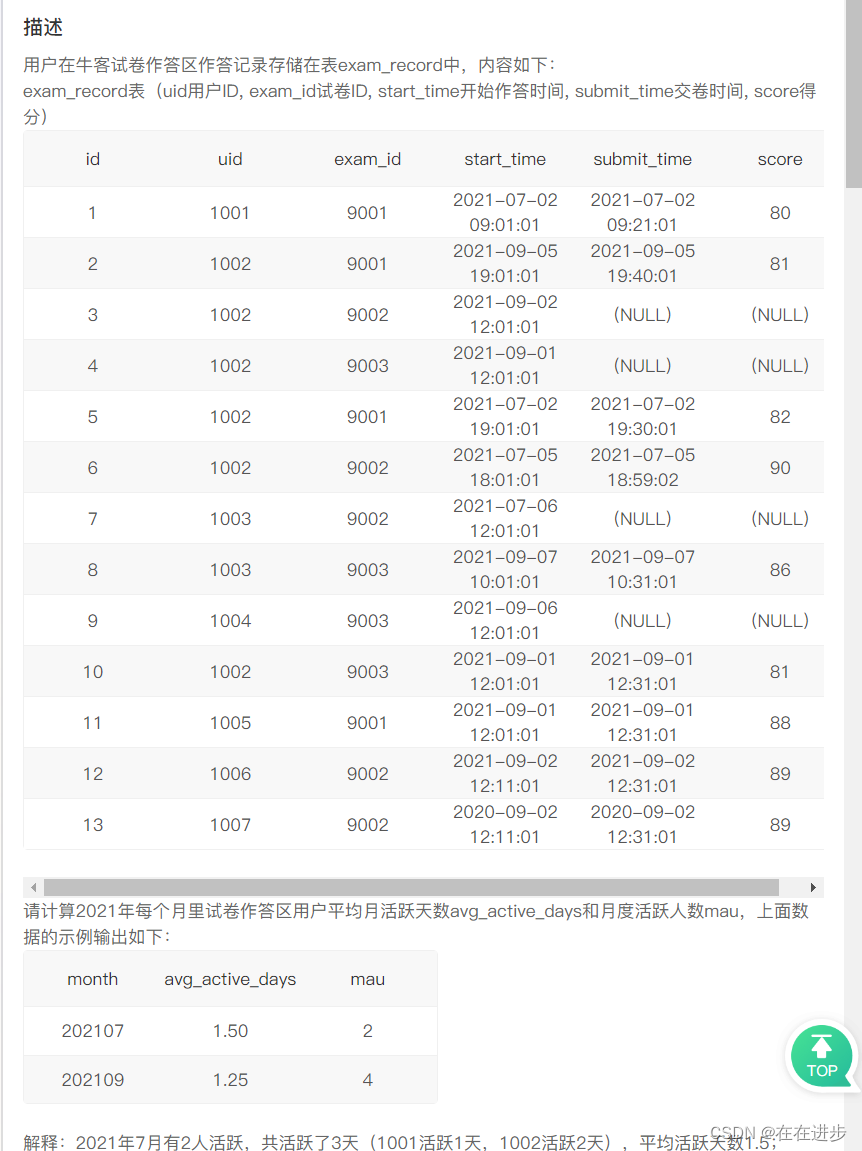
我的代碼:此處活躍指有交卷行為,用戶平均月活躍天數avg_active_days啥意思?
with t as
(select *
from exam_record
where year(start_time)=2021)select month(start_time) 'month',
count(submit_time) mau
from t
group by month(submit_time)正確代碼:
select DATE_FORMAT(start_time,"%Y%m") as month,
round(count(distinct uid,date_format(start_time,"%Y%m%d"))/count(distinct uid),2) as avg_active_days,
count(distinct uid) as mau
from exam_record
where submit_time is not NULL
and YEAR(submit_time) =2021
group by month;(1)202107是用date_format函數:DATE_FORMAT(start_time,"%Y%m") as month
(2)主要難的一點是天數的計算。
到底是count(distinct uid,date_format(start_time,"%Y%m%d"))
還是count(start_time)作為分子呢
關鍵是理解題目的意思是:天數。
假設一個uid 比如1001在2021-07-06這一天有二個記錄,如果是count(start_time)那么就是天數是2,但是如果是count(distinct uid,date_format(start_time,"%Y%m%d"))天數就是1了
復盤探索:
(1)先找出2021年,活躍的用戶ID和時間(具體到哪天)
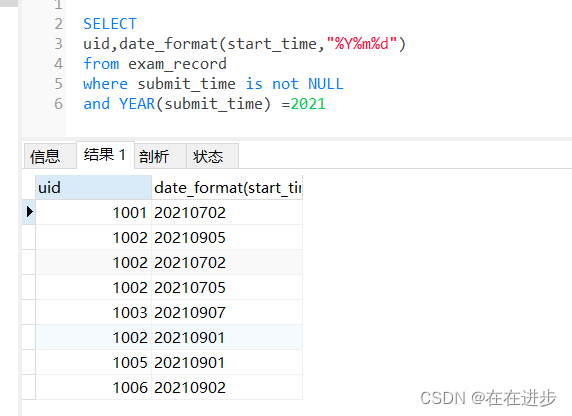
(2)如果不考慮uid,直接按照活躍時間去重,那么不同用戶在同一天活躍記錄會被去重到只剩下1條,
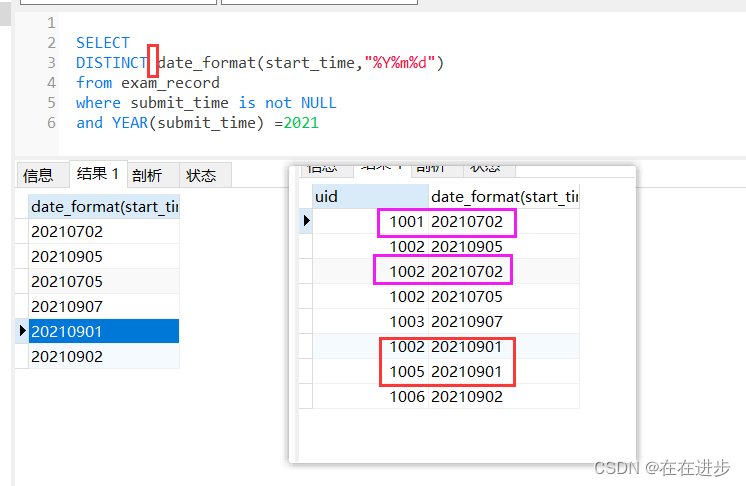
(3)同理,如果只安裝用戶ID去重,那么同一用戶在不同天的記錄也會被去重到只有1條。這里查詢的實際是月活躍的用戶有哪些。
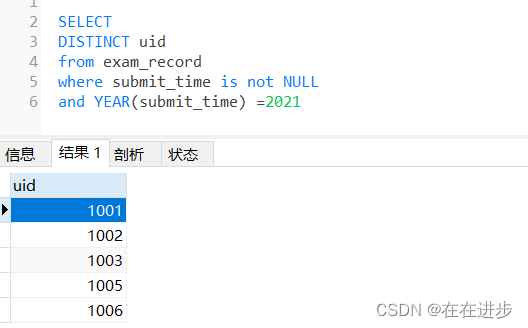
(4) 所以要去重的目的是,同一個用戶,在同一天,重復提交活躍多次的記錄。(因為這里是按天算,同一天同一個用戶只算一次。)
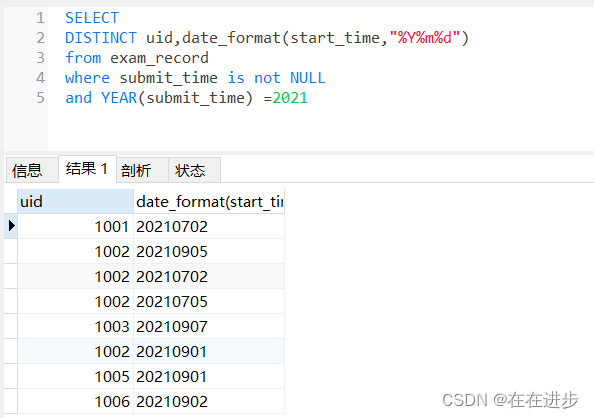
(5)用戶平均月活躍天數=月活躍天數?/月活躍用戶
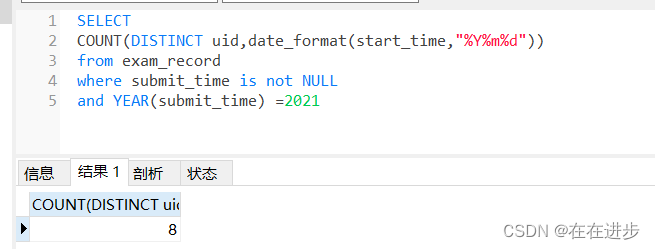
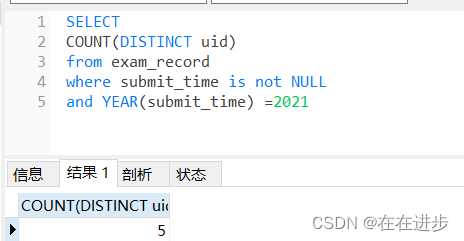
:count(distinct uid,date_format(start_time,"%Y%m%d"))/count(distinct uid)
月活躍天數:
月活躍用戶:?
2.2?月總刷題數和日均刷題數
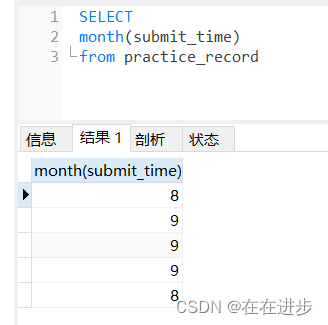
我的代碼:分組好像報錯,后面那個求總數我也不知道咋整
分組報錯問題:MySQL提供了any_value()函數來抑制ONLY_FULL_GROUP_BY值被拒絕
select
date_format(submit_time,'%y%m') submit_month,
count(score) month_q_cnt,
count(score)/day(month(submit_time)) avg_day_q_cnt
from practice_record
group by date_format(submit_time,'%y%m%d')
having year(submit_time)=2021(1)當月天數求錯了,我是想先求出當前月,再求出當月天:這樣操作結果是不對的。
 ? ??
? ??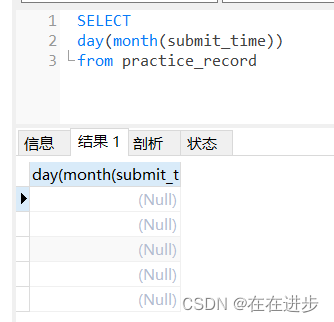
應該用last_day函數求出最后一天,然后用day函數求出這個日期的天數。

復習【日期時間函數】
●?? year(date)——獲取年的函數
●?? month(date)——獲取月的函數
●?? day(date)——獲取日的函數
●?? date_add(date,interval expr type)——對指定起始時間進行加操作
●?? date_sub(date,interval expr type)——對指定起始時間進行減操作
●?? datediff(date1,date2)——計算兩個日期之間間隔的天數
●?? date_format(date,format)——將日期和時間格式化
代碼改正:
select
date_format(submit_time,'%y%m') submit_month,
any_value(count(score)) month_q_cnt,
any_value(round(count(score)/day(last_day(submit_time)),3)) avg_day_q_cnt
from practice_record
where year(submit_time)='2021'
# where date_format(submit_time,'%y')='2021'
group by submit_month
該年的總體情況,可以用union all來連接,完整代碼:
select date_format(submit_time,'%Y%m') submit_month,
any_value(count(question_id)) month_q_cnt,
any_value(round(count(question_id)/day(LAST_DAY(submit_time)),3)) avg_day_q_cnt
from practice_record
where date_format(submit_time,'%Y')='2021'
group by submit_month
union all
select '2021匯總' as submit_month,
count(question_id) month_q_cnt,
round(count(id)/31,3) avg_day_q_cnt
from practice_record
where date_format(submit_time,'%Y')='2021'
order by submit_month;復習:
1、區別1:取結果的交集
1)union: 對兩個結果集進行并集操作, 不包括重復行,相當于distinct, 同時進行默認規則的排序;
2)union all: 對兩個結果集進行并集操作, 包括重復行, 即所有的結果全部顯示, 不管是不是重復;
2、區別2:獲取結果后的操作
1)union: 會對獲取的結果進行排序操作
2)union all: 不會對獲取的結果進行排序操作
3、總結
union all只是合并查詢結果,并不會進行去重和排序操作,在沒有去重的前提下,使用union all的執行效率要比union高。
2.3未完成試卷數大于1的有效用戶
我的代碼:羅里吧嗦答案還不對。。
with t as
(select uid,er.exam_id,start_time,submit_time,tag
from exam_record er , examination_info ei
where er.exam_id=ei.exam_id
and date_format(start_time,'%Y')='2021')select uid,
(select count(submit_time) from t
where submit_time is NULL) incomplete_cnt,
(select count(submit_time) from t
where submit_time is not NULL) complete_cnt
from t
where (select count(submit_time) from t
where submit_time is NULL)<5 and (select count(submit_time) from t
where submit_time is not NULL)>1
order by incomplete_cnt我的代碼改正:
select uid,
sum(case when submit_time is NULL then 1 else 0 end ) incomplete_cnt,
sum(case when submit_time is NULL then 0 else 1 end ) complete_cnt
from exam_record er join examination_info ei
on er.exam_id=ei.exam_id
where date_format(start_time,'%Y')='2021'
group by uid
having incomplete_cnt >1 and incomplete_cnt<5 and complete_cnt>1
order by incomplete_cnt接下來是detail,作答過的試卷tag集合,是提交日期:類型;一直重復顯示
![]()
我的完整代碼:
select uid,
sum(case when submit_time is NULL then 1 else 0 end ) incomplete_cnt,
sum(case when submit_time is NULL then 0 else 1 end ) complete_cnt,
group_concat(DISTINCT concat_ws(':',date_format(start_time,"%Y-%m-%d"),tag) order by start_time Separator ';') detailfrom exam_record er join examination_info ei
on er.exam_id=ei.exam_id
where date_format(start_time,'%Y')='2021'
group by uid
having incomplete_cnt >1 and incomplete_cnt<5 and complete_cnt>1
order by incomplete_cnt desc注意:select后面的屬性,不管計算了多長,每個之間都要有逗號!!!?
大佬代碼:
SELECT uid,
SUM(CASE WHEN submit_time IS NULL THEN 1 ELSE 0 END) "incomplete_cnt",
SUM(CASE WHEN submit_time IS NULL THEN 0 ELSE 1 END) "complete_cnt",
group_concat(distinct concat_ws(':',date(start_time),tag)
order by start_time separator ';') as detail
FROM exam_record er INNER JOIN
examination_info ei
ON er.exam_id = ei.exam_id
WHERE year(start_time) = 2021
GROUP BY uid
HAVING complete_cnt >= 1 AND incomplete_cnt > 1 AND
incomplete_cnt < 5
ORDER BY incomplete_cnt desc其中
(1)用sum和case when函數來求完成和未完成的試卷數
(2)detail的實現是用concat_ws或者concat函數將submit_time和tag連接并且同時distinct:
函數group_concat([DISTINCT] 要連接的字段 [Order BY ASC/DESC?排序字段] [Separator'分隔符'])
concat()函數
-
功能:將多個字符串連接成一個字符串。
-
語法:concat(str1, str2,…)
-
返回結果為連接參數產生的字符串,如果有任何一個參數為null,則返回值為null。
concat_ws()函數
- 功能:和concat()一樣,將多個字符串連接成一個字符串,但是可以一次性指定分隔符(concat_ws就是concat with separator)
- 語法:concat_ws(separator, str1, str2, …)
- 說明:第一個參數指定分隔符。需要注意的是分隔符不能為null,如果為null,則返回結果為null。

“泰迪杯”數據挖掘挑戰賽成績公示)










——體系:監控數據采集——概述、關注焦點)



JobSystem+Burst+批處理)


