前言
近年來,大語言模型 (LLM) 已經成為人工智能領域最熱門的研究方向之一,并在各種任務中展現出前所未有的性能。然而,由于商業利益的驅動,許多最具競爭力的模型,例如 GPT、Gemini 和 Claude,其訓練細節和數據來源往往被隱藏在專有接口背后。這限制了學術界對 LLM 的深入研究和應用。
為了解決這一問題,研究團隊開源了 MAP-Neo,一個高性能、透明的雙語大語言模型,旨在推動 LLM 研究的民主化。MAP-Neo 擁有 70 億參數,從頭開始訓練,并使用了 4.5T 經過精心清洗和篩選的高質量 token。
-
Huggingface模型下載:https://huggingface.co/m-a-p/neo_7b
-
AI快站模型免費加速下載:https://aifasthub.com/models/m-a-p
技術特點
MAP-Neo 的透明性和高性能源于其獨特的設計和訓練策略:
-
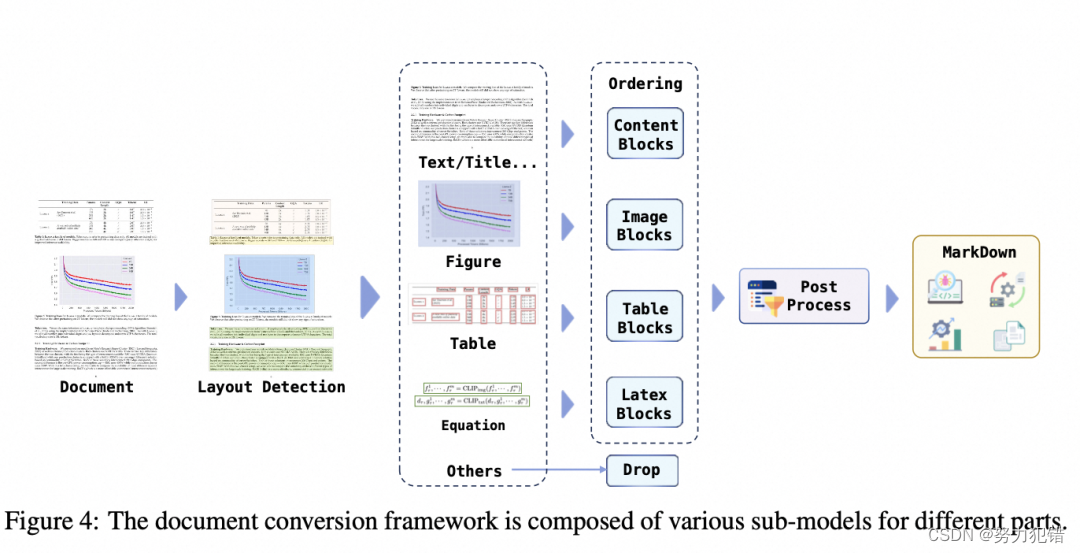
全流程透明: 與現有許多開源 LLM 不同,MAP-Neo 秉持著完全透明的理念,不僅公開了模型權重,還提供了完整的訓練代碼、預訓練數據以及數據清洗流程,方便研究人員復現和驗證模型。
-
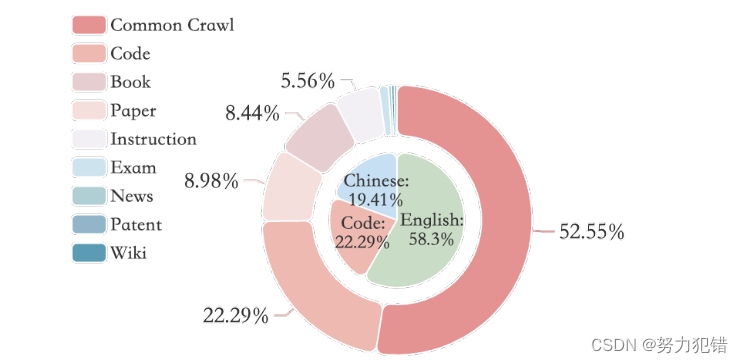
高質量數據訓練: MAP-Neo 使用了名為 Matrix Data Pile 的預訓練語料庫,包含 4.5T 高質量 token,其中 52.55% 來自 Common Crawl,22.29% 來自編程代碼,其余部分來自學術論文、書籍和其他印刷材料。研究團隊針對不同的數據來源和內容類型,制定了相應的清洗和過濾策略,以確保數據的質量和多樣性。
-
高效的訓練架構: MAP-Neo 在 Megatron-LM 框架的基礎上進行了改進,增強了其對大型數據集訓練的支持,并引入了 NEO Scaling Law,用于優化使用來自不同語料庫的預訓練數據集來擴展 LLM。
-
精心設計的模型架構: MAP-Neo 采用 Transformer 解碼器架構,并整合了 RoPE Embeddings、RMSNorm 以及 SwiGLU 等技術,以提高模型的效率和性能。此外,MAP-Neo 還采用了多階段的訓練策略,包括基礎階段和衰減階段。
性能表現
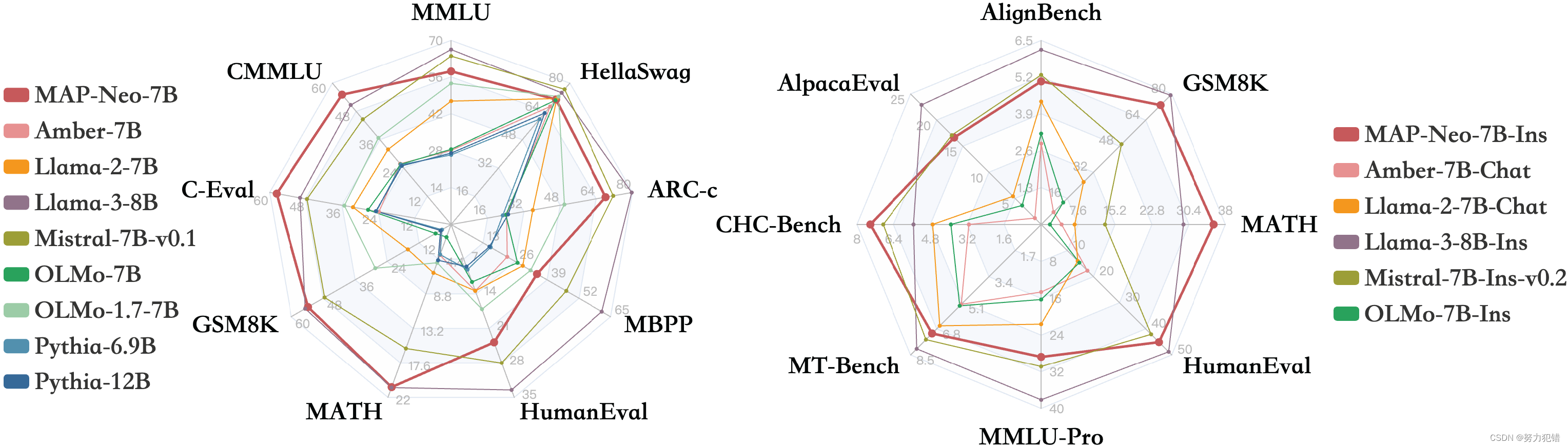
MAP-Neo 在多項任務中都展現出令人印象深刻的性能,超越了同等規模的其他開源 LLM,例如 LLaMA-3 和 Mistral-7B:
-
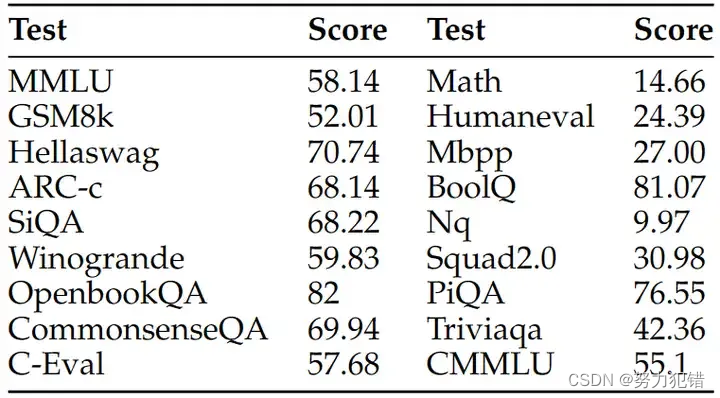
標準基準測試: MAP-Neo 在 BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-Challenge、OpenBookQA-Fact、CommonsenseQA、MMLU、C-Eval 和 CMMLU 等標準基準測試中取得了優異成績,展現出強大的語言理解和推理能力。
-
代碼生成: MAP-Neo 在 HumanEval、HumanEval-Plus、MBPP 和 MBPP-Plus 等代碼生成任務中也表現突出,展現出良好的代碼生成和理解能力。
-
數學推理: MAP-Neo 在 GSM8K 和 MATH 等數學推理任務中取得了領先成績,展現出強大的邏輯推理能力。
應用場景
MAP-Neo 作為一款全流程透明的雙語大模型,具有廣泛的應用場景:
-
學術研究: 為研究者提供一個可復現、可解釋的平臺,推動雙語大模型技術的發展。
-
中文應用: 幫助解決中文LLM資源匱乏的問題,促進中文自然語言處理技術的進步。
-
商業應用: 幫助企業快速構建自己的中文和英文LLM應用,降低開發成本,提升效率。
總結
MAP-Neo 的開源和透明,不僅為雙語大模型的研究和應用提供了寶貴的資源,也推動了AI技術的民主化進程。我們相信,MAP-Neo 將為LLM的發展和應用開辟新的道路,助力人工智能技術的進步和普及。
模型下載
Huggingface模型下載
https://huggingface.co/m-a-p/neo_7b
AI快站模型免費加速下載
https://aifasthub.com/models/m-a-p




和imutils庫實現輔助答題卡判別)




)





)



