歡迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有問題可以隨時與我交流, 謝謝大家!
LinkedIn Feed 排名
1. 問題陳述
設計一個個性化的LinkedIn Feed,以最大化用戶的長期參與度。衡量參與度的一種方法是用戶頻率,即每個用戶的參與次數,但在實踐中這非常困難。另一種方法是衡量點擊概率或點擊率(CTR)。
在LinkedIn這樣的社交媒體平臺上,“Feed”指的是向用戶顯示的內容的不斷更新的流。
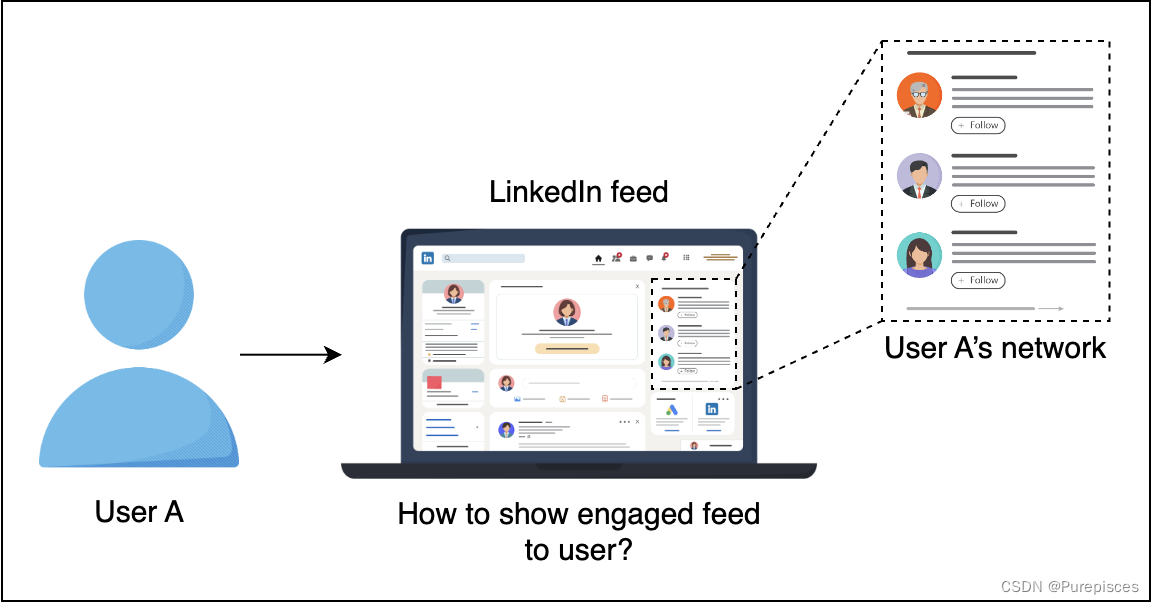
在LinkedIn Feed上,有五種主要的活動類型:
- 連接
- 信息
- 個人資料
- 觀點
- 特定站點
直觀上,不同的活動有非常不同的點擊率。這在構建模型和生成訓練數據時非常重要。
| 類別 | 示例 |
|---|---|
| 連接 | 成員連接、關注成員/公司、成員加入群組 |
| 信息 | 成員或公司分享文章/圖片/消息 |
| 個人資料 | 成員更新個人資料,例如照片、職位變動等 |
| 觀點 | 成員點贊或評論文章、圖片、職位變動等 |
| 特定站點 | LinkedIn特有的活動,例如成員為成員點贊等 |
2. 指標設計和要求
指標
離線指標
-
點擊率 (CTR):Feed收到的點擊次數除以Feed顯示的次數。
-
公式:
C T R = 點擊次數 顯示次數 CTR = \frac{\text{點擊次數}}{\text{顯示次數}} CTR=顯示次數點擊次數?
-
-
最大化CTR可以形式化為訓練一個有監督的二分類模型。對于離線指標,我們歸一化交叉熵和AUC。
-
歸一化交叉熵 (NCE):幫助模型對背景CTR不太敏感。
- 公式:
N C E = ? 1 N ∑ i = 1 n ( 1 + y i 2 log ? ( p i ) + 1 ? y i 2 log ? ( 1 ? p i ) ) ? ( p log ? ( p ) + ( 1 ? p ) log ? ( 1 ? p ) ) NCE = \frac{-\frac{1}{N} \sum\limits_{i=1}^{n} \left( \frac{1 + y_i}{2} \log(p_i) + \frac{1 - y_i}{2} \log(1 - p_i) \right)}{ - \left( p \log(p) + (1 - p) \log(1 - p) \right)} NCE=?(plog(p)+(1?p)log(1?p))?N1?i=1∑n?(21+yi??log(pi?)+21?yi??log(1?pi?))?
N:樣本總數。
y i y_i yi?:第 ( i ) 個樣本的實際標簽。如果項目被點擊,則 ( y_i ) 為 1,否則為 0。
p i p_i pi?:第 ( i ) 個項目被點擊的預測概率。
歸一化項:
? ( p log ? ( p ) + ( 1 ? p ) log ? ( 1 ? p ) ) - \left( p \log(p) + (1 - p) \log(1 - p) \right) ?(plog(p)+(1?p)log(1?p))
p p p:背景CTR(項目被點擊的平均概率)。
這個項是具有平均值 p p p 的伯努利分布的熵。它規范了交叉熵損失,以考慮點擊的固有可能性(背景CTR)。
交叉熵歸一化:
- 確保模型的性能不受固有點擊率高或低的項目的過度影響。
- 使模型在不同類型的項目上更加健壯和通用。
AUC:
- 提供一個全面的指標來評估模型區分點擊和未點擊項目的能力。
- 對于點擊次數可能遠小于未點擊次數的不平衡數據集特別有用。
背景CTR指的是在數據集中或特定數據子集中觀察到的平均點擊率(CTR)。它反映了所有項目在不考慮各個項目特征的情況下的固有點擊可能性。例如,如果平臺的總體CTR為0.02,這意味著平均有2%的顯示項目被點擊。
在線指標
- 對于非平穩數據,離線指標通常不是性能的良好指標。在線指標需要反映模型部署后用戶的參與度,即轉化率(點擊次數與Feed數量的比率)。
要求
訓練
- 處理大量數據:理想情況下,模型在分布式環境中進行訓練。
- 在線數據分布變化:每天多次增量地重新訓練模型,以應對數據分布的變化。
- 個性化:支持高度個性化,因為不同用戶對Feed的消費方式和風格不同。
- 數據新鮮度:避免在用戶的主頁Feed上顯示重復的Feed。
推斷
- 可擴展性:處理大量用戶活動并支持3億用戶。
- 延遲:Feed排名需要在50毫秒內返回,整個過程在200毫秒內完成。
- 數據新鮮度:確保Feed排名知道用戶是否已經看到某個特定活動,以避免顯示重復的活動。
總結
| 類型 | 期望目標 |
|---|---|
| 指標 | 合理的歸一化交叉熵 |
| 訓練 | 高吞吐量,能夠每天多次重新訓練 |
| 支持高度個性化 | |
| 推斷 | 延遲從100毫秒到200毫秒 |
| 提供高水平的數據新鮮度,避免多次顯示相同的Feed |
3. 模型
特征工程
| 特征 | 特征工程 | 描述 |
|---|---|---|
| 用戶檔案:職位、行業、人口統計等 | 低基數:使用獨熱編碼。高基數:使用嵌入。 | |
| 用戶之間的連接強度 | 由用戶之間的相似性表示。我們還可以使用嵌入來表示用戶,并測量距離向量。 | |
| 活動年齡 | 根據點擊目標的敏感度,將其視為連續特征或分箱值。 | |
| 活動特征: | 活動類型、標簽、媒體等。使用活動嵌入并測量活動與用戶之間的相似性。 | |
| 交叉特征 | 組合多個特征。 |
用戶檔案:對人口統計進行獨熱編碼,因為它的基數較低(例如,年齡組)。由于可能存在高基數(許多唯一的職位和行業),對職位和行業進行嵌入。
用戶之間的連接強度:例如,如果用戶A經常與用戶B互動(點贊帖子、評論、消息),則連接強度較高。
活動年齡:例如,活動的年齡(例如帖子或更新)可以表示為自創建以來的天數。如果點擊行為對活動的新鮮度敏感,則可以將其視為連續變量。或者,可以將其分箱為“少于一天”,“1-3天”,“4-7天”等,以簡化模型。示例:一個帖子創建于2天前。特征工程:1. 將年齡視為連續特征:年齡=2 2. 或者,將年齡分箱:年齡箱=“1-3天”。
活動特征:例如,活動可以包括分享文章、更新個人資料圖片或點贊帖子。每種活動類型都可以嵌入到一個向量空間中。如果用戶經常參與與“數據科學”相關的文章,可以使用這些嵌入來衡量新數據科學相關活動與用戶興趣的相似性。
交叉特征:交叉特征是多個基本特征的組合,以捕獲它們之間的交互。例如,結合“用戶行業”和“活動類型”,以查看技術行業的用戶是否比其他行業更喜歡信息活動(如文章分享)。
訓練數據
在構建任何機器學習模型之前,我們需要收集訓練數據。目標是收集不同類型帖子的數據,同時改善用戶體驗。以下是我們可以收集訓練數據的一些方法:
- 按時間順序排名:此方法按時間順序對每個帖子進行排名。使用這種方法收集點擊/未點擊數據。這里的權衡是用戶對前幾個帖子的關注導致的服務偏差。此外,由于不同的活動(如職位變動)相比于LinkedIn上的其他活動很少發生,因此存在數據稀疏問題。
- 隨機呈現:此方法按隨機順序對帖子進行排名。這可能會導致糟糕的用戶體驗。它也無法解決稀疏性問題,因為缺乏有關稀有活動的訓練數據。
- 使用Feed排名算法:這將對前幾個Feed進行排名。在頂部Feed中,你可以隨機排列。然后,使用點擊數據進行數據收集。這種方法提供了一些隨機性,有助于模型學習和探索更多活動。
基于此分析,我們將使用算法生成訓練數據,以便后續訓練機器學習模型。
我們可以通過選擇一段數據時間來開始使用數據進行訓練:上個月、過去6個月等。在實踐中,我們希望在訓練時間和模型準確性之間找到平衡。我們還對負面數據進行下采樣以處理不平衡數據。
模型選擇
我們可以使用概率稀疏線性分類器(邏輯回歸)。由于其計算效率高,這是一種流行的方法,適用于稀疏特征。
由于數據量大,我們需要使用分布式訓練:Spark中的邏輯回歸或交替方向乘子法(ADMM)。
我們也可以在分布式環境中使用深度學習。我們可以從全連接層開始,在最終層應用Sigmoid激活函數。由于CTR通常非常小(小于1%),我們需要重新采樣訓練數據集以使數據不那么不平衡。重要的是保持驗證集和測試集不變,以準確估計模型性能。
邏輯回歸可以有效處理稀疏向量,因為它只需要計算非零特征的加權和。
為什么邏輯回歸是線性分類器
線性決策邊界
特征的線性組合
邏輯回歸使用輸入特征的線性組合進行預測。這意味著輸入特征與結果的對數幾率之間的關系是線性的。
決策邊界
決策邊界是在特征空間中的直線(或更高維空間中的超平面),分隔不同的類別。
Apache Spark:Spark是一種強大的大數據處理和機器學習工具。它支持分布式計算,這意味著它可以通過在機器集群上分發數據和計算來處理大數據集。Spark中的邏輯回歸:Spark的MLlib庫包括可以分布式運行的邏輯回歸實現。這使得在非常大的數據集上進行高效訓練成為可能。
交替方向乘子法(ADMM):這是一種用于通過將復雜問題分解為更小的子問題來解決復雜問題的優化算法。每個子問題都可以獨立解決,使ADMM適用于分布式計算環境。邏輯回歸中的應用:ADMM可以用于并行優化邏輯回歸模型參數,提高效率和可擴展性。
保持驗證集和測試集不變意味著在對訓練數據進行更改(如重新采樣以解決類別不平衡)時不應修改這些數據集。以下是對其含義及其重要性的詳細解釋:
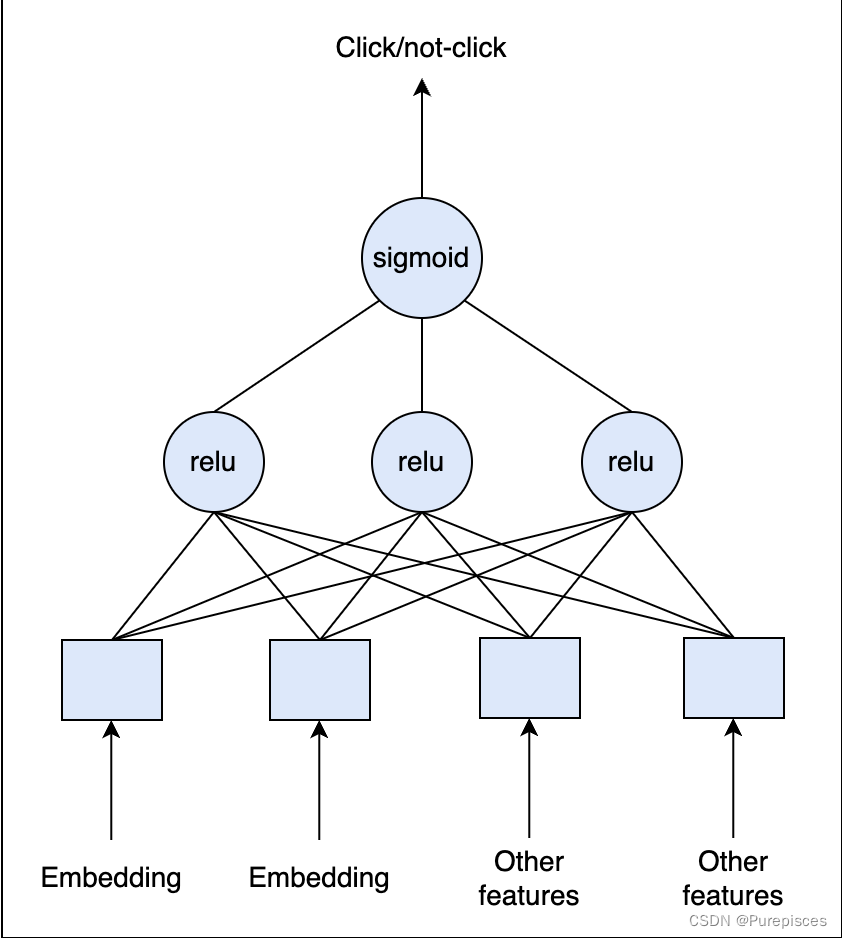
評估
一種方法是將數據分為訓練數據和驗證數據。另一種方法是重放評估以避免偏差的離線評估。我們使用直到時間 t t t 的數據來訓練模型。我們使用時間 t + 1 t+1 t+1 的測試數據,并在推斷過程中根據我們的模型重新排序它們的排名。如果在正確位置有準確的點擊預測,則記錄匹配。總匹配數將視為總點擊數。
在評估期間,我們還將評估我們的訓練數據集應有多大,以及我們應多頻繁地重新訓練模型,以及許多其他超參數。
重放評估是一種通過使用歷史數據模擬模型在現實世界場景中的表現來評估模型性能的方法。使用過去的數據評估模型,將歷史互動視為實時發生。通過使用歷史數據模擬實時預測,重放評估提供了模型在生產中的性能的更準確衡量。
位置匹配:意味著模型根據其預測的點擊概率最高(或其他特定排名)的項目與用戶實際點擊的項目相同。
4. 計算與估計
假設
- 3億月活躍用戶
- 平均每個用戶每次訪問看到40個活動。每個用戶每月訪問10次。
- 我們有 12 ? 1 0 10 12 * 10^{10} 12?1010 或1200億次觀察/樣本。
數據大小
- 假設點擊率約為1%(1個月)。我們收集了10億個正標簽和約1100億個負標簽。這是一個巨大的數據集。
- 通常,我們可以假設對于每個數據點,我們收集數百個特征。為了簡化,每行存儲需要500字節。
- 在一個月內,我們需要1200億行。總大小: 500 ? 120 ? 1 0 9 = 60 ? 1 0 12 500 * 120 * 10^{9} = 60 * 10^{12} 500?120?109=60?1012 字節 = 60 TB。為了節省成本,我們可以在數據湖中保留最近6個月或1年的數據,并將舊數據存檔在冷存儲中。
規模
- 支持3億用戶
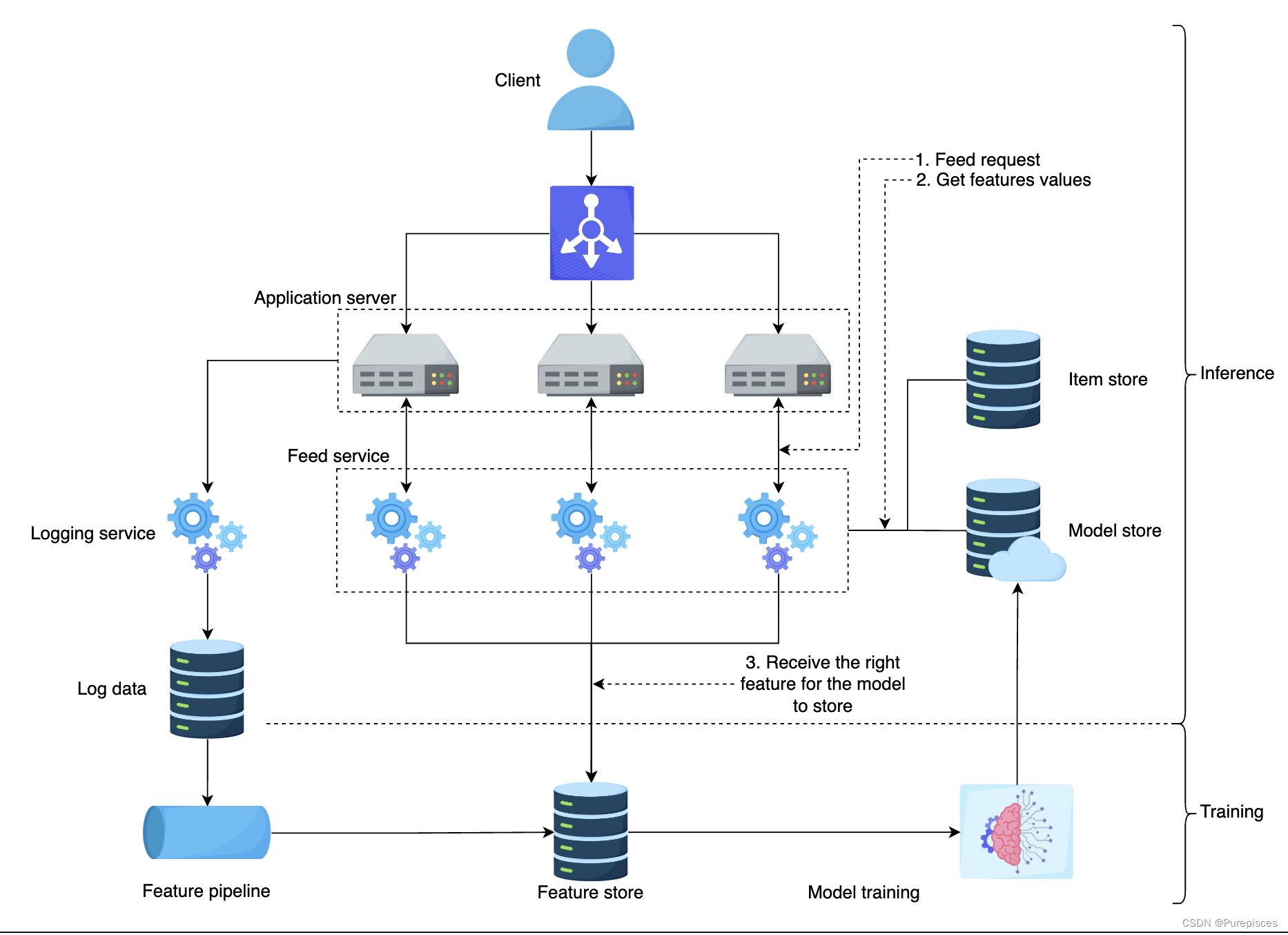
5. 高級設計
Feed 排序高級設計
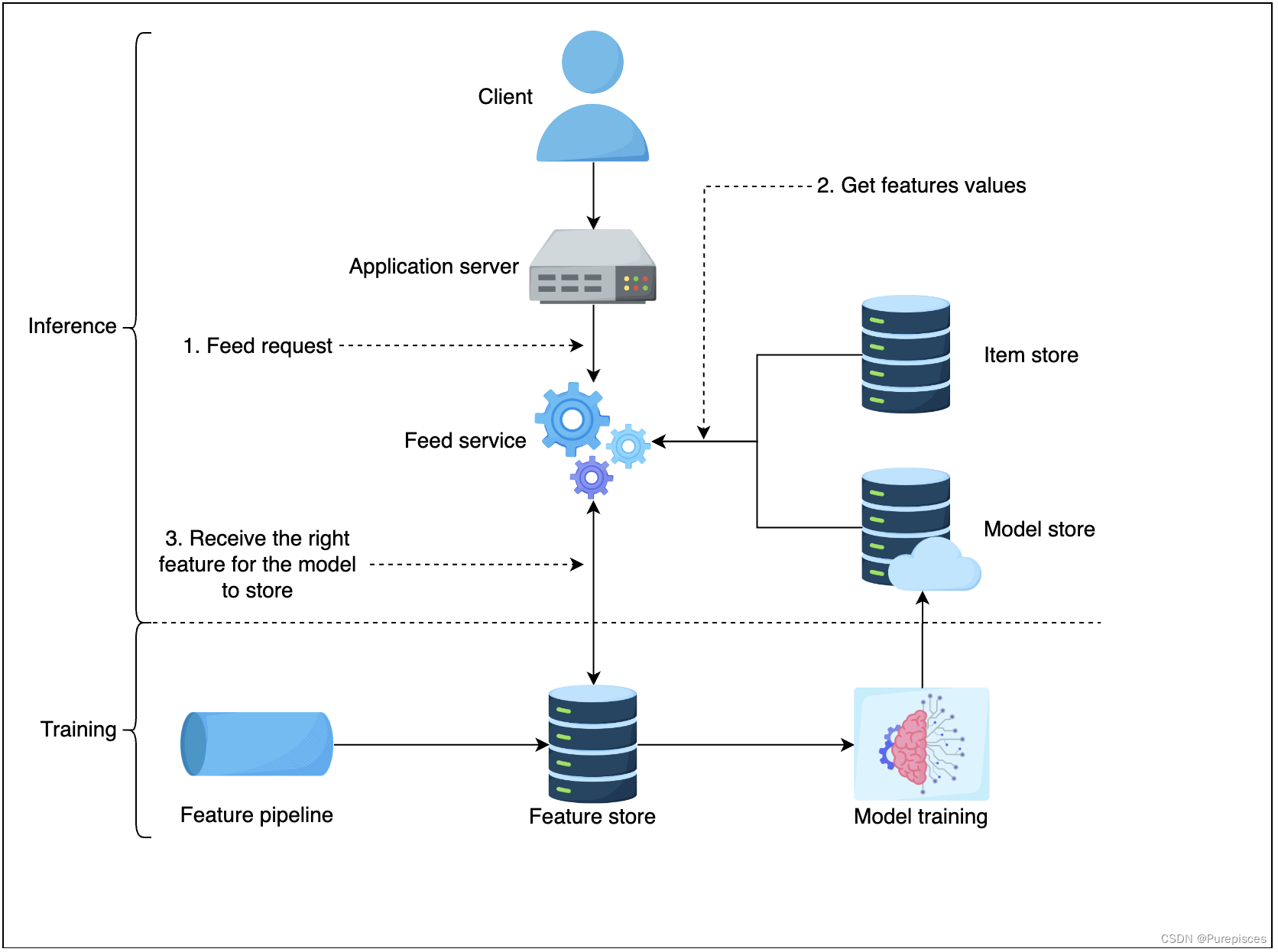
-
特征存儲 是特征值存儲。在推理過程中,我們需要低延遲(<10ms)訪問特征值以進行評分。特征存儲的示例包括 MySQL Cluster、Redis 和 DynamoDB。
-
項目存儲 存儲用戶生成的所有活動。它還存儲相應用戶的模型。一個目標是保持一致的用戶體驗,即對任何特定用戶使用相同的 Feed 排序方法。項目存儲為相應用戶提供正確的模型。
讓我們檢查系統的流程:
-
客戶端向應用服務器發送 Feed 請求
-
應用服務器向 Feed 檢索服務發送 Feed 請求
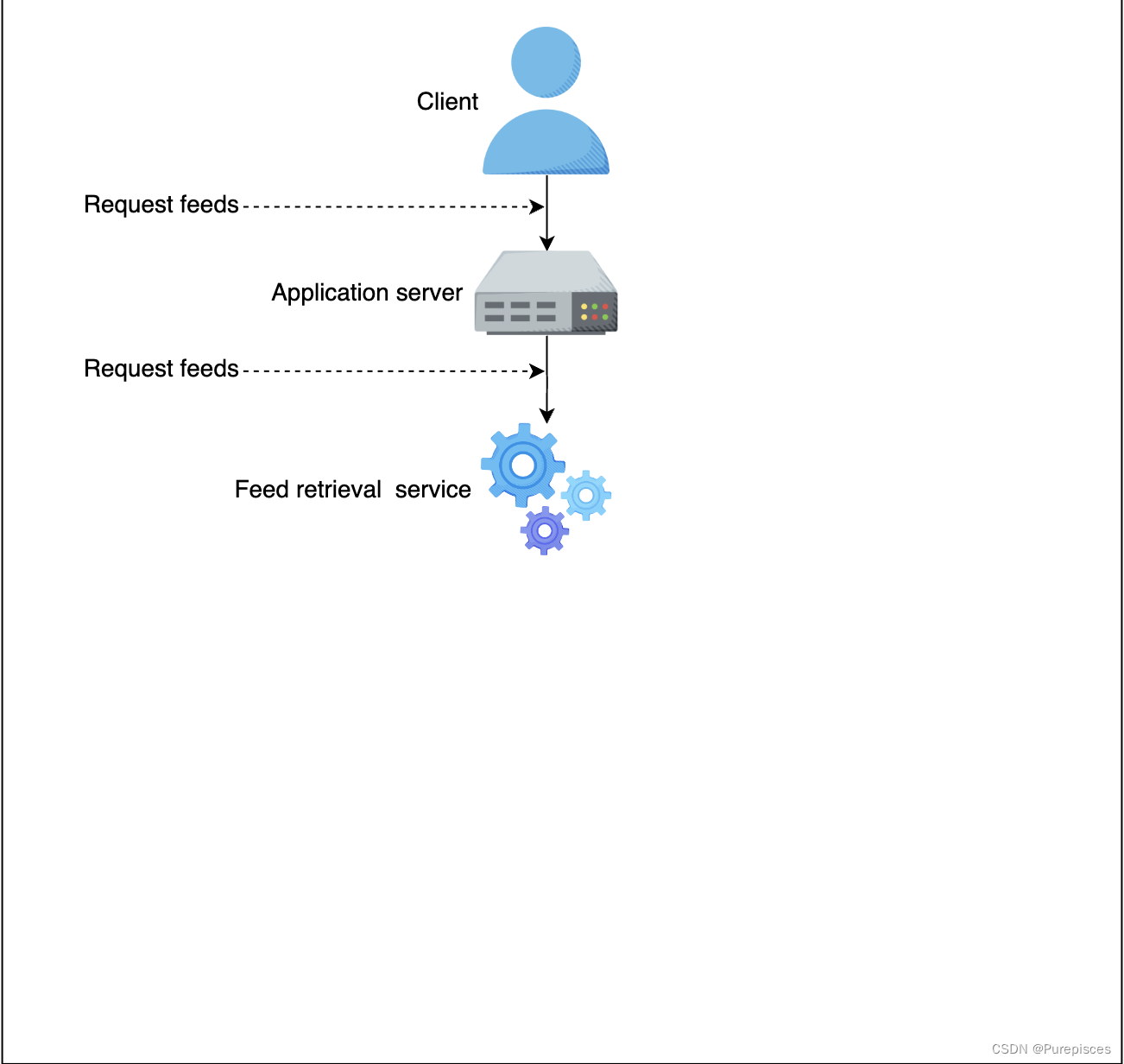
-
Feed 檢索服務從項目存儲中選擇最相關的 Feed
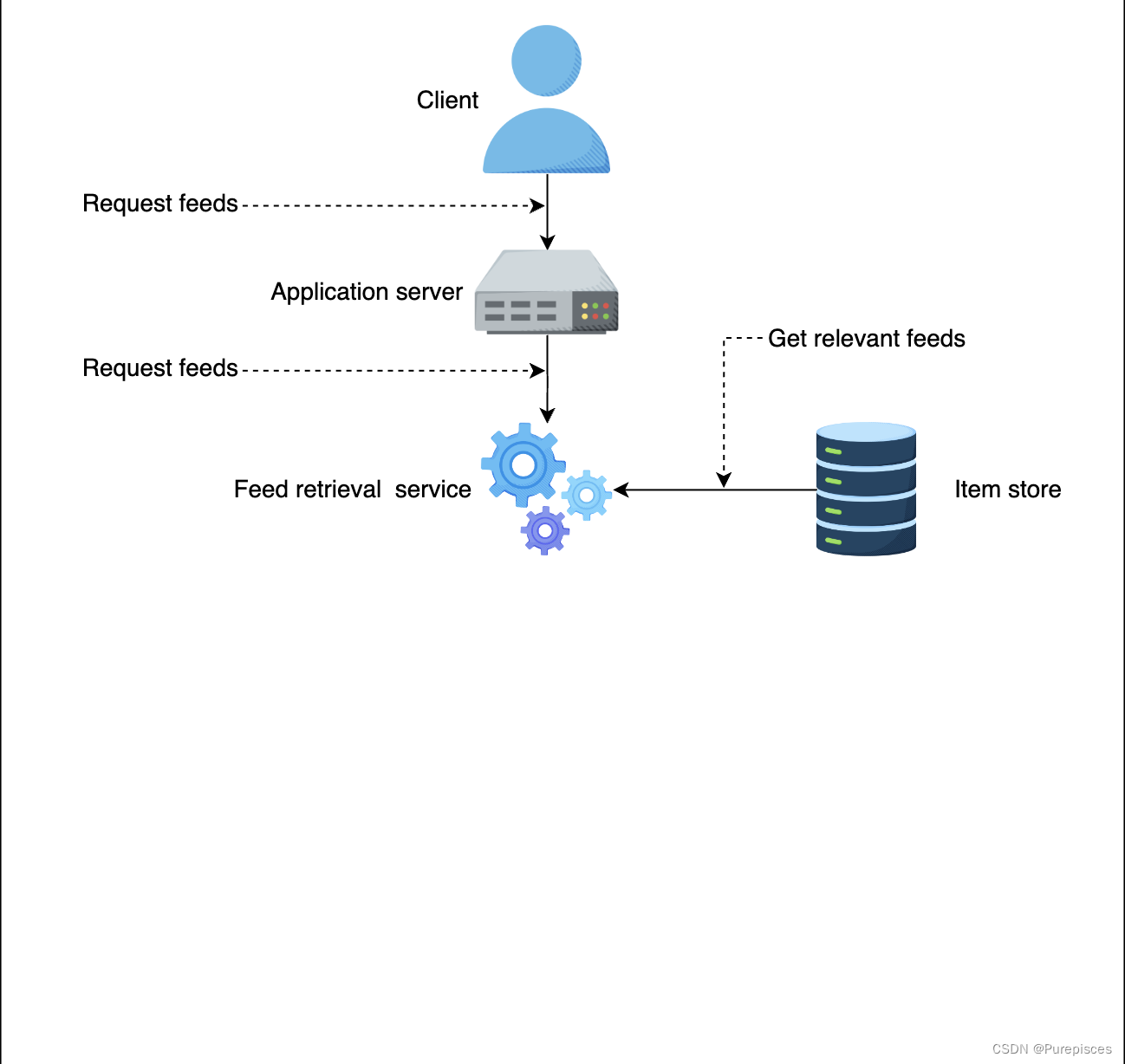
-
Feed 檢索服務向 Feed 排序服務發送 Feed 排序請求
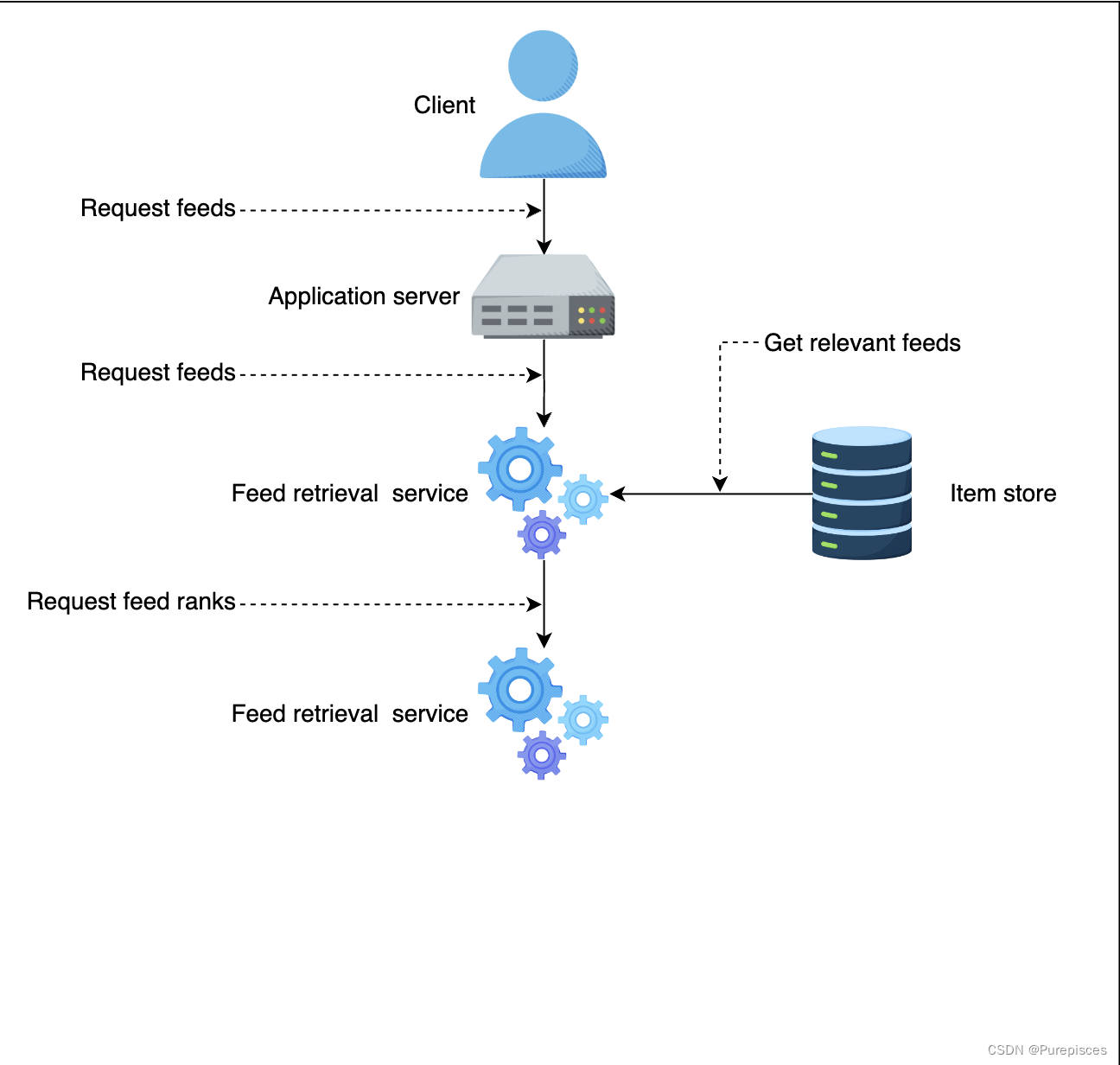
-
Feed 排序服務獲取最新的機器學習模型,從特征存儲中獲取正確的特征

-
Feed 排序服務為每個 Feed 打分并返回給 Feed 檢索服務和應用服務器。應用服務器按排名對 Feed 進行排序并返回給客戶端
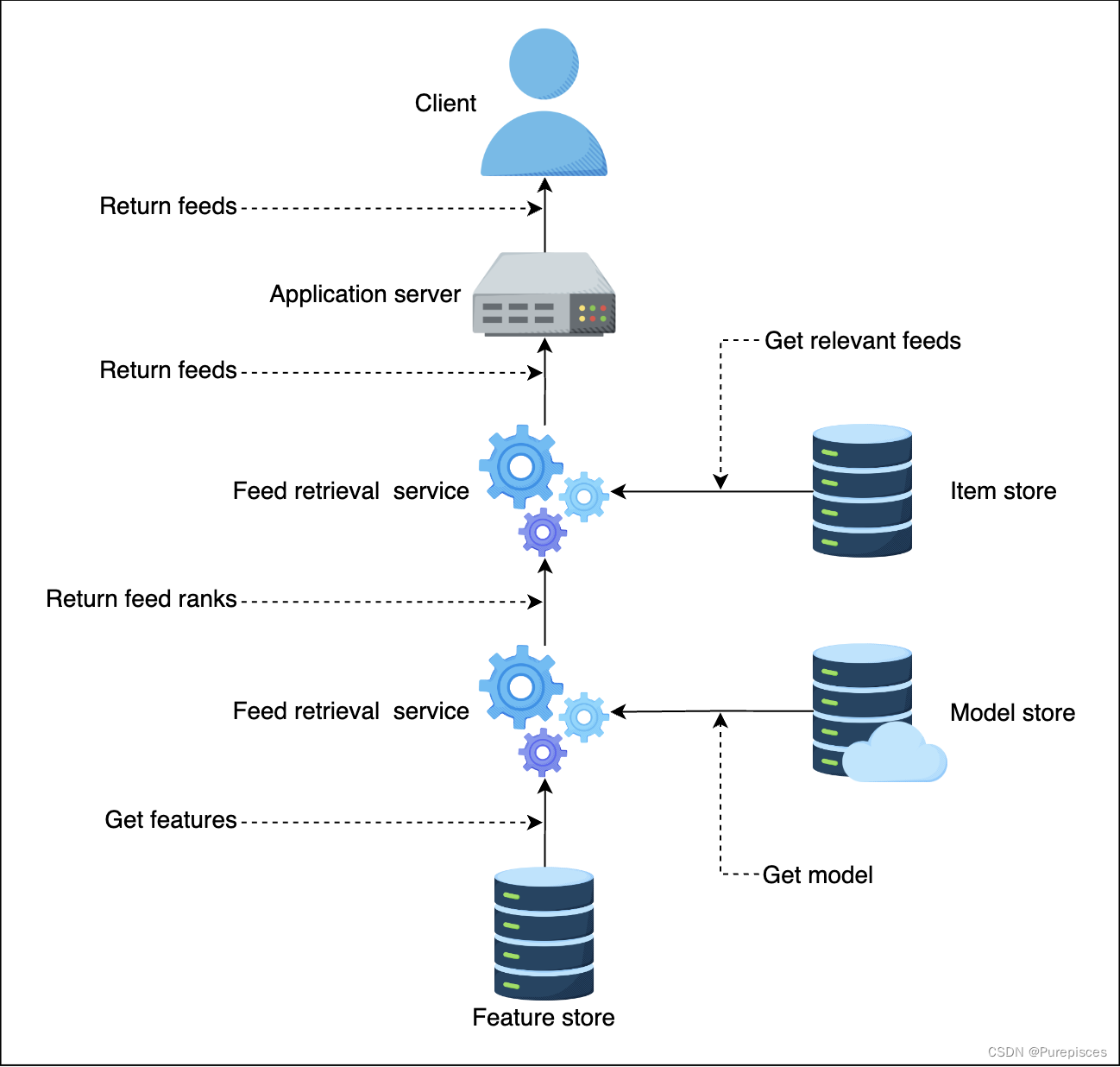
系統流程
- 用戶訪問 LinkedIn 首頁并向應用服務器請求 Feed。應用服務器向 Feed 服務發送 Feed 請求。
- Feed 服務從模型庫獲取最新模型,從特征存儲中獲取正確的特征,并從項目存儲中獲取所有 Feed。Feed 服務將為模型提供特征以獲取預測。
- 模型返回按點擊率可能性排序的推薦 Feed。
6. 擴展設計
- 擴展 Feed 服務模塊,因為它代表了檢索服務和排序服務。這提供了更好的可視化。
- 擴展應用服務器,并在應用服務器前放置負載均衡器以平衡負載。
7. 總結
- 我們學習了如何構建機器學習模型來排序 Feed。具有自定義損失函數的二元分類模型可以使模型對背景點擊率不太敏感。
- 我們學習了如何創建生成機器學習模型訓練數據的流程。
- 我們學習了如何通過擴展應用服務器和 Feed 服務來擴展訓練和推理。
附錄
邏輯回歸數值示例
假設一個簡單的邏輯回歸模型,具有以下權重( θ \theta θ)和輸入特征( x x x):
- 權重: θ = [ θ 0 , θ 1 , θ 2 , θ 3 , θ 4 ] \theta = [\theta_0, \theta_1, \theta_2, \theta_3, \theta_4] θ=[θ0?,θ1?,θ2?,θ3?,θ4?]
- 特征向量: x = [ 1 , 0 , 0 , 3 , 0 ] x = [1, 0, 0, 3, 0] x=[1,0,0,3,0]
這里, θ 0 \theta_0 θ0? 是截距項,其他 θ i \theta_i θi? 值是特征的權重。特征向量 x x x 是稀疏的,具有許多零值。
邏輯回歸計算
邏輯回歸模型計算線性組合 z z z 如下:
z = θ 0 × 1 + θ 1 × x 1 + θ 2 × x 2 + θ 3 × x 3 + θ 4 × x 4 z = \theta_0 \times 1 + \theta_1 \times x_1 + \theta_2 \times x_2 + \theta_3 \times x_3 + \theta_4 \times x_4 z=θ0?×1+θ1?×x1?+θ2?×x2?+θ3?×x3?+θ4?×x4?
將我們的示例中的值代入:
z = θ 0 × 1 + θ 1 × 0 + θ 2 × 0 + θ 3 × 3 + θ 4 × 0 z = \theta_0 \times 1 + \theta_1 \times 0 + \theta_2 \times 0 + \theta_3 \times 3 + \theta_4 \times 0 z=θ0?×1+θ1?×0+θ2?×0+θ3?×3+θ4?×0
簡化計算
因為任何數乘以零都為零,我們可以忽略特征值為零的項:
z = θ 0 × 1 + θ 3 × 3 z = \theta_0 \times 1 + \theta_3 \times 3 z=θ0?×1+θ3?×3
因此,計算簡化為:
z = θ 0 + 3 θ 3 z = \theta_0 + 3\theta_3 z=θ0?+3θ3?
參考資料:
- Machine learning System Design from educative



函數)

![【WP|9】深入解析WordPress [add_shortcode]函數](http://pic.xiahunao.cn/【WP|9】深入解析WordPress [add_shortcode]函數)



)






![[自學記錄09*]Unity Shader:在Unity里渲染一個黑洞](http://pic.xiahunao.cn/[自學記錄09*]Unity Shader:在Unity里渲染一個黑洞)


