HTTP協議
在上一節中,我們提到了協議的本質,其實是雙方約定好的某種格式的數據,常見的就是用結構體或者類來進行表達
而上層的業務邏輯決定了我們協議的定制,有了協議,雙方就可以按照同樣的角度,去解讀數據,這是一個自頂向下的過程
但是,雖然我們說應用層協議是我們程序猿自己定的.
實際上, 已經有大佬們定義了一些現成的, 又非常好用的應用層協議, 供我們直接參考使用.
HTTP(超文本傳輸協議)就是其中之一.
平時我們在瀏覽器輸入對應的網址,就能訪問對應的網站,看到對應的圖片等等,實際采用的就是我們的HTTP協議.
但是,我們又提到過網絡通信的本質,其實是兩個進程進行相互通信
用IP+PORT(端口號)來對進程的唯一性進行標識
所以我們在執行我們自己寫的代碼的時候,在linux系統下,用戶端都需要提供對應服務器端的ip+端口號
./文件.cpp serverip serverport
但我們在瀏覽器中輸入對應的網址,并沒有提供對應想要訪問的服務器端的ip和端口號啊?
進一步思考,網址究竟是什么呢?
這就是我們接下來需要探討的東西.
URL(網址)
URL(Uniform Resource Lacator)叫做統一資源定位符,也就是我們通常所說的網址,是因特網的萬維網服務程序上用于指定信息位置的表示方法.
它的基本格式如下:

總共有7個特點
1)協議方案名
http://表示的是協議名稱,表示請求時需要使用的協議,通常使用的是HTTP協議或安全協議HTTPS。
HTTPS是以安全為目標的HTTP通道,在HTTP的基礎上通過傳輸加密和身份認證保證了傳輸過程的安全性
除了HTTP協議外,還有DNS(Domain Name System)協議,FTP(File Transfer Protocol)協議,TELNET遠程終端協議等等
2)登錄信息認證
usr:pass表示的是登錄認證信息,包括登錄用戶的用戶名和密碼,但一般是被忽略的,我們平時輸入網址的時候,也沒有輸入該內容
3)服務器地址與服務器端口號
www.example.jp表示的是服務器地址,也叫做域名,比如www.baidu.com.
我們需要指定的服務器端ip,其實就是域名,瀏覽器作為軟件,會為我們提供對應的域名解析服務,所以在表面上看,我們輸入的是baidu.com 但在底層實際會被解析為183.2.172.185(百度服務器的ip地址)
在linux系統下通過ping指令,也可以驗證我們這一說法

那可以直接輸IP地址來訪問對應的服務器呢?
也是可以的(前提是你能記住的話)

那為什么不直接輸IP地址來訪問對應的服務器呢?
理由很簡單,一來數字不好記憶,通過baidu.com域名(公司名字拼音)的方式就能訪問對應的網址(資源),對用戶更友好;二來ip地址本身也并不適合給用戶看
那端口號呢?
Server服務器端的port端口號是不能隨意指定的,假如隨意指定,那就亂套了,一個公司說我要端口號80,另一個公司說我也要端口號80,那最終這個端口號應該分配給誰呢?
所以端口號必須是眾所周知且不能隨意更改的!
最簡單解決的方法就是,端口號和成熟的應用層協議一一進行對應! 兩者是1對1強相關的關系
對于HTTP協議而言,端口號為固定的80;而對于HTTPS協議而言,端口號為固定的443
而由于它是固定的,通常我們在輸入網址的時候,也經常把它忽略掉,瀏覽器會自動幫我們進行填充
4)帶層次的文件路徑
有了IP+端口號,我們就可以訪問到對應的服務器(唯一的進程),但具體要訪問的是哪一份數據呢?
這就需要我們指定對應的文件路徑,就像我們在XShell中通過cd指令跳轉到不同的目錄下,去訪問對應服務器的不同資源
比如我們輸入http://www.news.cn/,進入新華網的首頁
鼠標隨機點擊一篇文章進去,可以看到后面就帶上對應的文件路徑

此外我們可以看到,路徑分隔符是/,而不是\,這也就證明了實際很多服務都是部署在Linux系統上的,而不是Windows系統.
5)查詢字符串
uid=1表示的是請求時提供的額外的參數,這些參數是以鍵值對的形式,通過&符號分隔開的,將用戶數據傳遞給對應的服務器!
我們在瀏覽器搜索hello這個單詞的時候,可以看到在URL中就會出現一堆以&進行分割的查詢字符串,其中還有個字符串wd(word)=hello

urlencode和urldecode
在URL中(? / #)等等符號有著特殊的意義,那假如我們就是要搜索對應的這些特殊符號,又應該怎么辦呢?
Url encode 編碼針對的就是解決在url中出現特殊符號的問題(? / #),簡稱為urlencode.
比如我們在瀏覽器搜索?,在URL中我們可以看到它會被編碼成我們的%3F

關于urlencode我們有幾點需要學習
第一,它是我們瀏覽器自動做的,并不需要用戶端自己做的,我們搜索一個問號,并不需要知道怎么編碼
第二,轉義的規則如下:
將需要轉碼的字符轉為16進制,然后從右到左,取4位(不足4位直接處理),每2位做一位,前面加上%,編碼成%XY格式
第三,服務器除了支持編碼,也需要支持解碼decode,簡稱為urldecode
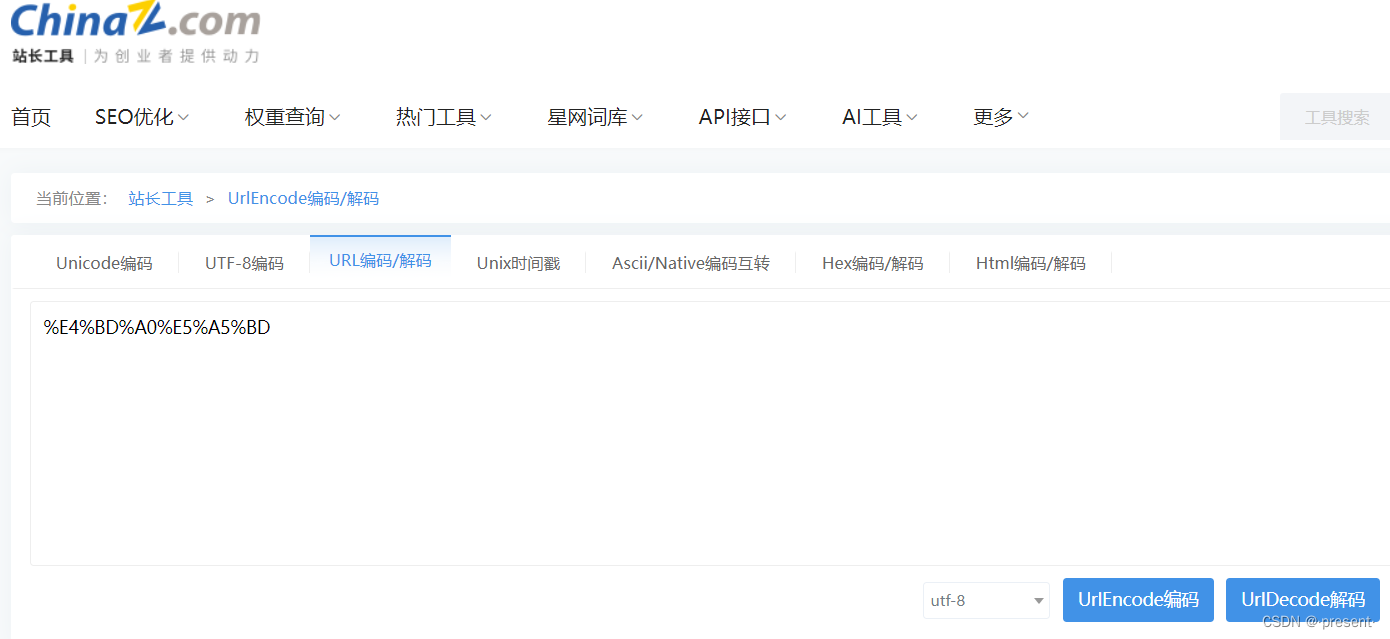
第四,有一些在線網站,其實支持我們在線進行編碼,比如https://tool.chinaz.com/Tools/urlencode.aspx
比如我們輸入你好,然后按下URL編碼鍵

就完成了對應"你好"的urlencode過程
HTTP請求與響應
在用戶端指定對應想要訪問的服務器端的ip+port端口號后,就會向對應的服務器端發送請求,申請對應的資源,隨后服務器端接收到對應請求,給用戶端返回對應的資源(圖片,視頻,運算結果等等)響應.
在我們協議一節中,我們設計的網絡版本計算器協議,請求的格式非常簡單,僅包含x,y兩個操作數以及對應的運算操作符;響應的格式也非常簡單,僅包含計算結果以及對應的錯誤碼.
但大佬設計的HTTP協議請求與響應格式明顯不會這么簡單,這是我們接下來需要詳談的部分.
HTTP請求
先來看HTTP請求的格式
總共可以分為四個部分,分別是請求行,請求報頭,空行以及有效載荷(可以沒有),兩兩之間以\r\n作為分割符隔開
其中請求行又包括請求方法,我們剛剛所學的URL,以及對應的協議版本,兩兩之間以空格隔開
請求方法:
有時也叫“動作”,來表明Request-URL指定的資源不同的操作方式
常見的一般指定為GET(獲取資源)或者POST(傳輸實體主體)
URL:
統一資源定位符,也被稱為網址,用來定位服務器資源
協議版本:
協議并非一成不變的,會不斷進行更新,這就像市面上存在不同的微信版本供我們下載
有HTTP1.0,1.1,2.0等等,通過指定協議版本,能讓新老客戶端很好的使用不同的功能

整個HTTP請求的格式設計其實與我們自主設計的網絡版本計算器邏輯類似
我們的請求需要以\r\n作為分割,HTTP請求也同樣是以\r\n進行數據的分割,實現序列化與反序列化提取對應數據的功能.
而HTTP請求中還單獨多了一個空行,這是因為我們還需要將報頭和有效載荷進行分離,讀到空行,則報頭就意味著讀完了.
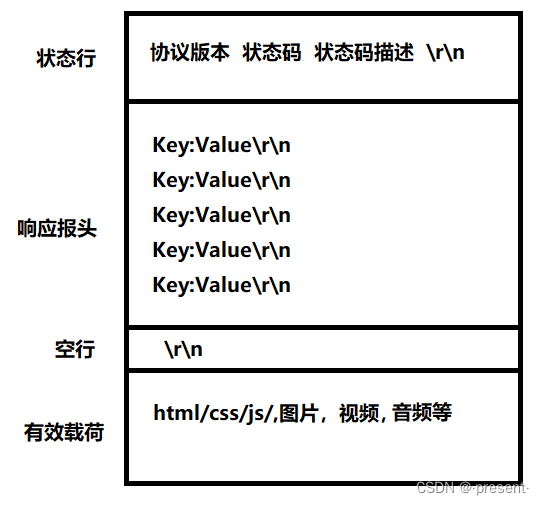
HTTP響應
HTTP響應是與請求一一進行對應的
總共也可以分為四個部分,分別是狀態行,響應報頭,空行以及有效載荷(可以沒有),兩兩之間以\r\n作為分割符隔開
其中狀態行又包括協議版本,狀態碼,以及對應的狀態碼描述,兩兩之間以空格隔開
協議版本很好理解,請求為HTTP1.0,則返回的響應也是HTTP1.0,防止因為雙方使用的http版本不同而導致無法正常通信,保證通信雙方良好的兼容性.
狀態碼我們也不陌生,有時候我們訪問某些網站時,屏幕顯示的404,就是我們對應的狀態碼
對狀態碼進行的解釋,比如NOT FOUND,我們稱之為狀態碼描述
與HTTP請求類似,HTTP響應也同樣是以\r\n進行數據的分割,實現序列化與反序列化提取對應數據的功能.
最簡單的HTTP服務器
下面,我們將編寫一個最簡單的HTTP服務器,來看看HTTP請求與響應.
看一看請求與響應
整體編寫的邏輯和我們網絡版本計算器類似(Sock.hpp,Log.hpp等頭文件和上節的相同)
創建一個類Class HttpServer,成員變量包括我們的端口號, Sock,以及成員函數func_t ,這樣上層同樣只需要添加方法即可!
#pragma once
#include <iostream>
#include <cstring>
#include <pthread.h>
#include <functional>
#include "Sock.hpp"
#include "Log.hpp"namespace http_server
{using func_t = std::function<std::string(std::string &)>;static const uint16_t defaultport = 8888;class HttpServer;class HttpData{public:HttpData(int sock, const std::string &ip, const uint16_t &port, HttpServer *htsr): _sock(sock), _clientip(ip), _clientport(port), _htsr(htsr){}~HttpData() {}public:int _sock;std::string _clientip;uint16_t _clientport;HttpServer *_htsr;};class HttpServer{public:HttpServer(func_t func, int port = defaultport): _func(func), _port(port){}~HttpServer() {}void InitServer(){_listensock.Socket();_listensock.Bind(_port);_listensock.Listen();}// 實際處理服務的方法void HandlerHttpRequest(int sock){char buffer[4096]; //創建一個緩沖區std::string request;ssize_t s = recv(sock,buffer,sizeof(buffer) - 1,0);if(s > 0){buffer[s] = 0;request = buffer;std::string response = _func(request); //服務器進行業務處理send(sock,response.c_str(),response.size(),0); //向用戶端發送響應}else{LogMessage(Info, "client quit...");}}static void *threadRoutine(void *args){pthread_detach(pthread_self());HttpData *td = static_cast<HttpData *>(args);td->_htsr->HandlerHttpRequest(td->_sock);close(td->_sock);delete td;return nullptr;}void Start(){while (true){std::string clientip;uint16_t clientport;int sock = _listensock.Accept(&clientip, &clientport);if (sock < 0)continue; // 假如連接失敗,則繼續重連pthread_t pid;HttpData *td = new HttpData(sock, clientip, clientport, this);pthread_create(&pid, nullptr, threadRoutine, td);}}private:Sock _listensock;int _port;func_t _func;};
}
對應的makefile文件如下:
httpServer:Main.ccg++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:rm -f httpServer
繼續完成我們main主函數的編寫
#include "HttpServer.hpp"
#include <memory>using namespace http_server;
//用戶使用手冊
static void Usage(std::string proc)
{std::cout << "Usage:\n\t" << proc << " serverport\n" << std::endl;
}std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" <<std::endl;std::cout << message << std::endl;return "";
}
int main(int argc,char* argv[])
{if(argc != 2){exit(USAGE_ERR);}uint16_t port = atoi(argv[1]);std::unique_ptr<HttpServer> tsvr(new HttpServer(HandlerHttp,port));tsvr->InitServer();tsvr->Start();return 0;
}
允許我們對應的服務器程序,并打開我們任意一個瀏覽器訪問我們的服務器,便可以看到HTTP請求輸出在屏幕上,格式和我們之前講的相同

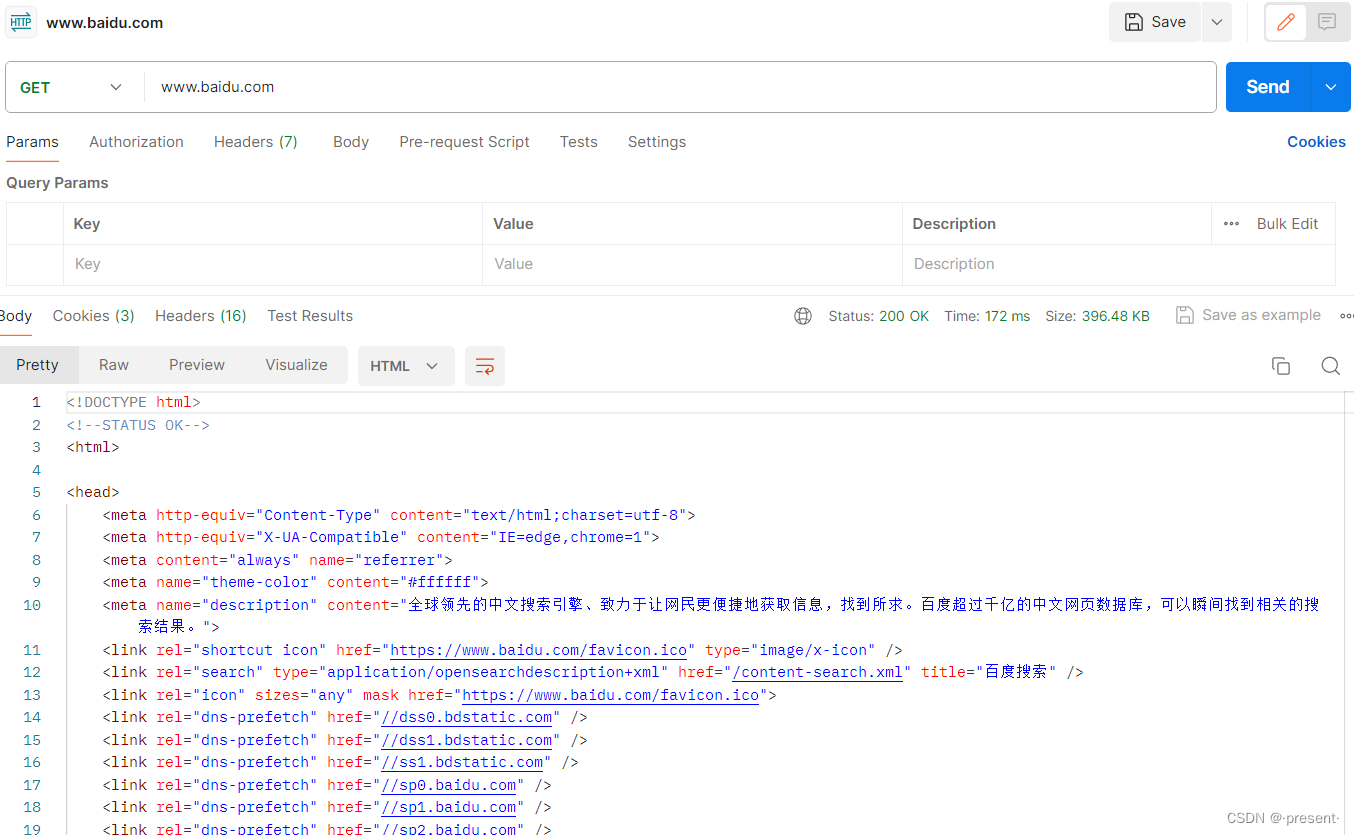
而對于HTTP響應,我們則是在Xshell中直接訪問百度服務器
telnet www.baidu.com 80
發送最簡單的請求GET / HTTP/1.0
便能獲取到百度服務器給我們對應的響應

但是返回的響應,信息實際上是非常多的,并不方便我們查看對應的內容!
我們可以下載一個叫做postman的軟件,輸入對應的網址,它就能輸出比較精美的格式,供我們查看對應的HTTP響應
編寫我們自己的響應
但是,單純這樣還不夠,我們可以嘗試編寫我們自己的響應,實際上就是
HttpServer方法繼續編寫(HandlerHttp函數)
我們在瀏覽器訪問時,響應一般都是以網頁的形式呈現出來,我們編寫的響應也應該以網頁的形式呈現
具體內容可以參照w3school這個網站進行學習
我們今天編寫的網站則沒有這么復雜,只需要有顯示對應文字即可
<html><header><h1>this is a test</h1></header>
</html>
#include "HttpServer.hpp"
#include "Util.hpp"
#include <memory>using namespace http_server;
// 用戶使用手冊
static void Usage(std::string proc)
{std::cout << "Usage:\n\t" << proc << " serverport\n"<< std::endl;
}const std::string SEP = "\r\n";
const std::string path = "./wwwroot/index.html";
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;std::string response = "HTTP/1.0 200 OK" + SEP;response += SEP; //序列化response += "<html><header> <h1>this is a test</h1></header></html>";return response;
}
int main(int argc, char *argv[])
{if (argc != 2){exit(USAGE_ERR);}uint16_t port = atoi(argv[1]);std::unique_ptr<HttpServer> tsvr(new HttpServer(HandlerHttp, port));tsvr->InitServer();tsvr->Start();return 0;
}
對代碼重新進行編譯允許,在瀏覽器上訪問,即可看到我們網頁版顯示內容.
進一步改造響應
但這還并不夠,有一些問題我們其實一直在回避,比如說在網絡版本計算器中,我們會在序列前面加上有效載荷的長度,用來區分不同報頭,那HTTP協議又是如何區分不同報頭呢? 還有我們響應的資源類型有很多種,可能是圖片,也可能是視頻等等,這也是HTTP被稱為超文本傳輸協議的原因.
解決這些問題的答案都在報頭中,報頭中會蘊含不同的報頭屬性,用來解決諸如區分不同報頭,指定資源類型等等問題.
通常,瀏覽器會給你自動處理進行解析,但是我們代碼里面還是要自己編寫的,所以我們上述的HandlerHttp函數還需要繼續進行改造.
Content_Length
Content_Length是報頭屬性之一,它的作用就是用來區分不同的報頭
const std::string SEP = "\r\n";
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;std::string response = "HTTP/1.0 200 OK" + SEP;response += "Content-length: " + std::to_string(body.size()) + SEP; //不要忘了加SEPresponse += SEP;response += body;return response;
}
Content-Type
Content-Type也是報頭屬性之一,它的作用就是指定Body(資源/有效載荷)的種類,它將決定瀏覽器將以什么形式、什么編碼讀取這個文件
那如何確定一個資源,它到底是什么類型呢?
無論是什么資源,比如說圖片,網頁,視頻,音頻等等,它的本質都是文件!是文件就都要有自己的后綴!
比如圖片的后綴是<.jpg .png…> ,網頁的后綴是<.html .htm> ,音頻的后綴是<.mp3>等等
不同的后綴名對應不同的文件類型
具體不同的對應關系,可以自行上網搜Content-Type對照表就可以獲得: 菜鳥教程
const std::string SEP = "\r\n";
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;std::string body = "<html><header> <h1>this is a test</h1></header></html>";std::string response = "HTTP/1.0 200 OK" + SEP;response += "Content-length: " + std::to_string(body.size()) + SEP; //不要忘了加SEPresponse += "Content-Type: text/html" + SEP; //不要忘了加SEPresponse += SEP;response += body;return response;
}
從文件中讀取Body(有效載荷)
但是在實際操作中,并不會像我們上述這樣,直接寫一個body字符串,那假如一個網頁的資源非常多,那代碼就會顯得很冗余,而且也不好修改.
實際操作中,程序員大多編寫html等等網頁代碼,我們負責從里面讀取相應的正文內容即可!
對此,我們要編寫一個ReadFile函數,它的功能就是從對應的文件中,讀取對應的內容,并存到我們的字符串中
整體函數可以分為四個部分:
1.調用stat函數來獲取文件大小
2.resize調整string的大小
3.open函數讀取文件內容
4.關閉文件
// 輸入: const &
// 輸出: *
// 輸入輸出: &
static bool ReadFile(const std::string &path, std::string *fileContent)
{// 1.stat函數 獲取文件大小struct stat st;int n = stat(path.c_str(), &st);if (n < 0)return false; // 獲取失敗,返回falseint size = st.st_size;// 2.調整string的大小 resizefileContent->resize(size);// 3.讀取 open函數int fd = open(path.c_str(),O_RDONLY);if(fd < 0) return false; //打開失敗read(fd,(char*)fileContent->c_str(),size);if (n < 0) return false;// 4.關閉close(fd);LogMessage(Info,"read file %s done",path.c_str());return true;
}
創建一個wwwroot文件夾,并創建對應的index.html網頁文件
<html><header><h1>this is a test</h1></header>
</html>
對應的路徑,我們設定為當前路徑,從wwwroot文件夾中的index.html網頁文件中讀取,則我們的HandlerHttp函數又可以進一步修改為
const std::string SEP = "\r\n";
const std::string path = "./wwwroot/index.html";
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;std::string body;Util::ReadFile(path,&body); //返回的是一張網頁std::string response = "HTTP/1.0 200 OK" + SEP;response += "Content-length: " + std::to_string(body.size()) + SEP; // 不要忘了加SEPresponse += "Content-Type: text/html" + SEP; // 不要忘了加SEPresponse += SEP;response += body;return "";
}
反序列化
上述的路徑,文件類型等等,我們其實都是自己給定的,在現實中,服務器應該根據用戶端的請求,提取對應的信息,并給出對應的響應!
(讀取請求------反序列化------分析請求)
我們再回顧一下HTTP請求的格式
現在我們要對其進行反序列化,構建出一個結構體,這樣就可以輕松的調用不同的資源,給用戶返回我們的響應.
結構體的成員變量設計,就是根據HTTP請求來設計
方法上,暫時沒有特殊要求,可以添加一個Print函數,來調試我們反序列化是否成功
class HttpRequest
{
public:HttpRequest() {}~HttpRequest() {}void Print(){LogMessage(Debug, "method: %s, url: %s, version: %s",_method.c_str(), _url.c_str(), _httpversion.c_str());for (const auto &line : _body)LogMessage(Debug, "-%s", line.c_str());}public:std::string _method; // 方法std::string _url; // 資源路徑std::string _httpversion; // 協議版本std::vector<std::string> _body;
};
現在的關鍵就是如何進行反序列化,將一個請求(字符串)轉換為我們的HttpRequest結構體
永遠不要忘記HTTP請求,是以\r\n進行切割內容
所以我們只要編寫兩個函數,一個我們稱之為ReadOneLine函數,它能夠一行一行(按照\r\n)讀取對應的請求行,請求報頭等等,然后壓入vector中,方便我們操作
另一個我們稱之為ParseRequestLine函數,它能夠切割我們的字符串,進一步讀取我們的內容,比如說我們通過調用ReadOneLine函數,可以讀取到請求行,那我們便可以用ParseRequestLine函數進一步切割,獲取到請求方法,URL以及協議版本.
我們先來編寫ReadOneLine函數
它的目標就是找到對應的分割符(\r\n),剪切對應子串,并將對應的子串從原串中刪除,直到原串(HTTP請求)全被提取完
static std::string ReadOneLine(std::string &message, const std::string &sep)
{auto pos = message.find(sep);if(pos == std::string::npos) return "";std::string s = message.substr(0,pos);message.erase(0,pos + sep.size()); //移除對應切割出的部分return s;
}
對于ParseRequestLine函數,我們也可以用find來提取,只不過此時分隔符變為了空格,但還有一個更簡單的方法,那就是用Stringstream類,它可以用輸出的方式,按照空格分割出不同的子串
static bool ParseRequestLine(const std::string &line, std::string *method, std::string *url, std::string *httpVersion)
{std::stringstream ss(line);ss >> *method >> *url >> *httpVersion;return true;
}
整體的所有方法代碼可以整合到一個頭文件中
// Util.hpp
#pragma once#include <iostream>
#include <cstdlib>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <cstring>
#include <sstream>
#include "Log.hpp"
#include <vector>
using namespace std;class Util
{
public:// 輸入: const &// 輸出: *// 輸入輸出: &static bool ReadFile(const std::string &path, std::string *fileContent){// 1.stat函數 獲取文件大小struct stat st;int n = stat(path.c_str(), &st);if (n < 0)return false; // 獲取失敗,返回falseint size = st.st_size;// 2.調整string的大小 resizefileContent->resize(size);// 3.讀取 open函數int fd = open(path.c_str(),O_RDONLY);if(fd < 0) return false; //打開失敗read(fd,(char*)fileContent->c_str(),size);if (n < 0) return false;// 4.關閉close(fd);LogMessage(Info,"read file %s done",path.c_str());return true;}static std::string ReadOneLine(std::string &message, const std::string &sep){auto pos = message.find(sep);if(pos == std::string::npos) return "";std::string s = message.substr(0,pos);message.erase(0,pos + sep.size()); //移除對應切割出的部分return s;}static bool ParseRequestLine(const std::string &line, std::string *method, std::string *url, std::string *httpVersion){std::stringstream ss(line);ss >> *method >> *url >> *httpVersion;return true;}
};
有了上述的方法,我們就可以完成我們的反序列化函數編寫了
按照分割符\r\n進行讀取一行數據,并存入對應的vector中,需要用的時候,只需要用下標就可以提取出.
HttpRequest Desearialize(std::string message)
{HttpRequest rq;std::string line = Util::ReadOneLine(message, SEP); // 根據分隔符讀出第一行Util::ParseRequestLine(line, &rq._method, &rq._url, &rq._httpversion);while (!message.empty()){line = Util::ReadOneLine(message, SEP);rq._body.push_back(line);}return rq;
}
那我們就可以從HTTP請求中提取我們想要的內容(反序列化),
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;HttpRequest rq = Desearialize(message);rq.Print(); //調試,看是否提取成功std::string body;Util::ReadFile(rq._url, &body);std::string response = "HTTP/1.0 200 OK" + SEP;response += "Content-length: " + std::to_string(body.size()) + SEP; // 不要忘了加SEPresponse += "Content-Type: text/html" + SEP; // 不要忘了加SEPresponse += SEP;response += body;return response;
}
Web根目錄
但上述的代碼還是有不足的,一般一個webserver服務器,不做特殊說明,如果用戶之間默認訪問’/‘,我們是絕對不能把整站數據給對方用戶端的,一來有些數據不可以被訪問,二來數據量太大了
所以我們需要添加默認首頁與默認根目錄,這個默認目錄我們稱作為Web根目錄
它并不是實際的linux系統根目錄,而是我們假定的默認根目錄,就像我們打開百度,默認打開的是搜索主頁面(默認根目錄下的默認首頁)

本次實驗我們的Web根目錄則是wwwroot,無論用戶想要訪問什么數據,都是從這個根目錄下開始尋找對應的資源,并且我們保證不能讓用戶訪問wwwtoot里面的任何一個目錄本身,而只能是文件!
所以,我們對HttpRequest類進一步修改,增添真實路徑這一成員變量,并在初始化時,就用默認構造進行初始化
const std::string defaultHomePage = "index.html"; // 默認首頁
const std::string webRoot = "./wwwroot"; // web根目錄class HttpRequest
{
public:HttpRequest() : _path(webRoot){}~HttpRequest() {}void Print(){LogMessage(Debug, "method: %s, url: %s, version: %s",_method.c_str(), _url.c_str(), _httpversion.c_str());LogMessage(Debug, "path: %s", _path.c_str());}public:std::string _method; // 方法std::string _url; // 資源路徑std::string _httpversion; // 協議版本std::vector<std::string> _body;// 真實資源路徑std::string _path;
};
對應的反序列化函數和HandlerHttp函數也可以進一步修改
HttpRequest Desearialize(std::string message)
{HttpRequest rq;std::string line = Util::ReadOneLine(message, SEP); // 根據分隔符讀出第一行Util::ParseRequestLine(line, &rq._method, &rq._url, &rq._httpversion);while (!message.empty()){line = Util::ReadOneLine(message, SEP);rq._body.push_back(line);}rq._path += rq._url; // "wwwroot/a/b/c.html", "./wwwroot/"if (rq._path[rq._path.size() - 1] == '/')rq._path += defaultHomePage;return rq;
}
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;HttpRequest rq = Desearialize(message);rq.Print(); //調試std::string body;Util::ReadFile(rq._path, &body);std::string response = "HTTP/1.0 200 OK" + SEP;response += "Content-length: " + std::to_string(body.size()) + SEP; // 不要忘了加SEPresponse += "Content-Type: text/html" + SEP; // 不要忘了加SEPresponse += SEP;response += body;return response;
}
文件后綴名
假如顯示的不是文本,而是圖片呢?
使用下面的bash指令可以下載對應的圖片到我們的Xshell中
mkdir image //創建名為image的文件夾
> cd image //進入image的文件夾
> wget +網絡圖片鏈接 //下載對應的圖片
> mv 圖片名字 //更改圖片名字
> du -h //查看圖片大小
編寫GetContentType函數,可以根據我們的Content-Type對照表,給不同的文件類型加上對應不同的后綴名
std::string GetContentType(const std::string &suffix)
{std::string content_type = "Content-Type: ";if (suffix == ".html" || suffix == ".htm")content_type += "text/html";else if (suffix == ".css")content_type += "text/css";else if (suffix == ".js")content_type += "application/x-javascript";else if (suffix == ".png")content_type += "image/png";else if (suffix == ".jpg")content_type += "image/jpeg";else{}return content_type + SEP;
}
完整代碼可以修改如下:
#include "HttpServer.hpp"
#include "Util.hpp"
#include <memory>using namespace http_server;
// 用戶使用手冊
static void Usage(std::string proc)
{std::cout << "Usage:\n\t" << proc << " serverport\n"<< std::endl;
}const std::string SEP = "\r\n";
const std::string path = "./wwwroot/index.html";const std::string defaultHomePage = "index.html"; // 默認首頁
const std::string webRoot = "./wwwroot"; // web根目錄class HttpRequest
{
public:HttpRequest() : _path(webRoot){}~HttpRequest() {}
public:std::string _method; // 方法std::string _url; // 資源路徑std::string _httpversion; // 協議版本std::vector<std::string> _body;// 真實資源路徑std::string _path;// 文件后綴std::string _suffix;
};HttpRequest Desearialize(std::string message)
{HttpRequest rq;std::string line = Util::ReadOneLine(message, SEP); // 根據分隔符讀出第一行Util::ParseRequestLine(line, &rq._method, &rq._url, &rq._httpversion);while (!message.empty()){line = Util::ReadOneLine(message, SEP);rq._body.push_back(line);}rq._path += rq._url; // "wwwroot/a/b/c.html", "./wwwroot/"if (rq._path[rq._path.size() - 1] == '/')rq._path += defaultHomePage;auto pos = rq._path.rfind(".");if (pos == std::string::npos)rq._suffix = ".html"; // 沒找到,默認后綴為網頁elserq._suffix = rq._path.substr(pos);return rq;
}std::string GetContentType(const std::string &suffix)
{std::string content_type = "Content-Type: ";if (suffix == ".html" || suffix == ".htm")content_type += "text/html";else if (suffix == ".css")content_type += "text/css";else if (suffix == ".js")content_type += "application/x-javascript";else if (suffix == ".png")content_type += "image/png";else if (suffix == ".jpg")content_type += "image/jpeg";else{}return content_type + SEP;
}std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;HttpRequest rq = Desearialize(message);std::string body;Util::ReadFile(rq._path, &body);std::string response = "HTTP/1.0 200 OK" + SEP;response += "Content-length: " + std::to_string(body.size()) + SEP; // 不要忘了加SEPresponse += GetContentType(rq._suffix);response += SEP;response += body;return "";
}
int main(int argc, char *argv[])
{if (argc != 2){exit(USAGE_ERR);}uint16_t port = atoi(argv[1]);std::unique_ptr<HttpServer> tsvr(new HttpServer(HandlerHttp, port));tsvr->InitServer();tsvr->Start();return 0;
}
PS:超鏈接跳轉,本質其實就是讓html中特定的標簽被瀏覽器解釋,重新發起HTTP請求
HTTP方法
HTTP常用的方法有如下幾種
| 方法 | 說明 | 支持的HTTP協議版本 |
|---|---|---|
| GET | 獲取資源 | 1.0、1.1 |
| POST | 傳輸實體主體 | 1.0、1.1 |
| PUT | 傳輸文件 | 1.0、1.1 |
| HEAD | 獲得報文首部 | 1.0、1.1 |
| DELETE | 刪除文件 | 1.0、1.1 |
| OPTIONS | 詢問支持的方法 | 1.1 |
| TRACE | 追蹤路徑 | 1.1 |
| CONNECT | 要求用隧道協議連接代理 | 1.1 |
| LINK | 建立和資源之間的聯系 | 1.0 |
| UNLINK | 斷開連接關系 | 1.0 |
最為常用的是GET與POST方法
瀏覽器客戶端向服務器發起請求時,攜帶的方法一般就是GET或者POST
一般沒有指定的話,用的都是GET方法
那兩者的區別在哪呢?
提交參數的方式不同,對于GET方法而言,是直接通過URL的方式進行參數提交;而POST請求,提交數據的時候,URL不會發生變化 ,沒有參數它是通過正文部分提交參數的!
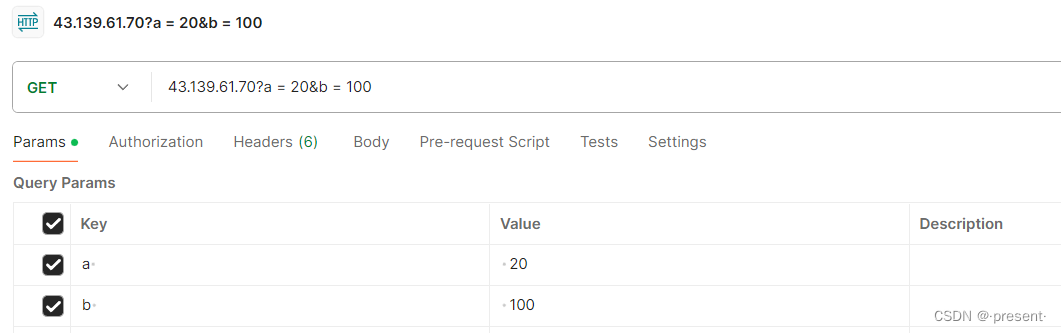
我們可以用Postman軟件對照GET和POST的區別,只需要運行我們的服務器,然后用Postman發出請求時,添加對應的參數,選擇不同方式,進行發送即可
那GET和POST各自的應用場景是什么呢?
用GET方法提交參數,是不私密的(不是不安全),很容易被竊取到對應的信息
而POST提交參數比較私密一點,畢竟提交的參數是在正文,而不是直接在URL字符串中顯示
一般而言,對于登錄注冊支付(QQ空間密碼)等行為,都要使用POST方法提交參數
一來會相對更私密,二來對于Url請求行字符串,一般都會有大小的約束,正文理論上則可以非常大!
但無論是GET和POST方法都不要直接說是安全還是不安全!對于我們發送的信息而言,至少都要進行加密!
否則用諸如Fiddler等軟件,很容易就能竊取到對應的消息
HTTP狀態碼
HTTP的狀態碼如下:
| – | 類別 | 原因 |
|---|---|---|
| 1XX | Informational(信息性狀態碼) | 接收的請求正在處理 |
| 2XX | Success(成功狀態碼) | 請求正常處理完畢 |
| 3XX | Redirection(重定向狀態碼) | 需要進行附加操作以完成請求 |
| 4XX | Client Error(客戶端錯誤狀態碼) | 服務器無法處理請求 |
| 5XX | Server Error(服務器錯誤狀態碼) | 服務器處理請求出錯 |
最常見的狀態碼,比如200(OK),404(Not Found),403(Forbidden請求權限不夠),302(Redirect),504(Bad Gateway)
PS:404報錯屬于客戶端報錯,而不是服務器端的錯,這就好比你去魚店買菜,而賣魚店里面沒有菜賣,這不是賣魚店的錯,而是你的錯,沒事不去賣菜的店買菜,而去魚店買菜,這不是自找苦吃嗎?
但服務器端有必要提醒用戶并沒有對應的資源存在!
404 NOT FOUND
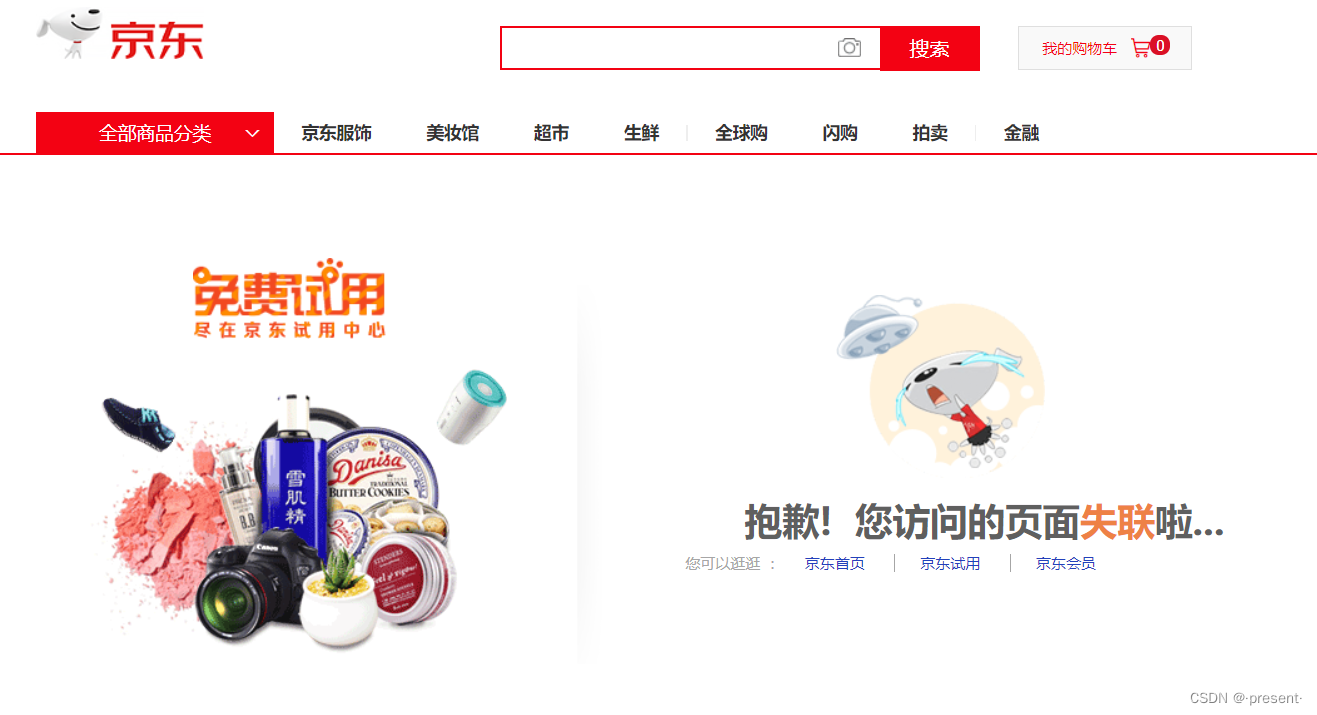
比如我們打開諸如京東等等外賣的網站,輸入不存在的資源路徑

京東網站會給我們輸出對應的錯誤資源信息
想要做到顯示404頁面代碼也很簡單,只需要修改源代碼,改成if else的邏輯進行頁面顯示即可
創建一個404顯示報錯頁面(page_404.html)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>404 Not Found</title>
<style>
body {
text-align: center;
padding: 150px;
}
h1 {
font-size: 50px;
}
body {
font-size: 20px;
}
a {
color: #008080;
text-decoration: none;
}
a:hover {
color: #005F5F;
text-decoration: underline;
}
</style>
</head>
<body>
<div>
<h1>404</h1>
<p>頁面未找到<br></p>
<p>
您請求的頁面可能已經被刪除、更名或者您輸入的網址有誤。<br>
請嘗試使用以下鏈接或者自行搜索:<br><br>
<a href="https://www.baidu.com">百度一下></a>
</p>
</div>
</body>
</html>
將服務器代碼修改為if else邏輯
#include "HttpServer.hpp"
#include "Util.hpp"
#include <memory>using namespace http_server;
// 用戶使用手冊
static void Usage(std::string proc)
{std::cout << "Usage:\n\t" << proc << " serverport\n"<< std::endl;
}const std::string SEP = "\r\n";
const std::string path = "./wwwroot/index.html";const std::string defaultHomePage = "index.html"; // 默認首頁
const std::string webRoot = "./wwwroot"; // web根目錄
const std::string page_404 = "./wwwroot/err_404.html"; //無法找到對應資源時,顯示的頁面class HttpRequest
{
public:HttpRequest() : _path(webRoot){}~HttpRequest() {}void Print(){LogMessage(Debug, "method: %s, url: %s, version: %s",_method.c_str(), _url.c_str(), _httpversion.c_str());// for (const auto &line : _body)// LogMessage(Debug, "-%s", line.c_str());LogMessage(Debug, "path: %s", _path.c_str());}public:std::string _method; // 方法std::string _url; // 資源路徑std::string _httpversion; // 協議版本std::vector<std::string> _body;// 真實資源路徑std::string _path;// 文件后綴std::string _suffix;
};
HttpRequest Desearialize(std::string message)
{HttpRequest rq;std::string line = Util::ReadOneLine(message, SEP); // 根據分隔符讀出第一行Util::ParseRequestLine(line, &rq._method, &rq._url, &rq._httpversion);while (!message.empty()){line = Util::ReadOneLine(message, SEP);rq._body.push_back(line);}rq._path += rq._url; // "wwwroot/a/b/c.html", "./wwwroot/"if (rq._path[rq._path.size() - 1] == '/')rq._path += defaultHomePage;auto pos = rq._path.rfind(".");if (pos == std::string::npos)rq._suffix = ".html"; // 沒找到,默認后綴為網頁elserq._suffix = rq._path.substr(pos);return rq;
}std::string GetContentType(const std::string &suffix)
{std::string content_type = "Content-Type: ";if (suffix == ".html" || suffix == ".htm")content_type += "text/html";else if (suffix == ".css")content_type += "text/css";else if (suffix == ".js")content_type += "application/x-javascript";else if (suffix == ".png")content_type += "image/png";else if (suffix == ".jpg")content_type += "image/jpeg";else{}return content_type + SEP;
}
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;HttpRequest rq = Desearialize(message);//rq.Print();std::string body;std::string response;if (true == Util::ReadFile(rq._path, &body)){ response = "HTTP/1.0 200 OK" + SEP;response += "Content-length: " + std::to_string(body.size()) + SEP; // 不要忘了加SEPresponse += GetContentType(rq._suffix);response += SEP;response += body;}else{response = "HTTP/1.0 404 Not Found" + SEP;Util::ReadFile(page_404, &body);response += "Content-length: " + std::to_string(body.size()) + SEP; // 不要忘了加SEPresponse += GetContentType(".html");response += SEP;response += body;}return response;
}
int main(int argc, char *argv[])
{if (argc != 2){exit(USAGE_ERR);}uint16_t port = atoi(argv[1]);std::unique_ptr<HttpServer> tsvr(new HttpServer(HandlerHttp, port));tsvr->InitServer();tsvr->Start();return 0;
}
但需要注意的是,不同瀏覽器對于協議的支持其實不是那么強,不同公司其實有著自己的狀態碼規定,并非說2xx,對應的一定是成功狀態碼的信息
3xx 重定向
在狀態碼中,還存在重定向這一選項,它的功能就是通過各種方法將各種網絡請求重新定個方向轉到其它位置
它就好比我們出校園的南門吃沙縣小吃,但沙縣小吃剛好在裝修,于是在門外貼了一張告示,讓同學們去西門的臨時店鋪吃,這張告示就發揮著重定向的作用
重定向又分為臨時重定向與永久重定向
臨時重定向,不更改瀏覽器的任何地址信息
永久重定向,會更改瀏覽器的本地書簽!
臨時店鋪那就是臨時重定向,但假如老板發現西門臨時店鋪帶來的生意其實更好,而裝修后的原店鋪反而生意一落千丈,老板將原店鋪關閉,而直接全部轉移到西門店鋪做生意,這就是永久重定向!
不過無論是臨時還是永久,都要求提供新的地址!
我們可以將我們的代碼修改一下,重定向至百度瀏覽器頁面
std::string HandlerHttp(std::string &message)
{std::cout << "---------------------------" << std::endl;std::cout << message << std::endl;HttpRequest rq = Desearialize(message);//重定向測試std::string response;response = "HTTP/1.0 301 Moved Permanently" + SEP;response += "Location: https://www.baidu.com/" + SEP;response += SEP;return response;
}
對于臨時還是永久,都有各自的應用場景
臨時重定向:
1.打開某個小的軟件,直接打開的是廣告,然后跳轉到京東淘寶等軟件
2.掃碼登錄注冊,跳轉到首頁
永久重定向:
1.一個網站,不僅僅是人在訪問,有可能其他的程序也在訪問,比如爬蟲 (搜索引擎)
2.搜出來一個條目,點擊,這個網站過期了,打不開了 (永久更新到新的網址)
會話保持 Cookie && Session
我們應該都遇過一個情況,就是基于HTTP登錄一個網站后,比如說b站,退出后,可以直接登錄,而不用重新輸入密碼進行登錄,甚至我們關機后重啟,也不需要再重新輸入密碼登錄.
HTTP不直接做這個工作,但是用戶需要這個功能,我們把用戶是否在線要持續的記錄下來這個功能稱作為會話保持(Cookie)
不要小瞧這個自動進行認證功能,在之前,client訪問每一個資源的時候,都是需要認證的!
對于VIP用戶來說,每點開一部電影,就要輸入一次賬號和密碼,那大概率會很煩
而有了會話保持功能,那看VIP電影就不用多次登錄,這就好比我們游樂場驗票,我們不需要每玩一個項目,就要買票,直接買一張票,暢玩所有項目卡,大大提高用戶的體驗!
當然,這和HTTP本身協議是無關的,HTTP協議是一種無狀態協議,每次請求/響應之間是沒有任何關系的,這個功能和瀏覽器有關!
在第一次登錄的時候,瀏覽器會將用戶中response(響應)的cookie信息在本地進行保存,并且這種保存不是內存級,而是文件級的,理由就是把瀏覽器關了,再打開對應的網址,依舊可以直接登錄
具體步驟如下圖所示:
1.用戶申請訪問服務器,服務器返回的響應中包含表單屬性,讓用戶輸入賬號和密碼
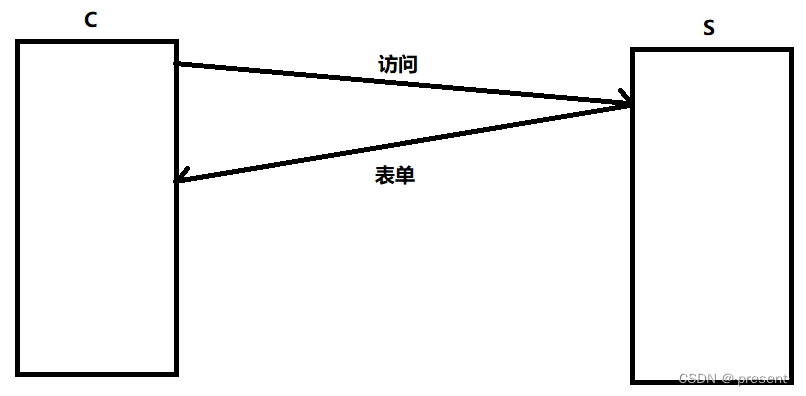
2.服務器對用戶輸入的請求,其中包括賬號和密碼進行驗證,假如驗證成功,則返回對應的資源,返回的響應中還包括Set-cookie字段(用戶輸入的賬號和密碼)
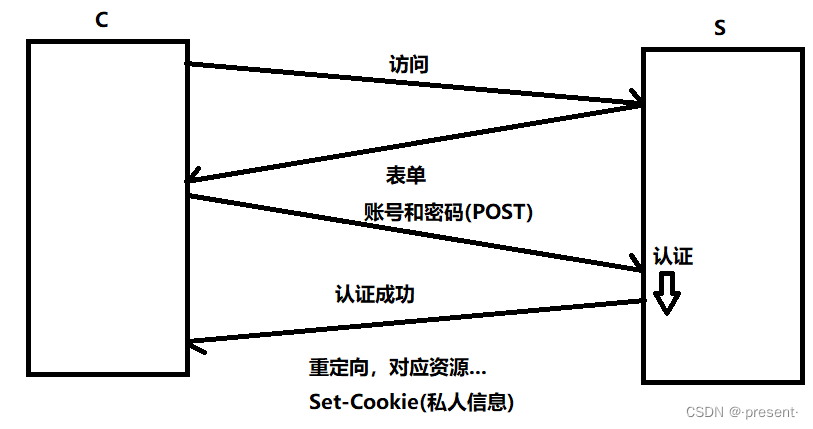
3.通過返回的請求,瀏覽器可以將response(響應)的cookie信息在本地進行保存(文件級)
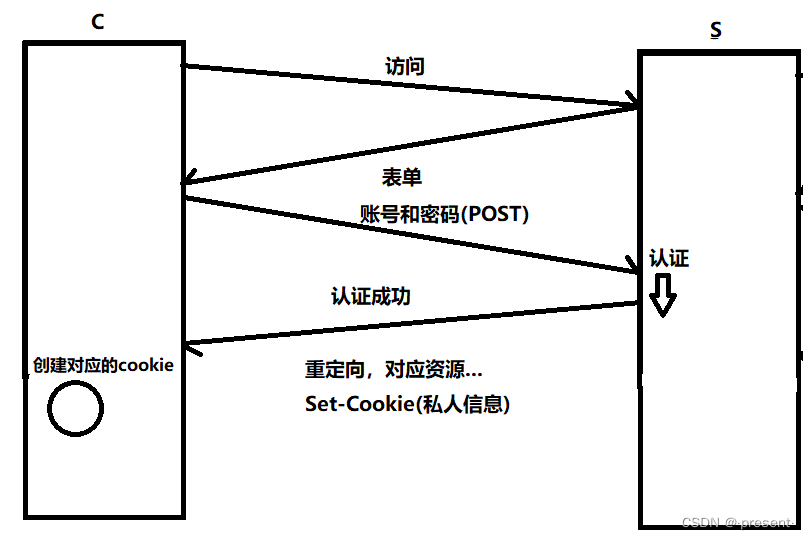
4.此后,對端服務器需要對你進行認證時就會直接提取出HTTP請求當中的cookie字段,而不會重新讓你輸入賬號和密碼了
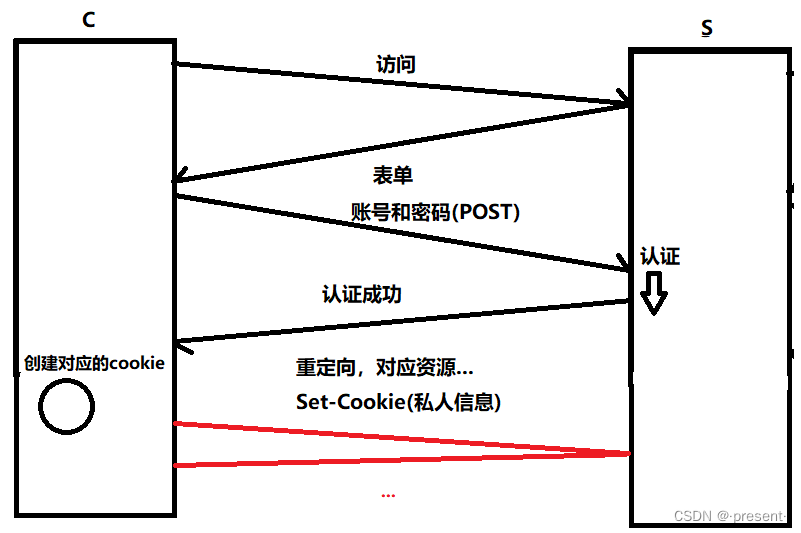
在Edge瀏覽器中,我們也可以看到我們保存的Cookie信息,并對其進行管理

但是這其實并不安全,假如我們電腦中了木馬病毒,比如說不小心進了惡意網站,點了不該點的鏈接等等,黑客就很輕松把你所有的cookie信息全部盜取過來,這樣它就能隨意利用用戶的信息訪問不同網站!
所以現在大多是用當前用戶的基本信息情況形成session對象 ,并且對應唯一的一個Session id
本地cookie文件只保存session id,以及其對應的期限
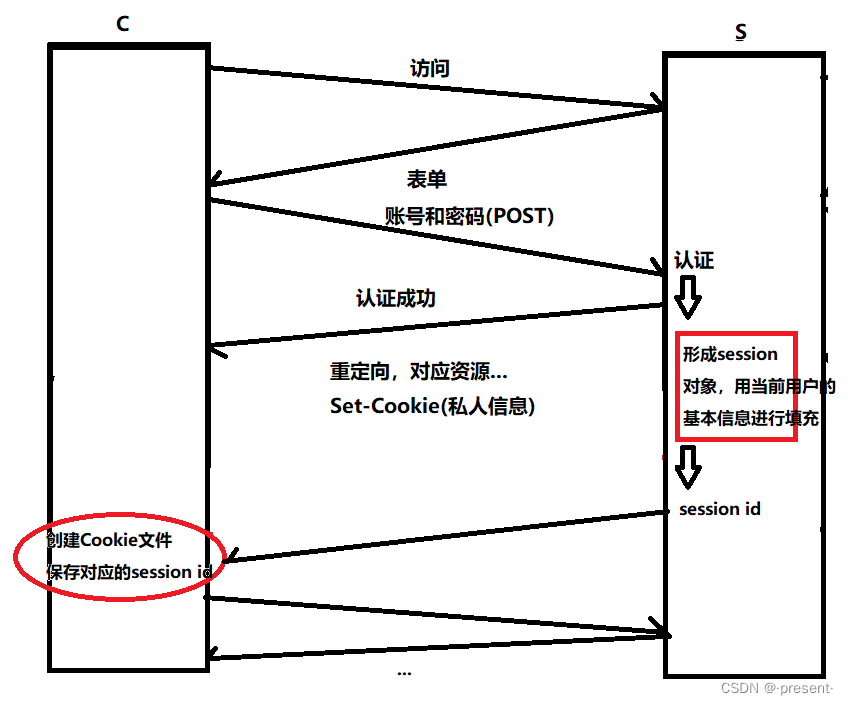
現在我們是通過session id的方式,來訪問對應的資源
有人可能會疑問,這根本沒有解決任何問題啊?
黑客同樣可以盜取用戶的session id來訪問不同的服務器!
但是通過session id的方式來訪問服務器,有兩大優勢所在
第一,用戶信息不再被泄漏,而是被server服務器維護起來,原來則能夠被黑客直接盜取
第二,Session id是會失效的 ,雖然不能徹底杜絕用戶Cookie丟失問題,但我們可以提出相應的新解決方案,比如說驗證ip地址,假如是異地登錄,即便黑客盜取了相應的session id,也無法訪問對應的服務器!
Tokens技術
但是Session技術雖然能夠一定程度緩解黑客入侵盜取信息的問題,但是犧牲的卻是我們服務器端的資源,畢竟在本質上,我們的用戶信息是被我們的服務器端進行維護的.
因此當用戶數量增加時,服務器的負擔也會增加,這可能會影響到應用的擴展性
于是有人就提出了另外一種技術——Tokens技術
Tokens作為計算機術語時,是“令牌”的意思.
它本質上是服務器端生成的一串加密字符串,以作客戶端進行請求的一個令牌
所有步驟都和之前的類似
1.用戶首先向服務器發送登錄請求,包含其憑證,如用戶名和密碼.
2.服務器驗證這些憑證.如果憑證有效,服務器會生成一個token.
不同之處在于,對于Sesson技術來說,用戶信息是我們的服務器端維護,客戶端只需要Session ID即可訪問對應的資源
但是Tokens技術不同,Token令牌是客戶端負責存儲的,通常是在本地存儲或者cookie中
用戶假如想訪問對應的服務器資源時,Token會被附加在請求頭中發送給服務器,即想要訪問對應的資源,只需要出示自己的token令牌即可(有點對暗號的感覺)
當然,黑客同樣也可以盜取我們用戶的token,從而訪問服務器資源,但是,依舊是那個道理,雖然我們不能徹底杜絕用戶token丟失問題,但我們可以提出相應的新解決方案
比如給token加數字簽名,以防止內容被篡改等等
基于tokens技術提出來的方案有很多,各式各樣不同的Token令牌種類,這里就不再詳細介紹,有興趣的可以自行去其它博主那搜索了解
JSON Web Tokens (JWT):
這是一種開放標準(RFC 7519),它定義了一種緊湊且自包含的方式,用于在各方之間安全地傳輸信息作為JSON對象。這個信息可以被驗證和信任,因為它是數字簽名的.JWT可以使用秘密(使用HMAC算法)或使用RSA或ECDSA的公/私鑰對進行簽名.
OAuth2 Tokens:
OAuth2是一個授權框架,它允許應用程序獲得有限的訪問權限到用戶帳戶。它主要用于授權,而不是身份驗證。OAuth2定義了四種授權方式來獲取Access Token,這些Token可以用來訪問受保護的資源。
Bearer Tokens:
Bearer Token是一種非常簡單的安全令牌,沒有簽名和加密機制,但是在傳輸過程中需要通過HTTPS進行保護.Bearer Tokens在OAuth 2.0規范中被廣泛使用。
Refresh Tokens:
在OAuth2中,Refresh Token用于在當前Access Token過期后獲取新的Access Token,而無需用戶重新認證。這對于那些需要長時間訪問用戶數據的應用程序非常有用。
API Keys:
API密鑰通常用作服務的簡單訪問令牌。它們通常是長期有效的,并且與特定的應用程序或用戶關聯。然而,它們通常不包含任何用戶信息,只是允許服務器識別請求的來源.
DNS服務
hosts文件
DNS(Domain Name System),是一整套從域名映射到IP的系統
我們說假如想要訪問對應的服務器,需要目標服務器的IP+端口號Port訪問網絡中唯一一個進程
瀏覽器作為軟件,在底層會為我們提供對應的域名解析服務,所以在表面上看,我們輸入的是baidu.com ,但在底層實際會被解析為183.2.172.185(百度服務器的ip地址)
將域名轉換為對應的IP系統,便被稱為DNS服務
IP它就好比我們的手機號,數目一旦多起來,便很難記住,但是姓名很容易記住,域名也是如此,通過域名就能訪問對應的服務器,這也是我們老百姓想要的,正所謂產品越簡單,越容易推行.
它的本質是一個字符串, 并且使用hosts文件來描述主機名和IP地址的關系
在Linux系統下,我們輸入下面的指令也可以查看我們對應的hosts文件
cat /etc/hosts
所以有的時候,我們QQ等其它軟件可以用,但是瀏覽器就是上不了網,訪問不了對應的網站,可能是域名解析DNS出了問題.
DNS服務器
最初, 我們通過互連網信息中心(SRI-NIC)來管理hosts文件
如果一個新計算機要接入網絡, 或者某個計算機IP變更, 都需要到信息中心申請變更hosts文件.
其他計算機也需要定期下載更新新版本的hosts文件才能正確上網.
但是這樣就會很麻煩,于是產生了DNS系統.
1.它是一個組織的系統管理機構, 維護系統內的每個主機的IP和主機名的對應關系.
2.如果新計算機接入網絡, 將這個信息注冊到數據庫中;
3.用戶輸入域名的時候, 會自動查詢DNS服務器, 由DNS服務器檢索數據庫, 得到對應的IP地址,當然并不是每次輸入域名都要查詢,它在瀏覽器中是有緩存功能的
查詢過程
但是我們說,全球有這么多家公司,每家公司又有這么多臺服務器,DNS服務器能夠容納那么多IP和主機名對應的關系嗎?
我們說并沒有,或者更進一步說,并不想要這樣的結果
一是機器承擔不起這樣的負擔
二是域名不斷在增加與注銷,要通知全球所有DNS服務器更新賬本,這樣的消耗是巨大的
所以,我們采取的是層級劃分的方法
在域名當中,我們有一級域名,二級域名的概念
比如我們熟知的
com:一級域名,表示這是一個工商企業域名.
同級的還有.net(網絡提供商)和.org(開源組織或非盈利組織)等,像是我們Linux內核源代碼網站,對應的域名就是kernel.org,表示非盈利組織
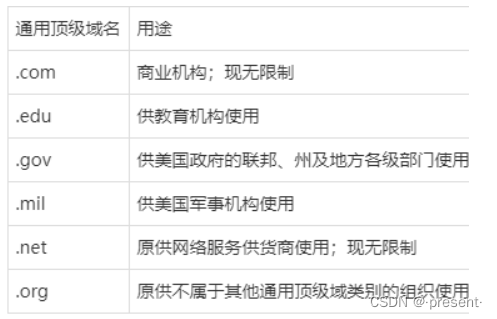
baidu:二級域名,一般對應的就是公司名
例如,我們在瀏覽器中輸入對應的域名www.example.com.cn
瀏覽器首先會在自己的緩存里面查找,看看有沒有對應的域名和IP對應;有則直接返回
發現沒有的話,就會去查詢操作系統中的DNS緩存;有則直接返回
還是沒有的話,就會去查找本地的hosts文件;有則直接返回
假如還是沒有,此時才會去查找當地的DNS服務器,本地DNS服務器IP地址一般由本地網絡服務商提供,如電信、移動等公司,一般通過DHCP自動分配,如果有對應的域名和IP對應關系,則直接返回,這個過程稱之為本地DNS解析
但是假如本地DNS服務器都也沒找到對應的域名和IP對應關系,我們只能去找對應的根DNS服務器了
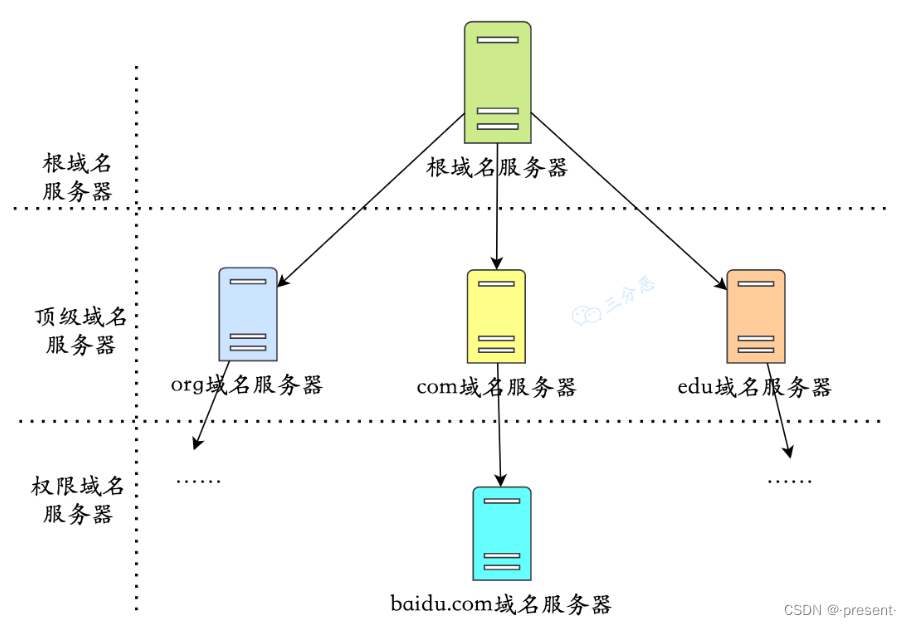
然后我們從根DNS服務器開始,逐級查詢對應的DNS服務器,直到找到具體的IP地址
比如在解析"www.example.com"時(假設本地DNS服務器沒有找到),我們會先去問"老大哥"根DNS服務器,但它不會直接返回IP地址給我們,而是返回負責.com頂級域的"二哥"頂級域名服務器的地址
同樣的,"二哥"它也不會直接返回IP地址,而是返回負責example.com的權限DNS服務器的地址
最后,本地DNS服務器接收到權限DNS服務器的地址后,向其發送查詢請求.
權限DNS服務器會查找自己的記錄,找到www.example.com對應的IP地址,然后返回給本地DNS服務器,本地DNS服務器再發回給我們.
在這個過程中,我們可以發現,全部都是由當地的DNS服務器全程參與負責,我們只需要等待結果就好,這樣美滋滋的查詢方式,我們稱之為遞歸查詢
假如客戶端向DNS服務器發送查詢請求,如果DNS服務器沒有存儲所需的信息,但是它自己不去查,而是將其他可能知道信息的DNS服務器的地址返回給客戶端,然后要客戶端自己,向這些服務器發送查詢請求,然后不斷重復這個過程,直到獲取最終的查詢結果
在這個過程中,客戶端需要參與整個查詢過程,這樣的查詢方式,我們稱之為迭代查詢
通過這樣層級劃分管理域名對應關系的方式(分而治之),各級DNS各司其職,統一將全球的域名成功解析,并完成去中心化的任務.
但是這里也會存在一個問題,根服務器應該設置到哪里呢?
畢竟一旦根服務器出故障,或者主動令某個國家無法訪問對應的根服務器,導致無法使用域名解析服務,那造成的損失將是不可估計的,畢竟現在的一切事物都和互聯網脫不開干系,而老百姓也不知道對應服務器的IP地址和端口號,一定會造成巨大的經濟損失.
所以,全世界根域名服務器的個數和分布,其實也象征著國家的某種實力
全世界一共有13臺根服務器,足足有9臺在美國,也足以看出來問題.
中文域名
除了英文域名外,我們發現輸入中文百度在搜索框里,同樣可以訪問對應的百度服務器,"百度"就是所謂的中文域名
在一開始的時候,中文域名其實并不支持,360殺毒軟件的老板,28歲的周鴻祎(鴻祎教主)創建了北京三七二一科技有限公司(3721的名字由“三七二十一”而來,目標是“不管3721,中國人上網真容易”)
它能夠提供對應的中文域名服務,使得用戶可以直接在瀏覽器地址欄輸入中文域名進行網站訪問,而不需要記住復雜的英文域名或者IP地址
當然它的定位并不是一款搜索引擎,別人搜索引擎輸入關鍵詞,還能出現一大片與之相關的網站,而不是某個特定的網站
因此,后面李彥宏回國,創建了百度搜索引擎,并同樣支持中文域名服務,沒過多久,3721就在與百度競爭的過程中逐漸沒落,最后被收購.



)
)
)





)




)


