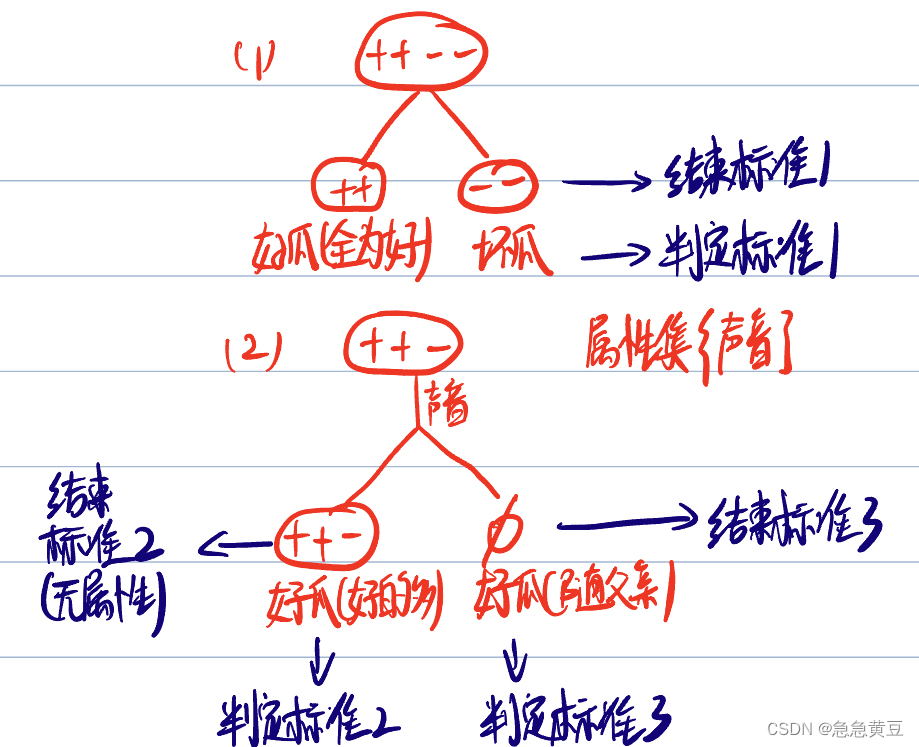
1 遞歸返回情況
? ? ? ? (1)結點包含樣本全為同一類別
? ? ? ? (2)屬性集為空,沒有屬性可供劃分了
? ? ? ? ? ? ? ? 或
? ? ? ? ? ? ? ? 有屬性,但是在屬性上劃分的結果都一樣
? ? ? ? (3)結點為空結點
**結束時判定該結點的類別遵循如下規則:
? ? ? ? (1)若全為一個類別,則該結點為該類別,如全為“好瓜”,則該結點為好瓜
? ? ? ? (2)若某一個類別比其他類別多,則該結點為該類別,如結點中的樣本“好瓜”>“壞瓜”,則該結點為好瓜。
? ? ? ? (3)若所有類別樣本數一樣,或為空集,則取其父節點的類別作為該結點的類別。
2.經典的屬性劃分方法
2.1.信息增益(選大)
- 求樣本集的信息熵,信息熵越小,則集合越純,如果集合只屬于1個類別,那么信息熵為0
- 求每個屬性每個取值的信息熵,這些信息熵按比例相加
- 求每個屬性的信息增益,等于樣本集信息熵減去該屬性的加權信息熵
- 信息熵Ent(D)越小,數據集D的純度越高
- 信息增益越大,則使用該屬性來進行劃分所獲得的“純度提升”越大
2.2.增益率(選大)
- 信息增益對可取值數目較多的屬性有所偏好,所以用增益率克服這一缺點
- 選擇增益率大的屬性,即選擇信息增益大且分支少的屬性
2.3.基尼指數(選小)
- 反映了從D中隨機抽取兩個樣本,其類別標記不一致的概率
- Gini(D)越小,數據集D的純度越高



3.剪枝處理
????????劃分選擇的各種準則雖然對決策樹的尺寸有較大影響,但對泛化性能的影響很有限;而剪枝方法和程度對決策樹泛化性能的影響更為顯著。(也就是說選擇剪枝方法比選基尼指數、信息增益還是增益率這種劃分策略的影響更大)
? ? ? ? 是對付“過擬合”的主要手段,剪枝的基本策略:
3.1.預剪枝
- 采用基于分層采樣的留出法,初始認為所有樣本都是好的,此時可計算模型的正確率為驗證集中好瓜的比例。
- 運用一種屬性劃分方法選擇出一個最好的屬性進行劃分,劃分之后計算加了一層之后的正確率,并與未引入劃分的正確率進行比較,若劃分后的正確率>未劃分就生成,否則不生成。
3.2.后剪枝
????????先生成完整的決策樹,再倒著看每棵子樹是否有價值。如果剪枝后的樹>未剪枝的樹則剪枝,否則不剪,當正確率相等時不做操作,一方面是防止欠擬合,一方面是剪枝也會有一定的開銷。


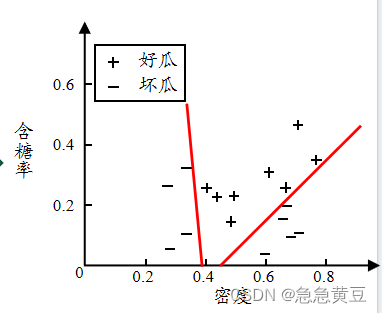
4.連續值處理?
- 與離散屬性不同,若當前結點劃分屬性為連續屬性,該屬性還可作為其后代結點的劃分屬性。也就是在某個點算出按密度<0.35和密度>0.35劃分,后面在計算時還要把密度納入考慮范圍,且下次的劃分點可能就不是0.35了。而別的離散屬性比如顏色,如果用過就從屬性集合中刪去了。
- 方法:二分法

5.缺失值處理
樣本賦權,權重劃分?


單變量決策樹
?
多變量決策樹

)




)





![【2024最新華為OD-C/D卷試題匯總】[支持在線評測] 字符串序列判定(100分) - 三語言AC題解(Python/Java/Cpp)](http://pic.xiahunao.cn/【2024最新華為OD-C/D卷試題匯總】[支持在線評測] 字符串序列判定(100分) - 三語言AC題解(Python/Java/Cpp))






線程的同步 進程間通信)